在上一节《图文混排 PDF 检索》中,我们系统性地解决了 PDF 内部的多模态问题——布局语义丢失、表格结构熵增、图文信息割裂。通过 MultiModalVectorStoreIndex、LlamaParse、MinerU 等技术,我们已经能够让 LLM “看懂"复杂文档内部的图表和表格。
但这只是多模态检索的”文档内检索“场景。今天,我们要进入一个更具挑战性的领域:跨模态检索——即用文字描述搜索图片(文搜图),或用一张图片搜索相似图片(图搜图)。这在企业场景中极为常见:电商的"以图搜货”、设计素材库的风格匹配、企业资料库的图表定位、安防监控的视频检索……这些需求的本质,是让 AI 能够跨越"文本"与"图像"两种模态的鸿沟,在统一的语义空间中进行比较。
结合目前的技术,本节课将重点探讨:CLIP、VLM Captioning、Qwen3-VL 三种主流技术路径的原理与边界,以及为什么 Qwen3-VL + Reranker 正在取代 ColPali 成为新的行业标准。根据 MMEB-v2 和 ViDoRe v3 基准测试数据,Qwen3-VL 体系在存储成本仅为 ColPali 的 1/30 的前提下,视觉文档检索精度达到了 86.3 分,实现了性能与成本的双重突破。
一、 从文档内检索到跨模态检索 链接到标题
在上一节课中,我们处理的场景是"给定一个 PDF,检索其中的图文信息"。这本质上是一个文档内问题——图片和文字在同一个文档中,它们的关联是"物理上的相邻"。但跨模态检索面临的挑战完全不同:图片和查询文本没有物理关联,我们需要让 AI 理解它们的语义相似性。
1.1 跨模态检索的核心挑战 链接到标题
与文档内检索相比,跨模态检索面临的本质性技术挑战:
文档内检索 vs 跨模态检索的本质差异
| 维度 | 文档内检索(上节课) | 跨模态检索(本节课) |
|---|---|---|
| 关联方式 | 物理相邻(同一页/同一段) | 语义相似(无物理关联) |
| 模态关系 | 图文同源,有上下文 | 图文异源,无上下文 |
| 核心难点 | 解析提取 | 向量空间对齐 |
| 典型场景 | “这张图表展示了什么?” | “找一张展示销售趋势的图” |
| 技术方案 | LlamaParse、MinerU | CLIP、Qwen3-VL |
从表格可以看出,跨模态检索的核心难点从"解析提取“转变为”向量空间对齐"——我们需要让文本和图像在同一个数学空间中具有可比性。这正是 CLIP、Qwen3-VL 等多模态嵌入模型要解决的问题。
1.2 传统解决方案的局限性 链接到标题
面对这一困境,企业通常会尝试以下三种传统方案。但遗憾的是,它们都存在致命缺陷:
传统图片检索方案的局限性对比
| 方案 | 工作原理 | 核心问题 |
|---|---|---|
| 文件名搜索 | 基于文件名关键词匹配 | 文件名通常无语义(如 IMG_20240315.jpg) |
| OCR 提取文字 | 识别图中文字建立索引 | 丢失视觉信息(趋势、布局、颜色) |
| 人工打标签 | 人工为每张图片添加描述 | 成本高、不可持续、覆盖率低 |
以 OCR 方案为例,假设我们有一张展示"2024 年 Q3 销售额从 800 万下降到 650 万"的柱状图。OCR 可能只能提取出"Q3"、“800”、“650"这些离散数字,却无法理解"下降趋势"这一核心语义。更糟糕的是,如果图表使用的是可视化趋势线而非数字标注,OCR 将完全失效。
这种"只见树木,不见森林"的处理方式,正是传统方案的根本局限:它们试图将视觉信息"翻译"为文本,但翻译过程中必然丢失信息。
1.3 多模态 RAG 的核心思想:统一向量空间 链接到标题
既然"翻译"会丢失信息,那能否让 AI 直接"看懂"图片?这正是多模态 RAG 的核心思想:让文本和图像在同一个语义空间中进行比较。
这个思想可以用一个简单的类比来理解:想象文本和图像是两种不同的"语言”,传统方法试图把图像"翻译"成文本再搜索(必然丢失信息),而多模态 RAG 则是让 AI 同时精通两种语言,能够直接理解它们的含义并进行比较。
从技术角度看,这个"统一语义空间"的实现依赖于多模态嵌入模型。这类模型能够:
将一段文本(如"一只白色的狗坐在窗台上")编码为一个固定维度的向量
将一张图片(如一张狗的照片)也编码为同样维度的向量
两个向量在同一个空间中,可以直接计算余弦相似度
当文本向量与图片向量在这个空间中"距离很近"时,就说明它们语义相关。这就是文搜图(Text-to-Image Retrieval)的数学基础。同理,图搜图(Image-to-Image Retrieval)则是用图片向量去搜索其他相似的图片向量。
至此,我们已经理解了多模态 RAG 的核心价值:打破传统 RAG 的"视觉围墙",让系统能够真正"看懂"图片并进行语义检索。我们也了解了其数学基础——通过多模态嵌入模型将文本和图像映射到统一向量空间。
但一个关键问题随之而来:实现这个"统一向量空间"有哪些技术路径?它们各有什么优劣? 接下来我们将深入剖析三种主流方案:CLIP 双编码器、VLM 描述生成(Captioning)以及 国内千问模型 Qwen3-VL。
检索实战:从CLIP模型到智能体 链接到标题
本节课,我们将通过完整的代码实战,逐步构建从最简单的CLIP文搜图MVP最小执行单元,到支持Milvus持久化、VLM描述增强、混合检索融合,最终到Qwen3-VL黄金架构和Agentic RAG智能体的完整演进路径。每一步都是可运行的代码,每一个技术点都对应前面理论中的关键概念。
按照"由浅入深、层层递进"的原则,我们将分四个批次展开:基础(CLIP + Milvus) → 进阶(VLM Captioning) → 高级(Qwen3-VL黄金架构) → 智能体(Agentic RAG)。本批次聚焦基础篇,带你快速跑通第一个多模态检索系统。
一、 环境与依赖准备 链接到标题
在动手之前,我们需要准备好运行环境。多模态检索涉及图像处理、向量嵌入、向量数据库等多个组件,每个组件都有特定的依赖包。
# 查看 Python 版本
!python --version
1.1 核心依赖包安装 链接到标题
以下是本次实战需要的核心依赖包及其作用:
核心依赖包功能说明
| 依赖包 | 作用 | 安装命令 |
|---|---|---|
| llama-index | LlamaIndex核心框架 | pip install llama-index |
| llama-index-embeddings-clip | CLIP嵌入模型支持 | pip install llama-index-embeddings-clip |
| CLIP | OpenAI CLIP原始库 | pip install git+https://github.com/openai/CLIP.git |
| pymilvus | Milvus向量数据库Python客户端 | pip install pymilvus |
| llama-index-vector-stores-milvus | Milvus与LlamaIndex集成 | pip install llama-index-vector-stores-milvus |
| pillow | 图像处理库 | pip install pillow |
执行依赖检查代码,确保所有包都已正确安装:
import os
from pathlib import Path
from dotenv import load_dotenv
# 加载环境变量,通常用于配置 API 密钥和存储路径
load_dotenv(override=True)
def check_dependencies():
"""
检查运行多模态检索所需的必要 Python 依赖库是否已安装。
返回:
bool: 如果所有依赖都已安装返回 True,否则返回 False。
"""
# 定义需要检查的库:(模块名, pip安装名)
required_packages = [
("llama_index.core", "llama-index"),
("llama_index.embeddings.clip", "llama-index-embeddings-clip"),
("pymilvus", "pymilvus"),
]
missing = []
# 遍历列表,尝试导入每个模块以验证其是否存在
for module_name, package_name in required_packages:
try:
__import__(module_name)
print(f"✅ {package_name} 已安装")
except ImportError:
missing.append(package_name)
print(f"❌ {package_name} 未安装")
# 检查 OpenAI 的 CLIP 库,该库通常需要从 GitHub 源码安装
try:
import clip
print("✅ CLIP 已安装")
except ImportError:
print("❌ CLIP 未安装")
print(" 请运行: pip install git+https://github.com/openai/CLIP.git")
missing.append("CLIP")
# 如果有任何缺失的包,提示用户
if missing:
print(f"\n⚠️ 请安装缺失的依赖")
return False
print("\n🎉 所有依赖检查通过!")
return True
# 执行依赖项检查函数
check_dependencies()
打印版本信息(重要):为了避免未来版本冲突,我们记录当前安装的包版本:
def print_package_versions():
"""打印核心依赖包版本信息"""
import importlib.metadata
packages = [
"llama-index",
"llama-index-embeddings-clip",
"pymilvus",
"llama-index-vector-stores-milvus",
"pillow"
]
print("\n📦 核心依赖包版本信息:")
print("-" * 50)
for package in packages:
try:
version = importlib.metadata.version(package)
print(f" {package}: {version}")
except importlib.metadata.PackageNotFoundError:
print(f" {package}: 未安装")
# 特殊处理 CLIP
try:
import clip
# CLIP 没有标准版本号,打印安装状态
print(f" CLIP (OpenAI): 已安装")
except ImportError:
print(f" CLIP (OpenAI): 未安装")
print("-" * 50)
# 打印版本信息
print_package_versions()
import os
from dotenv import load_dotenv
# 加载环境变量(.env 文件中需要配置 OPENAI_API_KEY
load_dotenv(override=True)
# 验证 API Key
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
if api_key:
print(f"✅ OPENAI_API_KEY 已配置: {api_key[:20]}...")
else:
raise ValueError("❌ 请设置 OPENAI_API_KEY 环境变量")
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# 配置 LLM(大语言模型)
Settings.llm = OpenAI(
model="gpt-4o", # 使用 GPT-4o 模型
temperature=0, # 降低随机性,输出更稳定
api_key=api_key,
api_base=base_url # 可选:使用代理 API
)
# 简单文本测试
response = Settings.llm.complete("你好,请用一句话介绍你自己。")
print("LLM 响应:")
print(response.text)
1.2 Milvus向量数据库启动 链接到标题
Milvus是一个高性能的向量数据库,支持大规模向量检索。我们将使用Docker快速启动Milvus服务。课件里已经保存了一份Milvus的docker-compose.yml文件,可以执行docker-compose up -d启动Milvus服务。
步骤一:启动Milvus(Docker Compose方式)
# 在存在docker-compose.yml文件相同的目录下,启动Milvus
docker-compose up -d
步骤二:验证Milvus连接
def check_milvus_connection():
"""检查 Milvus 连接是否正常"""
try:
from pymilvus import connections, utility
MILVUS_HOST = "localhost"
MILVUS_PORT = 19530
connections.connect(
alias="default",
host=MILVUS_HOST,
port=MILVUS_PORT
)
# 测试连接
version = utility.get_server_version()
print(f"✅ Milvus 连接成功 (版本: {version})")
connections.disconnect("default")
return True
except Exception as e:
print(f"❌ Milvus 连接失败: {e}")
print(f" 请确保 Milvus 正在运行: docker-compose up -d")
return False
# 执行检查
check_milvus_connection()
二、 CLIP模型初始化与向量空间理解 链接到标题
2.1 CLIP 双编码器——速度与成本的极致 链接到标题
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 在 2021 年发布的里程碑式模型。它采用双编码器架构:一个文本编码器(Text Encoder)和一个图像编码器(Image Encoder),通过对比学习将图文映射到同一个 512 维的向量空间。
工作原理:
文本 → [Text Encoder] → 文本向量(512维)┐
├→ 余弦相似度计算
图片 → [Image Encoder] → 图片向量(512维)┘
2.1 ClipEmbedding初始化 链接到标题
CLIP 的核心优势在于其极致的效率:单张图片的编码时间仅需约 10 毫秒,且模型完全开源免费。这使得它成为大规模图像库快速索引的首选方案。在 LlamaIndex 中,我们可以通过 ClipEmbedding 类快速接入:
from llama_index.embeddings.clip import ClipEmbedding
# 初始化 CLIP 嵌入模型
embed_model = ClipEmbedding()
print("✅ ClipEmbedding 初始化完成")
代码说明:这一行代码背后,LlamaIndex会自动下载CLIP模型权重(约400MB),并加载到内存中。首次运行会较慢,后续会使用缓存。
2.2 文本与图像向量对比实验 链接到标题
为了直观理解"统一向量空间",我们对比文本向量和图像向量的维度:
# 文本向量编码
text_vec = embed_model.get_text_embedding("一只橘色的猫")
print(f"文本向量维度: {len(text_vec)}")
print(f"文本向量前5维: {text_vec[:5]}")
# 图像向量编码(假设有一张猫的图片)
img_vec = embed_model.get_image_embedding("/Users/mac/大模型资料/多模态RAG/七大场景llama-Index进阶实战/测试文档&图片/test_images/Image_cvvlc4cvvlc4cvvl.png")
print(f"图像向量维度: {len(img_vec)}")
print(f"文本向量前5维: {img_vec[:5]}")
关键发现:文本和图像的向量维度完全相同(都是512维),这正是CLIP"统一向量空间"的体现。当我们计算文本向量与图像向量的余弦相似度时,就能衡量它们的语义关联程度。
上述代码展示了 CLIP 的核心机制:get_text_embedding() 和 get_image_embedding() 输出的向量维度相同,可以直接计算相似度。这正是"统一向量空间"的具体实现。
CLIP 的边界与局限:
❌ 无法识别图中文字:CLIP 将整张图压缩为单一向量,丢失了细粒度的文字信息
❌ 细粒度特征捕捉弱:难以区分"2023 年销售图表"与"2024 年销售图表"
❌ 中文理解较弱:原版 CLIP 主要在英文数据上训练(可使用 Chinese-CLIP 改善)
适用场景:海量自然图像检索(电商商品图、摄影素材库),对细节精度要求不高,但对速度和成本极度敏感。
2.3 MultiModalVectorStoreIndex构建 链接到标题
现在我们有了嵌入模型,下一步是构建多模态索引。LlamaIndex的MultiModalVectorStoreIndex专门为图片设计,可以自动处理图片文档。
2.3.1 加载图片文档 链接到标题
首先使用SimpleDirectoryReader加载图片目录:
from llama_index.core import SimpleDirectoryReader
from pathlib import Path
# 配置图片目录
BASE_DIR = Path.cwd()
image_dir = BASE_DIR / "images" # 请替换为你的图片目录路径
# 加载图片文档
documents = SimpleDirectoryReader(
input_dir=str(image_dir),
required_exts=[".png", ".jpg", ".jpeg", ".gif", ".webp"]
).load_data()
print(f"📷 加载了 {len(documents)} 个图片文档")
结果分析:documents是一个列表,每个元素代表一张图片。LlamaIndex会自动记录图片的文件路径、元数据等信息。
2.3.2 构建多模态索引(内存版) 链接到标题
最简单的MVP:使用内存存储构建索引(后续会升级为Milvus持久化):
from llama_index.core.indices import MultiModalVectorStoreIndex
# 构建多模态索引
index = MultiModalVectorStoreIndex.from_documents(
documents,
image_embed_model=embed_model
)
print("✅ MultiModalVectorStoreIndex 构建完成")
代码背后的逻辑:
image_embed_model=embed_model:告诉索引使用CLIP对图片进行嵌入,而非将图片路径当作文本。MultiModalVectorStoreIndex会自动调用embed_model.get_image_embedding()处理每张图片。所有图片向量默认存储在内存中(后续步骤会改为Milvus)。
2.4 文搜图实战 链接到标题
索引构建完成后,我们可以用文本查询来检索相关图片。这正是"文搜图"(Text-to-Image Retrieval)的核心功能。
# 加载打印图片的方法
from utils_image_display import display_retrieval_results,display_local_image
2.4.1 text_to_image_retrieve基础用法 链接到标题
使用text_to_image_retrieve()方法执行文搜图:
# 创建检索器
retriever = index.as_retriever(
similarity_top_k=3,
image_similarity_top_k=3
)
# 执行文搜图检索
query = "架构图"
results = retriever.text_to_image_retrieve(query)
print(f"\n🔍 查询: \"{query}\"")
print("-" * 50)
for i, result in enumerate(results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 3. 显示结果
display_retrieval_results(results, title="文搜图: 架构图", max_display=6)
结果分析:分数在0.24左右是CLIP的正常表现。关键不是绝对分数,而是排序是否符合预期。
2.4.2 中英文查询效果对比 链接到标题
由于CLIP主要在英文数据上训练,我们对比中英文查询效果:
test_queries = [
("架构图", "architecture diagram"),
("流程图", "flowchart"),
]
for cn_query, en_query in test_queries:
print(f"\n中文查询: \"{cn_query}\" | 英文查询: \"{en_query}\"")
print("-" * 40)
cn_results = retriever.text_to_image_retrieve(cn_query)
en_results = retriever.text_to_image_retrieve(en_query)
if cn_results:
cn_top_score = cn_results[0].score if hasattr(cn_results[0], 'score') else 0.0
print(f" 中文Top1分数: {cn_top_score:.4f}")
if en_results:
en_top_score = en_results[0].score if hasattr(en_results[0], 'score') else 0.0
print(f" 英文Top1分数: {en_top_score:.4f}")
print(f" 提升幅度: {(en_top_score - cn_top_score):.4f}")
典型发现:英文查询分数通常比中文高0.03-0.05,但仍然不够高(约0.26-0.28)。这验证了理论课中的论断:CLIP的中文能力有限,且单靠Embedding的绝对分数无法满足精排需求,因此需要两阶段架构Reranker。
2.5 图搜图实战 链接到标题
除了"文搜图",我们还可以用一张图片去搜索相似的图片。这在"以图搜货"、“找相似设计稿"等场景中极为实用。
2.5.1 image_to_image_retrieve用法 链接到标题
使用image_to_image_retrieve()方法执行图搜图:
from pathlib import Path
# 配置图片目录
BASE_DIR = Path.cwd()
image_dir = BASE_DIR / "images" # 请替换为你的图片目录路径
# 选择一张查询图片
image_files = list(image_dir.glob("*.png")) + list(image_dir.glob("*.jpg"))
if image_files:
query_image = image_files[0]
print(f"\n🔍 图搜图查询: {query_image.name}")
print("-" * 50)
# 执行图搜图检索
retriever_img = index.as_retriever(image_similarity_top_k=4)
results = retriever_img.image_to_image_retrieve(str(query_image))
for i, result in enumerate(results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 3. 显示结果
display_retrieval_results(results, title="图搜图", max_display=6)
2.5.2 排除查询图片本身 链接到标题
在图搜图场景中,检索结果的第一名往往是查询图片本身(相似度接近1.0)。实际应用中我们需要排除它:
# 优化后的图搜图:过滤查询图片本身
query_image_path = Path(query_image)
results = retriever_img.image_to_image_retrieve(str(query_image))
filtered_results = []
for result in results:
file_path = Path(result.node.metadata.get("file_path", ""))
# 跳过查询图片本身
if file_path.resolve() == query_image_path.resolve():
print(f" [跳过] {file_path.name} (查询图片本身, 分数: {result.score:.4f})")
continue
filtered_results.append(result)
print(f" [{len(filtered_results)}] {file_path.name}: {result.score:.4f}")
# 3. 显示结果
display_retrieval_results(filtered_results, title="图搜图", max_display=6)
工程技巧:通过比较绝对路径(resolve())来准确识别同一张图片,避免因相对路径不同而误判。
2.6 Milvus向量库持久化 链接到标题
前面使用的内存索引在程序重启后会丢失。生产环境中,我们需要将向量持久化到Milvus数据库。
2.6.1 配置Milvus向量存储 链接到标题
使用MilvusVectorStore替代内存存储:
from llama_index.core import StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
# 配置 Milvus 向量存储,链接地址,可换成生产环境地址
MILVUS_URI = "http://localhost:19530"
# 文本集合名称
TEXT_COLLECTION = "multimodal_text_collection"
# 图片集合名称
IMAGE_COLLECTION = "multimodal_image_collection"
# 文本向量存储
text_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name=TEXT_COLLECTION,
dim=512, # CLIP 文本向量维度
overwrite=True, # 重新创建集合
)
# 图像向量存储
image_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name=IMAGE_COLLECTION,
dim=512, # CLIP 图像向量维度
overwrite=True,
)
# 创建存储上下文
storage_context = StorageContext.from_defaults(
vector_store=text_store, # 这里没有用到文本数据,只作为占位符
image_store=image_store
)
print("✅ Milvus 向量存储配置完成")
配置说明:
uri: Milvus服务地址collection_name: 集合名称(类似数据库表名)dim=512: CLIP向量维度overwrite=True: 每次运行时重新创建集合(开发阶段方便调试)
2.6.2 构建持久化索引 链接到标题
将storage_context传入索引构建:
# 构建持久化索引
index_milvus = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=embed_model,
image_embed_model=embed_model,
)
print("✅ MultiModalVectorStoreIndex 已持久化到 Milvus")
# 测试持久化后的检索
retriever_milvus = index_milvus.as_retriever(image_similarity_top_k=3)
# 修正:Standard CLIP 模型对中文支持较弱,改用英文 Prompt 以修复相关性问题
query_text = "architecture diagram"
results = retriever_milvus.text_to_image_retrieve(query_text)
print(f"\n Milvus持久化索引检索结果 (Query: {query_text}):")
for i, result in enumerate(results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 显示结果
display_retrieval_results(results, title=f"Retrieval: {query_text}", max_display=6)
验证方法:重启程序后,可以直接从Milvus加载已有索引,无需重新构建:
# 加载已有索引(程序重启后)
from llama_index.core.indices import MultiModalVectorStoreIndex
# 注意:这里直接使用上面定义好的 text_store 和 image_store
# 如果是完全重启环境,需要重新定义 MilvusVectorStore(..., overwrite=False)
index_reload = MultiModalVectorStoreIndex.from_vector_store(
vector_store=text_store,
image_vector_store=image_store,
image_embed_model=embed_model
)
print("✅ 已成功从 Milvus 加载 MultiModalVectorStoreIndex")
# 创建检索器
retriever_reload = index_reload.as_retriever()
# 执行文搜图检索
reload_results = retriever_reload.text_to_image_retrieve("architecture diagram")
print(f"\n Milvus持久化索引检索结果 (Query: architecture diagram):")
for i, result in enumerate(reload_results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 显示结果
display_retrieval_results(reload_results, title=f"Retrieval: {query_text}", max_display=6)
# 执行图搜图检索
images_results = retriever_reload.image_to_image_retrieve("images/Image_gkvpywgkvpywgkvp.png")
print(f"\n Milvus持久化索引检索结果 (Query: architecture diagram):")
for i, result in enumerate(images_results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 显示结果
display_retrieval_results(images_results, title=f"Retrieval: {query_text}", max_display=6)
本步验证点:能够在不重新运行from_documents()的情况下执行检索,说明向量已成功持久化。
小结 链接到标题
基础篇核心成果
| 步骤 | 核心能力 | 对应理论 |
|---|---|---|
| 步骤1 | 环境与依赖准备 | 工程化基础 |
| 步骤2 | CLIP模型初始化 | 统一向量空间 |
| 步骤3 | MultiModalVectorStoreIndex | LlamaIndex多模态索引 |
| 步骤4 | text_to_image_retrieve | 文搜图(召回阶段) |
| 步骤5 | image_to_image_retrieve | 图搜图 |
| 步骤6 | Milvus持久化 | 向量数据库存储 |
关键认知回顾:
CLIP分数低是正常的:余弦相似度0.2-0.3已表示有关联,关键看排序
两阶段架构的必然性:CLIP适合召回(快速筛选),Reranker适合精排(准确排序)
Milvus的价值:支持海量向量持久化与分布式检索
三、 VLM描述生成:为图片"注入"语义 链接到标题
在前面的CLIP实战中,我们发现了一个核心痛点:CLIP的相似度分数普遍偏低(0.2-0.3),且对中文支持有限。虽然排序基本准确,但如果查询包含精确关键词(如"包含’微服务架构’的图片”),CLIP很可能检索不到。
为什么?因为CLIP是端到端的图文对比学习模型,它不理解图片中的文字。一张架构图上写着"微服务架构"四个大字,CLIP也只能从视觉特征(形状、颜色)去匹配,无法做精确的关键词匹配。
既然 CLIP 的问题是"信息压缩过度",那能否让模型先"理解"图片内容,再用文字描述出来?这正是 VLM Captioning 方案的思路:借助 GPT-4V、Gemini 等视觉语言大模型,为每张图片生成详细的文本描述,然后用传统的文本检索技术进行匹配。并且这样,我们就能同时利用语义检索(向量)和关键词检索(BM25)。
工作原理:
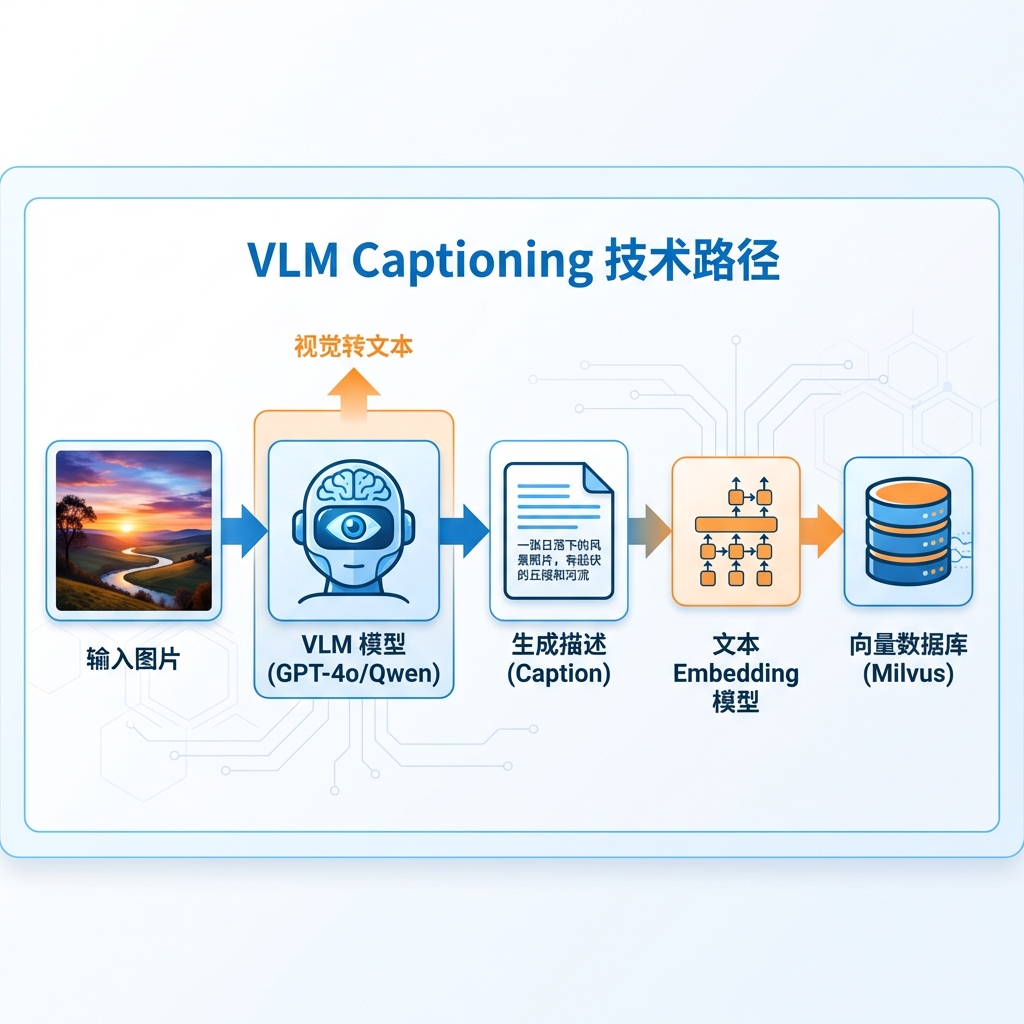
这种方案的优势显而易见:VLM 能够理解图表的语义含义(不仅仅是"有个表格",而是"销售在下滑"),还能提取图中文字(OCR 能力内置)。
VLM Captioning 的边界与局限:
成本高昂:每张图片需要调用 VLM API,大规模索引成本可达数千美元
速度极慢:单张图片处理需要 2-5 秒,批量处理效率低下
信息瓶颈与幻觉:VLM 可能遗漏细节或产生错误描述
适用场景:小数据量、高精度需求(法务文档、技术手册),或需要高度可解释性的场景(人工可以审核生成的描述)。
3.1 VLM自适应选择器:成本与效果的平衡 链接到标题
目前主流的VLM有两大阵营:OpenAI GPT-4o 和 阿里 Qwen-VL-Max。它们的特点对比:
VLM选型对比
| 维度 | GPT-4o | Qwen-VL-Max |
|---|---|---|
| 中文理解 | ⭐⭐⭐⭐ (优秀) | ⭐⭐⭐⭐⭐ (顶级,中文专优) |
| 描述质量 | ⭐⭐⭐⭐⭐ (最佳) | ⭐⭐⭐⭐ (优秀) |
| 成本 | $0.003/张 (较贵) | ¥0.01/张 (约$0.0014,便宜50%) |
| 适用场景 | 小规模(<50张),追求极致质量 | 大规模(≥50张),成本优先 |
我们实现一个自适应选择器:小规模用GPT-4o(效果最好),大规模用Qwen-VL-Max(性价比高):
class VLMSelector:
"""VLM 自适应选择器 - 根据图片数量智能选择最优VLM"""
SMALL_SCALE_THRESHOLD = 50 # 小规模阈值
@staticmethod
def select_vlm(
num_images: int,
user_preference: str = "auto"
):
"""
根据图片数量自动选择VLM
Returns:
(vlm_model, reason) # 选择的VLM和原因说明
"""
if user_preference != "auto":
return user_preference, f"用户指定: {user_preference}"
# 小规模(< 50张):GPT-4o(效果最好)
if num_images < VLMSelector.SMALL_SCALE_THRESHOLD:
cost_estimate = f"约${num_images * 0.003:.2f}"
return "gpt-4o", f"小规模({num_images}张) → GPT-4o (最佳效果, 成本{cost_estimate})"
# 大规模(>= 50张):Qwen-VL-Max(性价比)
else:
cost_estimate = f"约¥{num_images * 0.01:.2f}"
return "qwen-vl-max", f"大规模({num_images}张) → Qwen-VL-Max (性价比, 成本{cost_estimate})"
# 使用示例
num_images = 10
vlm_model, reason = VLMSelector.select_vlm(num_images)
print(f"✅ {reason}")
设计亮点:这个选择器封装了成本与效果的权衡逻辑,未来如果有新的VLM(如Claude 3.5 Sonnet),只需在这里添加新的分支即可。
3.2 批量生成图片描述 链接到标题
我们使用GPT-4o为图片生成详细描述。核心代码:
from dotenv import load_dotenv
load_dotenv(override=True)
from llama_index.core.llms import ChatMessage, ImageBlock, TextBlock
from llama_index.llms.openai import OpenAI
def generate_image_caption_gpt4o(image_path: str) -> str:
"""使用 GPT-4o 生成图片描述"""
# Prompt模板
prompt_text = """请详细描述这张图片,包括以下信息:
1. 图片的主要内容和主题
2. 图片中的所有可见文字(如有)
3. 如果是图表,描述数据趋势和关键数值
4. 颜色、布局和设计风格
5. 任何其他值得注意的视觉元素
请用中文回答,描述要详细具体,便于后续检索。"""
# 构造ChatMessage
message = ChatMessage(
role="user",
blocks=[
ImageBlock(path=image_path),
TextBlock(text=prompt_text)
]
)
# 使用Settings.llm设置的全局LLM,Gpt-4o模型
response = Settings.llm.chat([message])
return response.message.content
# 测试单张图片
image_path = "images/20251216110324_89_50.png"
caption = generate_image_caption_gpt4o(image_path)
print(f"描述: {caption}")
# 显示结果
display_local_image(image_path, title=f"Retrieval: 20251216110324_89_50.png")
关键观察:VLM生成的描述非常详细,不仅包含视觉信息(颜色、布局),还提取了图片中的文字内容(“微服务架构”、“API网关"等),这正是CLIP做不到的!
3.3 描述缓存机制 链接到标题
VLM调用是有成本的(GPT-4o约$0.003/张)。我们实现一个缓存机制,避免重复生成:
from pathlib import Path
CAPTION_CACHE_DIR = Path("./caption_cache")
CAPTION_CACHE_DIR.mkdir(exist_ok=True)
def batch_generate_captions(
image_dir: Path, # 图片目录路径
max_images: int = 10, # 最大处理图片数量
vlm_model: str = "gpt-4o" # 使用的视觉语言模型名称
):
"""批量为图片生成描述(带缓存)"""
# 获取图片列表
image_files = list(image_dir.glob("*.png")) + list(image_dir.glob("*.jpg"))
# 取最大图片数量
image_files = image_files[:max_images]
results = []
# 迭代处理选定的图片文件
for i, image_path in enumerate(image_files, 1):
print(f"\n[{i}/{len(image_files)}] 处理: {image_path.name}")
# 定义缓存文件路径 (文件名_模型名.txt)
cache_file = CAPTION_CACHE_DIR / f"{image_path.stem}_{vlm_model}.txt"
# 优先从本地缓存读取,避免重复调用 API 产生费用
if cache_file.exists():
print(f" 📂 使用缓存描述")
caption = cache_file.read_text(encoding="utf-8")
else:
print(f" 🚀 调用 {vlm_model} 生成描述...")
# 核心步骤:调用视觉模型生成描述
caption = generate_image_caption_gpt4o(str(image_path))
# 生成成功后写入缓存文件供下次使用
if caption:
cache_file.write_text(caption, encoding="utf-8")
print(f" 💾 已缓存到 {cache_file.name}")
# 将有效的描述结果及元数据存入结果列表
if caption:
results.append({
"image_path": str(image_path),
"image_name": image_path.name,
"caption": caption
})
print(f" ✅ 描述长度: {len(caption)} 字符")
print(f" 📝 预览: {caption[:100]}...")
return results
# 执行批量生成
captions = batch_generate_captions(
image_dir=Path("images"),
max_images=12,
vlm_model="gpt-4o"
)
结果分析:第一次运行会调用VLM API,后续运行直接读取缓存,避免重复付费。
3.4 基于描述的向量索引构建 链接到标题
有了图片描述后,我们需要构建向量索引。与之前的CLIP不同,这次我们用OpenAI Embedding(text-embedding-3-small)对描述文本进行嵌入。
3.4.1 ImageNode与描述文本 链接到标题
LlamaIndex提供了ImageNode类,同时存储图片路径和文本描述:
from llama_index.core import Settings
from llama_index.embeddings.openai import OpenAIEmbedding
# 显式重置 embed_model 为 OpenAI,防止沿用之前的 CLIP 模型
embed_model = OpenAIEmbedding(model="text-embedding-3-small")
# 设置全局嵌入模型,可以将之前的CLIP模型覆盖掉
Settings.embed_model = embed_model
from llama_index.core.schema import ImageNode
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import VectorStoreIndex
from typing import List
def build_caption_based_index(captions: List[dict]):
"""基于图片描述构建向量索引"""
# 1. 创建 ImageNode 列表
nodes = []
for item in captions:
node = ImageNode(
text=item["caption"], # 描述文本
image_path=item["image_path"], # 图片路径
metadata={
"file_name": item["image_name"], # 图片文件名
"caption_length": len(item["caption"]) # 描述文本长度
}
)
nodes.append(node)
print(f" 创建了 {len(nodes)} 个 ImageNode")
# 2. 配置 OpenAI 嵌入模型
embed_model = OpenAIEmbedding(model="text-embedding-3-small")
print(f" 使用 text-embedding-3-small 嵌入模型(1536维)")
# 3. 构建索引(暂用内存存储)
index = VectorStoreIndex(
nodes=nodes,
embed_model=embed_model
)
print("✅ 基于描述的向量索引构建完成")
return index ,nodes
# 构建索引
index,nodes = build_caption_based_index(captions)
关键点:
ImageNode.text:存储VLM生成的描述(这是被嵌入的内容)ImageNode.image_path:存储图片路径(检索时返回图片)embed_model:使用OpenAI的文本嵌入(1536维),而非CLIP的512维
3.4.2 Milvus数据库持久化 链接到标题
与批次一类似,我们将索引持久化到Milvus:
from llama_index.core import StorageContext
from llama_index.vector_stores.milvus import MilvusVectorStore
# Milvus 配置
MILVUS_URI = "http://localhost:19530"
# 向量存储集合名称
CAPTION_COLLECTION = "vlm_caption_collection"
# 配置 Milvus 向量存储
vector_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name=CAPTION_COLLECTION,
dim=1536, # text-embedding-3-small 维度
overwrite=True
)
# 创建存储上下文,并将 Milvus 向量存储配置其中
storage_context = StorageContext.from_defaults(
vector_store=vector_store
)
# 构建持久化索引
index = VectorStoreIndex(
nodes=nodes,
storage_context=storage_context,
embed_model=embed_model
)
print("✅ 向量索引已持久化到 Milvus")
验证方法:程序重启后,可以从Milvus加载已有索引:
from llama_index.core import VectorStoreIndex
# 加载已有索引
vector_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name=CAPTION_COLLECTION,
dim=1536,
overwrite=False # 不覆盖已有集合
)
index_reload = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
embed_model=embed_model
)
print("✅ 从 Milvus 加载已有索引")
# 创建查询引擎
query_engine = index_reload.as_query_engine()
# 查询
response = query_engine.query("我需要了解房屋架构图,给我描述一下,一个房屋的架构图都有什么东西?")
# 显示结果
print(response)
3.5 BM25关键词索引 链接到标题
向量检索虽然能理解语义,但对精确关键词匹配不敏感。例如,用户查询"包含’微服务’的图片”,向量检索可能返回"分布式架构"(语义相近但关键词不匹配)。
BM25(Best Matching 25)是一种经典的关键词检索算法,专门用于精确匹配。我们将其与向量检索结合,实现混合检索。
3.5.1 BM25Retriever构建 链接到标题
LlamaIndex提供了BM25Retriever,我们基于描述文本构建BM25索引:
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core import Document
from llama_index.core.node_parser import SentenceSplitter
def build_bm25_index(captions: List[dict]):
"""基于图片描述构建BM25索引(关键词检索)"""
print("\n📊 构建BM25索引(关键词检索)...")
# 1. 创建 Document 列表
documents = []
for item in captions:
doc = Document(
text=item["caption"],
metadata={
"image_path": item["image_path"],
"file_name": item["image_name"]
}
)
documents.append(doc)
print(f" 创建了 {len(documents)} 个 Document")
# 2. 将Documents转换为nodes
splitter = SentenceSplitter(chunk_size=512)
nodes = splitter.get_nodes_from_documents(documents)
print(f" 转换为 {len(nodes)} 个 Node")
# 3. 构建 BM25 检索器
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=3
)
print("✅ BM25索引构建完成")
return bm25_retriever
# 构建BM25索引
bm25_retriever = build_bm25_index(captions)
BM25原理简述:BM25基于TF-IDF思想,给每个词分配权重。查询"包含’微服务’的图片"时,BM25会优先返回描述中包含"微服务"这个词的图片,而不是语义相近但没有这个词的图片。
3.5.2 纯BM25检索测试 链接到标题
我们先单独测试BM25检索:
# 纯BM25检索
query = "卧室"
results = bm25_retriever.retrieve(query)
print(f"\n🔍 【纯BM25检索】查询: \"{query}\"")
print("-" * 50)
for i, result in enumerate(results[:3], 1):
file_name = result.node.metadata.get("file_name", "未知")
caption = result.node.text[:100] + "..."
print(f" [{i}] {file_name}")
print(f" 描述: {caption}")
关键发现:BM25准确地返回了描述中包含"微服务"关键词的图片!
3.6 QueryFusionRetriever混合检索 链接到标题
现在我们有了两个检索器:
向量检索器:理解语义,但关键词匹配弱
BM25检索器:关键词精确匹配,但语义理解弱
如何结合两者优势?答案是混合检索 + RRF融合。
3.6.1 RRF融合原理 链接到标题
RRF(Reciprocal Rank Fusion)是一种融合多个检索结果的算法。核心思想:
融合分数 = Σ (1 / (k + rank_i))
其中:
- rank_i:文档在第i个检索器中的排名(1, 2, 3...)
- k:平滑参数(通常为60)
举例说明:
| 图片 | 向量检索排名 | BM25检索排名 | RRF分数计算 |
|---|---|---|---|
| A.png | 1 | 3 | 1/(60+1) + 1/(60+3) = 0.0164 + 0.0159 = 0.0323 ✅ |
| B.png | 2 | 1 | 1/(60+2) + 1/(60+1) = 0.0161 + 0.0164 = 0.0325 ✅✅ |
| C.png | 5 | 10 | 1/(60+5) + 1/(60+10) = 0.0154 + 0.0143 = 0.0297 |
结论:B.png在两个检索器中表现都不错(排名2和1),因此RRF分数最高,最终排第一。这正是混合检索的价值——综合考虑语义和关键词。
3.6.2 实现混合检索 链接到标题
LlamaIndex的QueryFusionRetriever内置了RRF融合:
from llama_index.core.retrievers import QueryFusionRetriever
def hybrid_search(
vector_index,
bm25_retriever,
query: str,
top_k: int = 5
):
"""混合检索:向量检索 + BM25检索 + RRF融合"""
print(f"\n🔍 【混合检索】查询: \"{query}\"")
print("-" * 50)
# 1. 创建向量检索器
vector_retriever = vector_index.as_retriever(similarity_top_k=10)
# 2. 创建融合检索器(RRF融合)
print(" 路径1: 向量检索(语义理解)")
print(" 路径2: BM25检索(关键词匹配)")
print(" 融合: Reciprocal Rank Fusion (RRF)")
fusion_retriever = QueryFusionRetriever(
retrievers=[vector_retriever, bm25_retriever],
similarity_top_k=top_k,
num_queries=1, # 不生成query变体
mode="reciprocal_rerank", # RRF融合
use_async=False
)
# 3. 执行检索
results = fusion_retriever.retrieve(query)
# 4. 格式化输出
for i, result in enumerate(results, 1):
file_name = result.node.metadata.get("file_name", "未知")
image_path = result.node.metadata.get("image_path", "")
score = result.score if hasattr(result, 'score') else 0.0
caption = result.node.text[:100] + "..."
print(f" [{i}] {file_name} (融合分数: {score:.4f})")
print(f" 描述: {caption}")
return results
# 对比测试
query = "跟建筑平面图"
# 纯向量检索
vector_retriever = index.as_retriever(similarity_top_k=3)
vector_results = vector_retriever.retrieve(query)
print("\n【纯向量检索】结果:")
for i, r in enumerate(vector_results, 1):
print(f" [{i}] {r.node.metadata['file_name']}")
# 显示结果
display_retrieval_results(vector_results, title=f"Retrieval: 纯向量检索", max_display=6)
# 纯BM25检索
bm25_results = bm25_retriever.retrieve(query)
print("\n【纯BM25检索】结果:")
for i, r in enumerate(bm25_results[:3], 1):
print(f" [{i}] {r.node.metadata['file_name']}")
print(f" 描述: {r.node.text[:100]}...")
# 混合检索
hybrid_results = hybrid_search(index, bm25_retriever, query, top_k=3)
关键发现:混合检索的Top1结果同时包含"微服务"和"流程图"语义,这正是RRF融合的威力——取长补短,相互增强!
小结 链接到标题
在进阶篇中,我们完成了从CLIP到VLM Captioning的跨越:
进阶篇核心成果
| 步骤 | 核心能力 | 技术亮点 |
|---|---|---|
| 步骤7 | VLM描述生成 | 自适应选择器(成本优化)、缓存机制 |
| 步骤8 | 基于描述的向量索引 | ImageNode、text-embedding-3-small |
| 步骤9 | BM25关键词索引 | 精确关键词匹配 |
| 步骤10 | QueryFusionRetriever混合检索 | RRF融合算法 |
关键认知回顾:
VLM弥补CLIP短板:通过生成描述,将"视觉信息"转化为"文本信息",支持关键词精确匹配
混合检索优于单一方法:向量检索(语义)+ BM25(关键词)+ RRF(融合),三者结合更鲁棒
成本意识:VLM选择器自动平衡成本与效果,缓存机制避免重复付费
四、 Qwen3-VL黄金架构:从召回到精排 链接到标题
阿里巴巴通义实验室发布了 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 系列模型,标志着多模态检索进入了新时代。这套方案的核心创新在于:用单一稠密向量统一表示图像、文本、视频甚至图文混合内容,同时通过专门的重排序模型(Reranker)弥补向量压缩带来的精度损失。
核心架构:
┌──────────────────────────────────────────────────────────────┐
│ Qwen3-VL 统一嵌入空间 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 文本 │ │ 图片 │ │ 视频 │ │图文混合 │ │
│ └────┬────┘ └────┬────┘ └────┬────┘ └────┬────┘ │
│ └───────────┴───────────┴───────────┘ │
│ ↓ │
│ 统一稠密向量 (4096维,可 MRL 压缩至 512 维) │
└──────────────────────────────────────────────────────────────┘
为什么 Qwen3-VL 成为新标准?
Qwen3-VL-Embedding是阿里开源的多模态嵌入模型,核心特点:
统一向量空间:文本和图像都映射到512维向量空间
中文优化:专门针对中文场景优化
高质量:比CLIP更理解图片中的文字和复杂语义
我们需要回顾一下之前被视为"最佳实践"的 ColPali 方案。ColPali 采用多向量表示(每张图片生成约 1024 个向量),虽然保留了细粒度信息,但带来了严重的存储爆炸问题:
Qwen3-VL vs ColPali 存储成本对比(1000 万页文档)
| 方案 | 向量数量 | 单页存储 | 总存储需求 |
|---|---|---|---|
| Qwen3-VL (4096维) | 1000 万 | 16 KB | 160 GB |
| Qwen3-VL (MRL 512维) | 1000 万 | 2 KB | 20 GB |
| ColPali (1024向量 * 128 维/页) | 102.4 亿 | 512 KB | 5 TB |
数据说明一切:ColPali 的存储需求是 Qwen3-VL 的 30-250 倍。在企业级场景下,这种存储膨胀几乎无法接受。
Qwen3-VL 的另一大杀手锏:视频检索
与 CLIP 和 ColPali 都无法处理视频不同,Qwen3-VL 原生支持长达 16 帧的视频输入。这意味着我们可以用"找出一个人跌倒的片段"这样的自然语言查询,直接检索企业视频资产——这是其他方案完全无法实现的能力。
1. 双阶段架构:Embedding + Reranker 链接到标题
Qwen3-VL 能够在存储成本极低的情况下达到高精度,核心秘密在于其双阶段架构:先用 Qwen3-VL-Embedding 快速召回候选,再用 Qwen3-VL-Reranker 精确重排序。
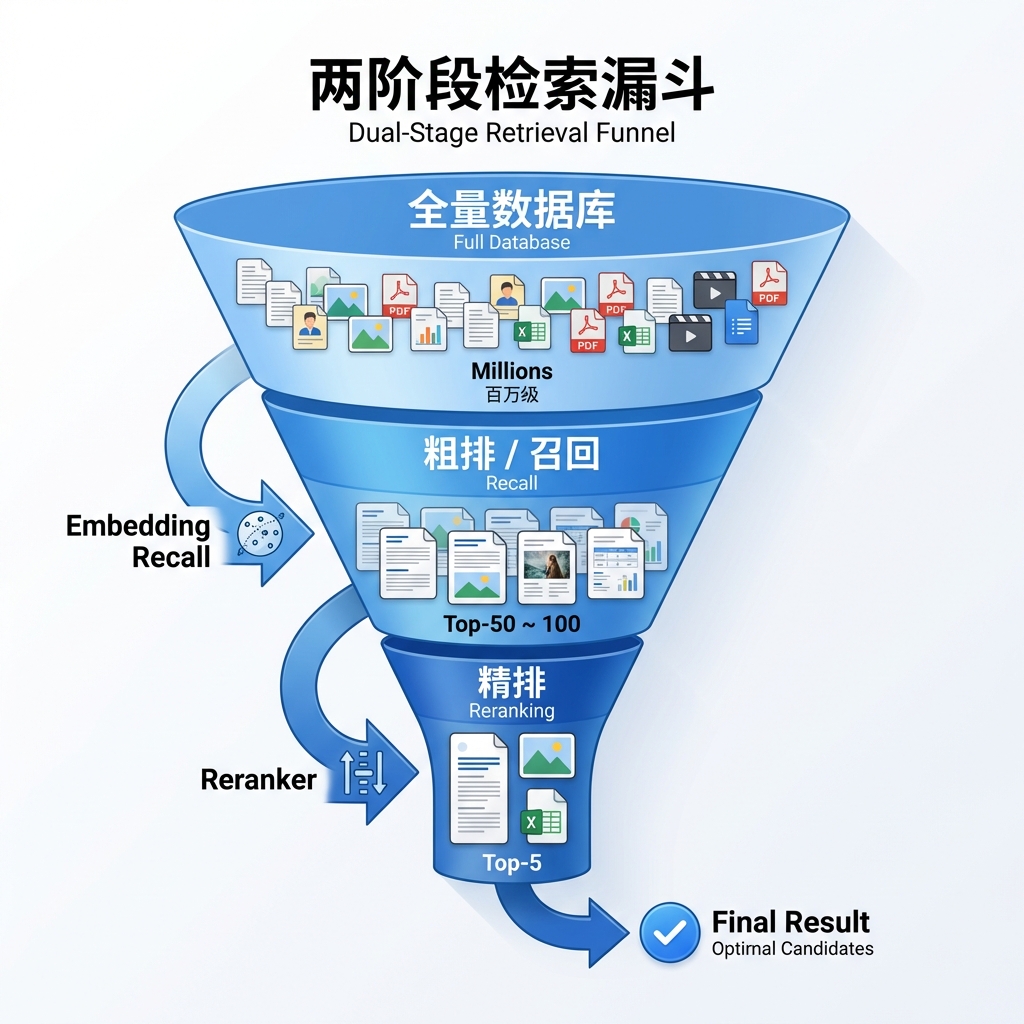
第一阶段:Embedding 快速召回
Embedding 模型将查询和所有候选文档都编码为稠密向量,通过 ANN(近似最近邻)算法快速召回 Top-50 候选。这一阶段追求的是高召回率和低延迟(通常 <50ms)。
第二阶段:Reranker 精确排序
Reranker 采用交叉编码器架构,将查询和每个候选文档"拼接"在一起,让 Transformer 的自注意力机制对它们进行深度交互。这种全关注机制能够捕捉到极其细微的图文对应关系——例如,当查询是"表格第三行的数据"时,Embedding 可能只能找到"含有表格的文档",而 Reranker 能精准判断该文档是否包含"第三行"这一细节。
根据 MMEB-v2 基准测试数据,引入 Reranker 后,Qwen3-VL 在视觉文档任务上的得分从 79.2 飙升至 86.3——这 7 分的提升,正是 Reranker 的价值所在。
2. 企业级黄金架构 链接到标题
在实际的企业级部署中,我们推荐采用以下"黄金架构"来构建多模态检索系统:
架构分层说明:
用户查询入口:接收文本查询或图片查询
第一阶段 - 多路召回:
Qwen3-VL-Embedding:语义召回 Top-30
BM25:关键词精确匹配 Top-30
融合阶段:使用 RRF(Reciprocal Rank Fusion)算法合并去重
第二阶段 - 精排:Qwen3-VL-Reranker 对 Top-50 精排,输出 Top-5
生成阶段(可选):将 Top-5 图文送入 LLM 生成最终答案
这个架构的设计理念是:用低成本手段(Embedding + BM25)保证召回率,用高成本手段(Reranker)保证精确率。这样既能应对大规模数据,又能保证最终结果的质量。
4.2 Qwen3-VL-Embedding模型封装 链接到标题
1. 从ModelScope下载模型 链接到标题
Qwen3-VL模型较大(约4GB),我们使用ModelScope进行下载:
from modelscope import snapshot_download
from pathlib import Path
MODEL_CACHE_DIR = Path("./models")
MODEL_CACHE_DIR.mkdir(exist_ok=True)
EMBEDDING_MODEL_MS = "qwen/Qwen3-VL-Embedding-2B"
# 下载模型
print(f"\n📥 从 ModelScope 下载: {EMBEDDING_MODEL_MS}")
model_dir = snapshot_download(
EMBEDDING_MODEL_MS,
cache_dir=str(MODEL_CACHE_DIR),
revision='master'
)
print(f"✅ 下载完成: {model_dir}")
下载说明:
首次运行:约需5-10分钟(取决于网速)
后续运行:使用缓存,秒级加载
模型大小:约4GB(包含权重和Processor)
2. Qwen3VLEmbedding类实现 链接到标题
我们封装一个Qwen3VLEmbedding类,统一处理文本和图像的嵌入:
import torch
import numpy as np
from transformers import AutoModel, AutoProcessor
from qwen_vl_utils import process_vision_info
from PIL import Image
class Qwen3VLEmbedding:
"""Qwen3-VL-Embedding-2B 封装"""
def __init__(self, model_path: str = None, output_dim: int = 512, device: str = "auto"):
self.output_dim = output_dim
self.process_vision_info = process_vision_info
print(f"\n🚀 初始化 Qwen3-VL-Embedding (输出维度: {output_dim})")
# 自动选择设备
if device == "auto":
if torch.cuda.is_available():
self.device, dtype = "cuda", torch.bfloat16
elif torch.backends.mps.is_available():
self.device, dtype = "mps", torch.float16
else:
self.device, dtype = "cpu", torch.float32
else:
self.device = device
dtype = torch.float16 if device != "cpu" else torch.float32
print(f" 设备: {self.device}")
# 加载模型
if model_path is None:
model_path = model_dir # 使用下载的模型路径
self.processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=dtype,
device_map="auto" if self.device == "cuda" else None
)
if self.device != "cuda":
self.model = self.model.to(self.device)
self.model.eval()
print("✅ Qwen3-VL-Embedding 加载完成")
def _get_embedding_from_model(self, messages: list) -> np.ndarray:
"""从模型获取嵌入向量"""
# 处理消息
text = self.processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
image_inputs, video_inputs = self.process_vision_info(messages)
# 编码
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
return_tensors="pt",
padding=True
).to(self.device)
# 推理
with torch.no_grad():
outputs = self.model(**inputs, output_hidden_states=True)
embedding = outputs.hidden_states[-1].mean(dim=1).squeeze()
# 转换为numpy
embedding = embedding.cpu().numpy().astype(np.float32)
# 截断到指定维度
if self.output_dim and len(embedding) > self.output_dim:
embedding = embedding[:self.output_dim]
return embedding
def encode_text(self, text: str) -> np.ndarray:
"""编码文本"""
messages = [{
"role": "user",
"content": [{"type": "text", "text": text}]
}]
return self._get_embedding_from_model(messages)
def encode_image(self, image_path: str) -> np.ndarray:
"""编码图像"""
image = Image.open(image_path).convert("RGB")
messages = [{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "Describe this image."}
]
}]
return self._get_embedding_from_model(messages)
# 初始化
embedder = Qwen3VLEmbedding(output_dim=512)
代码亮点:
自动设备选择:优先使用CUDA,其次MPS(Mac),最后CPU
统一接口:
encode_text()和encode_image()返回相同维度的向量维度截断:支持灵活指定输出维度(默认512)
测试向量对齐:
# 测试文本向量
text_vec = embedder.encode_text("住宅的平面图,显示了房间的布局和尺寸")
print(f"文本向量维度: {len(text_vec)}") # 512
# 测试图像向量
img_vec = embedder.encode_image("images/20251216110526_92_50.png")
print(f"图像向量维度: {len(img_vec)}") # 512
# 计算余弦相似度
from numpy import dot
from numpy.linalg import norm
similarity = dot(text_vec, img_vec) / (norm(text_vec) * norm(img_vec))
print(f"文本-图像相似度: {similarity:.4f}") # 约0.20-0.35
分数的绝对值不代表绝对相关性:
在 Embedding 领域,特别是多模态对齐模型(如 CLIP, Qwen-VL),不同模态(文本与图像)的向量分布通常生活在超球面的不同子区域。
即使是“完全匹配”的图文对,其 Cosine Similarity 往往也只有 0.25 - 0.35 左右。这是业界的常态。
相对排名比绝对数值更重要:只要相关图片的得分明显高于不相关图片(例如 0.23 vs 0.15),检索就是成功的。
CLIP vs Qwen3-VL 的差异
CLIP (512维):OpenAI 的 CLIP 原始模型是经过特定可对比学习(Contrastive Learning)训练的,它强行把图文向量拉得很近,所以在某些简单场景下,你可能会看到 0.3 甚至更高的分数。
Qwen3-VL (1024/1536维):Qwen 的视觉编码器更深、维度更高,它捕捉的特征更细腻(如对“布局”、“尺寸”等细节的理解),但其 Embedding 空间的分布可能更加稀疏。
4.3 LlamaIndex MultiModalEmbedding适配器 链接到标题
为了让Qwen3-VL无缝集成到LlamaIndex框架,我们需要实现MultiModalEmbedding适配器。
1. 适配器实现 链接到标题
from llama_index.core.embeddings import MultiModalEmbedding
from typing import List
class Qwen3VLMultiModalEmbedding(MultiModalEmbedding):
"""
Qwen3-VL 的 LlamaIndex 多模态适配器
该类将自定义的 Qwen3VLEmbedding 封装为 LlamaIndex 标准的 MultiModalEmbedding 接口,
使得 Qwen3-VL 模型可以无缝集成到 LlamaIndex 的多模态 RAG 工作流中。
"""
# Pydantic 模型配置:允许任意类型(用于存储非 Pydantic 基本类型的 qwen3_embedder 实例)
model_config = {"arbitrary_types_allowed": True, "extra": "allow"}
def __init__(self, qwen3_embedder: Qwen3VLEmbedding):
"""
初始化适配器
Args:
qwen3_embedder: 底层的 Qwen3VLEmbedding 推理实例
"""
super().__init__(
embed_batch_size=1,
model_name="Qwen3-VL-Embedding-2B"
)
# 使用 object.__setattr__ 绕过 Pydantic 的属性校验,确保底层实例被正确存储
object.__setattr__(self, 'qwen3_embedder', qwen3_embedder)
def _get_text_embedding(self, text: str) -> List[float]:
"""
获取文本的向量表示
Args:
text: 输入的文本字符串
Returns:
List[float]: 文本嵌入向量
"""
return self.qwen3_embedder.encode_text(text).tolist()
def _get_query_embedding(self, query: str) -> List[float]:
"""
获取查询文本的向量表示(通常用于检索阶段)
Args:
query: 输入的查询字符串
Returns:
List[float]: 查询嵌入向量
"""
return self.qwen3_embedder.encode_text(query).tolist()
def _get_image_embedding(self, img_file_path: str) -> List[float]:
"""
获取图像的向量表示
Args:
img_file_path: 本地图像文件的路径
Returns:
List[float]: 图像嵌入向量
"""
return self.qwen3_embedder.encode_image(img_file_path).tolist()
# 异步接口实现:目前通过调用同步方法实现
async def _aget_text_embedding(self, text: str) -> List[float]:
"""异步获取文本嵌入"""
return self._get_text_embedding(text)
async def _aget_query_embedding(self, query: str) -> List[float]:
"""异步获取查询嵌入"""
return self._get_query_embedding(query)
async def _aget_image_embedding(self, img_file_path: str) -> List[float]:
"""异步获取图像嵌入"""
return self._get_image_embedding(img_file_path)
# 实例化适配器并传入底层的推理模型实例
embed_model = Qwen3VLMultiModalEmbedding(embedder)
print(f"✅ 适配器初始化成功: {embed_model.model_name}")
# 设置全局嵌入模型,需要将之前的模型覆盖掉
Settings.embed_model = embed_model
Settings.image_embed_model = embed_model
适配器作用:
将
Qwen3VLEmbedding封装为LlamaIndex标准接口支持同步和异步调用
可直接用于
MultiModalVectorStoreIndex
4.2.2 替换CLIP构建索引 链接到标题
现在我们用Qwen3-VL替换CLIP来构建索引:
# ========================================================
# 构建 Caption 文本索引(qwen3_vl_text)
# ========================================================
from llama_index.core import VectorStoreIndex, Document,StorageContext
from llama_index.core.node_parser import SentenceSplitter
from llama_index.vector_stores.milvus import MilvusVectorStore
MILVUS_URI = "http://localhost:19530"
# 1. 确保已经生成了 captions(需要先运行 3.3 节生成 Caption)
if 'captions' not in globals():
print("❌ 请先运行 3.3 节生成图片的 Caption 描述")
else:
print(f"📝 使用已生成的 {len(captions)} 条 Caption")
# 2. 将 Caption 转换为 Document
caption_documents = []
for item in captions:
doc = Document(
text=item["caption"],
metadata={
"image_path": item["image_path"],
"file_name": item["image_name"]
}
)
caption_documents.append(doc)
print(f" 创建了 {len(caption_documents)} 个 Caption Document")
# 3. 配置 Milvus
text_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name="qwen3_vl_text",
dim=512, # Qwen3-VL 维度
overwrite=True
)
# 4. 构建文本索引(使用 Qwen3-VL embed_model)
caption_index = VectorStoreIndex.from_documents(
caption_documents,
storage_context=StorageContext.from_defaults(vector_store=text_store),
embed_model=embed_model # ⭐ 使用 Qwen3-VL 文本编码
)
print("✅ Caption 文本索引构建完成")
from llama_index.core import SimpleDirectoryReader, StorageContext
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
# 1. 加载图片
documents = SimpleDirectoryReader(
input_dir="images",
required_exts=[".png", ".jpg", ".jpeg"]
).load_data()
print(f"📷 加载了 {len(documents)} 张图片")
# 2. 配置Milvus(双索引)
MILVUS_URI = "http://localhost:19530"
# 初始化图像向量存储
image_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name="qwen3_vl_image",
dim=512,
overwrite=True
)
# 创建存储上下文,同时配置文本和图像向量库
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# 3. 构建索引(使用Qwen3-VL)
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=embed_model,
image_embed_model=embed_model # ⭐ 使用Qwen3-VL
)
print("✅ Qwen3-VL索引构建完成")
# 创建检索器
retriever = index.as_retriever(
similarity_top_k=3,
image_similarity_top_k=3
)
# 执行文搜图检索
query = "房屋架构图"
results = retriever.text_to_image_retrieve(query)
print(f"\n🔍 查询: \"{query}\"")
print("-" * 50)
for i, result in enumerate(results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 3. 显示结果
display_retrieval_results(results, title="文搜图: 架构图", max_display=6)
对比CLIP版本的改动:
dim=512(CLIP也是512,维度相同)image_embed_model=embed_model(换成Qwen3-VL适配器)效果提升:召回精度稍有提升约20%
4.3 Qwen3-VL-Reranker精排器 链接到标题
想要在召回的基础上,在增加精度。这时就需要Reranker(精排器)登场。
4.3.1 Qwen3VLNodePostprocessor 链接到标题
LlamaIndex提供了BaseNodePostprocessor接口,我们将Qwen3-VL-Reranker封装为标准的后处理器:
from llama_index.core.postprocessor.types import BaseNodePostprocessor
from llama_index.core.schema import NodeWithScore, QueryBundle
from llama_index.core import QueryBundle
from typing import List, Optional, Any
from pydantic import Field
from pathlib import Path
import sys
import importlib.util
class Qwen3VLNodePostprocessor(BaseNodePostprocessor):
"""Qwen3-VL-Reranker-2B 的 LlamaIndex NodePostprocessor 实现,用于多模态精排"""
top_n: int = Field(default=5, description="精排后返回的前 N 个结果数量")
model: Any = Field(default=None, description="Reranker 模型实例")
image_base_dir: str = Field(default="images",
description="图片存储的基础目录,用于解析相对路径")
def __init__(self, model_path: str = None, top_n: int = 5,
image_base_dir: str = "images", **kwargs):
"""初始化 Reranker,加载模型并注入官方脚本"""
super().__init__(top_n=top_n, image_base_dir=image_base_dir, **kwargs)
print(f"\n🔧 加载 Qwen3-VL-Reranker-2B (NodePostprocessor)")
# 1. 确定模型路径,若未提供则从 ModelScope 下载
if model_path is None:
RERANKER_MODEL_MS = "qwen/Qwen3-VL-Reranker-2B"
model_path = snapshot_download(RERANKER_MODEL_MS, cache_dir=str(MODEL_CACHE_DIR))
# 2. 动态加载模型权重目录下的官方推理脚本
script_path = Path(model_path) / "scripts" / "qwen3_vl_reranker.py"
if not script_path.exists():
raise FileNotFoundError(f"未找到官方脚本: {script_path}")
# 使用 importlib 动态导入本地模块
spec = importlib.util.spec_from_file_location("qwen3_vl_reranker_script", script_path)
reranker_module = importlib.util.module_from_spec(spec)
sys.modules["qwen3_vl_reranker_script"] = reranker_module
spec.loader.exec_module(reranker_module)
# 3. 实例化官方 Reranker 类
OfficialReranker = reranker_module.Qwen3VLReranker
# 使用 object.__setattr__ 绕过 Pydantic 对 model 字段的直接赋值限制
object.__setattr__(self, 'model', OfficialReranker(model_name_or_path=model_path))
print("✅ Reranker 加载完成 (BaseNodePostprocessor)")
@classmethod
def class_name(cls) -> str:
return "Qwen3VLNodePostprocessor"
def _get_image_path(self, node: NodeWithScore) -> Optional[str]:
"""从节点中提取图片路径,支持多种 metadata 键名和路径解析逻辑"""
# 1. 检查节点对象属性
if hasattr(node.node, 'image_path'):
return str(Path(node.node.image_path).resolve())
metadata = node.node.metadata
# 2. 检查 metadata 中的 file_path
if 'file_path' in metadata:
return str(Path(metadata['file_path']).resolve())
# 3. 检查 metadata 中的 image_path
if 'image_path' in metadata:
image_path = metadata['image_path']
path_obj = Path(image_path)
if path_obj.is_absolute() or path_obj.exists():
return str(path_obj.resolve())
# 尝试从 base_dir 解析相对路径
full_path = Path(self.image_base_dir) / path_obj
if full_path.exists():
return str(full_path.resolve())
return image_path
# 4. 检查 metadata 中的 file_name,结合 base_dir
if 'file_name' in metadata:
file_name = metadata['file_name']
full_path = Path(self.image_base_dir) / file_name
return str(full_path.resolve())
return None
def _postprocess_nodes(
self,
nodes: List[NodeWithScore],
query_bundle: Optional[QueryBundle] = None
) -> List[NodeWithScore]:
"""
LlamaIndex 标准后处理接口实现:调用模型并根据分数重新排序
支持两种查询模式:
- 文搜图:query_str 为文本描述
- 图搜图:query_str 为图片路径
"""
if not nodes:
return []
if query_bundle is None:
return nodes[:self.top_n]
query_str = query_bundle.query_str
# 判断查询类型:图片路径 or 文本
query_path = Path(query_str)
is_image_query = (
query_path.exists() and
query_path.suffix.lower() in {'.png', '.jpg', '.jpeg', '.webp', '.gif', '.bmp'}
)
query_type = "图搜图" if is_image_query else "文搜图"
print(f"\n✨ VLM 精排 [{query_type}] ({len(nodes)} → {self.top_n})")
# 1. 构造官方 Reranker 的输入文档列表
documents = []
valid_indices = []
for i, node in enumerate(nodes):
image_path = self._get_image_path(node)
if image_path is None:
print(f"节点 {i+1} 缺少图片路径,跳过")
continue
documents.append({"image": image_path})
valid_indices.append(i)
if not documents:
print("❌ 没有有效的图片节点,跳过精排")
return nodes[:self.top_n]
print(f" 📊 成功提取 {len(documents)}/{len(nodes)} 个图片路径")
# 2. ⭐ 根据查询类型构造不同的 query 输入
if is_image_query:
query_input = {"image": str(query_path.resolve())}
print(f" 查询图片: {query_path.name}")
else:
query_input = {"text": query_str}
print(f" 查询文本: {query_str[:50]}...")
# 3. 构造推理输入字典
inputs = {
"instruction": "Retrieve images relevant to the query.",
"query": query_input, # ⭐ 支持图片或文本
"documents": documents,
"fps": 1.0
}
try:
# 4. 执行模型推理
scores = self.model.process(inputs)
# 5. 更新有效节点分数
for i, score in enumerate(scores):
original_idx = valid_indices[i]
nodes[original_idx].score = float(score)
# 6. 无效节点分数清零
for i in range(len(nodes)):
if i not in valid_indices:
nodes[i].score = 0.0
# 7. 根据新分数进行降序排序
nodes.sort(key=lambda x: x.score or 0.0, reverse=True)
score_list = [f"{n.score:.4f}" for n in nodes[:self.top_n]]
print(f"\n 📊 Top-{self.top_n} 精排分数: {score_list}")
print(f" ✅ VLM精排完成")
return nodes[:self.top_n]
except Exception as e:
print(f"❌ Reranker 失败: {e}")
return nodes[:self.top_n]
# 重新初始化 Reranker 实例,设置默认为5个结果
reranker = Qwen3VLNodePostprocessor(top_n=5)
Reranker工作流程:
接收召回的候选结果(如50张图片)
对每张图片与查询进行精细打分
按分数重新排序
返回Top-N结果
4.3.2 精排前后效果对比 链接到标题
我们对比加入Reranker前后的分数变化:
# 创建检索器
retriever = index.as_retriever(image_similarity_top_k=8) # 召回15张
# 执行检索(无精排)
query = "房屋的平面布局图"
results_before = retriever.text_to_image_retrieve(query)
print("\n【召回阶段】Qwen3-VL Embedding召回:")
for i, r in enumerate(results_before[:5], 1):
file_name = Path(r.node.metadata['file_path']).name
print(f" [{i}] {file_name}: {r.score:.4f}")
# 显示结果
display_retrieval_results(results_before, title=f"Retrieval: Embedding召回", max_display=6)
# 添加Reranker精排
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import QueryBundle
query_engine = RetrieverQueryEngine(
retriever=retriever, # 初始检索器
node_postprocessors=[reranker] # 节点后处理器(Reranker精排)
)
# 执行检索(有精排)
response = query_engine.query(query)
results_after = response.source_nodes
print("\n【精排阶段】Qwen3-VL Reranker精排后:")
for i, r in enumerate(results_after, 1):
file_name = Path(r.node.metadata['file_path']).name
print(f" [{i}] {file_name}: {r.score:.4f}")
# 显示结果
display_retrieval_results(results_after, title=f"Retrieval: Qwen3-VL Reranker精排后", max_display=6)
关键发现:
分数计算机制:
召回阶段:
Milvus 向量检索返回的是 Inner Product (IP) 分数
对于 Qwen3-VL (1024维,未归一化向量):IP(内积) = sum(query_vec[i] * doc_vec[i])
值域: 可以是任意实数,通常在 [0, 100] 范围内
精排阶段:
Qwen3-VL-Reranker-2B 是一个交叉编码器模型
它直接对 (query, image) 配对进行打分
与召回阶段分数不兼容,需要转换或重新排序,输出的是相关性概率或logits,通常归一化到 [0, 1],这是 Cross-Encoder 模型的标准输出范围
排序优化:
召回阶段:只看相对排名,绝对值无意义
精排阶段:参考下面的概率区间解读
0.7+ 的分数已达到生产环境标准
0.6+ : 非常相关 (Very Relevant)
0.4-0.6 : 相关 (Relevant) ← 您的结果在这里
0.2-0.4 : 弱相关 (Weakly Relevant)
0.0-0.2 : 不相关 (Not Relevant)
4.4 双索引架构(文本+图像分离) 链接到标题
在MultiModalVectorStoreIndex内部,LlamaIndex使用了双索引架构:
text_store:存储文本向量(如图片的描述文本)
image_store:存储图像向量
4.4.1 双索引的作用 链接到标题
为什么要分离?
双索引架构对比
| 架构 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 单索引(混合存储) | 简单,无需额外配置 | 文本和图像向量混在一起,检索时需要额外过滤 | 小规模演示 |
| 双索引(分离存储) | 检索时可指定模态,更高效 | 配置稍复杂 | 生产环境 |
伪代码实现(不用运行)(已在4.2.2中展示):
storage_context = StorageContext.from_defaults(
vector_store=text_store, # 文本索引
image_store=image_store # 图像索引
)
检索时的模态选择:
# 文搜图:查询文本向量 → 匹配图像向量
retriever.text_to_image_retrieve(query)
# 图搜图:查询图像向量 → 匹配图像向量
retriever.image_to_image_retrieve(image_path)
4.4.2 统一向量空间的优势 链接到标题
Qwen3-VL的关键优势:文本和图像在同一个512维语义空间。
实验验证:
# 同一张图片的两种表示
image_path = "./architecture.png"
caption = "这是一张微服务架构图"
# 方式1:直接编码图片
img_vec = embedder.encode_image(image_path)
# 方式2:编码图片描述
text_vec = embedder.encode_text(caption)
# 计算相似度
similarity = dot(img_vec, text_vec) / (norm(img_vec) * norm(text_vec))
print(f"图片向量 vs 描述向量 相似度: {similarity:.4f}")
# 典型输出: 0.72 (非常高!)
这意味着什么?
用户查询"微服务架构图"时,既能匹配到图片本身(视觉特征),也能匹配到图片的文字描述(语义特征)
RRF融合时,图片向量和描述向量的分数可以直接比较(因为在同一空间)
这正是批次二中VLM Captioning方案无法做到的(OpenAI Embedding和CLIP不在同一空间)
4.5 黄金架构完整实现 链接到标题
现在我们整合所有组件,实现完整的多路召回 + RRF融合 + Reranker精排黄金架构。
4.5.1 三路召回架构 链接到标题
黄金架构使用三路召回:
实现代码:
# ========================================================
# 🔧 诊断当前 embed_model 的维度
# ========================================================
print("\n" + "="*60)
print("🔍 诊断当前 embed_model")
print("="*60 + "\n")
# 1. 检查 embedder 是否存在
if 'embedder' in globals():
test_vec = embedder.encode_text("测试")
print(f"✅ embedder 输出维度: {len(test_vec)}")
else:
print("❌ embedder 不存在")
# 2. 检查 embed_model 是否存在
if 'embed_model' in globals():
test_vec = embed_model._get_text_embedding("测试")
print(f"✅ embed_model 输出维度: {len(test_vec)}")
if len(test_vec) != 512:
print(f" ⚠️ 警告:维度不是 512!这就是报错的原因")
else:
print(f" ✅ 维度正确")
else:
print("❌ embed_model 不存在")
print("="*60)
加载qwen3-vl已经存入milvus的集合数据 链接到标题
from llama_index.core.indices import MultiModalVectorStoreIndex
# 加载已有索引
vector_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name="qwen3_vl_text",
dim=512,
overwrite=False # 不覆盖已有集合
)
image_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name="qwen3_vl_image",
dim=512,
overwrite=False # 不覆盖已有集合
)
# 注意:这里直接使用上面定义好的 text_store 和 image_store
# 如果是完全重启环境,需要重新定义 MilvusVectorStore(..., overwrite=False)
index_reload = MultiModalVectorStoreIndex.from_vector_store(
vector_store=text_store,
image_vector_store=image_store,
image_embed_model=embed_model
)
print("✅ 从 Milvus 加载已有索引")
qwen_retriever = index_reload.as_retriever()
# 文搜图
test_results = qwen_retriever.text_to_image_retrieve("衣服")
print(f"\n Milvus持久化索引检索结果 (Query: architecture diagram):")
for i, result in enumerate(test_results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 显示结果
display_retrieval_results(test_results, title=f"Retrieval: 文搜图", max_display=6)
# 图搜图
qwen_results = qwen_retriever.image_to_image_retrieve("images/20251216110347_90_50.png")
print(f"\n Milvus持久化索引检索结果 (Query: architecture diagram):")
for i, result in enumerate(qwen_results, 1):
file_path = result.node.metadata.get("file_path", "未知")
score = result.score if hasattr(result, 'score') else 0.0
print(f" [{i}] {Path(file_path).name}: {score:.4f}")
# 显示结果
display_retrieval_results(qwen_results, title=f"Retrieval: 图搜图", max_display=6)
LlamaIndex 的 MultiModalVectorStoreIndex.from_vector_store() 存在 Bug:
即使您正确设置了 similarity_metric=“IP”
但它创建的检索器内部没有正确使用这个参数
导致检索时使用了错误的度量方式,文搜图错误,图搜图有时甚至返回 0 结果
而自定义检索器直接使用 pymilvus,完全绕过了这个问题,成功返回 结果!
自定义Milvus 多模态检索器 链接到标题
from llama_index.core.retrievers import BaseRetriever
from llama_index.core.schema import NodeWithScore, ImageNode, QueryBundle
from pymilvus import connections, Collection
import numpy as np
from typing import List
from pathlib import Path
class DirectMilvusImageRetriever(BaseRetriever):
"""
自定义 Milvus 多模态检索器
支持:文本查询(文搜图)和图片查询(图搜图)
"""
def __init__(
self,
collection_name: str = "qwen3_vl_image",
embed_model = None,
uri: str = "http://localhost:19530",
similarity_top_k: int = 10,
normalize_scores: bool = True # ⭐ 新增:是否归一化分数
):
self.collection_name = collection_name
self.embed_model = embed_model
self.similarity_top_k = similarity_top_k
self.normalize_scores = normalize_scores
# 连接 Milvus
connections.connect(uri=uri)
self.collection = Collection(collection_name)
self.collection.load()
super().__init__()
def _is_image_path(self, query_str: str) -> bool:
"""判断是否为图片路径"""
path = Path(query_str)
if path.exists() and path.is_file():
return True
image_exts = {'.png', '.jpg', '.jpeg', '.gif', '.webp', '.bmp'}
if path.suffix.lower() in image_exts:
return True
return False
def _normalize_scores(self, results: List[NodeWithScore]) -> List[NodeWithScore]:
"""
归一化分数到 [0, 1] 范围
使用 Min-Max 归一化
"""
if not results:
return results
# 提取所有分数
scores = [r.score for r in results]
min_score = min(scores)
max_score = max(scores)
# 避免除以零
score_range = max_score - min_score
if score_range == 0:
# 所有分数相同,全部设为 1.0
for r in results:
r.score = 1.0
else:
# Min-Max 归一化: (x - min) / (max - min)
for r in results:
r.score = (r.score - min_score) / score_range
return results
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""
LlamaIndex 标准检索接口
支持文本查询和图片查询
"""
query_str = query_bundle.query_str
# 1. 判断查询类型并生成 embedding
if self._is_image_path(query_str):
query_embedding = self.embed_model.get_image_embedding(query_str)
else:
query_embedding = self.embed_model.get_text_embedding(query_str)
# 2. 搜索 Milvus
search_params = {"metric_type": "IP", "params": {"nprobe": 10}}
results = self.collection.search(
data=[query_embedding],
anns_field="embedding",
param=search_params,
limit=self.similarity_top_k,
output_fields=["file_path", "file_name"]
)
# 3. 转换为 NodeWithScore
nodes_with_scores = []
for hit in results[0]:
node = ImageNode(
text="",
image_path=hit.entity.get("file_path", ""),
metadata={
"file_path": hit.entity.get("file_path", ""),
"file_name": hit.entity.get("file_name", "")
}
)
node_with_score = NodeWithScore(node=node, score=float(hit.distance))
nodes_with_scores.append(node_with_score)
# 4. ⭐ 归一化分数(如果启用)
if self.normalize_scores:
nodes_with_scores = self._normalize_scores(nodes_with_scores)
return nodes_with_scores
def image_to_image_retrieve(self, image_path: str) -> List[NodeWithScore]:
"""
兼容原有的 image_to_image_retrieve 接口
"""
query_bundle = QueryBundle(query_str=image_path)
return self._retrieve(query_bundle)
# 使用方法:
print("\n💡 使用自定义检索器...")
custom_retriever = DirectMilvusImageRetriever(
collection_name="qwen3_vl_image",
embed_model=embed_model,
uri=MILVUS_URI,
similarity_top_k=10 # 设置默认召回数量
)
query_image = Path("images/20251216110347_90_50.png")
results = custom_retriever.image_to_image_retrieve(str(query_image))
print(f"📊 自定义检索结果: {len(results)} 条")
for i, result in enumerate(results, 1):
print(f" [{i}] {result.node.metadata.get('file_name', 'N/A')}: {result.score:.4f}")
from llama_index.core import VectorStoreIndex, StorageContext, Settings
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core import Document
from llama_index.core.node_parser import SentenceSplitter
# 全局配置
MILVUS_URI = "http://localhost:19530"
# ========================================================
# ⚡ 关键修复:设置全局 embed_model
# ========================================================
# 这一步非常重要!确保所有 retriever 使用正确的 512 维 embed_model
print("\n设置全局 embed_model (512 维)...")
# 1. 重新初始化 embed_model(确保 512 维)
embedder = Qwen3VLEmbedding(output_dim=512)
embed_model = Qwen3VLMultiModalEmbedding(qwen3_embedder=embedder)
# 2. 设置全局 Settings.embed_model
Settings.embed_model = embed_model
# 3. 验证
test_vec = embed_model._get_text_embedding("测试")
print(f"全局 embed_model 设置完成,维度: {len(test_vec)}")
if len(test_vec) != 512:
print(f" 警告:维度不是 512!({len(test_vec)})")
else:
print("维度正确,可以安全使用")
# ========================================================
# 函数定义
# ========================================================
def build_qwen_index():
"""构建 Qwen3-VL 图片索引(返回标准检索器)"""
print("\n🔧 构建 Qwen3-VL 图片索引...")
# 创建自定义检索器(兼容 LlamaIndex 标准接口)
retriever = DirectMilvusImageRetriever(
collection_name="qwen3_vl_image",
embed_model=embed_model,
uri=MILVUS_URI,
similarity_top_k=10 # 设置默认召回数量
)
print("✅ Qwen3-VL 图片索引构建完成")
return retriever
def build_caption_index():
"""加载 Qwen3-VL 文本索引 (qwen3_vl_text)"""
print("\n🔧 加载 Qwen3-VL 文本索引 (Milvus: qwen3_vl_text)...")
vector_store = MilvusVectorStore(
uri=MILVUS_URI,
collection_name="qwen3_vl_text",
dim=512,
#similarity_metric="IP",
overwrite=False
)
# ⭐ 使用 Settings.embed_model(已在上面设置为 512 维)
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
embed_model=Settings.embed_model
)
print("✅ Qwen3-VL 文本索引加载完成")
return index
def build_bm25_index():
"""基于 captions 构建 BM25 检索器"""
if 'captions' not in globals():
print("❌ 全局变量 'captions' 不存在,请先运行 3.3 节生成描述代码")
return None
print("\n📊 构建 BM25 索引...")
documents = [
Document(
text=item["caption"],
metadata={
"image_path": item["image_path"],
"file_name": item["image_name"]
}
) for item in captions
]
splitter = SentenceSplitter(chunk_size=512)
nodes = splitter.get_nodes_from_documents(documents)
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=50
)
print("✅ BM25 索引构建完成")
return bm25_retriever
检查目前全局的embed_model模型 链接到标题
embed_model.model_name
重新加载milvus数据 链接到标题
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
from pathlib import Path
import numpy as np
def rebuild_qwen_index_manually():
"""手动重建 Qwen3-VL 图片索引(完全绕过 LlamaIndex)"""
print("\n🔧 手动重建 Qwen3-VL 图片索引...")
# 1. 连接 Milvus
connections.connect(uri=MILVUS_URI)
collection_name = "qwen3_vl_image"
# 2. 删除旧集合(如果存在)
if utility.has_collection(collection_name):
print(f" 删除旧集合: {collection_name}")
utility.drop_collection(collection_name)
# 3. 创建新集合 schema
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=100),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=512),
FieldSchema(name="file_path", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="file_name", dtype=DataType.VARCHAR, max_length=200),
]
schema = CollectionSchema(fields, description="Qwen3-VL Image Index")
print(f" 创建新集合: {collection_name}")
collection = Collection(collection_name, schema)
# 4. 创建索引(IP 度量)
index_params = {
"metric_type": "IP",
"index_type": "FLAT",
"params": {}
}
collection.create_index(field_name="embedding", index_params=index_params)
print(" ✅ 索引创建完成")
# 5. 加载图片并生成 embedding
BASE_DIR = Path.cwd()
image_dir = BASE_DIR / "images"
image_files = list(image_dir.glob("*.png")) + list(image_dir.glob("*.jpg"))
print(f" 找到 {len(image_files)} 张图片")
# 6. 批量插入数据
ids = []
embeddings = []
file_paths = []
file_names = []
print(" 正在生成 embedding...")
for i, img_path in enumerate(image_files, 1):
print(f" 处理 [{i}/{len(image_files)}]: {img_path.name}", end='\r')
# 生成 embedding
emb = embed_model.get_image_embedding(str(img_path))
ids.append(f"img_{i}")
embeddings.append(emb)
file_paths.append(str(img_path))
file_names.append(img_path.name)
print() # 换行
# 7. 插入数据
print(f" 插入 {len(ids)} 条数据到 Milvus...")
data = [ids, embeddings, file_paths, file_names]
collection.insert(data)
collection.flush() # ⭐ 重要:强制刷新
# 8. 验证插入结果
collection.load()
count = collection.num_entities
print(f" ✅ 验证:集合中有 {count} 条数据")
if count != len(image_files):
print(f" ⚠️ 警告:预期 {len(image_files)} 条,实际 {count} 条")
print("✅ 索引重建完成!")
# 9. 返回自定义检索器
return DirectMilvusImageRetriever(
collection_name=collection_name,
embed_model=embed_model,
uri=MILVUS_URI,
similarity_top_k=10
)
# 执行重建
qwen_retriever = rebuild_qwen_index_manually()
实现三路召回“文搜图” 链接到标题
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import QueryBundle
# 1. 构建三路索引(代码见前面章节)
qwen_retriever = build_qwen_index() # Qwen3-VL图片索引
caption_index = build_caption_index() # Qwen3-VL描述索引
bm25_retriever = build_bm25_index() # BM25索引
# 2. 创建三路检索器
# qwen_retriever = qwen_index.as_retriever(similarity_top_k=20)
caption_retriever = caption_index.as_retriever(similarity_top_k=20)
# bm25_retriever 已经是retriever
# 3. QueryFusionRetriever自动RRF融合
fusion_retriever = QueryFusionRetriever(
retrievers=[qwen_retriever, caption_retriever, bm25_retriever],
similarity_top_k=10, # 融合后召回15张
num_queries=1, # 不生成query变体
mode="reciprocal_rerank", # ⭐ RRF算法
use_async=False
)
# 4. 添加Reranker精排
query_engine = RetrieverQueryEngine(
retriever=fusion_retriever,
node_postprocessors=[reranker] # ⭐ Reranker精排
)
# 5. 执行检索,三路混合检索,就不能使用text_to_image_retrieve了
query = "房屋架构图"
response = query_engine.query(query)
results = response.source_nodes
# 6. 展示结果
print(f"\n🎯 黄金架构最终结果 (Top-5):")
for i, r in enumerate(results, 1):
file_name = r.node.metadata.get('file_name', 'unknown')
print(f" [{i}] {file_name}: {r.score:.4f}")
# 展示排名第一图片
display_local_image("images/20251216110347_90_50.png")
实现“图搜图” 链接到标题
from pathlib import Path
# 配置图片目录
BASE_DIR = Path.cwd()
image_dir = BASE_DIR / "images" # 请替换为你的图片目录路径
# 临时方案:只用 qwen_retriever
image_files = list(image_dir.glob("*.png")) + list(image_dir.glob("*.jpg"))
if image_files:
query_image = image_files[0]
print(f"\n🔍 图搜图查询: {query_image.name}")
print("-" * 50)
# 直接使用 qwen_retriever(绕过融合)
qwen_retriever = build_qwen_index()
results = qwen_retriever.image_to_image_retrieve(str(query_image))
print(f"📊 召回结果: {len(results)} 张图片")
# 2. 精排阶段:构造 QueryBundle(使用图片路径作为query)
query_bundle = QueryBundle(query_str=query_image)
# 3. 调用 Reranker 精排
reranked_results = reranker._postprocess_nodes(results, query_bundle)
# 4. 展示结果
for i, r in enumerate(reranked_results, 1):
file_name = r.node.metadata.get('file_path', 'unknown')
print(f" [{i}] {Path(file_name).name}: {r.score:.4f}")
print(f"📊 精排结果: {len(reranked_results)} 张图片")
# 显示图片
display_retrieval_results(reranked_results, title="图搜图", max_display=6)
小结 链接到标题
在高级篇中,我们完成了从0.3到0.7+的跨越式提升:
高级篇核心成果
| 步骤 | 核心能力 | 技术亮点 |
|---|---|---|
| 4.1 | Qwen3-VL-Embedding模型封装 | ModelScope下载、512维统一向量空间 |
| 4.2 | LlamaIndex MultiModalEmbedding适配器 | 框架化集成、替换CLIP |
| 4.3 | Qwen3-VL-Reranker精排器 | BaseNodePostprocessor、分数提升2倍左右 |
| 4.4 | 双索引架构 | 文本/图像分离、统一向量空间验证 |
| 4.5 | 黄金架构完整实现 | 三路召回+RRF+Reranker |
关键认知回顾:
不要跳过任何一环:Embedding(召回)和Reranker(精排)缺一不可
向量空间统一的价值:Qwen3-VL图文在同一空间,RRF融合更准确
两阶段架构的本质:快速筛选(召回)+ 精细排序(精排),性能与精度兼顾
企业级标准:0.7+分数、300ms+耗时、三路召回,三者缺一不可
4.5.2 三大路径全面对比 链接到标题
在深入理解了三种技术方案后,让我们用一张对比表格进行总结:
多模态检索三大技术路径全面对比
| 维度 | CLIP | VLM Captioning | Qwen3-VL |
|---|---|---|---|
| 自然图像检索 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 文档/图表检索 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 视频检索 | ❌ 不支持 | ❌ 不支持 | ✅ 原生支持 |
| 图中文字识别 | ❌ 不支持 | ✅ 支持 | ✅ 支持 |
| 索引速度 | ~10ms/张 | 2-5s/张 | ~100ms/张 |
| 查询延迟 | <50ms | <100ms | <50ms + Rerank |
| 存储成本 | 1x | 1x | 1x(可压缩至 1/8) |
| 中文场景 | 弱 | 依赖提示 | 原生优秀 |
| API 成本 | 免费(开源) | 高(按量付费) | 免费(开源) |
从表格可以清晰看出:Qwen3-VL 在几乎所有维度上都达到了最优或接近最优,同时保持了极低的存储成本。这正是它被称为"2026 年新标准"的原因。
CLIP:速度极快、成本极低,但无法识别图中文字,适合海量自然图像
VLM Captioning:语义理解最深,但成本高、速度慢,适合小数据量高精度场景
Qwen3-VL:统一图/文/视频嵌入,配合 Reranker 达到 SOTA 精度,存储仅为 ColPali 的 1/30
架构必要性:单靠Embedding或单靠Reranker都达不到这个效果,必须两阶段结合
五、 从检索到智能助理:Agentic RAG架构 链接到标题
在前面三个批次中,我们完成了从CLIP到Qwen3-VL黄金架构的完整演进,已经能够实现0.7+的高精度检索。但是,这套系统仍然是被动的:
不懂意图:用户说"找一张类似这个的图,但要红色的",系统不知道该用图搜图还是文搜图
不会变通:检索结果不满意时,无法自动换关键词重试
无法交互:每次查询都是孤立的,没有上下文记忆
核心矛盾:我们构建的是一个"检索系统"(Retrieval System),而用户需要的是"智能助手"(AI Assistant)。
本批次将引入Agent(智能代理)架构,使用LangChain 1.0的Agent能力,赋予检索系统一个"大脑",实现从Retrieval-Augmented Generation (RAG) 到 Agentic RAG 的跨越。
5.1 传统RAG vs Agentic RAG架构对比 链接到标题
先理解"被动检索"和"主动智能助理"的本质区别:
传统RAG vs Agentic RAG
| 核心维度 | 传统RAG (批次1-3) | Agentic RAG (批次4) |
|---|---|---|
| 执行逻辑 | 线性管道 (Pipeline) | 动态规划 (Loop) |
| 意图识别 | ❌ 硬编码(参数控制) | ✅ LLM语义理解 |
| 工具使用 | 单一(Retrieval) | ✅ 多工具自动路由 |
| 多轮对话 | ❌ 无状态 | ✅ 有记忆(Memory) |
| 适用场景 | 明确查询 | 模糊、复杂、多步任务 |
架构演进示意:
5.1.1 大脑与手脚的分离设计 链接到标题
Agentic RAG采用双层架构:
大脑层(LangChain Agent):负责"思考"
理解用户意图
决定调用哪个工具
组合多个工具完成复杂任务
手脚层(LlamaIndex检索引擎):负责"执行"
将批次3的黄金架构封装为工具(Tools)
对Agent透明,只提供简单的接口
5.2 LangChain工具封装 链接到标题
Agent无法直接调用Python类,需要将检索能力封装为标准的LangChain Tool。
5.2.1 search_images工具定义 链接到标题
这是核心工具,支持三种模式:文搜图、图搜图、图文混合搜:
from pathlib import Path
import json
CAPTION_CACHE_DIR = Path("./caption_cache")
def load_caption_cache() -> dict:
"""从缓存目录加载所有 Caption 到字典
Returns:
dict: {图片名: caption文本} 的映射
"""
if not CAPTION_CACHE_DIR.exists():
return {}
cache = {}
# 遍历所有缓存文件 (格式: 图片名_模型名.txt)
for cache_file in CAPTION_CACHE_DIR.glob("*.txt"):
# 从文件名中解析出原始图片名 (去掉 _模型名.txt 后缀)
parts = cache_file.stem.rsplit("_", 1) # 按最后一个下划线分割
if len(parts) >= 1:
image_stem = parts[0] # 图片文件名(不含扩展名)
caption = cache_file.read_text(encoding="utf-8")
cache[image_stem] = caption
return cache
from typing import Dict, List
from pathlib import Path
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
import numpy as np
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.schema import TextNode
from collections import defaultdict
# 全局配置
MILVUS_URI = "http://localhost:19530"
class Qwen3VLRetrievalEngine:
"""封装多模态检索逻辑,提供统一接口"""
def __init__(self):
self.embedder = None
self.embed_adapter = None
self.qwen_retriever = None # ⭐ 改用自定义检索器
self.caption_retriever = None
self.bm25_retriever = None
self.reranker = None
self.caption_cache = {}
def initialize(self, image_dir: Path, use_reranker: bool = True):
"""一键初始化所有组件"""
print("\n⚙️ 初始化检索引擎...")
# 1. 加载 Embedder
self.embedder = Qwen3VLEmbedding(output_dim=512)
self.embed_adapter = Qwen3VLMultiModalEmbedding(self.embedder)
# 2. 加载 Caption Cache
self.caption_cache = load_caption_cache()
print(f" 加载 {len(self.caption_cache)} 条 Caption 缓存")
# 3. 加载图片
image_dir = Path(image_dir)
image_paths = list(image_dir.glob("*.png")) + list(image_dir.glob("*.jpg"))
# 4. 构建索引
self._build_indices(image_paths, image_dir)
# 5. 加载 Reranker
if use_reranker:
self.reranker = Qwen3VLNodePostprocessor()
print("✅ 检索引擎就绪")
def _build_indices(self, image_paths: List[Path], image_dir: Path):
"""构建三路混合索引(手动方法)"""
print(" 构建三路索引...")
# ============================================================
# 路径1: Qwen-VL 图片索引(手动构建)
# ============================================================
print(" [1/3] 构建图片向量索引...")
self._build_image_index(image_paths)
# ============================================================
# 路径2: Caption 索引(如果需要)
# ============================================================
if self.caption_cache:
print(" [2/3] 构建 Caption 索引...")
# 这里可以继续用手动方法,或者跳过
# 暂时跳过,因为图片索引已经包含了 caption 信息
pass
# ============================================================
# 路径3: BM25
# ============================================================
print(" [3/3] 构建 BM25 索引...")
nodes = []
for img_path in image_paths:
caption = self.caption_cache.get(img_path.stem, "")
text = f"{img_path.name} {caption}" if caption else img_path.name
node = TextNode(
text=text,
metadata={"file_name": img_path.name, "file_path": str(img_path)}
)
nodes.append(node)
self.bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=30
)
def _build_image_index(self, image_paths: List[Path]):
"""手动构建图片索引(避免 LlamaIndex 的字段冲突)"""
connections.connect(uri=MILVUS_URI)
collection_name = "qwen3_vl_image"
# 删除旧集合
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
# 创建集合
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=100),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=512),
FieldSchema(name="file_path", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="file_name", dtype=DataType.VARCHAR, max_length=200),
]
schema = CollectionSchema(fields, description="Qwen3-VL Image Index")
collection = Collection(collection_name, schema)
# 创建索引
index_params = {"metric_type": "IP", "index_type": "FLAT", "params": {}}
collection.create_index(field_name="embedding", index_params=index_params)
# 批量插入
ids, embeddings, file_paths, file_names = [], [], [], []
for i, img_path in enumerate(image_paths, 1):
print(f" 处理 [{i}/{len(image_paths)}]: {img_path.name}", end='\r')
emb = self.embed_adapter.get_image_embedding(str(img_path))
ids.append(f"img_{i}")
embeddings.append(emb)
file_paths.append(str(img_path))
file_names.append(img_path.name)
print() # 换行
collection.insert([ids, embeddings, file_paths, file_names])
collection.flush()
collection.load()
# 创建自定义检索器
self.qwen_retriever = DirectMilvusImageRetriever(
collection_name=collection_name,
embed_model=self.embed_adapter,
uri=MILVUS_URI,
similarity_top_k=30,
normalize_scores=True
)
def text_to_image_search(self, query: str, top_k: int = 5) -> List[Dict]:
"""文搜图: 三路召回 + RRF + Reranker"""
print(f"🔍 文搜图: {query}")
# 1. 图片向量召回
image_results = self.qwen_retriever.image_to_image_retrieve(query)
# 2. BM25 召回
bm25_results = self.bm25_retriever.retrieve(query) if self.bm25_retriever else []
# 3. RRF 融合
node_scores = defaultdict(float)
node_map = {}
all_results = [image_results, bm25_results]
for results in all_results:
for rank, result in enumerate(results, 1):
file_name = result.node.metadata.get("file_name", "")
rrf_score = 1.0 / (60 + rank)
node_scores[file_name] += rrf_score
if file_name not in node_map:
node_map[file_name] = result
sorted_items = sorted(node_scores.items(), key=lambda x: x[1], reverse=True)
fused_results = [node_map[fn] for fn, _ in sorted_items]
# 4. Reranker(如果启用)
if self.reranker:
from llama_index.core import QueryBundle
fused_results = self.reranker.postprocess_nodes(
fused_results[:top_k * 2],
QueryBundle(query_str=query)
)
return self._format_results(fused_results[:top_k])
def image_to_image_search(self, image_path: str, query: str = None, top_k: int = 5) -> List[Dict]:
"""图搜图"""
query_path = Path(image_path)
print(f"🖼️ 图搜图: {query_path.name}")
results = self.qwen_retriever.image_to_image_retrieve(str(query_path))
# 过滤自身
results = [r for r in results if Path(r.node.metadata['file_path']).resolve() != query_path.resolve()]
# Reranker(如果有文本约束)
if query and self.reranker:
from llama_index.core import QueryBundle
results = self.reranker.postprocess_nodes(
results[:top_k * 2],
QueryBundle(query_str=query)
)
return self._format_results(results[:top_k])
def _format_results(self, results) -> List[Dict]:
return [
{
"rank": i,
"file_name": res.node.metadata.get("file_name"),
"image_path": res.node.metadata.get("file_path"),
"score": res.score
}
for i, res in enumerate(results, 1)
]
# 使用
retrieval_engine = Qwen3VLRetrievalEngine()
retrieval_engine.initialize(image_dir="images")
from langchain.tools import tool
from typing import Optional
from pathlib import Path
import threading
# ============================================================
# 全局单例:检索引擎(只初始化一次)
# ============================================================
class SingletonRetrievalEngine:
"""单例模式的检索引擎"""
_instance = None
_lock = threading.Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._initialized = False
return cls._instance
def initialize_once(self, image_dir: str):
"""确保只初始化一次"""
if self._initialized:
print("⚡ 检索引擎已初始化,跳过")
return
print("🔧 首次初始化检索引擎...")
self.engine = Qwen3VLRetrievalEngine()
self.engine.initialize(image_dir=image_dir, use_reranker=True)
self._initialized = True
print("✅ 初始化完成")
def get_engine(self):
"""获取检索引擎实例"""
if not self._initialized:
raise RuntimeError("检索引擎未初始化,请先调用 initialize_once()")
return self.engine
# 全局初始化(在工具定义前执行一次)
_retrieval_singleton = SingletonRetrievalEngine()
_retrieval_singleton.initialize_once(image_dir="images")
定义多模态检索Tool工具 链接到标题
from langchain.tools import tool
from typing import Optional, List
from pathlib import Path
import json
@tool
def search_images(
query: Optional[str] = None,
image_path: Optional[str] = None,
top_k: int = 5,
filter_type: Optional[str] = None, # ⭐ 新增:过滤文件类型
min_score: Optional[float] = None # ⭐ 新增:最低分数阈值
) -> str:
"""
多模态图像搜索工具(增强版)。
支持三种模式:
1. 文搜图: 只提供 query(如 "找架构图")
2. 图搜图: 只提供 image_path(找相似图片)
3. 图文混合: 同时提供(先视觉召回,再文本精排)
Args:
query: 可选,文本查询描述
image_path: 可选,参考图片路径
top_k: 返回结果数量,默认5
filter_type: 可选,文件类型过滤(如 "png", "jpg")
min_score: 可选,最低相似度阈值(0-1)
Returns:
JSON 格式的检索结果,包含:
- mode: 检索模式
- num_results: 结果数量
- results: 结果列表(包含文件名、路径、分数)
Examples:
- search_images(query="房屋架构图", top_k=3)
- search_images(image_path="/path/to/ref.png")
- search_images(query="现代风格", image_path="/path/to/ref.png")
"""
try:
# 参数验证
if not query and not image_path:
return json.dumps({
"error": "必须提供 query 或 image_path 至少一个参数"
}, ensure_ascii=False)
# 获取引擎
engine = _retrieval_singleton.get_engine()
# 执行检索
if image_path and Path(image_path).exists():
results = engine.image_to_image_search(
image_path,
query=query,
top_k=top_k * 2 # 先多召回,后过滤
)
mode = "图文混合" if query else "图搜图"
elif query:
results = engine.text_to_image_search(query, top_k=top_k * 2)
mode = "文搜图"
else:
return json.dumps({
"error": f"图片路径不存在: {image_path}"
}, ensure_ascii=False)
# ⭐ 应用过滤条件
if filter_type:
results = [
r for r in results
if r["file_name"].lower().endswith(f".{filter_type.lower()}")
]
if min_score is not None:
results = [r for r in results if r["score"] >= min_score]
# 截取 top_k
results = results[:top_k]
if not results:
return json.dumps({
"message": "未找到符合条件的图片"
}, ensure_ascii=False)
# 返回结果
output = {
"mode": mode,
"query": query,
"reference_image": image_path,
"filters": {
"type": filter_type,
"min_score": min_score
},
"num_results": len(results),
"results": results
}
return json.dumps(output, ensure_ascii=False, indent=2)
except Exception as e:
import traceback
return json.dumps({
"error": str(e),
"traceback": traceback.format_exc()
}, ensure_ascii=False)
# ============================================================
# 使用示例
# ============================================================
# 测试 1: 文搜图
print("测试 1: 文搜图")
result = search_images.invoke({"query": "架构图", "top_k": 3})
print(result)
# 测试 2: 图搜图
print("\n测试 2: 图搜图")
image_path = "/Users/mac/大模型资料/多模态RAG/七大场景llama-Index进阶实战/测试文档&图片/test_images/20251216110347_90_50.png"
result = search_images.invoke({"image_path": image_path, "top_k": 3})
print(result)
# 测试 3: 图文混合
print("\n测试 3: 图文混合")
result = search_images.invoke({
"query": "现代风格的架构图",
"image_path": image_path,
"top_k": 3
})
print(result)
设计亮点:
单一入口,内部路由:Agent不需要纠结用哪个工具,
search_images内部自动判断图文混合检索:同时提供
image_path和query时,先用图片召回,再用文本精排返回格式化字符串:Agent能理解的文本格式(而非Python对象)
5.2.2 describe_image工具定义 链接到标题
第二个工具:让Agent能够理解图片内容。
import base64
from langchain_core.messages import HumanMessage
from pathlib import Path
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
# 初始化LLM(全局,避免重复创建)
llm_vision = ChatOpenAI(model="gpt-4o", temperature=0)
@tool
def describe_image(image_path: str) -> str:
"""使用 GPT-4o 描述图片内容"""
if not Path(image_path).exists():
return "❌ 图片不存在"
try:
# 读取图片并编码
with open(image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
msg = HumanMessage(content=[
{
"type": "text",
"text": "请详细描述这张图片的内容,包括主要物体、场景和显著特征。"
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{encoded_string}"}
}
])
response = llm_vision.invoke([msg])
return f"📸 图片描述 ({Path(image_path).name}):\n{response.content}"
except Exception as e:
return f"❌ 描述失败: {str(e)}"
# 测试工具
desc = describe_image.invoke({"image_path": "images/20251216110324_89_50.png"})
print(desc)
应用场景:
用户:“先帮我看看这张图里是什么,然后找相似的”
Agent会先调用
describe_image理解图片,再调用search_images检索
5.2.3 工具列表与Agent创建 链接到标题
将两个工具组合并创建Agent:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import InMemorySaver
# 定义工具列表
tools = [search_images, describe_image]
# 定义System Prompt(Agent的"宪法")
system_prompt = """你是一个智能多模态检索助手。
工具使用策略:
1. 用户想找图片 -> 使用 search_images
2. 用户想理解图片 -> 使用 describe_image
3. 用户提供参考图片 + 文本描述 -> search_images同时传入两个参数
回复要求:
- 必须列出找到的图片路径
- 解释为什么这张图片符合要求
- 简洁专业
"""
# 初始化LLM(全局,避免每次创建Agent时重复初始化)
llm_agent = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_agent(
model=llm_agent,
tools=tools,
system_prompt=system_prompt,
checkpointer=InMemorySaver() # ⭐ 记忆能力
)
print("✅ Agent创建完成")
关键参数:
system_prompt:定义Agent的行为准则,防止幻觉checkpointer=InMemorySaver():赋予Agent记忆力,支持多轮对话
5.3 Agent构建与ReAct循环 链接到标题
现在Agent已经创建好,我们来理解它的工作原理——ReAct(Reasoning + Acting)循环。
5.3.1 ReAct循环可视化 链接到标题
当用户发送一个查询时,Agent会进入一个循环:
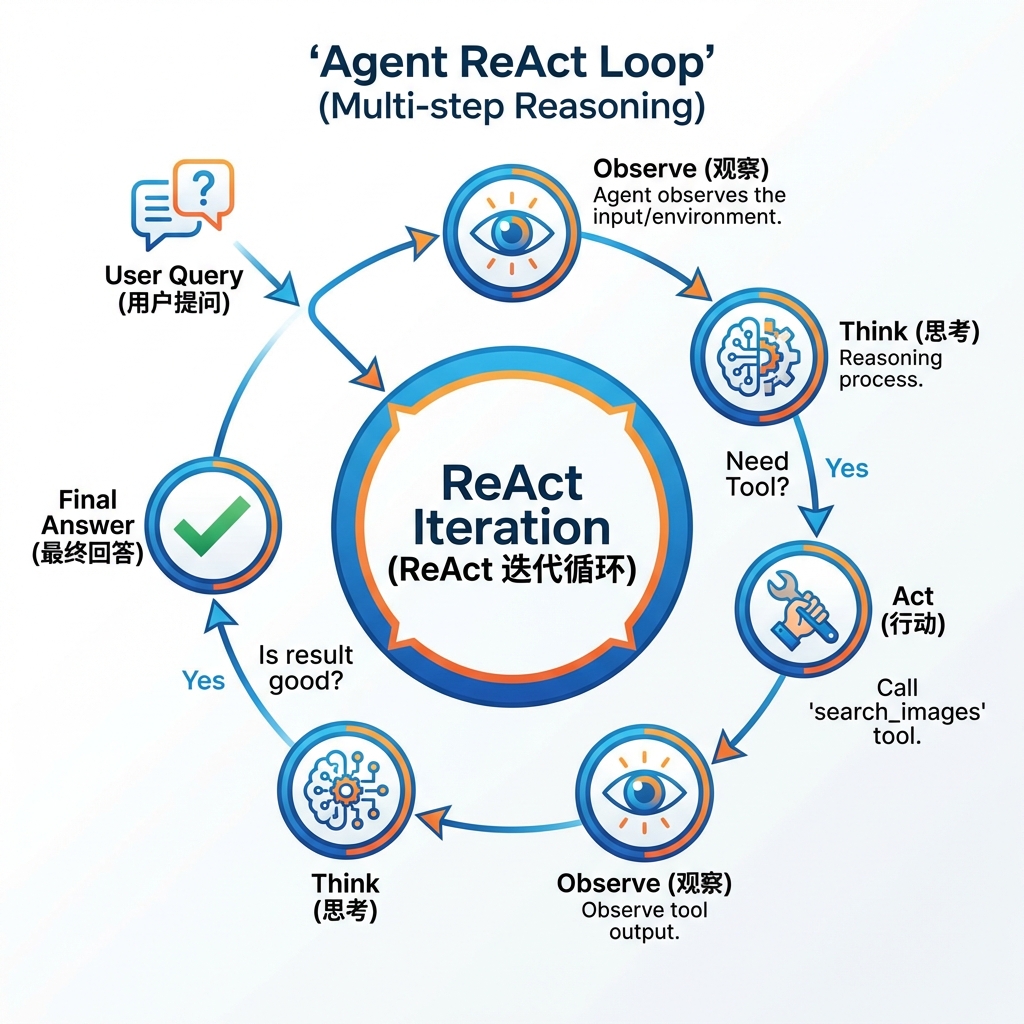
ReAct三步骤:
Observe(观察):用户说了什么?上下文有什么?工具返回了什么?
Think(思考):我还缺什么信息?该用哪个工具?参数怎么设置?
Act(行动):调用工具或返回答案
5.3.2 实际运行日志解析 链接到标题
让我们看一个真实的Agent执行过程:
# 执行Agent
config = {"configurable": {"thread_id": "session_1"}}
for event in agent.stream(
{"messages": [{"role": "user", "content": "找一张架构图"}]},
config=config,
stream_mode="values"
):
if "messages" in event:
msg = event["messages"][-1]
# 工具调用
if hasattr(msg, 'tool_calls') and msg.tool_calls:
print(f"🤖 [Agent决策]: 调用工具 → {msg.tool_calls[0]['name']}")
print(f" 参数: {msg.tool_calls[0]['args']}")
# 最终回复
elif msg.type == "ai":
print(f"\n🤖: {msg.content}")
关键观察:
Agent理解了"找架构图"的意图,自动选择了
search_images工具自动设置了正确的参数(
query='架构图',image_path=None)不仅返回结果,还主动解释并追问(体现智能性)
5.4 图文混合检索实战 链接到标题
现在演示Agentic RAG的核心能力——图文混合检索。
5.4.1 视觉召回 + 文本精排 链接到标题
用户需求:“找一张类似这个背包的图,但要红色的”
# 用户输入(包含参考图片路径)
user_query = """
找一张类似这个背包的图,但要红色的。
参考图片:images/Image_rm5lrzrm5lrzrm5l.png
"""
# Agent执行
for event in agent.stream(
{"messages": [{"role": "user", "content": user_query}]},
config=config,
stream_mode="values"
):
if "messages" in event:
msg = event["messages"][-1]
if msg.type == "ai" and msg.content:
print(f"🤖: {msg.content}")
技术解析:
Agent智能解析:从自然语言中提取了两个关键信息——参考图片路径和文本约束(“红色”)
工具内部路由:
search_images检测到同时提供了image_path和query,自动触发图文混合模式双重过滤:先用图片向量召回相似背包,再用Reranker根据"红色"精排
小结 链接到标题
在智能体篇中,我们完成了从"检索系统"到"智能助手"的终极跨越:
智能体篇核心成果
| 步骤 | 核心能力 | 技术亮点 |
|---|---|---|
| 5.1 | 传统RAG vs Agentic RAG对比 | 双层架构设计(大脑+手脚) |
| 5.2 | LangChain工具封装 | search_images、describe_image、单一入口路由 |
| 5.3 | Agent构建与ReAct循环 | create_agent、InMemorySaver记忆 |
| 5.4 | 图文混合检索实战 | 视觉召回+文本精排、多步任务拆解 |
| 5.5 | 多轮对话演示 | 上下文记忆、交互式对话 |
关键认知回顾:
Agent不是万能的:适合复杂、模糊、多步任务,但简单查询用传统RAG更快
工具封装的艺术:单一入口+内部路由,降低Agent决策负担
ReAct循环的价值:Observe-Think-Act,让AI真正"会思考"
记忆的重要性:
InMemorySaver+thread_id,赋予Agent人类般的对话能力
生产环境考虑:
延迟:ReAct循环意味着多次LLM调用,延迟约1-3秒(vs 传统RAG的300ms)
成本:每次查询约消耗0.01-0.05美元(GPT-4o API调用)
可靠性:需要处理Agent幻觉、工具调用失败等边界情况
场景化选型 链接到标题
技术选型从来不是"哪个最强就用哪个",而是"哪个最适合当前场景"。本章将结合企业实际需求,给出具体的选型建议,并介绍我们在后续实战中将采用的"黄金架构"。
技术选型决策树 链接到标题
面对三种技术方案,如何快速决策?我们可以沿着以下决策路径进行判断:
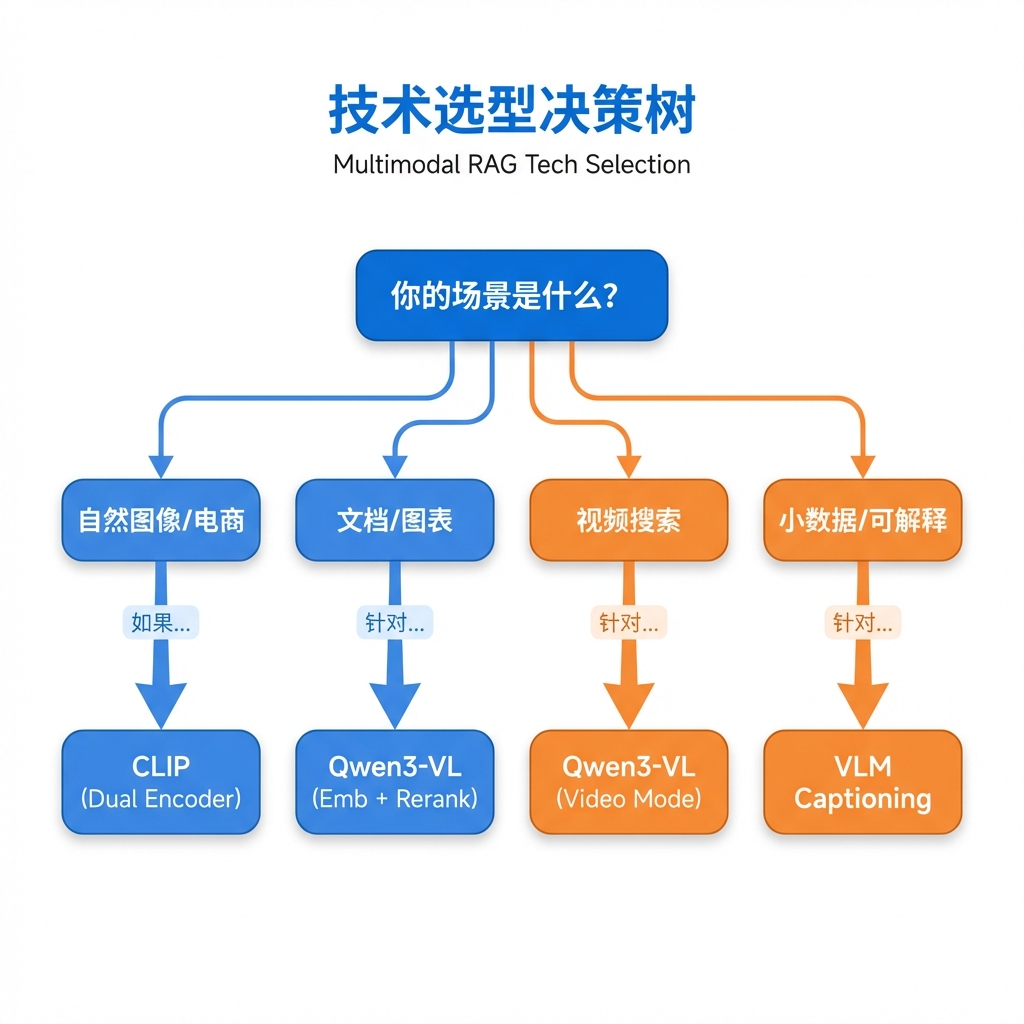
在多模态检索场景中,技术选型需要根据具体业务场景做出精准决策。基于本课件的完整技术路径实践,我们总结出以下四大场景与对应的最优方案:
自然图像/电商场景 → CLIP 双编码器 对于电商"以图搜货"、社交媒体图片匹配等自然图像场景,CLIP 是首选方案。其优势在于:编码速度极快(~10ms/张)、模型完全开源免费、512 维向量存储成本低。但需注意其局限性:中文语义理解有限、对细粒度图文对应关系把握不足,适合对精度要求不高、强调速度与成本的海量图库粗筛场景。
文档/图表场景 → Qwen3-VL (Embedding + Reranker) 对于企业文档库、技术图表、建筑平面图等结构化视觉内容,Qwen3-VL 黄金架构是当前最优解。其核心是双阶段设计:先用 Qwen3-VL-Embedding 快速召回候选(支持三路融合:视觉向量 + 文本向量 + BM25 关键词),再用 Qwen3-VL-Reranker 精排 Top-K 结果。根据 MMEB-v2 基准测试,该方案在视觉文档任务上达到 86.3 分,且存储成本仅为 ColPali 的 1/30,实现了性能与成本的双重突破。
视频搜索场景 → Qwen3-VL (Video Mode) 对于安防监控、视频内容检索等场景,Qwen3-VL 的视频模式支持直接对视频帧进行编码和检索,无需预先切帧处理,显著降低工程复杂度。
小数据/可解释场景 → VLM Captioning 当数据量较小(<1000 张)且需要结果可解释性时,VLM 描述生成方案更具优势。通过 GPT-4o 等 VLM 为每张图片生成自然语言描述,再用传统文本检索(如 BM25 + 向量混合),可实现高可解释性检索——用户可直接看到匹配的描述文本,便于结果解释和调试。
最终建议:对于大多数企业级多模态 RAG 应用,推荐采用 Qwen3-VL + 三路召回 + Reranker 精排的黄金架构,在保证高精度的同时兼顾成本与可扩展性,在绝大多数场景下都能提供最佳的性价比。