今天我们聚焦的是 Agent 技术中最容易被忽视却最关键的一层——认知层。在正式动手写代码之前,我们必须先完成一次彻底的认知跃迁。很多开发者第一次接触 AI Agent 时,会本能地把它理解为"更聪明的聊天机器人"——能记住更多上下文、回答更准确、偶尔还能联网搜索。但这种理解是有偏差的,甚至可以说是危险的。Agent 与聊天机器人之间的差距,不是"程度"上的,而是"范式"上的。就像自动驾驶汽车与定速巡航的区别——后者只是在一个维度上做了自动化,前者则需要感知、决策、执行的完整闭环。
结合当前的技术发展态势,我们会重点抓住三个核心问题:第一,Agent 到底是什么,它与传统 LLM 应用的本质区别在哪里;第二,所有 Agent 架构共同遵循的底层运行逻辑——TAO 循环(Think → Act → Observe)是如何运转的;第三,一个完整的 Agent 系统由哪些核心模块构成,这些模块又如何映射到我们后续的学习路径中。只有把这些认知基础打牢,后续的代码实战才不会沦为"照葫芦画瓢"。
为了把这些内容讲清楚,我们会按照一条"从宏观到微观、从概念到验证"的主线展开:先从 2025-2026 年 Agent 技术爆发的背景谈起,建立时代感;然后通过 CEO 助手类比和六维能力对比表,精确定义 Agent 的能力边界;接着深入剖析 TAO 循环的运行机制;再拆解 Agent 的四大核心特征;之后通过一个动手实验,让你亲身感受纯 LLM 的能力天花板;最后辨析 Agent 与 Workflow 的选型边界。现在,让我们从直播开场的必要准备开始。
课前预检
链接到标题
在正式进入 Agent 技术的核心内容之前,我们需要先完成两项前置工作:明确学习边界和环境就绪检查。这看似是"行政流程",实则是线上直播教学的关键防卡点——根据过往经验,环境问题是学员在课程早期掉队的常见原因,而这些问题完全可以通过前置预检避免。
0.0 学员画像 链接到标题
本课程面向以下目标学员:
核心受众:具备 Python 基础的初中级开发者,有 API 调用经验,希望系统学习 AI Agent 开发
扩展受众:对 AI Agent 技术感兴趣的技术管理者、产品经理,希望建立 Agent 的认知框架
不适用人群:完全没有编程经验的纯小白(建议先学习 Python 基础),或已有丰富 Agent 生产经验的高级工程师(本课侧重入门认知)
0.1 先修声明 链接到标题
本课程对学员的前置能力有明确要求,这不是为了设置门槛,而是为了确保你能跟上节奏、真正学有所获。以下是我们期望你具备的最低基础:
必备前置技能:
会使用 Python 基础语法,包括函数定义、字典和列表操作、异常处理(try/except)
能看懂 JSON 结构,知道字段、类型、可选项的含义
有基本的 API 调用经验,理解请求参数、返回结构、错误码的概念
会配置环境变量,知道如何安全管理 API Key(不硬编码在代码中)
学习边界声明:
本 Part 的目标是帮助你建立 Agent 的核心认知并完成可运行的样例,不覆盖完整的生产级合规体系(如审计、权限管控、数据加密等)
示例中的场景均为教学模拟,用于演示 Agent 的工作机制,不构成任何实际业务建议
⚠️ 常见误区:有些学员认为"只要会用 ChatGPT 就能学 Agent"。实际上,Agent 开发涉及工具编排、状态管理、错误处理等工程问题,需要一定的编程基础。如果你还不熟悉 Python,建议先补充基础后再回来学习。
0.2 环境预检 链接到标题
为了确保每位学员都能顺利跟随课程动手实践,请在正式开始前完成以下环境检查。
步骤一:Python 版本确认
我们推荐使用 Python 3.9 及以上版本(3.11 推荐)。请在终端或 Notebook 中运行以下命令确认版本:
import sys
print(f"Python 版本: {sys.version}")
assert sys.version_info >= (3, 9), "需要 Python 3.9 或更高版本"
print("✅ Python 版本检查通过")
# 需要把安装一下提前配置好的依赖
#!pip install -r requirements.txt
步骤二:API Key 可用性验证
本课程使用 DeepSeek API 作为主要演示接口(兼容 OpenAI SDK)。请确保你已获取有效的 API Key(本地.env文件保存),并能成功建立连接:
import os
from dotenv import load_dotenv
from openai import OpenAI
# 从项目根目录的 .env 文件加载环境变量(DEEPSEEK_API_KEY 等)
load_dotenv()
# 测试连接
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# 最小调用样例
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "你好"}],
max_tokens=50
)
print(f"✅ API 连接成功,模型响应: {response.choices[0].message.content}")
🔥 踩坑预警:如果在 API 连接环节遇到问题,请先检查以下几点:
- API Key 是否正确复制(注意是否有空格或换行)
- 网络是否畅通(部分地区可能需要代理)
- 账户是否有足够余额(新用户通常有免费额度)
第1章:宏观背景与 Agent 发展趋势
链接到标题
在深入技术细节之前,我们需要建立一个宏观视角——为什么是现在学习 Agent?这与两年前学习 Prompt Engineering 有什么不同?理解这个问题,能帮助你在后续学习中保持正确的方向感。
如果说 2023 年是大语言模型的"出圈之年",那么 2025-2026 年就是 Agent 技术的"落地之年"。这个判断基于三个关键基础设施的成熟:
Agent 技术成熟度演进(2023-2026)
| 阶段 | 时间 | 代表事件 | 成熟度 |
|---|---|---|---|
| 概念验证期 | 2023 | AutoGPT 引发热潮 | 能演示,不能生产 |
| 框架探索期 | 2024 | LangChain、CrewAI 发布 | 能开发,工程化不足 |
| 协议统一期 | 2024 末-2025 | MCP(Model Context Protocol,模型上下文协议)协议发布、LangChain 1.0 | 工具生态统一,框架成熟 |
| 生产落地期 | 2025-2026 | A2A(Agent-to-Agent)协议、Agent 中间件、LangSmith(LLM 应用观测与调试平台) | 全链路生产就绪 |
我们正处于"生产落地期"的开端。这意味着现在学习 Agent 开发,既不会太早(基础设施已经成熟),也不会太晚(大多数企业还在探索阶段)。MCP 协议正在成为工具集成的主流标准之一,LangChain、CrewAI、Claude Agent SDK 等框架趋于成熟,Agent 已经从实验室概念走向了生产环境。
但这里有一个关键区分需要明确:对于大部分开发者来说,一个核心问题始终没有被清晰回答——Agent 和我们每天用的 ChatGPT 到底有什么本质区别?在回答这个问题之前,我们需要先理解大模型应用技术的演进脉络。
1.1 技术演进脉络:从 Prompt 到 Agent 链接到标题
在理解 Agent 为什么在 2025-2026 年爆发之前,我们需要回顾大模型应用的技术演进史。这段历史不长——从 2023 年初到现在仅两年多——但每个阶段都解决了上一阶段的核心痛点。
大模型应用技术演进四阶段
| 阶段 | 时间 | 核心技术 | 解决的问题 | 遗留的问题 |
|---|---|---|---|---|
| Stage 1 | 2023.Q1 | 提示工程(Prompt Engineering) | 如何让 LLM 理解任务 | 知识库更新不及时 |
| Stage 2 | 2023.Q3 | 函数调用(Function Calling) | 如何让 LLM 调用工具 | 大模型幻觉问题 |
| Stage 3 | 2023.Q4 | RAG(检索增强生成) | 如何注入私有知识 | 只能单步问答 |
| Stage 4 | 2024-2026 | AI Agent(智能体) | 如何自主完成复杂任务 | 可靠性、成本、安全 |
Stage 1:提示工程(Prompt Engineering)
2020 年,OpenAI 在 GPT-3 论文中提出了 In-Context Learning(上下文学习)的概念。这个发现开启了使用大模型的新方式:通过向模型提供少量标注的"输入-输出对"示例(Few-Shot Learning),在不需要大规模微调的情况下即可显著改善大模型的输出质量。
这一阶段解决了"如何让 LLM 理解任务"的问题,但遗留了知识库更新不及时的痛点——LLM 的训练数据有截止日期,无法获取实时信息。
Stage 2:函数调用(Function Calling)
2023 年 6 月,OpenAI 为其 GPT 模型引入了函数调用功能。通过函数调用,我们可以让 LLM 智能地选择工具来回答问题,并以 JSON 格式返回结构化响应。这解决了"如何让 LLM 调用工具"的问题,但大模型幻觉问题依然存在。
Stage 3:RAG(Retrieval-Augmented Generation)
RAG 通过"检索 + 生成"的方式缓解了幻觉问题:先从知识库中检索相关文档,再让 LLM 基于检索结果生成答案。这在很大程度上约束了 LLM 的输出范围。但传统单轮 RAG pipeline 有一个根本局限:它是"单步"的——用户提问 → 检索一次 → 生成答案,无法处理需要多步推理、多次检索、动态调整策略的复杂任务。
Stage 4:AI Agent(智能体)
Agent 整合了前三个阶段的能力:利用提示工程激发涌现能力、通过函数调用使用工具、借助 RAG 注入知识,并在此基础上实现了多步迭代、动态规划、自主决策。这就是为什么我们说"提示工程解决了理解问题,函数调用解决了行动问题,RAG 解决了知识问题,Agent 解决了能力问题"。
从这个演进表可以看出,Agent 不是凭空出现的,而是在前三个阶段的基础上自然演化出来的。理解了这条技术演进脉络,我们才能更深刻地理解 Agent 的价值所在。
1.2 大模型能力的两个来源:原生 vs 涌现 链接到标题
理解了技术演进脉络之后,一个更深层的问题是:大模型的能力从何而来?为什么 Agent 能处理"没见过"的任务?这需要我们理解大模型能力的两个根本来源。
原生能力(Native Capability)
指大模型在预训练或微调阶段,通过学习大量数据而"记住"的知识和技能。就像你在大学学习三年后能解决高等数学问题一样,这种能力是通过学习得来的、固化在模型参数中的。
典型例子:
语言理解能力(语法、语义)
领域知识(历史、科学、编程)
常见任务模式(翻译、摘要、问答)
涌现能力(Emergent Capability)
指大模型在推理时,通过类比、组合已有知识来解决"没见过"的问题的能力。就像你在高考时遇到新题型,虽然没做过原题,但可以用学过的方法推理出答案。
典型例子:
根据示例学习新任务(Few-Shot Learning)
根据工具描述决定何时调用(Function Calling)
根据中间结果调整策略(ReAct)
原生能力 vs 涌现能力对比
| 维度 | 原生能力 | 涌现能力 |
|---|---|---|
| 获得方式 | 预训练/微调 | 推理时激发 |
| 稳定性 | 高(固化在参数中) | 中(依赖提示质量) |
| 可扩展性 | 低(需要重新训练) | 高(通过提示即可) |
| 典型应用 | 语言理解、知识问答 | 工具使用、任务规划 |
| Agent 中的作用 | 提供基础理解能力 | 支撑动态决策能力 |
Agent 的核心价值在于充分利用大模型的涌现能力——我们不需要为每个新任务重新训练模型,只需要通过提示工程、工具描述、示例演示,就能让 Agent 学会新技能。
这也解释了为什么 Agent 技术在 2024-2025 年才爆发:早期的大模型(如 GPT-2)虽然有一定的原生能力,但涌现能力不足,无法可靠地完成"根据工具描述选择工具"这样的推理任务。只有当模型规模达到一定程度(如 GPT-3.5、GPT-4),涌现能力才足够强,Agent 才真正可用。
1.3 失败的教训:为什么 GPT Plugins 没有成功? 链接到标题
既然大模型已经具备了原生能力和涌现能力,为什么 Agent 直到 2025 年才真正成功?让我们先看一个失败案例——OpenAI 在 2023 年中期推出的 GPT Plugins。
GPT Plugins 的愿景非常宏大:打造一个类似 App Store 的生态系统,让每个人都能以极低的门槛创建自己的智能应用。OpenAI 提供了强大的 GPT-4 模型和插件接口,开发者只需要定义工具的功能描述,GPT-4 就能自动决定何时调用。
但直到 2024 年底,GPT Plugins 的使用率远低于预期,OpenAI 最终在 2024 年 4 月关闭了 Plugins,转而推出 GPTs 和 Actions。为什么会失败?
GPT Plugins 失败的三大原因
| 原因 | 具体表现 | 影响 |
|---|---|---|
| 模型能力不足 | GPT-4(2023 版)工具调用可靠性不足,复杂场景常出错 | 复杂任务经常失败,用户体验差 |
| 工具生态混乱 | 插件质量参差不齐,缺少统一标准 | 用户不知道该用哪个插件 |
| 编排能力缺失 | 只能单步调用,无法多步规划 | 只能处理简单任务,无法解决复杂问题 |
这个失败案例揭示了一个关键洞察:Agent 不是"LLM + 工具"那么简单,它需要模型能力、工具生态、编排框架三者的协同进化。
那么,为什么 2025-2026 年 Agent 能成功?
因为三大基础设施已经成熟:
模型能力跃迁:GPT-4o、Claude 3.5 Sonnet、DeepSeek V3 等新一代模型的工具调用可靠性大幅提升,复杂场景下的成功率显著优于早期模型
工具生态统一:MCP 协议(2024.11)提供了被广泛采纳的工具集成标准
编排框架成熟:LangGraph、CrewAI、Claude Agent SDK 等框架提供了多步规划能力
这个案例告诉我们:即使有强大的 LLM,如果缺少工具生态和编排能力,Agent 也无法真正落地。只有当这三者同时成熟,Agent 才能从实验室走向生产环境。
通过对技术演进、能力来源和失败案例的分析,我们建立了对 Agent 发展背景的宏观认知。现在,让我们进入本 Part 最核心的认知节点——Agent 到底是什么?这是整门课程的认知基石,必须在继续深入之前彻底搞清楚。
1.4 Agent 技术生态全景 链接到标题
理解了 Agent 与 Workflow 的选型边界之后,我们需要从更宏观的视角来审视 Agent 技术在整个 AI 生态中的位置。这不仅能帮助你理解 Agent 的价值所在,还能让你在实际项目中做出更明智的技术选型。
当前的 Agent 技术生态可以从三个维度来理解:框架层、协议层和应用层。
框架层:Agent 开发框架的演进
从 2023 年的 AutoGPT、BabyAGI 概念验证,到 2024 年的 LangChain Agent、CrewAI 框架探索,再到 2025 年的 LangGraph、Claude Agent SDK 生产就绪,Agent 开发框架经历了从"能演示"到"能开发"再到"能生产"的三级跳。这些框架的核心差异在于:
AutoGPT/BabyAGI:证明了 Agent 的可行性,但工程化不足,主要用于概念验证
LangChain Agent/CrewAI:提供了可用的开发工具,但缺少生产级的监控、调试、版本管理能力
LangGraph/Claude Agent SDK:提供了完整的生产工具链,包括状态管理、错误恢复、可观测性、A/B 测试等
协议层:工具集成的统一标准
2024 年 11 月,Anthropic 发布的 MCP(Model Context Protocol)协议正在成为 Agent 工具集成的主流标准之一。在此之前,每个框架都有自己的工具定义方式,导致工具无法跨框架复用。MCP 的出现解决了这个问题——就像 HTTP 协议统一了 Web 服务的接口标准一样,MCP 统一了 Agent 工具的接口标准。
这意味着:一个遵循 MCP 协议的工具(如天气查询工具),可以被 LangChain、CrewAI、Claude Agent SDK 等任何支持 MCP 的框架直接使用,无需重复开发。
应用层:Agent 的实际落地场景
在应用层,Agent 技术已经在多个领域实现了生产级落地:
代码生成与调试:如 Devin、Cursor、GitHub Copilot Workspace,能够自主完成需求分析 → 代码编写 → 测试 → 调试的完整流程
客户服务:如智能客服 Agent,能够理解复杂问题、查询知识库、调用业务系统、生成个性化回答
数据分析:如 Data Analyst Agent,能够理解自然语言查询、生成 SQL、执行查询、可视化结果、解释发现
内容创作:如 Content Agent,能够调研主题、收集素材、生成初稿、优化润色、配图排版
从这可以看出,Agent 技术已经从实验室概念走向了生产环境,但仍处于快速演进阶段。选择 Agent 技术栈时,需要综合考虑:
成熟度:是否有生产案例?社区是否活跃?文档是否完善?
工具生态:是否支持 MCP 协议?有哪些现成工具可用?
可观测性:是否提供调试、监控、日志、追踪能力?
成本控制:Token 消耗如何?是否支持本地模型?是否有成本优化机制?
理解了这个生态全景,你就能在实际项目中做出更明智的技术选型——不是盲目追逐最新框架,而是根据项目需求、团队能力、成本预算来选择最合适的技术栈。
第2章:AI Agent 大爆发的本质
链接到标题
上一章我们建立了时代背景,现在让我们进入本 Part 最核心的认知节点——Agent 到底是什么?这是整门课程的认知基石,必须在继续深入之前彻底搞清楚。
2.1 Agent 的定义:CEO 的两种助手 链接到标题
在给出严格定义之前,我们先用一个真实世界的类比来建立直觉。想象你是一家公司的 CEO,你有两种助手可以选择:
助手 A(聊天机器人):你问他任何问题,他都能给出一个看起来不错的回答。但他只能"说",不能"做"。你让他查一下今天的股价,他会告诉你"我无法访问实时数据";你让他帮你订一张机票,他会给你一段订票的步骤说明,但不会真的去操作。他的全部能力就是基于训练数据生成文本。
助手 B(Agent):他不仅能回答问题,还拥有一个"万能工具箱"——可以上网搜索、查数据库、调 API、读写文件、执行代码。更关键的是,他会自主决定何时使用哪个工具。你说"帮我调研一下竞品 X 的最新动态并写一份报告",他会自己拆解任务:先搜索新闻、再查财报数据、然后整理成报告、最后保存到你的文件夹。整个过程你不需要逐步指挥。
这就是 Agent 的本质——一个能够感知环境、自主决策、调用工具、完成目标的智能系统。用更正式的语言来说:
AI Agent(智能体) 是一个以大语言模型为"大脑",通过感知环境信息、自主规划决策、调用外部工具来完成复杂目标的自主系统。它与传统聊天机器人的核心区别在于:Agent 不仅能"想",还能"做";不仅能回答单个问题,还能自主完成多步骤任务。
2.2 从提示工程到代理工程 链接到标题
理解了 Agent 的定义之后,我们需要明确一个术语演进:代理工程(Agent Engineering)。
在 2023 年之前,我们主要使用"提示工程"(Prompt Engineering)来优化 LLM 的输出——通过精心设计输入文本,让 LLM 生成更准确的回答。但提示工程有一个根本局限:它只能指导 LLM"想什么",无法让 LLM"做什么"。
代理工程的核心区别:
提示工程 vs 代理工程
| 维度 | 提示工程 | 代理工程 |
|---|---|---|
| 目标 | 优化单次输出质量 | 完成多步复杂任务 |
| 设计内容 | 输入文本 | 角色定位 + 工具集 + 执行流程 |
| 执行模式 | 单轮问答 | 多轮迭代循环 |
| 能力边界 | 文本生成 | 文本生成 + 工具调用 + 环境交互 |
所谓的代理工程,一种最简单的理解是:更加复杂的提示工程。从提示工程到代理工程的过渡体现在:不再只是提供单一的任务描述,而是明确界定代理所需承担的具体职责,详尽概述完成这些任务所需采取的操作,并清楚指定执行这些操作所必须具备的能力,形成一个高级的认知模型。
这个演进过程,正是本课程要带你完成的旅程——从"写一个好 Prompt"到"设计一个完整 Agent 系统"。
2.3 传统 AI 模型 vs Agent:六维能力对比 链接到标题
为了精确理解 Agent 相对于传统 AI 模型的能力跃迁,我们从六个关键维度进行对比。这不是一个简单的"好与坏"的比较,而是两种完全不同的系统范式。
传统 AI 模型 vs Agent 六维能力对比
| 维度 | 基础 LLM API(默认能力) | AI Agent |
|---|---|---|
| 交互模式 | 单轮问答:你问一句,它答一句 | 多轮自主:接收目标后自主规划、执行、迭代 |
| 工具使用 | 默认不具备工具调用能力,需外部编排实现 | 动态选择并调用任意工具(搜索、数据库、API、代码执行) |
| 环境感知 | 仅感知对话上下文 | 感知对话 + 工具返回结果 + 外部环境状态 |
| 任务复杂度 | 适合单步任务(翻译、摘要、问答) | 适合多步复杂任务(调研、分析、报告生成) |
| 错误处理 | 生成错误答案后无法自我纠正 | 可观察执行结果、判断是否正确、自主重试或换策略 |
| 状态管理 | 默认无状态,依赖外部机制实现上下文管理 | 有状态:维护工作记忆、长期记忆、任务进度 |
| 使用代价 | 低延迟、低成本、可控性强 | 高延迟、高成本、执行路径不可预测、调试复杂 |
从表格中可以清晰看到,Agent 在每个维度上都实现了从"被动响应"到"主动执行"的跃迁。但这并不意味着所有场景都需要 Agent——如果你只是想翻译一段文字或生成一封邮件,普通 LLM 调用更快、更便宜、更可控。Agent 的价值在于处理那些需要多步推理、工具协作、动态决策的复杂任务。需要注意的是,这里对比的是基础 LLM API 的默认能力,而非产品化后的 ChatGPT 等应用——后者通过内置工具和记忆机制已部分具备了 Agent 的特征。
2.4 从 RAG 到 Agent:最后一公里的跨越 链接到标题
理解了 Agent 与传统 AI 模型的六维能力对比之后,一个关键问题浮出水面:既然 RAG 已经解决了知识库更新和幻觉问题,为什么还需要 Agent?
大模型幻觉问题的本质
当 LLM 面对自己不了解的问题时,它不会诚实地说"我不知道",而是会基于训练数据中的模式"编造"一个看似合理的答案。例如:
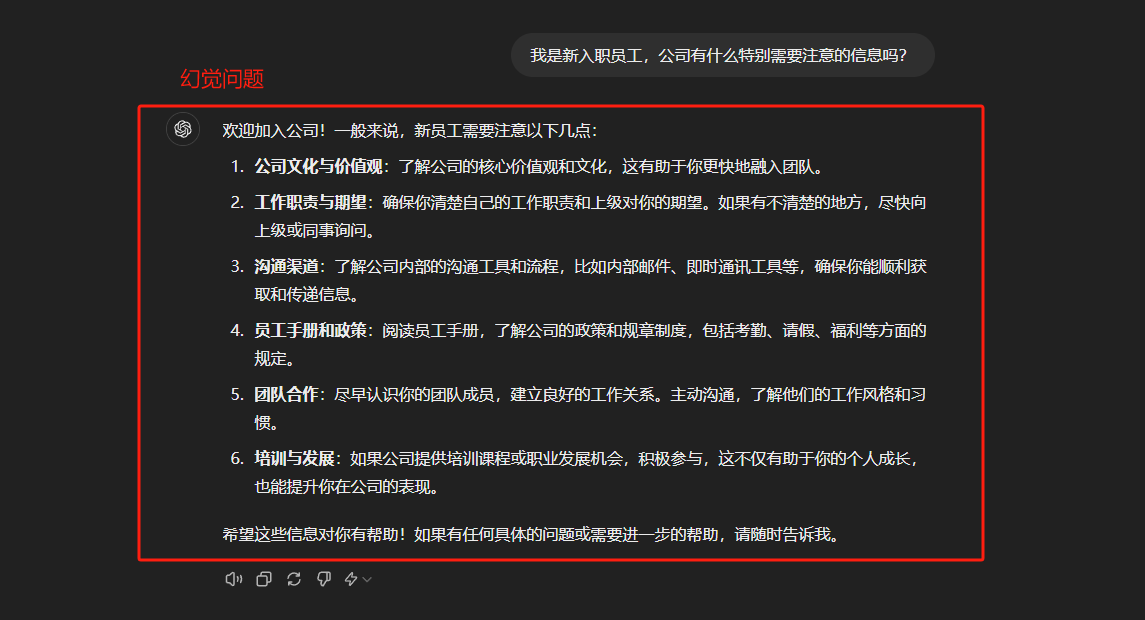
如上图所示,当被询问关于公司制度的问题时,在没有任何技术手段介入的情况下,理想的回答应该是"我不知道"或"请提供一下你所入职公司的具体制度",而我们看到的却是大模型错误地从一个 HR 的角度进行了回复,这就会给用户带来混淆和误导。
RAG 的解决方案与根本局限
RAG 通过"检索 + 生成"的方式缓解了这个问题:先从知识库中检索相关文档,再让 LLM 基于检索结果生成答案。这在很大程度上约束了 LLM 的输出范围。
但传统单轮 RAG pipeline 有一个根本局限:它是"单步"的。用户提问 → 检索一次 → 生成答案,整个流程结束。如果任务需要多步推理、多次检索、动态调整策略,RAG 就无能为力了。
RAG vs Agent 能力对比
| 维度 | RAG | Agent |
|---|---|---|
| 执行模式 | 单步:检索 → 生成 | 多步:规划 → 执行 → 观察 → 调整 |
| 适用任务 | 知识问答、文档总结 | 复杂调研、多步推理、工具协作 |
| 决策能力 | 无决策,固定流程 | 动态决策,根据中间结果调整 |
| 工具使用 | 仅检索工具 | 任意工具(搜索、计算、API、代码执行) |
| 错误处理 | 无法自我纠正 | 可观察结果、判断错误、重试 |
举个例子:如果用户问"帮我调研竞品 X 的最新动态并分析其对我们的威胁",RAG 只能检索一次相关文档然后生成答案,而 Agent 可以:
先搜索竞品的最新新闻
根据新闻内容判断需要进一步查询哪些数据(如融资、产品发布)
调用多个工具获取补充信息
整合所有信息生成分析报告
当然,现代 RAG 架构(如迭代式检索、Agentic RAG)已经开始融入多步推理能力,逐渐模糊了 RAG 与 Agent 的边界。但在理解核心概念时,这种对比仍然是有价值的。
这就是为什么我们说"RAG 解决了知识问题,Agent 解决了能力问题"。RAG 让 LLM 能够访问私有知识库,但仍然是单步执行;Agent 则在此基础上实现了多步迭代、动态规划、自主决策,真正具备了处理复杂任务的能力。
从这个过程中,我们理解了 Agent 相对于 RAG 的能力跃迁。但 Agent 内部到底是怎么运转的?答案就是下一章的核心主题——TAO 循环。
第3章:TAO 循环——Agent 的核心架构
链接到标题
理解了 Agent 与聊天机器人的区别之后,一个自然的问题是:Agent 内部到底是怎么运转的?答案是本章的核心主题——TAO 循环(Think → Act → Observe)。这个循环是所有 Agent 架构的共同基础,无论你后续使用 ReAct、Plan-and-Execute 还是多 Agent 编排,底层都是 TAO 循环的变体。在理解 TAO 循环之前,我们先回顾其理论溯源——从思想链(CoT)到 ReAct 框架的演进。
3.1 思想链(Chain-of-Thought) 链接到标题
在深入 ReAct 之前,我们需要理解它的理论基石——思想链(Chain-of-Thought, CoT)。这个技术最早由 Google 在 2022 年 1 月的论文中提出。
📄 论文链接:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
CoT 的核心思想是:通过将复杂问题分解为多个逻辑步骤,让 LLM 按顺序推理,从而提高准确率。
CoT 的两个关键机制:
分解问题:将复杂任务拆解为更小的子步骤
顺序思维:每一步建立在上一步的结果之上
示例:商店价格计算
问题:一家商店以 100 元的价格出售产品。如果商店降价 20%,然后加价 10%,产品的最终价格是多少?
CoT 推理过程:
步骤 1:计算降价 20% 后的价格:100 × (1 - 0.2) = 80 元
步骤 2:计算上涨 10% 后的价格:80 × (1 + 0.1) = 88 元
结论:最终售价为 88 元
CoT 的局限性
虽然 CoT 显著提升了 LLM 的推理能力,但它有一个致命缺陷:在推理的中间阶段,如果某一步出现错误,错误会沿着推理链传播,导致最终答案完全错误。更糟糕的是,LLM 无法自我验证中间步骤的正确性——它只能"想",不能"做"。
这就是 ReAct 要解决的问题:通过引入"行动"(Action)和"观察"(Observe)环节,让 LLM 能够在推理过程中与外部环境交互,验证中间结果,从而避免错误传播。
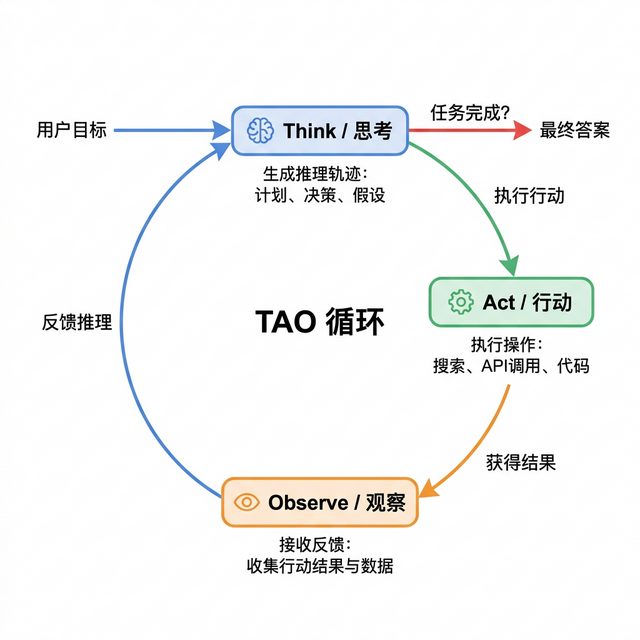
3.2 TAO 循环——ReAct 的运行机制 链接到标题
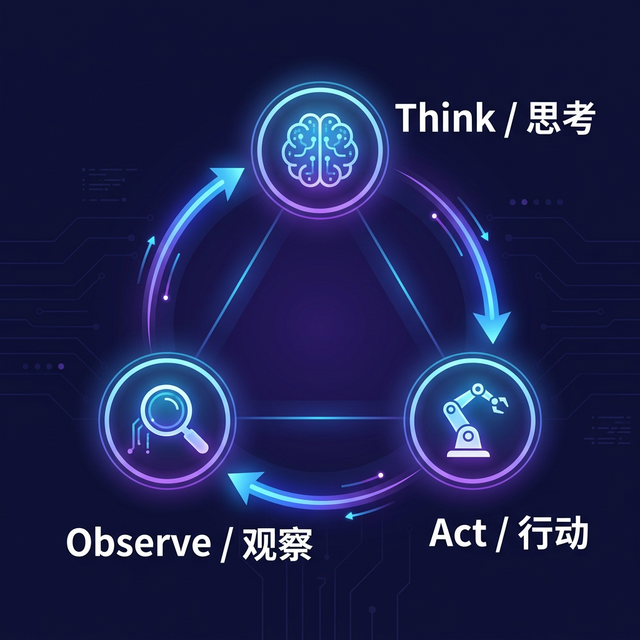
TAO 循环的名称来自三个核心环节的英文首字母:
Think(思考):LLM 作为"大脑",分析当前状态和用户目标,决定下一步行动。这一步可能包括:判断任务是否完成、确定需要调用的工具、规划执行顺序、评估风险等。
Act(行动):根据 Think 阶段的决策,调用相应的工具或生成回答。如果决定调用工具,就执行工具调用;如果判断任务已完成,就生成最终回答。
Observe(观察):收集 Act 阶段的结果——如果是工具调用,收集工具返回的数据;如果是生成回答,观察用户的反馈。将观察结果纳入上下文,为下一轮 Think 提供输入。
这三个环节形成一个闭环,循环往复直到任务完成。
3.3 查天气案例:两轮 TAO 循环拆解 链接到标题
我们用一个具体场景来拆解 TAO 循环的实际运行。假设用户对 Agent 说:“帮我查一下北京今天的天气,如果气温超过 30°C,就提醒我带防晒霜。”
第一轮循环:
Think(思考):Agent 的 LLM 大脑分析用户请求,识别出两个关键信息需求:(1)北京今天的天气状况;(2)气温是否超过 30°C。由于 LLM 没有实时天气数据,它判断需要先获取北京的实时天气。它在可用工具列表中找到了
get_weather工具,决定调用它。Act(行动):Agent 调用
get_weather(city="北京")工具,向天气 API 发送请求。Observe(观察):工具返回结果:
{"city": "北京", "temperature": 33, "condition": "晴"}。Agent 将这个结果纳入自己的上下文。
第二轮循环:
Think(思考):Agent 观察到气温 33°C > 30°C,触发了用户设定的条件。它判断不需要再调用任何工具,可以直接生成最终回答。
Act(行动):Agent 生成最终回复:“北京今天晴,气温 33°C,超过了 30°C,建议您带上防晒霜。”
Observe(观察):任务完成,循环终止。
TAO 循环的精妙之处在于它的自终止性——Agent 在每一轮的 Think 阶段都会判断"任务是否已经完成",如果完成就输出最终答案并退出循环,如果未完成就继续下一轮。这意味着 Agent 可以根据任务复杂度自动调整执行步数:简单任务一轮就结束,复杂任务可能需要五轮、十轮甚至更多。
关键洞察:TAO 循环本质上是一个带反馈的控制回路。传统聊天机器人是开环系统(输入 → 输出,没有反馈),而 Agent 是闭环系统(输入 → 执行 → 观察 → 调整 → 再执行)。这就是为什么 Agent 能处理复杂任务——它可以根据中间结果动态调整策略。
3.4 学术溯源:ReAct 论文的核心贡献 链接到标题
通过查天气案例,我们看到了 TAO 循环的实际运行。但这个循环并不是我们凭空发明的概念,它来自一篇在 Agent 领域具有里程碑意义的论文。
📄 论文链接:REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
这篇论文由 Shunyu Yao 等人于 2022 年 10 月发表,提出了 ReAct(Reasoning and Acting)框架。论文的核心洞察是:人类在解决复杂问题时,会交替进行"推理"(Reasoning)和"行动"(Acting)。
例如,当你在做数学题时,你会先推理"这道题应该用什么公式",然后行动"在草稿纸上计算",再观察"结果是否合理",如果不合理就重新推理。这种"想 → 做 → 看"的循环,正是人类智能的核心机制。
ReAct 的关键创新:推理跟踪(Reasoning Trace)
论文的关键创新是引入了"推理跟踪"——让 LLM 在每次行动前先生成一段推理文本,解释"为什么要这样做"。这不仅提高了决策的可解释性,还显著提升了任务成功率。
在 HotpotQA(问答)和 FEVER(事实验证)等基准测试中,ReAct 相比纯 CoT 和纯 Act-only 方法均取得了显著提升(具体数值因任务和设置而异,详见原论文 Table 1-3)。
与 TAO 循环的关系
我们课程中讲的 TAO 循环,本质上就是 ReAct 的简化版本:
Think 对应 ReAct 中的 Reasoning(推理)
Act 对应 ReAct 中的 Acting(行动)
Observe 对应 ReAct 中的 Observation(观察行动结果)
理解这个学术背景,能帮助你在后续学习中更深刻地理解 Agent 的设计哲学。ReAct 不仅是一个技术框架,更是对人类认知过程的一次成功模拟。
ReAct 如何解决 CoT 的幻觉问题
让我们用一个具体例子来理解 ReAct 相对于纯 CoT 的优势。假设用户问:“地球质量的两倍是多少?”
纯 CoT 的执行路径:
Thought: 我需要知道地球的质量
Thought: 根据我的训练数据,地球质量约为 5.972 × 10²⁴ kg
Thought: 两倍就是 5.972 × 10²⁴ × 2 = 1.1944 × 10²⁵ kg
Answer: 地球质量的两倍是 1.1944 × 10²⁵ kg
问题在哪?如果 LLM 在第二步"记错"了地球质量(比如记成了 6.0 × 10²⁴),后续所有计算都会基于错误数据,且 LLM 无法自我纠正。
ReAct 的执行路径:
Thought: 我需要查询地球的准确质量
Action: search(“地球质量”)
Observation: 搜索结果显示地球质量为 5.972 × 10²⁴ kg
Thought: 现在我需要计算两倍
Action: calculate(5.972e24 * 2)
Observation: 计算结果为 1.1944 × 10²⁵ kg
Answer: 地球质量的两倍是 1.1944 × 10²⁵ kg
关键区别:ReAct 通过"行动 → 观察"机制,将推理过程中的关键步骤交给外部工具验证,避免了 LLM 的幻觉和计算错误。这也与论文在 HotpotQA、FEVER 等任务上的结论一致:ReAct 相比纯 CoT 和纯 Act-only 方法整体表现更优(具体数值见原论文 Table 1-3)。
3.5 从理论到实践:ReAct Prompt 设计模板 链接到标题
理解了 ReAct 的理论原理之后,一个关键问题是:如何将这个理论转化为实际可用的 Prompt?让我们看一个标准的 ReAct Prompt 模板。
标准 ReAct Prompt 结构
react_prompt = """
你在一个由"思考、行动、观察、回答"组成的循环中运行。
在循环的最后,你输出一个答案。
使用"思考"来描述你对所提问题的思考。
使用"行动"来执行你可用的动作之一。
"观察"将是执行这些动作的结果。
"回答"将是分析"观察"结果后得出的答案。
你可用的动作包括:
calculate(计算):
例如:calculate: 4 * 7 / 3
执行计算并返回数字
wikipedia(维基百科):
例如:wikipedia: Django
返回从维基百科搜索的摘要
如果有机会,请始终在维基百科上查找信息。
示例会话:
问题:法国的首都是什么?
思考:我应该在维基百科上查找关于法国的信息
行动:wikipedia: France
PAUSE
你然后会收到:
观察:法国是一个国家。首都是巴黎。
思考:我已经找到了答案
回答:法国的首都是巴黎
现在轮到你了:
"""
Prompt 设计的三个关键要素
循环机制说明:明确告诉 LLM 它处于一个循环中,需要重复"思考 → 行动 → 观察"直到任务完成
工具定义:清晰描述每个工具的功能、调用格式、返回内容
示例演示(Few-Shot):通过完整示例展示期望的推理格式
LangChain 的 ReAct Prompt 变体
在实际应用中,不同框架会对 ReAct Prompt 进行微调。例如,LangChain 使用以下格式:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action Observation: the result of the action … (this Thought/Action/Action Input/Observation can repeat N times) Thought: I now know the final answer Final Answer: the final answer to the original input question
Begin!
Question: {input} Thought: {agent_scratchpad}
这个模板中有四个占位符:
{tools}:工具的详细描述{tool_names}:工具名称列表{input}:用户的原始问题{agent_scratchpad}:保存历史推理记录
⚠️ 常见误区:很多初学者认为"只要告诉 LLM 有哪些工具就行"。实际上,示例演示(Few-Shot)是 ReAct Prompt 成功的关键——它教会 LLM"应该以什么格式输出",而不仅仅是"应该做什么"。
TAO 循环描述了 Agent 的运行机制,但要真正理解 Agent 的能力边界,我们需要从更高的抽象层次来审视其构成要素。
第4章:智能体核心四要素
链接到标题

学习到这里,我们已经从理论(CoT→ReAct)和机制(TAO 循环)两个角度理解了 Agent 的运转方式。接下来,我们换一个视角——从能力分解的角度来审视 Agent:它需要哪些核心能力才能完成上述运转?TAO 循环是"时序视角"(Agent 按时间顺序做了什么),四大核心特征是"能力视角"(Agent 需要什么能力),两者是对同一系统的互补描述。
TAO 循环描述了 Agent 的运行机制,但要真正理解 Agent 的能力边界,我们需要从更高的抽象层次来审视其构成要素。学术界和工业界对 Agent 的核心特征有不同的分类方式,但综合来看,以下四个特征是所有 Agent 系统的共同基础。
4.1 自主性 / 感知 / 推理 / 行动执行 链接到标题
自主性(Autonomy)——从"被指挥"到"自驱动"
自主性是 Agent 最核心的特征。一个具备自主性的 Agent,在接收到高层目标后,能够独立完成任务分解、工具选择、执行顺序规划和异常处理,而不需要人类逐步指挥。例如,当用户说"帮我调研竞品",Agent 能自主决定:调研哪些维度、从哪些渠道获取信息、如何组织报告结构。
感知能力(Perception)——从"只读文字"到"感知世界"
传统聊天机器人的输入只有用户的文字消息。而 Agent 的感知范围要广得多——它可以通过工具获取实时数据(天气、股价、新闻)、读取文件系统中的文档、解析数据库查询结果、甚至处理图片和音频输入。更重要的是,Agent 的感知是主动的:它不是被动等待用户提供信息,而是在推理过程中主动判断"我还需要什么信息"。
推理与规划(Reasoning & Planning)——从"直觉回答"到"深思熟虑"
LLM 本身就具备一定的推理能力,但这种推理是"单次"的——给定输入,直接生成输出。Agent 的推理则是迭代式的:它可以先生成一个初步计划,执行第一步后根据结果调整后续计划,遇到障碍时回退并尝试替代方案。规划能力是 Agent 处理复杂任务的关键。
行动执行(Action Execution)——从"纸上谈兵"到"真实操作"
行动执行是 Agent 区别于所有"纯文本生成"系统的标志性能力。Agent 不仅能生成"应该怎么做"的文字描述,还能通过工具真正执行操作:发送 HTTP 请求、执行 SQL 查询、运行 Python 代码、操作文件系统、调用第三方 API。
4.2 四要素与课程章节映射表 链接到标题
这四个特征并不是孤立的,它们在 TAO 循环中紧密协作。理解它们与后续学习内容的对应关系,能帮助你在学习每一章时都清楚"我在构建 Agent 的哪个部分"。
Agent 四大核心特征
| 核心特征 | 能力描述 |
|---|---|
| 自主性(Autonomy) | 独立分解任务、选择工具、规划执行 |
| 感知能力(Perception) | 主动获取环境信息、处理多模态输入 |
| 推理与规划(Reasoning & Planning) | 迭代推理、任务分解、动态重规划 |
| 行动执行(Action Execution) | 调用工具执行真实操作 |
感知能力为 Think 阶段提供信息输入,推理与规划能力驱动 Think 阶段的决策,行动执行能力支撑 Act 阶段的工具调用,而自主性则是整个循环能够自驱运转的前提。
4.3 经典架构图:Lilian Weng 的 Agent 框架 链接到标题
理解了四大核心特征与课程章节的映射关系之后,我们需要看一张在 Agent 领域被广泛引用的架构图,它来自 OpenAI 研究员 Lilian Weng 的经典博客文章《LLM Powered Autonomous Agents》。
📝 博客链接:https://lilianweng.github.io/posts/2023-06-23-agent/ ⚠️ 强烈建议:这篇博客是 Agent 领域的必读文献,建议课后完整阅读。

这张图清晰地展示了一个完整 Agent 系统的四大核心模块:
Planning(规划):Agent 如何将复杂任务分解为子任务,如何制定执行计划
Memory(记忆):Agent 如何存储和检索历史信息,包括短期记忆和长期记忆
Tool Use(工具使用):Agent 如何调用外部工具来扩展自己的能力
Action(行动):Agent 如何将决策转化为具体的执行操作
这四个模块与我们前面讲的"四大核心特征"是对应的:
理解这张架构图的价值在于:它为我们提供了一个通用的分析框架。当你在评估一个 Agent 系统时,可以从这四个维度去审视:它的规划能力如何?记忆机制是否完善?工具集是否丰富?行动执行是否可靠?
在后续章节中,我们会逐一深入这四个模块,构建一个完整的 Agent 系统。
理论讲了不少,现在让我们动手验证。这个实验的目标很明确:通过向 LLM 提出五类它无法独立完成的任务,亲身感受"纯 LLM"的能力天花板。这些天花板,恰好就是 Agent 需要通过工具来突破的地方。
第5章:动手实验——探索 LLM 能力边界
链接到标题
理论讲了不少,现在让我们动手验证。这个实验的目标很明确:通过向 LLM 提出五类它无法独立完成的任务,亲身感受"纯 LLM"的能力天花板。这些天花板,恰好就是 Agent 需要通过工具来突破的地方。
5.1 环境准备 链接到标题
首先,我们安装必要的依赖并配置 API Key。这里使用 OpenAI 兼容的 SDK 来调用 DeepSeek 的 API。
pip install openai -q
安装完成后,我们配置 API 连接。这里使用 python-dotenv 从项目根目录的 .env 文件中加载环境变量,将 API Key 保存在 .env 中而非硬编码在代码里,更安全也更便于管理。
import os
from dotenv import load_dotenv
from openai import OpenAI
# 从项目根目录的 .env 文件加载环境变量(DEEPSEEK_API_KEY 等)
load_dotenv()
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com" # DeepSeek API 端点
)
def chat(prompt: str, model: str = "deepseek-chat") -> str:
"""向 LLM 发送单轮对话请求并返回回答"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=1024
)
return response.choices[0].message.content
# 验证连接
print(chat("你好,请用一句话介绍你自己。"))
如果一切正常,你应该看到 DeepSeek 返回了一段自我介绍。这说明 API 连接已经建立成功。接下来,我们开始探索它的能力边界。
5.2 五类无法完成的任务 链接到标题
现在我们依次向 LLM 提出五类任务,观察它的表现。每一类任务都对应 Agent 需要通过工具来解决的一个核心能力缺口。
实验一:实时信息获取
LLM 的训练数据有截止日期,它无法获取实时信息。让我们验证这一点。
# 实验一:实时信息获取
response = chat("今天北京的天气怎么样?气温多少度?")
print("【实时信息获取】")
print(response)
print("\n" + "="*60)
print("📌 观察:LLM 无法获取实时天气数据,只能给出模糊回答或声明自己无法访问实时信息。")
print("🔧 Agent 解法:通过 get_weather 工具调用天气 API 获取实时数据。")
运行后你会发现,LLM 要么坦诚地说"我无法获取实时数据",要么给出一个基于训练数据的模糊回答(如"北京夏天通常比较热")。这正是 Agent 需要搜索工具和API 调用工具的原因。
实验二:精确数学计算
LLM 本质上是一个文本生成模型,它的"计算"是通过模式匹配完成的,而不是真正的数学运算。对于复杂计算,它经常出错。
# 实验二:精确数学计算
response = chat("请计算 7654321 × 1234567 的结果。")
print("【精确数学计算】")
print(response)
print("\n" + "="*60)
# 验证正确答案
correct = 7654321 * 1234567
print(f"✅ Python 计算的正确答案:{correct}")
print(f"📌 观察:LLM 的回答是否与正确答案一致?大概率不一致。")
print(f"🔧 Agent 解法:通过 calculator 工具或 code_executor 工具执行精确计算。")
这个实验的结果通常很有戏剧性——LLM 会自信地给出一个看起来合理但实际上错误的数字。这不是模型的"bug",而是其架构的固有局限:Transformer 不是为精确计算设计的。
实验三:文件系统操作
LLM 被困在一个"文字沙箱"中,它无法触及文字之外的任何系统资源。让我们验证这一点。
# 实验三:文件系统操作
response = chat("请帮我在桌面上创建一个名为 'agent_test.txt' 的文件,内容写入 'Hello Agent!'。")
print("【文件系统操作】")
print(response)
print("\n" + "="*60)
print("📌 观察:LLM 只能告诉你'怎么做',但无法真正执行文件操作。")
print("🔧 Agent 解法:通过 file_write 工具直接操作文件系统。")
LLM 会给你一段 Python 代码或命令行指令来创建文件,但它自己无法执行这些操作。这就是"能说不能做"的典型体现。
实验四:多步推理与信息整合
单步任务对 LLM 来说不算难,但当任务需要多步推理、信息整合和自我验证时,纯 LLM 的局限就会充分暴露。
# 实验四:多步推理与信息整合
response = chat(
"请帮我完成以下任务:\n"
"1. 查找 Python 3.12 的发布日期\n"
"2. 计算从发布日期到今天过了多少天\n"
"3. 查找 Python 3.12 新增了哪些主要特性\n"
"4. 将以上信息整理成一份简短的技术摘要"
)
print("【多步推理与信息整合】")
print(response)
print("\n" + "="*60)
print("📌 观察:LLM 会尝试回答,但信息可能过时、天数计算可能错误、特性列表可能不完整。")
print("🔧 Agent 解法:分步调用搜索工具获取准确信息 + 计算工具精确计算 + 最终整合。")
这个实验暴露了纯 LLM 在复杂任务上的多重局限:信息可能过时(感知缺陷)、计算可能出错(工具缺陷)、无法验证自己的回答(反思缺陷)。
实验五:与外部服务交互
现代应用离不开与外部服务的交互——发送 HTTP 请求、调用第三方 API、读取远程数据。让我们看看 LLM 能否独立完成这些操作。
# 实验五:与外部服务交互
response = chat("请帮我向 https://httpbin.org/post 发送一个 POST 请求,body 为 {'test': 'hello'},并告诉我返回结果。")
print("【外部服务交互】")
print(response)
print("\n" + "="*60)
print("📌 观察:LLM 会给出代码示例,但无法真正发送 HTTP 请求。")
print("🔧 Agent 解法:通过 http_request 工具直接发送请求并获取响应。")
!curl -X POST https://httpbin.org/post -H "Content-Type: application/json" -d '{"test": "hello"}'
同样,LLM 只能"教你怎么做",而不能"替你做"。Agent 通过 HTTP 请求工具,可以直接与外部服务交互并将结果纳入推理过程。
5.3 实验总结 链接到标题
通过以上五个实验,我们可以清晰地总结出 LLM 的五大能力缺口——这些缺口恰好构成了 Agent 工具体系的设计蓝图。
LLM 五大能力缺口与 Agent 工具解法
| 能力缺口 | 具体表现 | Agent 工具解法 | 对应课程章节 |
|---|---|---|---|
| 无法获取实时信息 | 训练数据有截止日期 | 搜索工具、API 调用工具 | 第二章 Function Calling |
| 无法精确计算 | 大数乘法、复杂公式出错 | 计算器工具、代码执行工具 | 第二章 Function Calling |
| 无法操作外部系统 | 不能读写文件、发送请求 | 文件工具、HTTP 工具 | 第二章 Function Calling、第九章 MCP |
| 无法多步推理验证 | 复杂任务信息遗漏、无法自检 | ReAct 循环、Reflection | 第三章 ReAct、第六章 Reflection |
| 无法跨系统协作 | 单一模型能力有上限 | 多 Agent 协作、A2A 协议 | 第八章 Multi-Agent、第十章 A2A |
这张表格就是我们整门课程的"路线图"。从下一章开始,我们将逐一填补这些能力缺口,把一个"只能聊天"的 LLM 逐步改造成一个"能感知、能推理、能行动、能协作"的完整 Agent 系统。
第6章:Agent vs Workflow 概念辨析
链接到标题
在理解了 Agent 的能力之后,一个实际开发中非常重要的问题浮出水面:是不是所有任务都应该用 Agent?答案是否定的。Agent 的灵活性和自主性是有代价的——它的执行路径不可预测、调试难度更高、Token 消耗更多、出错概率也更大。在很多场景下,一个简单的固定流程(Workflow)反而是更好的选择。
6.1 核心区别 链接到标题
Workflow(工作流)是指任务的执行路径在设计时就已经确定——步骤 A 完成后执行步骤 B,步骤 B 完成后执行步骤 C,整个流程是固定的、可预测的。而 Agent 的执行路径是动态的——它在每一步都根据当前状态自主决定下一步做什么,路径在运行时才确定。
用一个具体例子来感受两者的差异。假设我们要构建一个"每日新闻摘要"系统:
Workflow 方案:每天早上 8 点 → 抓取 RSS 源 → 过滤关键词 → 调用 LLM 生成摘要 → 发送邮件。这个流程每天执行完全相同的步骤,不需要任何动态决策。
Agent 方案:用户说"帮我整理今天 AI 领域的重要新闻"→ Agent 自主决定搜索哪些来源 → 判断哪些内容值得纳入 → 决定摘要的详细程度 → 必要时追加搜索补充信息。这个流程每次执行路径都可能不同。
显然,第一个场景用 Workflow 更合适——路径固定、成本低、可靠性高;第二个场景才需要 Agent——路径不确定、需要动态判断。
6.2 选型决策树 链接到标题
在实际项目中,我们可以用以下三个问题来快速判断应该用 Agent 还是 Workflow:
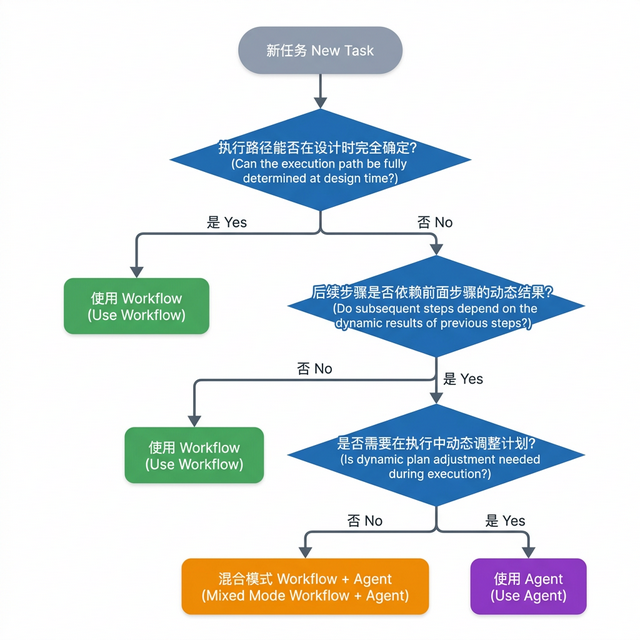
问题一:任务的执行路径是否在设计时就能完全确定?
如果你能在写代码之前就画出完整的流程图(每个步骤、每个分支都确定),那就用 Workflow。如果流程图上有"视情况而定"的节点,就需要考虑 Agent。
问题二:后续步骤的选择是否依赖前面步骤的结果?
如果"步骤 B 做什么"取决于"步骤 A 返回了什么",且这种依赖关系在设计时无法穷举,就需要 Agent 的动态决策能力。
问题三:任务是否需要在执行过程中动态调整计划?
如果任务执行到一半发现原计划不可行,需要 Agent 自主切换策略,那就必须用 Agent。
6.3 典型场景对比表 链接到标题
Agent vs Workflow 典型场景选型对比
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 每日定时发送报告 | Workflow | 路径固定,步骤可预测 |
| 用户问"帮我调研竞品" | Agent | 调研路径动态,依赖中间结果 |
| 表单提交后发送确认邮件 | Workflow | 触发条件和执行步骤完全确定 |
| 用户问"帮我订一张最便宜的机票" | Agent | 需要搜索、比价、条件判断 |
| 数据清洗流水线(ETL) | Workflow | 步骤固定,可用有向无环图(DAG)描述 |
| 客服机器人处理复杂投诉 | Agent | 对话路径不可预测,需动态决策 |
| 代码 CI/CD 流程 | Workflow | 每个阶段明确,顺序固定 |
| 自动化漏洞扫描与修复 | Agent | 修复策略依赖扫描结果,路径动态 |
从表格中可以看出一个规律:Workflow 适合"已知路径"的自动化,Agent 适合"未知路径"的智能决策。在实际项目中,最常见的架构是"Workflow 作为骨架,Agent 作为关键节点"——用 Workflow 控制整体流程,在需要动态决策的节点嵌入 Agent。这种混合架构兼顾了可靠性和灵活性。
⚠️ 常见误区:很多初学者在学了 Agent 之后,倾向于"什么都用 Agent"。这会导致系统不可预测、调试困难、成本失控。记住:Agent 是解决"不确定性"的工具,如果任务本身是确定的,Workflow 永远是更好的选择。
本章总结
链接到标题
让我们回顾本章的核心收获:
本章核心收获:
Agent 不是"更聪明的聊天机器人",而是一个能感知、能推理、能行动的自主系统
TAO 循环(Think → Act → Observe)是所有 Agent 架构的共同基础
Agent 的四大核心特征:自主性、感知、推理规划、行动执行
2025-2026 年 Agent 技术进入生产落地期,三大基础设施(模型能力、MCP 协议、框架工具链)已经成熟
LLM 存在五大能力缺口,Agent 通过工具体系来填补这些缺口
Agent 适合"未知路径"的智能决策,Workflow 适合"已知路径"的固定流程
Agent 技术生态包含框架层、协议层、应用层,正处于快速演进阶段
在本章的实验中,我们反复遇到同一个问题:LLM 能"想"但不能"做"。它知道应该调用天气 API,但无法真正发送请求;它知道应该用 Python 计算,但无法真正执行代码。那么,如何让 LLM 真正"动手"呢?
答案就是下一章的主题——Function Calling。我们将从零实现工具定义、参数提取、执行调度的完整流程,不依赖任何框架,用原生 API 手写 Agent 的第一个核心能力。
⏰ 版本与时效声明:本课件内容截至 2026 年 3 月。文中涉及的框架版本、协议标准、模型能力等信息可能随技术发展而变化,建议结合最新官方文档进行验证。
第二部分:技术层
链接到标题
在上一节认知层的课程中,我们建立了对 AI Agent 的整体认知框架——理解了 TAO 循环的运转逻辑、Agent 与 Workflow 的本质区别,以及智能体的四要素构成。现在我们将进入技术实现的核心环节:Function Calling。这是 Agent 从"纸上谈兵"走向"动手执行"的关键跃迁。
很多初学者对 Function Calling 存在一个根深蒂固的误解:以为是"LLM 自己执行了函数"。这个理解是错误的。实际上,LLM 从头到尾都没有执行任何代码——它只是生成了一段结构化的"调用指令",真正的执行完全由我们的代码完成。准确理解这个分工机制,是后续所有开发工作的基础。
本节课程的设计理念是 “先裸写后框架”。我们不会引入 LangChain 或任何其他框架,而是用原生 OpenAI/DeepSeek API 从零实现 Function Calling 的完整流程。这样做的目的是让你真正理解工具调用的底层机制——当你后续使用框架时,你知道框架在背后帮你做了什么,遇到问题时也能快速定位。
第7章:Function Calling 底层原理详解
链接到标题
本章是整个技术层的基础章节,必须打破一个常见误解并建立正确的底层认知。我们会用"调度员"类比来直观理解 LLM 与代码的分工关系,然后详细拆解 Function Calling 的六步完整流程。
⚠️ 前置知识提醒:本章内容假设你已经了解基本的 LLM API 调用方式(如
client.chat.completions.create())。如果你对 Chat Completions API 还不熟悉,建议先学习相关基础课程。
7.1 核心误解纠正:LLM 并不执行函数 链接到标题
在开始写代码之前,我们需要先准确理解 Function Calling 的本质。这个知识点看似简单,但它是整个 Agent 体系的基石——理解偏差会导致后续一系列设计错误。
核心误解:很多人以为 Function Calling 是"LLM 自己执行了函数"。
正确理解:LLM 只生成"调用指令"(JSON 格式),代码负责真正执行。
用一个生活类比来理解:Function Calling 就像你和一个非常聪明的"调度员"合作。调度员(LLM)听了你的需求后,会告诉你"你应该打电话给张三,告诉他这些信息"(生成调用指令)。但打电话这个动作,是你自己完成的(代码执行)。打完电话后,你把张三的回复告诉调度员,调度员再综合所有信息给你最终建议。
💡 注意:调度员不会自己打电话,只是告诉你应该打给谁、说什么。同样,LLM 不会执行代码,只是生成执行指令。
更正式地说,Function Calling 的完整流程分为六个步骤:
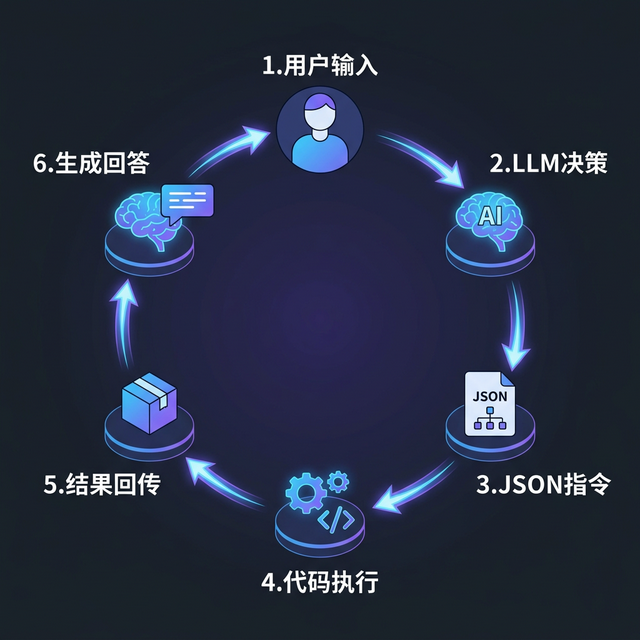
让我们逐步拆解这六个步骤:
Function Calling 六步流程详解
| 步骤 | 阶段名称 | 执行者 | 核心动作 |
|---|---|---|---|
| 步骤 1 | 用户输入 | 用户 | 向 Agent 提出请求,例如"北京今天天气怎么样?" |
| 步骤 2 | LLM 分析与决策 | LLM | 接收用户请求和可用工具列表,判断是否需要调用工具 |
| 步骤 3 | 生成调用指令 | LLM | 返回结构化 JSON:{"name": "get_weather", "arguments": {"city": "北京"}} |
| 步骤 4 | 代码执行工具 | 代码 | 解析调用指令,找到对应函数并执行 |
| 步骤 5 | 结果回传 | 代码 | 将工具执行结果封装为消息,回传给 LLM |
| 步骤 6 | LLM 综合回答 | LLM | 结合用户请求和工具结果,生成最终自然语言回答 |
理解了这个流程之后,一个关键问题浮出水面:LLM 是怎么知道有哪些工具可用、每个工具需要什么参数的?答案就是下一节的主题——工具定义。
⚠️ 常见误区:这个误解非常普遍,值得花时间反复强调。可以用"LLM 永远不会真正执行任何代码"这句话作为核心结论记住。
真实代码逻辑拆解(Python 示例) 我们来看一段极简但完整的真实流水线代码:
- 第一阶段:准备本地工具和路由表
import json
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
# 使用Deepseek的API来调用大模型
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# 1. 这是你本地真正能干活的函数(大模型并不知道它的具体实现代码)
def get_weather(location: str):
print(f"🔧 [本地执行中] 正在查询 {location} 的天气...")
# 这里可以是发HTTP请求、查数据库等真实操作
if location == "北京":
return '{"temp": 25, "condition": "晴"}'
return '{"temp": 20, "condition": "未知"}'
# 2. 【关键抽象】建立“字符串名字”到“内存里的真实函数”的映射字典
available_functions = {
"get_weather": get_weather, # 这里是将字符串 "get_weather" 映射到你本地的 get_weather 函数
# 如果有别的工具:"search_database": search_database
}
# 3. 告诉大模型你有这个工具(只给说明书,不给代码)
tools_description = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"]
}
}
}]
- 第二阶段:第一次请求大模型
messages = [{"role": "user", "content": "北京今天热吗?"}]
# 大模型看到你的问题和工具说明书,它决定调用工具
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools_description # 告诉大模型你有哪些工具
)
response_message = response.choices[0].message
# 查看大模型是否调用了工具
print(response_message.tool_calls)
- 第三阶段:【核心】你的本地代码接管并执行 此时,response_message 里虽然没有回答,但带有 tool_calls。 你必须写代码来拦截并处理它:
# 检查大模型是不是发出了调用工具的请求
if response_message.tool_calls:
# 记得把大模型的"请求调用"这条记录也放进历史对话里
messages.append(response_message)
# 遍历大模型想要调用的所有函数(有时候它会并行调用多个)
for tool_call in response_message.tool_calls:
# 1. 提取大模型建议的指令
function_name = tool_call.function.name # 比如提取到 "get_weather"
function_args_json = tool_call.function.arguments # 比如提取到 "{\"location\": \"北京\"}"
# 2. 将大模型生成的 JSON 字符串解析为真正的 Python 字典
function_args = json.loads(function_args_json)
# 3. 【真正执行的魔法在此】
# 通过大模型给的字符串名字,从你的映射字典里找到真正的 Python 函数内存地址
function_to_call = available_functions.get(function_name)
if function_to_call:
# 4. 在你的本地机器上,真正执行这个函数,并传入解析好的参数!
function_result = function_to_call(**function_args)
print(f"✅ [本地执行完毕] 得到结果: {function_result}")
else:
function_result = "Error: 找不到该函数"
# 5. 将执行得到的结果,打包成特定格式(role="tool"),准备发回给大模型
messages.append({
"tool_call_id": tool_call.id, # 必须带上这个ID,告诉大模型这是对刚才它请求的回复
"role": "tool",
"name": function_name,
"content": function_result, # 把真实结果(如 '{"temp": 25}')塞进去
})
# 打印最终的messages
print(messages)
- 第四阶段:第二次请求大模型(带着结果)
# 现在 messages 里面包含了:用户问题 -> 模型的调用请求 -> 你本地执行的结果
# 再次发给大模型,它就能看着真实结果,总结出人话了
second_response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
)
print("\n🤖 最终回答:", second_response.choices[0].message.content)
其实说穿了,这套机制是一个 “RPC(远程过程调用)思想” 的变种:
大模型充当了 大脑/调度器。 你的 Python 脚本充当了 中间件和执行节点。 available_functions 字典是连接虚拟文本世界(名字)和真实物理世界(内存代码)的唯一桥梁。 没有你在本地写一个 for tool_call in tool_calls: 去遍历、解析、然后主动调用原本写好的函数(function_to_call(**args)),大模型传回来的那段 JSON 就只是一段死板的文本而已,什么真实的事情都不会发生。
OpenAI 官方原生的 Python SDK (openai 包) 并没有帮你封装这部分执行逻辑。你必须自己写 if tool_calls: 判断、自己做字典映射 available_functions[function_name]、自己执行函数,并自己把结果拼装回 messages 数组里发送给大模型。
你在使用 LangChain、AutoGen, Dify 等各种上层 Agent 框架时,觉得“大模型好神奇,自己去调用了搜索工具”,其实都只是这些框架的底层帮你封装好了对应着我们上述「第三阶段」的 if/for 拦截、查表和执行的代码罢了。
第8章:API 基础概念与工具定义规范
链接到标题
本章是工具定义的基础,重点在于理解 JSON Schema 的作用以及工具定义的三要素。工具定义写得好不好,直接决定 Agent 能否正确工作。
8.1 工具定义三要素:name、description、parameters 链接到标题
Function Calling 的第一步,是告诉 LLM"你有哪些工具可以用"。这通过一个标准化的 JSON Schema 来实现。每个工具的定义包含三个核心字段:name(工具名称)、description(工具描述)、parameters(参数定义)。LLM 完全依赖这三个字段来决定何时调用哪个工具、传什么参数。
让我们先看一个完整的工具定义示例,然后逐字段解析:
# 一个完整的工具定义示例:天气查询工具
weather_tool = {
"type": "function",
"function": {
"name": "get_weather", # 工具名称,建议:小写 + 下划线 + 动词开头
"description": ( # 工具描述,决定调用命运:做什么、何时调用、边界在哪里。
"获取指定城市的当前天气信息,包括气温、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞等问题时,调用此工具。"
),
"parameters": { # 参数定义
"type": "object", # 参数类型:object 表示 JSON 对象
"properties": {
"city": { # 属性名:city
"type": "string", # 基础类型:string、number、boolean
"description": "要查询天气的城市名称,例如:北京、上海、广州" # 参数说明
}
},
"required": ["city"] # 必填参数列表
}
}
}
8.1.1 name:工具的唯一标识 链接到标题
name 是工具的唯一标识符,LLM 在决定调用工具时会返回这个名称。命名规则很简单:使用小写字母和下划线,清晰表达工具的功能。
# ✅ 好的命名:清晰、具体、动词开头
# "name": "get_weather"
# "name": "search_web"
# "name": "calculate_math"
# "name": "read_file"
# ❌ 差的命名:模糊、过于通用
# "name": "tool1"
# "name": "helper"
# "name": "do_something"
命名的关键原则是让 LLM 一眼就能理解这个工具做什么。虽然 LLM 主要依赖 description 来决策,但一个好的名称能提供额外的语义线索。
8.1.2 description:决定工具命运的关键字段 链接到标题
description 是整个工具定义中最重要的字段——它直接决定了 LLM 是否会在正确的时机调用这个工具。很多 Agent 的工具调用失败,根源不在代码逻辑,而在于工具描述写得不够好。
一个好的工具描述需要回答三个问题:
这个工具做什么?(功能说明)
什么时候应该调用它?(触发条件)
它不能做什么?(能力边界,可选但推荐)
我们通过一个对比来感受好描述和差描述的差距:
工具描述质量对比:好描述 vs 差描述
| 维度 | 差描述 | 好描述 |
|---|---|---|
| 功能说明 | “获取天气” | “获取指定城市的当前天气信息,包括气温、天气状况和湿度” |
| 触发条件 | (缺失) | “当用户询问某个城市的天气、气温、是否需要带伞等问题时调用” |
| 能力边界 | (缺失) | “仅支持中国大陆城市,不支持历史天气查询” |
| LLM 决策效果 | 可能在不该调用时调用,或该调用时不调用 | 精准匹配用户意图,几乎不会误调用 |
🔥 踩坑预警:工具描述是写给 LLM 看的,不是写给人看的。LLM 需要明确的触发条件来做决策,而不是模糊的功能概述。如果你发现 Agent 经常调用错误的工具,第一个排查方向就是工具描述。
我们设计一个实验:用三个测试问题分别测试好描述和坏描述版本的工具,观察 LLM 的调用准确率。
import json
# 好描述版本的工具定义(前面已定义)
good_tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时,调用此工具。"
"目前支持的城市:北京、上海、广州、深圳、杭州。"
),
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "要查询天气的城市名称,例如:北京、上海、广州"
}
},
"required": ["city"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": (
"执行数学计算,支持加减乘除、幂运算、三角函数、对数等。"
"当用户需要精确计算数学表达式时调用此工具。"
"输入应为合法的 Python 数学表达式,例如:'2**10'、'sqrt(144)'。"
),
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "要计算的数学表达式,使用 Python 语法"
}
},
"required": ["expression"]
}
}
}
]
# 坏描述版本的工具定义
bad_tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取天气", # ❌ 过于简略
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市"}
},
"required": ["city"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "计算", # ❌ 极度模糊
"parameters": {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "表达式"}
},
"required": ["expression"]
}
}
}
]
# 测试用例
test_cases = [
("北京今天天气怎么样?", "应调用 get_weather"),
("帮我算一下 123 * 456", "应调用 calculate"),
("Python 是什么语言?", "不应调用任何工具"),
]
print("=" * 60)
print("📊 对照实验:好描述 vs 坏描述")
print("=" * 60)
MODEL="deepseek-chat"
for question, expected in test_cases:
print(f"\n问题:{question}")
print(f"预期:{expected}")
# 好描述版本
resp_good = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": question}],
tools=good_tools,
tool_choice="auto",
max_tokens=256
)
good_calls = resp_good.choices[0].message.tool_calls
good_result = [tc.function.name for tc in good_calls] if good_calls else ["无工具调用"]
# 坏描述版本
resp_bad = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": question}],
tools=bad_tools,
tool_choice="auto",
max_tokens=256
)
bad_calls = resp_bad.choices[0].message.tool_calls
bad_result = [tc.function.name for tc in bad_calls] if bad_calls else ["无工具调用"]
print(f" 好描述结果:{good_result}")
print(f" 坏描述结果:{bad_result}")
基于实践经验,我们总结出一个工具描述的"黄金模板",包含四个要素:

按照这个模板,一个完整的工具描述应该是这样的:
# 黄金模板示例
description = (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。" # 功能说明
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时," # 触发条件
"城市名称应为中文全称,例如:北京、上海、广州。" # 输入格式
"目前仅支持中国大陆主要城市,不支持历史天气和天气预报查询。" # 能力边界
)
这个模板不是死板的公式,而是一个思维框架。核心原则是:站在 LLM 的角度思考——它需要什么信息才能做出正确的调用决策?
8.1.3 parameters:参数的 JSON Schema 定义 链接到标题
parameters 字段使用 JSON Schema 标准来定义工具接受的参数。JSON Schema 是一个广泛应用于 API 定义的国际标准(类似于 OpenAPI/Swagger 中的参数定义)。使用标准化格式的好处是:LLM 在训练时已经见过大量 JSON Schema 样本,因此能够精准理解参数定义的含义。
LLM 会根据这个定义,从用户的自然语言输入中提取出结构化的参数值。
# 一个更复杂的参数定义示例:搜索工具
search_tool_params = {
"type": "object", # 参数容器类型,通常为 object
"properties": { # 具体参数定义集合
"query": { # 参数名:query(搜索词)
"type": "string", # 参数数据类型:字符串
"description": "搜索关键词,应该是简洁明确的搜索查询" # 参数功能描述,供模型理解何时使用
},
"max_results": { # 参数名:max_results(结果数)
"type": "integer", # 参数数据类型:整数
"description": "返回的最大结果数量,默认为 5", # 参数功能描述
"default": 5 # 默认值设定:若模型未提供则使用此值
},
"language": { # 参数名:language(语言)
"type": "string", # 参数数据类型:字符串
"description": "搜索结果的语言偏好", # 参数功能描述
"enum": ["zh", "en"], # 枚举约束:限定模型只能从指定列表中选择
"default": "zh" # 默认值设定
}
},
"required": ["query"] # 只有 query 是必填的
}
这段参数定义展示了几个关键特性:type 指定参数类型(string、integer、boolean 等),description 帮助 LLM 理解参数含义,enum 限定可选值范围,required 标注必填参数,default 提供默认值。LLM 会根据这些信息,从用户的自然语言中精确提取参数。
OpenAI 官方关于 Function Calling 参数的说明
OpenAI 官方也明确指出了他们的底层就是基于 JSON Schema 的:
OpenAI 官方指南: https://platform.openai.com/docs/guides/function-calling
注意点:OpenAI 目前支持的是 JSON Schema Draft 2020-12 版本的一个子集(绝大部分核心功能都支持,但极少数太生僻的正则特性可能不支持,具体以 OpenAI 文档为准)。
给学员的一个小建议: 刚开始写结构复杂的 properties 很容易漏写括号或者类型不匹配,可以向学员推荐一个可视化校验工具:https://www.json.cn/ 把写好的 JSON 贴进去,可以一键检查格式对不对。
第9章:大模型内置提示词模板与工具调用响应模式
链接到标题
在理解了 Function Calling 的基本流程后,我们需要深入 API 层面,理解如何控制 LLM 的工具调用行为。本章重点讲解 tool_choice 参数和 LLM 返回的 tool_calls 结构。
9.1 tool_choice 四种模式:控制 LLM 的工具调用行为 链接到标题
在前面的流程中,我们一直假设 LLM 自主决定是否调用工具。但实际上,API 提供了精确控制这一行为的参数——tool_choice。理解这些模式,能让你在不同场景下精确控制 Agent 的行为。
在实际项目中,我们经常需要精确控制 LLM 的工具调用行为。例如:在日志记录场景下,我们希望每次对话都强制调用日志工具;在纯文本生成场景下,我们希望禁止调用任何工具。tool_choice 参数就是为了满足这些需求而设计的。

tool_choice 四种模式行为对比
| 模式 | 值 | LLM 行为 | 适用场景 |
|---|---|---|---|
| 自动模式 | "auto" | LLM 自主判断是否调用工具 | 通用场景,最常用 |
| 强制调用 | "required" | 必须调用至少一个工具,不能直接回答 | 需要确保工具被执行时 |
| 禁止调用 | "none" | 不允许调用任何工具,只能生成文本 | 需要纯文本回答时 |
| 指定工具 | {"type": "function", "function": {"name": "xxx"}} | 强制调用指定的工具 | 需要确保特定工具被调用时 |
下面我们用代码实际测试这三种模式的行为差异:
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载 .env 配置文件,获取 API 密钥等环境变量
load_dotenv()
# 初始化 OpenAI 客户端(此处配置为 DeepSeek API 终端)
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
MODEL = "deepseek-chat"
# 定义工具(Tools)列表,采用 JSON Schema 描述函数接口
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的当前天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"] # 声明必选参数
}
}
}
]
def test_tool_choice_mode(user_message: str, mode, label: str):
"""
封装测试函数,演示不同 tool_choice 策略对模型决策的影响
:param user_message: 用户输入的文本
:param mode: tool_choice 参数值 ('auto', 'required', 'none')
:param label: 打印显示的模式说明
"""
print(f"\n{'='*55}")
print(f"模式:{label} | tool_choice={mode!r}")
print(f"问题:{user_message}")
print('='*55)
# 发起对话请求
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": user_message}
],
tools=tools, # 注入工具定义
tool_choice=mode, # 控制工具调用行为的关键参数
temperature=0.7, # 控制随机性
max_tokens=512 # 控制回复长度
)
msg = response.choices[0].message
# 判断模型返回的是工具调用指令还是普通文本回复
if msg.tool_calls:
for tc in msg.tool_calls:
print(f" 🔧 调用工具:{tc.function.name}")
print(f" 📦 参数:{tc.function.arguments}")
else:
# 若无 tool_calls,则输出模型生成的直接回答
print(f" 💬 直接回答:{msg.content[:200]}")
# 核心对比测试:针对同一天气查询问题,观察三种模式的差异
question = "北京今天天气怎么样?"
# 1. auto:默认模式,模型根据意图自动判断是否需要调用工具
test_tool_choice_mode(question, "auto", "自动模式(auto)")
# 2. required:强制模式,模型必须选择并调用一个工具(即使不一定合适)
test_tool_choice_mode(question, "required", "强制调用(required)")
# 3. none:禁用模式,模型被禁止使用工具,只能进行纯文本回复
test_tool_choice_mode(question, "none", "禁止调用(none)")
运行这段代码后,你会看到三种截然不同的行为表现:
auto模式:LLM 判断需要工具,调用get_weatherrequired模式:LLM 被强制调用工具(即使它本来想直接回答也不行)none模式:LLM 只能用训练数据回答,会说"我无法获取实时天气"
让我们进一步测试一个不需要工具的问题,观察三种模式的差异:
# 测试:对于不需要工具的问题,三种模式的差异
question2 = "Python 中 list 和 tuple 有什么区别?"
test_tool_choice_mode(question2, "auto", "自动模式(auto)")
test_tool_choice_mode(question2, "required", "强制调用(required)")
test_tool_choice_mode(question2, "none", "禁止调用(none)")
这个测试更有趣:对于"Python 知识"这类不需要工具的问题,auto 模式下 LLM 会直接回答;但 required 模式下,LLM 被强制调用工具——这可能导致不符合预期的行为。这说明 required 模式要谨慎使用——强制调用工具可能导致 LLM 产生"为了调用而调用"的奇怪行为。
9.2 LLM 返回的 tool_calls 结构解析 链接到标题
当 LLM 决定调用工具时,它会返回一个包含 tool_calls 字段的消息。理解这个结构对正确处理工具调用至关重要。
# 获取带工具调用的响应
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=tools,
tool_choice="auto"
)
assistant_message = response.choices[0].message
# 检查是否包含工具调用
if assistant_message.tool_calls:
for tool_call in assistant_message.tool_calls:
print(f"调用 ID:{tool_call.id}") # 唯一标识符
print(f"工具类型:{tool_call.type}") # 通常是 "function"
print(f"函数名称:{tool_call.function.name}") # 要调用的函数名
print(f"函数参数:{tool_call.function.arguments}") # JSON 格式的参数
print("-" * 40)
每个 tool_call 对象包含以下关键字段:
tool_call 对象字段说明
| 字段 | 类型 | 说明 |
|---|---|---|
id | string | 唯一标识符,用于将执行结果与调用请求关联 |
type | string | 调用类型,目前固定为 “function” |
function.name | string | 要调用的函数名称 |
function.arguments | string | JSON 格式的参数字符串 |
特别注意 tool_call_id 字段——它必须与 LLM 返回的调用 ID 完全一致,否则 LLM 无法将结果与调用请求关联,会导致后续推理出错。
实践建议:在绝大多数场景下,
"auto"是最佳选择。"required"适合"必须执行某个操作"的场景(如每次对话都记录日志)。"none"适合"需要纯文本输出"的场景(如生成报告时不希望 LLM 中途调用工具)。指定工具模式适合"强制执行特定操作"的场景(如强制用户身份验证)。
第10章:Function Calling 完整生命周期复现
链接到标题
本章是本技术层的核心实战环节。我们将不依赖任何框架,用原生 OpenAI SDK 手写完整的工具调用链路,完整走通"用户输入 → LLM 决策 → 参数提取 → 工具执行 → 结果回传 → 最终回答"的全流程。
10.1 环境准备与基础配置 链接到标题
首先,确保我们的环境已经就绪。如果你已经完成了前面的配置,可以直接复用。
import os
import json
from dotenv import load_dotenv
from openai import OpenAI
# 从项目根目录的 .env 文件加载环境变量(DEEPSEEK_API_KEY 等)
load_dotenv()
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
MODEL = "deepseek-chat"
print("✅ 环境配置完成")
10.2 步骤一:定义工具函数 链接到标题
我们先实现两个真实可用的工具函数。注意,这些是普通的 Python 函数——Function Calling 的魔法不在函数本身,而在于 LLM 如何决定调用它们。
import math
import requests
# 请确保环境变量中已经设置了 TAVILY_API_KEY,获取API官网地址:https://app.tavily.com/home
TAVILY_API_KEY = os.environ.get("TAVILY_API_KEY", "你的_tavily_api_key")
# ==========================================
# 1. 本地真正的工具函数执行逻辑:调用 Tavily API
# ==========================================
def get_weather(query: str) -> str:
"""
使用 Tavily 搜索天气信息的底层真实函数
"""
print(f"\n🌍 [Tool 执行中] 正在通过 Tavily 搜索: {query} ...")
url = "https://api.tavily.com/search"
headers = {"Content-Type": "application/json"}
payload = {
"api_key": TAVILY_API_KEY,
"query": query,
"search_depth": "basic", # 基础搜索速度更快
"include_answer": True, # 让 Tavily 尝试直接提取简短回答
"max_results": 3 # 只要前 3 个最相关的网页结果
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
data = response.json()
# 提取有价值的信息返回给大模型(优先返回 Tavily 的总结内容)
result_text = data.get("answer", "")
if not result_text:
# 如果没有直接 answer,就把搜索到的 snippet 组装起来
snippets = [result["content"] for result in data.get("results", [])]
result_text = "\n".join(snippets)
return json.dumps({"status": "success", "search_result": result_text},ensure_ascii=False)
else:
return json.dumps({"status": "error", "message": f"Tavily API 请求失败: {response.text}"})
def calculate(expression: str) -> str:
"""安全的数学计算工具,支持基本运算和常用数学函数"""
# 安全白名单:只允许数学相关的函数和运算符
allowed_names = {
"abs": abs, "round": round, "min": min, "max": max,
"pow": pow, "sum": sum,
"sqrt": math.sqrt, "log": math.log, "log10": math.log10,
"sin": math.sin, "cos": math.cos, "tan": math.tan,
"pi": math.pi, "e": math.e,
}
try:
# 使用 eval 配合白名单,防止代码注入
result = eval(expression, {"__builtins__": {}}, allowed_names)
return json.dumps({
"expression": expression,
"result": result,
"status": "success"
}, ensure_ascii=False)
except Exception as e:
return json.dumps({
"expression": expression,
"error": str(e),
"status": "failed"
}, ensure_ascii=False)
# 验证工具函数
print("天气查询测试:", get_weather("搜索北京今天的天气"))
print("计算测试:", calculate("7654321 * 1234567"))
这两个工具函数有几个值得注意的设计决策。calculate 使用了带白名单的 eval,而不是直接执行任意代码,这是一个重要的安全实践:永远不要让 LLM 生成的内容直接执行任意代码,必须通过白名单或沙箱进行限制。最后,两个函数都返回 JSON 字符串而非 Python 对象,因为工具的返回值需要作为消息传回 LLM,字符串格式更通用。
text = "(1 + 2) * 3"
print(text)
# 输出的是字符串本身:"(1 + 2) * 3"
result = eval(text)
print(result)
# 输出的是数字:9
🔥 踩坑预警:
eval函数是 Python 中最危险的函数之一——如果不加限制,攻击者可以通过构造恶意表达式执行任意代码(如__import__("os").system("rm -rf /"))。本例中通过{"__builtins__": {}}禁用了内置函数,并用白名单限制了可用函数,但在生产环境中,建议使用ast.literal_eval或专门的数学表达式解析库(如sympy、numexpr)来替代eval。
11.3 步骤二:构建工具定义(JSON Schema) 链接到标题
有了工具函数之后,我们需要用 JSON Schema 告诉 LLM 这些工具的存在。这一步是 Function Calling 的"注册"环节。
# 定义工具的 JSON Schema —— 这是 LLM 的"工具说明书"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时,调用此工具。"
"目前支持的城市:北京、上海、广州、深圳、杭州。"
),
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "要查询天气的城市名称,例如:北京、上海、广州,对应的日期,例如:今天、明天、后天,以及需要查询的天气信息,例如:天气、气温、湿度等"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": (
"执行数学计算,支持加减乘除、幂运算、三角函数、对数等。"
"当用户需要精确计算数学表达式时调用此工具。"
"输入应为合法的 Python 数学表达式,例如:'2**10'、'sqrt(144)'、'7654321 * 1234567'。"
"注意:不要用此工具回答不涉及计算的问题。"
),
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "要计算的数学表达式,使用 Python 语法,例如:'2**10'、'sqrt(144)'"
}
},
"required": ["expression"]
}
}
}
]
print(f"✅ 已注册 {len(tools)} 个工具:{[t['function']['name'] for t in tools]}")
注意观察工具描述的写法——每个描述都包含了"做什么"(功能说明)、“什么时候调用”(触发条件)和"能力边界"(支持的城市列表、输入格式要求)。这种三段式描述能显著提升 LLM 的工具选择准确率。
工具描述的三段式写法(功能说明 + 触发条件 + 能力边界)如何提升 LLM 的工具选择准确率?让我们理解其背后的原理:功能说明让 LLM 知道"这个工具能做什么",触发条件让 LLM 知道"什么时候应该用它",能力边界让 LLM 知道"什么情况下不该用它"。这三个维度共同构成了 LLM 决策的完整信息空间,缺少任何一个都会导致决策不准确。
11.4 步骤三:发送请求并获取 LLM 的工具调用决策 链接到标题
现在进入 Function Calling 的核心环节——将用户消息和工具定义一起发送给 LLM,让它决定是否需要调用工具。
def call_llm_with_tools(messages: list, tools: list) -> dict:
"""向 LLM 发送带工具定义的请求,返回完整的响应对象"""
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools,
tool_choice="auto", # "auto" 让 LLM 自主决定是否调用工具
temperature=0.7,
max_tokens=2048
)
return response
# 测试:一个需要工具的问题
messages = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气和进行数学计算。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
response = call_llm_with_tools(messages, tools)
assistant_message = response.choices[0].message
# 检查 LLM 是否决定调用工具
print(f"LLM 是否调用工具:{assistant_message.tool_calls is not None}")
if assistant_message.tool_calls:
for tool_call in assistant_message.tool_calls:
print(f" 工具名称:{tool_call.function.name}")
print(f" 调用参数:{tool_call.function.arguments}")
print(f" 调用 ID:{tool_call.id}")
else:
print(f" 直接回答:{assistant_message.content}")
运行这段代码后,你应该看到 LLM 决定调用 get_weather 工具,参数为 {"city": "北京"}。这里有几个关键细节值得注意:tool_choice="auto" 表示让 LLM 自主决定是否调用工具(也可以设为 "none" 强制不调用,或设为特定工具名强制调用);tool_calls 是一个列表,因为 LLM 可能在一次响应中决定调用多个工具;每个 tool_call 都有一个唯一的 id,用于在后续步骤中将执行结果与调用请求关联。
11.5 步骤四:执行工具并回传结果 链接到标题
LLM 给出了调用指令,现在轮到我们的代码来执行了。这一步的核心是:解析 LLM 返回的函数名和参数,找到对应的 Python 函数并执行,然后将结果封装为特定格式的消息回传给 LLM。
# 建立工具名称到函数的映射(工具注册表),方便根据 LLM 返回的名称动态调用
TOOL_REGISTRY = {
"get_weather": get_weather,
"calculate": calculate,
}
def execute_tool_calls(assistant_message) -> list:
"""
解析并执行 LLM 消息中的所有工具调用请求。
参数:
assistant_message: LLM 生成的消息对象,包含 tool_calls 列表。
返回:
list: 包含工具执行结果的消息列表,格式符合 OpenAI API 的 tool 角色要求。
"""
tool_results = []
# 如果 LLM 没有发起工具调用,直接返回空结果列表
if not assistant_message.tool_calls:
return tool_results
# 遍历 LLM 请求的所有工具调用(LLM 可能会一次性请求调用多个工具)
for tool_call in assistant_message.tool_calls:
# 提取工具名称和 LLM 生成的参数(参数通常为 JSON 字符串,需解析为字典)
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"🔧 正在执行工具:{func_name},参数:{func_args}")
# 在注册表中查找对应的函数并传入参数执行
if func_name in TOOL_REGISTRY:
# 使用 ** 语法将字典解包为函数的关键字参数
result = TOOL_REGISTRY[func_name](**func_args)
else:
# 如果 LLM 请求了一个未定义的工具,返回错误信息给模型
result = json.dumps({"error": f"未知工具:{func_name}"})
print(f"📋 执行结果:{result}")
# 将执行结果封装为特定的消息格式
# 核心要点:role 必须为 "tool",且 tool_call_id 必须与原始请求的 id 严格一致
tool_results.append({
"role": "tool",
"tool_call_id": tool_call.id, # 关键:用于 LLM 匹配请求与响应
"content": str(result) # 结果内容需转为字符串
})
return tool_results
# 调用执行函数,处理 assistant_message 中的工具请求
tool_results = execute_tool_calls(assistant_message)
print(f"\n✅ 工具执行完毕,共完成 {len(tool_results)} 个任务")
这段代码的核心逻辑很直接:遍历 LLM 返回的每个 tool_call,从注册表中找到对应函数,用 json.loads 解析参数后调用函数,最后将结果封装为 role: "tool" 的消息。特别注意 tool_call_id 字段——它必须与 LLM 返回的调用 ID 完全一致,否则 LLM 无法将结果与调用请求关联,会导致后续推理出错。
11.6 步骤五:将结果回传 LLM 生成最终回答 链接到标题
最后一步,我们将工具执行结果追加到消息历史中,再次调用 LLM,让它综合用户请求和工具结果生成最终的自然语言回答。
# 将 assistant 的工具调用决策追加到消息历史中
messages.append(assistant_message.model_dump())
# 将工具的实际执行结果追加到消息历史中,作为 LLM 生成回答的参考上下文
messages.extend(tool_results)
# 再次调用 LLM,传入包含工具执行结果的完整上下文,以生成最终的自然语言回答
final_response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools,
temperature=0.7,
max_tokens=2048
)
# 从响应中提取最终的回答文本内容
final_answer = final_response.choices[0].message.content
# 打印并展示最终生成的回答结果
print("🤖 最终回答:")
print(final_answer)
运行后,你应该看到 LLM 生成了一段自然流畅的回答,例如:“今天北京有小雪,气温较低,建议您:外出时穿厚外套,注意保暖"注意,LLM 不仅复述了工具返回的数据,还基于数据做了推理(“注意保暖”)——这就是 LLM 作为"大脑"的价值所在。
11.7 封装完整的 Function Calling 管线 链接到标题
前面我们逐步拆解了 Function Calling 的六个步骤。现在让我们把它们封装成一个完整的、可复用的管线函数。
def function_calling_pipeline(
user_message: str,
tools: list,
tool_registry: dict,
system_prompt: str = "你是一个有用的助手。",
model: str = "deepseek-chat",
verbose: bool = True
) -> str:
"""
完整的 Function Calling 管线(单轮工具调用)
参数:
user_message: 用户输入
tools: 工具定义列表(JSON Schema)
tool_registry: 工具名称到函数的映射字典
system_prompt: 系统提示词
model: 模型名称
verbose: 是否打印中间过程
返回:
LLM 的最终回答文本
"""
# 步骤 1:构建消息历史
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
]
# 步骤 2-3:发送请求,获取 LLM 决策
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice="auto",
temperature=0.7,
max_tokens=2048
)
assistant_message = response.choices[0].message
# 如果 LLM 不需要调用工具,直接返回回答
if not assistant_message.tool_calls:
if verbose:
print("💬 LLM 直接回答(未调用工具)")
return assistant_message.content
# 步骤 4:执行工具调用
if verbose:
print(f"🔧 LLM 决定调用 {len(assistant_message.tool_calls)} 个工具")
messages.append(assistant_message.model_dump())
for tool_call in assistant_message.tool_calls:
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
if verbose:
print(f" → {func_name}({func_args})")
# 执行工具
if func_name in tool_registry:
result = tool_registry[func_name](**func_args)
else:
result = json.dumps({"error": f"未知工具:{func_name}"})
if verbose:
print(f" ← {result[:200]}") # 截断过长的输出
# 步骤 5:将结果追加到消息历史
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
# 步骤 6:再次调用 LLM 生成最终回答
final_response = client.chat.completions.create(
model=model, messages=messages,
tools=tools, temperature=0.7, max_tokens=2048
)
final_answer = final_response.choices[0].message.content
if verbose:
print(f"✅ 最终回答生成完成")
return final_answer
这个管线函数封装了完整的六步流程,并添加了 verbose 参数用于调试。让我们用几个不同类型的问题来测试它的表现。
# 测试 1:需要天气工具的问题
print("=" * 60)
print("测试 1:天气查询")
print("=" * 60)
answer = function_calling_pipeline(
"上海今天天气怎么样?需要带伞吗?",
tools=tools,
tool_registry=TOOL_REGISTRY
)
print(f"\n🤖 {answer}\n")
# 测试 2:需要计算工具的问题
print("=" * 60)
print("测试 2:数学计算")
print("=" * 60)
answer = function_calling_pipeline(
"请帮我计算 2 的 20 次方是多少?",
tools=tools,
tool_registry=TOOL_REGISTRY
)
print(f"\n🤖 {answer}\n")
# 测试 3:不需要工具的问题
print("=" * 60)
print("测试 3:纯知识问答(不需要工具)")
print("=" * 60)
answer = function_calling_pipeline(
"请简要解释什么是 Function Calling?",
tools=tools,
tool_registry=TOOL_REGISTRY
)
print(f"\n🤖 {answer}\n")
# 测试 4:需要同时调用两个工具的问题
print("=" * 60)
print("测试 4:多工具调用")
print("=" * 60)
answer = function_calling_pipeline(
"北京今天多少度?另外帮我算一下 sqrt(144) + 3.14 * 2",
tools=tools,
tool_registry=TOOL_REGISTRY
)
print(f"\n🤖 {answer}")
运行这四个测试,你会观察到几个重要现象:测试 1 和测试 2 分别触发了天气工具和计算工具;测试 3 中 LLM 判断不需要工具,直接给出了回答;测试 4 最有趣——LLM 可能在一次响应中同时调用两个工具(get_weather 和 calculate),这就是 tool_calls 为什么是列表的原因。
⚠️ 常见误区:很多初学者以为 Function Calling 每次只能调用一个工具。实际上,现代 LLM(
GPT-4o、DeepSeek-V3等)支持并行工具调用——在一次响应中返回多个tool_call。我们的管线已经正确处理了这种情况(遍历tool_calls列表)。
第12章:Function Calling 故障教学与排障路径
链接到标题
在前面的章节中,我们完整实现了 Function Calling 的六步流程,并封装了一个可复用的管线函数。但在真实项目中,Function Calling 经常会遇到各种故障——工具没有被调用、调用了错误的工具、工具执行失败、LLM 的回答与工具结果不相关等等。这些故障往往让初学者感到困惑:明明代码逻辑看起来没问题,为什么就是跑不通?
本章的目标不是讲新概念,而是把高频故障一次讲透。我们会用"问题复现 → 问题分析 → 修复方案 → 效果验证"的四步法,逐一拆解四种最常见的故障类型。每个故障都会提供完整的可运行代码,让你能够亲手复现错误、理解根因、验证修复效果。掌握了这些排障技巧,你在实际项目中遇到 Function Calling 问题时,就能快速定位并解决。
在开始具体的故障分析之前,我们需要先区分两个容易混淆的概念:工具调用失败(LLM 没有调用工具或调用了错误的工具)和工具执行失败(LLM 正确调用了工具,但工具执行过程中出错)。前者通常是工具定义问题,后者通常是代码实现问题。明确区分这两者,能帮助你快速定位问题所在层级。
接下来,我们建立一个统一的排障思路。当 Function Calling 出现问题时,不要盲目调试,而是按照以下顺序逐层排查:
Function Calling 统一排障顺序
| 排查顺序 | 排查层级 | 常见问题 | 排查方法 |
|---|---|---|---|
| 第 1 步 | 工具定义层 | 描述模糊、参数定义不清、触发条件缺失 | 检查 description 是否包含功能说明、触发条件、能力边界 |
| 第 2 步 | 工具注册层 | 函数名拼写错误、注册表中缺少工具 | 检查工具定义中的 name 与注册表的 key 是否完全一致 |
| 第 3 步 | 消息拼接层 | tool_call_id 不匹配、消息顺序错误 | 检查 tool 消息的 tool_call_id 是否与 LLM 返回的 id 一致 |
| 第 4 步 | 执行层 | 工具超时、异常未捕获、返回空值 | 添加异常处理、超时控制、空值检查 |
这个排障顺序遵循"从外到内"的原则:先检查 LLM 能看到的信息(工具定义),再检查代码的映射关系(工具注册),然后检查消息格式(tool_call_id),最后检查执行逻辑(异常处理)。按照这个顺序排查,能够快速缩小问题范围,避免在错误的方向上浪费时间。
接下来,我们将用同一个测试问题"北京今天天气怎么样?",逐一复现和修复这四种故障类型。
12.1 故障类型一:参数提取错误 链接到标题
这是最常见的故障类型之一。表现为:LLM 决定调用工具,但返回的参数缺失、类型不匹配或格式错误,导致工具执行失败。很多初学者会认为这是 LLM 的问题,但实际上,90% 的参数提取错误都是因为工具定义中的参数描述不够清晰。
12.1.1 问题复现:参数描述不清导致提取失败 链接到标题
让我们先定义一个参数描述非常模糊的工具,观察 LLM 的行为:
import os
import json
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
MODEL = "deepseek-chat"
# ❌ 错误示例:参数描述过于简略
bad_weather_tool = {
"type": "function",
"function": {
"name": "get_weather",
"description": "获取天气", # ← 描述过于简略
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市" # ← 参数描述不清晰
}
},
"required": ["city"]
}
}
}
# 测试:LLM 能否正确提取参数?
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=[bad_weather_tool],
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
print(f"🔧 LLM 决定调用工具:{tool_call.function.name}")
print(f"📦 提取的参数:{tool_call.function.arguments}")
# 解析参数
args = json.loads(tool_call.function.arguments)
print(f"✅ 参数解析成功:{args}")
else:
print("💬 LLM 直接回答,未调用工具")
运行这段代码后,你可能会发现 LLM 大概率能正确提取参数 {"city": "北京"}。但这并不意味着参数描述没有问题——当问题变得更复杂时,模糊的描述就会导致提取错误。让我们用一个更容易暴露问题的测试:
# 更复杂的测试问题
complex_question = "我下周要去北京出差,帮我查一下那边的天气"
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": complex_question}],
tools=[bad_weather_tool],
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
print(f"📦 提取的参数:{args}")
# 可能出现的问题:LLM 提取了 {"city": "北京出差"} 或 {"city": "那边"}
else:
print("💬 LLM 未调用工具")
在这个更复杂的问题中,由于参数描述不清晰,LLM 可能会提取错误的城市名称(如"北京出差”、“那边”),或者干脆不调用工具。
12.1.2 问题分析:为什么参数描述如此重要 链接到标题
LLM 在提取参数时,完全依赖 parameters 中的 description 字段来理解"应该提取什么信息"。如果描述只写"城市",LLM 不知道:
应该提取完整的城市名称还是简称?
应该提取"北京"还是"北京市"?
遇到"那边"、“这里"等代词时应该如何处理?
参数描述的核心原则是:给 LLM 提供足够的上下文和示例,让它能够从自然语言中精确提取出结构化参数。
让我们深入理解这个原理:LLM 在提取参数时,需要将自然语言映射到结构化字段。如果描述只写"城市”,LLM 需要自行推断:1)应该提取完整名称还是简称?2)遇到代词如何处理?3)格式要求是什么?描述越详细,LLM 的推断空间越小,提取准确率越高。
12.1.3 修复方案:优化参数描述 链接到标题
让我们用清晰的参数描述重新定义工具:
# ✅ 修复版本:清晰的参数描述
good_weather_tool = {
"type": "function",
"function": {
"name": "get_weather",
"description": (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时,调用此工具。"
"目前支持的城市:北京、上海、广州、深圳、杭州。"
),
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": (
"要查询天气的城市名称,必须是完整的中文城市名(不含'市'字)。"
"例如:北京、上海、广州。"
"如果用户使用代词(如'那边'、'这里'),需要根据上下文推断具体城市名。"
)
}
},
"required": ["city"]
}
}
}
# 用相同的复杂问题测试修复后的工具
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": "我下周要去北京出差,帮我查一下那边的天气"}],
tools=[good_weather_tool],
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
print(f"✅ 修复后提取的参数:{args}")
# 预期输出:{"city": "北京"}
12.1.4 效果验证与对比 链接到标题
让我们用对比表格量化两个版本的差异:
参数描述质量对比:错误版本 vs 修复版本
| 维度 | 错误版本 | 修复版本 |
|---|---|---|
| 参数描述长度 | “城市”(2字) | “要查询天气的城市名称,必须是完整的中文城市名…"(50+字) |
| 是否提供示例 | ❌ 否 | ✅ 是(“例如:北京、上海、广州”) |
| 是否说明格式要求 | ❌ 否 | ✅ 是(“不含’市’字”) |
| 是否处理代词 | ❌ 否 | ✅ 是(“如果用户使用代词…需要根据上下文推断”) |
| 参数提取准确率 | 较低(易出错) | 显著提升(准确可靠) |
通过这个对比可以看出,参数描述的投入产出比极高——多写 50 个字,就能显著提升参数提取的准确性和可靠性。
12.1.5 补充方案:添加参数校验 链接到标题
除了优化参数描述,我们还可以在工具函数内部添加参数校验,作为第二道防线:
def get_weather_safe(city: str = None) -> str:
"""带参数校验的天气查询工具"""
# 参数校验
if not city or not isinstance(city, str):
return json.dumps({
"error": "参数错误:city 必须是非空字符串",
"received": city,
"hint": "请提供有效的城市名称,例如:北京、上海、广州"
}, ensure_ascii=False)
# 支持的城市列表
supported_cities = ["北京", "上海", "广州", "深圳", "杭州"]
if city not in supported_cities:
return json.dumps({
"error": f"暂不支持查询 {city} 的天气",
"supported_cities": supported_cities
}, ensure_ascii=False)
# 模拟天气数据
weather_db = {
"北京": {"temperature": 33, "condition": "晴", "humidity": 45},
"上海": {"temperature": 28, "condition": "多云", "humidity": 72},
"广州": {"temperature": 35, "condition": "雷阵雨", "humidity": 85},
"深圳": {"temperature": 34, "condition": "晴转多云", "humidity": 78},
"杭州": {"temperature": 30, "condition": "阴", "humidity": 68},
}
data = weather_db[city]
return json.dumps({
"city": city,
"temperature": data["temperature"],
"condition": data["condition"],
"humidity": data["humidity"],
"unit": "摄氏度"
}, ensure_ascii=False)
# 测试参数校验
print("测试1:正常参数")
print(get_weather_safe("北京"))
print("\n测试2:空参数")
print(get_weather_safe(None))
print("\n测试3:不支持的城市")
print(get_weather_safe("纽约"))
🔥 踩坑预警:参数校验返回的错误信息会被传回 LLM,LLM 会基于错误信息生成友好的回答。因此,错误信息应该是结构化的 JSON 格式,而不是直接抛出异常。
12.2 故障类型二:工具注册错误 链接到标题
这是一个看似低级但极其高频的错误。表现为:LLM 决定调用某个工具,但代码执行时报 KeyError,提示找不到对应的函数。根因往往是工具定义中的 name 与注册表中的函数名不一致——通常是拼写错误或大小写不匹配。
12.2.1 问题复现:名称拼写错误导致工具找不到 链接到标题
让我们故意制造一个名称不匹配的错误:
# 定义工具(正确的名称)
tools = [
{
"type": "function",
"function": {
"name": "get_weather", # ← 正确的名称
"description": (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时,调用此工具。"
),
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "要查询天气的城市名称,例如:北京、上海、广州"
}
},
"required": ["city"]
}
}
}
]
# ❌ 错误示例:注册表中的名称拼写错误
def get_weather(city: str) -> str:
"""天气查询工具"""
weather_db = {
"北京": {"temperature": 33, "condition": "晴", "humidity": 45},
"上海": {"temperature": 28, "condition": "多云", "humidity": 72},
}
data = weather_db.get(city, {"temperature": 25, "condition": "未知", "humidity": 50})
return json.dumps({"city": city, **data}, ensure_ascii=False)
# 注册表中的名称拼写错误(少了一个 't')
BUGGY_TOOL_REGISTRY = {
"get_waether": get_weather, # ← 拼写错误!应该是 get_weather
}
# 测试调用
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=tools,
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"🔧 LLM 决定调用工具:{func_name}")
print(f"📦 参数:{func_args}")
# 尝试执行工具(会报错)
try:
func = BUGGY_TOOL_REGISTRY[func_name] # ← 这里会抛出 KeyError
result = func(**func_args)
print(f"✅ 执行成功:{result}")
except KeyError as e:
print(f"❌ 执行失败:KeyError: {e}")
print(f"💡 原因:注册表中没有名为 '{func_name}' 的工具")
print(f"💡 注册表中的工具:{list(BUGGY_TOOL_REGISTRY.keys())}")
这个错误非常隐蔽——工具定义和注册表都在代码中,但因为拼写错误,两者无法匹配。在真实项目中,如果工具数量很多,这种错误很难通过肉眼发现。
12.2.2 问题分析:为什么会出现名称不匹配 链接到标题
名称不匹配的根本原因是硬编码字符串。工具定义中写了一次 "get_weather",注册表中又写了一次 "get_waether",两处的字符串没有任何关联,编译器无法检查拼写错误。
核心原则:任何需要在多处使用的标识符,都应该用常量定义,而不是硬编码字符串。
12.2.3 修复方案一:使用常量定义工具名 链接到标题
# ✅ 修复方案一:使用常量定义工具名
TOOL_NAME_WEATHER = "get_weather"
# 工具定义中使用常量
tools_fixed = [
{
"type": "function",
"function": {
"name": TOOL_NAME_WEATHER, # ← 使用常量
"description": (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时,调用此工具。"
),
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "要查询天气的城市名称,例如:北京、上海、广州"
}
},
"required": ["city"]
}
}
}
]
# 注册表中使用常量
TOOL_REGISTRY_FIXED = {
TOOL_NAME_WEATHER: get_weather, # ← 使用常量
}
# 测试修复后的版本
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=tools_fixed,
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"🔧 LLM 决定调用工具:{func_name}")
print(f"📦 参数:{func_args}")
# 执行工具
func = TOOL_REGISTRY_FIXED[func_name]
result = func(**func_args)
print(f"✅ 执行成功:{result}")
12.2.4 修复方案二:自动生成注册表 链接到标题
更进一步,我们可以让注册表自动从工具定义中生成,彻底消除不一致的可能:
# ✅ 修复方案二:自动从工具定义生成注册表
def build_tool_registry(tools: list, func_map: dict) -> dict:
"""
根据工具定义自动构建注册表,确保名称一致
参数:
tools: 工具定义列表(JSON Schema)
func_map: 函数名到函数对象的映射
返回:
工具注册表(工具名 -> 函数对象)
"""
registry = {}
for tool in tools:
name = tool["function"]["name"]
if name in func_map:
registry[name] = func_map[name]
else:
raise ValueError(f"工具 '{name}' 没有对应的函数实现,请检查 func_map")
return registry
# 函数映射(函数名 -> 函数对象)
FUNC_MAP = {
"get_weather": get_weather,
}
# 自动生成注册表
TOOL_REGISTRY_AUTO = build_tool_registry(tools_fixed, FUNC_MAP)
print(f"✅ 自动生成的注册表:{list(TOOL_REGISTRY_AUTO.keys())}")
12.2.5 效果验证与对比 链接到标题
工具注册方式对比:错误版本 vs 修复版本
| 维度 | 错误版本(硬编码) | 修复版本一(常量) | 修复版本二(自动生成) |
|---|---|---|---|
| 工具定义 | "name": "get_weather" | "name": TOOL_NAME_WEATHER | "name": TOOL_NAME_WEATHER |
| 注册表 | {"get_waether": ...} | {TOOL_NAME_WEATHER: ...} | 自动从工具定义生成 |
| 拼写错误风险 | ❌ 高(两处独立字符串) | ✅ 低(单一常量定义) | ✅ 无(自动生成) |
| 工具数量增加时 | ❌ 每个工具都可能出错 | ⚠️ 需要手动维护常量 | ✅ 自动保证一致性 |
| 推荐场景 | 不推荐 | 工具数量 < 5 | 工具数量 ≥ 5 |
💡 实践建议:如果你的项目只有 2-3 个工具,使用常量定义即可;如果工具数量超过 5 个,强烈建议使用自动生成注册表的方式,避免维护成本随工具数量线性增长。
12.3 故障类型三:消息拼接错误 链接到标题
这是最隐蔽、最难排查的错误类型。表现为:工具执行成功了,但 LLM 的最终回答与工具结果完全不相关,或者说"我无法获取该信息”。很多初学者会怀疑是 LLM 的问题,但实际上,这通常是因为 tool_call_id 不匹配,导致 LLM 无法将工具结果与调用请求关联起来。
12.3.1 问题复现:使用错误的 tool_call_id 链接到标题
让我们故意使用一个错误的 tool_call_id,观察 LLM 的行为:
# 注意:本节代码依赖 之前定义的 tools_fixed 和 TOOL_REGISTRY_FIXED
# 如果你是单独运行本节代码,请先运行上面的代码
# 步骤一:LLM 返回工具调用
messages = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools_fixed,
tool_choice="auto"
)
assistant_message = response.choices[0].message
tool_call = assistant_message.tool_calls[0]
print(f"🔧 LLM 决定调用工具:{tool_call.function.name}")
print(f"🆔 LLM 返回的 tool_call_id:{tool_call.id}")
# 步骤二:执行工具
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
result = TOOL_REGISTRY_FIXED[func_name](**func_args)
print(f"📋 工具执行结果:{result}")
# 步骤三:❌ 错误的消息拼接(使用自定义 ID)
messages.append(assistant_message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": "my_custom_id_12345", # ← 错误:不是 LLM 返回的 ID
"content": result
})
print(f"\n❌ 错误版本:使用自定义 ID 'my_custom_id_12345'")
# 步骤四:再次调用 LLM
final_response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools_fixed
)
print(f"🤖 LLM 回答:")
print(final_response.choices[0].message.content)
直接抛出 400 网络错误(报错退出代码):像代码中 client.chat.completions.create(…) 这一行发起的第二次请求,甚至都没有真正送到大模型(服务器推理引擎)的大脑里去,就直接被 API 服务器拒绝了。这就是 tool_call_id 不匹配导致的问题。
12.3.2 问题分析:为什么 tool_call_id 必须精确匹配 链接到标题
在 Function Calling 的消息流中,LLM 需要将工具的执行结果与之前的调用请求关联起来。这个关联是通过 tool_call_id 实现的:
LLM 在返回工具调用时,会为每个调用生成一个唯一的
id(例如call_abc123xyz)代码执行工具后,必须在
tool消息中使用相同的tool_call_idLLM 收到
tool消息后,会根据tool_call_id找到对应的调用请求,将结果与请求关联如果
tool_call_id不匹配,LLM 会认为"这个工具结果不是我要的",从而忽略它
核心原则:tool_call_id 必须与 LLM 返回的 tool_call.id 完全一致,不能使用自定义 ID,也不能省略。
12.3.3 修复方案:严格使用 LLM 返回的 ID 链接到标题
# ✅ 修复版本:使用正确的 tool_call_id
messages_fixed = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
# 步骤一:LLM 返回工具调用
response = client.chat.completions.create(
model=MODEL,
messages=messages_fixed,
tools=tools_fixed,
tool_choice="auto"
)
assistant_message = response.choices[0].message
tool_call = assistant_message.tool_calls[0]
print(f"🔧 LLM 决定调用工具:{tool_call.function.name}")
print(f"🆔 LLM 返回的 tool_call_id:{tool_call.id}")
# 步骤二:执行工具
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
result = TOOL_REGISTRY_FIXED[func_name](**func_args)
print(f"📋 工具执行结果:{result}")
# 步骤三:✅ 正确的消息拼接(使用 LLM 返回的 ID)
messages_fixed.append(assistant_message.model_dump())
messages_fixed.append({
"role": "tool",
"tool_call_id": tool_call.id, # ← 正确:使用 LLM 返回的 ID
"content": result
})
print(f"\n✅ 修复版本:使用 LLM 返回的 ID '{tool_call.id}'")
# 步骤四:再次调用 LLM
final_response = client.chat.completions.create(
model=MODEL,
messages=messages_fixed,
tools=tools_fixed
)
print(f"🤖 LLM 回答:")
print(final_response.choices[0].message.content)
12.3.4 效果验证与对比 链接到标题
消息拼接方式对比:错误版本 vs 修复版本
| 维度 | 错误版本 | 修复版本 |
|---|---|---|
| tool_call_id | "my_custom_id_12345" | tool_call.id(LLM 返回的原始 ID) |
| LLM 是否看到工具结果 | ❌ 否(ID 不匹配,无法关联) | ✅ 是(ID 匹配,成功关联) |
| LLM 回答质量 | ❌ “无法获取信息”(忽略了工具结果) | ✅ 准确回答(基于工具结果推理) |
| 用户体验 | ❌ 差(明明工具成功了,却说失败) | ✅ 好(流畅的对话体验) |
12.3.5 补充说明:消息顺序错误 链接到标题
除了 tool_call_id 不匹配,另一个常见错误是消息顺序错误。必须先追加 assistant 的工具调用消息,再追加 tool 的结果消息。如果顺序颠倒,API 会直接报错:
# ❌ 错误示例:消息顺序错误
messages_wrong_order = [
{"role": "user", "content": "北京今天天气怎么样?"}
]
# 错误:先追加 tool 消息
messages_wrong_order.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
# 错误:后追加 assistant 消息
messages_wrong_order.append(assistant_message.model_dump())
# 尝试调用 LLM(会报错)
try:
response = client.chat.completions.create(
model=MODEL,
messages=messages_wrong_order,
tools=tools_fixed
)
except Exception as e:
print(f"❌ API 报错:{e}")
# 预期错误信息:"tool message must follow assistant message with tool_calls"
# ----------------------------------------------------
# ✅ 正确示例:先存 assistant 消息,再存 tool 执行结果
# ----------------------------------------------------
messages_correct = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
try:
# 第一次调用 LLM
response = client.chat.completions.create(
model=MODEL,
messages=messages_correct,
tools=tools_fixed,
tool_choice="auto"
)
# 拿到模型返回的原始消息对象
assistant_message = response.choices[0].message
tool_call = assistant_message.tool_calls[0]
print(f"🔧 LLM 决定调用工具:{tool_call.function.name}")
print(f"🆔 拿到 LLM 分配的订单号 ID:{tool_call.id}")
# ===== 执行本地真实工具 =====
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
result = TOOL_REGISTRY_FIXED[func_name](**func_args)
print(f"📋 工具执行结果:{result}")
# ===== 拼装历史记录送还给 LLM =====
# 步骤一:✅ 必须【先】把模型刚才那条带 tool_calls 的消息存入上下文
# (如果不存,模型会忘记自己曾经下过单)
messages_correct.append(assistant_message)
# 步骤二:✅ 然后紧接着存入你的本地执行结果
# 并且使用严格匹配的订单号 tool_call.id
messages_correct.append({
"role": "tool",
"tool_call_id": tool_call.id, # ← 取自上面提取的 ID
"name": func_name, # (可选但推荐)带上当前执行的函数名
"content": str(result) # 必须转化为字符串
})
print(f"\n✅ 成功拼接上下文,准备发起第二次回答...")
# 第二次调用 LLM
final_response = client.chat.completions.create(
model=MODEL,
messages=messages_correct,
tools=tools_fixed
)
print(f"\n🤖 LLM 最终回答:")
print(final_response.choices[0].message.content)
except Exception as e:
print(f"❌ 发生了意料之外的错误:{e}")
🔥 踩坑预警:在并行调用多个工具时,所有工具的结果必须在同一轮回传。不能先回传一个工具的结果、调用 LLM、再回传另一个工具的结果。正确的做法是:遍历所有
tool_calls,执行所有工具,将所有结果追加到消息历史后,再调用 LLM。
12.4 故障类型四:执行层错误 链接到标题
前面三种故障都发生在"LLM 决策"和"消息传递"环节,而执行层错误发生在"工具真正执行"的环节。表现为:工具执行超时、外部 API 返回异常、返回空值等,导致整个流程中断或 LLM 收到错误的结果。执行层错误的危害最大——如果不做异常处理,一个工具的失败会导致整个 Agent 崩溃。
12.4.1 问题复现:异常未捕获导致流程中断 链接到标题
让我们定义一个会抛出异常的工具,模拟真实场景中的 API 调用失败:
# 注意:本节代码依赖 6.2 节定义的 tools_fixed
# 如果你是单独运行本节代码,请先运行 6.2 节的代码
# ❌ 错误示例:定义一个会抛异常的工具
def buggy_get_weather(city: str) -> str:
"""模拟外部 API 调用失败"""
# 模拟网络超时或 API 错误
raise Exception("API connection timeout: Unable to reach weather service")
BUGGY_TOOL_REGISTRY = {
"get_weather": buggy_get_weather,
}
# 测试调用(会崩溃)
messages_buggy = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
response = client.chat.completions.create(
model=MODEL,
messages=messages_buggy,
tools=tools_fixed,
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"🔧 LLM 决定调用工具:{func_name}")
print(f"📦 参数:{func_args}")
# 尝试执行工具(会抛异常)
try:
result = BUGGY_TOOL_REGISTRY[func_name](**func_args)
print(f"✅ 执行成功:{result}")
except Exception as e:
print(f"\n❌ 流程中断:{e}")
print(f"💡 问题:异常未被捕获,整个对话流程中断,用户看不到任何回答")
这是最糟糕的用户体验——用户提出问题后,系统直接崩溃,没有任何友好的错误提示。
12.4.2 问题分析:为什么需要统一异常处理 链接到标题
在真实项目中,工具通常会调用外部 API(天气服务、数据库、搜索引擎等),这些调用都可能失败:
网络超时
API 返回 500 错误
返回空值或格式错误的数据
权限不足或配额用尽
如果不做异常处理,任何一个工具的失败都会导致整个 Agent 崩溃。核心原则:工具执行失败不应中断主流程,而应该将错误信息转换为结构化的 JSON,传回 LLM,让 LLM 生成友好的降级回答。
12.4.3 修复方案:实现统一的异常处理包装器 链接到标题
# ✅ 修复方案:统一的异常处理包装器
def safe_execute_tool(func, func_name: str, args: dict) -> str:
"""
安全执行工具,统一处理异常
参数:
func: 要执行的工具函数
func_name: 工具名称(用于错误信息)
args: 工具参数
返回:
工具执行结果(JSON 字符串)
如果执行失败,返回包含错误信息的 JSON
"""
try:
result = func(**args)
# 检查结果是否为空
if not result or result == "null":
return json.dumps({
"warning": f"工具 {func_name} 返回了空结果",
"args": args,
"hint": "可能是参数不正确或服务暂时不可用"
}, ensure_ascii=False)
return result
except Exception as e:
# 将异常转换为 JSON 格式的错误信息
return json.dumps({
"error": f"执行 {func_name} 时发生错误",
"message": str(e),
"type": type(e).__name__,
"args": args,
"hint": "请稍后再试,或联系技术支持"
}, ensure_ascii=False)
# 测试修复后的版本
messages_fixed = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
response = client.chat.completions.create(
model=MODEL,
messages=messages_fixed,
tools=tools_fixed,
tool_choice="auto"
)
assistant_message = response.choices[0].message
if assistant_message.tool_calls:
tool_call = assistant_message.tool_calls[0]
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"🔧 LLM 决定调用工具:{func_name}")
print(f"📦 参数:{func_args}")
# 使用安全包装器执行工具
result = safe_execute_tool(
BUGGY_TOOL_REGISTRY[func_name],
func_name,
func_args
)
print(f"⚠️ 工具执行失败,但已捕获异常")
print(f"📋 返回给 LLM 的错误信息:{result}")
# 将结果回传给 LLM
messages_fixed.append(assistant_message.model_dump())
messages_fixed.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
# 再次调用 LLM
final_response = client.chat.completions.create(
model=MODEL,
messages=messages_fixed,
tools=tools_fixed
)
print(f"\n🤖 LLM 回答:")
print(final_response.choices[0].message.content)
虽然工具执行失败了,但流程没有中断,LLM 基于错误信息生成了友好的降级回答。这就是优雅降级的核心思想。
12.4.4 效果验证与对比 链接到标题
异常处理方式对比:错误版本 vs 修复版本
| 维度 | 错误版本(未捕获异常) | 修复版本(统一异常处理) |
|---|---|---|
| 异常处理 | ❌ 未捕获,直接抛出 | ✅ 捕获并转换为 JSON |
| 流程是否中断 | ❌ 是(整个 Agent 崩溃) | ✅ 否(继续执行) |
| 用户看到的内容 | ❌ 错误堆栈或无响应 | ✅ 友好的降级回答 |
| 错误信息传递 | ❌ 未传递给 LLM | ✅ 结构化传递给 LLM |
| 用户体验 | ❌ 极差(系统崩溃) | ✅ 良好(优雅降级) |
12.4.5 补充说明:超时控制和空值检查 链接到标题
除了异常捕获,执行层还需要考虑超时控制和空值检查:
import time
from functools import wraps
# 超时控制装饰器(简化版)
def with_timeout(timeout_sec: float):
"""装饰器:为函数添加超时控制"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
try:
result = func(*args, **kwargs)
elapsed = time.time() - start
if elapsed > timeout_sec:
return json.dumps({
"error": f"工具执行超时(>{timeout_sec}s)",
"elapsed": elapsed,
"hint": "请稍后再试或联系技术支持"
}, ensure_ascii=False)
return result
except Exception as e:
return json.dumps({
"error": f"工具执行异常:{str(e)}",
"type": type(e).__name__
}, ensure_ascii=False)
return wrapper
return decorator
# 使用超时控制
@with_timeout(timeout_sec=5.0)
def get_weather_with_timeout(city: str) -> str:
"""带超时控制的天气查询工具"""
# 注意:这里使用 6.2 节定义的 get_weather 函数
# 如果单独运行,需要先定义 get_weather 函数
# 模拟耗时操作
time.sleep(2.0)
# 简化版:直接返回模拟数据
weather_db = {
"北京": {"temperature": 33, "condition": "晴", "humidity": 45},
}
data = weather_db.get(city, {"temperature": 25, "condition": "未知", "humidity": 50})
return json.dumps({"city": city, **data}, ensure_ascii=False)
print("测试超时控制:")
result = get_weather_with_timeout("北京")
print(result)
💡 实践建议:在生产环境中,建议使用
concurrent.futures.TimeoutError或signal.alarm()实现真正的超时控制。上面的简化版只是演示思路,实际项目中需要更健壮的实现。
12.5 故障速查表 链接到标题
在实际项目中,当 Function Calling 出现问题时,你可以使用这个速查表快速定位故障类型和解决方案:

Function Calling 四大常见陷阱速查表
| 故障类型 | 症状 | 根因 | 快速排查方法 | 解决方案 |
|---|---|---|---|---|
| 参数提取错误 | LLM 返回的参数缺失、类型错误或格式不对 | 参数描述不清晰,LLM 无法准确提取 | 检查 parameters.properties 中的 description 是否包含示例和格式要求 | 使用黄金模板重写参数描述,添加示例和格式说明 |
| 工具注册错误 | 执行时报 KeyError,提示找不到工具 | 工具定义中的 name 与注册表的 key 不一致(拼写错误) | 打印 list(TOOL_REGISTRY.keys()) 对比工具定义中的 name | 使用常量定义工具名,或自动从工具定义生成注册表 |
| 消息拼接错误 | 工具执行成功,但 LLM 回答与结果不相关或说"无法获取" | tool_call_id 不匹配,LLM 无法关联结果与调用 | 打印 tool_call.id 和 tool 消息中的 tool_call_id,检查是否一致 | 严格使用 tool_call.id,不使用自定义 ID |
| 执行层错误 | 工具执行超时、抛异常、返回空值,导致流程中断 | 未捕获异常,外部 API 调用失败 | 在工具执行处添加 try-except,观察是否有异常抛出 | 实现 safe_execute_tool 包装器,统一处理异常和空值 |
使用这个速查表的建议流程:
先看症状:根据你观察到的现象(参数错误、KeyError、回答不相关、流程中断),定位到对应的故障类型
再查根因:理解为什么会出现这个问题
快速排查:按照"快速排查方法"列的指引,用最少的代码验证你的猜测
应用方案:参考"解决方案"列,选择合适的修复方式
💡 实践建议:建议将这个速查表打印出来或保存为书签。在实际项目中遇到 Function Calling 问题时,先查表定位故障类型,再针对性地排查和修复,能节省大量调试时间。
本章总结
链接到标题
本章我们用"问题复现 → 问题分析 → 修复方案 → 效果验证"的四步法,逐一拆解了 Function Calling 的四种高频故障。让我们回顾核心要点:
核心收获:
- 参数提取错误:90% 的参数问题都是因为参数描述不清晰。解决方案是用黄金模板重写描述,包含功能说明、示例、格式要求。
- 工具注册错误:名称拼写错误是最常见的低级错误。解决方案是使用常量定义工具名,或自动从工具定义生成注册表。
- 消息拼接错误:
tool_call_id不匹配是最隐蔽的错误。解决方案是严格使用tool_call.id,不使用自定义 ID,并确保消息顺序正确(先 assistant 后 tool)。 - 执行层错误:异常未捕获会导致整个 Agent 崩溃。解决方案是实现
safe_execute_tool包装器,将异常转换为结构化的 JSON 错误信息,让 LLM 生成友好的降级回答。 - 统一排障顺序:按照"工具定义层 → 工具注册层 → 消息拼接层 → 执行层"的顺序排查,能快速缩小问题范围。
掌握了这些排障技巧后,你在实际项目中遇到 Function Calling 问题时,就不会再感到困惑和无助。你知道该先查哪里、后查哪里,知道每种错误的典型症状和修复方案。
在下一章中,我们将进入 Function Calling 的高级主题——并行调用和多函数调用。我们会深入理解并行调用的工作原理,并用实际数据对比串行 vs 并行的性能差异。这是真实项目中提升 Agent 性能的关键手段。
第13章:并行调用和多函数调用
链接到标题
本章是真实项目中的高频场景,也是性能提升的关键手段。我们会深入理解并行调用的机制,并用实际数据对比串行 vs 并行的性能差异。
13.1 并行调用的工作原理 链接到标题
当用户的请求需要多个相互独立的工具时,LLM 会在一次响应中返回多个 tool_call 对象。我们的代码遍历这个列表,依次执行每个工具,然后将所有结果一起回传给 LLM。
关键点在于:多个工具的执行结果必须全部回传后,LLM 才会生成最终回答——这意味着如果我们串行执行工具,总耗时是所有工具耗时之和;如果并行执行,总耗时接近最慢那个工具的耗时。
13.2 串行 vs 并行性能对比实验 链接到标题
有了模拟延迟的工具之后,我们分别实现串行执行和并行执行两种方式,并对比耗时:
import json
import time
import math
import concurrent.futures
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv(override=True)
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com" # DeepSeek API 端点
)
# ==========================================
# 1. 定义本地真实函数 & 注册表
# ==========================================
def get_weather(location):
print(f"☁️ [执行工具] 开始查询 {location} 的天气...")
time.sleep(2.0) # 模拟 2 秒的网络延迟
print(f"☁️ [执行工具] 查询完成: {location}")
return json.dumps({"location": location, "weather": "晴转多云", "temp": "25℃"})
def calculate_sqrt(number):
print(f"🧮 [执行工具] 开始计算 {number} 的平方根...")
time.sleep(2.0) # 模拟 2 秒的计算延迟
result = math.sqrt(float(number))
print(f"🧮 [执行工具] 计算完成: {number}")
return json.dumps({"number": number, "sqrt": result})
# 函数注册表
TOOL_REGISTRY = {
"get_weather": get_weather,
"calculate_sqrt": calculate_sqrt
}
# ==========================================
# 2. 面向大模型的工具描述 (JSON Schema)
# ==========================================
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询指定城市的天气状况",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "要查询的城市名称,例如北京"
}
},
"required": ["location"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate_sqrt",
"description": "计算一个数字的平方根",
"parameters": {
"type": "object",
"properties": {
"number": {
"type": "number",
"description": "需要计算平方根的数字"
}
},
"required": ["number"]
}
}
}
]
# ==========================================
# 3. 串行 vs 并行 的底层调度实现
# ==========================================
def execute_tools_serial(tool_calls):
"""串行执行:一个接一个排队执行"""
results = []
start_time = time.time()
for tc in tool_calls:
func_name = tc.function.name
func_args = json.loads(tc.function.arguments)
if func_name in TOOL_REGISTRY:
res = TOOL_REGISTRY[func_name](**func_args)
results.append({"id": tc.id, "result": res})
end_time = time.time()
print(f"⏳ 串行执行总耗时: {end_time - start_time:.2f} 秒")
return results
def execute_tools_parallel(tool_calls):
"""并行执行:开多线程同时干活"""
results = []
start_time = time.time()
# 定义单个线程要干的活
def _run_single_tool(tc):
func_name = tc.function.name
func_args = json.loads(tc.function.arguments)
if func_name in TOOL_REGISTRY:
res = TOOL_REGISTRY[func_name](**func_args)
return {"id": tc.id, "result": res}
return None
# 使用 Python 原生的线程池实现并发调用
with concurrent.futures.ThreadPoolExecutor() as executor:
# executor.map 会自动开多线程执行,并且最后收集结果时仍保持原本的顺序
results = list(executor.map(_run_single_tool, tool_calls))
end_time = time.time()
print(f"🚀 并行执行总耗时: {end_time - start_time:.2f} 秒")
return results
# ==========================================
# 以下是你提供的调用测试代码
# ==========================================
MODEL = "deepseek-chat" # 替换成你实际可用的模型,比如 "deepseek-chat" 或 "gpt-4o"
print("🤖 发送并行请求给大模型...")
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "帮我查一下北京的天气,同时计算 sqrt(256)"}
],
tools=tools,
tool_choice="auto",
temperature=0.7,
max_tokens=512
)
assistant_msg = response.choices[0].message
if assistant_msg.tool_calls:
print(f"\n✅ LLM 决定同时调用 {len(assistant_msg.tool_calls)} 个工具:")
for tc in assistant_msg.tool_calls:
print(f" - {tc.function.name} 参数: {tc.function.arguments}")
print("\n--- 【对比测试开始】 ---")
print("\n[模式 A] 串行执行(慢):")
serial_results = execute_tools_serial(assistant_msg.tool_calls)
print("\n[模式 B] 并行执行(快):")
parallel_results = execute_tools_parallel(assistant_msg.tool_calls)
else:
print("LLM 直接回答,未调用工具")
运行后你会看到明显的性能差异:串行执行的总耗时是所有工具耗时之和,而并行执行的总耗时接近最慢那个工具的耗时。在真实项目中,如果一次请求需要调用 5 个各耗时 2 秒的 API,串行需要 10 秒,并行只需要 2 秒——性能差距随工具数量线性放大。
本节课程我们实现的 Function Calling 管线有一个关键限制:它是单轮的。LLM 调用一次工具、获取一次结果、生成一次回答,整个流程就结束了。但现实中的复杂任务往往需要多步推理——例如"先搜索 LangChain 的最新版本号,再搜索该版本的 changelog,最后总结主要变化"。这需要 LLM 在获取第一步结果后,基于结果决定下一步行动,形成一个推理-行动的循环。
这个循环有一个著名的名字——ReAct(Reasoning + Acting)。在下一节课程中,我们将手写一个 ReAct 循环,真正理解 Agent 如何实现多步推理和自我纠错。
import json
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv(override=True)
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com" # DeepSeek API 端点
)
# ==========================================
# 1. 准备你的工具(为了演示多次调用,准备两个工具)
# ==========================================
def search_web(query):
print(f"👉 [执行工具 1] 正在全网搜索:{query}...")
if "苹果" in query and "CEO" in query:
return '{"result": "苹果现任CEO是蒂姆·库克(Tim Cook),他的净资产约为 20 亿美元。"}'
elif "汇率" in query:
return '{"result": "今天1美元兑换约149日元。"}'
return '{"result": "没有找到相关信息。"}'
def multiply_numbers(a, b):
print(f"👉 [执行工具 2] 正在利用计算器计算:{a} * {b}...")
return json.dumps({"result": float(a) * float(b)})
available_functions = {
"search_web": search_web,
"multiply_numbers": multiply_numbers
}
tools_description = [
{
"type": "function",
"function": {
"name": "search_web",
"description": "搜索引擎。当需要查找人物信息、实时数据、汇率等知识时使用。",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string", "description": "搜索关键词"}},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "multiply_numbers",
"description": "计算器。当需要计算两个数字的乘积时使用。",
"parameters": {
"type": "object",
"properties": {
"a": {"type": "number", "description": "第一个数字"},
"b": {"type": "number", "description": "第二个数字"}
},
"required": ["a", "b"]
}
}
}
]
# ==========================================
# 2. 核心大循环引擎 (ReAct Runtime)
# ==========================================
def run_agent_loop(user_query, max_iterations=10):
messages = [
{"role": "system", "content": "你是一个能够自主拆解任务并使用工具的高级 AI 助手。"},
{"role": "user", "content": user_query}
]
print("====== 🎬 Agent 开始运行 ======")
# 开始无尽的循环,直到任务完成或者超出最大轮数
for iteration in range(1, max_iterations + 1):
print(f"\n🌀 第 {iteration} 轮思考开始...")
# 1. 把目前的全部对话历史扔给大模型
response = client.chat.completions.create(
model="deepseek-chat", # 在多次逻辑推理中表现更好
messages=messages,
tools=tools_description
)
assistant_message = response.choices[0].message
# ⚠️ 不要忘记:先把大模型的此刻状态存入剧本
messages.append(assistant_message)
# 2. 终止条件判定:如果大模型觉得没必要调工具了(直接给出了自然语言回答),退出循环
if not assistant_message.tool_calls:
print("\n✅ Agent 决定结束任务,认为已经拿到最终答案。")
return assistant_message.content
# 3. 工具执行处理阶段:大模型要求调用工具
for tool_call in assistant_message.tool_calls:
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
# --- 本地执行 ---
if func_name in available_functions:
result = available_functions[func_name](**func_args)
else:
result = f"Error: 找不到工具 {func_name}"
# --- 拼装结果,准备进入下一轮 (严格对应 tool_call_id) ---
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": func_name,
"content": str(result)
})
# 如果把 range(1, 10) 全跑完了还没退出,说明陷入了死循环
return "\n❌ 超过最大迭代次数,Agent 可能陷入死循环,被迫终止。"
# ==========================================
# 3. 开始测试刁钻问题
# ==========================================
if __name__ == "__main__":
hard_question = "苹果公司的CEO是谁?他的净资产是多少?请把他的净资产(按美元算)乘以今天的日元汇率,告诉我大概等于多少日元。"
print(f"👤 用户:{hard_question}\n")
final_answer = run_agent_loop(hard_question)
print("\n🎉 最终的大模型回复:")
print("-" * 50)
print(final_answer)
本章总结
链接到标题
让我们回顾本节课程的核心收获:
核心收获:
Function Calling 的本质:LLM 只生成"调用指令",代码负责真正执行——这是 Agent 从"纸上谈兵"走向"动手执行"的关键跃迁
工具定义三要素:
name(唯一标识)、description(决策依据)、parameters(参数 Schema)——description是最重要的字段完整的六步调用周期:用户输入 → LLM 决策 → 生成指令 → 执行工具 → 结果回传 → 综合回答
工具描述的黄金模板:功能说明 + 触发条件 + 输入格式 + 能力边界
四大常见陷阱:描述模糊、参数校验缺失、tool_call_id 不匹配、返回值过长
并行调用的性能优势:串行执行时间累加,并行执行时间取最大——工具越多优势越明显
综合实战:从认知到工程化落地
链接到标题
前面的章节里,我们已经系统建立了对 AI Agent 的认知框架:它不是“更聪明的聊天机器人”,而是一个能够感知环境、自主决策、调用工具、完成目标的智能系统。我们也围绕 TAO 循环、Function Calling、ReAct 等核心机制,逐步拆开了 Agent 的底层工作原理,理解了“为什么 Agent 能做事、它到底是怎么做事的”。
但如果这些知识只停留在单个 Notebook 示例或局部实验里,仍然很难迁移到真实项目。一个真正可用的 Agent 系统,不只是“会调用工具”这么简单,它还需要前后端协作、配置管理、工具注册、错误处理、流式输出、过程可视化和用户交互界面。也就是说,从“原理会了”到“项目能跑”,中间还隔着一层工程化实现。
因此,在课程最后,我们引入一个完整的工程案例 agent-travel-code。这一章不会再从零手写 Agent,而是聚焦三件事:第一,带你把项目在本地真正跑起来;第二,帮助你建立“前面学过的知识点 → 项目中对应实现”的完整映射;第三,通过一个可观察、可交互、可扩展的真实案例,让你看清楚 Agent 是如何从课堂概念变成产品系统的。
最后实战:Agent Travel 旅行规划智能体项目
链接到标题
7.1 项目引入:为什么课程最后要看一个完整工程项目 链接到标题
在前面的内容中,我们已经完成了 Agent 学习中最容易“卡住”的部分:认知层。你已经知道了 Agent 与传统 LLM 应用的本质区别,理解了它为什么需要工具、为什么能够进行多步推理,也知道了 Function Calling 的本质并不是“LLM 自己执行函数”,而是“LLM 生成调用指令,代码负责真实执行”。
但这些知识如果不落到真实项目里,很容易停留在“我看懂了”而不是“我会用了”的阶段。比如,单个代码示例可以让你理解一次工具调用的流程,却无法让你真正体会:当工具越来越多时,如何管理它们?当用户连续提问时,如何维护上下文?当工具执行失败时,如何优雅降级?当 Agent 已经完成了多轮推理时,如何把这些中间过程展示给用户?
这正是最后引入工程项目的原因。agent-travel-code 不是为了“再演示一个 Demo”,而是为了把本课前面讲过的 Agent 核心认知、TAO 循环、Function Calling、ReAct 推理、工具体系设计 等知识,全部收拢到一个可运行、可观察、可继续扩展的系统里。通过这个项目,你会第一次真正看到:Agent 不是若干零散技巧的堆叠,而是一个完整的应用架构。
7.2 项目概览与技术栈 链接到标题
本章的工程项目叫做 Agent Travel Demo。这是一个面向教学场景设计的旅行规划智能体系统,它并不追求“旅游业务最复杂”,而是刻意选择了一个足够具体、又足够典型的任务场景:旅行规划。这个场景天然具备 Agent 的几个关键特征:需要获取实时信息、需要组合多个工具、需要根据中间结果动态调整后续行动,因此非常适合用来展示 Agent 与普通 LLM 的能力差异。
在这个项目中,用户可以围绕旅行问题发起请求,例如查询天气、筛选景点、比较酒店、搜索交通方案、做预算计算等。系统支持两种模式:一种是 原生 LLM 模式,模型只基于当前输入生成回答;另一种是 Agent 模式,模型会根据任务需要自主决定是否调用天气、景点、酒店、交通、计算等工具,并根据工具返回结果继续推理,直到完成任务。
更重要的是,这个项目并不把 Agent 的执行过程藏在后端黑盒中,而是把它“摊开”给学员看。你不仅能看到最终回答,还能看到 Agent 的思考轨迹、工具调用行为、返回结果以及整个执行链路。这一点对于教学尤其重要,因为它让我们第一次不再只是“相信 Agent 在工作”,而是能够直接观察 Agent 是如何工作的。
从技术栈上看,项目采用前后端分离架构。前端使用 React + TypeScript + Vite,负责交互界面、过程可视化和配置页面;后端使用 FastAPI,负责模型调用、工具调度、ReAct 循环、配置管理与 API 服务;模型接入采用 OpenAI Compatible API;通信方式使用 SSE 来支持流式输出;工具层则结合了 高德 API、Tavily 和本地 mock 数据来构建完整的旅行规划能力。这种技术组合,恰好构成了一个真实 Agent 项目的最小工程骨架。
7.3 本地运行:三步把项目跑起来 链接到标题
这一章的第一个目标不是读代码,而是先把项目真正跑起来。只有当你在浏览器里看到一个可以交互的 Agent 系统,前面学过的所有抽象概念才会开始“落地”。项目目录位于 agent-travel-code/,采用标准的前后端分离结构,环境要求为 Python 3.10+ 和 Node.js 18+。
步骤一:进入项目目录
cd agent-travel-code
ls
如果目录中能看到 backend/、frontend/、scripts/ 和 README.md,说明项目结构完整。其中 backend/ 是后端服务,frontend/ 是前端界面,scripts/ 目录中提供了一键启动脚本。
步骤二:确认配置项
项目依赖模型和部分外部工具的 API Key。后端配置通常位于 backend/.env,前端配置通常位于 frontend/.env。在第一次运行项目之前,建议先了解几个关键配置项:
OPENAI_API_KEY=your_api_key_here
OPENAI_BASE_URL=https://api.openai.com/v1
MODEL_NAME=gpt-4o-mini
AMAP_API_KEY=your_amap_api_key_here
TAVILY_API_KEY=your_tavily_api_key_here
其中,OPENAI_API_KEY 和 OPENAI_BASE_URL 决定模型接入方式;AMAP_API_KEY 主要用于天气、景点、交通相关工具;TAVILY_API_KEY 用于补充联网搜索能力。如果暂时没有全部 Key,也可以先启动项目,只是部分工具能力可能无法完整工作。
如果你是第一次接触这些外部服务,建议在这里顺手补充两个工具平台的注册入口。AMAP_API_KEY 对应高德开放平台,官网地址为:https://lbs.amap.com/api。进入官网后注册/登录账号,创建应用,并在控制台申请 Web Service 或相关服务的 Key,随后将拿到的 Key 填入 backend/.env 中的 AMAP_API_KEY=。这一项是旅行 Agent 获取天气、景点和部分路径信息的基础。
TAVILY_API_KEY 对应 Tavily 搜索服务,官网地址为:https://app.tavily.com/home。注册并登录后,可以在控制台查看或创建自己的 API Key,再把它填入 backend/.env 中的 TAVILY_API_KEY=。这一项主要用于补充联网搜索能力,帮助 Agent 在交通查询或外部信息检索场景下获得更实时的结果。
从教学角度看,这一步也很重要:它能帮助你清楚地区分“模型能力”和“工具能力”的边界。模型本身负责理解任务和做决策,而像高德、Tavily 这样的外部服务,则为 Agent 提供实时世界信息。只有把这两类能力接起来,Agent 才能真正从“会说”走向“会做”。
步骤三:执行一键启动脚本
项目已经提供了与课程工程案例一致风格的一键启动脚本,会自动完成虚拟环境创建、依赖安装以及前后端服务启动。
macOS / Linux:
chmod +x scripts/start-macos-linux.sh
./scripts/start-macos-linux.sh
Windows:
scripts\start-windows.bat
启动成功后,你会看到以下地址:
前端界面:
http://127.0.0.1:5173后端 API:
http://127.0.0.1:8000API 文档:
http://127.0.0.1:8000/docs
如果浏览器中能打开前端页面,就说明项目已经成功运行。到这里,我们就从“课件里的概念”真正进入了“可交互的工程系统”。
7.4 课程知识如何映射到工程项目 链接到标题
这一节是本章最重要的部分。我们前面花了很多时间学习 Agent 的概念、流程和实现机制,现在要回答一个关键问题:这些知识在真实项目里分别落到了哪里?如果你不能建立这种映射关系,那么工程项目在你眼里就仍然只是“一堆代码”;只有把映射关系建立起来,你才会真正感受到自己学到的是一套可以迁移的能力。
课程知识点 → 工程项目实现映射
| 前面课程中的知识点 | 项目中的对应实现 | 工程化升级点 |
|---|---|---|
| Agent 的定义与能力边界 | LLM 模式 / Agent 模式 / Compare 模式 | 不再停留在概念对比,而是能直接体验两类系统的行为差异 |
| TAO 循环(Think → Act → Observe) | 后端 Agent 运行逻辑 | 从静态示意图升级为真实运行的多轮推理闭环 |
| Function Calling | 工具定义、注册表、调度执行链路 | 从单次工具调用示例升级为可维护的工具体系 |
| 工具描述与参数提取 | 天气、景点、酒店、交通、计算等工具 | 多工具并存,更能体现描述设计的重要性 |
| ReAct 推理 | Agent 执行过程中的思考、行动、观察 | 从论文术语升级为界面中的可视化过程 |
| 错误处理与降级 | 外部 API 失败后的结构化返回 | 从“能跑通”升级为“出错不崩” |
| Workflow vs Agent 选型 | 普通 LLM 对话与 Agent 多步规划对比 | 让学员直观看到什么任务需要 Agent |
| 配置管理 | Settings 页面与后端配置接口 | 从改代码升级为通过 UI 配置系统参数 |
从这张表里可以看出,项目前后端的每一块能力几乎都能在前面的课程中找到理论根源。比如,TAO 循环 在课上是一个抽象的运行模型,而在项目里它变成了真实的多轮决策流程;Function Calling 在课上是“LLM 生成调用指令、代码执行工具”,而在项目里则进一步扩展成了工具注册、参数解析、结果回传、异常处理和前端展示的完整链路。
这也是工程化学习中最重要的认知跃迁之一:项目并没有引入什么“完全陌生的新魔法”,它只是把你已经学过的知识,升级成了一个更完整、更稳定、更可用的系统。理解了这一点,你面对真实项目时就不会再有“课上学的是一套,项目里用的是另一套”的割裂感。
7.5 项目页面与使用流程讲解 链接到标题
项目跑起来之后,我们不建议一上来就钻进源码,而是先按照“先配置、再体验、再观察、再验证”的顺序使用一遍界面。这样你会更容易把用户体验层和系统实现层对应起来。
7.5.1 设置页(Settings) 链接到标题
这是项目的入口页面之一,也是整个系统的配置中心。你需要在这里填写模型相关参数,例如 API Key、Base URL、模型名称,以及外部工具依赖的相关密钥。这个页面的存在本身就体现了工程化系统与 Notebook 示例的差异:在前面的课程中,我们往往通过代码变量或 .env 文件来修改参数;而在项目中,这些配置被收敛成了统一的设置入口。
这一层设计非常重要,因为它意味着系统的“运行参数”不再写死在代码里,而是成为可维护、可修改、可观察的系统状态。
7.5.2 对话页(Chat) 链接到标题
这是项目的核心交互页面。用户可以在这里输入旅行规划相关问题,例如:“帮我规划一个北京两日游行程,预算 2000 元以内。”或者“明天去上海旅行,需要准备什么?”系统会根据当前所选模式,给出两种不同的响应方式。
如果使用 LLM 模式,模型主要依据已有上下文直接生成回答;如果使用 Agent 模式,系统会进入多轮推理状态,自主决定是否调用天气、景点、酒店、交通、计算等工具。也就是说,这个页面本质上是前面课程里“LLM vs Agent 范式差异”的现场实验台。
在这里,你会第一次真正感受到:普通 LLM 更像是“给建议”,而 Agent 更像是“先行动、再回答”。
7.5.3 对比模式(Compare) 链接到标题
这是项目最有教学价值的页面之一。它允许你针对同一个问题,同时查看 LLM 与 Agent 两种模式的输出结果。比如面对“帮我推荐周末去杭州旅行的方案,并估算预算”这样的请求,普通 LLM 可能给出一个看起来合理但并未基于真实数据验证的回答;而 Agent 则更可能通过多步工具调用来获取天气、景点、酒店和交通信息,再综合生成更具体的结果。
这个页面的价值不在于“证明 Agent 一定更强”,而在于帮助你建立正确的判断标准:不是所有任务都需要 Agent,但凡任务涉及多步信息获取、条件判断和动态规划时,Agent 的优势会迅速放大。
7.5.4 工具测试页(Tools Playground) 链接到标题
这是理解 Agent 执行能力的关键页面。很多初学者学到 Agent 时,容易把注意力全部放在“LLM 很聪明”这件事上,忽略了系统真正能“做事”的根基,其实是工具。这个页面允许你绕过大模型,直接测试每个工具的输入和输出,例如天气查询工具、景点搜索工具、酒店搜索工具、交通搜索工具和计算工具。
这一步非常重要,因为它会让你更清楚地意识到:Agent 并不是凭空拥有能力,而是建立在一个可用工具集合之上的。LLM 负责“判断什么时候该用哪个工具”,而工具本身负责“真正把事情做出来”。
7.6 Agent 过程可视化:让 TAO 循环“看得见” 链接到标题
这是这个项目最具教学价值的地方,也是它与前面 Notebook 实验最大的区别。在 Notebook 示例中,我们通常通过打印日志、查看 JSON、观察工具返回值来理解 Agent 的执行过程;这些方法虽然有效,但本质上仍然比较“工程师视角”。而在这个项目中,Agent 的运行过程被可视化地展示在界面里,你能够直接看到它是如何完成 Think → Act → Observe 循环的。
这意味着,TAO 循环 不再只是课件图里的三个框,而是一个真实发生的动态过程。你可以看到 Agent 在什么时候决定调用工具、调用了哪个工具、传了什么参数、拿到了什么返回结果、又是如何基于这些结果继续推理的。这种体验对于理解 Agent 特别关键,因为它第一次让“推理链路”从抽象概念变成了可观察对象。
同样,ReAct 也不再只是论文中的一个术语,而是在系统里以真实行为的形式出现:Reasoning 对应思考过程,Acting 对应工具调用,Observation 对应结果回收与下一轮判断。通过这类过程展示,学员能够清晰区分三件事:哪些内容属于 LLM 的推理,哪些内容属于工具的执行,哪些内容属于系统层的调度与状态维护。
这对后续真正做 Agent 开发非常重要。因为一旦系统出问题,你就需要知道问题出在“模型决策错了”“工具结果错了”还是“调度链路错了”。而可视化,正是帮助我们建立这种诊断能力的第一步。
7.7 本章总结:从 Agent 原理到 Agent 产品 链接到标题
到这里,这门课最后一块最重要的拼图就补齐了。前面的章节帮助我们建立了 Agent 的认知框架和底层机制:我们知道了 Agent 为什么会出现、它与普通 LLM 有什么本质区别、它如何通过 TAO 循环 运转、如何通过 Function Calling 使用工具、又如何通过 ReAct 完成多步推理。今天这一章,则把这些知识全部收拢进了一个可运行、可观察、可交互的工程项目中。
更重要的是,这个项目证明了一件事:你前面学到的并不是“只能在课堂上使用的概念”,而是一套能够直接迁移到真实应用中的设计语言。TAO 循环 可以落地为后端推理执行器,Function Calling 可以落地为工具调度系统,ReAct 可以落地为多轮推理引擎,工具描述与错误处理则共同构成了 Agent 系统可靠性的基础。
换句话说,前面的课程回答的是三个问题:Agent 是什么?为什么可行?它怎么工作?
而这一章回答的是最后一个问题:这些知识,如何变成一个真实项目。
从学习路径上看,你现在已经完成了一次非常关键的跃迁:从“理解 Agent”走到了“看见 Agent 作为系统如何工作”。这意味着你已经具备了继续向前走的基础。接下来,你完全可以在这个项目之上继续扩展:增加更多工具、引入记忆模块、增强任务分解能力、接入知识库检索,甚至进一步走向多 Agent 协作系统。
✅ 到本章为止,你已经完成了从 Agent 基础认知、到核心机制理解、再到工程化案例落地的完整闭环。