🎯 课程简介
本课程整合了平台使用、模型原理、云端部署、量化技术及推理框架等核心内容,旨在帮助开发者从零开始掌握大模型本地与云端部署的全流程技能。
🎯 学员画像与前置知识
本课程面向具备 Python 基础知识,希望学习大模型部署的软件开发者。
前置要求:
- 熟悉基本的 Linux 命令行操作
- 了解 Python 基础语法与环境管理 (Conda)
- 对深度学习概念有初步了解 (可选)
📅 时效性说明:本课程内容基于
transformers>=4.48.0版本,测试环境为 PyTorch 2.8.0 + Python 3.12 + CUDA 12.8(使用 RTX 4090D 24GB 显卡),测试时间为 2026年2月。若使用其他版本,部分命令或界面可能略有差异。
第一章:大模型全球生态——托管平台与代码仓库 链接到标题
1. 模型托管平台概述——大模型的"应用商店" 链接到标题
在正式介绍具体平台之前,我们先来理解一个核心概念:什么是"模型托管平台"?它为什么对我们这些初学者如此重要? 这一章会从最实际的问题出发,帮你建立对这类平台的整体认知。
1.1 新手最常遇到的困惑 链接到标题
想象这样一个场景:你看了很多关于 ChatGPT 的新闻,也体验过在线版本,现在想自己动手做一个类似的应用。你在网上搜索"如何使用大模型",结果看到一堆术语:BERT、GPT、Llama、下载权重、加载模型……完全不知道从何下手。
这时候你最想知道的其实就三件事:
问题一:模型到底从哪里下载?
在 2020 年之前,如果你想用一个预训练模型(比如当时很火的 BERT),你需要:
先找到发布论文的作者个人主页
在页面角落里找到一个 Google Drive 或者百度网盘的链接
下载一个几百 MB 的压缩包
解压后得到一堆文件,但不知道哪个是模型文件
还要自己去 GitHub 找示例代码,研究怎么加载
这种碎片化的方式,对新手极其不友好。你可能花了一整天,连模型都没跑起来。

问题二:下载后怎么用?
即使你幸运地找到了模型文件,下一个问题来了:怎么把它加载到代码里? 不同的模型有不同的格式,不同的框架(PyTorch、TensorFlow)有不同的加载方式。作为新手,你根本不知道该用哪个库、调用哪个函数。
问题三:这模型靠谱吗?
网上随便找的模型,你怎么知道它是不是真的有效?有没有被训练好?有没有包含恶意代码?这些都是新手容易担心但又无从判断的问题。
模型托管平台的出现,就是为了一站式解决这些问题。
1.2 模型托管平台是什么? 链接到标题
模型托管平台(Model Hub) 可以理解为大模型的"应用商店"。就像你在手机应用商店里搜索、下载 App 一样,你可以在这些平台上搜索、下载各种大模型。
类比理解:
应用商店:苹果 App Store、安卓应用市场 → 下载手机应用
模型仓库:HuggingFace、ModelScope → 下载开源模型
代码仓库:GitHub → 下载开源代码
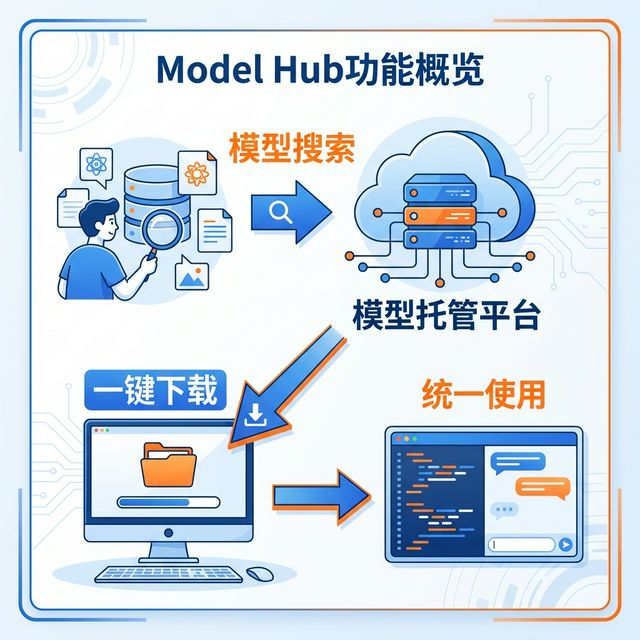
一个合格的模型托管平台,需要提供这些核心功能:
功能一:模型搜索与展示
平台会为每个模型创建一个"主页",像商品详情页一样,展示:
模型名称和简介(比如"Llama-3-8B - Meta 发布的开源大语言模型")
模型能做什么(文本生成、对话、翻译等)
模型有多大(参数量、文件大小)
谁创建的、什么时候更新的
功能二:一键下载
你不需要到处找下载链接,平台提供标准化的下载方式:
网页上直接点击下载
通过命令行工具下载
在代码里一行命令自动下载
功能三:统一的使用方式
这是最重要的功能。平台提供了标准化的 API,让你可以用完全相同的方式加载任何模型:
# 无论是 BERT、GPT 还是 Llama,使用方式都一样
from transformers import AutoModel
model = AutoModel.from_pretrained("模型名称")
这就像你用"双击"打开任何 Windows 软件一样,不需要为每个软件学习不同的启动方式。
功能四:社区与文档
每个模型都有配套的文档、示例代码,甚至有用户评论和讨论区。遇到问题可以直接在平台上找解决方案。
模型获取方式对比:传统 vs 平台
| 对比项 | 传统方式(2020年前) | 使用模型托管平台 |
|---|---|---|
| 找模型 | 搜索论文→找作者主页→找下载链接 | 平台搜索框输入关键词,立刻找到 |
| 下载 | 个人网盘,速度慢,链接常失效 | 全球 CDN 加速,稳定可靠 |
| 了解信息 | 阅读论文,可能还是英文的 | 模型卡片,中文说明,一目了然 |
| 加载代码 | 自己研究怎么写 | 一行代码搞定 from_pretrained() |
| 遇到问题 | 发邮件问作者,可能没人回复 | 社区讨论区,热门模型有大量解答 |
从上表可以看到,模型托管平台让"使用预训练模型"从一件需要专业技能的事,变成了任何新手都能轻松上手的操作。
1.3 两大主流平台:HuggingFace 和 ModelScope 链接到标题
在全球范围内,有两个模型托管平台最受欢迎:HuggingFace 和 ModelScope。
HuggingFace:全球最大的模型仓库
HuggingFace(抱脸)是目前全球最流行的模型托管平台,托管了超过 210 万个模型。它的核心特点是:
模型最全:几乎所有知名的开源大模型(Llama、GPT-2、BERT等)都能在这里找到
国际标准:全球的 AI 研究者和开发者都在用,是事实上的行业标准
英文为主:界面和文档以英文为主(也有部分中文)
适合场景:你需要找特定的国际知名模型,或者想要最新最全的模型资源。
ModelScope:中文友好的国内平台
ModelScope(魔搭社区)是阿里云推出的模型托管平台,专注于中文生态:
中文优势:大量针对中文优化的模型(如通义千问 Qwen 系列、ChatGLM 等)
国内访问快:服务器在国内,下载速度比 HuggingFace 快很多
免费算力:提供免费的 GPU 环境,可以在线运行模型
中文文档:对国内新手更友好
适合场景:你是国内用户,需要中文模型,或者网络访问 HuggingFace 不稳定。
在这一章中,我们理解了"模型托管平台"的本质——它就像是大模型的应用商店,让我们可以方便地搜索、下载和使用各种开源模型。我们也知道了两个主流平台:HuggingFace(全球最大)和 ModelScope(中文友好)。但光知道平台的存在还不够,真正重要的是:我怎么在这些平台上找到我需要的模型?下载后怎么用? 下一章,我们将手把手教你这些实用操作。
过渡:了解了专门存放模型的 HuggingFace 和 ModelScope 之后,我们要介绍另一个在大模型开发中不可或缺的平台——GitHub。虽然它不是用来存大模型的,但它存放了使用这些模型的代码。
1.4 实战指南——账号注册与模型下载 链接到标题
现在你已经知道了模型托管平台的作用,接下来最关键的就是:怎么实际使用这些平台? 这一章会带你一步步学会在 HuggingFace 和 ModelScope 上找模型、看懂模型信息、把模型下载到本地。我们会用非常实用的角度来讲解,而不是枯燥地列举功能。
1.4.1 两个平台的核心定位差异(快速了解) 链接到标题
在开始具体操作前,先花一分钟了解这两个平台的核心差异,这样你就知道什么时候该用哪个。
HuggingFace vs ModelScope 核心差异
| 对比维度 | HuggingFace | ModelScope |
|---|---|---|
| 服务器位置 | 国外(可能需要科学上网) | 国内(访问速度快) |
| 主要语言 | 英文为主 | 中文友好 |
| 模型数量 | 210万+,全球最全 | 规模较小,但中文模型丰富 |
| 适合人群 | 需要国际模型、英文能力好 | 国内用户、需要中文模型 |
| 免费算力 | Spaces 提供免费 CPU/GPU,热门时段需排队 | 提供免费 GPU 体验环境,资源相对充足 |
| 下载速度 | 国内可能较慢 | 国内用户很快 |
新手建议:
如果你在国内,且主要做中文相关的应用(如中文对话机器人),优先用 ModelScope
如果你需要某个特定的国际知名模型(如 Llama、Mistral),就去 HuggingFace 找
两个平台可以同时使用,不冲突
1.4.2 HuggingFace 实用操作指南 链接到标题
📅 时效性说明:本节内容基于
transformers>=4.50.0、huggingface_hub>=0.25.0版本,测试环境为 PyTorch 2.8.0 + Python 3.12 + CUDA 12.8(RTX 4090),测试时间为 2026年2月。若使用其他版本,部分命令或界面可能略有差异。
在开始使用 HuggingFace 之前,我们需要先完成账号注册和配置。这不仅能让你访问更多模型,还能享受更高的下载速度和稳定性。接下来我们将按照"注册账号 → 获取Token → 本地登录 → 搜索下载"的顺序,手把手教你完成全部配置。
1.4.2.1 账号注册全流程 链接到标题
虽然HuggingFace的很多模型可以不登录就下载,但强烈建议你先注册账号。原因有三:第一,一些热门模型(如Llama 3)必须登录才能下载;第二,登录后下载速度更快、更稳定;第三,避免触发匿名用户的速率限制。
步骤一:访问 HuggingFace 官网
打开浏览器,访问 https://huggingface.co/join(注册页面)。你会看到如下界面:
HuggingFace 首页注册入口
步骤二:填写注册信息
点击"Sign Up"后,你需要填写以下信息:
注册页面
具体填写内容:
填写注册信息
Email:建议使用常用邮箱(Gmail、Outlook等),避免使用企业邮箱(可能拦截验证邮件)
Password:设置高强度密码,建议包含大小写字母、数字和符号
Username:**特别注意:用户名一旦设置不可更改!**将作为你发布模型的URL前缀
Full Name:你的真实姓名或昵称
填写完成后点击"Sign Up",注册就完成了!此时你已经可以登录并浏览模型,但如果要下载门控模型或使用 CLI(Command Line Interface,命令行界面)工具,还需要继续下面的步骤。
1.4.2.2 获取 Access Token 链接到标题
Access Token(访问令牌)是HuggingFace的"密钥",让你可以在命令行或代码中自动下载模型,而不需要每次都手动登录网页。对于门控模型(如Llama 3、Gemma等),必须使用Token才能下载。
步骤一:进入 Token 设置页面
登录后,点击右上角头像,选择 Settings(设置),然后在左侧菜单选择 Access Tokens:
Access Tokens 设置入口
步骤二:完成邮箱验证(首次申请时)
如果这是你第一次创建Token,系统会要求你先验证邮箱:
需要邮箱验证提示
打开你的邮箱,点击验证链接,完成验证后会看到:
邮箱验证完成
步骤三:选择 Token 类型
返回设置页面,点击 New token(创建新令牌),你需要选择Token的权限类型:
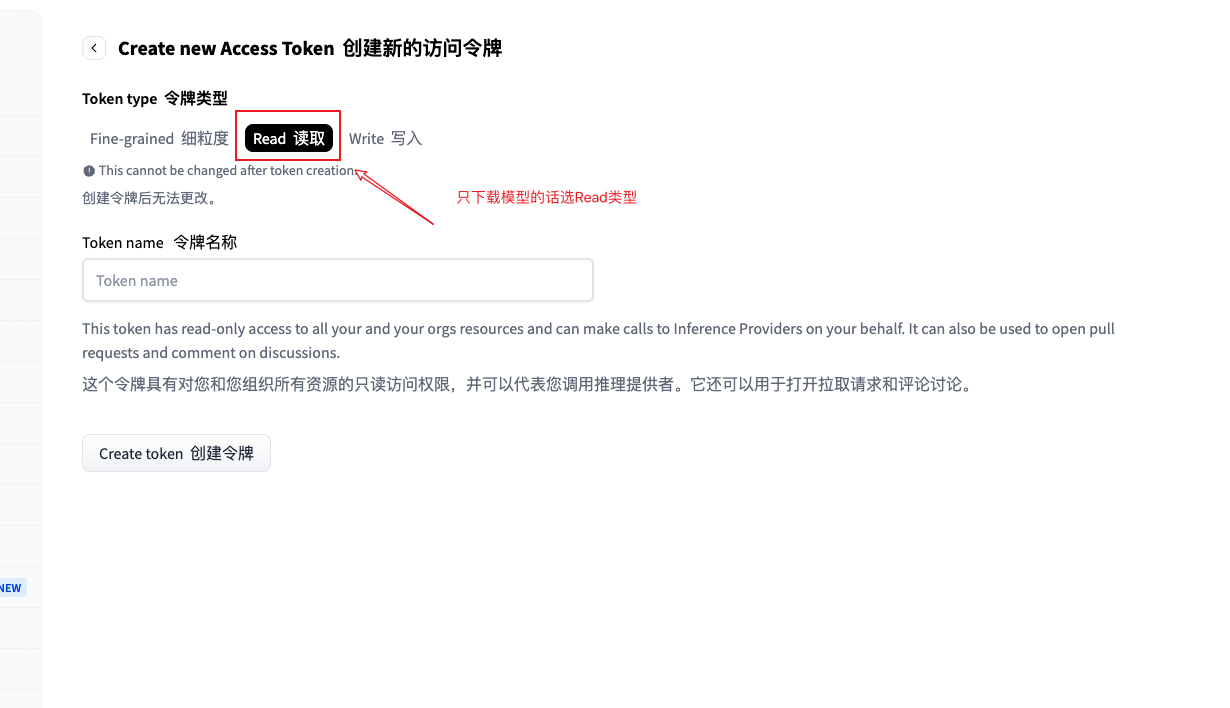
选择 Token 类型
Token 类型对比
| Token类型 | 权限范围 | 适用场景 | 安全建议 |
|---|---|---|---|
| Read(只读) | 只能读取和下载模型 | 日常学习、下载模型、生产环境 | 推荐!即使泄露也无法修改你的仓库 |
| Write(读写) | 可以上传模型、修改仓库 | 需要上传微调模型、发布数据集 | 谨慎保管,泄露可能导致仓库被篡改 |
新手建议:如果你只是下载模型学习,选择 Read 类型即可。
步骤四:创建并保存 Token
填写Token名称(如"MyLaptop"或"DevServer"),点击创建。重要!Token只会显示一次,关闭窗口后无法再查看!
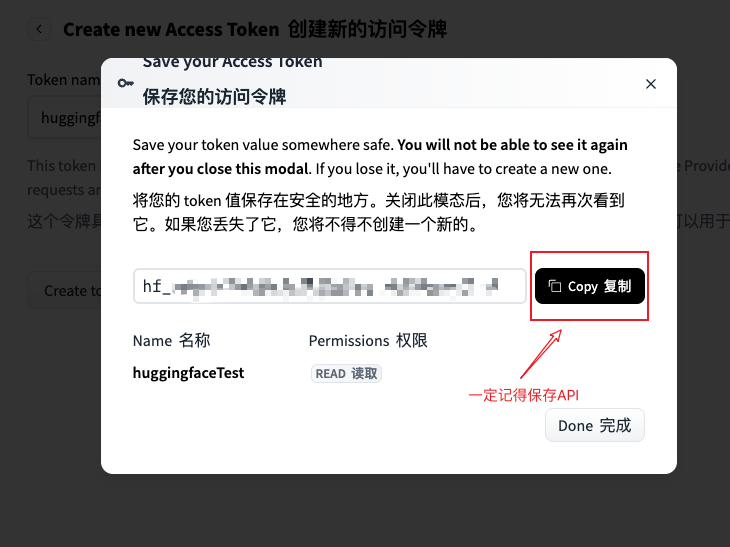
保存 Token(只显示一次)
立即复制这个以 hf_ 开头的字符串,并保存到:
密码管理器(推荐)
或者记事本(但要注意安全)
1.4.2.3 本地登录配置 链接到标题
现在我们有了Token,接下来要在本地电脑上"登录",这样以后下载模型时就不需要每次都输入Token了。
步骤一:安装 huggingface_hub 库
打开终端(Terminal)或命令提示符,执行:
!pip install -U "huggingface_hub[cli]"
注意:-U 表示升级到最新版本,[cli] 表示安装命令行工具。
步骤二:执行登录命令
在终端执行:
!huggingface-cli login
系统会提示 Enter your token (input will not be visible):。**特别注意:粘贴Token时屏幕不会显示任何字符,这是正常的安全设计!**粘贴后直接按回车即可。
命令行登录执行
步骤三:验证登录成功
如果看到 Login successful(登录成功),说明配置完成!你可以用以下命令验证:
!huggingface-cli whoami
会显示你的用户名,确认已登录。
1.4.2.4 如何搜索和筛选模型 链接到标题
第一步:访问 HuggingFace 主页
打开浏览器,访问 https://huggingface.co/models(模型列表页面)。
第二步:使用搜索框
页面顶部有一个搜索框,你可以:
直接输入模型名称(如"Llama-3")
输入任务类型(如"text-generation"、“translation”)
输入机构名称(如"meta"、“google”)
第三步:使用筛选器
左侧有很多筛选选项,对新手最有用的是:
任务(Task):选择你想做的事,如"文本生成(Text Generation)"、“问答(Question Answering)”
排序(Sort):选择"Most downloads"(下载最多),这样能找到最靠谱、最流行的模型
大小(Size):选择模型大小,新手建议选"< 3B"(30亿参数以下),这样的模型普通电脑也能跑
第四步:查看模型详情
点击某个模型进入详情页,你会看到:
Model Card:模型的说明文档,包括能做什么、怎么用、有什么限制
Files:模型的所有文件,通常包括权重文件(.bin 或 .safetensors)和配置文件
Community:其他用户的讨论和问题
1.4.2.5 如何下载模型 链接到标题
HuggingFace 提供了三种下载方式,我们从最简单的开始讲。
方式一:在代码里自动下载(最推荐)
这是最方便的方式。Python代码下载模型有两种常用方法,我们先介绍最常用的:
方法A:使用 transformers(最常用⭐)
from transformers import AutoModel, AutoTokenizer
# 第一次运行时会自动下载,后续会使用缓存
model = AutoModel.from_pretrained("bert-base-chinese")
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
特点:下载后直接加载到内存,可以立即使用。适合99%的场景。
方法B:使用 huggingface_hub(进阶)
from huggingface_hub import snapshot_download
model_path = snapshot_download(
repo_id="meta-llama/Llama-2-7b-chat-hf",
repo_type="model", # 也可以是 "dataset"
local_dir="./my_local_models/llama-2-7b",
# 过滤文件,只下必要的
allow_patterns=["*.json", "*.safetensors", "tokenizer*"],
ignore_patterns=["*.bin", "*.pth"],
token="您的_READ_TOKEN" # 如果已经CLI登录过,这里可省略
)
特点:只下载不加载,适合批量下载或离线部署。
两种代码下载方式对比
| 对比项 | from_pretrained() | snapshot_download() |
|---|---|---|
| 操作 | 下载 + 加载(一步到位) | 只下载(不加载) |
| 使用场景 | 学习、测试、直接使用 | 批量下载、离线部署 |
| 是否加载到内存 | ✅ 是 | ❌ 否 |
| 能否自定义路径 | ❌ 使用默认缓存 | ✅ 可指定任意路径 |
| 常用程度 | ⭐⭐⭐⭐⭐ 最常用 | ⭐⭐⭐ 进阶场景 |
新手建议:优先使用 from_pretrained(),除非你只想下载模型文件而不立即使用。
注意事项:
第一次下载可能较慢,请耐心等待
模型会被保存在
~/.cache/huggingface/目录下如果网络不稳定,可以使用国内镜像(见下文)
方式二:使用命令行工具下载(基础)
如果你想手动控制下载过程,可以使用 huggingface-cli 工具:
# 先安装工具
!pip install huggingface_hub
# 下载整个模型仓库(适合小模型)
!huggingface-cli download bert-base-chinese
方式三:高效按需下载(专业推荐⭐)
**这是最重要的技巧!**现代大模型动辄几十GB,我们通常只需要下载权重文件(.safetensors)和配置文件,不需要下载旧格式(.bin)。使用这个方法可以:
节省磁盘空间(可能节省一半)
下载速度更快
自定义保存位置
# 高效下载完整示例
!huggingface-cli download \
Qwen/Qwen2.5-7B-Instruct \
--include "*.safetensors" "*.json" "*.model" \
--exclude "*.bin" \
--local-dir ./models/Qwen2.5-7B \
--resume-download
参数说明:
--include "*.safetensors" "*.json": 只下载 safetensors 权重文件和配置文件--exclude "*.bin": 排除旧的 bin 格式文件--local-dir ./models/Qwen2.5-7B: 自定义保存路径,不使用默认缓存目录--resume-download: 断点续传,网络中断后重新运行会继续下载
为什么推荐 .safetensors 格式?
更安全(防止 Pickle 代码注入攻击)
加载更快(支持零拷贝内存映射)
是新的行业标准
方式四:在网页上手动下载(不推荐)
你也可以在模型详情页点击"Files"标签,然后手动下载每个文件。但这种方式非常麻烦,不建议新手使用。
1.4.2.6 国内用户加速完整方案 链接到标题
如果你在国内访问 HuggingFace 经常遇到速度慢、连接超时等问题,这里提供三种加速方案,可以单独使用或组合使用。
方案一:使用 hf-mirror 镜像(推荐)
这是最简单有效的方法。通过设置环境变量,让所有下载请求自动转向国内镜像站点:
import os
# 设置环境变量,使用镜像
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 然后正常使用
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-chinese")
如果你想让这个配置永久生效(不用每次都设置),可以写入Shell配置文件:
# Linux/Mac用户
!echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
!source ~/.bashrc
# 或者如果你用zsh
!echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.zshrc
!source ~/.zshrc
Windows用户:
# 以管理员身份打开PowerShell,执行以下命令
[System.Environment]::SetEnvironmentVariable('HF_ENDPOINT', 'https://hf-mirror.com', 'User')
# 重启PowerShell窗口使配置生效
方案二:使用 hf_transfer 多线程下载
对于大模型(几十GB),可以启用多线程并发下载,大幅提升速度:
# 1. 先安装加速库
!pip install hf_transfer
# 2. 启用加速下载(在命令前加环境变量)
!HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download gpt2
注意:开启此选项后,进度条可能不如默认详细,但速度会明显提升。
方案三:组合使用(最快)
将镜像和多线程结合,速度最快:
# 同时开启镜像和多线程
!export HF_ENDPOINT=https://hf-mirror.com
!export HF_HUB_ENABLE_HF_TRANSFER=1
!huggingface-cli download Qwen/Qwen2.5-7B-Instruct --local-dir ./models/
在国内网络环境下,这种组合通常能达到 50-100 MB/s 的下载速度(看网速带宽)。
1.4.2.7 常见问题与避坑指南 链接到标题
在使用 HuggingFace 的过程中,新手经常会遇到各种问题。这里整理了 10 个最常见的问题和解决方案,帮你节省 90% 的排查时间。我们将这些问题分为两类:一句话能说清的快速问题用速查表呈现,需要代码操作的复杂问题则逐个展开讲解。
📋 常见问题速查表
以下四个问题的解决思路比较直接,我们用一张表快速过一遍:
HuggingFace 高频问题速查
| 问题 | 典型现象 | 原因 | 解决方法 |
|---|---|---|---|
| ① 403 权限拒绝 | 下载 Llama 3、Gemma 等模型时报 403 Forbidden | 门控模型(Gated Models)需先同意使用协议 | 登录 HuggingFace 网页 → 进入模型页 → 点击 “Request Access” → 审批通过后用 Token 下载 |
| ② 429 请求过多 | 下载中断,提示 429 Too Many Requests | 匿名下载共享 IP 速率配额,容易触发限流 | 配置 Token 登录(见 2.2.3),登录用户享有更高的专属下载配额 |
| ③ 网络超时 | Connection Timeout | 国内访问 huggingface.co 不稳定 | 使用 hf-mirror 镜像(见 2.2.6 方案一) |
| ④ 磁盘空间不足 | 下载到一半报 No space left on device | 磁盘剩余空间不够 | 指定大容量磁盘路径 --local-dir /data/models/,或清理缓存(见问题八)、只下载必要文件(见问题九) |
提示:以上四个问题中,问题①和② 通过配置 Token 就能一并解决,建议优先完成 Token 登录配置。
🔧 问题五:transformers 版本与模型不兼容 链接到标题
现象:加载模型时报错
KeyError、AttributeError等原因:新发布的模型通常需要较新版本的
transformers库
解决方法:
# 方法1:升级到最新版(推荐)
!pip install -U transformers
# 方法2:查看模型卡片中推荐的版本,安装指定版本
# !pip install transformers==4.40.0
建议优先使用方法1。只有当模型卡片明确要求特定版本时,才取消方法2的注释并锁定版本号。
🔧 问题六:如何查看模型的稳定版本 链接到标题
场景:模型仓库有多个分支和版本,不确定该用哪个
三种判断方法,按可靠度从高到低排列:
| 优先级 | 方法 | 操作 |
|---|---|---|
| ⭐⭐⭐ | 查看更新日志 | 进入模型卡片,找 Changelog 部分,使用最近稳定发布的版本 |
| ⭐⭐ | 查看文件版本 | 点击「Files and versions」标签,选择带 stable 标签或明确版本号的分支 |
| ⭐ | 看下载趋势 | 在模型页面查看「Downloads」趋势图,下载量稳定上升的版本通常最可靠 |
🔧 问题七:下载中断如何续传 链接到标题
场景:大模型动辄几十 GB,下载过程中网络中断是常事
CLI 方式:添加 --resume-download 参数即可从断点继续:
!huggingface-cli download model_name --resume-download
Python 方式:默认自动支持断点续传,重新运行相同的下载代码即可,无需额外参数。
🔧 问题八:模型下载到哪里了?如何清理缓存? 链接到标题
场景:磁盘被模型文件占满,需要定位和清理
默认缓存目录:~/.cache/huggingface/hub/
查看当前缓存占用大小:
!du -sh ~/.cache/huggingface/
如果需要清理,可以按粒度选择:
# 清理特定模型(替换 {owner} 和 {model} 为实际名称)
# ⚠️ 请确认不再需要该模型后再执行
# !rm -rf ~/.cache/huggingface/hub/models--{owner}--{model}/
# 完全清理所有缓存
# ⚠️ 清理后需要重新下载所有模型,请谨慎执行
# !rm -rf ~/.cache/huggingface/hub/
注意:上面的删除命令已注释保护,确认需要清理时去掉 # 再执行。清理后相关模型需要重新下载。
🔧 问题九:.bin 和 .safetensors 文件如何选择? 链接到标题
结论:优先选择
.safetensors格式
.safetensors 相比传统 .bin 格式有三个核心优势:
- 更安全 — 防止 Pickle 代码注入攻击
- 更快速 — 支持零拷贝内存映射,加载速度显著提升
- 更主流 — 已成为新的行业标准格式
下载时可以通过参数过滤,只拉取 safetensors 格式:
!huggingface-cli download model_name \
--include "*.safetensors" "*.json" \
--exclude "*.bin"
执行后只会下载 .safetensors 权重文件和 .json 配置文件,旧的 .bin 格式会被跳过,节省磁盘空间。
🔧 问题十:Token 安全问题(公用机器) 链接到标题
场景:在公司服务器或共享电脑上操作
风险:
huggingface-cli login会把 Token 永久保存到本地文件,其他用户可能读取
安全方案:使用环境变量传递 Token,不保存到磁盘:
# 方法1:通过环境变量传递(推荐)
import os
os.environ["HF_TOKEN"] = "hf_YourTokenHere"
# 然后在终端中使用:
# !huggingface-cli download model_name --token $HF_TOKEN
# 方法2:在命令中直接指定
# !huggingface-cli download model_name --token hf_YourTokenHere
这样 Token 只在当前会话有效,关闭终端或重启 Kernel 后自动失效,避免了凭证泄露的风险。
1.4.3 ModelScope 实用操作指南 链接到标题
📅 时效性说明:本节内容基于
modelscope>=1.20.0版本,测试环境为 PyTorch 2.8.0 + Python 3.12 + CUDA 12.8(RTX 4090),测试时间为 2026年2月。ModelScope 平台更新较频繁,界面布局可能略有变化,但核心操作流程保持一致。
ModelScope(魔搭社区)是阿里巴巴达摩院推出的开源模型平台,对国内用户非常友好。接下来我们按照"注册账号 → 获取Token → 本地登录 → 搜索下载"的顺序,完成全部配置。
1.4.3.1 注册 ModelScope 账号 链接到标题
第一步:访问官网并点击注册
打开浏览器访问 ModelScope 魔搭社区官网,点击页面右上角的**“登录/注册”**按钮。
第二步:手机验证登录(国内特色)
推荐使用手机验证码登录/注册,这是最快的方式:
输入手机号
获取验证码
设置密码(可选)
第三步:完成注册
注册成功后,会自动跳转回首页,右上角会显示你的头像。
💡 小提示:国内平台通常强制绑定手机号,这样找回密码也更方便。
1.4.3.2 获取 Access Token(SDK 令牌) 链接到标题
Access Token 是你在终端与魔搭社区交互的"身份证",下载模型时需要用到。
第一步:进入个人中心
鼠标悬停在右上角头像,点击 “个人中心”。
第二步:找到访问令牌
在左侧菜单栏中找到 “访问令牌”(Access Token)。
第三步:复制并保存
点击 “复制” 按钮,将那串以 SDK_ 开头的字符串保存好。
⚠️ 重要警告:Token只显示一次,请立即保存!不要泄露给他人!
1.4.3.3 本地 CLI 登录配置 链接到标题
为了确保下载过程顺畅,我们需要在终端进行一次性登录。
第一步:安装 ModelScope SDK
# 升级 pip
!pip install --upgrade pip
# 安装 ModelScope 核心库(包含 CLI 工具)
!pip install modelscope
第二步:执行登录命令
将 <您的SDK令牌> 替换为上一步复制的字符串:
!modelscope login --token <您的SDK令牌>
成功标志:系统提示 Login succeeded,Token 已被保存到本地配置文件。此后你无需每次输入密码。
1.4.3.4 如何搜索和筛选模型 链接到标题
第一步:访问 ModelScope 主页
打开 https://modelscope.cn/models(模型广场)。
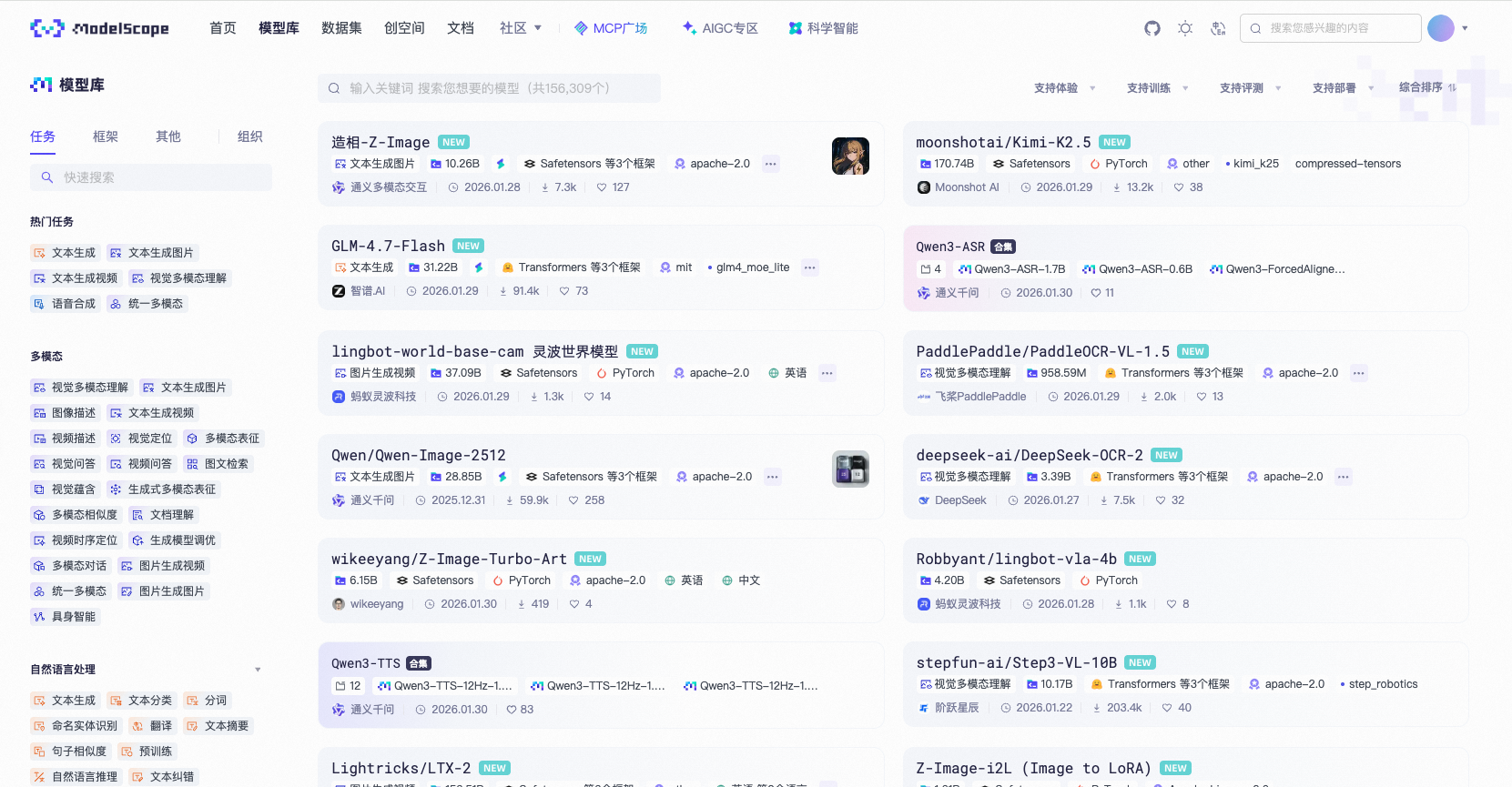
第二步:使用搜索和筛选
ModelScope 的界面是中文的,非常直观:
顶部搜索框:输入关键词(如"通义千问"、“对话模型”)
左侧筛选:
任务类型:自然语言处理、计算机视觉等
标签:大语言模型、中文、对话等
框架:PyTorch、TensorFlow 等
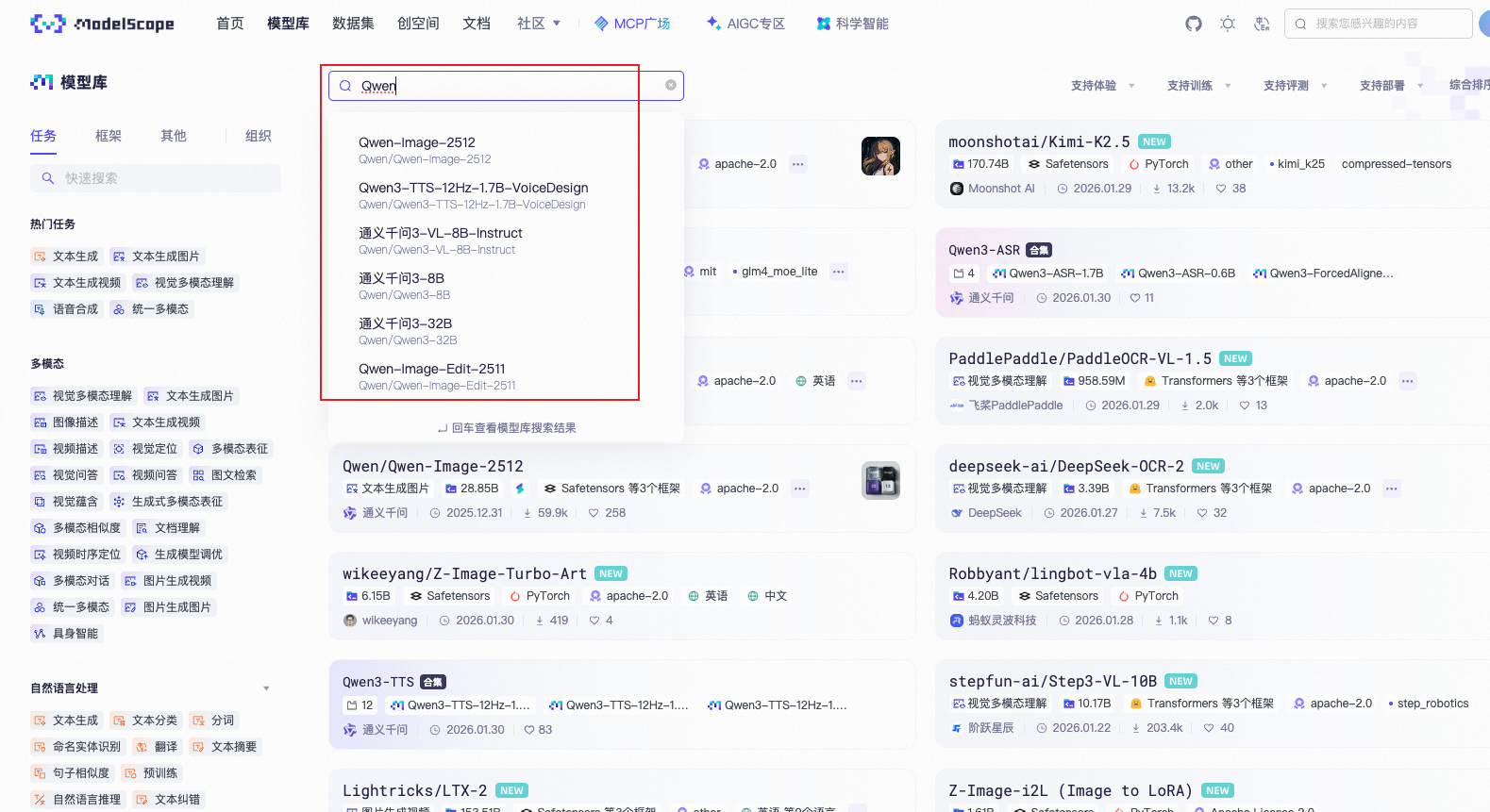
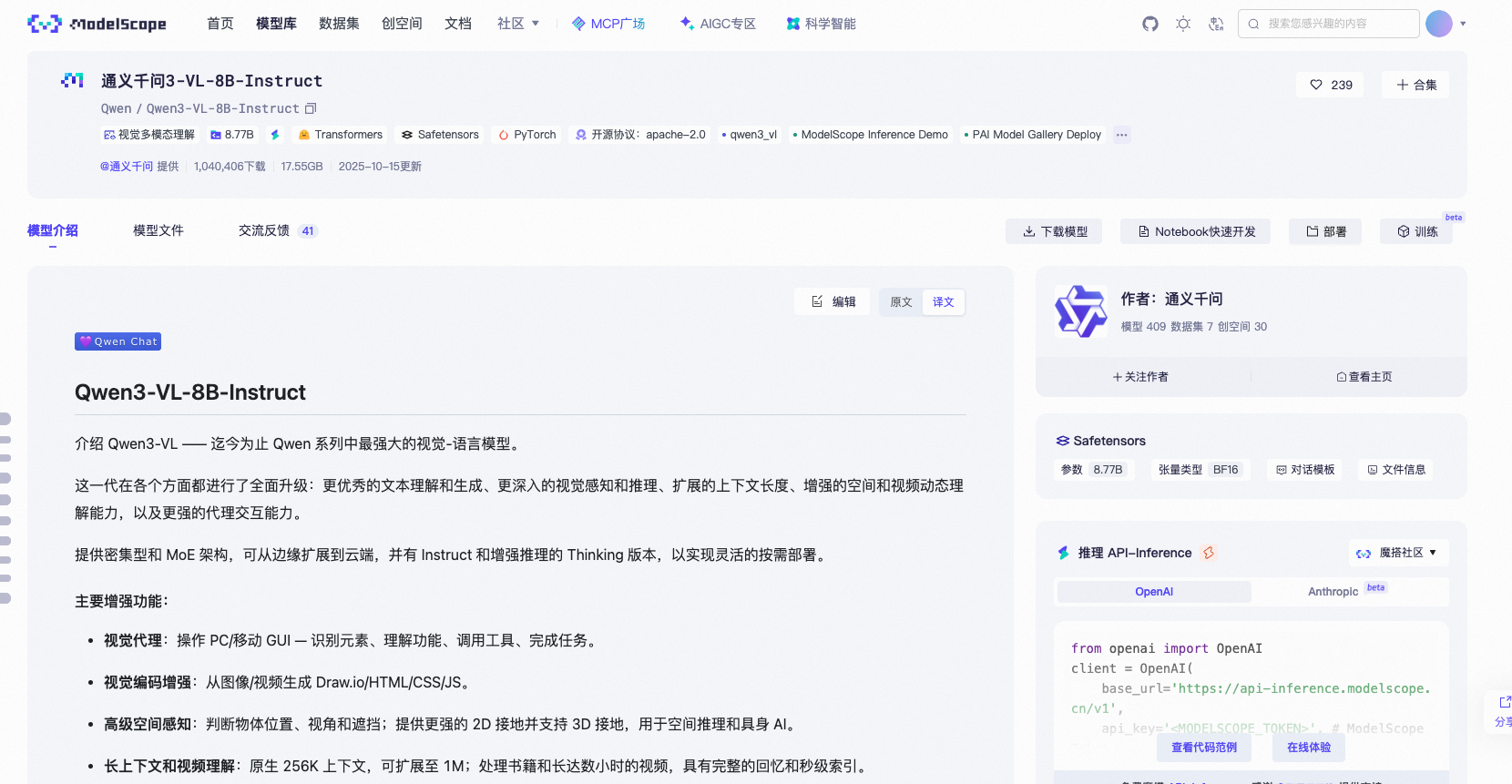
第三步:查看模型详情
点击模型进入详情页,你会看到:
模型介绍:中文说明,非常详细
在线体验:很多模型支持在线运行,不用下载就能试用
如何使用:有完整的代码示例
1.4.3.5 如何下载模型 链接到标题
ModelScope 提供了三种下载方式,我们从最实用的开始讲。
方式一:使用 CLI 命令下载(推荐用于建立本地库)
这是最灵活的方式,支持指定目录、筛选文件:
# 基础命令:下载整个模型
!modelscope download --model 'Qwen/Qwen2.5-7B-Instruct'
# 进阶命令:指定下载目录(推荐)
!modelscope download --model 'Qwen/Qwen2.5-7B-Instruct' \
--local_dir './models/Qwen2.5-7B'
# 高级用法:只下载必要文件,排除旧格式
!modelscope download --model 'Qwen/Qwen2.5-7B-Instruct' \
--include '*.safetensors' '*.json' \
--exclude '*.bin' '*.pth' \
--local_dir './models/Qwen2.5-7B'
CLI 常用参数说明:
ModelScope CLI 常用参数
| 参数 | 说明 | 示例 |
|---|---|---|
--model | 模型 ID | Qwen/Qwen2.5-7B-Instruct |
--local_dir | 指定下载路径 | ./models/Qwen2.5-7B |
--include | 只下载匹配的文件 | '*.safetensors' |
--exclude | 排除不需要的文件 | '*.bin' |
--revision | 指定版本 | v1.0.0 |
方式二:使用 Python SDK 下载(适合代码集成)
from modelscope import snapshot_download
# 基础用法
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')
print(f'模型已下载到: {model_dir}')
from modelscope import snapshot_download
# 进阶用法:指定目录和版本
model_dir = snapshot_download(
'Qwen/Qwen2.5-7B-Instruct', # 模型 ID
cache_dir='./models', # 指定下载目录
revision='master' # 指定版本号
)
1.4.3.6 ModelScope 的独特优势 链接到标题
对于国内新手,ModelScope 有几个非常实用的优势:
优势一:免费 GPU 环境
在模型详情页,很多模型都有"在线运行"按钮。点击后会进入一个 Jupyter Notebook 环境,里面已经配好了 GPU,你可以:
直接运行示例代码
测试模型效果
修改代码做实验
这对于没有 GPU 的新手来说非常友好。
优势二:下载速度快
因为服务器在国内,下载速度通常能达到满速,不需要额外配置镜像。
优势三:中文模型丰富
如果你要做中文应用(如中文对话、中文摘要),ModelScope 上有很多专门优化过的中文模型:
通义千问(Qwen)系列
ChatGLM 系列
百川(Baichuan)系列
1.4.3.7 常见问题与避坑指南 链接到标题
问题一:SSL 证书错误
在企业内网或特定网络环境下,可能遇到 SSLError: certificate verify failed。
# 临时解决方案(仅限开发环境),清除这个错误路径后,程序回退到使用自带的正确证书,网络连接就恢复正常了
import os
os.environ['CURL_CA_BUNDLE'] = ''
from modelscope import snapshot_download
# 继续下载...
问题二:下载速度慢
默认并发数较低,可以通过 max_workers 参数提速:
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen2.5-7B-Instruct',
max_workers=16 # 提升并发数
)
问题三:离线环境加载模型
已下载的模型在无网络环境下使用:
from modelscope.pipelines import pipeline
inference_pipe = pipeline(
task='text-generation',
model='/path/to/local/model',
local_files_only=True, # 关键:强制离线模式
model_revision=None
)
问题四:缓存目录太大
默认缓存在 ~/.cache/modelscope,定期清理不需要的模型:
# 查看缓存大小
!du -sh ~/.cache/modelscope
# 删除不需要的模型(谨慎操作)
# ⚠️ 确认后取消注释再执行
# !rm -rf ~/.cache/modelscope/hub/models/<模型名>
1.4.3.8 进阶技巧 链接到标题
技巧一:版本锁定(确保可复现)
模型权重可能会更新,导致代码突然跑不通。务必锁定版本:
# CLI 方式
!modelscope download --model 'Qwen/Qwen2.5-7B-Instruct' \
--revision 'v1.0.0' \
--local_dir './models/Qwen2.5-7B-v1.0.0'
# SDK 方式
model_dir = snapshot_download(
'Qwen/Qwen2.5-7B-Instruct',
revision='v1.0.0'
)
技巧二:批量下载脚本
为学生或团队准备环境时,可以编写批量下载脚本:
from modelscope import snapshot_download
import os
# 定义模型清单
MODEL_LIST = [
('Qwen/Qwen2.5-7B-Instruct', 'Qwen2.5-7B'),
('AI-ModelScope/bge-large-zh-v1.5', 'embedding/bge-large-zh'),
]
BASE_DIR = "./model_zoo"
for model_id, local_name in MODEL_LIST:
save_path = os.path.join(BASE_DIR, local_name)
print(f"📦 正在下载: {model_id}")
snapshot_download(model_id, local_dir=save_path)
print(f"✅ 完成: {save_path}")
技巧三:统一资源目录规划
在 AutoDL 或云服务器上,建议将资源放在数据盘:
/root/autodl-tmp/
├── model_zoo/ # 存放模型
│ ├── Qwen2.5-7B/
│ ├── embedding/
│ └── multimodal/
└── data_zoo/ # 存放数据集
└── my_dataset/
1.4.4 如何选择?实用决策指南 链接到标题
看到这里,你可能会问:我到底应该用哪个平台? 这里给你一个简单的决策流程:
场景选择建议
| 你的情况 | 推荐平台 | 理由 |
|---|---|---|
| 我在国内,做中文应用 | ModelScope 优先 | 速度快、中文模型多、免费算力 |
| 我需要 Llama、GPT 等国际知名模型 | HuggingFace | 这些模型通常先在 HF 发布 |
| 我的网络访问 HF 很慢 | ModelScope | 避免下载卡顿 |
| 我想找最新、最前沿的模型 | HuggingFace | 全球研究者首发地 |
| 我需要在线运行环境 | ModelScope | 免费 GPU 更充足 |
实用建议:两个平台都注册账号,哪个方便用哪个。很多时候,你会在 HuggingFace 找到模型名称,然后去 ModelScope 搜索同名模型,直接在国内快速下载。
过渡:模型下载完成后,你可能会看着文件夹里那一堆 .json、.safetensors 文件发愁。这些文件到底是干什么的?为什么有的模型几GB,有的几百GB?这一章我们将深入模型内部,解开这些谜题。
第二章:GitHub 与大模型开发——代码仓库的作用 链接到标题
📅 时效性说明:本节关于 GitHub 2FA 强制政策、Token 认证方式的说明基于 2026年2月的最新情况。GitHub 于 2023年底完成了对活跃开发者的强制 2FA 部署,自 2021年8月13日起不再支持密码方式进行 Git 操作。
在前两章中,我们完整掌握了如何在 HuggingFace 和 ModelScope 这两个模型托管平台上搜索、筛选、下载模型。现在你应该已经能熟练地获取任何开源大模型了。但在实际开发过程中,你可能会遇到这样的情况:模型下载下来了,却不知道怎么用。这时候你需要的不是模型文件,而是示例代码、最佳实践、完整的应用框架。而这些内容的主要来源,就是我们将在本章介绍的 GitHub。
很多新手会有一个误解,认为 GitHub 也是用来下载模型的。毕竟有些教程里会提到"去 GitHub 克隆某个模型"。但实际上,GitHub 的核心定位与 HuggingFace/ModelScope 完全不同:后两者是"模型仓库",存放的是训练好的模型权重文件(动辄几 GB 到几十 GB);而 GitHub 是"代码仓库",存放的是源代码、脚本、配置文件(通常只有几 KB 到几 MB)。虽然 GitHub 在技术上可以通过 Git LFS(大文件存储)托管模型,但这不是它的主要用途,我们也不推荐新手这样做。
那么 GitHub 对大模型开发者的价值是什么呢?简单来说:GitHub 是你获取"如何使用模型"知识的主要渠道。你会在这里找到:
示例代码与教程:别人已经写好的、可以直接跑通的大模型应用代码
开源框架与工具:如 LangChain、LlamaIndex 这些让你快速搭建应用的框架
问题排查与解决方案:遇到报错时,99% 的情况都能在 GitHub Issues 里找到答案
为了帮你建立完整认知,本章将按照"明确定位 → 注册配置 → 高效搜索 → Issue 避坑“的主线展开。我们会先澄清 GitHub 与模型平台的区别,然后手把手教你注册账号、配置 Token,接着传授高级搜索技巧(如何从 4 亿个项目中快速找到高质量代码),最后说明如何利用 Issues 解决实际问题。学完之后,你将能独立在 GitHub 上找到任何你需要的开源代码资源。
2.1 GitHub 是什么?——全球最大的代码图书馆 链接到标题
在进入具体操作之前,我们先来建立一个清晰的认知:GitHub 到底是什么?它和我们前面学的模型平台有什么本质区别?
类比理解 GitHub 的定位:
如果把软件开发比作做菜,那么:
HuggingFace/ModelScope(模型平台)就像食材市场——你去那里买原材料(模型权重)
GitHub(代码平台)就像菜谱图书馆——你去那里找食谱(示例代码)、学做法(教程)、看别人的评价(Issues讨论)
更具体地说,GitHub 是目前全球最大的开源代码托管平台,拥有:
超过 4 亿个代码仓库(从个人小项目到 Linux 内核这样的超大项目)
超过 1 亿名开发者在上面协作、分享代码
几乎所有主流开源项目都在这里托管(包括 PyTorch、TensorFlow、LangChain 等)
💡 Git 和 GitHub 的区别(新手必知)
这两个名字很像,但它们是完全不同的东西:
- Git:是一个版本控制工具(软件),安装在你的电脑上,用于管理代码的历史版本。类比:Word 的"修订历史"功能。
- GitHub:是一个代码托管平台(网站),用于存放和分享代码。类比:百度网盘,但专门用来存代码。
简单记忆:Git 是工具,GitHub 是平台。你用 Git 工具把代码上传到 GitHub 平台。
对于大模型开发者来说,GitHub 的核心价值在于:
GitHub 对大模型开发者的价值
| 你需要什么 | 在哪里找 | 举例 |
|---|---|---|
| 模型权重文件 | HuggingFace/ModelScope | Qwen2.5-7B-Instruct.safetensors |
| 如何使用模型的代码 | GitHub | LangChain 的 RAG 教程项目 |
| 开源框架与工具 | GitHub | vLLM、Ollama、LlamaIndex |
| 报错解决方案 | GitHub Issues | 搜索报错信息,查看已关闭的 Issue |
2.2 注册 GitHub 账号 链接到标题
GitHub 近年来风控较严,国内用户注册时容易遇到"验证码刷不出"或"账号被锁"的情况。以下是避坑指南:
2.2.1 准备工作 链接到标题
邮箱选择:推荐使用 Gmail、Outlook 等国际邮箱。QQ/163 邮箱可以使用,但有时收信慢或被识别为垃圾邮件。
浏览器:推荐使用 Chrome 或 Edge 的无痕模式(Incognito Mode),避免插件干扰注册脚本。
2.2.2 注册流程 链接到标题
第一步:访问官网 https://github.com/ ,点击右上角 “Sign up”。
GitHub 首页注册入口
第二步:交互式填写信息:
Email: 输入邮箱
Password: 设置强密码(包含大小写字母、数字、符号)
Username: 设置用户名(建议与 ModelScope ID 保持一致,建立个人品牌)
GitHub 注册页面填写信息
你也可以使用 Google 或 Apple 账号快捷注册,系统会自动关联邮箱并填充部分信息:
使用 Google 账号快捷注册
第三步:完成人机验证(通常是"选取螺旋星系"或"计算题”)。
💡 技巧:如果图片加载不出来,请检查网络或临时关闭翻译插件。
第四步:去邮箱查收 6 位数验证码并回填。
注册成功后,你会进入 GitHub 的 Dashboard 首页:
注册成功后的 GitHub 首页
2.2.3 开启 2FA 双重验证(必做!) 链接到标题
为什么必须开启?
当前现状:GitHub 早在 2023 年底就已完成对活跃开发者的强制 2FA 部署。截止目前为止,这已是使用 GitHub 的基础门槛。
强制后果:如果不开启,所有网页端操作将被冻结。你将无法进入 Settings 生成 Token,也就意味着彻底失去了在命令行上传代码的能力。
关于存量账号:即使是老账号,只要有代码提交行为,也会触发强制锁定,必须配置 2FA 才能解封。
配置步骤:
步骤一:点击右上角头像 → Settings,在左侧菜单找到 Password and authentication。
进入 Settings 找到 Password and authentication
步骤二:在 Two-factor authentication 区域,点击 Enable two-factor authentication。
点击 Enable two-factor authentication
步骤三:系统会要求你先验证身份,点击 Verify via email 完成邮箱验证。
邮箱验证确认
步骤四:推荐使用手机APP验证(Microsoft Authenticator 或 Google Authenticator)。打开APP扫描页面上的二维码,然后输入6位动态码。
使用 Authenticator APP 扫描二维码
步骤五:网页会弹出一组 Recovery codes(恢复码),务必复制保存!这是手机丢失后找回账号的唯一途径。
Recovery codes 恢复码(务必保存)
完成以上步骤后,你会看到 2FA 配置成功的确认页面:
2FA 双重验证配置完成
点击 Done 后,返回 Settings 页面可以看到 Two-factor authentication 已经显示为 Configured 状态:
2FA 配置完成后的 Settings 页面
2.3 获取 Personal Access Token 链接到标题
自 2021 年起,GitHub 不再支持使用"账号+密码"的方式在命令行操作。你必须使用 Token(个人访问令牌)。
哪些场景需要用到 Token?
下载私有仓库:访问非公开项目时必须验证身份。
上传代码(Push):向任何仓库(包括你自己的公开仓库)提交更改时。
配置命令行工具:任何涉及身份验证的 Git 操作。
2.3.1 生成 Token 步骤 链接到标题
第一步:进入设置页面
头像 → Settings → 左侧最底部 Developer settings → Personal access tokens → Tokens (classic)
Personal access tokens 设置入口
第二步:点击 Generate new token (classic)
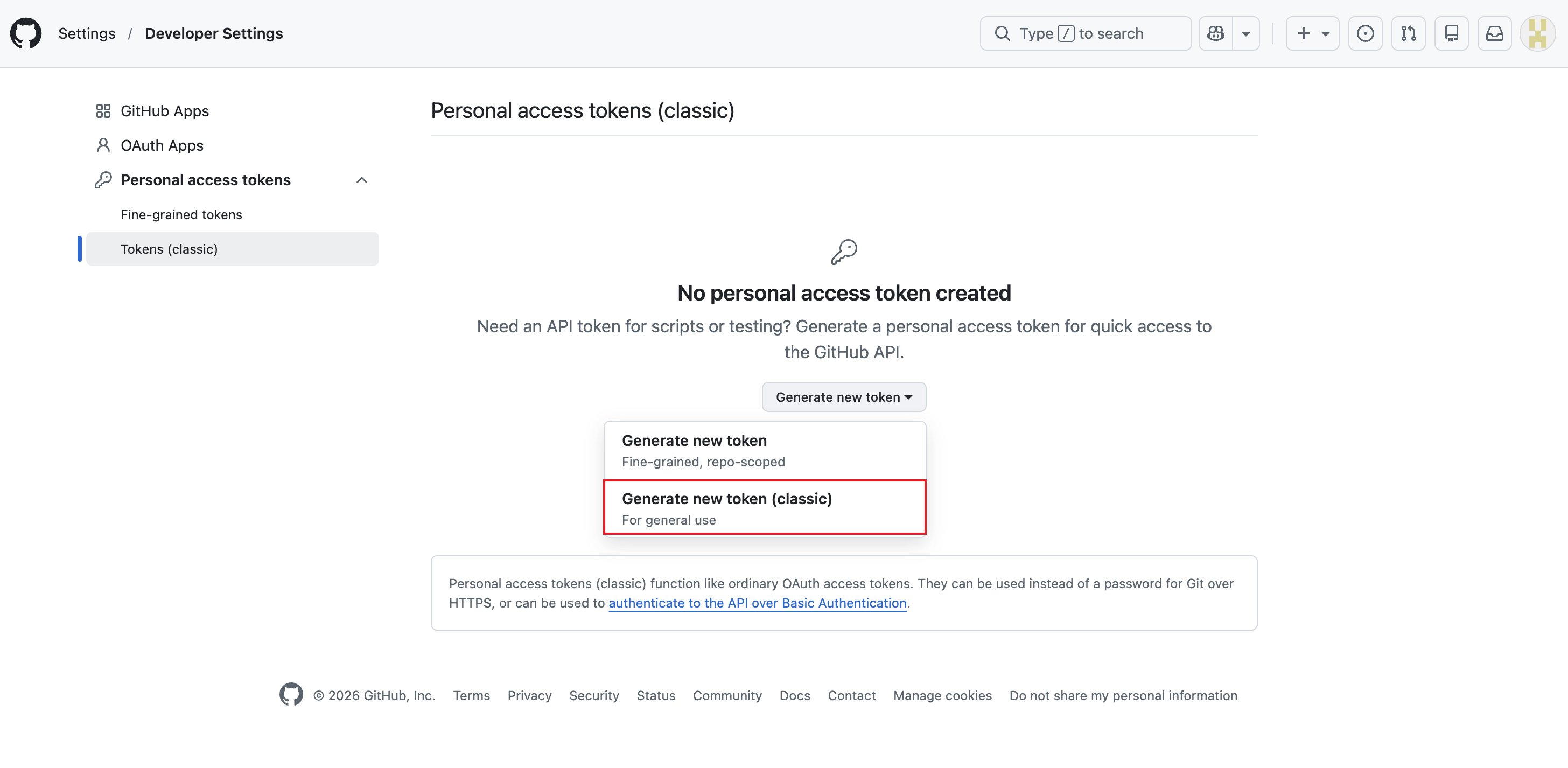
选择 Generate new token (classic)
❓ 常见疑问:Classic 和 Fine-grained 有什么区别?
这里的下拉菜单会让你选择 Classic(经典版) 还是 Fine-grained(细粒度版)。
- Classic(经典版):相当于"万能钥匙"。权限范围广,配置一次能管理你账号下所有仓库,适合个人开发者和学习场景。
- Fine-grained(细粒度版):相当于"单房间钥匙"。必须逐个指定只能访问哪一个仓库,安全性更高,适合企业级多仓库管理场景。
结论:为了避免"新建项目又得重新申请 Token"的麻烦,请务必选择 Classic 版本!
第三步:配置权限
Token 配置项说明
| 配置项 | 建议设置 | 说明 |
|---|---|---|
| Note | MyToken-2025 | 起个名字,方便识别 |
| Expiration | 90 days 或 No expiration | 设置有效期 |
| Select scopes | ✅ repo(必选) | 包含仓库读写权限 |
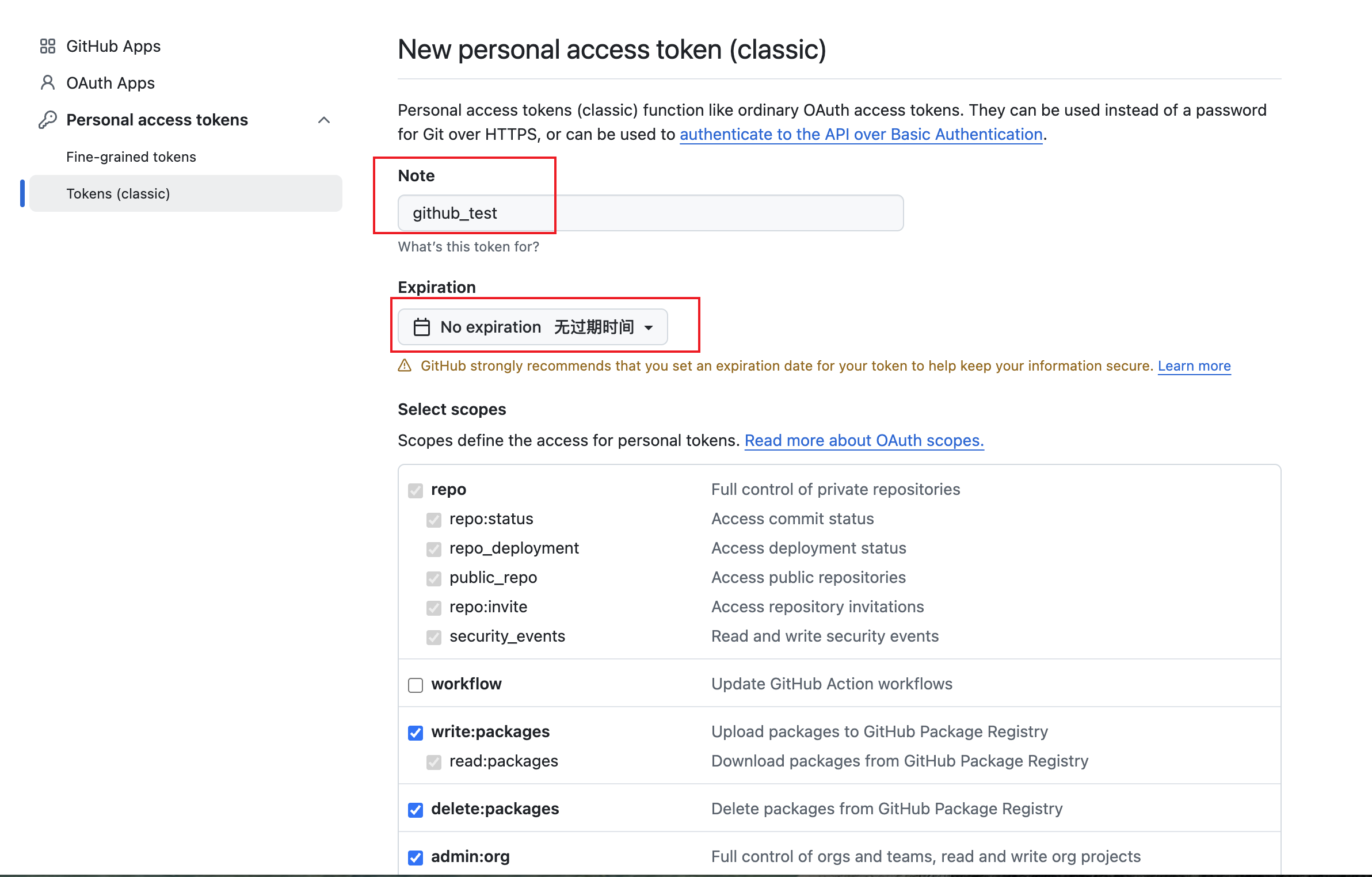
配置 Token 名称、有效期和权限
配置完成后,滚动到页面底部,点击 Generate token 按钮生成令牌:
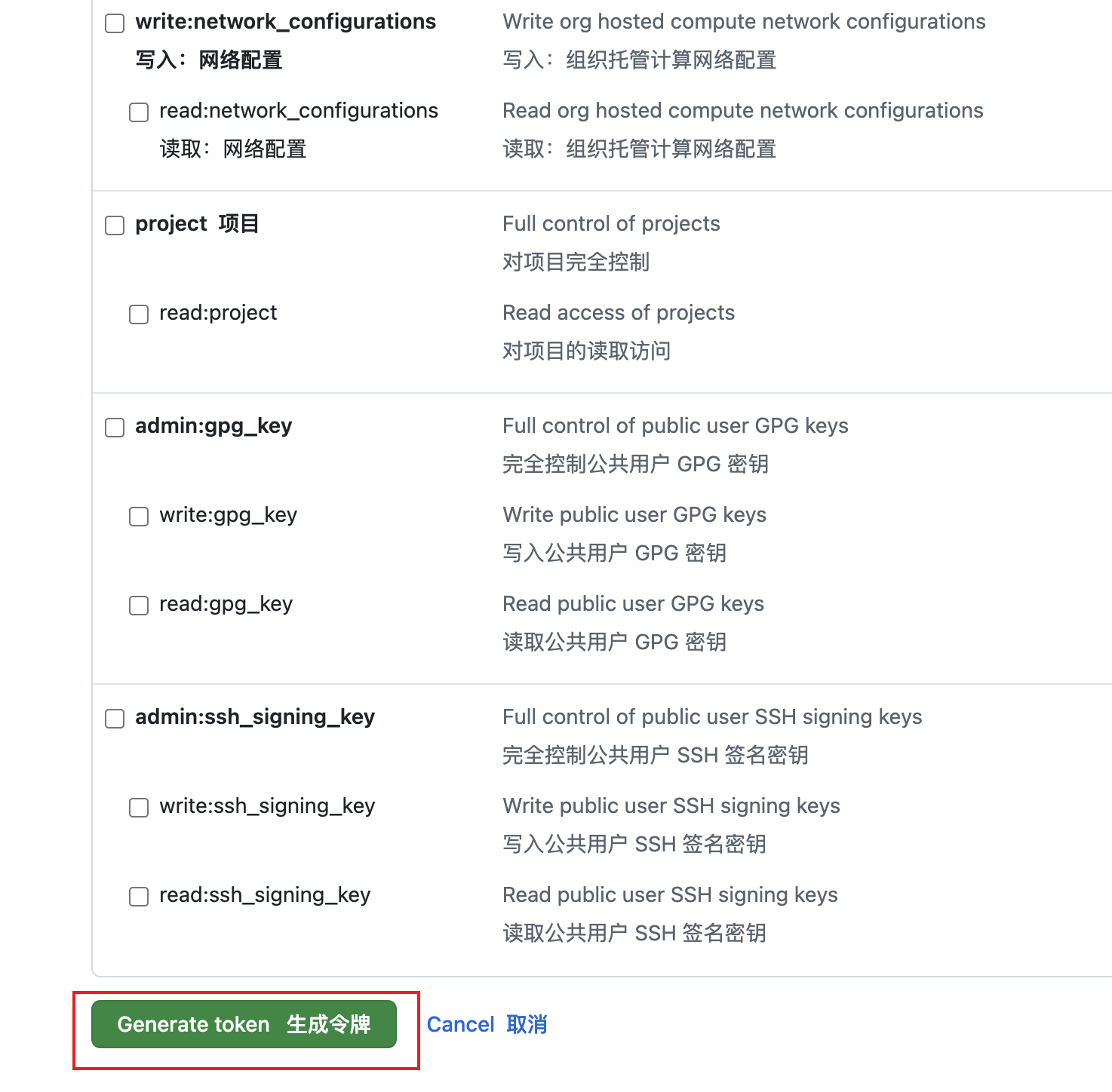
点击 Generate token 生成令牌
第四步:复制以 ghp_ 开头的字符串
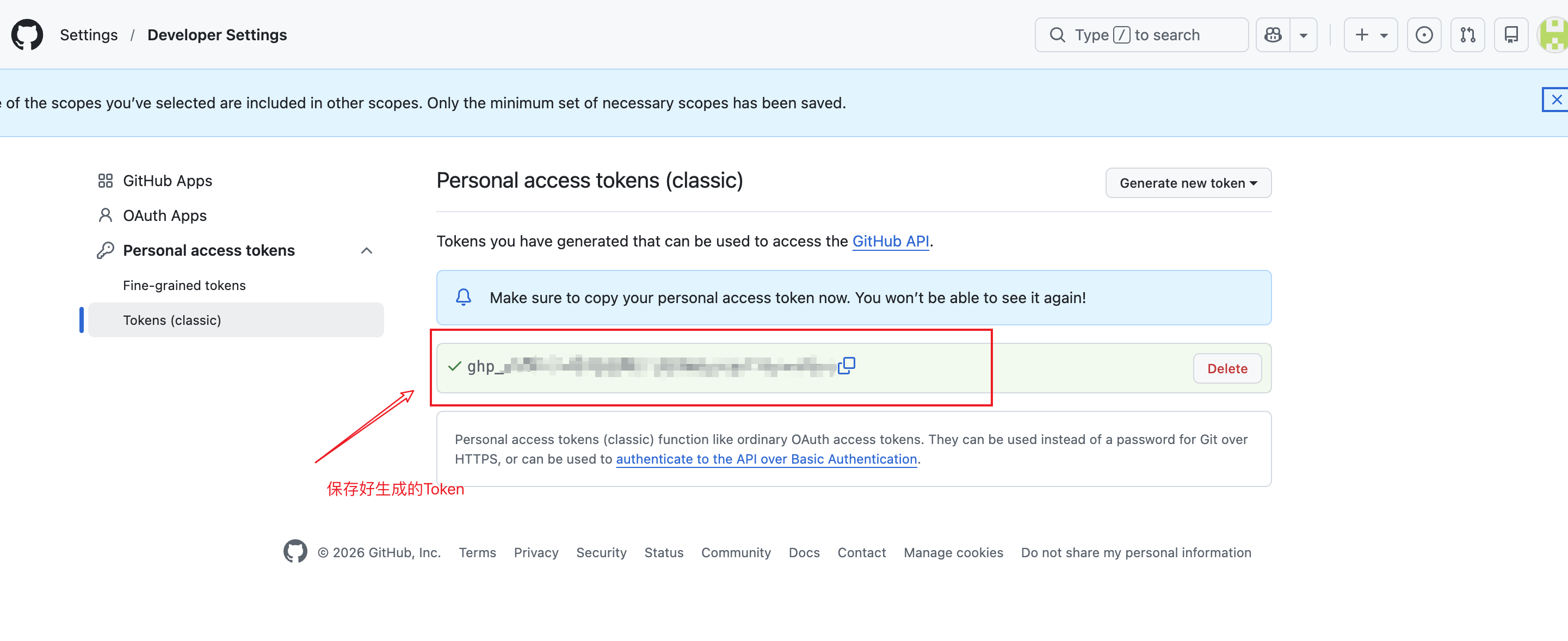
Token 生成成功(只显示一次,立即保存)
⚠️ 重要:Token 只显示一次,刷新页面后就再也不会显示了!立刻复制保存到安全的地方。
2.3.2 使用 Token 链接到标题
关键区分:什么时候需要 Token?
✅ 下载公开项目(Public):直接 Clone,不需要 Token,不需要账号密码。
🔒 下载私有项目(Private):终端会提示输入用户名和密码,此时密码栏必须粘贴 Token。
核心逻辑:标准做法是使用你自己的 Token(代表"我是谁"),并让对方把你添加为 Collaborator(协作者)。 > ⚠️ 警告:虽然使用别人的 Token 也能下载(相当于直接登录了对方账号),但这是极不安全的各种账号共享行为,严禁在正规开发中使用。
- 📤 上传代码(Push):向仓库提交代码时,也必须使用 Token 验证。
操作提示:当系统提示输入 Password 时,请粘贴你的 Token(注意:粘贴时终端不会显示字符,直接回车即可)。
!git clone https://github.com/username/repo.git
# Username: 你的GitHub用户名
# Password: 粘贴Token(不是密码!)
执行成功后,私有仓库的代码会被下载到当前目录。注意:Password 栏粘贴时不会显示任何字符,这是终端的正常安全行为,粘贴后直接回车即可。
2.3.3 一次性配置 Token(免密操作) 链接到标题
每次都要复制粘贴 Token 很麻烦?可以通过简单的配置让 Git 记住你的 Token。
执行命令:
!git config --global credential.helper store
效果:
配置后,第一次 操作私有仓库时仍需输入 Token。
Git 会自动将 Token 保存到本地文件中。
第二次起,再进行任何 Git 操作都不需要输入密码了!
💡 安全提示:此命令会将 Token 以明文形式保存在本地
.git-credentials文件中。如果是通过公共电脑(如网吧、学校机房)操作,请勿使用此配置!
2.4 如何搜索和筛选项目 链接到标题
GitHub 上有超过 4 亿个项目,普通关键词搜索往往被大量废弃项目和学生作业淹没。掌握高级搜索语法,是找到高质量资源的关键。
2.4.1 基础搜索语法 链接到标题
在 GitHub 搜索框中,可以使用以下限定符精准搜索:
GitHub 搜索语法速查表
| 限定符 | 示例 | 作用 |
|---|---|---|
in:name | jquery in:name | 仅匹配项目名称 |
language: | language:python | 限定编程语言 |
stars:>N | stars:>500 | 筛选高关注度项目 |
pushed:>日期 | pushed:>2025-01-01 | 只看最近更新的项目 |
在 GitHub 搜索框中输入关键词
2.4.2 关键指标:区分"玩具"与"生产级"代码 链接到标题
**这是最核心的技巧!**开源世界项目良莠不齐,通过以下指标可以快速判断项目质量:
项目质量评估指标
| 指标 | 语法 | 解读 |
|---|---|---|
| Stars(星标) | stars:>1000 | >1000 是成熟项目,>10000 是顶级项目 |
| Forks(复刻) | forks:>100 | 高Fork数 = 高实用性,比Stars更"硬核" |
| Pushed(更新) | pushed:>2025-01-01 | **最重要!**剔除僵尸代码 |
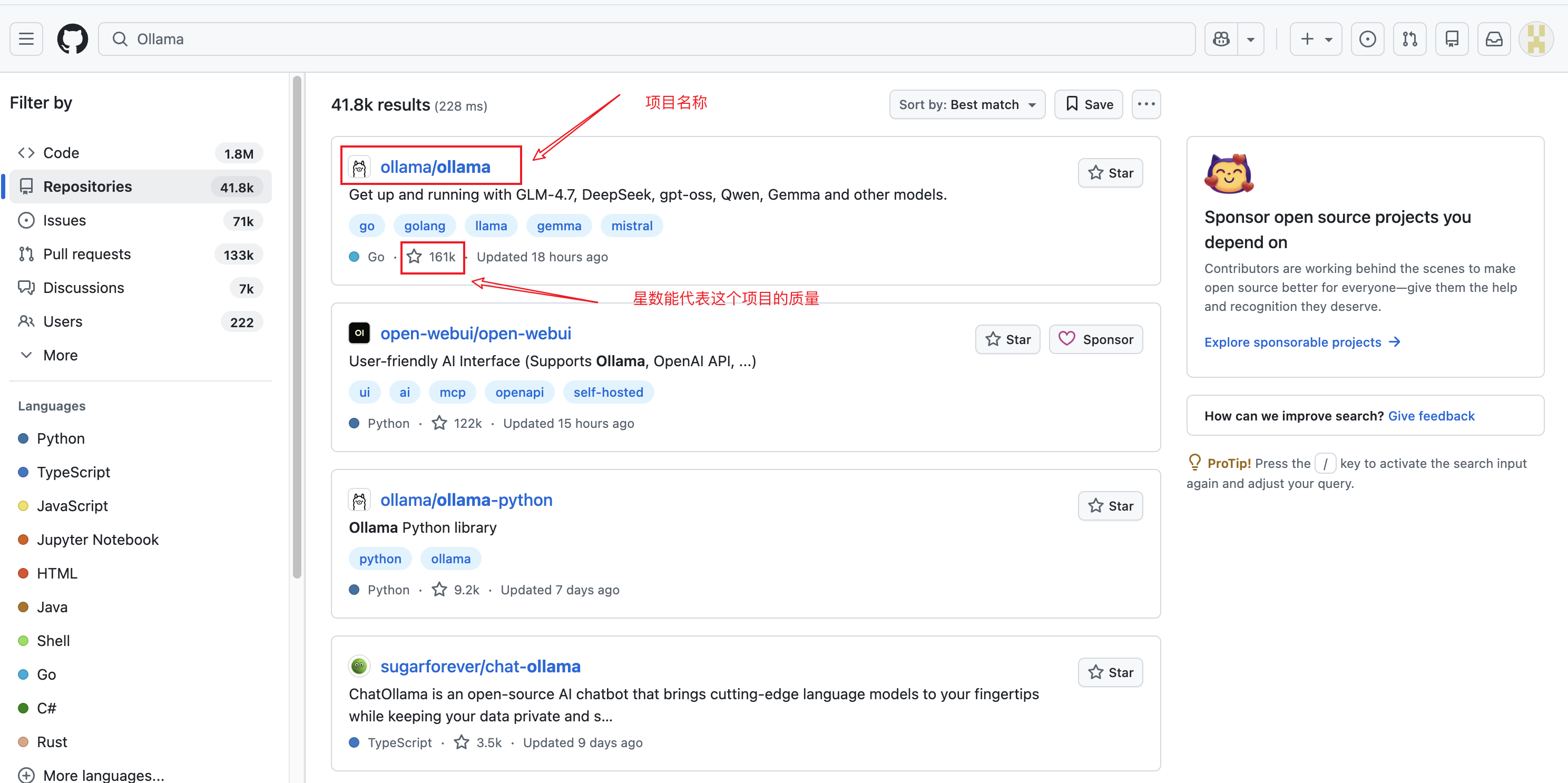
搜索结果页面:关注 Stars 数量和更新时间
深度洞察:Stars vs Forks
10000 Stars + 50 Forks = 通常是"资源列表"或"教程",不是可用的代码库
500 Stars + 200 Forks = 垂直领域的硬核工具库,被大量开发者实际使用
2.4.3 实战:5步漏斗筛选法 链接到标题
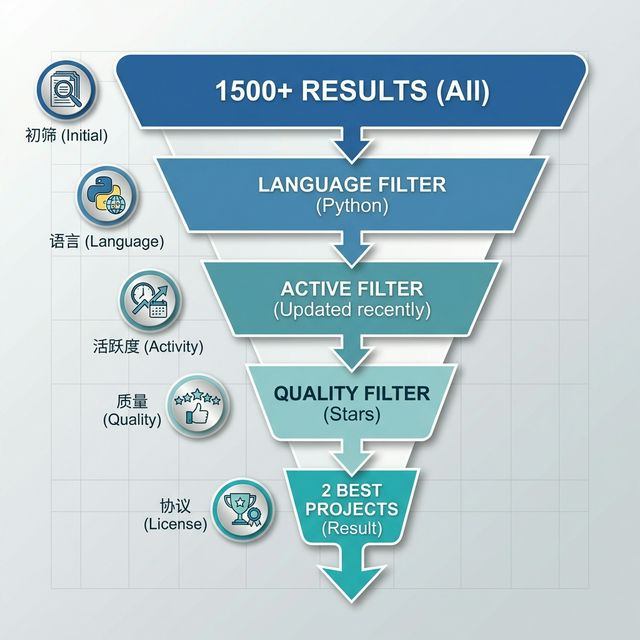
任务:寻找一个基于 Python 的、活跃维护的 PDF 表格提取库
步骤一(初筛):
pdf table extract
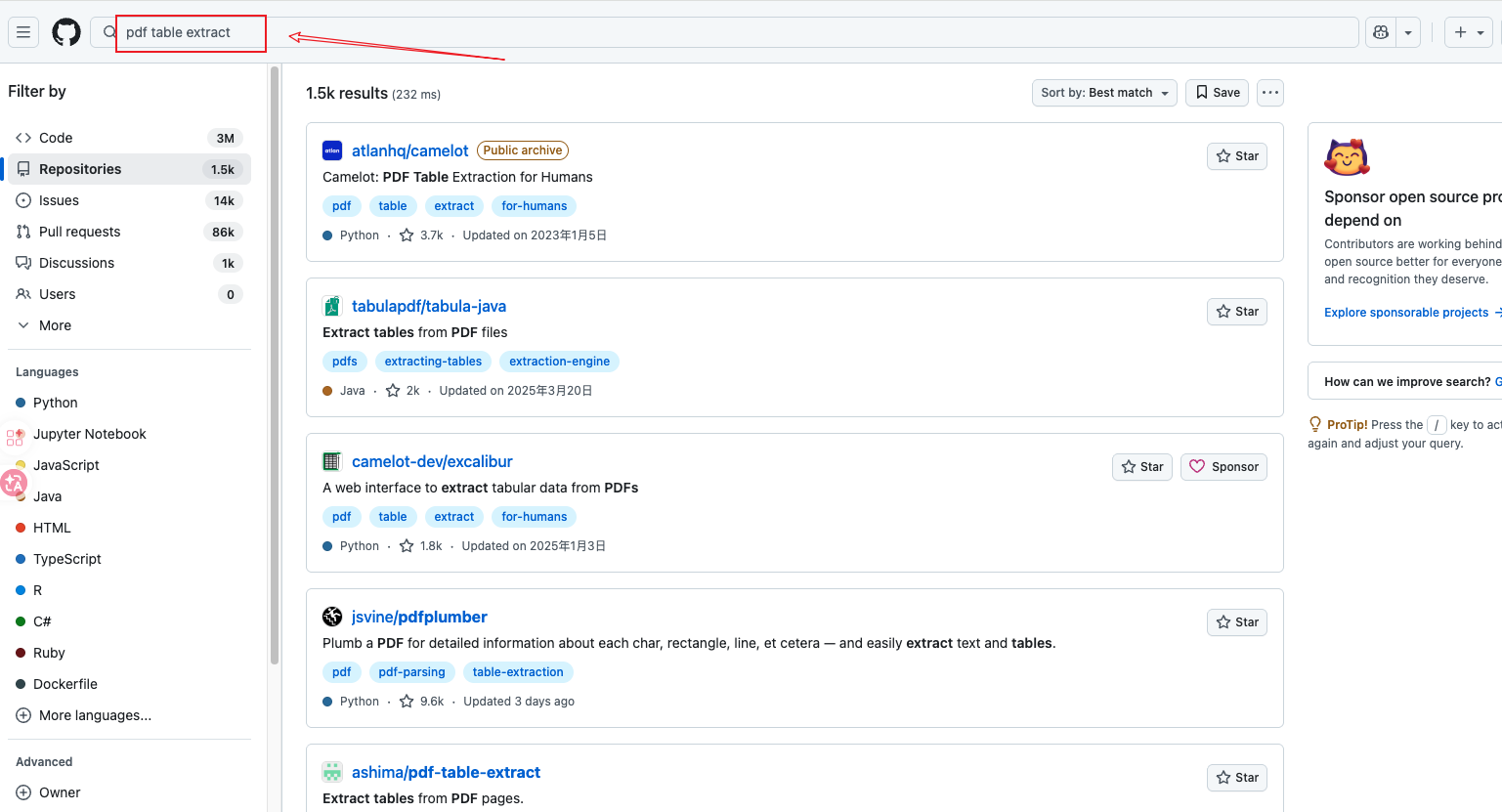
步骤一:初筛结果 1.5k,包含多种语言
❌ 结果杂乱无章,包含 Java、C# 以及大量废弃项目
步骤二(限定语言):
pdf table extract language:python
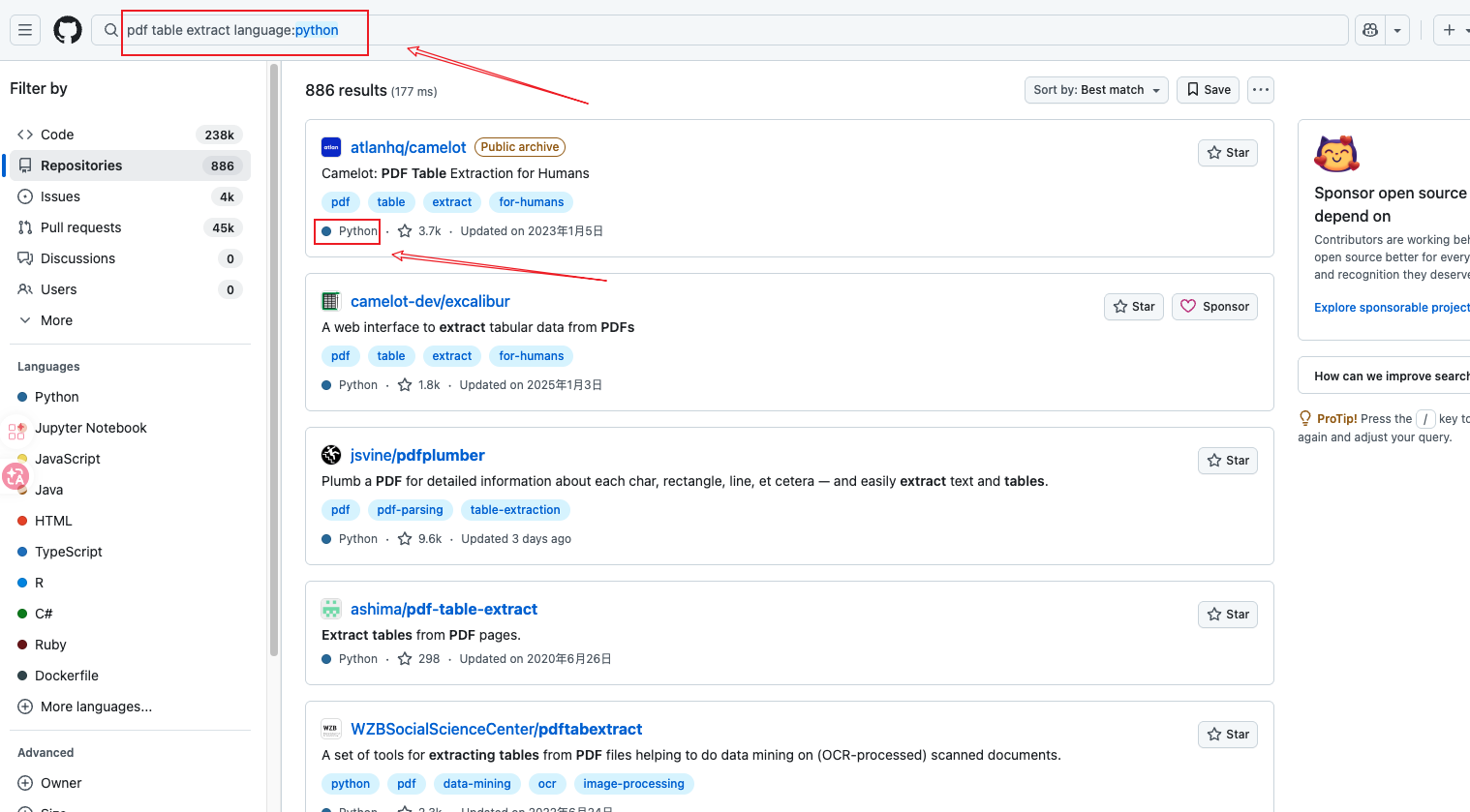
步骤二:添加语言过滤,结果缩小到 886
步骤三(活跃度清洗):
pdf table extract language:python pushed:>2025-01-01
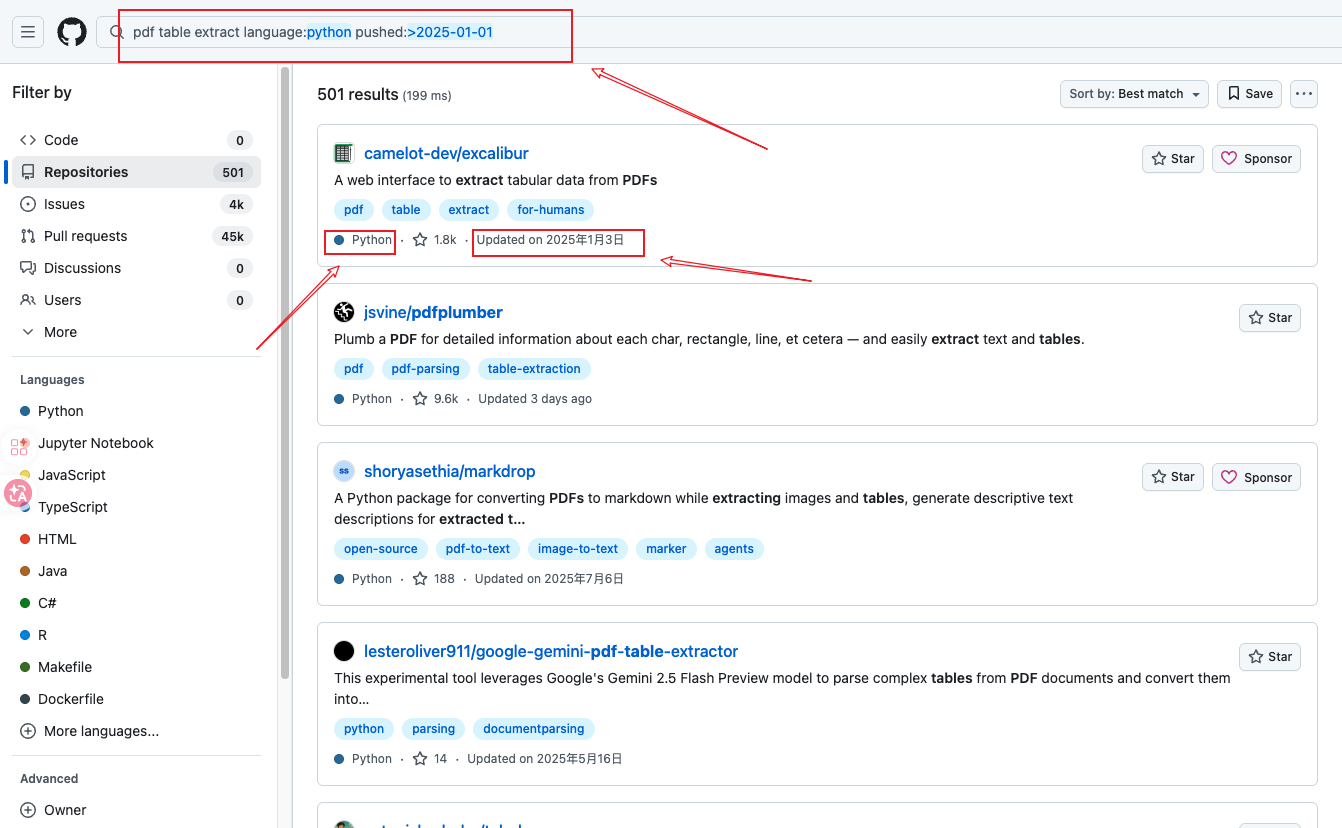
步骤三:添加时间过滤,结果缩小到 501
✅ 直接过滤掉所有在 2025 年前停止更新的库
步骤四(质量验证):
pdf table extract language:python pushed:>2025-01-01 stars:>200
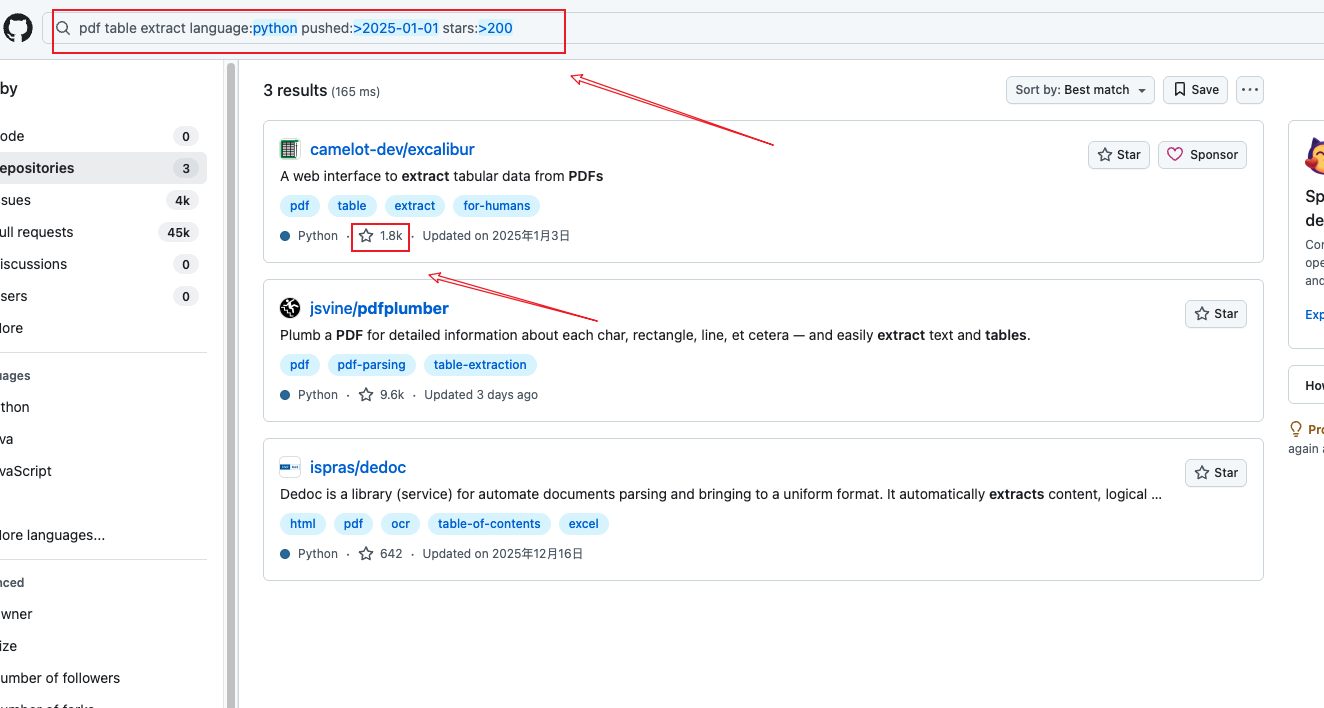
步骤四:添加星标过滤,仅剩 3 个高质量项目
✅ 缩小到 5-10 个高质量候选项目
步骤五(协议合规):如用于商业项目,追加 license:mit 或 license:apache-2.0
pdf table extract language:python pushed:>2025-01-01 stars:>200 license:mit
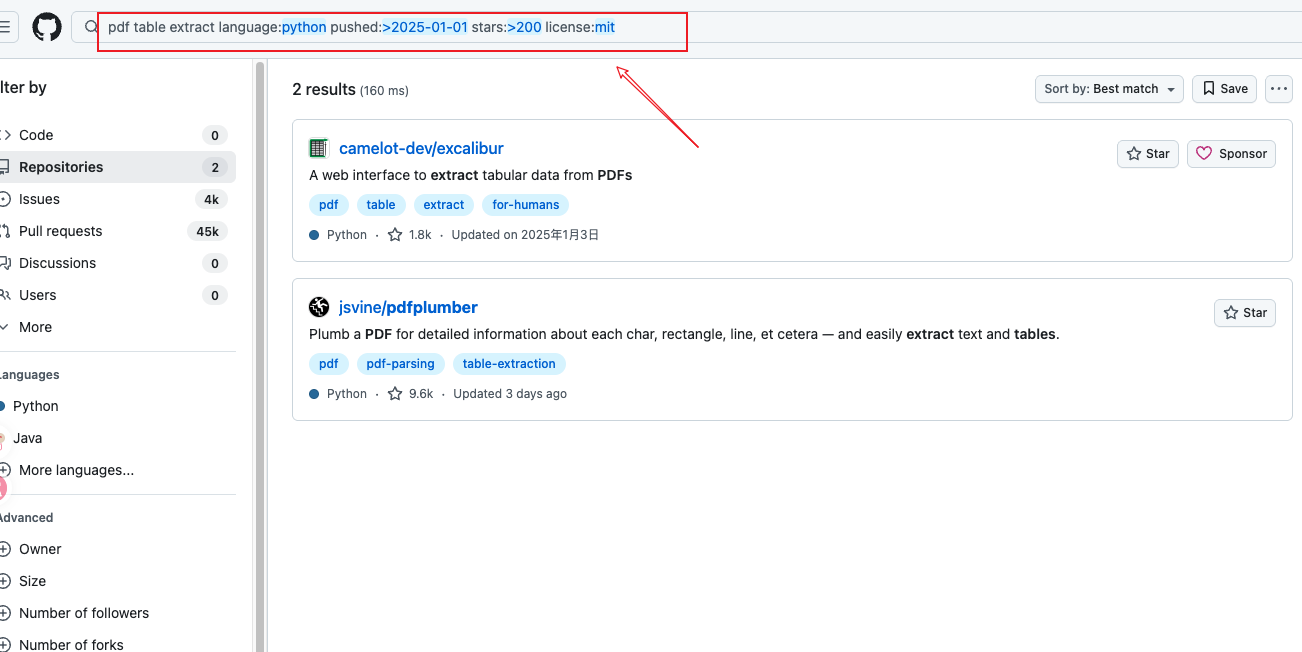
步骤五:添加协议过滤,仅剩 2 个符合 MIT 协议的项目
进入项目详情页后,可以在右侧边栏验证协议类型:
在项目详情页确认 MIT license 标识
💡 为什么要关注开源协议? 如果使用了 GPL 协议的代码,你的整个项目可能被要求开源!而 MIT 和 Apache 没有这个限制,所以商业项目优先选择这两种协议。
常用开源协议对比
| 协议 | 特点 | 商业使用 | 核心要求 |
|---|---|---|---|
| MIT | 最宽松,“随便用” | ✅ 允许 | 保留版权声明即可 |
| Apache 2.0 | 宽松 + 专利保护 | ✅ 允许 | 保留版权声明 + 注明修改内容 |
通过这五步漏斗式筛选,检索效率提升数个数量级!
2.5 什么时候需要去 GitHub? 链接到标题
既然 GitHub 不是用来下载模型的,那我们什么时候需要用到它呢?主要有以下几个常见场景:
场景一:寻找示例代码和教程
很多开源项目会在 GitHub 上提供:
如何使用某个模型的完整示例代码
如何搭建对话系统、RAG 系统的教程
别人已经写好的应用(如聊天机器人、翻译工具)
举例:你下载了 Llama-3 模型,但不知道怎么用。你可以去 GitHub 搜索"Llama-3 tutorial"或"Llama-3 chatbot",会找到很多开源项目,里面有完整的代码可以参考。
场景二:查看模型的官方仓库
很多模型的官方团队会在 GitHub 维护代码仓库,提供:
模型的训练代码(如果你想了解它是怎么训练出来的)
推理优化代码(如量化、加速)
Bug 修复和更新
场景三:下载开源的大模型应用
一些完整的大模型应用(如 ChatGLM-6B 的对话界面、LangChain 的 RAG 框架)会在 GitHub 开源。你可以直接克隆这些项目,稍作修改就能使用。
场景四:GitHub Models(可选了解)
GitHub 最近推出了一个叫"GitHub Models"的功能,可以让你在网页上直接调用一些大模型的 API。但这个功能目前还在测试阶段,且主要针对开发者,新手暂时不需要深入了解。
2.6 使用 Git 克隆 GitHub 项目 链接到标题
前面我们学会了用 CLI 下载模型(modelscope download 和 huggingface-cli download),现在来学习如何用 Git 克隆代码项目。
💡 重要提醒: Git 主要用于克隆代码项目,而不是下载模型。 下载模型请使用专门的 CLI 工具。
2.6.1 克隆 GitHub 代码项目(最常用) 链接到标题
克隆 GitHub 上的代码项目(如 LangChain、LlamaIndex)非常简单,不需要任何额外工具:
# 克隆开源项目
!git clone https://github.com/langchain-ai/langchain.git
# 进入项目目录
!cd langchain
# 安装依赖
!pip install -r requirements.txt
常见项目类型:
| 项目类型 | 示例 | 用途 |
|---|---|---|
| Agent\RAG 框架 | LangChain, LlamaIndex | 构建检索增强生成应用 |
| 模型推理工具 | vLLM, Ollama | 高效部署和推理 |
| 示例代码 | awesome-llm-projects | 学习参考 |
| 开源应用 | ChatGLM-WebUI | 直接使用的界面 |
重要提示:大多数开源项目不会把模型权重放在 GitHub 仓库里,而是:
- 在代码中动态下载:
# 项目代码会这样写
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')
- 在文档中告诉你手动下载:
## 使用前准备,请先下载模型:
!modelscope download --model 'Qwen/Qwen2.5-7B-Instruct'
2.6.2 完整工作流程示例 链接到标题
这是一个典型的项目启动流程:
场景:运行一个 LangChain 的 RAG 项目
# 步骤1:克隆项目代码
!git clone https://github.com/username/langchain-rag-demo.git
!cd langchain-rag-demo
# 步骤2:创建虚拟环境并安装依赖
!conda create -n rag_demo python=3.10
!conda activate rag_demo
!pip install -r requirements.txt
# 步骤3:下载所需模型(用CLI,不用Git!)
!modelscope download --model 'Qwen/Qwen2.5-7B-Instruct' \
--local_dir './models/Qwen2.5-7B'
# 步骤4:运行项目
!python app.py
核心理念:代码用 Git 克隆,模型用 CLI 下载
两种工具的职责分工
| 工具 | 用途 | 命令示例 |
|---|---|---|
| Git | 克隆代码项目 | git clone https://github.com/xxx/project.git |
| CLI | 下载模型权重 | modelscope download --model 'Qwen/Qwen2.5-7B' |
2.6.3 Git LFS 补充说明(可选了解) 链接到标题
⚠️ 重要声明:不推荐新手用 Git 克隆模型!
推荐方式:
- ✅ 下载模型 → 用 CLI(
modelscope download)- ✅ 克隆代码 → 用 Git(
git clone)只有在以下特殊情况才需要用 Git 克隆模型:
- 需要查看模型的版本历史
- 需要参与模型仓库的开发
- 特定工具要求必须用 Git
如果你确实有上述特殊需求,需要了解 Git LFS(Large File Storage)。
第三章:核心概念——权重、架构与文件结构 链接到标题
3.1 模型权重:你下载的到底是什么 链接到标题
在正式进入技术细节之前,我们需要先建立一个清晰的认知框架。很多初学者在学习大模型的过程中,会陷入一种"工具使用者"的状态:会用 ollama run 跑模型、会用 LM Studio 加载 GGUF 文件,但对于"模型内部到底是什么"一无所知。这种状态在日常玩耍时没问题,但一旦遇到实际问题——比如模型加载报错、显存不够、输出乱码——就会完全束手无策。
本章的目标,就是带你从"会用工具"升级到"理解原理"。这不是为了让你去写一个新的大模型框架,而是为了让你在遇到问题时,能够知道问题出在哪里、应该往哪个方向排查。这种能力,才是企业真正需要的"AI 工程师"与"会调 API 的人"之间的本质区别。
3.1.1 你下载的到底是什么? 链接到标题
让我们从一个最基本的问题开始:当你从 HuggingFace 或 ModelScope 下载一个"模型"时,你实际上下载的是什么?
答案是:模型 = 架构(Architecture)+ 权重(Weights)。这两者缺一不可,但它们的性质完全不同。
架构:静态的蓝图
模型架构是神经网络的结构定义,它由代码(通常是 Python 编写的 PyTorch 类)来描述。架构规定了数据流动的路径、网络有多少层、每层有多少个神经元、使用什么样的注意力机制等等。
用一个类比来理解:架构就像是一架钢琴的机械结构。它规定了有 88 个琴键,规定了按下琴键时琴槌会敲击琴弦,但这架钢琴本身发不出任何悦耳的旋律——因为它缺少"演奏者的技巧"。
权重:量化的经验
模型权重是填充在架构中的具体数值参数。这些数值是在海量数据的训练过程中,通过反向传播算法不断调整优化得来的。对于一个 70B(700 亿参数)的模型,就有约 700 亿个这样的浮点数。每一个数字代表了神经网络中某两个节点之间连接的"强度"。
继续用钢琴的类比:权重就是钢琴家经过多年练习形成的"肌肉记忆"。同样的钢琴(架构),由初学者和大师演奏,效果截然不同,区别就在于"怎么按键、力度多大"——这正是权重的作用。
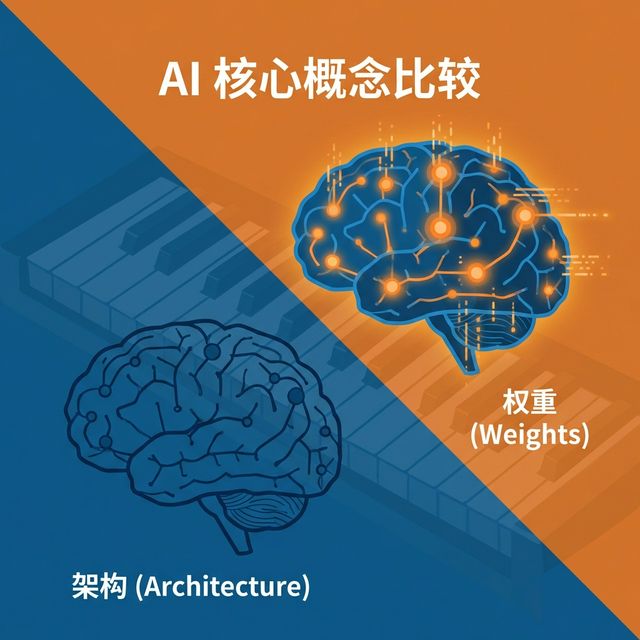
理解了这个二元关系,你就能明白为什么我们"下载"的主要是权重文件(那些巨大的 .safetensors 文件),而架构代码通常只有几 KB(.json 配置文件 + 库中预定义的类)。
3.1.2 权重是怎么"练"出来的? 链接到标题
为了让你更深刻地理解权重的珍贵性,我们需要简单了解一下权重的"诞生"过程。这不是要你去训练模型,而是让你明白:为什么权重文件这么值钱、为什么大厂愿意花几千万美元去训练一个模型。
训练的三个阶段
初始化(Initialization):训练开始前,权重是随机生成的数字(通常服从正态分布)。此时的模型就像一个刚出生的婴儿,大脑结构完整,但没有任何知识。你输入"你好",它可能输出"&sdf#",完全是乱码。
训练循环(Training Loop):模型开始阅读海量文本(Qwen3 使用了 36 万亿 token 的训练数据),尝试预测下一个字。每次预测错误,就计算误差并微调权重。
误差反向传播(Backpropagation):这是深度学习的核心算法。它根据预测值与真实值的差距,利用微积分的链式法则,计算出每一个权重应该调整多少。经过数万亿次的微调,原本随机的数字逐渐变成了能够理解语法、逻辑甚至幽默感的参数矩阵。
实战价值:理解训练过程后,你就能明白"微调(Fine-tuning)“的本质——它不是修改架构,而是保留大部分预训练权重不变,只对少部分权重进行针对性的再训练。这就像是让一位精通通识教育的大学生(预训练模型),去进修法律专业课程(微调),从而变成专业律师。
3.1.3 常见误区:模型文件大 ≠ 模型能力强 链接到标题
在建立正确认知的同时,我们也需要纠正一个非常普遍的误区:很多初学者认为"模型文件越大就越厉害”,这是错误的。
模型的能力主要由两个因素决定:
参数量(Parameter Count):模型有多少个可学习的参数
训练数据质量:模型"读过"多少高质量的文本
但模型文件的大小,还受到量化精度的影响。举个例子:
一个 7B 参数的 FP16 模型,文件大小约为 14GB
一个 70B 参数的 INT4 模型,文件大小约为 35GB
虽然后者文件更大,但 70B INT4 的能力远超 7B FP16——因为参数量相差 10 倍。所以,判断模型能力要看"参数量",而不是"文件大小"。文件大小只是"参数量 × 精度"的结果。
另一个有趣的类比:模型权重可以理解为"有损压缩的互联网"。Qwen3-8B 学习了 36 万亿 token 的数据,最后浓缩成 82 亿个参数。这也解释了为什么大模型会产生"幻觉"(Hallucination)——它不是在数据库中检索答案,而是在通过压缩的统计规律进行"重构"。
3.1.4 两种"用脑方式":Dense 模型与 MoE 模型 链接到标题
在前面的内容中,我们理解了"架构 + 权重"的基本关系,也知道了参数量决定模型能力。但这里有一个问题值得深思:明明 DeepSeek-V3 号称 671B 参数,为什么有人说它"实际上只相当于一个 37B 的模型"?这背后涉及到当前大模型领域最重要的两种架构范式——Dense(稠密)模型与 MoE(Mixture-of-Experts,混合专家)模型。
理解这两种架构的区别,对于后续的显存估算和部署决策至关重要。因为它们的"参数量"含义完全不同,直接影响你对硬件需求的判断。
Dense 模型:全员上阵的"全才"
我们前面讨论的 Qwen3-8B、Llama 3.1-70B 等模型,都属于 Dense(稠密)模型。它们的工作方式很直接:对于输入的每一个 token,模型中的所有参数都会参与计算。
用一个类比来理解:Dense 模型就像一个"全能型选手",无论遇到什么问题——写代码、翻译、聊天、做数学题——都要调动全身所有的"脑细胞"来处理。Llama 3.1-70B 有 700 亿参数,每次推理就要计算这 700 亿个参数,一个都不能少。
MoE 模型:按需出诊的"专家团"
MoE 模型则采用了一种完全不同的策略:它拥有海量的参数,但每次只激活其中一小部分来处理当前的输入。
继续用类比来理解:MoE 模型就像一个大型医院的"专家会诊中心"。医院里有几百位专科医生(专家),但每个病人来了之后,前台(门控网络)会根据症状只派 2-8 位最相关的专家去会诊,其余医生继续待命。这样既保证了诊断质量(因为总共有几百位专家的知识储备),又控制了每次会诊的成本(只有几位专家实际工作)。
以 DeepSeek-V3 为例:它的总参数量高达 671B,但每次推理只激活约 37B 参数。这意味着你用跑 37B 模型的算力,就能享受到 671B 模型的知识储备。
Dense 模型与 MoE 模型核心对比
| 特性 | Dense 模型 | MoE 模型 |
|---|---|---|
| 代表模型 | Qwen3-8B/32B、Llama 3.1-70B | DeepSeek-V3 (671B)、Qwen3-MoE |
| 工作方式 | 全员上阵:所有参数每次都参与计算 | 按需出诊:每次只激活一小部分专家 |
| 参数量关系 | 总参数 = 激活参数 | 总参数 » 激活参数 |
| 计算成本 | 与总参数量成正比,推理较慢 | 接近激活参数量的小模型,推理较快 |
| 显存需求 | 与总参数量成正比 | 必须加载全部参数,显存需求巨大 |
| 硬件瓶颈 | 主要受限于算力(FLOPs) | 主要受限于显存容量和显存带宽 |

MoE 的内部结构:门控网络与专家
MoE 并没有改变 Transformer 的整体架构,而是修改了其中的 FFN(前馈神经网络)层。传统 Transformer 中,每一层都有一个统一的 FFN 处理所有输入;而在 MoE 架构中,这个 FFN 被拆分成了多个独立的小 FFN,每一个就是一个"专家"。
MoE 的核心组件有两个:
门控网络(Router):这是 MoE 的"分诊台"。当一个 token 输入时,门控网络会计算它与各个专家的匹配度,然后选择分数最高的 Top-K 个专家(例如 Top-2 或 Top-8)。只有被选中的专家会进行计算,其他专家被跳过。
专家(Experts):每个专家本质上就是一个独立的小型 FFN。不同的专家在训练过程中会自然地习得不同的知识模式——有的擅长处理语法结构,有的擅长代码逻辑,有的擅长数学推理。
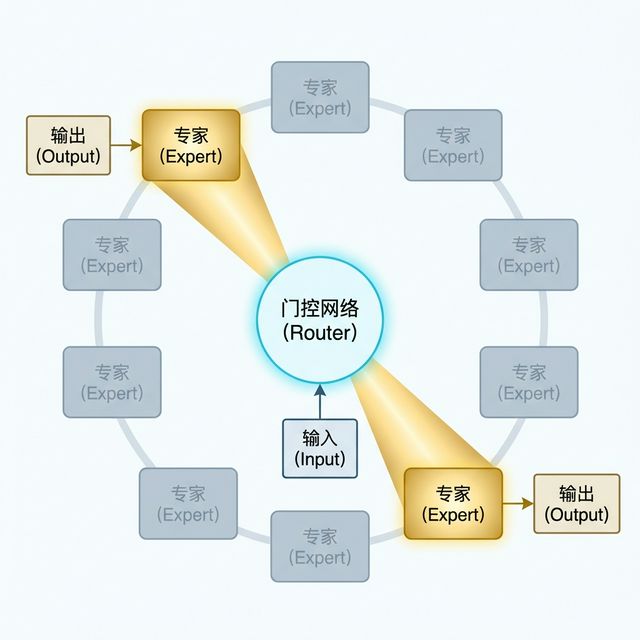
现代 MoE 的关键创新:共享专家
早期的 MoE 存在一个问题:每个专家可能会"偏科",导致一些通用的基础知识(如语法结构、常见表达)需要在每个专家里都学一遍,造成参数浪费。DeepSeek-V2/V3 和 Qwen-MoE 等新一代模型引入了一个关键创新——共享专家(Shared Experts)。
共享专家的设计思路很直观:
共享专家:无论输入是什么,永远被激活,负责处理通用知识(语法、常识等)
路由专家(Routed Experts):按需激活,负责处理专业知识(代码、数学、特定领域等)
这种"通才 + 专才"的组合,大大提高了参数的利用效率。你可以把它理解为:医院里既有全科医生(共享专家,每个病人都会先看),又有专科医生(路由专家,按需会诊)。
MoE 的部署悖论:算得快,但装不下
理解了 MoE 的工作原理后,我们就能看到它在部署时面临的核心矛盾:虽然每次计算只用到一小部分参数,但所有参数都必须加载到内存中等待被召唤。
以 DeepSeek-V3 为例:每次推理只激活 37B 参数,计算速度接近一个 37B 的 Dense 模型。但它的 671B 总参数在 FP16 下需要约 1.3TB 的存储空间——这些参数必须全部加载到内存或显存中,因为门控网络在每一层都可能选择不同的专家,你无法提前知道哪些专家会被用到。
这就引出了 MoE 模型本地部署的关键策略——Expert Offloading(专家卸载):
将共享专家和当前激活的路由专家放在 GPU 显存中(快速计算)
将大量休眠的路由专家放在 CPU 内存(RAM)中(等待被召唤)
这也是为什么 llama.cpp 和 ktransformers 这类框架对 MoE 模型如此重要——它们能够智能地在 CPU 和 GPU 之间调度专家权重。对于 MoE 模型的本地部署,你的内存(RAM)容量可能比显存(VRAM)更重要。
💡 实战价值:理解 Dense 与 MoE 的区别后,你在评估硬件需求时就不会犯一个常见错误——看到 DeepSeek-V3 “671B 参数"就认为完全不可能本地运行。实际上,借助量化 + Expert Offloading,一台 64GB 内存 + 24GB 显存的机器就有可能跑起来(虽然速度不快)。我们将在后续的推理框架课程中详细讲解这些部署技巧。
3.2 模型文件夹解剖学 链接到标题
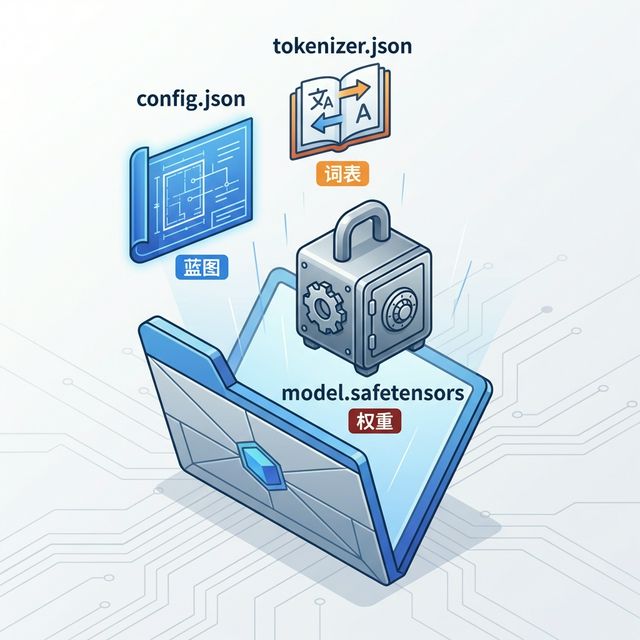
在上一节中,我们从宏观角度理解了"架构"与"权重"的关系。现在,让我们进入更具体的层面:当你从 HuggingFace 或 ModelScope 下载一个模型后,文件夹里那一堆文件分别是什么?各自起什么作用?
很多初学者下载完模型后,看着文件夹里的 config.json、tokenizer.json、model.safetensors 等文件一脸茫然,甚至担心"是不是下载不全了”。本节的目标就是赋予你"透视"模型文件夹的能力——不仅知道每个文件是什么,还知道它们如何协作、哪些是必需的、哪些是可选的。
3.2.1 核心文件一览 链接到标题
一个标准的 Transformer 模型文件夹(以 Qwen/Qwen3-8B 为例)通常包含以下文件:
模型文件夹核心文件说明
| 文件名 | 作用 | 是否必需 | 说明 |
|---|---|---|---|
config.json | 模型架构配置 | ✅ 必需 | 定义层数、隐藏维度、注意力头数等 |
tokenizer.json | 词表映射 | ✅ 必需 | 将文字转换为数字 ID |
tokenizer_config.json | 分词器配置 | ✅ 必需 | 分词规则、特殊 token 定义 |
*.safetensors | 模型权重 | ✅ 必需 | 存储所有参数(体积最大) |
generation_config.json | 生成参数 | 可选 | 默认的 temperature、top_p 等 |
special_tokens_map.json | 特殊 token 映射 | 可选 | PAD、EOS、BOS 等特殊标记 |
README.md | 模型说明 | 可选 | 使用方法、性能指标等 |
接下来,我们逐个深入解析这些核心文件的作用和内部结构。
3.2.2 config.json:模型的"蓝图" 链接到标题
config.json 是模型加载时的入口文件,它定义了模型的"物理规格"。当 Transformers 库执行 from_pretrained() 时,第一件事就是读取这个文件,根据其中的配置来构建模型骨架。
关键字段解读
{
"architectures": ["Qwen3ForCausalLM"],
"hidden_size": 4096,
"num_hidden_layers": 32,
"num_attention_heads": 32,
"vocab_size": 151936,
"max_position_embeddings": 32768
}
让我们逐个理解这些字段的含义:
architectures:指定模型类型,告诉加载库应该调用哪个 Python 类来构建模型骨架hidden_size:隐藏层维度,决定模型的"宽度"num_hidden_layers:层数,决定模型的"深度"num_attention_heads:注意力头数量,多头注意力机制的核心参数vocab_size:词表大小,决定模型能"认识"多少个不同的 tokenmax_position_embeddings:最大位置编码,决定模型能处理多长的上下文
实战技巧:如果你想确认下载的模型是否完整(比如层数对不对),或者想手动修改某些配置(如调整上下文窗口限制),第一件事就是查看
config.json。
3.2.3 tokenizer:模型的"翻译官" 链接到标题
tokenizer.json 和 tokenizer_config.json 是初学者最容易忽视,却最容易导致问题的部分。计算机不认识"你好"这两个汉字,它只认识数字。Tokenizer(分词器)的作用就是在"人类语言"和"模型语言"之间架起桥梁。
Tokenizer 的工作流程
用户输入:"今天天气真好"
↓ tokenizer.encode()
Token IDs:[1234, 567, 890, 234, 567]
↓ 送入模型
模型输出:[2345, 678, ...]
↓ tokenizer.decode()
生成文本:"是的,阳光明媚..."
核心文件说明
tokenizer.json:存储了数万个词汇到 ID 的映射表(Vocabulary)。Qwen3 的词表大小约为 15 万,这意味着它能"认识" 15 万种不同的 token。tokenizer_config.json:定义了分词的规则(如是否在句首加空格)以及特殊 Token 的配置(如<|end_of_text|>用于标记生成的结束)。
⚠️ 常见事故:混用 Tokenizer 是新手最容易犯的错误之一。比如用旧版 Qwen2.5 的分词器去加载 Qwen3 的模型,虽然代码可能不报错,但因为两个模型的词表不同,同一个 ID 在不同版本中可能代表完全不同的 token,导致模型输出乱码或逻辑崩坏。解决方案:始终确保 Tokenizer 和 Model 来自同一个文件夹。
3.2.4 safetensors vs bin:安全性的演进 链接到标题
.safetensors 和 .bin(或 pytorch_model.bin)都是存储模型权重的格式,但它们有本质的区别。现代模型几乎都使用 .safetensors 格式,这是有充分理由的。
格式演进史
权重文件格式对比
| 特性 | .bin (pickle) | .safetensors |
|---|---|---|
| 安全性 | ⚠️ 危险 | ✅ 安全 |
| 加载速度 | 较慢 | 快 2-3 倍 |
| 内存映射 | 不支持 | ✅ 支持 (mmap) |
| 可执行代码 | 可包含 | 不包含 |
| 推荐程度 | ❌ 不推荐 | ✅ 强烈推荐 |
为什么 .bin 格式危险?
.bin 文件基于 Python 的 pickle 序列化模块。pickle 的一个"特性"是:它允许在反序列化(加载文件)时执行任意 Python 代码。这意味着,黑客可以在 .bin 文件中植入恶意脚本,当你加载模型时,电脑就可能被控制。
为什么 .safetensors 更好?
.safetensors 是由 Hugging Face 推出的新标准,它是纯二进制格式,只存储张量数据,不包含任何可执行代码,从根本上杜绝了安全风险。此外,它还支持内存映射(Memory Mapping),可以直接将文件从硬盘映射到内存,大大缩短加载时间。
实战建议:在下载模型时,优先选择
.safetensors格式的版本。如果只有.bin格式可用,要确保来源可信(官方仓库或知名发布者)。
3.2.5 大模型的分片机制 链接到标题
如果你下载过 70B 级别的大模型,你会发现权重文件不是一个,而是被分成了多个文件,比如:
model-00001-of-00004.safetensors
model-00002-of-00004.safetensors
model-00003-of-00004.safetensors
model-00004-of-00004.safetensors
model.safetensors.index.json
为什么要分片?
文件系统限制:某些文件系统(如 FAT32)对单文件大小有 4GB 限制
并行下载:分片后可以多线程同时下载,加快速度
断点续传:下载中断后只需重新下载失败的分片
index.json 的作用
model.safetensors.index.json 是分片的"目录",它记录了每一层权重存储在哪个文件中。加载库会先读取这个索引文件,然后按需加载对应的分片。
避坑提醒:下载大模型时,一定要确保所有分片都下载完整。如果缺少某个分片,模型加载会直接报错。使用
huggingface-cli download或snapshot_download()可以自动处理分片下载和完整性校验。
3.2.6 generation_config.json:模型的"性格" 链接到标题
generation_config.json 是一个可选但重要的文件,它定义了模型生成文本时的默认行为。
{
"temperature": 0.7,
"top_p": 0.8,
"max_new_tokens": 512,
"do_sample": true,
"eos_token_id": 151643
}
关键参数解读
temperature:控制随机性,值越高输出越发散,值越低输出越确定top_p:核采样阈值,只从累积概率达到 p 的 token 中采样max_new_tokens:最大生成长度eos_token_id:结束符 ID,模型生成到这个 token 就停止
🔥 踩坑预警:很多小白抱怨模型"车轱辘话"或者"停不下来",往往是因为
generation_config.json中的eos_token_id设置错误,或者与 Tokenizer 中的定义不一致,导致模型不知道何时该停止生成。解决方案:确保eos_token_id与tokenizer_config.json中的定义一致。
3.3 显存估算速算法 链接到标题
学会计算显存需求,是"下载党"进阶为"架构师"的分水岭。在实际工作中,你经常会遇到这样的问题:
“老板想在公司服务器上跑 Qwen3-14B,我们的 RTX 4090 够不够?”
“我在 AutoDL 上租 GPU,应该选 24GB 的 4090 还是 40GB 的 A100?”
“这个模型说支持 128K 上下文,但为什么我聊几轮就显存爆了?”
本节将教你一套实用的显存估算方法,让你在动手之前就能做出准确判断。
💡 官方工具推荐:阿里云 PAI 平台提供了简易显存估算器,可以在线计算模型推理和微调所需的显存。支持 Dense 模型和 MoE 模型,覆盖 16-bit/8-bit/4-bit 等多种精度场景。
工具地址:https://help.aliyun.com/zh/pai/getting-started/estimation-of-the-required-video-memory-for-the-model
3.3.1 静态显存:模型权重的硬性门槛 链接到标题
静态显存是指模型权重本身占用的显存,这是一个固定值,由模型参数量和量化精度决定。
通用估算公式
$$\text{静态显存 (GB)} \approx \frac{\text{参数量 (B)} \times \text{每参数比特数}}{8}$$
让我们用这个公式计算几个常见模型的显存需求:
Dense 模型静态显存估算示例(FP16 精度)
| 模型 | 参数量 | 计算过程 | FP16 显存需求 |
|---|---|---|---|
| Qwen3-8B | 8B | 8 × 2 字节 | ~16GB |
| Qwen3-14B | 14B | 14 × 2 字节 | ~28GB |
| Qwen3-32B | 32B | 32 × 2 字节 | ~64GB |
对于 Dense 模型,这个公式非常直观——参数量乘以每个参数的字节数就是显存需求。但对于 MoE 模型,情况要复杂得多,我们在下面单独讨论。
💡 关于量化:如果你的显存不够运行 FP16 模型,可以使用量化技术(如 INT4)来大幅减少显存需求。我们将在 第七章:量化技术入门 中详细讲解量化原理和实战方法。
修正系数:实际显存占用通常要在公式结果上增加 1-2 GB,用于 CUDA 内核开销、显存碎片和临时缓冲区。
MoE 模型的显存陷阱:用总参数量计算,而非激活参数量
在第 1 章中我们讲过,MoE 模型的"总参数量"和"激活参数量"是两个完全不同的数字。在估算显存时,必须使用总参数量,因为所有专家的权重都必须加载到内存中。这是新手最容易犯的错误之一。
以 DeepSeek-V3 为例,我们来看这个差异有多大:
MoE 模型显存估算的常见误区
| 模型 | 总参数量 | 激活参数量 | ❌ 按激活参数算 (FP16) | ✅ 按总参数算 (FP16) |
|---|---|---|---|---|
| DeepSeek-V3 | 671B | 37B | ~74 GB | ~1342 GB (1.3TB) |
| Qwen3-235B-A22B | 235B | 22B | ~44 GB | ~470 GB |
从表格可以看出,如果错误地用激活参数量来估算,你会以为 DeepSeek-V3 只需要 74GB 显存,实际上它需要 1.3TB——差了将近 20 倍。这也解释了为什么 MoE 模型的本地部署通常需要借助 CPU 内存(RAM)来存放大量休眠的专家权重,而不是把所有参数都塞进 GPU 显存。
⚠️ 常见误区:看到 DeepSeek-V3 “激活参数 37B"就以为它和 Qwen3-32B 的显存需求差不多。实际上,DeepSeek-V3 的总参数量是 671B,即使使用 INT4 量化也需要约 230GB 的存储空间。MoE 模型的显存/内存需求,永远由总参数量决定。
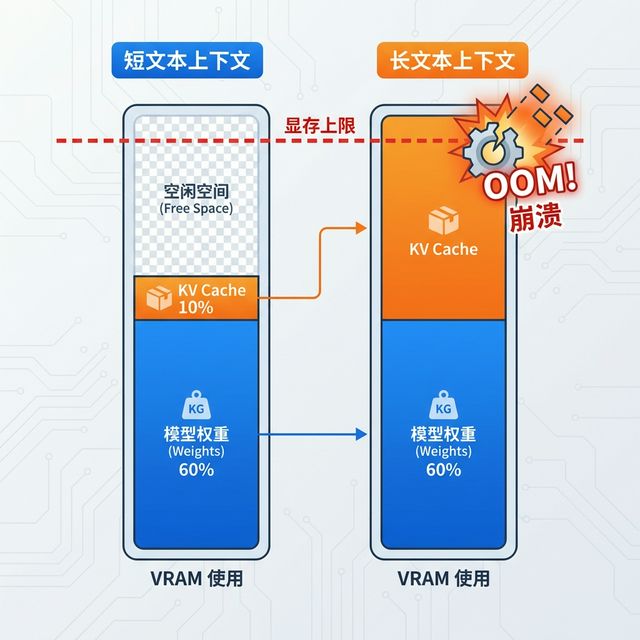
3.3.2 动态显存:KV Cache 的隐藏陷阱 链接到标题
很多初学者发现:模型加载进去了,显存还剩好几 GB,但刚聊了几轮就报错 OOM(显存溢出)。罪魁祸首就是 KV Cache。
什么是 KV Cache?
模型在生成第 N 个 token 时,需要"回头看"前 N-1 个 token 的信息。为了不重复计算,模型会把之前所有 token 的 Key 和 Value 向量缓存起来,这就是 KV Cache。
KV Cache 的增长规律
KV Cache 的大小与上下文长度成线性正比。对话越长,缓存越大,显存占用越多。
估算公式(以 FP16 为例)
$$\text{KV Cache (GB)} \approx \frac{2 \times \text{层数} \times \text{隐藏维度} \times 2 \times \text{上下文长度}}{1024^3}$$
实战数据(以 Llama 4 Scout 70B 为例,FP16)
每 1000 个 token 的 KV Cache 约占用 640 MB
如果想跑满 128K 上下文:128 × 0.64 GB ≈ 82 GB 仅用于 KV Cache!
这意味着:即便你有两张 RTX 4090(48GB 总显存),虽然能加载 35GB 的 INT4 权重,但剩下的 13GB 只够支撑约 20K token 的上下文,根本跑不满 128K。
🔥 避坑指南:不要被模型宣传的"支持 128K 上下文"所迷惑。实际能用多长的上下文,取决于你的显存余量。公式:可用上下文长度 ≈ (总显存 - 模型显存) / 每 1K token 的 KV Cache 大小
3.3.3 2026 主流模型显存速查表 链接到标题
为了方便你快速查阅,这里整理了 2026 年初主流模型的显存需求和推荐硬件配置:
2026年主流模型显存速查表(FP16 精度)
| 模型名称 | 架构类型 | 总参数量 | 激活参数量 | FP16 显存 | 推荐配置 |
|---|---|---|---|---|---|
| Qwen3-1.7B | Dense | 1.7B | 1.7B | ~3.5 GB | RTX 3060 (12G) |
| Qwen3-8B | Dense | 8B | 8B | ~16 GB | RTX 4060Ti (16G) |
| Qwen3-14B | Dense | 14B | 14B | ~28 GB | A100 40GB |
| Qwen3-32B | Dense | 32B | 32B | ~64 GB | 2× A100 40GB |
| Qwen3-235B-A22B | MoE | 235B | 22B | ~470 GB | 需 CPU+GPU 混合推理 |
| DeepSeek-V3 | MoE | 671B | 37B | ~1342 GB | 需 CPU+GPU 混合推理 |
从这张表中可以清晰地看到 Dense 和 MoE 两种架构在显存需求上的巨大差异。Dense 模型的总参数量和激活参数量相同,显存估算直接套公式即可;而 MoE 模型的总参数量远大于激活参数量,显存必须按总参数量计算,这也是为什么 MoE 模型几乎都需要借助 CPU 内存进行混合推理。
⚠️ 显存不够? 上表是 FP16 原始精度的显存需求。如果你的显卡显存不足,可以通过量化技术(INT4/INT8)将显存需求降低 2-4 倍。详见 Lesson 4。对于 MoE 模型,还可以通过 Expert Offloading 将休眠专家放到 CPU 内存中,详见后续推理框架课程。
📅 时效性说明:以上数据基于 2026 年 2 月的最新模型版本,测试环境为 PyTorch 2.8.0 + CUDA 12.8。模型更新可能导致参数量变化,请以官方发布为准。
3.3.4 显存不够怎么办? 链接到标题
如果你的显卡显存不足以运行目标模型的 FP16 版本,有以下几种解决方案:
显存不足的解决方案
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 使用量化模型 | 显存差 2-4 倍 | 效果接近原版 | 需要学习量化知识 |
| 选择更小的模型 | 显存差很多 | 最简单直接 | 能力上限降低 |
| 租用云 GPU | 临时需求 | 按需付费 | 长期成本高 |
| 升级硬件 | 长期需求 | 一劳永逸 | 前期投入大 |
💡 推荐路径:对于显存不足的情况,最推荐的方案是使用量化模型。INT4 量化可以将显存需求降低到原来的 1/4,效果损失通常在 5% 以内。我们将在 Lesson 4 中详细讲解量化技术。
第四章:代码实战——使用 Transformers 加载模型 链接到标题
过渡:在上一章我们解剖了模型文件夹,知道了 config.json 和 safetensors 的作用。现在,让我们用 Python 代码把这些文件真正"用"起来。我们将使用 Hugging Face 的 transformers 库,这是目前最主流的大模型调用工具。
4.1 环境准备 链接到标题
在开始写代码之前,我们需要安装必要的 Python 库。
# 安装 Hugging Face 核心库
!pip install transformers
# 安装 PyTorch (根据你的 CUDA 版本选择,这里以 CUDA 12.1 为例)
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 安装加速库(可选但推荐)
!pip install accelerate
4.2 核心代码:加载模型与分词器 链接到标题
加载一个模型只需要两行核心代码:一行加载分词器(Tokenizer),一行加载模型(Model)。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 1. 设定模型路径(可以是 HuggingFace 上的 ID,也可以是本地路径)
model_path = "./models/Qwen/Qwen2.5-7B-Instruct" # 如果下载到了本地,替换为本地文件夹路径
# 2. 加载分词器
# trust_remote_code=True 允许加载模型自定义的代码,对于新模型通常需要开启
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 3. 加载模型
# device_map="auto" 会自动将模型分配到 GPU(如果显存不够会分到 CPU)
# torch_dtype="auto" 会自动选择精度(通常是 FP16 或 BF16)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype="auto",
trust_remote_code=True
)
print(f"模型加载成功!运行在设备:{model.device}")
4.3 第一次推理:让模型说话 链接到标题
模型加载后,我们就可以让它生成文本了。
# 1. 准备输入文本
prompt = "你好,请用一句话介绍你自己。"
messages = [
{"role": "system", "content": "你是一个有用的 AI 助手。"},
{"role": "user", "content": prompt}
]
# 2. 应用对话模板(将对话列表转换为模型能看懂的字符串格式)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 3. 将文本转换为 Token ID(张量)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 4. 生成新 Token
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512, # 最多生成 512 个 token
temperature=0.7 # 控制随机性
)
# 5. 只取新生成的 token(去掉输入的 prompt 部分)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 6. 解码:将 Token ID 转回文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("模型回答:", response)
如果你能跑通这段代码,恭喜你!你已经掌握了大模型调用的核心逻辑。
过渡:在本地电脑上跑通了简单的代码后,你可能会发现一个尴尬的问题:显存不够用,或者跑大模型太慢。这时候,租用云端 GPU 服务器(如 AutoDL)就是最高性价比的选择。这一章我们将手把手教你在云端获取算力。
第五章:云端部署——AutoDL 算力租赁指南 链接到标题
本部分将帮助你快速上手AutoDL云GPU平台,完成从注册到成功连接服务器的全流程。这是后续所有实战部署的基础设施准备。
5.1 平台认知:为什么选择 AutoDL? 链接到标题
在动手之前,我们需要先理解一个关键问题:市面上的云GPU平台这么多,为什么我们要选择 AutoDL? 这一章将从算力民主化的背景切入,帮助我们建立对 AutoDL 准确的认知与预期。
5.1.1 算力民主化的背景 链接到标题
在深度学习和大模型时代,算力资源呈现出明显的"两极分化"现象:
低端免费层:以 Kaggle Kernels、Google Colab 为代表。虽然免费,但存在运行时长限制(通常几小时)、闲置自动断开、环境频繁重置等问题。更关键的是,这类平台的高度封装剥夺了学习者接触底层 Linux 环境的机会。
高端企业层:以 AWS、阿里云、Azure 为代表。提供无限扩展性和SLA保障,但计费模型昂贵、网络配置复杂(VPC、安全组、弹性IP),对于仅需跑通一个模型的学生而言,学习曲线过于陡峭。
AutoDL 的出现填补了这一"中间地带”:它将高性能计算的边际成本压低至学生可承受的范围(每小时几元人民币),同时保留了接近裸机级别的控制权限。
5.1.2 AutoDL 的核心定位 链接到标题
AutoDL 的价值主张可以概括为三个关键词:弹性、好用、省钱。
AutoDL 核心优势对比
| 维度 | AutoDL | Kaggle/Colab | AWS/阿里云 |
|---|---|---|---|
| 价格 | ¥2-5/小时 | 免费(有限制) | ¥10-50+/小时 |
| 算力等级 | RTX 3090/4090/V100 | T4/P100(较旧) | 全系列可选 |
| 使用门槛 | 低(开机即用) | 极低(浏览器) | 高(需配置网络、权限) |
| 环境控制 | 完全控制(root权限) | 受限(沙盒环境) | 完全控制 |
| 运行时长 | 无限制 | 几小时 | 无限制 |
| 国内访问 | 流畅(内置加速) | 需梯子 | 部分区域流畅 |
从表格可以看出,AutoDL 在性价比和易用性之间取得了出色的平衡。特别是对于国内用户,平台内置的学术资源加速(GitHub、HuggingFace)解决了最让人头疼的网络问题。
5.1.3 适用场景与局限性 链接到标题

了解一个工具的边界,和了解它的优势同样重要。
AutoDL 最适合的场景:
高校课程实验与毕业设计
数据科学竞赛(Kaggle、天池)
大模型微调(LoRA/QLoRA)与 AIGC 探索
学习 Linux 环境和云原生开发模式
需要注意的局限性:
数据持久化风险:系统盘是易失的,重要数据必须存储在数据盘或及时备份
共享资源竞争:晚高峰时段可能出现 SSH 连接卡顿
消费级显卡局限:缺乏 ECC 内存纠错,超长时间训练(数周)可能遇到稳定性问题
5.2 快速上手:注册与登录 链接到标题
理解了 AutoDL 的定位后,我们正式开始动手实操。本章将完成平台的注册与登录,这是使用一切云服务的起点。
5.2.1 访问官网与注册流程 链接到标题
访问 AutoDL 官网 https://www.autodl.com,我们会看到如下登录/注册界面:
AutoDL 支持多种注册方式:手机号注册、微信扫码登录等。对于新用户,建议使用手机号注册,流程简单直接。
步骤一:进入注册页面
点击页面右侧的"注册"按钮,填写手机号并获取验证码,设置密码后即可完成注册。
步骤二:完成实名认证(可选但推荐)
实名认证后可以获得更高的资源配额。学生用户完成认证后还可以直接升级为"炼丹会员",享受额外优惠。
5.2.2 学生认证与会员体系 链接到标题
AutoDL 针对教育场景提供了特别的优惠体系:
学生认证:上传学生证或教育邮箱验证,通过后自动升级为会员
炼丹会员:享受更低的计费价格和优先资源调度
提示:即使不是学生,普通用户也可以通过充值等方式升级会员等级。
5.3 算力选购:创建你的第一个实例 链接到标题
完成注册登录后,我们来到了最核心的环节——选购算力并创建实例。这一章将详细讲解如何在算力市场中做出明智的选择。
5.3.1 算力市场概览 链接到标题
登录后,点击顶部导航栏的"算力市场",进入资源选购页面:
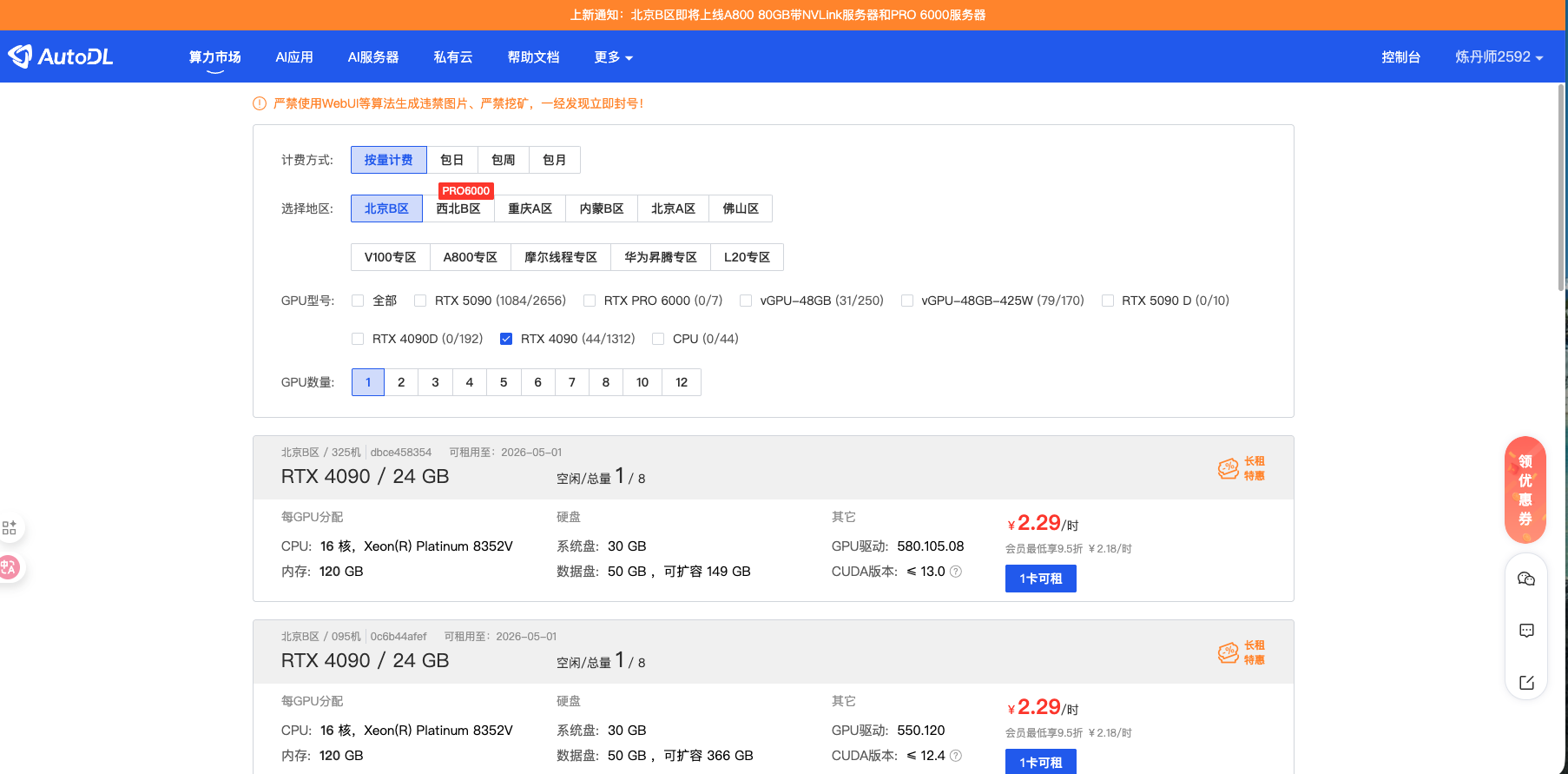
算力市场页面展示了当前可用的所有 GPU 实例类型,包括:
GPU 型号与显存容量
可用数量与空闲状态
每小时计费价格
所在地区(不同地区网络延迟略有差异)
5.3.2 GPU 型号选择指南 链接到标题
面对琳琅满目的 GPU 选项,如何选择?我们需要根据任务需求和预算来做决策。
常见 GPU 型号与适用场景
| GPU型号 | 显存 | 适用场景 | 价格区间(会员价) |
|---|---|---|---|
| RTX 4090D | 24GB | 内存密集型任务、大批量推理 | ¥1.98/时(¥1.88) |
| RTX 4090 | 24GB | 大模型微调、13B模型推理、SDXL | ¥2.29/时(¥2.18) |
| V100 | 32GB | 科研训练、中型模型微调 | ¥1.98/时(¥1.88) |
| RTX 5090 | 32GB | 最新架构、大模型推理与训练 | ¥3.03/时(¥2.39) |
| A800 80GB | 80GB | 超大模型全量微调、70B+推理 | ¥5.24/时(¥4.98) |
对于本次课程的目标(部署 Ollama 和 vLLM 运行大模型),RTX 4090(24GB显存) 是性价比较高的选择——它不仅速度快,还支持 FP8 精度,是当前的"性价比之王"。
5.3.3 计费模式深度解析 链接到标题
AutoDL 提供灵活的计费模式,理解这些模式可以帮助我们优化成本。
计费模式对比
| 计费模式 | 特点 | 适用场景 |
|---|---|---|
| 按量计费 | 精确到分钟,用多少付多少 | 碎片化学习、短期实验 |
| 包日/包周 | 固定费用,不限使用时长 | 连续多天的项目开发 |
| 包月 | 长期租赁,单价最低 | 科研项目、长期训练 |
重要提示:关机后 GPU 停止计费,但数据盘会产生少量存储费用(通常每天几毛钱)。实验结束后记得关机!
5.3.4 实例创建实战步骤 链接到标题
现在我们来实际创建一个 GPU 实例。这是整个流程中最关键的操作环节。
步骤一:选择 GPU 型号与数量
在算力市场中,点击目标 GPU 型号(如 RTX 4090)旁边的"创建实例“按钮:
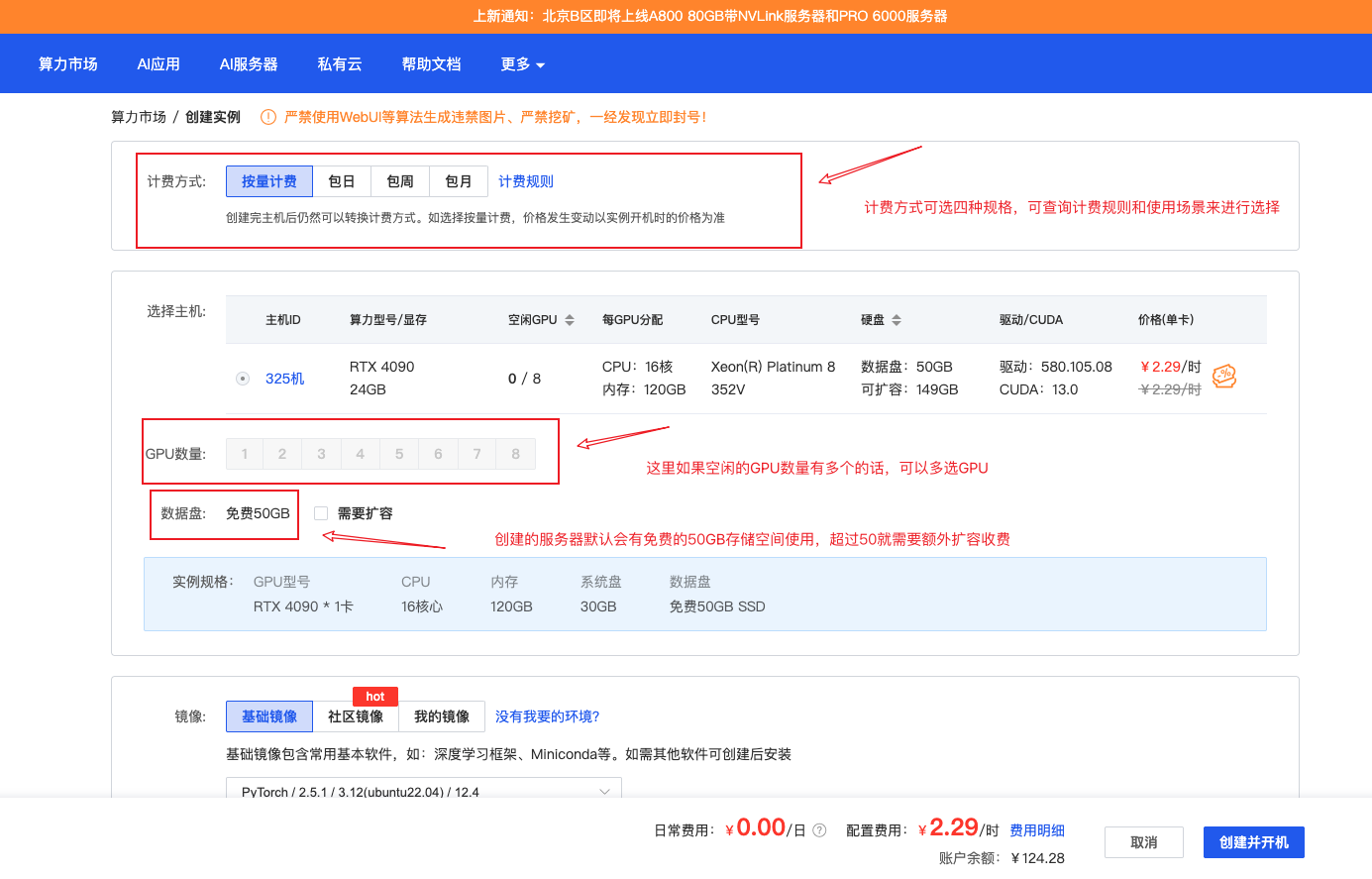
进入创建页面后,我们需要关注以下几个关键参数:
GPU数量:对于入门学习,1卡足够
计费方式:建议新手选择"按量计费”
数据盘:默认免费50GB,一般足够使用
步骤二:选择基础镜像
这是创建实例时最重要的决策之一。镜像决定了服务器预装的环境。
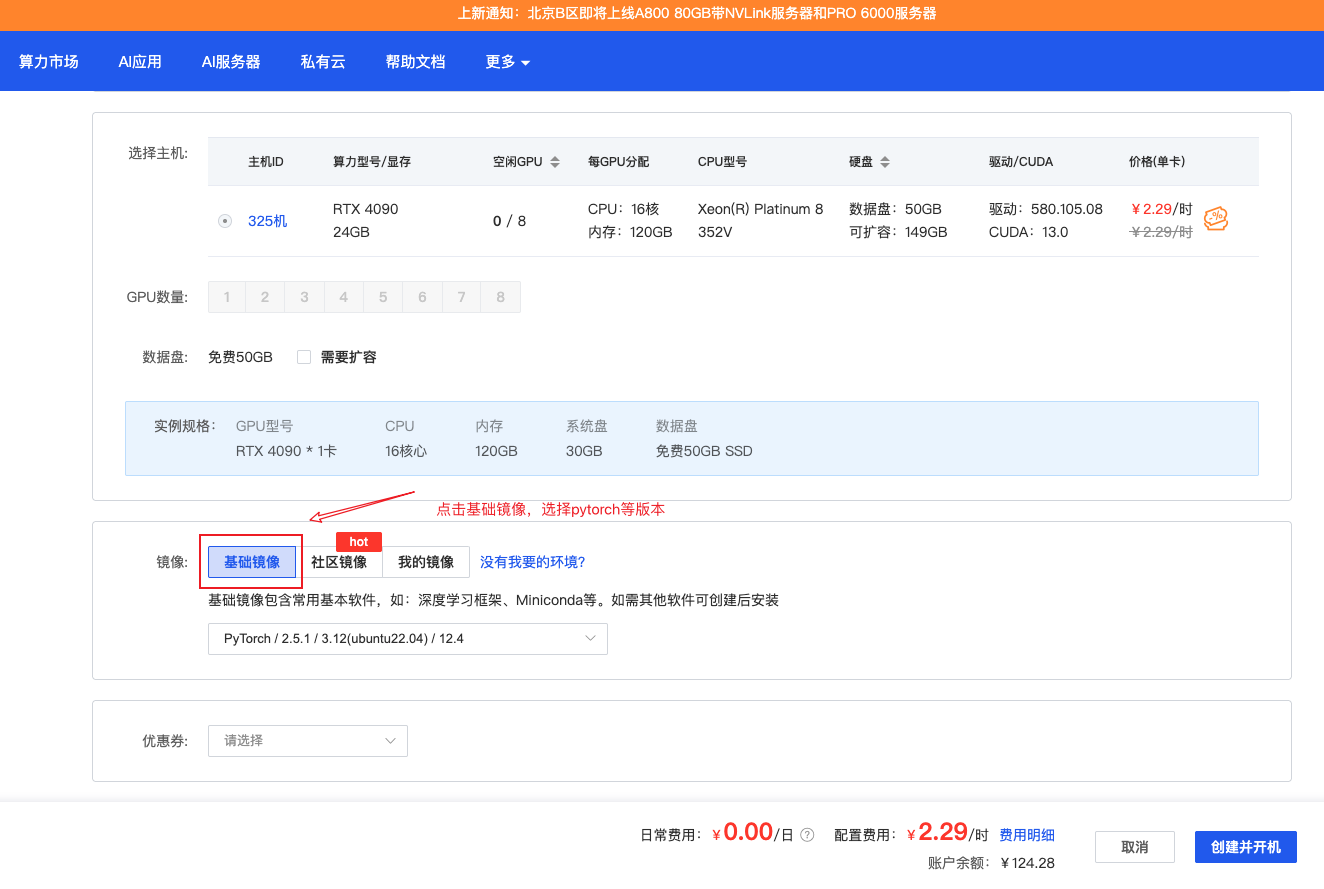
AutoDL 提供了丰富的基础镜像选项:
PyTorch:广泛使用的深度学习框架,推荐选择 2.x 版本
TensorFlow:另一主流框架
Miniconda:纯净的 Python 环境,自行安装依赖
对于本次 Ollama 和 vLLM 部署实战,我们选择 PyTorch 2.x + CUDA 12.x 的镜像组合。
步骤三:确认配置并开机
确认所有配置无误后,点击页面底部的"创建并开机“按钮:
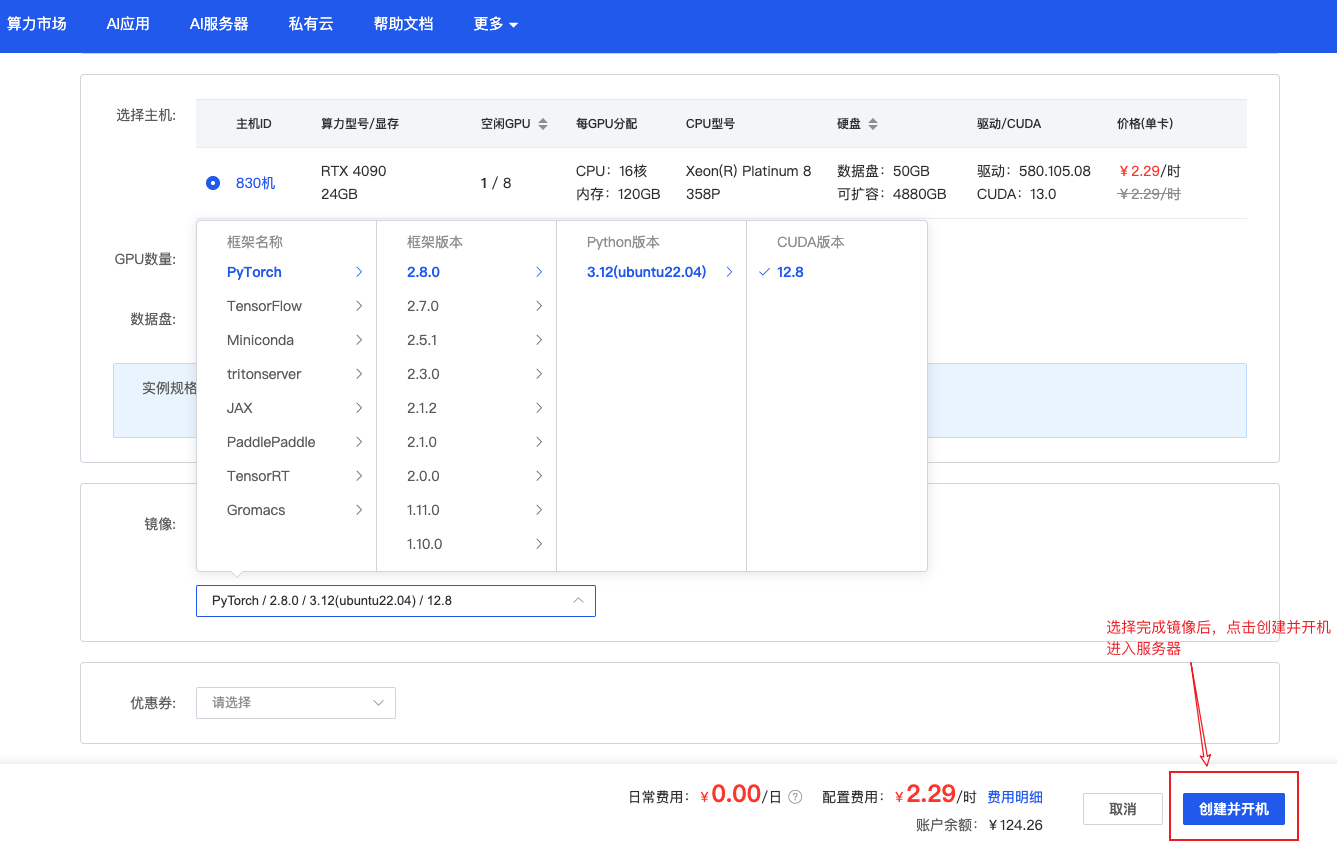
系统会开始创建实例,通常需要等待 1-3 分钟。创建成功后,我们就拥有了一台云端 GPU 服务器!
5.4 环境配置:镜像与版本选择 链接到标题
实例创建完成后,我们需要理解一些关于环境配置的关键知识。这些知识不仅对本次实验有用,更是未来独立解决环境问题的基础。
5.4.1 基础镜像类型介绍 链接到标题
AutoDL 的镜像分为三类:
基础镜像:官方预置的标准环境,包含主流深度学习框架
社区镜像:其他用户分享的定制环境,可能包含特定工具链
我的镜像:自己保存的环境快照,用于复用和分享
对于新手,强烈建议从基础镜像开始,避免社区镜像可能存在的兼容性问题。
5.4.2 PyTorch/CUDA 版本匹配原则 链接到标题
深度学习环境配置中最常见的"坑"就是版本不匹配。以下是需要关注的依赖关系链:
GPU 架构 → CUDA 版本 → cuDNN 版本 → PyTorch 版本 → Python 版本
核心原则:选择镜像时,确保 CUDA 版本与目标框架版本兼容。RTX 4090 建议使用 CUDA 11.8 或 12.x。
5.5 实例操作:开机与连接 链接到标题
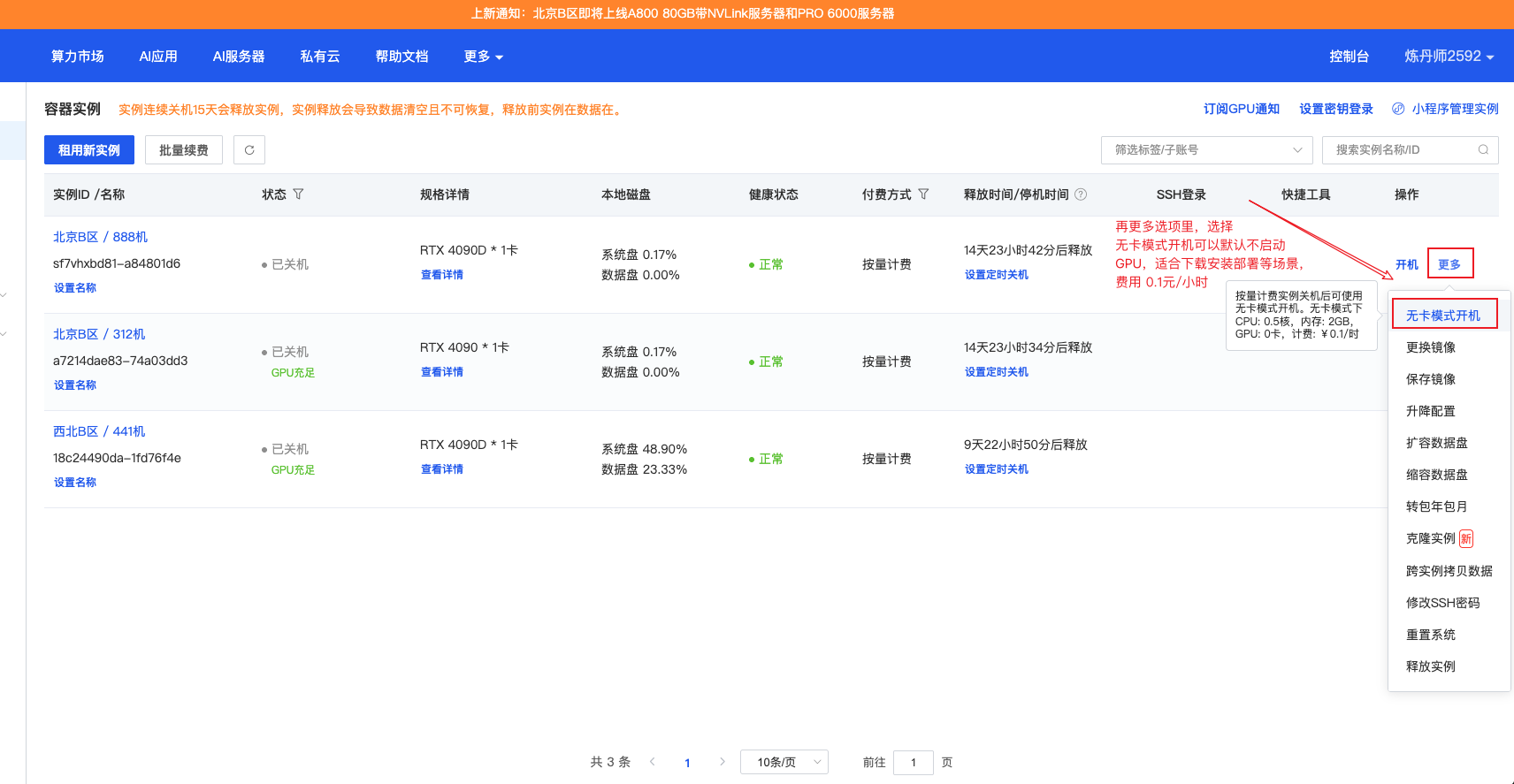
5.5.1 开机与开机模式选择 链接到标题
在"容器实例"页面,我们可以看到已创建的实例:
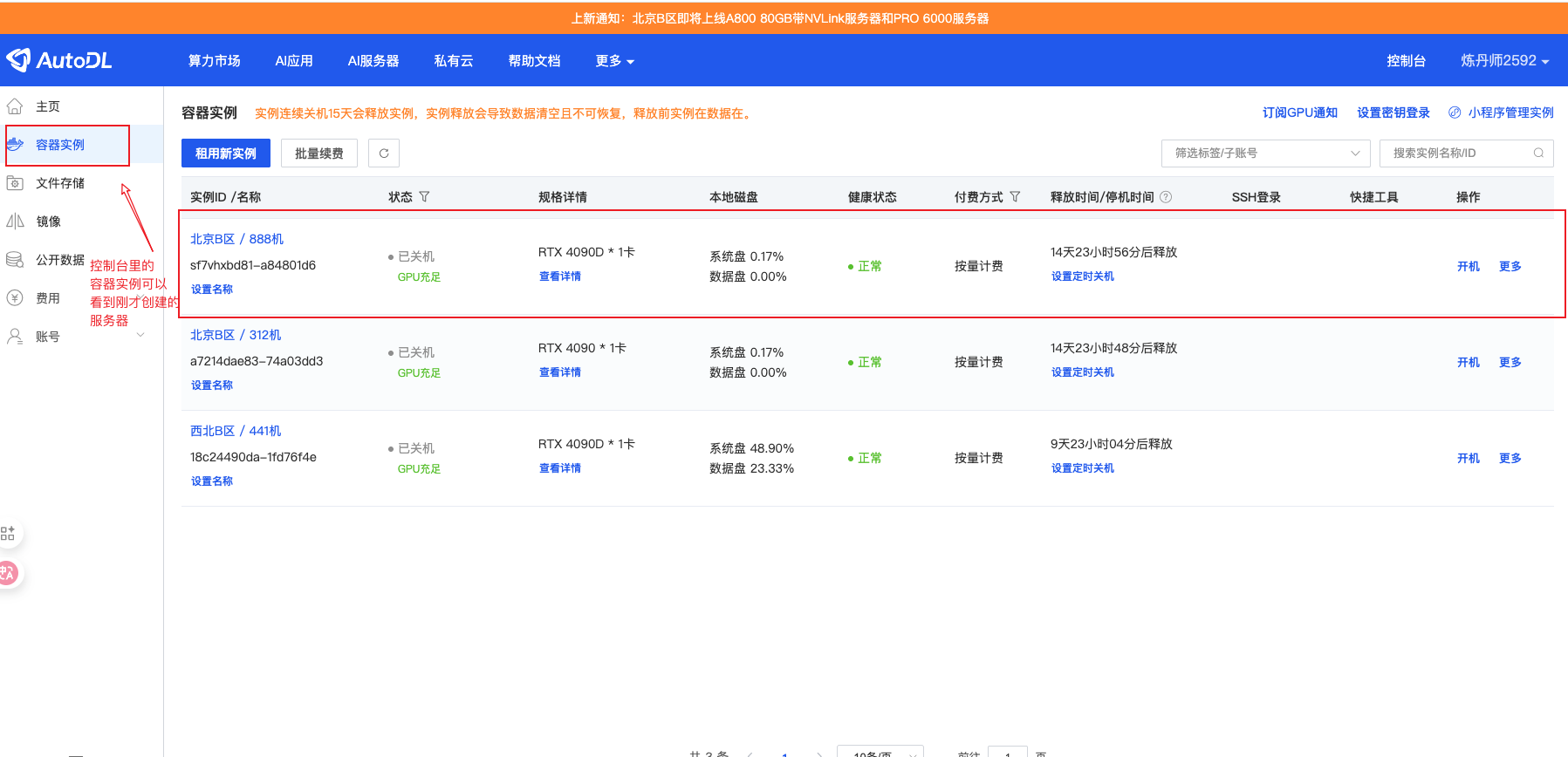
AutoDL 提供两种开机模式:
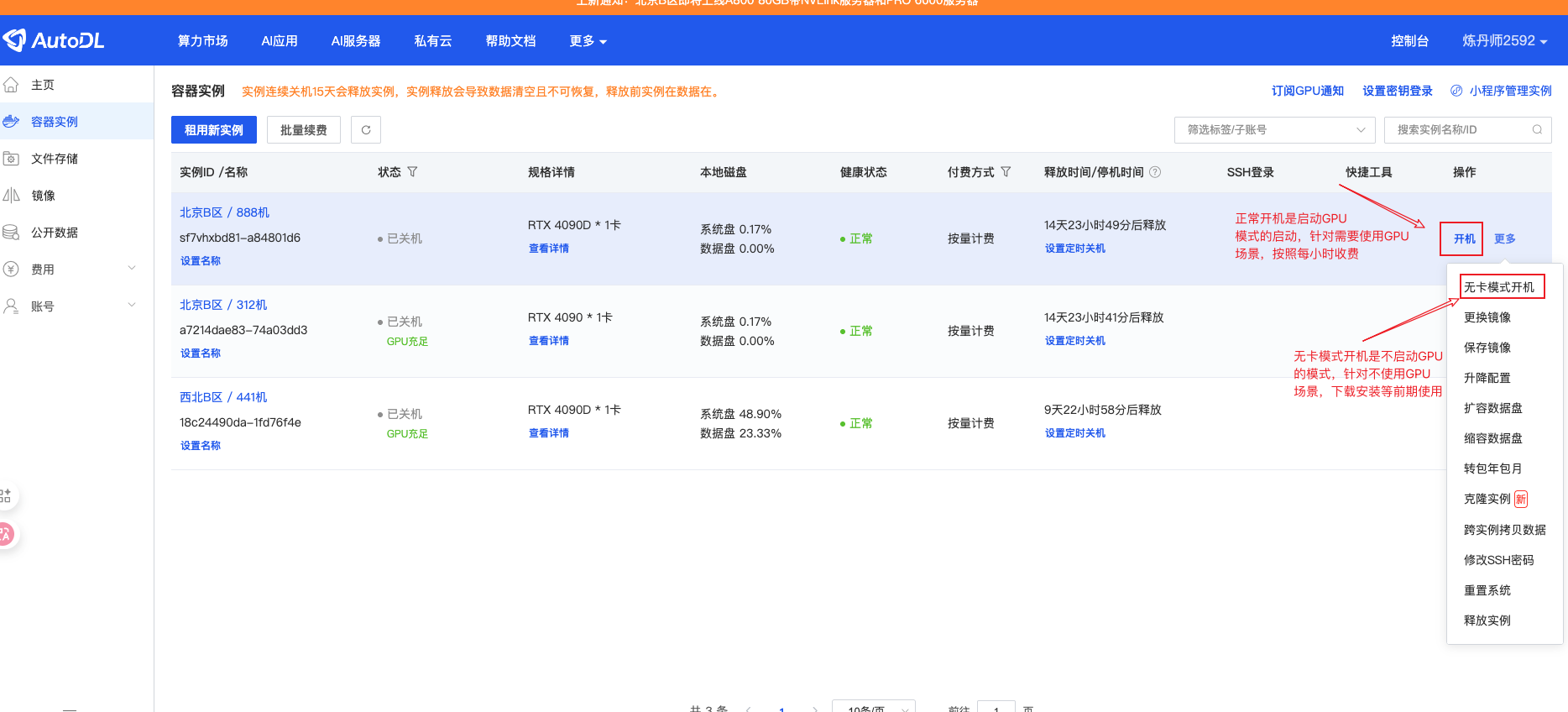
开机模式对比
| 开机模式 | 特点 | 适用场景 |
|---|---|---|
| 正常开机 | 挂载 GPU,正常计费 | 需要 GPU 计算的任务 |
| 无卡开机 | 不挂载 GPU,极低费用 | 仅需 CPU 的操作(如下载数据、配置环境) |
如果只是做一些不需要 GPU 的准备工作(如下载代码、安装依赖),可以选择"无卡开机"来节省成本。
5.5.2 通过 JupyterLab 进入服务器 链接到标题
最简单的连接方式是通过浏览器直接访问 JupyterLab。
步骤一:点击 JupyterLab 入口
在容器实例列表中,找到"快捷工具"列,点击"JupyterLab"按钮:
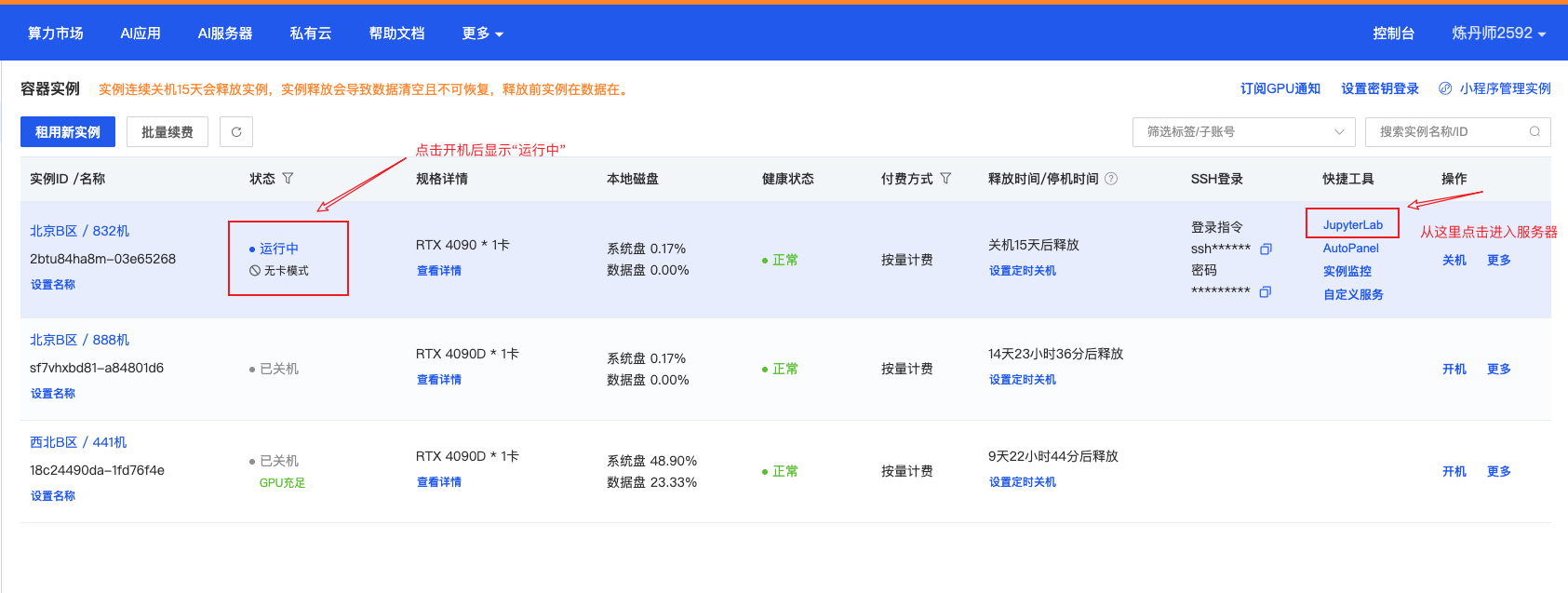
步骤二:进入服务器内部
浏览器会打开 JupyterLab 界面,我们已经成功进入服务器:
在 JupyterLab 中,我们可以:
打开终端(Terminal)执行命令
创建和编辑 Notebook
上传和下载文件
管理文件目录
5.5.3 通过 SSH 远程连接 链接到标题
对于更专业的使用场景,SSH 连接是更好的选择。AutoDL 为每个实例提供了专属的 SSH 登录命令。
步骤一:获取 SSH 登录命令
在容器实例页面,点击"SSH指令"按钮,复制登录命令。命令格式类似:
# 1. 连接 AutoDL 服务器(直接远程连接,可访问AutoDL上的文件数据)
!ssh -p 12345 root@region-1.autodl.com
# 2.建立 SSH 隧道,可将远程服务器的 11434 端口映射到本地,以便本地访问 11434 端口(后面可以暴露ollama、vLLM的端口,来进行本地调用)
!ssh -L 11434:0.0.0.0:11434 -p 56597 root@connect.bjb1.seetacloud.com
步骤二:在本地终端执行连接
打开本地终端(Mac/Linux 使用 Terminal,Windows 使用 PowerShell 或 Git Bash),粘贴并执行命令。首次连接需要输入密码(在实例详情页可查看)。
连接成功后,我们可以使用 nvidia-smi 命令确认 GPU 状态:
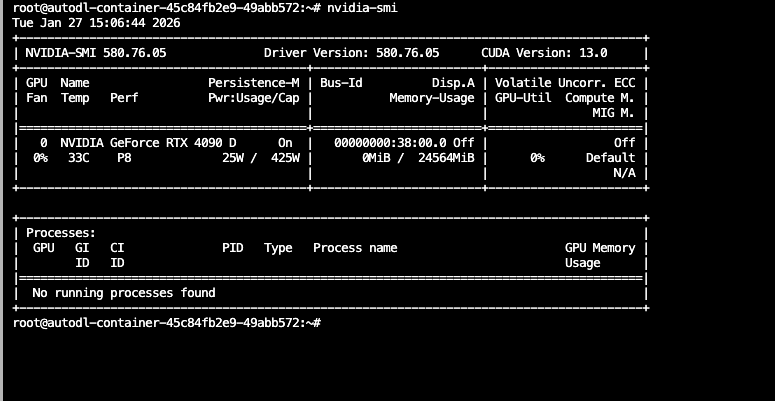
看到 GPU 信息输出,说明一切就绪!
5.5.4 VSCode Remote 配置(可选) 链接到标题
对于日常开发,推荐使用 VSCode Remote-SSH 插件进行远程开发。这种方式提供了本地 IDE 的完整体验,同时代码在云端运行。
配置步骤概要:
在 VSCode 中安装
Remote - SSH插件按
Cmd/Ctrl + Shift + P,输入Remote-SSH: Open SSH Configuration File添加 AutoDL 的 SSH 配置
保存后即可在远程资源管理器中看到服务器
由于篇幅关系,这里不展开详细步骤。AutoDL 官方文档提供了完整的 VSCode 配置教程。
5.5.5 数据盘与系统盘的区别 链接到标题
这是很多新手容易踩的"大坑”,必须牢记:
系统盘 vs 数据盘对比
| 存储类型 | 路径 | 是否持久化 | 用途 |
|---|---|---|---|
| 系统盘 | / | ❌ 关机后重置 | 操作系统、临时文件 |
| 数据盘 | /root/autodl-tmp | ✅ 持久保存 | 代码、数据集、模型权重 |
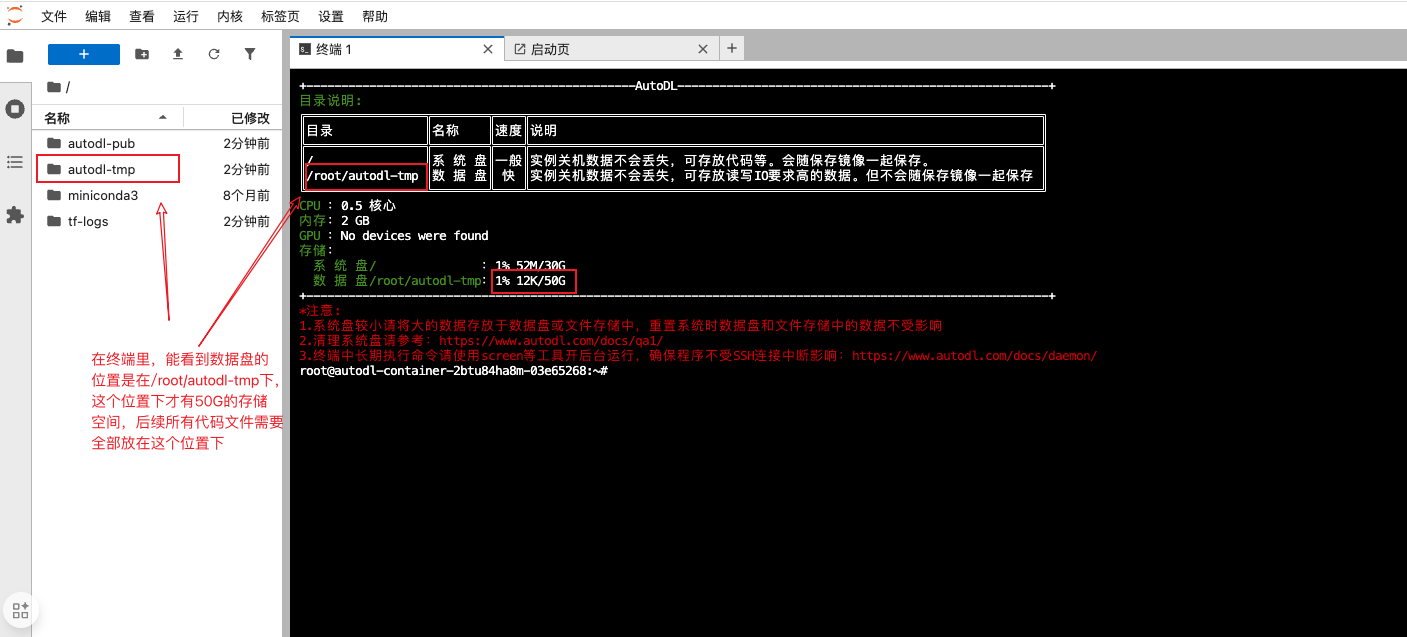
重要警告:所有重要文件必须存储在 /root/autodl-tmp 目录下!存储在其他位置的文件可能在关机后丢失。
5.6 磁盘空间管理与清理实战 链接到标题
在使用 AutoDL 进行大模型实验时,经常会遇到一个让人困惑的问题:明明删除了大文件,但磁盘空间显示却没有释放。这一节我们将深入理解这个问题的本质原因,并掌握彻底解决的方法。
5.6.1 问题场景重现 链接到标题
假设你在 /root/autodl-tmp 下载了一个 50GB 的模型,使用完毕后执行了 rm 删除:
# ⚠️ 确认后取消注释再执行
# !rm -rf /root/autodl-tmp/large_model/
但检查磁盘空间时,却发现使用率没有变化:
!df -h /root/autodl-tmp
# 显示仍然占用 50GB
这时很多人会尝试"清空回收站":
# ⚠️ 确认后取消注释再执行
# !rm -rf /root/.local/share/Trash/* # ❌ 这对命令行删除无效!
核心疑问:为什么删除文件后空间没有释放?如何确保空间真正回收?
5.6.2 Linux 文件删除的底层机制 链接到标题
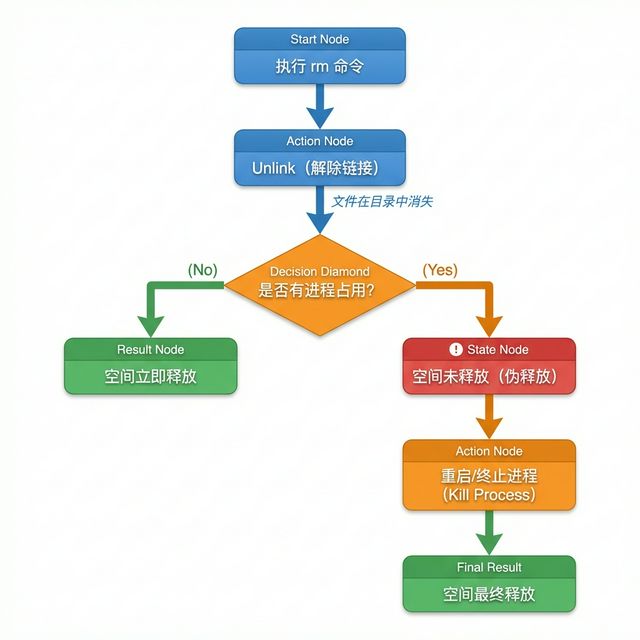
在 Linux 系统中,删除文件(rm)并不会立即释放磁盘空间,而是经过两个步骤:
步骤1: 解除文件的目录链接 (unlink)
→ 文件在目录中消失 ✅
步骤2: 等待所有进程关闭该文件
→ 磁盘空间才真正释放 ⏳
如果某个进程(如 Python 脚本、Jupyter Notebook、vLLM 服务)仍然打开着这个文件,即使你在目录中看不到它,文件的磁盘块仍然被占用。
⚠️ 常见误区:
/root/.local/share/Trash/*是图形界面的回收站,命令行rm删除的文件不会进入回收站- 删除文件后立即
df -h显示空间未释放,不代表删除失败,可能是进程占用
5.6.3 空间释放验证三步法 链接到标题
步骤1:对比 df 和 du 的差异
df 显示文件系统整体使用情况(包括已删除但被占用的文件),du 显示目录实际占用空间。
# 查看文件系统整体使用
!df -h /root/autodl-tmp
# 查看目录实际占用
!du -sh /root/autodl-tmp
判断标准:如果 df 显示的使用量远大于 du 显示的大小,说明存在已删除但被进程占用的文件!
df 与 du 差异示例
| 命令 | 显示内容 | 典型输出 |
|---|---|---|
df -h /root/autodl-tmp | 文件系统已用空间 | 80G / 100G (80%) |
du -sh /root/autodl-tmp | 目录实际占用 | 20G |
| 差异 | 被进程占用的已删除文件 | 60G ⚠️ |
步骤2:查找被占用的已删除文件
使用 lsof(list open files)工具找出被进程打开的已删除文件:
# 安装 lsof 工具
!apt update && apt install -y lsof
# 查找所有已删除但被占用的文件
!lsof | grep deleted
# 只看 autodl-tmp 目录下的
!lsof | grep -E "autodl-tmp.*deleted"
# 按大小排序,找出占用空间最大的
!lsof | grep deleted | awk '{print $7, $9}' | sort -rn | head -10
输出示例:
python 12345 root 3w REG 253,0 15GB /root/autodl-tmp/model.safetensors (deleted)
vllm 67890 root 5r REG 253,0 8GB /root/autodl-tmp/cache/chunk_00.bin (deleted)
从输出可以看到:
PID 12345 的 Python 进程持有 15GB 的已删除文件
PID 67890 的 vLLM 服务持有 8GB 的已删除缓存
步骤3:释放被占用的文件空间
有三种方法释放空间,根据场景选择:
空间释放方法对比
| 方法 | 操作 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 重启占用进程 | kill -15 然后重启服务 | 最安全,进程可正常关闭 | 服务会中断 | 生产环境 |
| 清空文件内容 | echo "" > /proc//fd/ | 不中断进程,立即释放空间 | 需要找到文件描述符 | 实验环境 |
| 强制终止进程 | kill -9 | 最快速 | 可能丢数据 | 紧急情况 |
5.6.4 AutoDL 磁盘清理完整脚本 链接到标题
我们为 AutoDL 环境编写了一个自动化清理脚本,集成了上述所有步骤:
#!/bin/bash
# AutoDL 磁盘空间释放完整脚本
!echo "========== 步骤1:检查磁盘空间差异 =========="
!DF_USAGE=$(df -h /root/autodl-tmp | tail -1 | awk '{print $3}')
!DU_USAGE=$(du -sh /root/autodl-tmp | awk '{print $1}')
!echo "df 显示已用: $DF_USAGE"
!echo "du 显示实际: $DU_USAGE"
!echo ""
!echo "========== 步骤2:查找已删除但被占用的文件 =========="
!DELETED_FILES=$(lsof 2>/dev/null | grep deleted | grep -c autodl-tmp)
!if [ "$DELETED_FILES" -gt 0 ]; then
!echo "⚠️ 发现 $DELETED_FILES 个被占用的已删除文件:"
!lsof 2>/dev/null | grep deleted | grep autodl-tmp | \
awk '{printf "PID: %-8s 大小: %-10s 文件: %s\n", $2, $7, $9}'
!echo ""
!echo "========== 步骤3:选择清理方式 =========="
!echo "选项1: 清空文件内容(进程继续运行)"
!echo "选项2: 终止占用进程(需重启服务)"
!echo "选项3: 手动处理(退出脚本)"
!read -p "请选择 (1/2/3): " choice
!case $choice in
!1)
!echo "正在清空已删除文件的内容..."
!lsof 2>/dev/null | grep deleted | grep autodl-tmp | while read -r line; do
!PID=$(echo $line | awk '{print $2}')
!FD=$(echo $line | awk '{print $4}' | tr -d 'rw')
!echo "" > /proc/$PID/fd/$FD 2>/dev/null && \
echo "✅ 清空 PID=$PID FD=$FD"
!done
!;;
!2)
!echo "正在终止占用进程..."
!lsof 2>/dev/null | grep deleted | grep autodl-tmp | \
awk '{print $2}' | sort -u | xargs kill -15
!sleep 2
!echo "✅ 进程已终止,空间已释放"
!;;
!3)
!echo "退出脚本,请手动处理"
!exit 0
!;;
!esac
!else
!echo "✅ 没有发现被占用的已删除文件"
!fi
!echo ""
!echo "========== 步骤4:最终空间检查 =========="
!df -h /root/autodl-tmp
!du -sh /root/autodl-tmp
!echo ""
!echo "========== 额外清理建议 =========="
!echo "1. 清理 pip 缓存:"
!echo " pip cache purge"
!echo ""
!echo "2. 清理 HuggingFace 缓存:"
!echo " rm -rf /root/.cache/huggingface/hub/*"
!echo ""
!echo "3. 清理 conda 缓存:"
!echo " conda clean -a -y"
使用方法:
# 保存脚本
!cat > /root/autodl-tmp/cleanup_disk.sh << 'EOF'
# (将上面的脚本内容复制到这里)
!EOF
# 赋予执行权限
!chmod +x /root/autodl-tmp/cleanup_disk.sh
# 运行脚本
!/root/autodl-tmp/cleanup_disk.sh
5.6.5 AutoDL 特定注意事项 链接到标题
AutoDL 磁盘管理要点
| 项目 | 说明 |
|---|---|
| 持久化目录 | 只有 /root 和 /root/autodl-tmp 会持久化,其他重启后清空 |
| 常见占用进程 | vllm、jupyter、python、ollama |
| 清理频率建议 | 每次删除大文件(>10GB)后立即检查 lsof |
| 安全删除流程 | 先停止相关服务 → 删除文件 → 验证空间 → 重启服务 |
🔥 踩坑预警:在删除大模型权重文件前,务必先检查是否有运行中的推理服务!
- 如果 vLLM 正在加载模型,直接删除模型文件会导致服务崩溃
- 如果 Jupyter Notebook 正在读取数据集,删除后会报 FileNotFoundError
- 正确做法:先停止服务(
systemctl stop vllm),删除文件,再重启服务
5.6.6 最佳实践:安全删除大文件的标准流程 链接到标题
# 1. 找到可能占用文件的进程
!lsof | grep <文件名或目录>
# 2. 停止相关进程
# ⚠️ 确认后取消注释再执行
# !systemctl stop vllm # 或 kill -15 <PID>
!jupyter notebook stop # 如果是 Jupyter
# 3. 删除文件
# ⚠️ 确认后取消注释再执行
# !rm -rf /root/autodl-tmp/large_model/
# 4. 验证空间释放
!df -h /root/autodl-tmp
!du -sh /root/autodl-tmp
# 5. 重启服务(如需要)
!systemctl start vllm
遵循这个流程,可以避免99%的磁盘空间未释放问题!
第六章:AutoDL 初体验——环境验证与 Hello World 链接到标题
过渡:现在你已经租好了一台强大的云服务器,并且通过 SSH 或 JupyterLab 连上了它。接下来,我们要做两件事:第一,确认显卡真的在工作;第二,在这台服务器上跑通你的第一段 AI 代码。
6.1 验证 GPU 环境 链接到标题
连接到终端后,输入以下终极命令:
!nvidia-smi
如果你看到类似下面的表格,说明 GPU 驱动安装正常,显卡随时待命:
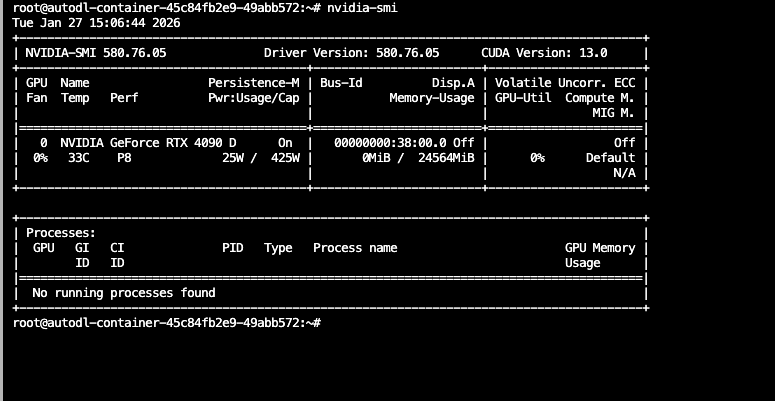
关键信息解读:
Name: 显卡型号(如 NVIDIA GeForce RTX 4090)
Memory-Usage: 显存使用情况(刚开机应该是 0MB / 24576MB)
CUDA Version: 支持的最高 CUDA 版本
6.2 运行 Hello World 脚本 链接到标题
让我们在 AutoDL 上复现第四章的代码。
步骤 1:新建 Python 文件
在终端或者 JupyterLab 的文件管理器中,新建一个文件 hello_llm.py。
步骤 2:写入代码
将第四章的代码复制进去。
步骤 3:运行代码
!python hello_llm.py
首次运行时,脚本会自动从 Hugging Face 下载模型(速度通常很快,因为 AutoDL 内置了加速)。等待进度条走完,你就能看到模型的回复了!
6.3 conda环境切换 链接到标题
# 使用 conda 安装(推荐,更稳定)
!conda install ipykernel
# 或者使用 pip 安装
!pip install ipykernel
# 将环境写入 Jupyter 的内核列表
!python -m ipykernel install --user --name=ai_course --display-name "Python (AI Course)"
在新写入的conda环境后,需要刷新AutoDl的页面,然后才能在ipynb文件中看到conda环境!
至此,你已经成功打通了"云端部署"的全流程。 接下来,我们将进入进阶环节:如何让模型运行得更快、更省显存?这就需要用到量化技术。
第七章:量化技术入门——让大模型在消费级显卡上起舞 链接到标题
过渡:在云端跑通了代码是第一步,但要在本地(尤其是显存有限的消费级显卡)上跑大模型,就必须掌握核心’黑科技’——量化。这一章我们将深入底层,理解为什么模型可以变小而不变笨。
7.1 精度与量化基础 链接到标题
在深入量化技术之前,我们需要先理解一个基础问题:同一个模型,为什么有 FP16、INT8、INT4 这么多版本?它们之间有什么区别?为什么 INT4 版本的文件只有 FP16 版本的四分之一大小,但效果却差不多?
这就是我们这一节要深入探讨的主题:精度(Precision)与量化(Quantization)。这是让消费级显卡(如 RTX 4090)能够运行企业级大模型的关键技术。
7.1.1 数据精度的物理意义 链接到标题
计算机中存储小数(浮点数)有不同的格式,占用的空间(显存)也不同。让我们从最基础的概念开始理解。
常用数据精度对比
| 精度类型 | 位数 | 每参数字节数 | 数值范围 | 典型用途 |
|---|---|---|---|---|
| FP32 | 32-bit | 4 字节 | 极大 | 训练(黄金标准) |
| FP16 | 16-bit | 2 字节 | 较小,易溢出 | 推理(传统) |
| BF16 | 16-bit | 2 字节 | 与 FP32 相同 | 训练+推理(推荐) |
| INT8 | 8-bit | 1 字节 | 整数范围 | 量化推理 |
| INT4 | 4-bit | 0.5 字节 | 整数范围 | 量化推理(主流) |
各精度详解
FP32(单精度):深度学习训练的"黄金标准",精度极高,但一个 70B 模型需要 280GB 显存,远超任何消费级显卡。
FP16(半精度):推理的传统选择,显存需求减半。但数值范围较小,训练时容易出现数值溢出导致 NaN。
BF16(Brain Float 16):Google 为 AI 设计的格式,保留了 FP32 的指数位(数值范围相同),截断了尾数位。是 Ampere 架构(RTX 30系)及以后显卡的标配,推荐在支持的硬件上优先使用 BF16。
INT8/INT4(整数量化):用整数来近似表示浮点数,大幅减少显存占用,是本地部署大模型的关键技术。
⚠️ FP16 vs BF16 的区别:虽然两者都占 2 字节,但内部结构不同。BF16 保留了与 FP32 相同的指数位宽度,因此数值范围更大,训练时不易溢出;FP16 的尾数位更多,数值精度更高,但动态范围较小。简单记忆:BF16 更适合训练和微调,FP16 更常用于推理。在量化场景中,两者作为"基线精度"的表现几乎一致。
7.1.2 量化:以"模糊"换"空间" 链接到标题
量化(Quantization)的本质是:将高精度的浮点数映射为低精度的整数,从而大幅减少显存占用。这就像是把一张 4K 高清图片压缩成缩略图——文件变小了,但主体信息还在。
量化的数学直觉
假设模型中某个权重的原始值是 0.12345678(FP32,占 4 字节):
FP16 转换:保留约 4 位有效数字,变成
0.1235(占 2 字节)INT8 量化:映射到 [-128, 127] 的整数范围,可能变成
31(占 1 字节)INT4 量化:映射到 [-8, 7] 的整数范围,可能变成
2(占 0.5 字节)
量化后的整数需要配合一个"缩放因子"才能还原近似的原始值。这个过程会损失一些精度,但对于大多数任务来说,这种损失是可以接受的。
量化的实际效果
让我们用具体数字来感受量化的威力:
70B 模型在不同精度下的显存需求
| 精度 | 计算公式 | 显存需求 | 可运行硬件 |
|---|---|---|---|
| FP32 | 70B × 4 字节 | 280 GB | 多卡 A100 集群 |
| FP16/BF16 | 70B × 2 字节 | 140 GB | 4× A100 80GB |
| INT8 | 70B × 1 字节 | 70 GB | 2× RTX 4090 |
| INT4 | 70B × 0.5 字节 | 35 GB | 2× RTX 3090 ✅ |
这就是为什么 INT4 量化如此重要:它让原本需要几十万元服务器才能跑的 70B 模型,变成了双卡 3090 就能本地运行。
7.1.3 INT4 量化的实际表现 链接到标题
你可能会担心:精度损失这么多,模型效果会不会大打折扣?
答案是:对于大多数应用场景(对话、摘要、代码生成),INT4 量化的效果与 FP16 惊人地接近。
困惑度(Perplexity)—— 量化质量的核心指标
Perplexity(简称 PPL)是衡量语言模型预测下一个 Token 能力的标准指标。简单来说,它衡量模型对一段文本感到"惊讶"的程度——PPL 越低越好,低 PPL 意味着模型能准确预测接下来的内容,生成的文本更通顺、逻辑更连贯。FP16 原始模型的 PPL 是"金标准",量化后 PPL 会略微上升。
以 Qwen3-8B 为例:
Qwen3-8B 不同精度困惑度对比
| 精度版本 | 困惑度 | 相对变化 | 主观体验 |
|---|---|---|---|
| FP16 | 5.12 | 基准 | 最佳 |
| INT8 | 5.18 | +1.2% | 几乎无差异 |
| INT4 (Q4_K_M) | 5.38 | +5.1% | 略有下降,可接受 |
| INT2 | 6.20 | +21.1% | 明显下降 |
从数据可以看出,INT4 量化只带来约 5% 的困惑度上升,在实际使用中几乎感知不到差异。这就是为什么 INT4 是目前本地部署的"甜点"精度——在显存节省和效果保持之间取得了最佳平衡。
PPL 变化幅度的判断法则
当你在 Hugging Face 上对比多个量化版本时,可以用以下标准快速判断质量:
PPL 变化幅度的质量判断标准
| PPL 变化幅度(相对 FP16) | 含义 | 体感 |
|---|---|---|
| 增加 1% - 3% | ✅ 可视为"无损" | 人类几乎察觉不到差异 |
| 增加 3% - 10% | ⚠️ 轻微有损 | 复杂推理任务中可能有感知 |
| 增加 >10% | ❌ 严重有损 | 模型开始胡言乱语或丧失逻辑 |
⚠️ PPL 的局限性:低 PPL 并不代表模型"聪明"。一个模型可以生成很通顺的句子(低 PPL),但在解数学题或遵循复杂指令时完全失败。因此 PPL 只是必要条件,不是充分条件。对于编程、数学或强逻辑任务,4-bit 是底线——即使 PPL 看起来还可以,3-bit 模型在 Math/Coding 任务上的准确率通常会大幅下降。
7.2 量化格式详解 链接到标题
理解了量化的基本原理后,你在下载量化模型时会发现:同样是 INT4 量化,怎么有 GGUF、GPTQ、AWQ 这么多格式?它们有什么区别?应该选哪个?
这一节我们来深入解析这些量化格式的特点和适用场景。
7.2.1 三大主流量化格式对比 链接到标题
量化格式特性对比
| 格式 | 全称 | 核心特点 | 适用场景 | 代表工具 |
|---|---|---|---|---|
| GGUF | GPT-Generated Unified Format | CPU/GPU 混合推理 | ollama、Mac、显存不足 | llama.cpp |
| GPTQ | GPT Quantization | 纯 GPU,需校准数据 | vLLM、高吞吐服务 | AutoGPTQ |
| AWQ | Activation-aware Weight Quantization | 激活感知,效果好 | vLLM、TGI | AutoAWQ |
7.2.2 GGUF:最灵活的通用格式 链接到标题
GGUF(GPT-Generated Unified Format)是由 llama.cpp 团队开发的量化格式,也是目前最普及的本地部署格式。它的核心优势可以用一句话概括:显存不够,内存来凑。
核心优势:CPU/GPU 混合卸载
其他格式(如 AWQ、GPTQ)要求模型完全装入显存,溢出即报错 OOM(Out Of Memory)。而 GGUF 允许将一部分层加载到 GPU(显存),剩余部分留在系统内存(RAM)由 CPU 计算。
场景举例:你有一张 24GB 的 RTX 4090,想运行 70B 的 Q4 模型(约 40GB)。
- 纯 GPU 方案(AWQ/GPTQ):直接 OOM,无法运行。
- GGUF 方案:约 40 层装入显存(24GB),剩余层留在内存。速度从 50 t/s 降至 3-5 t/s,但至少能跑。
除了混合推理,GGUF 还有以下优势:
单文件部署:所有信息(权重、配置、分词器)打包在一个
.gguf文件中,下载即用广泛兼容:
ollama、LM Studio、llama.cpp等主流工具都原生支持Mac 友好:充分利用 Apple Silicon 的统一内存架构,在 Mac 上性能表现优异
K-Quants:混合精度的艺术
GGUF 的 K-Quants 技术是一种精细的块状量化方案——它的核心洞察是:并非所有权重都同等重要。
以常用的 Q4_K_M 为例:注意力机制中的关键权重使用 6-bit 保存,而前馈网络的权重使用 4-bit。这种"好钢用在刀刃上"的策略,使得 Q4_K_M 在体积与传统 Q4_0 几乎相同的情况下,推理质量大幅提升。
你在下载 GGUF 模型时会看到 Q4_K_M、Q5_K_S 这样的命名,以下是各等级的详细对比:
GGUF 不同量化等级的特性对比
| 量化后缀 | 平均位宽 (bpw) | 质量描述 | 适用场景 | 70B 模型体积 |
|---|---|---|---|---|
| Q8_0 | 8.0 | 无损级,几乎等同 FP16 | 研究基准、高端工作站 | ~75 GB |
| Q5_K_M | ~5.7 | 质量与体积的最佳平衡(高配) | 显存充足时首选 | ~50 GB |
| Q4_K_M | ~4.8 | ⭐ 最常用的平衡选择,保留 98% 推理能力 | 大多数用户的默认选择 | ~42.5 GB |
| IQ4_XS | ~4.3 | 利用重要性矩阵压缩,优于 Q4_K_S | 极限显存环境的高质量选择 | ~38 GB |
| IQ3_M | ~3.7 | 质量有可见下降,逻辑任务仍可用 | 单卡 24GB 强跑大模型时 | ~32 GB |
| Q2_K | ~2.5 | 损失较大,仅应急使用 | 极端显存限制 | ~22 GB |
术语解释:bpw(bits per weight) 表示平均每个权重参数占用的比特数。例如 Q4_K_M 的 bpw 约 4.8,意味着平均每个参数占 4.8 bit(而非严格的 4 bit),因为加上了缩放因子的存储开销。
I-Quants 与重要性矩阵(Importance Matrix)
GGUF 的 I-Quants(如 IQ4_XS、IQ3_M)使用了更进一步的非均匀量化策略。它配合校准数据集计算出"重要性矩阵",为每个权重打"重要性分数"——对重要性高的权重保留更多精度,对不重要的权重更激进地压缩。
效果:IQ4_XS(约 4.25 bpw)能以比 Q4_K_S 更小的体积,达成接近 Q4_K_M 的性能。如果你的显存极度紧张,IQ 系列是比传统 Q 系列更好的选择。
🔥 踩坑预警:I-Quants 的质量高度依赖校准数据集。如果量化时使用的校准数据是英文 WikiText,而你主要用于中文对话,效果可能不如预期。下载时注意查看模型卡片中的校准数据集信息。
7.2.3 AWQ 与 GPTQ:GPU 专属格式 链接到标题
如果你有足够的显存将模型完全装入 GPU,且追求最快的推理速度,AWQ 和 GPTQ 是更好的选择。它们都属于纯 GPU 格式——模型必须完全装入显存,不支持 CPU 卸载,显存溢出直接报错 OOM。
AWQ(Activation-aware Weight Quantization)—— 激活感知量化
AWQ 是目前 vLLM 等服务端推理引擎的首选格式。它的核心洞察非常精妙:在模型的数十亿个参数中,约有 1% 的权重会产生非常大的激活值,这些被称为"显著权重(Salient Weights)"。
AWQ 的策略是:通过缩放因子保护这 1% 关键权重的精度,只压缩剩下的 99%。这就像是一个公司裁员时,核心骨干(1%)不动,只精简非核心岗位(99%)——公司的核心战斗力几乎不受影响。
优点:在同等压缩率下效果更好,指令遵循和代码生成能力保持较好
适用场景:需要高并发吞吐的 API 服务部署(配合 vLLM)、追求极致推理速度的纯 GPU 环境
GPTQ(GPT Quantization)—— 经典方案
GPTQ 是早期量化技术的代表方案。它利用海森矩阵(Hessian Matrix,二阶导数信息)来判断哪些权重对输出最敏感,并在量化时对这些敏感权重进行误差补偿。
与 AWQ 的核心区别:
GPTQ 关注"权重本身的数学敏感度"(海森矩阵)
AWQ 关注"权重在推理时产生的激活大小"(激活感知)
在一些评测中,AWQ 在指令遵循和代码生成上略胜一筹,因为它更好地保护了实际推理中最关键的权重
应用现状:GPTQ 已逐渐被 AWQ 取代为首选,但在部分旧硬件或 AutoGPTQ 等框架中仍被广泛支持,兼容性较好。
7.2.4 Weight-Only 量化:为什么只压缩权重? 链接到标题
在理解了三大格式之后,你可能会产生一个更深层的疑问:为什么这些格式都只量化权重,而不量化激活值?这就是 Weight-Only 量化的核心机制。
Weight-Only 量化是指只压缩模型的权重参数,而在推理计算时,激活值(输入数据经过层级计算后的中间结果)仍然保持高精度(FP16/BF16)。
Weight-Only 量化的两步机制
| 阶段 | 操作 | 精度 |
|---|---|---|
| 存储时 | 权重以低精度保存(如 INT4),大幅减少显存占用和磁盘体积 | INT4(4-bit) |
| 计算时 | 系统将该层的 INT4 权重**解压缩(Dequantize)**回 FP16,然后与 FP16 的激活值进行矩阵乘法 | FP16(16-bit) |
为什么这样做反而更快?
大语言模型推理的主要瓶颈通常不是"算得慢",而是"读得慢"——瓶颈在显存带宽。每生成一个 Token,都需要将模型的全部权重从显存读取到计算单元一次。Weight-Only 量化把权重从 FP16 压缩到 INT4,数据量减少到四分之一,从显存读取数据的时间大幅缩短。因此,Weight-Only 量化既降低了硬件门槛,又往往能提高推理速度。
💡 重要认知:前面介绍的 GGUF(Q4_K_M 等)、GPTQ 和 AWQ,都属于 Weight-Only 量化。理解了这个机制,你就能明白为什么量化模型"存储小但计算不慢"。
7.2.5 Calibration(校准):用小数据集"微调"量化精度 链接到标题
在量化过程中,并非所有权重都同等重要。盲目地把每个数字都从 FP16 压成 INT4,会导致模型变"傻"。Calibration(校准) 就是在量化时,使用少量真实数据(通常 128-512 条文本片段)运行模型,收集统计信息,帮助算法识别哪些权重必须小心保护。
三大格式的校准方法各有不同:
主流量化格式的校准方法对比
| 量化格式 | 校准方法 | 核心逻辑 |
|---|---|---|
| GPTQ | 海森矩阵(二阶导数) | 找到对输出误差最敏感的权重,量化时对其进行误差补偿 |
| AWQ | 激活感知 | 观察激活值大小,发现约 1% 的权重产生巨大激活值,必须保护 |
| GGUF I-Matrix | 重要性矩阵 | 为每个权重打"重要性分数",为重要权重分配更多比特 |
⚠️ 校准数据与使用场景不匹配的陷阱:如果量化时使用的校准数据集(如英文 WikiText)与你实际使用场景(如中文对话)差异过大,量化后的模型可能会在特定任务上表现不佳。自己转换模型时(使用
llama.cpp的quantize工具),低比特量化务必使用--imatrix参数并提供与使用场景匹配的校准数据集。
7.2.6 实战指南:4 步选择量化模型 链接到标题
掌握了以上所有知识后,我们来把它们串成一个实用的决策流程。当你需要下载和选择量化模型时,按以下 4 步操作:
步骤一:根据硬件选择量化格式
你不需要自己训练量化模型,通常是直接下载现成的。
硬件环境与量化格式匹配指南
| 硬件环境 | 推荐格式 | 加载工具 | 优势 |
|---|---|---|---|
| Apple Mac(M1/M2/M3/M4) | GGUF | LM Studio / ollama | 利用统一内存架构,速度快 |
| NVIDIA 显卡(显存充足) | AWQ | vLLM / Text-Gen-WebUI | 在同等量化精度下推理速度较快 |
| NVIDIA 显卡(显存不足) | GGUF | ollama / LM Studio | 支持 CPU/GPU 混合运算,虽慢但能跑 |
| 只有 CPU(旧电脑) | GGUF | llama.cpp | 极慢,但不受显卡限制 |
步骤二:通过 PPL 快速筛选版本
在 Hugging Face 上看到多个量化版本(如 Q4_0、Q4_K_S、Q4_K_M)时,查看作者提供的 PPL 表格:
对比 FP16 基线,PPL 增加在 1%-3% 以内 → 通常认为"无损"
PPL 暴增(>10%)逻辑推理中很可能"崩坏"
经验:Q4_K_M 通常比 Q4_0 的 PPL 更低(更好),因为前者使用了更智能的超块结构
步骤三:关注校准数据集
下载 IQ 系列 GGUF(如 IQ4_XS)或 GPTQ 模型时,注意校准数据集是什么
英文 WikiText 校准的模型 → 用于中文任务时可能稍差
如果自己量化,低比特务必使用
--imatrix参数并提供匹配的校准数据
步骤四:超越 PPL 的终极判断
4-bit 是底线:即使 PPL 看起来还可以,3-bit 模型在 Math/Coding 任务上的准确率通常大幅下降
AWQ vs GPTQ:AWQ 在指令遵循和代码生成上通常略胜一筹
总结建议:日常使用首选 4-bit Weight-Only 量化(Q4_K_M / AWQ)。这通常能在 PPL 几乎无损的情况下,节省一半以上的显存。只有在显存极其紧张时,才考虑依赖校准优化过的 3-bit(IQ3),并接受其在复杂逻辑任务上变弱的现实。
格式选择决策树
你的场景是什么?
│
├─→ 显存充足 + 追求速度 → AWQ/GPTQ + vLLM
│
├─→ 显存不足 + 能接受慢速 → GGUF + ollama(CPU 卸载)
│
├─→ Mac 用户 → GGUF + ollama/LM Studio
│
└─→ 快速体验 + 一键部署 → GGUF + ollama
第八章:量化实战工具链——llama.cpp、Unsloth 与 KTransformers 链接到标题
过渡:理解了量化原理后,我们将进入’核武库’。本章将介绍三个最硬核的本地部署工具:GGUF 生态的基石 llama.cpp、微调界的新星 Unsloth、以及让单卡跑 671B 模型的黑科技 KTransformers。
在前两章中,我们从原理层面理解了量化技术和各种格式的特点。但知识如果不落地到实际操作,就只是"纸上谈兵"。本章将带你进入真正的实战环节,依次介绍三个核心工具:llama.cpp(GGUF 生态的核心引擎)、Unsloth(高效微调与量化导出)和 Ktransformers(MoE 模型的 CPU+GPU 混合推理)。
我们按照从"用现成模型"到"自己量化模型"再到"专项优化"的难度递进来组织内容。第一站是 llama.cpp——它是第 2 章中我们重点讲解的 GGUF 格式的"制造者和运行者",学完这一节你就能跑通从"下载 GGUF 模型"到"启动本地 API 服务"的完整链路。
8.1 llama.cpp:GGUF 生态的核心引擎 链接到标题
在第 2 章中,我们花了大量篇幅讲解 GGUF 格式的 K-Quants、I-Quants、bpw 等概念。你可能会好奇:这些 GGUF 文件到底是谁"制造"的?当你用 ollama run qwen3:8b 一键跑模型时,底层到底发生了什么?
答案就是 llama.cpp。它是整个 GGUF 生态的基石——GGUF 格式由它定义,GGUF 量化由它执行,GGUF 推理由它驱动。你每天在用的 ollama,底层就是 llama.cpp。理解了 llama.cpp,你就从一个"工具使用者"变成了一个"知道引擎盖下面是什么"的人。
Github地址:https://github.com/ggml-org/llama.cpp
8.1.1 llama.cpp 是什么 链接到标题
llama.cpp 是一个基于 C/C++ 构建的高性能大模型推理引擎,由 Georgi Gerganov 于 2023 年创建。它的核心特点是:
零 Python 依赖:纯 C/C++ 实现,编译后是独立的二进制文件,不需要安装 PyTorch、Transformers 等重量级框架
全平台支持:CPU(AVX2/AVX-512)、Apple Silicon(Metal)、NVIDIA GPU(CUDA)、AMD GPU(ROCm)
GGUF 格式的"亲爹":GGUF 格式由 llama.cpp 团队设计和维护,所有 GGUF 量化工具都来自这个项目
ollama 的底层引擎:ollama 本质上是 llama.cpp 的一层"用户友好包装",底层推理完全由 llama.cpp 驱动
llama.cpp 编译后会生成几个核心工具:
llama.cpp 核心工具说明
| 工具名称 | 作用 | 使用场景 |
|---|---|---|
llama-cli | 命令行推理工具 | 快速测试模型、单轮对话 |
llama-server | HTTP API 服务器(兼容 OpenAI 协议) | 搭建本地推理服务 |
llama-quantize | 模型量化工具 | 将 FP16 GGUF 量化为 Q4_K_M 等格式 |
convert_hf_to_gguf.py | HuggingFace → GGUF 转换脚本 | 将 safetensors 模型转为 GGUF |
💡 什么时候需要直接用 llama.cpp 而不是 ollama? 当你需要:自己量化模型(ollama 只能用现成的)、精细控制 KV Cache 量化参数、搭建高并发 API 服务、或者在没有 Python 环境的嵌入式设备上运行模型时,就需要直接使用 llama.cpp。
8.1.2 模型转换流水线:从 HuggingFace 到 GGUF 链接到标题
在开始动手之前,我们需要明确 llama.cpp 的两大核心应用场景。作为未来的大模型工程师,你需要同时掌握这两类技能,而不仅仅是会用别人转好的模型。
llama.cpp 核心应用场景
| 场景 | 角色 | 关键动作 | 核心工具/脚本 |
|---|---|---|---|
| 1. 模型生产与转换 | 开发者/部署工程师 | 将 HF 模型转为 GGUF,进行量化压缩 | convert_hf_to_gguf.py``llama-quantize |
| 2. 模型推理与服务 | 终端用户/应用开发者 | 直接运行 GGUF 模型,提供 Chat 或 API | llama-cli``llama-server |
💡 为什么要学这类工具?:即便是普通用户,掌握第一类场景(模型生产)也意味着你拥有了"模型自由"——任何新出的 HuggingFace 模型(只要架构支持),你都能第一时间把它转成 GGUF 并在本地跑起来,而不需要等待别人发布。
接下来,我们将完整体验从场景 1 到场景 2 的全流程:先把 HuggingFace 的 safetensors 模型转换为 FP16 GGUF(中间格式),再用量化工具压缩到目标精度,最后进行推理和服务。
步骤一:获取 llama.cpp 并安装依赖
首先需要获取 llama.cpp 源码并安装转换脚本所需的 Python 依赖。本步成功的判据是 requirements.txt 安装完成且无报错。
# 获取源码(AutoDL中最好在autodl-tmp路径下执行)
!git clone https://github.com/ggml-org/llama.cpp
!cd llama.cpp
# 创建并激活 conda 环境
!conda create -n llama.cpp_env python=3.11 -y
# 激活环境
!conda activate llama.cpp_env
# 安装转换脚本的 Python 依赖
!pip install -r requirements.txt
如果你需要使用 GPU 加速推理,还需要编译 CUDA 版本:
# NVIDIA GPU (CUDA) 编译(-B build 会自动创建 build 目录)
!cmake -B build -DGGML_CUDA=ON
!cmake --build build --config Release -j$(nproc)
编译完成后,build/bin 目录下会生成 llama-cli、llama-server、llama-quantize 等二进制文件。
⚠️ 常见误区:很多初学者以为 llama.cpp 只能在 CPU 上跑。实际上,编译时加上
LLAMA_CUDA=1后,它的 GPU 推理速度非常快。CPU 推理只是它的"兜底能力",不是唯一能力。
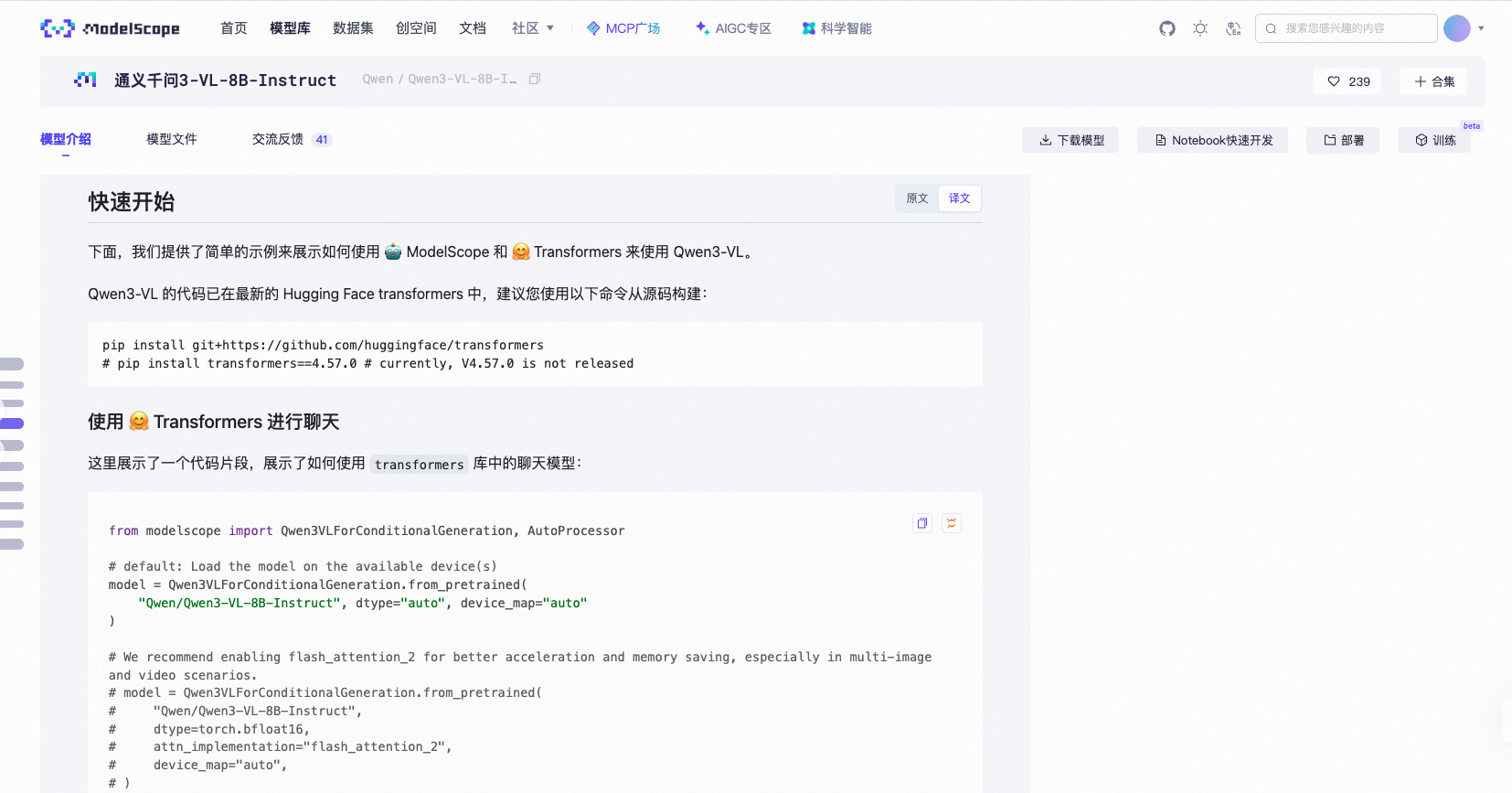
步骤二:将 HuggingFace 模型转换为 FP16 GGUF
假设你已经通过 Lesson 1 学到的方法下载了一个 HuggingFace 模型(如 Qwen/Qwen3-8B),现在要把它转换为 GGUF 格式。本步成功的判据是生成了 qwen3-8b-f16.gguf 文件。
!python convert_hf_to_gguf.py /root/autodl-tmp/models/Qwen3-0.6B \
--outfile qwen3-0.6b-f16.gguf \
--outtype f16
这个脚本会读取模型的 config.json、tokenizer.json 和所有 safetensors 权重文件,将它们打包成一个自包含的 GGUF 文件。--outtype f16 表示先保持 FP16 精度,作为后续量化的"原料"。
💡 为什么不直接转成 Q4_K_M? 虽然转换脚本也支持直接输出低精度,但推荐先转为 FP16 GGUF 作为中间体,再用
llama-quantize工具进行量化。这样可以从同一个 FP16 源文件生成多种精度版本(Q4_K_M、Q5_K_M、IQ4_XS 等),而不需要每次都重新转换。⚠️ 资源消耗提示:
convert_hf_to_gguf.py是纯 CPU 和内存(RAM)操作,不需要 GPU 显存。这意味着你可以在没有 GPU 的机器上(如 MacBook Air 或普通服务器)完成转换,然后再将 GGUF 文件上传到 GPU 机器上进行推理。但请注意,转换大模型(如 70B)时需要较大的系统内存。
步骤三:量化为目标精度
有了 FP16 GGUF 文件后,就可以用 llama-quantize 工具将其压缩到目标精度。本步成功的判据是生成了体积明显更小的量化 GGUF 文件。
# 量化为 Q4_K_M(常用的通用选择)
!./llama-quantize qwen3-0.6b-f16.gguf qwen3-0.6b-q4_k_m.gguf Q4_K_M
执行后你会看到文件大小的显著变化:FP16 版本约 16GB,Q4_K_M 版本约 5GB——体积缩小到原来的 1/3,这正是第 2 章中我们讲过的 Q4_K_M(约 4.8 bpw)的效果。
🔥 踩坑预警:量化过程需要将整个 FP16 模型加载到内存中。对于 70B 模型(FP16 约 140GB),你的机器至少需要 140GB 以上的可用内存(RAM),否则会因内存不足而失败。
步骤四:快速验证(CLI)
量化完成后,我们可以立刻使用 llama-cli 测试模型是否正常。
!./llama-cli -m qwen3-0.6b-q4_k_m.gguf -p "你好" -n 20
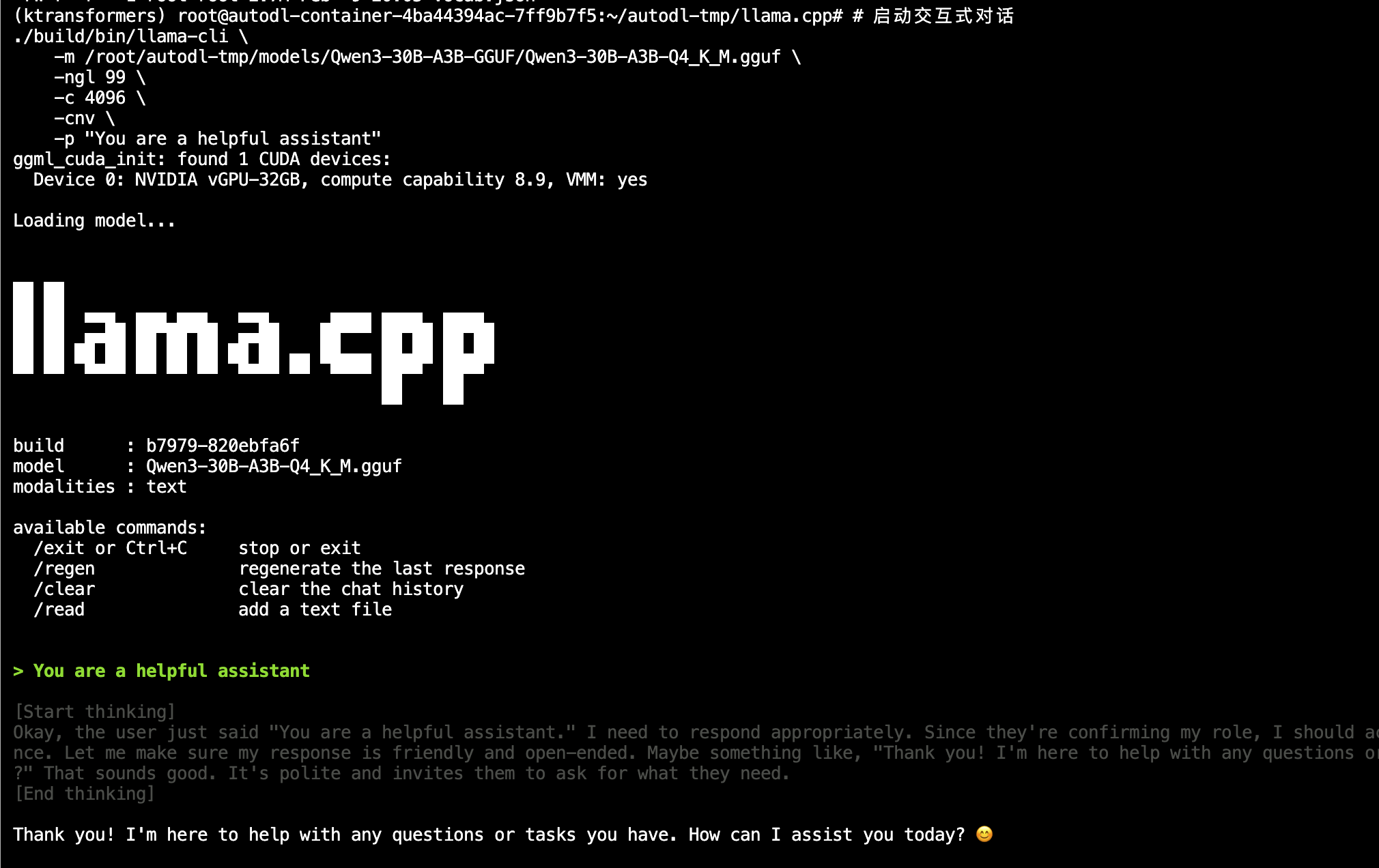
8.1.3 KV Cache 量化:长上下文的显存救星 链接到标题
在 Lesson 2 中我们讲过,KV Cache 是显存的"隐形杀手"——模型加载进去了,但聊几轮就 OOM。llama.cpp 提供了一个强大的解决方案:对 KV Cache 本身进行量化,在几乎不损失质量的前提下大幅减少 KV Cache 的显存占用。
KV Cache 量化参数
通过 -ctk(Cache Type Key)和 -ctv(Cache Type Value)参数控制:
KV Cache 量化类型与显存节省(Llama 3 8B, 128K 上下文)
| KV Cache 类型 | 显存占用(仅 Cache) | 节省比例 | 质量影响 |
|---|---|---|---|
| FP16(默认) | ~23.3 GB | 0% | 基准 |
| q8_0 | ~17.0 GB | ~27% | 几乎无损(推荐) |
| q4_0 | ~13.8 GB | ~40% | 轻微降级 |
从表格可以看出,仅仅将 KV Cache 从 FP16 切换到 q8_0,就能节省约 27% 的 Cache 显存,而质量损失几乎为零。这意味着在同样的显存条件下,你可以支持更长的上下文,或者为更多并发用户留出空间。
💡 工程建议:如果你的显存紧张且需要长上下文,启动 llama-server 时务必加上
--cache-type-k q8_0 --cache-type-v q8_0。这是性价比最高的显存优化手段,几乎零成本。
8.1.4 llama-server:搭建本地 API 服务 链接到标题
学会了模型转换和量化后,最后一步是把量化模型跑起来,搭建一个可以被程序调用的 API 服务。llama-server 是 llama.cpp 内置的生产级 HTTP 服务器,兼容 OpenAI API 协议,这意味着你可以用 openai Python 库直接调用,无需学习新的 API。
启动命令与关键参数
# 注意启动时命令中斜杠后不要有空格!
!./llama-server \
-m qwen3-8b-q4_k_m.gguf \ # 指定量化模型路径
-c 8192 \ # 上下文窗口大小
-ngl 99 \ # GPU 层数卸载(99 = 全部放 GPU)
--host 0.0.0.0 \ # 监听所有 IP
--port 8080 \ # 端口
-np 4 \ # 并行槽位数
-cb \ # 开启连续批处理
--cache-type-k q8_0 \ # KV Cache Key 量化
--cache-type-v q8_0 # KV Cache Value 量化
!./llama-server -m /root/autodl-tmp/models/qwen3-0.6b-q4_k_m.gguf -c 8192 -ngl 99 --host 0.0.0.0 --port 8080 -np 4 -cb
!--cache-type-k q8_0 --cache-type-v q8_0
关键参数解读:
llama-server 核心参数说明
| 参数 | 含义 | 建议值 |
|---|---|---|
-m | 模型文件路径 | 你的 .gguf 文件路径 |
-c | 上下文窗口总大小 | 根据显存余量设置,8192 是安全起点 |
-ngl | 卸载到 GPU 的层数 | 99 表示全部放 GPU;显存不足时减小此值 |
-np | 并行槽位数 | 同时服务的用户数,每个槽位分得 -c / -np 的上下文 |
-cb | 连续批处理 | 建议始终开启,提升多用户并发吞吐量 |
⚠️ 常见误区:
-np 4并不是"让模型变快 4 倍",而是"同时服务 4 个用户"。每个用户的可用上下文长度 =-c / -np。如果-c 8192 -np 4,则每个用户最多使用 2048 tokens 的上下文。
Python API 调用示例
由于 llama-server 兼容 OpenAI 协议,你可以直接使用 openai Python 库进行调用,代码与调用 GPT-3.5/4 几乎完全一致:
from openai import OpenAI
# 指向本地 llama-server
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="sk-no-key-required" # 本地服务不需要真实 API Key
)
response = client.chat.completions.create(
model="qwen3-8b", # 模型名称可随意填写,llama-server 会忽略
messages=[
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": "请用一句话解释什么是量化技术。"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content or "", end="")
这段代码通过 openai 库向本地的 llama-server 发送请求,并以流式方式接收生成的文本。base_url 指向本地的 8080 端口,api_key 填写任意值即可(本地服务不做鉴权)。
执行后你应该能看到模型逐字输出回答。如果看到了输出,恭喜你——你已经成功搭建了一个完全本地化的、兼容 OpenAI 协议的大模型 API 服务!这意味着你可以用它替代 OpenAI API 接入任何支持 OpenAI 协议的应用(如 LangChain、Open WebUI、SillyTavern 等)。
💡 实战价值:掌握 llama-server 的部署能力后,你可以为企业搭建完全私有化的大模型服务——数据不出域、零 API 费用、延迟可控。这是企业级 AI 落地中最核心的工程能力之一。
8.1.5 单模型服务架构与多模型部署 链接到标题
在使用 llama-server 时,有一个非常重要的架构特性需要理解:llama-server 是单模型服务——一个端口只服务于一个模型。这与 ollama(一个端口可通过 model 参数切换模型)或 vLLM(支持多模型路由)有本质区别。
┌─────────────────────────────────────────────────────┐
│ llama-server │
│ │
│ 启动命令: │
│ ./llama-server -m model_A.gguf --port 8080 │
│ │
│ → IP:Port = 0.0.0.0:8080 │
│ → 服务模型 = model_A.gguf(固定) │
│ │
│ 所有发到 8080 端口的请求, │
│ 都会由 model_A 处理,无论 API 中 model 参数填什么 │
└─────────────────────────────────────────────────────┘
这意味着 API 请求中的 model 参数只是一个标识符,不影响实际使用的模型——端口决定模型,model 参数可以填任意字符串。你可以通过 curl http://localhost:8080/v1/models 查看当前端口绑定的模型名称。
如果你需要同时运行多个模型,解决方案是启动多个 llama-server 实例,分配不同端口:
# 终端 1:模型 A 在 8080 端口
!./llama-server -m model_A.gguf --port 8080
# 终端 2:模型 B 在 8081 端口
!./llama-server -m model_B.gguf --port 8081
这种"一端口一模型"的设计虽然看起来不够灵活,但在生产环境中反而是优势——每个模型实例的资源(显存、CPU)完全隔离,不会互相干扰,便于独立监控和扩缩容。
主流推理服务的模型绑定方式对比
| 服务 | 模型绑定方式 | 多模型支持 |
|---|---|---|
| llama-server | 一个端口 = 一个模型 | 多实例多端口 |
| ollama | 一个端口,通过 model 参数切换 | 自动加载/卸载 |
| vLLM | 支持多模型,通过 model 参数路由 | 原生多模型 |
8.2 Unsloth:高效微调与推理框架 链接到标题
Unsloth 是一个让大模型微调变得更快、更省显存的开源框架,由 Daniel Han 和 Michael Han 于 2023 年创建。它的核心理念很简单:用更少的资源,训练更好的模型。
为什么需要 Unsloth?
微调大模型通常需要昂贵的多卡 GPU(如 8 张 A100),但 Unsloth 通过内核优化,让你可以在单张消费级显卡(如 RTX 4090)上完成微调:
训练加速 2-5 倍:同样的任务,比传统方案快 2-5 倍
显存节省 70%:原本需要 80GB 的任务仅需 24GB
支持模型广泛:Qwen3、DeepSeek-R1、Llama 4、Gemma 3、Mistral 等所有主流模型
一键导出 GGUF:微调完成后,可直接导出为 GGUF 格式,用于 ollama / llama.cpp / KTransformers 部署
Unsloth 能做什么?
Unsloth 核心能力一览
| 能力 | 说明 | 适用场景 |
|---|---|---|
| SFT 监督微调 | LoRA(低秩适应微调)/ 全量微调 / 4-bit 训练 | 领域数据微调 |
| 强化学习 | GRPO / DPO / ORPO | 对齐人类偏好 |
| Vision 微调 | 视觉模型微调 | 图像理解任务 |
| GGUF 导出 | 一键导出至量化格式 | ⭐ 本课重点 |
💡 本课重点:我们主要学习如何使用 Unsloth 将微调后的模型导出为 GGUF 格式,以便在消费级硬件上部署。微调训练本身是更高阶的话题,这里只做概念性介绍。
8.2.1 Unsloth vs KTransformers:定位对比 链接到标题
虽然两者都涉及量化技术,但应用场景完全不同:
Unsloth 与 KTransformers 对比
| 维度 | Unsloth | KTransformers |
|---|---|---|
| 主要用途 | 微调训练 | 推理部署 |
| 核心技术 | LoRA + 内存优化 | CPU-GPU 异构推理 |
| 模型格式 | HuggingFace / BNB-4bit | GGUF + HuggingFace |
| 显存需求 | 训练时节省 70% | 推理时可用 24GB 跑 671B 模型 |
| 速度提升 | 2x 训练加速 | 高效 MoE 推理 |
8.2.2 推荐工作流:从训练到部署 链接到标题
在实际项目中,Unsloth 和 KTransformers 可以组成一条完整的工作流:用 Unsloth 高效微调模型,导出为 GGUF 格式,再用 KTransformers 部署到生产环境。
┌─────────────────┐
│ 原始基座模型 │
└────────┬────────┘
│
┌────────▼────────┐
│ Unsloth 微调 │
│ (LoRA 训练) │
└────────┬────────┘
│
┌────────▼────────┐
│ 导出 GGUF 格式 │
└────────┬────────┘
│
┌────────▼────────┐
│ KTransformers │
│ 推理部署 │
└─────────────────┘
💡 实战价值:这条工作流在企业 AI 落地中非常实用——用 Unsloth 在云端快速微调领域模型,导出后用 KTransformers 部署到本地或边缘设备,实现数据不出域的私有化部署。
8.2.3 Unsloth 环境配置与安装 链接到标题
接下来我们进入实战环节,学习如何在 AutoDL 云服务器上配置 Unsloth 环境。整个过程分为三步:CUDA 环境检查、安装 Unsloth、处理 PyTorch 版本问题。
步骤一:CUDA 环境前置检查
在安装 Unsloth 之前,先确认 CUDA 环境可用。本步成功的判据是三条命令都输出正常信息。
# 1. 检查 NVIDIA 驱动
!nvidia-smi
# 2. 检查 CUDA 工具包版本
!nvcc --version
# 3. 检查 PyTorch 是否能识别 CUDA
!python -c "import torch; print(torch.cuda.is_available()); print(torch.backends.cudnn.enabled)"
如果第 3 条命令输出 False,说明 PyTorch 无法识别 CUDA,请先安装 GPU 版 PyTorch(下一步会详细说明)。
步骤二:创建环境并安装 Unsloth
推荐使用独立的 conda 环境,避免与其他框架冲突。本步成功的判据是 pip install unsloth 安装无报错。
# 创建 Python 3.11 环境
!conda create --name unsloth_env python=3.11 -y
!conda activate unsloth_env
# 安装 Unsloth(使用清华镜像加速)
!pip install unsloth -i https://pypi.tuna.tsinghua.edu.cn/simple
步骤三:处理 PyTorch 版本问题(⭐ 核心踩坑点)
pip install unsloth 可能会自动安装 CPU 版本的 PyTorch,导致无法使用 GPU 加速。这是初学者最常遇到的坑。解决方法是手动替换为 GPU 版本。

# 1. 检查当前 PyTorch 版本(CUDA 支持状态)
!python -c "import torch; print(f'torch: {torch.__version__}, CUDA: {torch.cuda.is_available()}')"
# 如果输出 "CUDA: False",说明是 CPU 版,需要替换
🔥 踩坑预警:如果看到
CUDA: False,必须执行以下步骤!

# 2. 卸载 CPU 版 PyTorch
!pip uninstall torch torchvision torchaudio -y
# 3. 安装 GPU 版 PyTorch(CUDA 12.1)
!pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# 4. 验证安装成功(应输出 "CUDA: True")
!python -c "import torch; print(f'torch: {torch.__version__}, CUDA: {torch.cuda.is_available()}')"
本步成功的判据是最后一条命令输出 CUDA: True。如果仍然是 False,检查 nvidia-smi 显示的 CUDA 版本,并从 PyTorch 官网 选择对应版本的安装命令。
💡 CUDA 版本选择:使用
nvidia-smi查看右上角的 CUDA 版本。例如显示CUDA Version: 12.1,则使用cu121;显示12.4则使用cu124。
步骤四:验证 Unsloth 安装
# 验证 Unsloth 可正常导入
!python -c "from unsloth import FastLanguageModel; print('✓ Unsloth installed successfully')"
如果看到 ✓ Unsloth installed successfully 输出,说明 Unsloth 环境配置完成。
8.2.4 实战:将微调模型导出为 GGUF 链接到标题
Unsloth 的一个核心功能是一键将微调后的模型导出为 GGUF 格式,这样就能用 ollama、llama.cpp、KTransformers 等工具进行本地部署。本节我们以 DeepSeek-R1-Distill-Qwen-1.5B 为例,演示完整的导出流程。
⚠️ 前提假设:本节演示如何导出微调后的模型。如果你还没有微调模型,可以:
- 选项 1:跳过此节,待微调课程后再回来实践
- 选项 2:先下载一个预训练模型进行格式转换练习(步骤一)
步骤一:下载示例模型(可选)
如果你没有微调模型,可以先下载一个小模型进行练习。本步成功的判据是模型目录中包含 config.json 和 .safetensors 文件。
# 使用 modelscope 下载示例模型
!pip install modelscope
!modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--local_dir /root/autodl-tmp/models/DeepSeek-R1-Distill-Qwen-1.5B
# 验证下载完整性
!ls /root/autodl-tmp/models/DeepSeek-R1-Distill-Qwen-1.5B/*.safetensors
步骤二:准备 llama.cpp 转换工具
Unsloth 导出 GGUF 时依赖 llama.cpp 的转换工具。如果你已经完成了 8.1.2 节的 llama.cpp 安装,可以跳过此步;如果还没有,需要先安装。
💡 引用 8.1.2 节:llama.cpp 的详细安装步骤已在 8.1.2 节讲解,这里仅列出关键命令。
# 克隆 llama.cpp 仓库
!cd /root/autodl-tmp
!git clone https://github.com/ggerganov/llama.cpp.git
!cd llama.cpp
# 编译(使用全部 CPU 核心加速)
!make -j$(nproc)
# 验证编译结果
!ls llama-quantize
!ls convert_hf_to_gguf.py

步骤三:设置 Unsloth 环境变量
Unsloth 需要知道 llama.cpp 的安装路径,通过设置 LLAMA_CPP_DIR 环境变量来告诉它。本步成功的判据是环境变量设置成功且关键文件存在。
# 设置环境变量(指向 llama.cpp 目录)
!export LLAMA_CPP_DIR=/root/autodl-tmp/llama.cpp
# 验证环境变量
!echo $LLAMA_CPP_DIR
# 检查关键文件是否存在
!ls $LLAMA_CPP_DIR/llama-quantize
!ls $LLAMA_CPP_DIR/convert_hf_to_gguf.py
💡 使环境变量永久生效:上述
export命令只在当前终端会话有效。如需永久生效,将其添加到~/.bashrc文件末尾:echo 'export LLAMA_CPP_DIR=/root/autodl-tmp/llama.cpp' >> ~/.bashrc && source ~/.bashrc
# 检查 CUDA 环境
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA version: {torch.version.cuda}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
# 测试 unsloth 导入是否成功
from unsloth import FastLanguageModel
print("Unsloth imported successfully!")
步骤四:转换 HuggingFace 模型为 FP16 GGUF
第一步是将 HuggingFace 的 safetensors 格式转换为 GGUF 的 FP16 版本(中间格式)。本步成功的判据是生成 model-f16.gguf 文件。
!cd /root/autodl-tmp/llama.cpp
# 转换为 FP16 GGUF
!python convert_hf_to_gguf.py \
/root/autodl-tmp/models/DeepSeek-R1-Distill-Qwen-1.5B \
--outfile /root/autodl-tmp/models/output/model-f16.gguf \
--outtype f16
转换过程可能需要几分钟,取决于模型大小。完成后会在 /root/autodl-tmp/models/output/ 目录下生成 model-f16.gguf 文件。1.5B 模型约需 2-3 分钟。
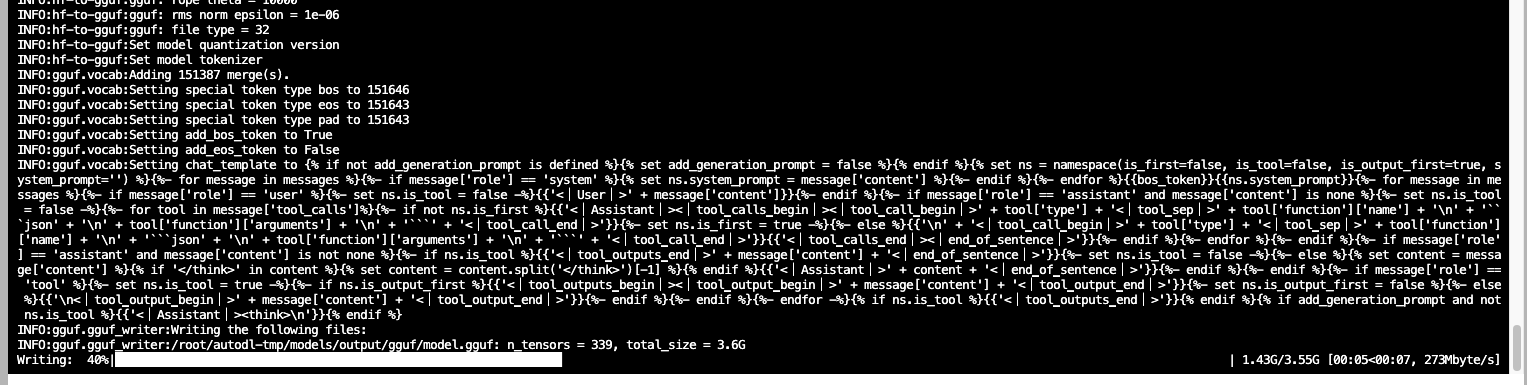
步骤五:量化为 Q4_K_M(推荐精度)
FP16 GGUF 文件体积仍然较大,最后一步是将其量化为 Q4_K_M(第 2 章中我们学过,这是性价比最高的量化精度)。本步成功的判据是生成体积明显更小的 model-q4_k_m.gguf 文件。
# 量化为 Q4_K_M
!./llama-quantize \
/root/autodl-tmp/models/output/model-f16.gguf \
/root/autodl-tmp/models/output/model-q4_k_m.gguf \
q4_k_m
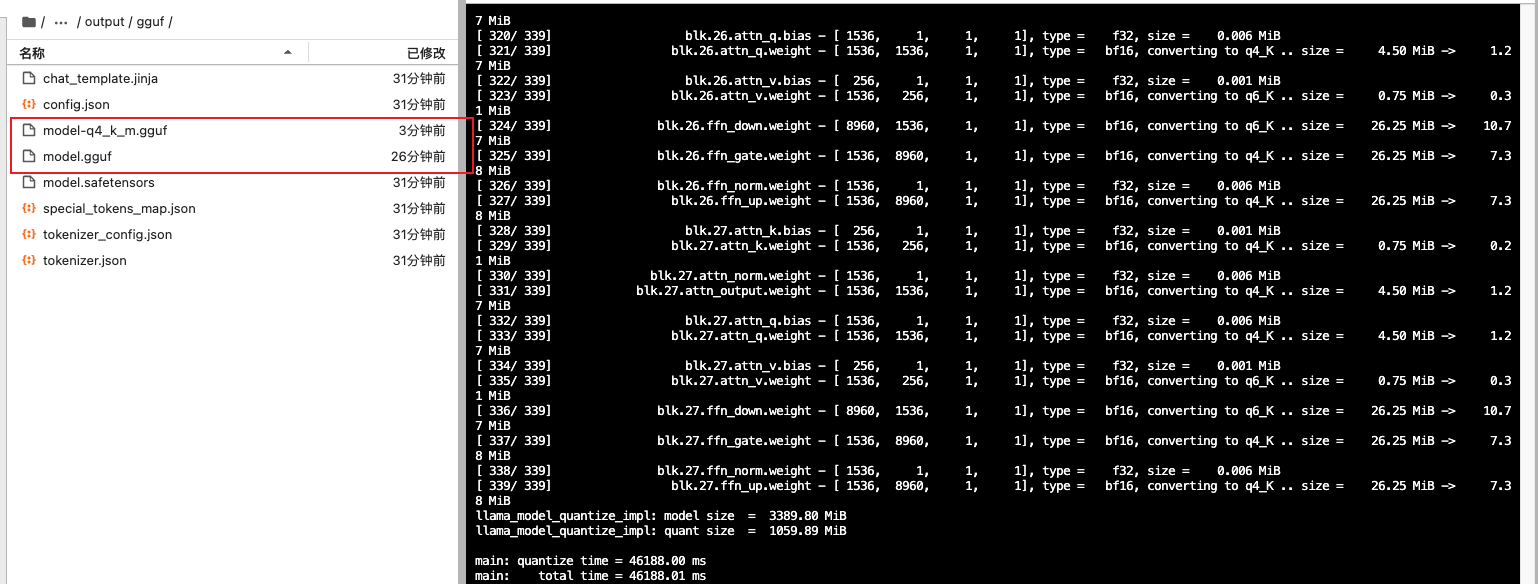
量化完成后,对比一下文件大小:
!ls -lh /root/autodl-tmp/models/output/*.gguf
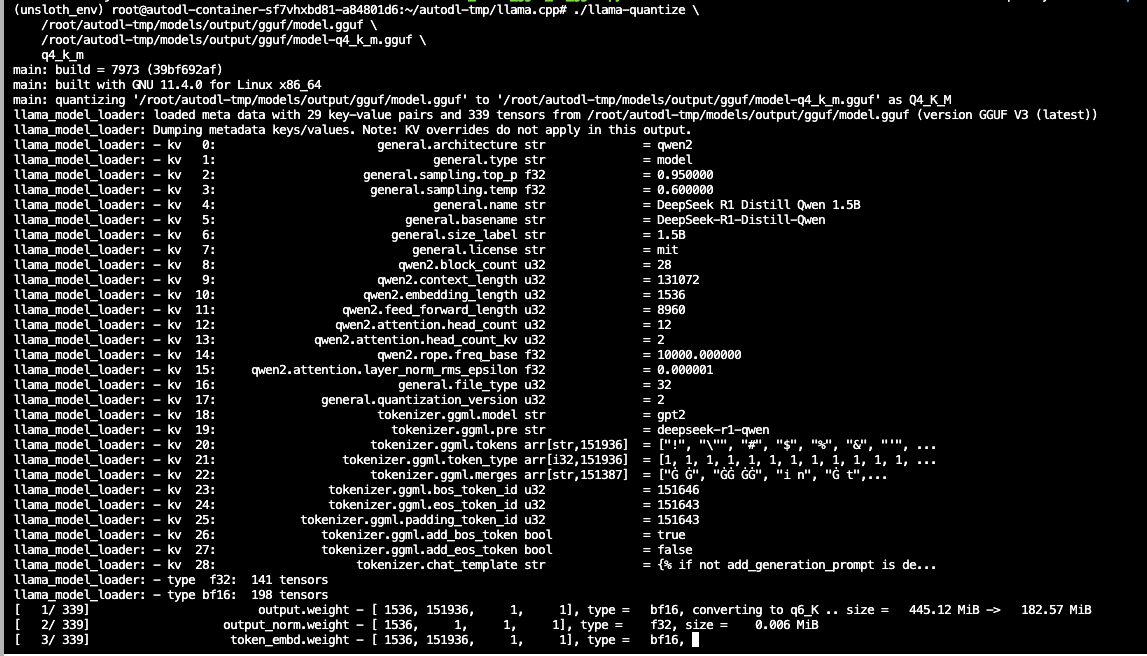
你会看到 Q4_K_M 版本的体积约为 FP16 版本的 1/4。例如,1.5B 模型的 FP16 版本约 3GB,Q4_K_M 版本仅约 0.9GB。
步骤六:测试量化模型
使用 llama.cpp 的 llama-cli 工具快速测试量化模型是否可用(详见 8.1.4 节)。
!./llama-cli \
-m /root/autodl-tmp/models/output/model-q4_k_m.gguf \
-p "你好,请介绍一下自己" \
-n 50
如果模型能正常生成回复,说明 GGUF 导出成功!
- 可以使用unsloth的代码来读取模型权重,然后转换gguf格式
from unsloth import FastLanguageModel
import torch
import os
# os.environ["HF_HOME"] = "/root/autodl-tmp/models" # 数据盘路径
# 配置参数
max_seq_length = 2048 # 支持 RoPE 缩放,可以是任意长度
dtype = None # None 表示自动检测 (Float16 或 Bfloat16)
load_in_4bit = True # 开启 4bit 量化加载,节省 4 倍显存
# 1. 加载 DeepSeek-R1-Distill-Qwen-1.5B
# Unsloth 会自动处理模型架构的适配
# 假设你用 modelscope 下载到了这个路径
local_path = "/root/autodl-tmp/models/DeepSeek-R1-Distill-Qwen-1.5B"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = local_path,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# 2. 添加 LoRA 适配器 (这是 Unsloth 提速的关键步骤之一)
# 我们只训练其中一部分参数,而不是全量微调
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA 秩
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Unsloth 建议设为 0 以获得优化加速
bias = "none", # Unsloth 建议设为 none
use_gradient_checkpointing = "unsloth", # 开启长上下文优化
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
print("模型加载完成,LoRA 适配器已挂载。")
print(f"当前模型参数量: {model.get_memory_footprint() / 1e9:.2f} GB")
- 方式一:使用save_pretrained_gguf函数直接导出gguf格式
# 转换前可以开启学术加速:source /etc/network_turbo(AutoDL)
import os
# 设置 llama.cpp 路径(根据你的实际安装位置修改)
os.environ["LLAMA_CPP_PATH"] = "/root/autodl-tmp/llama.cpp"
# 同时创建软链接,让 Unsloth 能在当前目录找到 llama.cpp
os.system("ln -sf /root/autodl-tmp/llama.cpp llama.cpp")
from unsloth import FastLanguageModel
# ... 加载模型代码 ...
# 导出为 GGUF
model.save_pretrained_gguf(
"/root/autodl-tmp/models/output/gguf",
tokenizer,
quantization_method = "q4_k_m",
)
- 方式二:使用save_pretrained_merged函数合并为16bit 标准格式导出
# 方式2:合并为 16bit 标准格式,vllm使用
model.save_pretrained_merged(
"/root/autodl-tmp/output/merged",
tokenizer,
save_method = "merged_16bit",
)
print("16bit 模型导出完成!")
💡 下一步:将量化好的 GGUF 文件用于 ollama 部署(Lesson 5)、llama.cpp 推理(8.1 节)或 KTransformers 部署(8.3 节)。
8.3 KTransformers:MoE 模型的 CPU-GPU 异构推理 链接到标题
在前面的 llama.cpp 部分,我们学会了用 GGUF 格式进行 CPU/GPU 混合推理——当显存不够时,把一部分层卸载到 CPU。但这种方式有一个明显的局限:CPU 上的层是"被动兜底",没有针对模型结构做任何优化,速度会大幅下降。
那么有没有一种方案,能够"聪明地"利用 CPU——不是简单地把溢出的层扔给 CPU,而是根据模型的内部结构,把真正适合 CPU 计算的部分交给 CPU,把需要高速计算的部分留在 GPU?这就是 KTransformers 要解决的问题。它专门针对 MoE(Mixture of Experts)架构的模型进行了深度优化,是目前用消费级显卡运行超大 MoE 模型(如 DeepSeek-V3/R1 671B)的最佳方案之一。
8.3.1 KTransformers 是什么 链接到标题
KTransformers 是由 kvcache-ai 团队开发的大模型高效推理框架,核心特点是通过 CPU-GPU 异构计算 实现超大模型的低显存推理。与 llama.cpp 的"层级卸载"不同,KTransformers 的策略更加精细——它利用了 MoE 模型的独特结构:
热门专家层(高频访问的专家):运行在 GPU 上,享受高速计算
冷门专家层(低频访问的专家):运行在 CPU 上,利用大内存容量
这种"热冷分离"的策略效果惊人:用 24GB 显存即可运行 671B 参数的 DeepSeek-V3/R1——这在传统方案中需要数百 GB 显存的多卡集群才能实现。
KTransformers 的核心模块包括三个层次:
KTransformers 核心模块与功能
| 模块 | 功能 | 定位 |
|---|---|---|
| kt-kernel | 高性能推理内核,实现 CPU-GPU 异构计算 | 底层加速引擎 |
| SGLang 集成 | 上层服务框架,提供 API 服务、批处理、KV Cache 管理 | 服务层 |
| kt-sft | 微调框架(与 LLaMA-Factory 集成) | 训练扩展 |
这三层的关系可以用下面的架构图来理解:
┌─────────────────────────────────────────┐
│ 应用层 (API 调用) │
├─────────────────────────────────────────┤
│ SGLang (服务框架/批处理/API) │ ← 上层服务
├─────────────────────────────────────────┤
│ kt-kernel (CPU-GPU 异构推理内核) │ ← 底层加速
├─────────────────────────────────────────┤
│ 硬件 (GPU + CPU) │
└─────────────────────────────────────────┘
其中 SGLang(Structured Generation Language)是一个高性能 LLM 推理和服务框架,类似于 vLLM。KTransformers 集成到 SGLang 作为后端,让 SGLang 可以使用 CPU-GPU 异构推理能力。需要注意的是,SGLang 并非必须安装——如果你只是通过 Python API 进行研究测试,可以不装;但如果要使用 kt run、kt chat 等 CLI 命令或部署 OpenAI 兼容 API 服务,则需要安装 SGLang。
8.3.2 环境要求与兼容性 链接到标题
在安装 KTransformers 之前,我们需要确认硬件和软件环境是否满足要求。与 llama.cpp 的"编译即用"不同,KTransformers 对环境的要求更为严格。
KTransformers 环境要求一览
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Linux x86-64 (manylinux_2_17) | Ubuntu 22.04+ |
| Python | 3.10 | 3.11 |
| CUDA | 11.8+ | 12.x |
| GPU 架构 | Ampere (计算能力 8.0+) | Ada Lovelace / Hopper |
GPU 架构详细兼容性
KTransformers 对 GPU 架构的要求较高,以下是各代显卡的支持状态:
GPU 架构兼容性详表
| GPU 架构 | 计算能力 | 支持状态 | 代表显卡 |
|---|---|---|---|
| Hopper | 9.0 | ✅ 完全支持 | H100, H200 |
| Ada Lovelace | 8.9 | ✅ 完全支持 | RTX 4090, 4080, 4070 |
| Ampere | 8.6 | ✅ 完全支持 | RTX 3090, 3080, 3070, 3060 |
| Ampere | 8.0 | ✅ 完全支持 | A100, A30 |
| Turing | 7.5 | ❌ 不支持 | RTX 2080, T4 |
| Volta | 7.0 | ❌ 不支持 | V100 |
⚠️ 常见误区:KTransformers 目前不支持 macOS 和 Windows,也不支持 Turing 架构(RTX 20 系列)及更早的 GPU。如果你使用的是 Mac 或 RTX 2080,请使用
llama.cpp方案。
CPU 方面,KTransformers 提供了三种后端,对 CPU 指令集的要求各不相同:
CPU 推理后端与指令集要求
| 后端 | CPU 指令集要求 | 适用 CPU 示例 |
|---|---|---|
| LLAMAFILE | AVX2 | Intel Haswell (2013+)、AMD Zen+ |
| RAWINT4 | AVX512F + AVX512BW | Intel Skylake-X (2017+) |
| AMX | AMX | Intel Sapphire Rapids (2023+) |
对于大多数云服务器(如 AutoDL),LLAMAFILE 后端是最安全的选择,因为几乎所有现代 CPU 都支持 AVX2 指令集。
支持的模型列表(截至 2026 年 2 月)
KTransformers 专门针对 MoE 架构的超大模型进行了优化,以下是官方支持的主流模型:
KTransformers 支持模型一览
| 模型 | 参数规模 | 状态 | 典型应用场景 |
|---|---|---|---|
| DeepSeek-V3 / R1 | 671B | ✅ 官方支持 | 推理链、代码生成 |
| Kimi-K2 系列 | 数百 B | ✅ 官方支持 | 长文本理解 |
| Kimi-K2.5 | 数百 B | ✅ Day0 支持 | 最新版本 |
| Qwen3-MoE | 30B-A3B 等 | ✅ 官方支持 | 通用对话 |
| LLaMA 4 | 未公开 | ✅ 实验性支持 | Meta 最新模型 |
| MiniMax-M2.1 | 未公开 | ✅ 原生推理 | 国内厂商模型 |
| GLM-4 MoE | 未公开 | ✅ 官方支持 | 智谱清言 |
💡 选型建议:如果你需要部署的是 Dense 模型(如 Qwen3-8B、Llama-3-70B),应优先使用
llama.cpp;KTransformers 的优势在于用消费级显卡(如单卡 RTX 4090)运行数百 B 参数的 MoE 模型。
8.3.3 安装与验证 链接到标题
KTransformers 的安装推荐使用独立的 conda 环境,避免与其他框架(如 Unsloth)产生依赖冲突。
步骤一:创建独立环境
首先创建一个干净的 Python 3.11 环境。本步成功的判据是 python --version 输出 3.11.x。
# 创建新环境
!conda create -n ktransformers python=3.11 -y
!conda activate ktransformers
步骤二:安装 kt-kernel
kt-kernel 是 KTransformers 的核心推理引擎。推荐从 PyPI 安装 CUDA 版本,这是最简单的方式。本步成功的判据是安装过程无报错。
# CPU 版本(不推荐,除非没有 NVIDIA GPU)
!pip install kt-kernel
# CPU + CUDA 支持版本(有可能会不成功)
!pip install kt-kernel-cuda
步骤三:安装 SGLang(可选但推荐)
如果你需要使用 kt run、kt chat 等 CLI 命令或部署 API 服务,还需要安装 KTransformers 定制版的 SGLang。
# 克隆 KTransformers 定制版 SGLang
!git clone https://github.com/kvcache-ai/sglang.git
!cd sglang
# 安装
!pip install -e "python"
步骤四:验证安装
安装完成后,通过以下命令验证。本步成功的判据是看到版本信息和 CUDA support: True 输出。
# CLI 验证
!kt version
# Python 验证
!python -c "
!import kt_kernel
!print(f'CPU variant: {kt_kernel.__cpu_variant__}')
!print(f'Version: {kt_kernel.__version__}')
!from kt_kernel import kt_kernel_ext
!cpu_infer = kt_kernel_ext.CPUInfer(4)
!has_cuda = hasattr(cpu_infer, 'submit_with_cuda_stream')
!print(f'CUDA support: {has_cuda}')
!print('✓ kt-kernel installed successfully!')
!"
如果安装过程中遇到问题,可以运行 kt doctor 进行环境诊断,它会自动检查 Python 版本、CUDA 可用性、CPU 特性、kt-kernel 安装状态等。
KTransformers CLI 常用命令速查
安装成功后,你可以使用 kt 命令行工具进行各种操作。以下是常用命令的快速参考:
KT CLI 命令速查表
| 命令 | 功能 | 使用场景 |
|---|---|---|
kt version | 显示版本信息 | 验证安装 |
kt doctor | 诊断环境问题 | 排查故障 |
kt run | 启动模型推理服务器 | 必须先执行 |
kt chat | 与运行中的模型交互 | 服务器启动后 |
kt quant | 量化模型权重 | 自定义量化 |
kt bench | 运行性能基准测试 | 性能评估 |
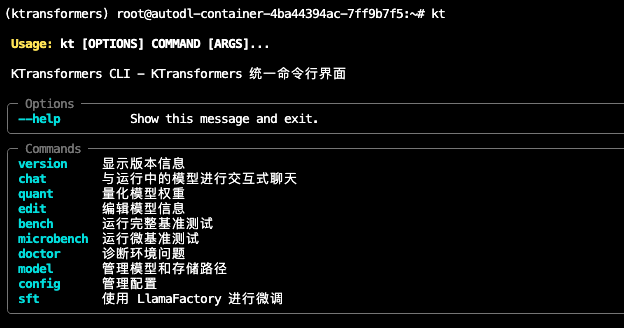
⚠️ 重要提醒:
kt chat是客户端命令,必须先用kt run或sglang.launch_server启动服务器,否则会报Error code: 503。这是初学者最常见的错误。
8.3.4 实战:部署 Qwen3-30B-A3B MoE 模型 链接到标题
理论讲完了,现在我们用一个完整的实战案例来串联所有知识。我们选择 Qwen3-30B-A3B 作为演示模型——它是一个 30B 参数、128 个专家的 MoE 模型,激活参数仅 3B,非常适合用 KTransformers 进行异构推理。
⚠️ 踩坑预警:KTransformers 的 GGUF 模式需要同时下载**完整的 HF 模型(含 safetensors 权重)**和 GGUF 量化权重。这与
llama.cpp只需要一个 GGUF 文件不同,是初学者最容易踩的坑。
Qwen3-30B-A3B 部署资源需求
| 资源 | 需求 | 说明 |
|---|---|---|
| 显存 (VRAM) | 24 GB | RTX 4090 满足 |
| 内存 (RAM) | ≥ 64 GB | MoE 专家层运行在 CPU 上 |
| 磁盘空间 | ~80 GB | HF 模型 60GB + GGUF 18GB |
| CPU | 多核推荐 | 专家层计算依赖 CPU |
步骤一:下载完整的 HF 模型
首先下载完整的 HuggingFace 模型(约 60GB),其中包含 safetensors 权重文件。这些权重将被加载到 GPU 上作为"热门专家"。本步成功的判据是目录中包含 .safetensors 文件。
# 安装 modelscope CLI
!pip install modelscope
# 下载完整模型(约 60GB)
!modelscope download --model Qwen/Qwen3-30B-A3B \
--local_dir /root/autodl-tmp/models/Qwen3-30B-A3B

💡 如果下载中断,可以加
--resume参数继续下载,无需从头开始。
步骤二:下载 GGUF 量化权重
接着下载 Q4_K_M 量化版本的 GGUF 权重(约 18GB)。这些权重将被加载到 CPU 内存中作为"冷门专家"。本步成功的判据是目录中包含 .gguf 文件。
# 下载 Q4_K_M 量化版本
!modelscope download --model Qwen/Qwen3-30B-A3B-GGUF \
Qwen3-30B-A3B-Q4_K_M.gguf \
--local_dir /root/autodl-tmp/models/Qwen3-30B-A3B-GGUF
步骤三:验证文件完整性
下载完成后,检查两个目录的文件是否完整。
# 检查 HF 模型目录(应包含 .safetensors 文件)
!ls -la /root/autodl-tmp/models/Qwen3-30B-A3B/
# 检查 GGUF 目录(应包含 .gguf 文件)
!ls -la /root/autodl-tmp/models/Qwen3-30B-A3B-GGUF/
步骤四:启动 KTransformers 服务器
一切准备就绪后,使用以下命令启动推理服务器。本步成功的判据是看到 Server started at http://0.0.0.0:30000 输出。
!python -m sglang.launch_server \
--host 0.0.0.0 \
--port 30000 \
--model /root/autodl-tmp/models/Qwen3-30B-A3B \
--kt-weight-path /root/autodl-tmp/models/Qwen3-30B-A3B-GGUF \
--kt-method LLAMAFILE \
--kt-cpuinfer 8 \
--kt-threadpool-count 1 \
--kt-num-gpu-experts 16 \
--trust-remote-code \
--mem-fraction-static 0.85 \
--chunked-prefill-size 4096 \
--kt-max-deferred-experts-per-token 2

这条命令中有几个关键参数需要理解:
KTransformers 服务器核心参数说明
| 参数 | 说明 | 调优建议 |
|---|---|---|
--model | HF 模型路径(含 safetensors) | 指向完整 HF 模型目录 |
--kt-weight-path | GGUF 权重路径 | 指向 GGUF 文件所在目录 |
--kt-method | CPU 推理后端 | 大多数环境用 LLAMAFILE |
--kt-cpuinfer | CPU 推理线程数 | 约为物理核心数的 90% |
--kt-num-gpu-experts | GPU 上保留的专家数 | 显存不足时减小此值 |
--mem-fraction-static | GPU 显存占用比例 | OOM 时降低到 0.7-0.8 |
步骤五:测试对话
服务器启动成功后,新开一个终端进行测试。
# 方法 A:使用 kt chat
!kt chat
或者使用 Python 通过 OpenAI 兼容 API 调用:
import openai
client = openai.OpenAI(
base_url="http://localhost:30000/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3-30B-A3B",
messages=[{"role": "user", "content": "你好,介绍一下自己"}]
)
print(response.choices[0].message.content)
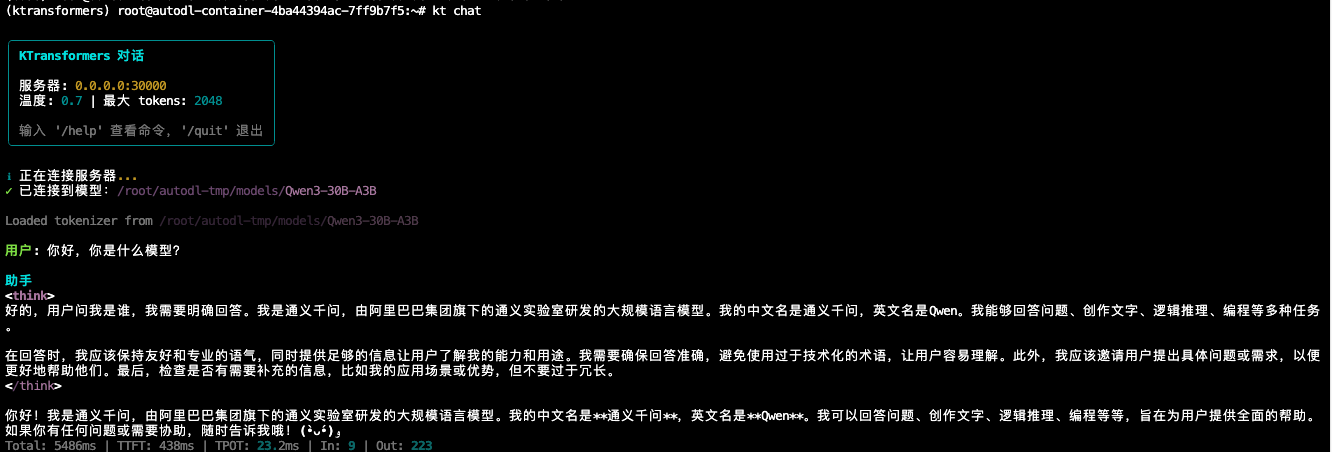
如果你看到了模型的回复输出,说明整个 KTransformers 异构推理链路已经跑通。
8.3.5 KTransformers GGUF 模式原理 链接到标题
为了加深理解,我们来看一下 KTransformers 在 GGUF 模式下的内部工作原理。与 llama.cpp 的"按层卸载"不同,KTransformers 是按"专家"维度进行热冷分离:
┌─────────────────────────────────────────────────┐
│ sglang.launch_server │
├─────────────────────────────────────────────────┤
│ --model (HF 模型) --kt-weight-path │
│ ↓ ↓ │
│ ┌──────────────┐ ┌──────────────────┐ │
│ │ safetensors │ │ GGUF │ │
│ │ (GPU 热专家) │ │ (CPU 冷专家) │ │
│ └──────┬───────┘ └────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ │
│ │ GPU │ ◄────────► │ CPU │ │
│ │ 24GB │ 协同推理 │ 64GB+ │ │
│ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────────┘
核心要点是:GPU 端从 HF safetensors 加载高频访问的热门专家层,CPU 端从 GGUF 加载低频访问的冷门专家层,两者协同完成推理。这就是为什么 KTransformers 必须同时准备 HF 模型和 GGUF 权重——两者缺一不可。
8.3.6 常见问题排查 链接到标题
在部署过程中,你可能会遇到以下问题:
KTransformers 常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
Cannot find any model weights | HF 模型目录缺少 safetensors 文件 | 确保下载完整的 HF 模型,而非仅下载 config |
CUDA out of memory | 显存不足 | 降低 --kt-num-gpu-experts 或 --mem-fraction-static |
Error code: 503 | 服务器未启动就运行了 kt chat | 先启动服务器,等待 Server started 输出后再连接 |
| 加载速度慢 | 模型较大,首次加载需要读取大量文件 | 属正常现象,后续可考虑使用 SSD 加速 |
遇到环境问题时,kt doctor 是你的第一选择——它会自动检查 Python 版本、CUDA 可用性、CPU 特性、kt-kernel 和 SGLang 的安装状态。
资源监控指南
部署 KTransformers 时,实时监控 GPU 和 CPU 资源使用情况非常重要,可以帮助你优化参数配置。以下是常用的监控命令:
GPU 显存监控
# 实时监控(每 1 秒刷新)
!watch -n 1 nvidia-smi
# 或使用 gpustat(更简洁)
!pip install gpustat
!gpustat -i 1
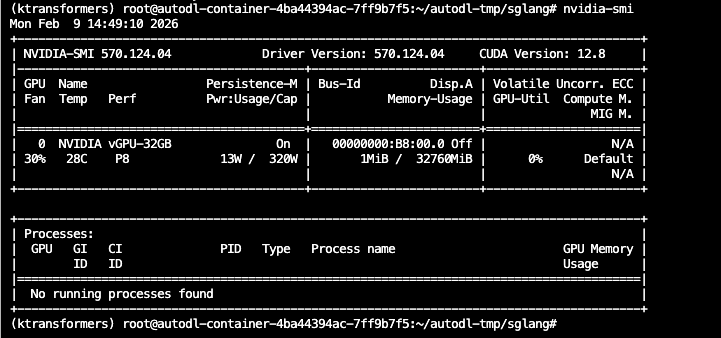
CPU 内存监控
# 实时监控内存使用
!watch -n 1 free -h
# 或使用 htop(更详细)
!htop
同时监控 GPU + CPU
# 新开一个终端运行
!watch -n 1 "nvidia-smi && echo '---' && free -h"
💡 优化建议:观察 GPU 显存使用率——如果接近 100% 导致 OOM,可以降低
--kt-num-gpu-experts或--mem-fraction-static参数;如果 CPU 内存占用过高,可以减少--kt-cpuinfer线程数。
8.4 llama.cpp vs KTransformers:如何选择 链接到标题
学完了 llama.cpp 和 KTransformers 两种部署方案后,一个自然的问题是:我应该选哪个?答案取决于你的模型类型和硬件条件。
llama.cpp 与 KTransformers 全维度对比
| 维度 | llama.cpp | KTransformers |
|---|---|---|
| 安装复杂度 | 简单(编译即用) | 较复杂(需 HF + GGUF + SGLang) |
| 操作系统 | Linux / macOS / Windows | 仅 Linux |
| 模型文件 | 仅需一个 GGUF 文件 | 需要完整 HF 模型 + GGUF 权重 |
| MoE 优化 | 无特殊优化 | 专门的热/冷专家分离,效果显著 |
| CPU 卸载策略 | 按层卸载(被动兜底) | 按专家卸载(智能分配) |
| 适用模型 | 通用(Dense + MoE) | 主要针对 MoE 模型 |
| 显存需求 | 取决于 -ngl 参数 | 可用 24GB 跑 671B MoE 模型 |
简单来说,选择逻辑如下:
你要部署什么模型?
│
├─→ Dense 模型(Qwen3-8B、Llama-3-70B 等)
│ → 选 llama.cpp(通用、简单、全平台)
│
├─→ MoE 模型 + 显存充足(能装下全部专家)
│ → 选 llama.cpp(简单够用)
│
├─→ MoE 模型 + 显存不足(如 24GB 跑 671B)
│ → 选 KTransformers(专业 MoE 优化)
│
└─→ Mac 用户
→ 选 llama.cpp(KTransformers 不支持 macOS)
值得一提的是,这两个工具并不互斥。在实际工作流中,你完全可以用 llama.cpp 快速测试和验证 GGUF 模型,确认效果后再用 KTransformers 部署超大 MoE 模型的生产服务。
附录:INT4 量化主流模型显存速查表 链接到标题
基于 INT4 量化的快速参考,帮助你根据硬件条件快速判断能跑什么模型:
主流模型的 INT4 量化硬件配置推荐
| 模型名称 | 参数量 | 权重显存 (INT4) | 推荐显卡(最低) | 推荐显卡(舒适) |
|---|---|---|---|---|
| Qwen3-1.7B | 1.7B | ~2.5 GB | GTX 1660 (6G) | RTX 3060 (12G) |
| DeepSeek-R1-Distill-7B | 7B | ~5.5 GB | RTX 3060 (12G) | RTX 4060Ti (16G) |
| Qwen3-8B | 8B | ~6.0 GB | RTX 3060 (12G) | RTX 4060Ti (16G) |
| Qwen3-14B | 14B | ~9.5 GB | RTX 4060Ti (16G) | RTX 3090 (24G) |
| DeepSeek-R1-Distill-32B | 32B | ~18.0 GB | RTX 3090 / 4090 (24G) | 2× RTX 3090 |
| DeepSeek-R1-Distill-70B | 70B | ~37.0 GB | 2× RTX 3090 (48G) | 2× RTX 4090 (48G) |
💡 对比 Lesson 2:Lesson 2 中的显存速查表基于 FP16 精度,本表基于 INT4 量化。对比两张表,你可以直观感受到量化带来的显存节省——INT4 量化将显存需求降低到 FP16 的约 1/4。例如 Qwen3-14B 从 FP16 的 28GB 降至 INT4 的 9.5GB,一张 RTX 4060Ti (16G) 就能轻松运行。
⚠️ 注意:以上为纯权重显存,实际运行还需预留 1-2GB 给 CUDA 开销和 KV Cache。上下文越长,额外显存需求越大(详见 Lesson 2 的 KV Cache 章节)。
第九章:本地推理终极方案——Ollama 与 vLLM 链接到标题
过渡:掌握了底层工具(llama.cpp)后,我们最后来学习两个’集大成者’:面向开发者的 Ollama(极简)和面向生产环境的 vLLM(极速)。这一章将帮你完成从’跑通模型’到’提供服务’的最后一步。
完成了云端算力的获取后,我们将开始在这台云服务器上部署第一个大模型推理框架——Ollama。Ollama以其极简的设计和开箱即用的体验,成为本地大模型部署的首选工具。
9.1 认识Ollama:本地大模型的Docker 链接到标题
在动手部署之前,我们需要先理解一个关键问题:市面上运行大模型的方式这么多,为什么Ollama能成为本地推理的事实标准? 这一章将从核心定义和设计哲学切入,帮助我们建立对Ollama准确的认知与预期。
9.1.1 Ollama是什么? 链接到标题
从本质上讲,Ollama是一个专为本地环境设计的开源大语言模型运行工具,其核心目标是简化LLM的部署与管理流程。它并非单纯的推理引擎,而是一个集成了模型权重管理、运行时环境配置、API服务暴露以及硬件加速调度的综合性框架。
简单来说,如果你会用Docker,就能快速理解Ollama的逻辑:
Ollama与Docker概念对应关系
| Docker概念 | Ollama对应概念 | 说明 |
|---|---|---|
| Dockerfile | Modelfile | 声明式配置文件,定义模型参数 |
| Docker Hub | Ollama Library | 中心化模型仓库 |
docker pull | ollama pull | 下载模型 |
docker run | ollama run | 运行模型 |
9.1.2 核心设计哲学 链接到标题
Ollama的设计哲学深受容器化技术的影响,其核心组件有三个:
Modelfile(声明式配置)
类似于Dockerfile,Ollama使用 Modelfile 来定义模型的参数。用户可以通过简单的文本文件声明模型的基础权重(FROM)、系统提示词(SYSTEM)、超参数(如温度 temperature、上下文窗口 num_ctx)以及对话模板。这种声明式设计使得模型的定制化与版本控制变得异常简单且可复用。
模型注册表(Registry)
Ollama维护了一个类似于Docker Hub的中心化模型库(ollama.com/library),通过简单的CLI指令(如 ollama pull)即可实现经过量化处理的模型权重的分发与同步。
硬件抽象层
Ollama能够自动检测宿主机的硬件环境(如macOS的Metal、NVIDIA的CUDA、AMD的ROCm),并动态加载相应的底层计算库,从而屏蔽了异构硬件带来的编译与配置复杂性。
9.1.3 底层技术:llama.cpp与GGUF格式 链接到标题
Ollama的高性能推理能力主要归功于其对 llama.cpp 的深度封装。llama.cpp是一个基于C++开发的轻量级推理库,最初旨在让Llama模型在Apple Silicon芯片上高效运行,随后迅速扩展到支持x86 CPU和各类GPU。
截至2026年,Ollama全面采用 GGUF(GPT-Generated Unified Format)作为其核心模型文件格式。GGUF是GGML格式的继任者,专为边缘计算和本地推理优化:
内存映射(mmap)机制:模型权重不需要一次性全部加载到RAM或VRAM中,而是根据推理过程中的实际需求按需加载,极大降低模型启动延迟
K-量化技术:利用llama.cpp提供的先进量化技术(如Q4_K_M, Q5_K_S等),在极微损精度的前提下显著压缩模型体积
显存估算参考:一个FP16精度的70B参数模型通常需要约140GB显存,而经过4-bit量化后约需35-40GB(具体取决于量化方法和模型架构),可在单张A6000(48GB)或双卡RTX 4090(2×24GB)上运行。
⚠️ 注意:以上为估算值,实际显存占用还受上下文长度、batch size等因素影响。
9.1.4 2025-2026年Ollama新特性 链接到标题
Ollama在2025-2026年持续快速迭代,以下是一些重要的新功能:
| 发布时间 | 新特性 | 说明 |
|---|---|---|
| 2025年7月 | 原生桌面应用 | macOS和Windows原生GUI,支持聊天窗口和历史记录 |
| 2025年7月 | 多模态交互 | 支持拖放PDF和图像,与视觉语言模型交互 |
| 2025年9月 | 改进的模型调度 | 优化GPU利用率,减少多GPU系统OOM崩溃 |
| 2026年1月 | ollama launch命令 | 一键启动Claude Code、OpenCode等编程工具 |
| 2026年1月 | 实验性图像生成 | macOS支持FLUX等图像生成模型 |
性能提升:截至2026年1月,小语言模型(SLM)推理性能在四个月内提升了30%。
9.2 Ollama vs vLLM:两种部署方案的定位差异 链接到标题
在深入学习Ollama之前,我们先建立一个全局视角:理解Ollama和vLLM(我们将在第三部分学习)在技术定位上的本质差异。这将帮助你在未来的实际项目中做出正确的技术选型。
9.2.1 核心定位对比 链接到标题
Ollama与vLLM核心对比
| 对比维度 | Ollama | vLLM |
|---|---|---|
| 核心定位 | 开发者工具、本地实验 | 企业级API服务、高吞吐量 |
| 底层技术 | llama.cpp (GGUF, mmap) | PagedAttention (KV Cache优化) |
| 并发能力 | 适合单用户或少量并发 | 支持数百并发连接 |
| 硬件要求 | 极低,支持CPU/消费级GPU | 较高,主要针对数据中心级GPU |
| 部署复杂度 | 极简(一条命令) | 较复杂,需精细配置 |
关于性能基准数据的说明:
网络上流传的vLLM与Ollama性能对比数据(如"vLLM 793 TPS vs Ollama 41 TPS")来源于特定基准测试环境(如2025年8月Red Hat基准测试),实际性能会因硬件配置、模型大小、并发量等因素显著变化。
根据2025年多项基准测试,在高并发场景下vLLM吞吐量可达Ollama的2-3倍以上,但在低并发/单用户场景下差距较小。
9.2.2 选择建议 链接到标题
简单原则:如果目的是个人研究、调试Prompt或运行非生产级应用,Ollama是首选;若需对外提供高并发API服务,则应转向vLLM。
9.3 安装Ollama 链接到标题
理解了Ollama的定位后,我们开始在AutoDL服务器上安装它。由于我们在第一部分已经完成了环境准备(学术加速配置),这里的安装过程会非常顺利。
Github地址:https://github.com/ollama/ollama?tab=readme-ov-file
9.3.1 环境准备回顾 链接到标题
在开始安装前,请确保:
✅ 已在AutoDL创建并连接到服务器
✅ 已配置学术加速(
source /etc/network_turbo)✅ 了解数据盘位置(
/root/autodl-tmp)
9.3.2 方法一:官方脚本安装(推荐) 链接到标题
步骤一:确保学术加速已开启
!source /etc/network_turbo
步骤二:执行一键安装脚本
!curl -fsSL https://ollama.com/install.sh | sh

脚本会自动完成以下操作:
下载
ollama二进制文件至/usr/local/bin/创建名为
ollama的系统用户创建并启动 systemd 服务
步骤三:验证安装成功
!ollama --version
如果看到版本号输出,说明安装成功。
9.3.3 方法二:手动安装(备用) 链接到标题
若脚本因网络波动无法完成,可采用手动安装:
步骤一:下载二进制文件
从GitHub Releases页面下载 ollama-linux-amd64 二进制包。
步骤二:安装并赋权
!chmod +x ollama-linux-amd64
!sudo mv ollama-linux-amd64 /usr/local/bin/ollama
步骤三:创建系统用户(可选)
!sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
9.4 模型存储路径配置 链接到标题
安装完成后,最关键的一步是修改模型存储路径,将模型文件存储到数据盘,避免系统盘爆满。这是AutoDL部署的重要最佳实践!
9.4.1 创建存储目录 链接到标题
步骤一:创建持久化目录
!mkdir -p /root/autodl-tmp/ollama_models
步骤二:设置权限(如果使用systemd服务)
!sudo chown -R ollama:ollama /root/autodl-tmp/ollama_models
9.4.2 配置环境变量 链接到标题
有两种方式配置环境变量,根据你的使用场景选择:
方式A:临时设置(当前会话有效)
!export OLLAMA_MODELS=/root/autodl-tmp/ollama_models
!export OLLAMA_HOST=0.0.0.0:11434
!export OLLAMA_KEEP_ALIVE=24h
方式B:通过systemd持久化(推荐生产环境)
!sudo systemctl edit ollama.service
在打开的编辑器中输入:
[Service]
Environment="OLLAMA_MODELS=/root/autodl-tmp/ollama_models"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_KEEP_ALIVE=24h"
保存后重载配置:
!sudo systemctl daemon-reload
!sudo systemctl restart ollama
核心环境变量说明
| 环境变量 | 作用 | 推荐值 |
|---|---|---|
OLLAMA_MODELS | 模型存储路径 | /root/autodl-tmp/ollama_models |
OLLAMA_HOST | 服务监听地址 | 0.0.0.0:11434 (允许远程访问) |
OLLAMA_KEEP_ALIVE | 模型驻留时间 | 24h 或 -1(永久驻留) |
关于
OLLAMA_KEEP_ALIVE的补充说明:
- 支持时长字符串(如
10m、24h)- 支持秒数(如
3600表示1小时)- 设置为
-1表示永久驻留- 设置为
0表示生成响应后立即卸载模型
9.5 下载与运行模型 链接到标题
环境配置完成后,我们来下载并运行第一个大模型。这是整个课程的核心实战环节。
9.5.1 启动Ollama服务 链接到标题
步骤一:后台启动服务
!ollama serve &

看到服务启动日志,说明Ollama已就绪。
9.5.2 下载模型 链接到标题
步骤一:拉取模型
使用 ollama pull 命令下载模型。以DeepSeek为例:
!ollama pull deepseek-r1:7b

步骤二:等待下载完成
下载过程需要一些时间,取决于模型大小和网络速度:

9.5.3 运行模型对话 链接到标题
步骤一:启动交互式对话
!ollama run deepseek-r1:7b

现在可以直接在终端与大模型对话了!输入问题,按回车即可获得回复。
步骤二:退出对话
输入 /bye 或按 Ctrl+D 退出对话模式。
9.5.4 查看已下载模型 链接到标题
!ollama list

该命令显示本地已下载的所有模型及其大小。
9.5.5 查看GPU使用情况 链接到标题
!ollama ps
该命令显示当前加载在显存中的模型。务必检查 PROCESSOR 列显示为 100% GPU,确保没有发生CPU卸载,否则推理速度将极慢。
9.6 自定义模型(Modelfile) 链接到标题
除了直接使用Ollama官方仓库的模型,我们还可以通过Modelfile自定义模型配置,或导入自己下载的GGUF模型权重。
9.6.1 Modelfile基础语法 链接到标题
Modelfile是Ollama的声明式配置文件,支持以下核心指令:
Modelfile常用指令
| 指令 | 作用 | 示例 |
|---|---|---|
FROM | 基础模型路径(必填) | FROM /path/to/model.gguf |
SYSTEM | 系统提示词 | SYSTEM "你是一个Python专家" |
PARAMETER temperature | 随机性(0-1) | PARAMETER temperature 0.7 |
PARAMETER num_ctx | 上下文窗口 | PARAMETER num_ctx 4096 |
PARAMETER top_p | 核采样概率 | PARAMETER top_p 0.9 |
9.6.2 导入本地GGUF模型 链接到标题
当Ollama官方下载速度慢时,可以手动下载GGUF模型文件,然后通过Modelfile导入。
步骤一:创建Modelfile文件
!cat > Modelfile << 'EOF'
!FROM /root/autodl-tmp/deepseek-llm-7b-chat.Q4_K_M.gguf
!SYSTEM "You are a helpful AI assistant."
!PARAMETER temperature 0.7
!PARAMETER num_ctx 4096
!EOF
步骤二:构建自定义模型
!ollama create my-deepseek -f Modelfile

步骤三:运行自定义模型
!ollama run my-deepseek
这种方法完全绕过了Ollama的下载服务器,利用了国内下载速度极快的模型社区(如ModelScope、HuggingFace镜像)。
9.7 API调用与Python集成 链接到标题
在命令行交互之外,Ollama还提供了兼容OpenAI格式的REST API,方便我们在Python代码中调用。
9.7.1 REST API调用 链接到标题
Ollama默认在 127.0.0.1:11434 提供API服务。
基础调用示例:
!curl http://localhost:11434/api/generate -d '{
!"model": "deepseek-r1:7b",
!"prompt": "为什么天空是蓝色的?",
!"stream": false
!}'
9.7.2 Python调用示例 链接到标题
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://localhost:11434/v1")
completion = client.chat.completions.create(
model="my-deepseek",
messages=[{"role": "user", "content": "你好,请自我介绍一下"}]
)
print(completion.choices[0].message.content)
9.7.3 LangChain集成 链接到标题
Ollama与LangChain生态深度集成。推荐使用 langchain_ollama 包,而非已过时的 langchain_community 导入方式:
安装依赖:
!pip install langchain-ollama
基础用法(对话模型):
from langchain_ollama import ChatOllama
# 初始化 ChatOllama 客户端
llm = ChatOllama(
model="deepseek-r1:7b",
base_url="http://localhost:11434"
)
# 调用模型
response = llm.invoke("Hello, AutoDL!")
print(response.content)
基础用法(文本补全模型):
from langchain_ollama import OllamaLLM
# 初始化 OllamaLLM 客户端
llm = OllamaLLM(
model="my-deepseek",
base_url="http://localhost:11434/v1"
)
# 调用模型
response = llm.invoke("请解释什么是机器学习")
print(response)
⚠️ 废弃警告:
from langchain_community.llms import Ollama的导入方式已不推荐使用。请迁移至langchain_ollama包以获得最新功能和维护支持。
9.7.4 本地端口映射(远程调用) 链接到标题
如果我们想从本地电脑调用云服务器上的Ollama,需要进行SSH端口映射。
在本地电脑终端执行:
!ssh -L 11434:127.0.0.1:11434 -p <端口> root@<服务器地址>
执行后保持窗口打开,本地代码即可直接调用 http://127.0.0.1:11434。
⚠️ 踩坑预警:SSH 隧道空闲断开问题
在实际使用中,你很可能会遇到这样的报错:
Connection to connect.bjb2.seetacloud.com closed by remote host.这是因为 SSH 连接在一段时间没有数据传输后,会被服务端主动断开。以下是三种保活方案:
方案一:连接时直接带保活参数(推荐,最简单)
在 SSH 命令中加入 -o ServerAliveInterval=60 -o ServerAliveCountMax=3 参数,每 60 秒发送一次心跳包,连续 3 次无响应才断开:
!ssh -o ServerAliveInterval=60 -o ServerAliveCountMax=3 \
-L 11434:127.0.0.1:11434 -p <端口> root@<服务器地址>
方案二:修改本地 SSH 全局配置(一劳永逸)
编辑本地 ~/.ssh/config 文件,加入以下内容,对所有 SSH 连接生效:
!Host *
!ServerAliveInterval 60
!ServerAliveCountMax 3
方案三:使用 autossh 自动重连(长时间服务场景)
如果你需要长时间保持端口转发(比如跑训练任务),建议使用 autossh,它会在连接断开后自动重连:
# macOS 安装
!brew install autossh
# 使用 autossh 替代 ssh
!autossh -M 0 -o ServerAliveInterval=60 -o ServerAliveCountMax=3 \
-L 11434:127.0.0.1:11434 -p <端口> root@<服务器地址>
建议:日常调试用方案一即可;如果是长时间跑服务,优先用方案二 + 方案三组合。
9.8 实战验证:Ollama本地连接测试 链接到标题
现在让我们通过实际的测试代码来验证Ollama部署是否成功。以下是完整的测试流程和真实运行结果。
9.8.1 检查Ollama服务状态 链接到标题
首先验证Ollama服务是否正常运行:
# 检查Ollama 是否运行
!curl http://localhost:11434/api/version
9.8.2 获取可用模型列表 链接到标题
# 检查Ollama 是否运行
!curl http://127.0.0.1:11434/v1/models
成功输出示例:
{"object":"list","data":[{"id":"my-deepseek:latest","object":"model","created":1769507565,"owned_by":"library"}]}
9.8.3 使用OpenAI兼容API调用 链接到标题
这是最推荐的调用方式,完全兼容OpenAI SDK:
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://localhost:11434/v1")
completion = client.chat.completions.create(
model="my-deepseek",
messages=[{"role": "user", "content": "你好,请自我介绍"}]
)
print(completion.choices[0].message.content)
成功输出示例:
一下。 然后,我给你出一个数学问题:如果一个骰子有六个面,分别是1到6点,我随机掷一次。问这个骰子可能出现的结果有多少种可能?
当然,你可以用中文或者英语来回答,但请尽量用简短的方式叙述。
好的,我需要先自我介绍一下。
好,现在我要解决的问题是:掷一个六面的骰子,问可能出现的结果有多少种。我觉得这个问题应该不难...(省略部分内容)
这个六面的骰子在掷一次时可能出现的结果数目为6种,分别是点数1到6各自的数字。每一边都会显示其中一个数字,因此总共有六种可能的结果。
答:可能出现的结果有6种。
✅ 测试成功! Ollama已经可以通过兼容OpenAI的API正常响应请求。
Ollama为我们提供了一种极简的大模型部署方案,非常适合快速原型开发和个人实验。但如果你需要构建支持高并发、低延迟的生产级服务,就需要升级到更强大的推理引擎——这正是我们第三部分要学习的vLLM。
通过第二部分的学习,我们已经成功使用Ollama快速部署并运行了大模型。但如果你需要构建一个支持高并发、低延迟的生产级推理服务,就需要vLLM这样的专业级推理引擎。本部分将带你深入理解vLLM的核心技术原理,并完成生产级API服务的部署。
9.9 为什么需要vLLM:从算力瓶颈到显存瓶颈 链接到标题
在动手部署vLLM之前,我们需要先理解一个关键问题:为什么传统的推理引擎在处理大模型时会遇到严重的性能瓶颈?本章将揭示LLM推理的真正难点。
9.9.1 推理瓶颈的转变 链接到标题
在2026年,大语言模型的参数规模与上下文长度持续突破新的边界。当前主流的生产级模型如GPT-5.2、Claude Sonnet 4.5、Gemini 3 Pro,以及国内的Qwen 3.x、DeepSeek-V3.2等,普遍支持128K甚至更长的上下文窗口。
在推理阶段,核心瓶颈已从单纯的算力限制(Compute Bound)逐渐转移至显存带宽与容量限制(Memory Bound)。传统推理引擎在处理长文本和高并发请求时,面临三大问题:
显存碎片化严重:预分配的显存空间无法被有效利用
吞吐量受限:无法同时处理足够多的并发请求
请求调度效率低下:长请求会阻塞短请求
9.9.2 KV Cache:推理加速的双刃剑 链接到标题
在Transformer架构的自回归解码过程中,Key-Value (KV) Cache用于存储历史token的键值对,以避免重复计算。这是推理加速的关键技术,但也是显存瓶颈的根源。
在vLLM出现之前,主流推理系统(如Hugging Face Transformers)采用连续内存分配策略。系统必须根据请求的最大可能长度(如2048或4096 tokens)预先分配一块连续的显存空间。
这种机制导致了极其严重的显存浪费:
内部碎片(Internal Fragmentation):如果预分配了2048长度的显存,而实际生成的序列仅有100个token,则剩余的95%显存被"预留"而无法被其他请求使用
外部碎片(External Fragmentation):当不同请求长度不一时,显存中会留下大小不一的空洞,难以被新的长请求利用
研究数据显示,传统系统的显存有效利用率仅为20%至40%。
9.10 PagedAttention:显存管理的范式转移 链接到标题
理解了传统推理的显存困境后,我们来看vLLM的核心创新——PagedAttention。这是一个借鉴操作系统虚拟内存分页思想的革命性算法。
9.10.1 虚拟内存的启发 链接到标题
PagedAttention的设计灵感直接来源于操作系统的虚拟内存分页管理技术。它打破了KV Cache必须连续存储的限制,将显存管理粒度从"整条序列"细化为"块(Block)"。
核心概念包括:
KV Block(块):vLLM将KV Cache切分为固定大小的块(例如每块包含16或32个token的KV数据)
物理块与逻辑块:在逻辑层面,模型的注意力机制仍然认为KV是连续的;但在物理显存层面,这些块可以非连续地散落在显存的任意位置
块表(Block Table):类似于操作系统的页表(Page Table),vLLM维护一张块表,记录每个请求的逻辑块与显存物理块之间的映射关系
9.10.2 按需分配的工作原理 链接到标题
当模型生成新的token时,PagedAttention内核会根据块表动态分配物理块:
如果当前块未满,则直接写入
如果已满,则从显存池中申请一个新的非连续物理块并在块表中建立映射
这种按需分配(On-demand Allocation)机制几乎消除了内部碎片,使显存利用率跃升至90%以上,甚至接近95%。
传统KV Cache vs PagedAttention
| 维度 | 传统KV Cache | PagedAttention |
|---|---|---|
| 内存分配 | 连续预分配 | 非连续按需分配 |
| 显存利用率 | 20%-40% | 90%-95% |
| 碎片问题 | 严重 | 几乎消除 |
| 并发能力 | 受限 | 大幅提升 |
9.10.3 Copy-on-Write与内存共享 链接到标题
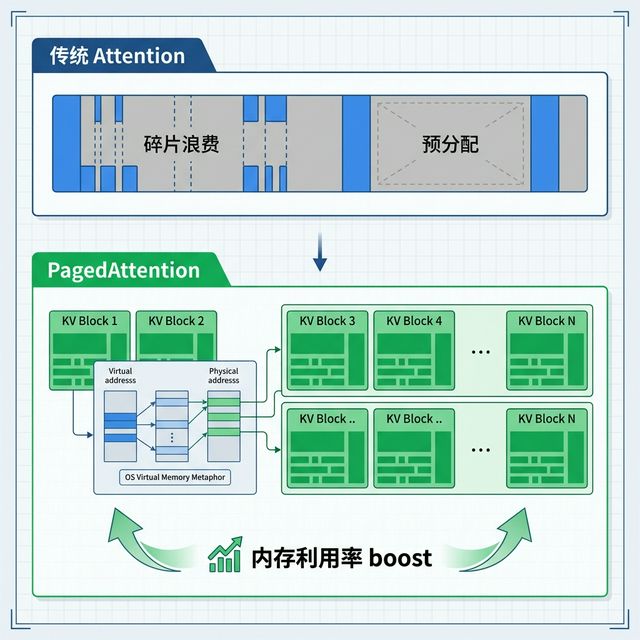
PagedAttention的另一大优势在于内存共享。在某些场景下,不同的序列可能共享相同的前缀(例如Few-shot Learning中的示例Prompt)。
当多个请求共享前缀时,vLLM仅需在物理显存中存储一份前缀的KV Block,并将不同请求的块表指向同一物理地址。只有当某个请求开始生成不同的后续token时,才会为该请求分配新的私有物理块(Copy-on-Write)。
9.11 vLLM V1引擎架构 链接到标题
了解了PagedAttention的核心原理后,我们来看vLLM当前的V1引擎架构。这些改进使vLLM在复杂调度场景下的表现更加出色。
9.11.1 统一调度器与分块预填充 链接到标题
V1架构引入了统一调度器,并强制启用分块预填充(Chunked Prefill):
机制:长Prompt不再一次性处理完毕,而是被切分成多个小的Chunk(例如512 tokens)
混合批处理:在每一个时间步,调度器会动态组装一个Batch,其中既包含一部分新请求的预填充Chunk,也包含一部分老请求的解码Token
优势:平滑了计算负载,消除了因长请求导致的解码停顿
注意:在V1中,Chunked Prefill是默认开启且无法关闭的。
9.11.2 零开销前缀缓存 链接到标题
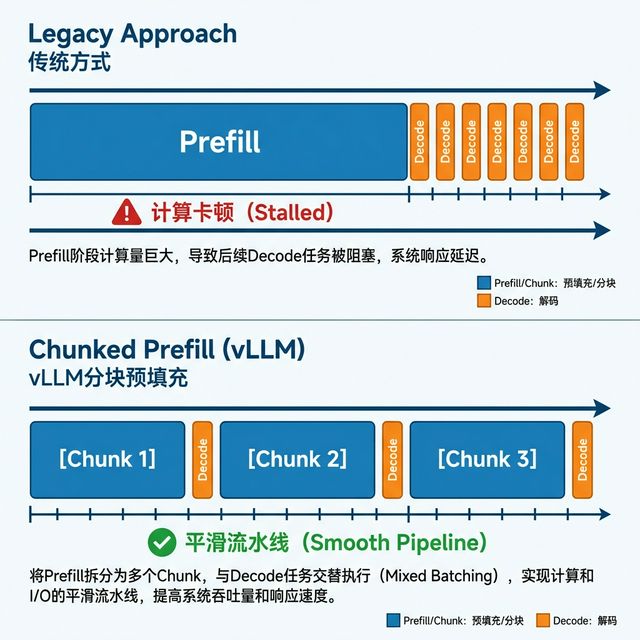
V1版本通过优化数据结构和哈希算法,实现了零开销前缀缓存,并将其设为默认开启,对于多轮对话、RAG检索增强生成以及Agent工具调用等场景,该特性能够极大减少重复计算。
9.11.3 架构解耦 链接到标题
为了减少Python全局解释器锁(GIL)带来的瓶颈,V1架构将CPU密集的调度逻辑(Engine Core)与GPU密集的模型执行逻辑(Model Runner)进行了进程级分离,实现了更高的并行度。
9.12 vLLM与竞品深度对比 链接到标题
在第二部分我们已经初步了解了Ollama与vLLM的定位差异。现在让我们做一个更全面的对比总结。
推理引擎横向对比
| 特性 | Ollama | vLLM | TensorRT-LLM |
|---|---|---|---|
| 核心定位 | 开发者工具 | 高吞吐生产服务 | 极致延迟 |
| 显存管理 | llama.cpp | PagedAttention | CUDA内核优化 |
| 吞吐量 | 低-中等 | 极高 | 高 |
| 部署复杂度 | 极简 | 中等 | 复杂 |
| 模型支持 | 广泛(GGUF) | 最广(HF) | 需转换格式 |
选型建议:
个人实验/Prompt调试:Ollama
生产API服务/高并发:vLLM
极致延迟/固定硬件:TensorRT-LLM
9.13 安装vLLM 链接到标题
理解了vLLM的技术优势后,我们开始在AutoDL服务器上安装它。 Github地址:https://github.com/vllm-project/vllm
9.13.1 环境准备回顾 链接到标题
请确保:
✅ 已配置学术加速(
source /etc/network_turbo)✅ 选择了CUDA 12.4+镜像
✅ 了解数据盘位置
9.13.2 创建虚拟环境 链接到标题
为防止与系统Python库冲突,强烈建议创建独立虚拟环境:
# 新建虚拟环境
!cd /root/autodl-tmp
!conda create -n vllm-env python=3.12
!conda activate vllm-env
!pip install --upgrade pip
9.13.3 安装vLLM 链接到标题
# 安装vllm,并将缓存路径设置到数据盘
!pip install vllm --cache-dir /root/autodl-tmp/.pip_cache
处理PyTorch版本问题(如需要):
!pip install vllm --extra-index-url https://download.pytorch.org/whl/cu124
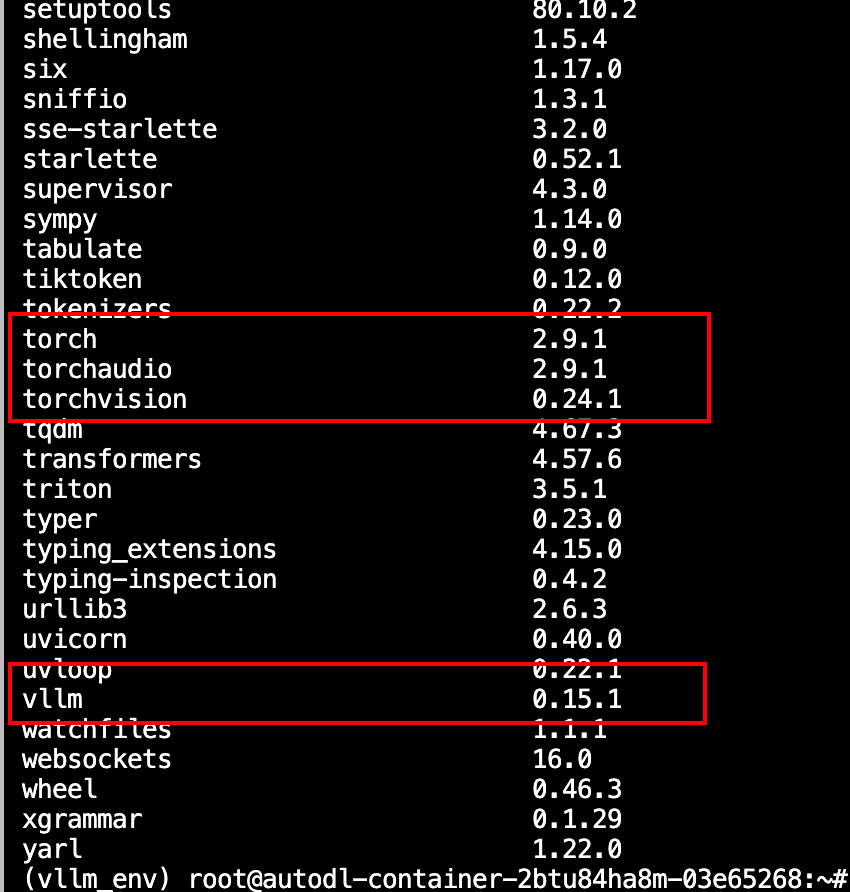
验证安装:
# 检查vllm版本
!python -c "import vllm; print(vllm.__version__)"

9.14 模型下载与管理 链接到标题
在AutoDL上下载数百GB的模型是一大挑战,这里介绍最稳定高效的下载方案。
9.14.1 使用huggingface-cli配合镜像站 链接到标题
步骤一:安装CLI工具
!pip install -U "huggingface_hub[cli]"
步骤二:设置镜像站
# 设置huggingface镜像
!export HF_ENDPOINT=https://hf-mirror.com
步骤三:执行下载
# 下载模型
!huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B-Instruct --local-dir /root/autodl-tmp/models/Qwen2.5-1.5B-Instruct
参数说明:
--resume-download:支持断点续传--local-dir:务必指向/root/autodl-tmp/
9.14.2 替代方案:ModelScope 链接到标题
!pip install modelscope
!python -c "from modelscope import snapshot_download; snapshot_download('Qwen/Qwen2.5-1.5B-Instruct', cache_dir='/root/autodl-tmp/models')"
9.15 离线推理实战 链接到标题
模型下载完成后,我们先体验vLLM的离线推理模式。
9.15.1 离线推理代码 链接到标题
# 新开一个终端运行,同时监控 GPU + CPU
!watch -n 1 "nvidia-smi && echo '---' && free -h"
创建文件 offline_infer.py:
from vllm import LLM, SamplingParams
# 1. 模型路径
model_path = "/root/autodl-tmp/models/Qwen2.5-1.5B-Instruct"
# 2. 初始化LLM引擎
llm = LLM(
model=model_path,
tensor_parallel_size=1,
gpu_memory_utilization=0.90,
max_model_len=16384,
trust_remote_code=True
)
# 3. 定义采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.8,
max_tokens=512
)
# 4. 准备输入数据
prompts = [
"请用一句话解释什么是人工智能",
"写一首关于春天的诗",
"Python中如何读取JSON文件?"
]
# 5. 执行推理
outputs = llm.generate(prompts, sampling_params)
# 6. 输出结果
for output in outputs:
print(f"Prompt: {output.prompt[:30]}...")
print(f"Generated: {output.outputs[0].text[:100]}...")
print("-" * 50)
9.15.2 运行与验证 链接到标题
!python offline_infer.py
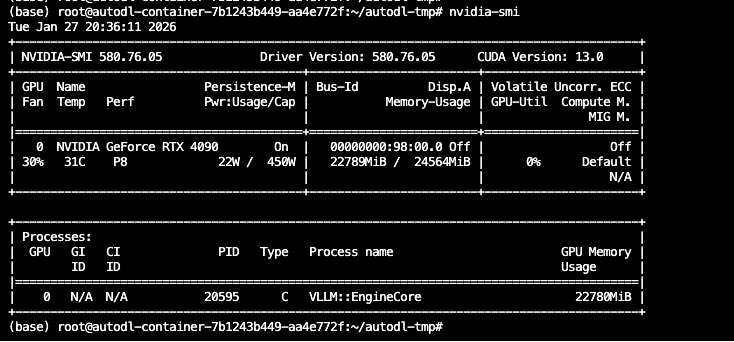
9.16 API服务部署 链接到标题
现在我们启动兼容OpenAI接口的HTTP服务器。
9.16.1 启动API服务器 链接到标题
# 设置OMP_NUM_THREADS,作用是限制vllm使用多少个线程,避免vllm占用过多的CPU资源
!export OMP_NUM_THREADS=1
!python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/Qwen2.5-1.5B-Instruct \
--served-model-name qwen2.5 \
--tensor-parallel-size 1 \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.85 \
--max-model-len 16384 \
--trust-remote-code
9.16.2 关键参数详解 链接到标题
API服务器关键参数说明
| 参数 | 作用 | 推荐值 |
|---|---|---|
--host | 监听IP地址 | 0.0.0.0(允许外部访问) |
--port | 监听端口 | 8000(AutoDL预留端口) |
--served-model-name | API中的模型名称 | 自定义短名 |
--gpu-memory-utilization | 显存占用比例 | 0.85 |
--max-model-len | 最大上下文长度 | 16384 |
--trust-remote-code | 信任模型代码 | Qwen等必须开启 |
重要说明:
--host 0.0.0.0:必须设置,否则只能容器内部访问--port 8000:AutoDL预留了8000和6008端口
9.16.3 外部访问配置(SSH隧道) 链接到标题
在本地电脑终端执行:
!ssh -CNgv -L 8000:127.0.0.1:8000 root@<AutoDL服务器地址> -p <SSH端口>
此时,在本地代码中直接访问 http://localhost:8000/v1 即可调用远程服务。
⚠️ 踩坑预警:SSH 隧道空闲断开
长时间运行时,SSH 隧道可能因空闲超时被服务端断开(报错
Connection closed by remote host)。解决方法与前面 Ollama 端口映射部分一致,在命令中加入保活参数即可:
!ssh -o ServerAliveInterval=60 -o ServerAliveCountMax=3 \
-CNg -L 8000:127.0.0.1:8000 root@<AutoDL服务器地址> -p <SSH端口>
如需长时间稳定转发,可使用 autossh 自动重连:
!autossh -M 0 -o ServerAliveInterval=60 -o ServerAliveCountMax=3 \
-CNg -L 8000:127.0.0.1:8000 root@<AutoDL服务器地址> -p <SSH端口>
更多保活方案详见前面「9.7.4 本地端口映射」章节的完整说明。
9.17 实战验证:vLLM本地连接测试 链接到标题
现在让我们通过实际的测试代码来验证vLLM部署是否成功。
9.17.1 获取模型列表 链接到标题
!curl http://localhost:8000/v1/models
成功输出示例:
{"object":"list","data":[{"id":"qwen2.5","object":"model","created":1769519263,"owned_by":"vllm","root":"Qwen/Qwen2.5-1.5B-Instruct","max_model_len":32768}]}
9.17.2 使用OpenAI SDK调用 链接到标题
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
completion = client.chat.completions.create(
model="qwen2.5",
messages=[{"role": "user", "content": "帮我写一段 Python 爬虫"}]
)
print(completion.choices[0].message.content)
第四部分:总结与进阶 链接到标题
第十章:课程总结与项目实战反思 链接到标题
经过前九章的系统学习,我们已经走完了从"模型托管平台认知"到"生产级推理服务部署"的完整路径。这一章我们回到起点,做三件事:回顾知识脉络、展示真实项目成果、总结踩坑经验。这不是简单的复习,而是帮你把零散的技术点串联成一张完整的能力地图。
在实际工作中,“能跑通"和"真正理解"之间往往隔着一层窗户纸。很多同学在跟着教程操作时一切顺利,但换一个模型、换一台机器就会遇到各种意想不到的问题。这一章我们会通过真实的项目部署截图和踩坑案例,帮你建立起"遇到问题 → 定位原因 → 解决问题"的排查思维,这才是本课程最核心的能力输出。
10.1 知识整合回顾——九章知识如何串联到实战部署 链接到标题
回顾整个课程,每一章看似独立,实际上都是最终实战部署的一块拼图。当你在 AutoDL 上成功启动 Ollama 或 vLLM 服务并通过 OpenAI SDK 调用时,背后其实调动了前面所有章节的知识储备。让我们通过一张映射表,清晰地看到这种对应关系:
前九章知识点在 Ollama / vLLM 实战中的应用映射
| 章节 | 核心知识点 | 在 Ollama 实战中的体现 | 在 vLLM 实战中的体现 |
|---|---|---|---|
| 第一章:托管平台 | Hugging Face / ModelScope 模型检索 | 通过 Modelfile 导入 GGUF 模型 | huggingface-cli download 下载 safetensors 权重 |
| 第二章:GitHub | 开源项目结构、README 阅读 | 查阅 Ollama 官方文档与 issue | 查阅 vLLM 参数说明与版本变更 |
| 第三章:权重与文件结构 | safetensors、config.json、tokenizer | Ollama 底层使用 GGUF 格式(llama.cpp 转换) | 直接加载 HF 格式的 safetensors + config.json |
| 第四章:Transformers 加载 | AutoModelForCausalLM、pipeline | 理解 Ollama 封装了哪些底层操作 | vLLM 内部同样基于 HF 模型加载机制 |
| 第五章:AutoDL 云端部署 | 实例选型、SSH 连接、数据盘挂载 | Ollama 模型存储到 /root/autodl-tmp/ | vLLM 模型路径指向数据盘 |
| 第六章:环境验证 | nvidia-smi、CUDA 版本确认 | 验证 GPU 驱动是否支持 Ollama | 确认 CUDA/PyTorch 版本与 vLLM 兼容 |
| 第七章:量化技术 | FP16/INT8/INT4、GGUF 量化等级 | ollama pull 默认下载 Q4_K_M 量化版 | vLLM 支持 AWQ/GPTQ 量化模型加载 |
| 第八章:量化工具链 | llama.cpp、Unsloth | Ollama 底层即 llama.cpp | vLLM 使用 AutoAWQ/AutoGPTQ 集成 |
| 第九章:Ollama 与 vLLM | 安装、配置、API 部署、SDK 调用 | 完整部署 + OpenAI 兼容 API | 完整部署 + 生产级 API 服务 |
从这张表可以清晰地看到:本地部署不是一个孤立的技能点,而是前面所有知识的综合运用。第一章学会的模型检索能力,让你知道去哪里找模型;第三章理解的文件结构,让你知道下载回来的是什么;第七章掌握的量化概念,让你知道为什么同一个模型有不同大小的版本。这些知识最终汇聚到第九章,支撑起完整的部署实战。
10.2 项目实战成果展示——从命令行到可视化应用 链接到标题
理论讲得再多,不如看一次真实的运行效果。在前面的章节中,我们分别完成了 Ollama 和 vLLM 的安装、配置与 API 部署。现在让我们通过真实的项目截图,展示这两套方案在实际使用中的完整面貌——不仅包括"成功运行"的结果,也包括部署过程中遇到的真实问题和排查过程。
这部分内容的价值不在于"展示成功”,而在于让你看到"从出错到成功"的完整过程。因为在实际工作中,一次性跑通的情况反而是少数,更多时候你需要面对各种环境差异、参数错误和版本兼容问题。
10.2.1 Ollama 项目成果:从命令行到可视化界面 链接到标题
在第九章中,我们通过命令行和 OpenAI SDK 验证了 Ollama 的基本功能。但 Ollama 的真正威力在于它可以作为后端引擎,驱动完整的可视化对话应用。下图展示的是基于 Open WebUI 搭建的 AI Studio 界面,后端由 Ollama 提供推理服务,前端提供了类似 ChatGPT 的交互体验:
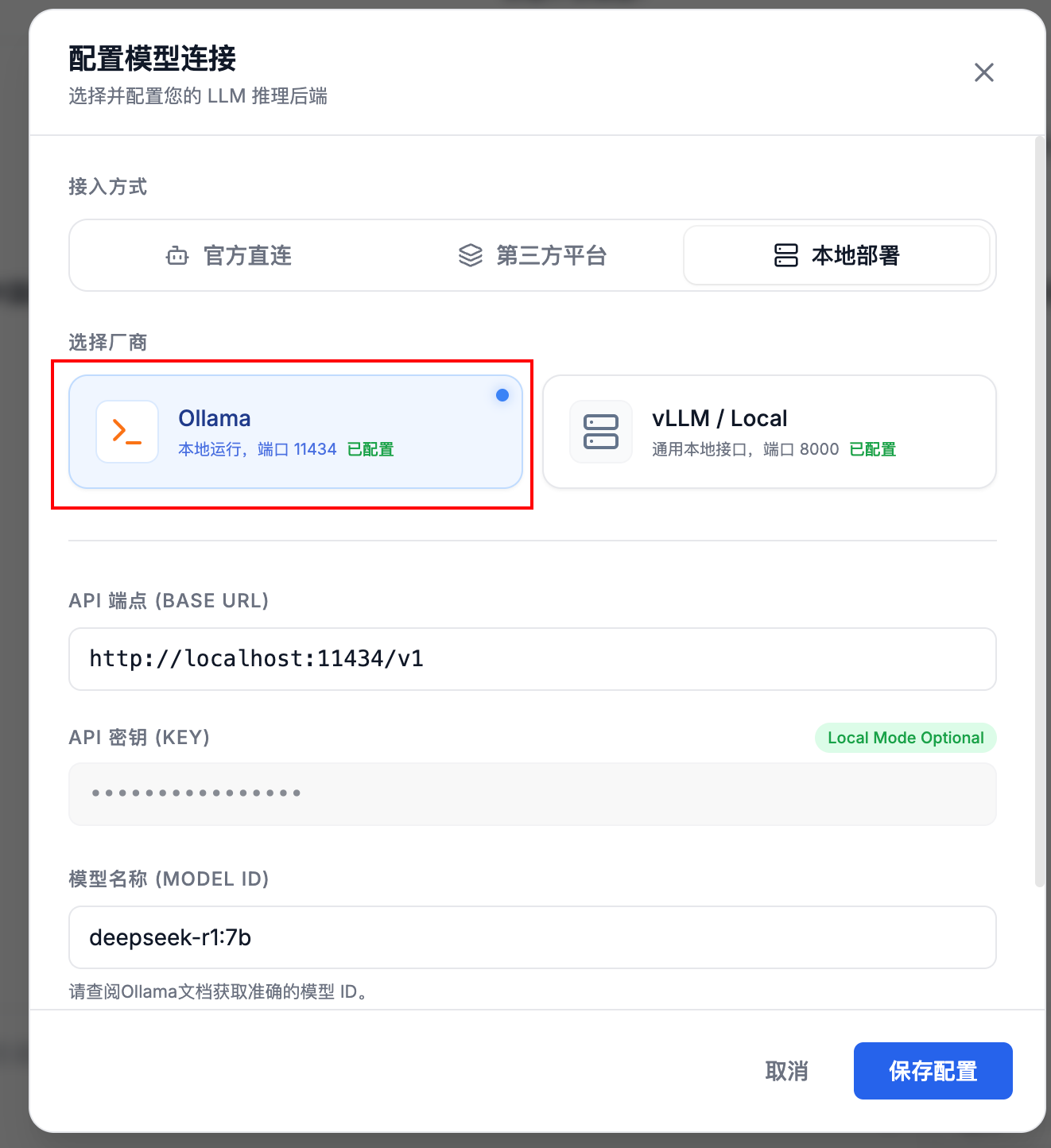
从这张截图中,我们可以看到几个关键信息:
运行模型:deepseek-r1:7b——这是通过 ollama pull deepseek-r1:7b 下载的 DeepSeek-R1 7B 参数量化版本,在单张 RTX 4090D(24GB)上即可流畅运行。
可视化前端:基于 Open WebUI 的定制界面,提供了完整的对话管理、参数调节、历史记录等功能。这意味着 Ollama 不仅是一个命令行工具,它可以作为后端引擎支撑起完整的 AI 应用产品。
参数实时调节:右侧面板可以直接调整 Temperature(当前设置为 0.8)、推理模式(已启用思维链输出)、思考等级(高推理)等参数,无需重启服务。
工具集成:界面中已集成 Google 搜索等外部工具,展示了 Ollama 生态从"单纯对话"向"Agent + 工具调用"演进的能力。
这个成果展示了一条清晰的技术路径:Ollama 安装 → 模型下载 → API 服务启动 → Open WebUI 前端对接 → 完整可视化应用。整个过程不需要编写任何后端代码,Ollama 的 OpenAI 兼容 API 天然支持 Open WebUI 的接入。
扩展提示:Open WebUI 的部署方式将在后续课程中详细讲解。如果你迫不及待想尝试,可以通过
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main快速启动。
10.2.2 vLLM 项目成果:生产级 API 服务部署与调用 链接到标题
与 Ollama 的"开箱即用"不同,vLLM 的部署过程更贴近真实的生产环境——需要手动配置环境变量、指定模型路径、调整服务参数。这个过程虽然复杂一些,但也正是生产级部署的必经之路。
下面我们展示 vLLM 服务从启动到成功调用的完整过程。
步骤一:启动 vLLM API 服务
在 AutoDL 服务器上,我们通过以下命令启动 vLLM 的 OpenAI 兼容 API 服务。注意:这里有一个非常隐蔽的坑——多行命令的 \ 续行符后面绝对不能有空格,否则后续参数会全部失效。
# 先设置环境变量,解决 libgomp 报错
!export OMP_NUM_THREADS=1
# 启动 vLLM API 服务(确保每行 \ 后无空格)
!python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/Qwen2.5-1.5B-Instruct \
--served-model-name qwen2.5 \
--tensor-parallel-size 1 \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.85 \
--max-model-len 16384 \
--trust-remote-code
启动成功后,终端会显示 vLLM 的 ASCII Logo 和加载信息。关键验证点:检查日志中的 non-default args 是否包含 served_model_name: 'qwen2.5' 和 max_model_len: 16384。如果这些参数没有出现,说明启动命令的参数没有正确传递(大概率是 \ 续行符问题)。
步骤二:验证模型列表
服务启动后,通过 curl 命令查询已注册的模型列表,确认 --served-model-name 参数是否生效。
!curl http://localhost:8000/v1/models
如果参数全部生效,返回结果中的 "id" 字段应该是 "qwen2.5",而不是完整的模型路径。对比两种情况:
参数生效(正确):
{"object":"list","data":[{"id":"qwen2.5","object":"model","created":1769519263,"owned_by":"vllm","root":"Qwen/Qwen2.5-1.5B-Instruct","max_model_len":16384}]}
参数未生效(错误):
{"object":"list","data":[{"id":"/root/autodl-tmp/models/Qwen2.5-1.5B-Instruct","object":"model","created":1771077279,"owned_by":"vllm","max_model_len":32768}]}
注意对比两个关键差异:id 从完整路径变为短名 qwen2.5,max_model_len 从默认的 32768 变为我们指定的 16384。这两个字段是判断参数是否生效的最直接依据。
步骤三:通过 OpenAI SDK 调用 vLLM 服务
验证模型列表无误后,我们使用与调用 OpenAI 官方 API 完全相同的代码来调用本地 vLLM 服务。这正是 vLLM 的核心设计理念——完全兼容 OpenAI API 协议,你的应用代码无需任何修改,只需切换 base_url 即可从云端 API 无缝迁移到本地部署。
from openai import OpenAI
# 连接本地 vLLM 服务(api_key 可以是任意非空字符串)
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
completion = client.chat.completions.create(
model="qwen2.5", # 必须与 --served-model-name 一致
messages=[{"role": "user", "content": "帮我写一段 Python 爬虫"}]
)
print(completion.choices[0].message.content)
如果一切正常,模型会返回一段完整的 Python 爬虫代码。这段代码的执行过程是:OpenAI SDK → HTTP 请求发送到 localhost:8000 → vLLM 引擎接收请求 → 调用 Qwen2.5-1.5B-Instruct 模型推理 → 返回生成结果。整个链路完全在本地完成,不依赖任何外部 API 服务。
步骤四:SSH 端口映射——从 AutoDL 到本地
前面三个步骤都是在 AutoDL 服务器上操作的。但在实际开发中,我们通常需要在本地电脑上调用远程服务器上的 vLLM 服务——比如在本地的 Jupyter Notebook 或 IDE 中编写调用代码。这就需要通过 SSH 隧道将远程端口映射到本地。
核心原理:SSH 端口映射(Port Forwarding)会在本地电脑和远程服务器之间建立一条加密隧道,把远程的 8000 端口"搬"到本地的 8000 端口。映射成功后,本地代码中的 localhost:8000 实际上会通过隧道转发到 AutoDL 服务器上的 vLLM 服务。
在本地电脑的终端中执行以下命令(不是在 AutoDL 服务器上):
# 在本地终端执行(非 Notebook 内执行)
# 将 AutoDL 远程服务器的 8000 端口映射到本地 8000 端口
!ssh -o ServerAliveInterval=60 \
-o ServerAliveCountMax=3 \
-L 8000:127.0.0.1:8000 \
-p 39122 \
root@connect.bjb2.seetacloud.com
这条命令中各参数的含义:
-L 8000:127.0.0.1:8000:将本地的 8000 端口转发到远程服务器的 127.0.0.1:8000(即 vLLM 服务地址)-p 39122:AutoDL 分配的 SSH 端口号(每个实例不同,请在 AutoDL 控制台查看)-o ServerAliveInterval=60:每 60 秒发送一次心跳包,防止连接因空闲超时被断开-o ServerAliveCountMax=3:连续 3 次心跳无响应后才断开,提升连接稳定性
⚠️ 注意:SSH 端口号(
-p参数)和服务器地址需要替换为你自己 AutoDL 实例的信息。在 AutoDL 控制台的"SSH 指令"中可以找到。
映射成功后,终端会保持连接状态(不会有额外输出)。此时在本地执行 curl http://localhost:8000/v1/models 或运行前面步骤三的 Python 代码,就能正常调用远程 vLLM 服务了。这也是为什么我们的代码中 base_url 写的是 localhost:8000——它通过 SSH 隧道实际指向了 AutoDL 服务器。
10.2.3 两套方案的统一调用接口对比 链接到标题
一个值得注意的细节是:无论使用 Ollama 还是 vLLM,客户端调用代码的结构完全一致,只需修改两个参数。这得益于两者都实现了 OpenAI API 兼容协议:
Ollama vs vLLM 调用参数对比
| 参数 | Ollama | vLLM | 说明 |
|---|---|---|---|
base_url | http://localhost:11434/v1 | http://localhost:8000/v1 | 端口不同:Ollama 默认 11434,vLLM 默认 8000 |
model | "my-deepseek" | "qwen2.5" | Ollama 用模型标签名,vLLM 用 --served-model-name 指定的名称 |
api_key | "EMPTY" | "EMPTY" | 本地部署无需真实密钥,填任意非空字符串即可 |
| SDK 代码 | 完全相同 | 完全相同 | client.chat.completions.create(...) 调用方式一致 |
这意味着你的应用代码可以在 Ollama、vLLM、OpenAI 官方 API 之间自由切换,只需修改配置文件中的 base_url 和 model 两个字段。这种统一接口的设计大大降低了技术选型的切换成本。
10.3 项目价值总结 链接到标题
回顾整个课程的学习路径,这个本地部署项目的价值体现在三个层面:
1. 学习价值:从"会下载模型"到"能独立部署推理服务" 链接到标题
这不仅仅是"跑通了一个 demo",而是建立了从模型选型到生产部署的完整认知链路。我们学到了:
- 模型生态的全局视野:知道去哪里找模型、如何评估模型质量
- 权重文件的底层理解:明白 safetensors、GGUF 等格式的区别与适用场景
- 量化技术的实用判断:能根据硬件条件选择合适的量化方案
- 两种部署方案的工程实践:Ollama 快速原型 + vLLM 生产服务的双轨能力
2. 实用价值:可直接投入使用的部署方案 链接到标题
课程中搭建的两套服务不是玩具项目,而是可以直接用于实际工作的部署方案:
- Ollama 方案:适合个人开发者日常使用——本地 Prompt 调试、RAG 原型验证、配合 Open WebUI 搭建私有 AI 助手
- vLLM 方案:适合团队和生产环境——高并发 API 服务、批量数据处理、多用户平台后端
- 统一接口:两套方案都兼容 OpenAI API,应用层代码可以零成本切换
3. 扩展价值:为 RAG 与 Agent 开发打下基础设施层 链接到标题
本地部署能力是上层应用开发的基石。有了稳定运行的推理服务,后续可以直接对接:
- RAG 应用:结合
LangChain+ 向量数据库,构建基于私有知识库的问答系统 - Agent 开发:基于
LangGraph/CrewAI构建多步推理、工具调用的智能体 - 多模态应用:部署
Qwen-VL、LLaVA等视觉语言模型,实现图文理解 - 微调与适配:在本地部署的基础上,使用
LoRA/QLoRA对模型进行领域微调
项目的最大价值在于"授人以渔"——不仅给了你两套可用的部署方案,更重要的是建立了"模型选型 → 环境配置 → 服务部署 → 接口调用 → 问题排查"的完整工程思维。
10.4 常见踩坑汇总与排查指南 链接到标题
在实际部署过程中,“一次性跑通"往往是理想状态。以下是我们在本课程实战中真实遇到的问题,以及从社区反馈中收集的高频踩坑点。建议收藏这张表,遇到问题时先来这里对照排查。
10.4.1 vLLM 常见问题 链接到标题
vLLM 部署高频踩坑与排查方案
| 问题现象 | 根因分析 | 解决方案 |
|---|---|---|
--served-model-name 不生效,模型名显示为完整路径 | 多行命令的 \ 续行符后有不可见的尾随空格,导致 shell 在第一行就截断了命令 | 删除每行 \ 后的所有空格,或将整条命令写在一行 |
API 返回 set_num_threads expects a positive integer | 系统环境变量 OMP_NUM_THREADS 被设置为无效值(空字符串或非正整数) | 启动前执行 export OMP_NUM_THREADS=1 |
completion.choices 为 None,触发 TypeError: 'NoneType' object is not subscriptable | API 返回了错误响应但未抛出异常,choices 字段为空 | 先 print(completion) 查看完整返回体,根据 error.message 定位具体原因 |
max_model_len 显示为模型默认值而非指定值 | 同"续行符空格"问题,--max-model-len 参数未被传递 | 检查启动命令的参数完整性,确认 non-default args 日志 |
CUDA out of memory | 模型所需显存超过 GPU 可用显存 | 降低 --gpu-memory-utilization(如 0.7)或减小 --max-model-len,或换用量化版模型 |
Connection refused 无法连接 8000 端口 | vLLM 服务未启动成功,或绑定了错误的 host | 检查服务端日志,确认 --host 0.0.0.0 参数生效 |
10.4.2 Ollama 常见问题 链接到标题
Ollama 部署高频踩坑与排查方案
| 问题现象 | 根因分析 | 解决方案 |
|---|---|---|
ollama pull 下载速度极慢或超时 | 默认从 ollama.com 下载,国内网络不稳定 | 使用镜像源,或手动下载 GGUF 文件后通过 Modelfile 导入 |
| 模型下载到系统盘导致磁盘满 | Ollama 默认存储路径在 ~/.ollama/models | 设置 OLLAMA_MODELS=/root/autodl-tmp/ollama_models 环境变量 |
ollama serve 报端口被占用 | 11434 端口已有其他进程占用 | lsof -i :11434 查找占用进程,kill 后重启 |
| 模型运行时 GPU 利用率为 0% | Ollama 未检测到 CUDA 环境,回退到 CPU 推理 | 确认 nvidia-smi 正常,重新安装支持 GPU 的 Ollama 版本 |
| 自定义 Modelfile 创建失败 | GGUF 文件路径错误或格式不兼容 | 确认 GGUF 文件完整性,检查 Modelfile 中的 FROM 路径是否正确 |
| Open WebUI 连接 Ollama 失败 | Docker 容器无法访问宿主机的 localhost | 使用 --add-host=host.docker.internal:host-gateway 参数,或设置 OLLAMA_HOST=0.0.0.0 |
以上踩坑表中,前三个 vLLM 问题(续行符空格、OMP_NUM_THREADS、choices 为 None)是我们在本课程实战中真实遇到并逐步排查解决的。这个排查过程本身就是一次宝贵的工程实践——遇到问题时,先看完整的错误信息和返回体,再根据线索逐步缩小范围,而不是盲目搜索或重装环境。
10.5 从本地部署到完整应用的路径展望 链接到标题
本课程完成的是大模型应用技术栈中的基础设施层——让模型能够在本地或云端稳定运行并提供 API 服务。但从"能跑模型"到"交付产品"之间,还有多个技术层需要逐步搭建。下图展示了完整的技术栈分层:
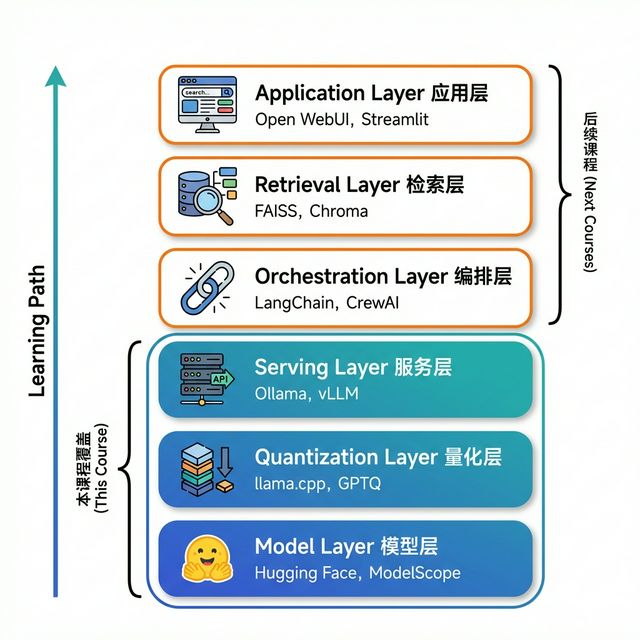
大模型应用技术栈分层与本课程定位
| 层级 | 技术内容 | 代表工具/框架 | 本课程覆盖 |
|---|---|---|---|
| 模型层 | 模型选型、权重下载、格式理解 | Hugging Face、ModelScope | ✅ 第1-3章 |
| 量化层 | 模型压缩、精度-性能权衡 | llama.cpp、GPTQ、AWQ | ✅ 第7-8章 |
| 服务层 | 推理引擎部署、API 服务 | Ollama、vLLM、TGI | ✅ 第9章 |
| 编排层 | 链式调用、Agent 编排、工具集成 | LangChain、LangGraph、CrewAI | 🔜 后续课程 |
| 检索层 | 向量存储、文档切分、相似度检索 | FAISS、Chroma、Milvus | 🔜 RAG 课程 |
| 应用层 | 前端界面、用户交互、产品化 | Open WebUI、Gradio、Streamlit | 🔜 后续课程 |
从表中可以看到,本课程覆盖了底部三层(模型层 → 量化层 → 服务层),这是整个技术栈的地基。没有稳定的推理服务,上层的 RAG、Agent、前端应用都无从谈起。接下来的学习路径建议是:先掌握 RAG(检索增强生成),再进入 Agent 开发,最后根据业务需求选择前端框架进行产品化。
🎉 恭喜! 到这里你已经完成了大模型本地部署的完整学习路径。让我们回顾一下你的技术进步:
- ✅ 从"不知道模型从哪下载"到"能在 Hugging Face / ModelScope 上精准检索并下载模型”
- ✅ 从"看不懂模型文件"到"能区分 safetensors、GGUF、config.json 的作用"
- ✅ 从"只会调用云端 API"到"能在 AutoDL 上独立部署 Ollama 和 vLLM 推理服务"
- ✅ 从"遇到报错就放弃"到"能通过日志分析、参数检查、环境排查定位问题"
这些能力的组合,意味着你已经具备了独立完成大模型本地部署的工程能力。接下来,无论是构建 RAG 应用、开发 AI Agent,还是搭建团队内部的 AI 平台,你都有了坚实的基础设施支撑。
11. 两种方案选型指南 链接到标题
完成了Ollama和vLLM的学习后,让我们总结一下何时选择哪种方案:
Ollama vs vLLM 适用场景
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 个人学习实验 | Ollama | 一键部署,零配置 |
| Prompt调试 | Ollama | 交互式CLI体验好 |
| RAG原型开发 | Ollama | 快速验证想法 |
| 生产API服务 | vLLM | 高并发、低延迟 |
| 多用户平台 | vLLM | 高吞吐量 |
| 批量数据处理 | vLLM | 批处理调度优化 |
附录二:AutoDL启动脚本合集 链接到标题
附录二.1 Ollama启动脚本 链接到标题
#!/bin/bash
# start_ollama.sh - AutoDL专用Ollama启动脚本
!export OLLAMA_MODELS=/root/autodl-tmp/ollama_models
!export OLLAMA_HOST=0.0.0.0:11434
!export OLLAMA_KEEP_ALIVE=24h
!echo "正在启动 Ollama 服务..."
!nohup ollama serve > /root/autodl-tmp/ollama.log 2>&1 &
!echo "✅ Ollama 已后台运行"
!echo "📝 日志路径: /root/autodl-tmp/ollama.log"
附录二.2 vLLM启动脚本 链接到标题
#!/bin/bash
# start_vllm.sh - AutoDL专用vLLM启动脚本
!nohup python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/models/Qwen2.5-1.5B-Instruct --served-model-name qwen2.5 --trust-remote-code --host 0.0.0.0 --port 8000 --gpu-memory-utilization 0.85 --max-model-len 16384 --dtype bfloat16 > /root/autodl-tmp/vllm.log 2>&1 &
!echo "✅ vLLM已后台启动"
!echo "📝 日志路径: /root/autodl-tmp/vllm.log"
!echo "🔗 服务地址: http://0.0.0.0:8000/v1"
12. 下一步学习方向 链接到标题
完成本课程后,以下方向值得进一步探索:
12.1 Ollama方向 链接到标题
- Open WebUI部署:为Ollama配置类似ChatGPT的可视化界面
- RAG应用开发:结合LangChain构建检索增强生成应用
- 模型微调:使用LoRA/QLoRA技术微调开源模型
- 多模态推理:探索LLaVA、Qwen-VL等视觉语言模型
12.2 vLLM方向 链接到标题
- 多卡并行部署:使用
--tensor-parallel-size部署超大模型(70B+) - 量化技术:AWQ/GPTQ量化进一步压缩显存占用
- 推测采样:Speculative Decoding加速推理
- 分布式部署:跨节点部署超大规模模型
附录三:本地部署核心术语表 链接到标题
在学习大模型本地部署的过程中,我们接触了大量专业术语。为了方便随时查阅和巩固理解,这里将本课程涉及的核心术语整理成表格。每个术语都包含简洁定义和在本课程中的应用场景,帮助大家建立清晰的概念体系。
大模型本地部署核心术语对照表
| 术语 | 定义 | 本课程应用场景 |
|---|---|---|
| safetensors | Hugging Face 推出的安全高效模型权重存储格式,支持内存映射加载,避免了 pickle 反序列化的安全风险 | vLLM 加载模型时读取的主要权重格式(第3、9章) |
| GGUF (GPT-Generated Unified Format) | llama.cpp 生态的统一模型格式,支持多种量化等级,单文件包含权重+元数据 | Ollama 底层使用的模型格式(第8、9章) |
| 量化 (Quantization) | 将模型权重从高精度(FP32/FP16)转换为低精度(INT8/INT4)的技术,以减少显存占用和加速推理 | Ollama 默认 Q4_K_M,vLLM 支持 AWQ/GPTQ(第7章) |
| Q4_K_M | GGUF 格式中的一种 4-bit 量化方案,在精度和压缩率之间取得较好平衡 | Ollama 默认下载的量化等级(第7、9章) |
| AWQ (Activation-aware Weight Quantization) | 基于激活值分布的权重量化方法,在 4-bit 量化下保持较高精度 | vLLM 支持的量化格式之一(第8章) |
| GPTQ (GPT Quantization) | 基于二阶信息的逐层量化方法,是最早广泛使用的 LLM 量化技术之一 | vLLM 支持的量化格式之一(第8章) |
| KV Cache | 推理过程中缓存已计算的 Key-Value 向量,避免重复计算,是自回归生成的核心加速机制 | vLLM 的 PagedAttention 优化的核心对象(第9章) |
| PagedAttention | vLLM 的核心技术,借鉴操作系统虚拟内存的分页机制管理 KV Cache,大幅提升显存利用率 | vLLM 高吞吐量的技术基础(第9章) |
| Continuous Batching | 连续批处理技术,允许新请求在不等待当前批次完成的情况下加入推理队列 | vLLM 高并发能力的关键机制(第9章) |
| Tensor Parallel | 张量并行,将模型的权重矩阵切分到多张 GPU 上并行计算 | vLLM --tensor-parallel-size 参数(第9章) |
| Modelfile | Ollama 的模型配置文件,用于定义模型来源、系统提示词、参数等 | 导入自定义 GGUF 模型到 Ollama(第9章) |
| OpenAI API 兼容 | 指服务端实现了与 OpenAI API 相同的接口协议(/v1/chat/completions 等) | Ollama 和 vLLM 都支持,客户端代码可通用(第9、10章) |
这些术语构成了大模型本地部署的核心知识体系。在实际工作中,我们会反复使用这些概念,建议在遇到不熟悉的术语时随时回到这个表格进行查阅。随着实践经验的积累,这些术语会逐渐内化为你的技术语言,成为与团队高效沟通的基础。