第一阶段:基础认知与准备 链接到标题
1. RAG基础知识回顾 链接到标题
首先回顾之前的RAG入门内容和基础架构:
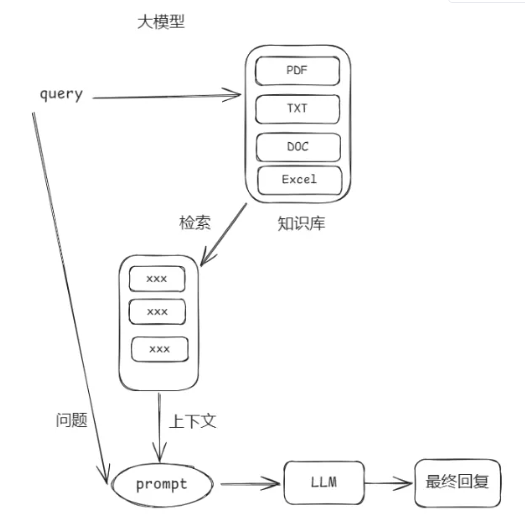
通用大模型的局限性:
- 知识可能过时:大语言模型的训练数据都是存在时效性
- 会产生“幻觉”:生成的内容看似合理,但实际上与既定事实、真实数据或逻辑相悖
- 无法访问私有知识库数据:本身学习不到企业或者个人的私有知识库知识
- 回答缺乏具体出处:调研场景下,回答的内容给出具体的出处,一般是文章、论文等资料
- 最大对话上下文限制:大部分模型上下文限制还是128k左右
RAG的核心要素:
- 检索增强生成(Retrieval + Augmented + Generation)
- 为LLM提供了从某些数据源检索到的信息,并基于此修正生成的答案
- 让大模型学会“查资料”后再回答问题,而不是仅凭记忆回答
- 优势
- 灵活性、适应性强
- 提高大模型回答准确性
- 成本相对低
- 个性化程度高
2. 常见文档类型与解析需求 链接到标题
在真实企业环境中,会遇到各种数据源,特别是在金融领域的财报、报表等场景下,文档解析的需求尤为突出。
常见的文档类型 链接到标题
扩展名称 支持文件类型 适用场景示例
csv
.csv
表格数据提取
docx
.doc, .docx
Word 文档解析
pdf
.pdf
PDF 文本/布局提取
image
.jpeg .png .tiff 等
图片 OCR 文字识别
pptx
.ppt, .pptx
幻灯片内容提取
xlsx
.xls, .xlsx
Excel 表格解析
3. 文档解析挑战认知 链接到标题
理解文档解析的难点 链接到标题
在考虑解析PDF文件时,我们需要根据当前的技术栈发展情况,并结合实际的业务诉求,综合考量这其中的技术难点,因为每一项技术难点所涉及的技术方案都会需要一个算法/或者技术手段去突破。
而开发者从解析的效果去考虑,可以从简单的做起,逐步突破难点,这对于开发人员自身的自信心提升也是一种正向的导向。在整个PDF解析过程中,以下几项是比较难处理的:

布局解析困难:PDF文件的布局可能会因为不同的作者、工具或用途而有所不同,通常具有多列文本,对于图像或表格来说,这些文本可能会突然中断,因此解析其布局是一个具有挑战性的任务。
格式错综复杂:PDF文件中可能包含各种格式的内容,包括文字、图像、表格等,因此解析其内容需要考虑到这种多样性和复杂性。
复合表格:纵向/横向合并的复杂表格,在PDF中进行抽象还原是最难处理的问题之一
文本、图片、表格顺序提取:提取PDF文件中的文本、图片和表格,并确保它们的顺序正确性,是一个需要解决的重要问题。
文档结构还原:还原PDF文件的文档结构,包括标题、目录等信息,是实现自动化文档处理和理解的关键步骤之一。
元数据提取:在PDF中隐藏的元数据信息是RAG产品的关键数据,比如链接、目录、字体等等
扫描件:PDF中如果是扫描件,就需要依靠OCR模型来进行有效的提取,这里面还会包含清晰度、模型的稳定性等等问题
Latex公式提取:在一些特殊领域,PDF文本中包含了Latex等数学公式。通过完整的提取和转换是对RAG问答的有效补充
第二阶段:技术选型与工具对比 链接到标题
1. 主流工具对比与选择 链接到标题
技术选型决策
数字原生PDF:优先选择PyMuPDF,利用其渲染效率优势处理纯文本/简单表格批量任务
扫描PDF:必须启用OCR流程,可搭配Unstructured的"ocr_only"策略
复杂学术文档:推荐Marker(代码/公式支持)或MinerU(数学公式识别),但需容忍GPU加速需求
工具性能对比表 链接到标题
工具 核心优势 适用场景 性能代价
unstructured.io
支持50+格式,生态完善
多源数据ETL入口
处理速度较慢
PyMuPDF
解析速度>200页/分钟
纯文本/简单PDF批量处理
无OCR能力
Marker
代码/公式支持优秀
技术白皮书/学术文献
需GPU加速
MinerU
数学公式识别精准
科技/专利类文档
高计算负载
DoclingAI
表格提取精度98%+
金融财报/科研报告
仅专注表格
DeepDoc
中文优化+端到端方案
中文RAG系统建设
需API调用
2. 文档解析技术差异 链接到标题
PDF解析技术核心差异 链接到标题
PDF解析技术的核心差异体现在对文档结构的处理逻辑上:
PyMuPDF:渲染优先策略,高效文本提取,采用渲染优先策略,通过直接解析页面绘制指令实现高效文本提取;并非直接去“寻找”那些对人类而言可读的文字(内容流),而是像一名打印机,通过理解和执行模拟页面渲染(绘制)过程,执行底层绘制命令,来重建页面的内容,并从中精准定位和识别文本
- 处理速度可达200页/分钟,尤其在规则表格识别中表现出坐标精度优势
- 但缺乏OCR能力,无法处理扫描生成的图像型PDF,且对复杂公式和代码块的支持有限
OCR技术:处理扫描件的核心能力
- 针对无文本层的扫描件或多列布局文档,通过OCR提取文字
OCR生态/大模型 链接到标题
OCR(光学字符识别)最终的目的是将非结构化的图像信息,转化为结构化的、可计算和可理解的数据,所以本质上是对图片内容的理解,可以考虑的开源组件如下:

Unstructured.io的集成优势 链接到标题
Unstructured.io作为集成框架,通过strategy参数实现后端自适应切换:
“fast"策略:调用PyMuPDF等轻量引擎处理规则文档
“hi_res"策略:激活YOLOX目标检测模型进行布局分析,配合detectron2实现表格与图像的精准提取
“ocr_only"策略:使用OCR模型进行图文识别
“vlm"策略:针对极端复杂场景调用GPT-4o等多模态模型,通过视觉语义理解突破传统解析局限
这种混合架构使其在金融财报(表格提取精度98%+)和科研报告等场景中表现突出。
Unstructured的核心优势 链接到标题
可以和Agent框架集成(LangChain、LlamaIndex)
也可以解析多种不同的文档形式(比较通用)
主流应用的比较多、适用性比较广
生态协同核心地位:Unstructured库通过与LangChain主流框架的深度集成(如UnstructuredLoader组件),与LlamaIndex的深度集成(如UnstructuredReader组件)已成为检索增强生成(RAG)pipeline中的关键预处理节点。其能够将非结构化数据转化为向量数据库可索引的结构化格式,有效解决了RAG系统中"数据输入异构性"这一核心痛点,为下游的知识检索与生成任务提供了标准化数据基础
第三阶段:unstructured.io库入门与实践 链接到标题
1. 环境准备与安装 链接到标题
推荐使用Python 3.9及以上版本
(1)基本安装(纯文本处理) 链接到标题
此安装方式适用于处理纯文本:
pip install unstructured
uv add unstructured
(2)全量安装(多类型文档处理) 链接到标题
针对需要处理多类型文档(如PDF、Office格式、图片等)的场景,全量安装会包含docx、pptx、pdf、image等扩展依赖,适合企业级全场景文档处理需求:
包含本地推理能力(支持PDF/图片OCR等)
pip install "unstructured[local-inference]"
支持所有文档类型(不含本地推理,需依赖外部API)
pip install "unstructured[all-docs]"
uv add "unstructured[all-docs]"
(3)特定文档类型安装 链接到标题
如需进一步精简依赖,可按目标文件类型单独安装扩展模块,格式为unstructured[],支持同时指定多个扩展,以逗号分隔:
仅安装PDF和DOCX处理能力
pip install "unstructured[pdf,docx]"
(4)Serverless API安装 链接到标题
Serverless API通过优化处理流程,将文档处理启动时间从30分钟缩短至3秒以内,并支持多区域横向扩展,有效提升了高并发场景下的吞吐量:
pip install unstructured-client
(5)Docker安装 链接到标题
docker pull downloads.unstructured.io/unstructured-io/unstructured:latest
docker run -dt --name unstructured downloads.unstructured.io/unstructured-io/unstructured:latest
docker exec -it unstructured bash
2. 核心系统依赖配置 链接到标题
(1)Tesseract OCR:图像文本识别 链接到标题
提供图像文本识别能力,是处理扫描版PDF和图片文件的核心组件。
- 安装指南:https://tesseract-ocr.github.io/
- 多语言支持:tesseract-lang扩展包
windows安装:
- 下载安装包:https://github.com/UB-Mannheim/tesseract/wiki
- 安装文档参考:https://developer.baidu.com/article/detail.html?id=3803413
macOS安装:
brew install tesseract
brew install tesseract-lang
Linux安装:
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-chi-sim # 中文简体支持
验证安装:
tesseract --list-langs # 查看已安装的语言包
!tesseract -v
(2)Poppler:PDF内容提取底层引擎 链接到标题
通过pdf2image库将PDF转换为图像格式,为后续OCR处理提供输入。
macOS安装:
brew install poppler
Linux安装:
sudo apt-get install poppler-utils
验证安装:
import os
# mac系统
# 设置 poppler 工具路径到环境变量
os.environ["PATH"] = "/opt/homebrew/bin:" + os.environ.get("PATH", "")
# windows系统
# 将此处路径替换为你自己的poppler\bin目录路径
#poppler_path = "C:\\Poppler\\bin"
# 将poppler路径临时添加到当前会话的环境变量中,os.pathsep 是自动添加路径分隔符(在Windows上是分号;)
#os.environ["PATH"] = poppler_path + os.pathsep + os.environ.get("PATH", "")
!pdfinfo -v
(3)Pandoc:富文本格式转换 链接到标题
处理EPUB、RTF等富文本格式的转换工具,必须使用2.14.2及以上版本以确保RTF文件解析兼容性。
(4)libmagic:跨平台文件类型检测 链接到标题
Linux和macOS系统需手动安装,Windows环境可忽略此依赖。
(5)常见依赖问题解决方案 链接到标题
注意事项:本地完整安装可能触发依赖链报错(如"Could not build wheels for pikepdf”),需预先安装qpdf、libheif和pillow等图像处理依赖。
3. unstructured核心功能理解 链接到标题
功能分类与作用 链接到标题
一般来说,这些功能分为几类:
分区(Partitioning):将原始文档分解为标准的结构化元素
清理(Cleaning):从文档中删除不需要的文本,例如样板文件和句子片段
暂存(Staging):函数格式化下游任务的数据,例如ML推理和数据标记
分块(Chunking):功能将文档分割成更小的部分,以便在RAG应用程序和相似性搜索中使用
嵌入(Embedding):编码器类提供了一个接口,可以轻松地将预处理的文本转换为向量
# UnstructuredIO核心组件
from unstructured.partition.auto import partition
from typing import List
from unstructured.documents.elements import Element
# 使用partition函数自动检测文件类型并解析,默认strategy策略是auto,还会有fast策略,速度比image-to-text models的快100倍
elements: List[Element] = partition(filename="RAG评估.md", strategy="auto")
# 元素的文本内容
print(elements[0].text)
print("===========================")
# 元素的类型
print(elements[0].category)
print("==================")
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
基于元素的方法优势 链接到标题
为什么这种基于元素的方法如此重要?
- 结构为王:通过将文档分解为这些语义元素,可以保留原始文档的大部分逻辑结构。您获得的不仅仅是原始文本;你得到的是带有上下文的文本
- 精细控制:您可以迭代这些元素,按类型过滤(例如,“过滤所有Table元素”),或者根据它们的类别以不同的方式处理它们
- 丰富的元数据:每个元素都包含有用的元数据:其文本内容、它来自的页码、通常是它在页面上的坐标(边界框)、原始文件名、HTML格式的元素以及检测到的语言。这允许精确的下游处理或链接回源
元数据的应用价值 链接到标题
这些元数据让你能够:
- 精确定位:知道文本在PDF中的确切位置
- 页面管理:按页码组织和检索内容
- 多语言处理:根据语言选择合适的处理策略
- 布局理解:利用坐标信息进行版面分析
从本质上讲,unstructured不仅仅是"读取"PDF文档;它理解文档并进行解构它,这对于基于正则表达式来进行抓取的方式来说,这种解析方式无疑是一种对文档的更强大、更具语义性的理解。
4. Partition功能实践 链接到标题
partition通用参数如下:
encoding:指定输入文本/文档读取时使用的字符编码。对于非 UTF-8 文档非常有用
include_page_breaks:如果设置为 True,当文档支持 “分页” 时,输出中会包含 PageBreak 元素,以标识不同页的边界
strategy:指定解析策略,尤其对于 PDF/Image 文档,控制“快速 vs 高保真 vs OCR”方式
ocr_languages/languages:当文档含有图像文字或扫描件时,可指定 OCR 语言包,如 [“eng”,“deu”]
skip_infer_table_types:可指定跳过表格类型推断的文档类型,减少表格识别错误
fields_include:控制输出 JSON 中包含哪些字段。可用于减小输出大小或过滤敏感字段[“element_id”,“text”,“type”,“metadata”]
metadata_include / metadata_exclude:用于控制在输出元素的 metadata 字段中,保留哪些键或者排除哪些键,默认全部输出
content_type:在使用 URL 或文件流时,指定 MIME 类型提示,提高文件类型识别准确性
starting_page_number:当处理文档是某个较大文档的一部分时,可以指定起始页号,用于 metadata
from typing import List, Dict, Any, Optional, Sequence
from pathlib import Path
# 自定义解析函数,支持任意类型的文件格式
def parse_file_with_unstructured(file_path: str):
"""
使用UnstructuredIO解析单个文件
Args:
file_path: 文件路径
Returns:
Dict: 包含解析结果和统计信息的字典
"""
print(f"\n 解析文件: {file_path}")
try:
# 使用partition函数自动检测文件类型并解析,默认strategy策略是auto,还会有fast策略,速度比image-to-text models的快100倍
elements: List[Element] = partition(filename=file_path, strategy="auto")
# 分析解析结果
analysis = {
"file_path": file_path,
"file_extension": Path(file_path).suffix.lower(),
"total_elements": len(elements),
"element_types": {},
"elements": elements,
"text_content": "",
"statistics": {}
}
# 统计元素类型
for element in elements:
element_type = type(element).__name__
analysis["element_types"][element_type] = analysis["element_types"].get(element_type, 0) + 1
# 提取文本内容
text_parts = []
for element in elements:
if hasattr(element, 'text') and element.text:
text_parts.append(element.text)
analysis["text_content"] = "\n\n".join(text_parts)
# 计算统计信息
analysis["statistics"]["total_characters"] = len(analysis["text_content"])
print(f" 解析完成")
print(f" 元素总数: {analysis['total_elements']}")
print(f" 元素类型: {analysis['element_types']}")
print(f" 总字符数: {analysis['statistics']['total_characters']}")
print(f" 文本内容: {analysis['text_content'][:200]} ")
except Exception as e:
print(f"文件解析失败: {e}")
return {}
(1)Markdown文档解析 链接到标题
parse_file_with_unstructured("RAG评估.md")
from unstructured.partition.md import partition_md
from typing import List
from unstructured.documents.elements import Element
# 使用partition_md函数检测markdown文件类型解析,include_page_breaks若希望在 Markdown 中标识页面断点(少见场景)
elements: List[Element] = partition_md(filename="RAG评估.md", languages=["zho"],include_page_breaks=True)
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text)
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
(2)HTML文档解析 链接到标题
parse_file_with_unstructured("html-tags-decode.html")
支持 URL 输入、headers、ssl 验证选项
除通用参数外:
url:直接给出网页 URL,无需先下载。
headers:HTTP 请求头(User-Agent 等)。
ssl_verify:是否验证 SSL 证书(False 可用于测试环境)。
file/filename/text:支持本地文件、文件流或网页文本输入。
content_type:可指定 text/html。
from unstructured.partition.html import partition_html
from typing import List
from unstructured.documents.elements import Element
# 使用partition_html函数检测html网页类型解析
elements = partition_html(url="https://docs.unstructured.io/welcome",
headers={"User-Agent":"MyBot"},
ssl_verify=False,
include_page_breaks=False,
encoding="utf-8")
#elements: List[Element] = partition_html(url="https://docs.unstructured.io/welcome", languages=["zho"])
# 元素的元数据
print(elements[1].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[1].text)
print("===========================")
# 元素的类型
print(elements[1].category)
print("===========================")
(3)EXCEL文档解析 链接到标题
parse_file_with_unstructured("销售数据统计.xlsx")
表格处理,支持多个 Sheet。
可调参数仍为通用那些(如 encoding、include_page_breaks)。
from unstructured.partition.xlsx import partition_xlsx
from typing import List
from unstructured.documents.elements import Element
# 使用partition_xlsx函数检测excel文件类型并解析
elements: List[Element] = partition_xlsx(filename="销售数据统计.xlsx", languages=["zho"])
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text)
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
(4)CSV文档解析 链接到标题
parse_file_with_unstructured("训练数据.csv")
相对简单,主要表格抽取。
可调参数少,通常只使用通用参数如 encoding、include_page_breaks。
输出为一个 Table 元素,其 metadata.text_as_html 包含 HTML 表格。
from unstructured.partition.csv import partition_csv
from typing import List
from unstructured.documents.elements import Element
# 使用partition_csv函数检测csv文件类型并解析
elements = partition_csv(filename="训练数据.csv", encoding="utf-8")
# 元素的元数据
#print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text[:400])
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
(5)Word文档解析 链接到标题
parse_file_with_unstructured("数组.docx")
支持 .docx(样式信息)和 .doc(需 LibreOffice 转换)。
参数:同通用参数。
from unstructured.partition.docx import partition_docx
from unstructured.partition.doc import partition_doc
from typing import List
from unstructured.documents.elements import Element
# 使用partition_docx函数检测word文件类型并解析,include_page_breaks当文档支持 “分页” 时,以标识不同页的边界
elements = partition_docx(filename="数组.docx", encoding="utf-8", include_page_breaks=True)
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text[:400])
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
(6)Image图片解析 链接到标题
模型下载说明
在对Image图片进行解析时,默认下载的Yolox模型来进行识别。默认是从huggingface上下载模型,所以需要科学上网。
安装完poppler-utils、tesseract-ocr后,成功下载yolox模型即可正常使用。
parse_file_with_unstructured("PDF解析截图.png")
类似于 PDF 的策略调用,但直接针对单张或多张图片。
特定参数:
strategy:可选 “auto”, “hi_res”, “ocr_only”。
languages / ocr_languages:OCR 多语言支持。
include_page_breaks:如图片列表可视为 “页”。
from unstructured.partition.image import partition_image
from typing import List
from unstructured.documents.elements import Element
# 使用partition_image函数检测png类型并解析,strategy="ocr_only"使用ocr来进行图片内容文字识别
elements = partition_image(filename="PDF解析截图.png",
strategy="ocr_only",
languages=["eng","chi_sim"],
include_page_breaks=False)
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text[:400])
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
elements = partition_image(filename="数学公式.png",
strategy="ocr_only",
languages=["eng","chi_sim"],
include_page_breaks=False)
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text[:400])
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
需要注意:
- OCR的识别效果很大程度上取决于原始图像的质量。如果识别结果不理想,可以尝试对图像进行预处理,例如二值化、降噪、倾斜校正等
(7)PDF文件解析 链接到标题
parse_file_with_unstructured("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf")
关键额外参数:
strategy:PDF解析策略的选择直接影响提取效果,可选 “auto”(默认)、“hi_res”、“fast”、“ocr_only”。控制解析方式。
auto(默认):适用于无图像嵌入文本的标准PDF,解析速度快
hi_res:使用布局检测模型(例如 会调用布局检测模型 Detectron2/YOLOX/自研Chipper等)提取结构信息。
fast:快速解析,以可提取文本为主。
ocr_only:针对扫描件/图像版 PDF,只做 OCR 提取。
vlm:VLM模型,如OpenAI/Anthropic等提供的视觉语言模型
extract_images_in_pdf(布尔):当 strategy 为 hi_res 时,可控制是否提取嵌入图像块。
extract_image_block_types(列表):指定提取哪些类型(如 [“Image”,“Table”])的图像块。
extract_image_block_to_payload(布尔):是否把提取块转换为 payload(例如 base64)输出。
extract_image_block_output_dir(字符串):如果不转换为 payload,可将提取图像块保存到指定目录。
max_partition:当使用 ocr_only 策略时,限制单个元素(文本块)最大字符长度。默认为 1500。
languages 或 ocr_languages:对 OCR 使用的语言包列表。
skip_infer_table_types:可以跳过表格类型推断以提高速度。
split_pdf_page:True,大文件分块处理,可实现大文件分块处理,提升解析效率
infer_table_structure:True,表格结构推断,是否尝试推断表格结构
表格提取功能已集成至unstructured库核心模块,无需再向unstructured-inference传递extract_tables参数。通过elements对象的category属性可精准筛选表格元素。
from unstructured.partition.pdf import partition_pdf
from typing import List
from unstructured.documents.elements import Element
# 使用partition_pdf函数检测pdf类型并解析
elements = partition_pdf(filename="甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf",
strategy="hi_res", # 使用hi_res模式进行高精度解析
extract_images_in_pdf=True, # 提取pdf中的图片
extract_image_block_types=["Table","Image"], # 提取表格和图片
extract_image_block_output_dir="./images", # 保存图片到images目录
languages=["eng","zho"],
split_pdf_page=True, # 大文件分块处理,优化性能
infer_table_structure=True, # 是否尝试推断表格结构,会下载一个ocr模型
include_page_breaks=True) # 是否包含页码信息
# 元素的元数据
print(elements[0].metadata.__dict__)
print("===========================")
# 元素的文本内容
print(elements[0].text[:400])
print("===========================")
# 元素的类型
print(elements[0].category)
print("===========================")
在加上infer_table_structure=True(是否尝试推断表格结构)参数以后会直接下载一个ocr模型
(8)Element对象核心字段 链接到标题
返回的Element对象包含以下核心字段:
- text:元素的文本内容(表格会以Markdown表格格式呈现)
- category:元素类型,如Title、NarrativeText、ListItem、Table等
- metadata:元素的元数据
(9)category元素类型详解 链接到标题
- Title(标题):文档的标题和副标题
- NarrativeText(叙事文本):纯文本的段落
- Table(表格):表格数据
- Text(段落):文本段落
- Image(图像):所有图片
- Formula(数学公式):文本 y = Wx + b
- Header/Footer(页眉/页脚):可以将它们与主要内容区分开来
(10)metadata元数据详解 链接到标题
- 页码(page_number):该文本块所在的页码(从1开始)
- 坐标信息(coordinates):
- points:文本块在页面上的边界框坐标(4个角的坐标点)
- 格式:
[左上, 左下, 右下, 右上] - 单位:像素点
- 格式:
- system:坐标系统类型(PixelSpace = 像素坐标系)
- layout_width/height:页面的总宽度和高度(像素)
- 语言(languages):检测到的文档语言(如
["zho"]= 中文,ISO 639-3语言代码) - 文件基本信息:
- filename:原始文件名
- last_modified:文件最后修改时间(ISO 8601格式)
- filetype:文件MIME类型(如
application/pdf)
(11)下游RAG应用优化 链接到标题
在检索增强生成(RAG)系统中:
- 通过category过滤非文本元素(如图像)
- 或优先使用标题元素构建文档层次结构,提升检索准确性
(12)额外配置:指定OCR Agent 链接到标题
如果你想切换OCR引擎(例如用Paddle OCR做中文识别更好),可以在环境中设置OCR_AGENT:
- 官方文档:https://docs.unstructured.io/open-source/how-to/set-ocr-agent?utm_source=chatgpt.com
使用Tesseract(默认)
- export OCR_AGENT=“unstructured.partition.utils.ocr_models.tesseract_ocr.OCRAgentTesseract”
或使用Paddle OCR(若已安装)
- export OCR_AGENT=“unstructured.partition.utils.ocr_models.paddle_ocr.OCRAgentPaddle”
并确保你安装了对应依赖(Tesseract二进制+语言包,或Paddle、Google SDK)。这能显著影响中文识别质量。
6. 常见问题与解决方案 链接到标题
partition_pdf导入错误处理
- 问题:
partition_pdf导入时报错或找不到模块(版本差异) - 解决:检查
unstructured版本与文档示例是否匹配;有时接口结构在minor/patch版本中变更(例如partition_pdf的import路径)。必要时查看GitHub issues
hi_res本地安装复杂问题
- 问题:
hi_res本地安装复杂(detectron2在Windows安装困难) - 解决:使用
unstructured-api的远程推理端点或者在Linux/GPU容器中部署unstructured-inference
表格转换结果错位修正
- 问题:表格转换结果错位/合并不正确
- 解决:尝试在
hi_res下调整表格推断参数,或在解析后用pandas的post-processing(合并列/填充空值)修正;对复杂表格考虑手工清洗或专用表格抽取工具(Camelot、Tabula)做对比
中文识别问题
- 问题:识别不到中文/乱码
- 解决:确认Tesseract已安装相应语言包(
tesseract --list-langs);使用languages=["chi_sim","eng"]并重启进程
混合中英文本方向/版式混乱
- 解决:优先使用
strategy="hi_res"做布局检测,再对图片区域分别OCR;对低质量扫描先做图像预处理(deskew、denoise、binarize)
性能优化策略(经验型):
- 在处理大量电子PDF(有文本层)时:
fast+ PyMuPDF/pdftotext管线通常最快且足够准确 - 在需要高质量表格边界或复杂布局时:
hi_res能显著提高表格/标题/图片检测但开销大(时间/依赖)。若对吞吐量有严格要求,考虑把hi_res推理外包到推理服务并对任务做批量调度(异步/队列)
第四阶段:LlamaIndex框架介绍 链接到标题
1. 大模型开发框架(SDK)是什么? 链接到标题
SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。 所有开发框架(SDK)的核心价值,都是降低开发、维护成本。 大语言模型开发框架的价值,是让开发者可以更方便地开发基于大语言模型的应用。
主要提供两类帮助:
第三方能力抽象。比如LLM、向量数据库、搜索接口等
常用工具、方案封装
底层实现封装。比如流式接口、超时重连、异步与并行等
好的开发框架,需要具备以下特点:
可靠性、鲁棒性高
可维护性高
可扩展性高
学习成本低
举些通俗的例子:
- 与外部功能解依赖
- 比如可以随意更换LLM而不用大量重构代码
- 更换三方工具也同理
- 经常变的部分要在外部维护而不是放在代码里
- 比如Prompt模板
- 各种环境下都适用
- 比如线程安全
- 方便调试和测试
- 至少要能感觉到用了比不用方便吧
- 合法的输入不会引发框架内部的报错
选对了框架,事半功倍;反之,事倍功半。
参考资源:
- 什么是SDK? https://aws.amazon.com/cn/what-is/sdk/
- SDK和API的区别是什么? https://aws.amazon.com/cn/compare/the-difference-between-sdk-and-api/
2. LlamaIndex介绍 链接到标题
LlamaIndex 是一个为开发「上下文增强」的大语言模型应用的框架(也就是 SDK)。上下文增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如:
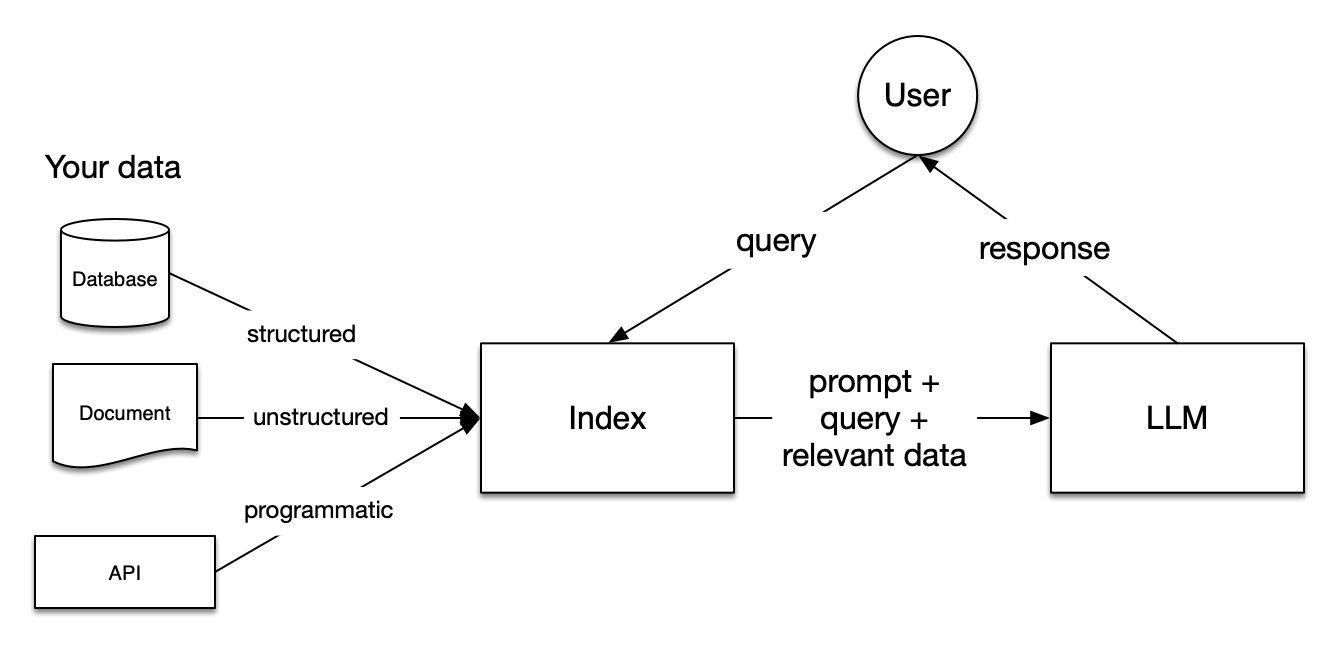
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
Python 文档地址:https://docs.llamaindex.ai/en/stable/
Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/
TS 文档地址:https://ts.llamaindex.ai/
TS API 接口文档:https://ts.llamaindex.ai/api/
LlamaIndex 是一个开源框架,Github 链接:https://github.com/run-llama
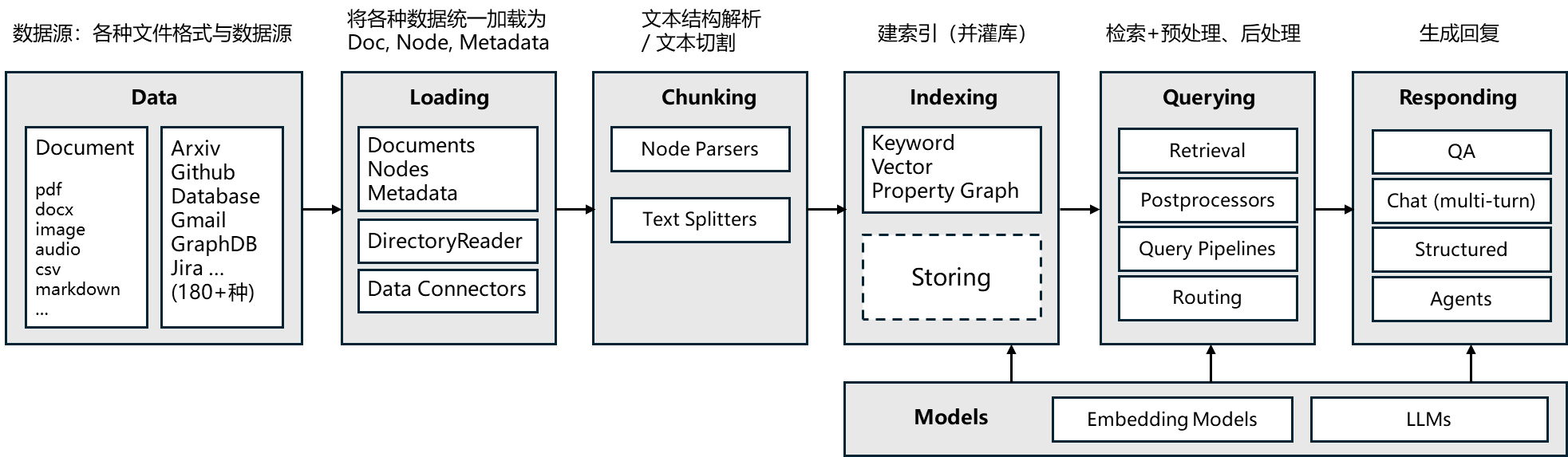
3.LlamaIndex 的核心模块 链接到标题
4. 框架对比:LangChain vs LlamaIndex 链接到标题
对比维度 LangChain LlamaIndex(原 GPT Index)
定位与设计
通用型 LLM 应用框架(可构建 Agent、Tool、RAG 等各种系统)
专注文档理解与 RAG 的索引、检索、问答框架
核心理念
“链式调用(Chains)” 和 “工具组合(Tools)”,强调可编排性
“数据接口(Data Index + Query Engine)”,强调数据到知识的映射
文档加载能力
`DocumentLoader` 支持多格式文档(PDF、HTML、TXT)
深度集成解析器(如 LlamaParse、Unstructured、PandasReader)
数据解析深度
主要提取纯文本,结构化需手动实现
提供高层结构抽象(Document → Node → Index),保留层级关系
索引结构
VectorStore(Chroma、FAISS、Milvus等)为核心,开发者需手动管理
提供多种索引:`VectorStoreIndex`, `SummaryIndex`, `KnowledgeGraphIndex`
上下文压缩 / rerank
需额外配置 Reranker 或 ContextCompressor
原生支持 Context Compression / Node PostProcessor
多文档检索
可通过 `MultiQueryRetriever`、`ParentDocumentRetriever` 实现
内置 `ComposableGraph` 实现多索引融合检索
Agent 能力
强(LangChain 是 Agent 生态核心框架)
弱(更偏向数据检索与知识问答)
生态与扩展性
最大的 LLM 生态,插件、工具链最丰富
与数据密集型 RAG 项目结合最紧(适合文档知识库类应用)
适用场景
多步骤推理、Agent系统、工具调用、企业助手
文档问答、知识检索、企业知识库、研究型报告分析
示例语法简洁度
代码偏工程风格,组件组装较多
封装层高,一行代码即可构建 query engine
性能优化方向
优化在链路编排与检索召回效率
优化在文档解析、chunk 切分与上下文压缩
代表项目
Chatbot、智能助理、Agent系统、数据问答
企业知识库问答、PDF报告分析、学术RAG系统
LangChain 是“逻辑大脑”:强在工作流编排、Agent化、工具集成。
LlamaIndex 是“知识记忆”:强在文档结构化、RAG索引、检索优化。
- 两者并不是竞争关系,而是 RAG 系统的天然组合
第五阶段:LlamaIndex集成与进阶 链接到标题
1. LlamaIndex环境准备 链接到标题
核心库安装
LlamaIndex版本0.14.x
pip install llama-index-core llama-index
解析库安装
pip install llama-parse unstructured nest-asyncio python-multipart llama-index-readers-file
pip install pytest
pip install "unstructured[md]"
2. LlamaIndex常用组件 链接到标题
常用组件:
SimpleDirectoryReaderLlamaParse(针对复杂 PDF)UnstructuredReader(多格式文档)PandasReader(表格类文件)- 官方文档申请api_key:https://llamaindex.org.cn/blog/pdf-parsing-llamaparse
示例:
from llama_index.core import SimpleDirectoryReader
from llama_parse import LlamaParse
# 如果文档结构复杂,优先使用 LlamaParse
# parser = LlamaParse(api_key="YOUR_LLAMA_CLOUD_API_KEY")
# documents = parser.load_data("sample.pdf")
# 或者使用简单读取器
documents = SimpleDirectoryReader(input_files=["RAG评估.md"]).load_data()
print(documents[0].metadata)
print("===========================")
print(documents[0].text)
print("===========================")
3. LlamaIndex集成unstructured 链接到标题
LlamaIndex与Unstructured的关系 链接到标题
LlamaIndex本身并不专注于文件解析(Parsing),而专注于:
“结构化地管理与大模型交互的外部知识(即索引、检索、问答)。”
而Unstructured.io是一个独立的"文档解析引擎”,核心职责是:
“将各种复杂格式(PDF、DOCX、HTML、Excel、图片等)解析成统一的文本元素(elements)。”
因此:
LlamaIndex是知识管理层(Knowledge Layer)
Unstructured是文档提取层(Extraction Layer)
两种集成方式对比 链接到标题
对比点
使用unstructured.partition直接解析
使用LlamaIndex UnstructuredReader
**底层调用**
直接调用`unstructured`官方API(`partition()`)
内部封装了`partition()`,简化调用
**灵活度**
可访问所有底层参数(如`strategy`、`hi_res_model`、`ocr_languages`)
封装后部分参数隐藏,仅暴露常用接口
**可控性**
可自定义处理流程(过滤、正则、chunk策略)
自动化程度高,但定制难度大
**集成便捷性**
需手动将结果转为`Document`
自动输出为`Document`列表
**依赖管理**
由开发者决定何时安装哪些后端(pdfminer, tesseract)
自动导入必要模块,错误提示更友好
**适用场景**
高级研发/多源异构文档处理
快速原型/小规模项目
方式一:直接使用UnstructuredReader 链接到标题
推荐场景:快速测试/教学/单格式文件读取
优点:
- 写法极简
- 自动生成Document对象
- 无需显式调用
partition
缺点:
- 无法细调OCR、chunk_size、文本清洗
- 对图片、HTML、公式等复杂结构支持有限
- Document对象只保留了文本和元数据,没有数据类型
from llama_index.readers.file.unstructured import UnstructuredReader
from pathlib import Path
reader = UnstructuredReader()
documents = reader.load_data(file=Path("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf"))
print("打印列表长度:" + str(len(documents)))
print("==================================")
print("打印解析的文本内容:" + documents[0].text[:100])
print("==================================")
print("打印元数据信息:" + str(documents[0].metadata))
方式二:独立使用unstructured.partition + 自定义逻辑 链接到标题
推荐场景:生产级RAG应用/多格式数据管线/高可控性需求
优点:
- 可自由控制解析策略(OCR、chunk、去噪、正则)
- 可在加载前后插入清洗逻辑(例如表格转结构化文本)
- 易于扩展(批量处理/并行任务/自定义metadata)
from unstructured.partition.auto import partition
# 使用LlamaIndex的Document对象,将解析后的元素转换为Document对象
from llama_index.core import Document
# 使用partition函数自动检测文件类型并解析
elements = partition(
filename="甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf",
strategy="hi_res",
split_pdf_page=True,
infer_table_structure=True,
languages=["eng","chi_sim"])
# 将解析后的元素转换为Document对象
docs = [
Document(text=e.text,
metadata={"source":"甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf",
"type": e.category})
for e in elements]
docs
方式三:最佳混合方案(推荐实践) 链接到标题
结合两者优势:
from llama_index.readers.file.unstructured import UnstructuredReader
from unstructured.partition.auto import partition
from llama_index.core import Document
from pathlib import Path
def smart_load(file_path):
"""
智能文档加载器:根据文件类型选择最佳解析策略
Args:
file_path: 文件路径
Returns:
解析后的Document对象列表
"""
file_path = Path(file_path)
file_ext = file_path.suffix.lower()
# 定义复杂文件类型(需要高精度解析)
complex_types = {
'.pdf', # PDF文档(可能包含表格、图像、复杂布局)
'.png', '.jpg', '.jpeg', '.gif', '.bmp', '.tiff', # 图片文件(需要OCR)
'.docx', '.doc', # Word文档(可能包含复杂格式)
'.pptx', '.ppt', # PowerPoint(复杂布局)
'.xlsx', '.xls' # Excel(表格结构)
}
# 简单文件类型(可以用Reader直接处理)
simple_types = {
'.txt', '.md', '.csv', '.html', '.xml', '.json'
}
if file_ext in complex_types:
# 复杂文件使用底层解析,获得更好的结构识别
print(f"检测到复杂文件类型 {file_ext},使用partition高精度解析")
try:
elements = partition(
filename=str(file_path),
# 使用hi_res模式进行高精度解析
strategy="hi_res",
# 支持中文、英文
languages=["eng", "chi_sim"],
# 推断表格结构
infer_table_structure=True
)
# 将解析元素转换为Document对象
return [Document(text=e.text, metadata={
"source": str(file_path),
"element_type": type(e).__name__,
"file_type": file_ext
}) for e in elements if e.text.strip()] # 过滤空文本
except Exception as e:
print(f"高精度解析失败,回退到Reader: {e}")
# 回退到Reader
reader = UnstructuredReader()
return reader.load_data(file=file_path)
else:
# 简单文件或未知类型优先使用Reader
print(f"检测到简单文件类型 {file_ext},使用Reader解析")
try:
# 直接使用Reader进行简单解析
reader = UnstructuredReader()
# 加载解析后的文档,返回 Document 对象列表
docs = reader.load_data(file=file_path)
return docs
except Exception as e:
print(f"Reader解析失败,回退到partition: {e}")
# 回退到底层解析
elements = partition(filename=str(file_path), strategy="auto")
return [Document(text=e.text, metadata={"source": str(file_path)}) for e in elements]
documents = smart_load("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf")
documents
这种做法在实际RAG框架开发中非常常见:
- 90%文件走LlamaIndex内置Reader
- 特殊格式(扫描件、混合HTML、表格)回退到底层
unstructured
总结一句话
LlamaIndex的
UnstructuredReader** = 快速封装,适合上层应用**unstructured.partition** = 底层引擎,适合复杂数据管线**在原型阶段用
UnstructuredReader,在生产阶段直接集成unstructured。
场景 推荐方式 理由
初学者/快速Demo
`UnstructuredReader()`
封装好,一行搞定
RAG系统
`UnstructuredReader()`
输出直接是Document
生产系统/多文件管线
`partition()`
可完全控制OCR/分块/过滤
精细元数据追踪(页码/坐标/字体)
`partition()`
元数据更丰富
4. 基础索引案例实现 链接到标题
基础文档解析实现 链接到标题
PDF文档需要先转换成Markdown带有标签的格式,有了文本和图片等标签以后,再进行对应部分的操作,会更加的方便。
解析得到的
documents可以直接用于构建LlamaIndex的向量索引,这是RAG系统的核心。
#!pip install llama-index-embeddings-openai llama-index-llms-openai
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI # 导入OpenAI LLM类
from llama_index.core.settings import Settings
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 设置为全局默认Embedding模型
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
api_key=os.getenv("OPENAI_API_KEY"),
api_base=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
)
# 设置为全局默认 LLM
Settings.llm = OpenAI(
model="gpt-3.5-turbo",
api_key=os.getenv("OPENAI_API_KEY"),
api_base=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
)
# 解析pdf文档
documents = smart_load("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf")
# 构建索引
index = VectorStoreIndex.from_documents(documents)
# 生成查询引擎
query_engine = index.as_query_engine()
# 测试提问
response = query_engine.query("请用中文总结这些文档的主要内容")
print(response)
第六阶段:特定领域应用 链接到标题
金融领域:财报解析与问答 链接到标题
- 重点:表格提取精度
- 推荐工具:DoclingAI(表格提取精度98%+)
- 策略:使用
hi_res策略进行高精度表格解析
医疗领域:文献分析与检索 链接到标题
- 重点:公式识别与专业术语处理
- 推荐工具:MinerU(数学公式识别精准)
- 策略:结合OCR与专业词典
法律领域:合同解析与条款提取 链接到标题
- 重点:文档结构还原与条款定位
- 策略:利用标题元素构建文档层次结构
- 元数据:页码、坐标信息用于精确定位
教育领域:教材内容分析与问答 链接到标题
- 重点:多模态内容处理(文字、图片、公式)
- 推荐工具:Marker(代码/公式支持优秀)
- 策略:使用
vlm策略处理复杂版面
学习资源与参考 链接到标题
官方资源 链接到标题
unstructured官网:https://unstructured.io/
unstructured GitHub:https://github.com/Unstructured-IO/unstructured
LlamaIndex官方文档:https://docs.llamaindex.org.cn/en/stable/
Tesseract OCR官方文档:https://tesseract-ocr.github.io/
pdf2image文档:https://pdf2image.readthedocs.io/
LlamaIndex 的更多功能 链接到标题
智能体(Agent)开发框架:https://docs.llamaindex.ai/en/stable/module_guides/deploying/agents/
RAG 的评测:https://docs.llamaindex.ai/en/stable/module_guides/evaluating/
过程监控:https://docs.llamaindex.ai/en/stable/module_guides/observability/
此外,LlamaIndex 针对生产级的 RAG 系统中遇到的各个方面的细节问题,总结了很多高端技巧(Advanced Topics),对实战很有参考价值,非常推荐有能力的同学阅读。
技术文档