第一阶段、LangChain 框架介绍 链接到标题
LangChain 是一个构建 LLM 应用的框架,目标是把 LLM 与外部工具、数据源和复杂工作流连接起来 —— 支持从简单的 prompt 封装到复杂的 Agent(能够调用工具、做决策、执行多步任务)。它不仅仅是对LLM API的封装,而是提供了一套完整的工具和架构,让开发者能够更轻松地构建上下文感知和具备推理能力的AI应用。LangChain 1.0 版本把“Agent 的稳定化、结构化输出、可观测性与生产化”作为核心改进目标。
1.1 用 LangChain 能做什么? 链接到标题
构建 Retrieval-Augmented Generation(RAG)问答系统
把 LLM 当作“Agent”去调用外部 API(搜索、数据库、文件系统)并返回任务结果
组织 prompt → 模型 → 后处理 的可复用流水线(Chains)
实现多轮对话带记忆(Memory)与长会话管理
在生产中管理可观测性与评估(配合 LangSmith/LangGraph)
核心价值:让开发者用10行代码完成原本需要1000行代码的AI应用,并且自动获得状态持久化、人工干预、并发控制等企业级能力。
1.0 的架构风格可以用一句话概括:以“统一智能体抽象 + 标准化内容表示 + 可插拔治理中间件”为设计骨干,以 LangGraph 为底座运行时,实现“开发简单性”与“生产可控性”的兼顾。它一方面通过 create_agent 提供低门槛的构建入口,另一方面保留足够的钩子点与下探能力,以满足复杂工作流与高标准治理的需求。
你要做什么AI应用?
│
├─ 只想简单调用模型聊天(翻译/问答)
│ └─> 直接用OpenAI SDK(更轻量,无需LangChain)
│
├─ 需要联网查资料、执行代码、操作数据库
│ └─> 用LangChain 1.0(快速搭建Agent)
│ └─> 参考:客服机器人、数据分析助手
│
├─ 流程很复杂(多人审批/定时任务/状态分支)
│ └─> 用LangGraph 1.0(精确控制每个步骤)
│ └─> 参考:自动化工作流、ERP系统集成
│
└─ 不确定,先试试想法
└─> 用LangChain 1.0快速验证,后期可无缝迁移到LangGraph
1.2 LangChain 生态概览 链接到标题
模型层(Models) 链接到标题
LangChain 1.0 的统一模型抽象层,为所有模型提供标准化调用,覆盖文本、多模态、Embedding、Rerank 等多类型模型,实现跨供应商一致体验
统一抽象:init_chat_model() 适配20+模型厂商
异步/流式/批处理:ainvoke(),stream(), batch()
执行方式:完全兼容 LCEL 与 LangGraph
扩展能力:with_structured_output()、Tool Calling、多模态 Content Blocks
工具层(Tools) 链接到标题
工具系统提供统一 Tool 抽象,支持所有主流模型的 Tool Calling,深度集成 LangGraph,构建可执行 agent 环境的关键能力层
内置工具:搜索、计算、代码执行等100+工具
自定义工具:@tool装饰器 / BaseTool / ToolNode
工具包:Toolkit(如GitHub、Slack集成)
记忆层(Memory) 链接到标题
记忆层提供统一 State 管理、对话记录、长期检索、多模态 Memory 等能力,支持持久化与复杂工作流状态流转
短期记忆:消息历史自动管理
长期记忆:向量数据库存储(Chroma, Pinecone)
存储接口:Store(跨会话持久化)
Agent层(Agents) 链接到标题
LangChain 1.0 Agents系统实现从碎片化到标准化升级,以create_agent为核心接口,基于LangGraph构建统一Agent抽象,10行代码即可创建基础Agent,封装"模型调用→工具选择→执行→结束"闭环流程
核心API:create_agent()
执行引擎:LangGraph Runtime(自动持久化)
中间件:Middleware(HITL、压缩、路由)
工作流层(Workflows) 链接到标题
Workflows 体系实现从 线性链式(Chain)到图结构(Graph) 的范式转移,以 StateGraph 为核心画布,将业务逻辑解耦为 “节点(Node)+ 边(Edge)+ 状态(State)",原生支持循环(Loop)与条件分支,完美适配复杂任务编排、容错重试及长会话保持。
简单链:Chain(快速串联)
复杂图:LangGraph(条件分支、循环)
模板库:LangChain Hub(共享Agent模板)
调试监控层(Debugging) 链接到标题
LangChain 1.0 调试监控层实现了从 日志黑盒到全链路可观测性(Observability) 的质变,深度集成 LangSmith 平台,自动捕获链(Chain)与图(Graph)的每一步骤状态、Token 消耗及延迟,支持"Trace → Playground"一键回放调试,彻底解决复杂 Agent 逻辑难以排查的痛点。
本地日志:verbose=True
云端平台:LangSmith(可视化链路追踪)
评估工具:LangChain Evaluate(效果评估)
其他关键组件 (LangGraph & LangServe) 链接到标题
langgraph: 这是一个底层的Agent 调度框架 (Agent Runtime),是一个相对“低级”(Low-level)的编排框架,它专注于解决复杂的“控制流”问题,用于构建健壮且有状态的多角色 LLM 应用程序。LangChain 1.0 中的新 Agents (通过 create_agent()) 就是建立在 LangGraph 之上的。
langserve: 用于将任何 LangChain chain 或 agent 部署为 REST API 的包,方便快速将应用投入生产环境。
1.3 LangChain 1.0 底层运行架构 链接到标题
# 简化版架构示意图
┌─────────────────────────────────────────┐
│ LangChain 1.0 应用层 │
│ (create_agent, 工具和中间件) │
└──────────────────┬──────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ LangGraph 编排层 │
│ (StateGraph, Nodes, Edges, Checkpoints)│
└──────────────────┬──────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ LCEL 运行时层 │
│ (Runnable接口, |运算符, 流式/批处理) │
└──────────────────┬──────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 大语言模型API(OpenAI/DeepSeek) │
└─────────────────────────────────────────┘
LCEL:提供Runnable接口(invoke, stream, batch)和组合原语(|运算符),是无状态的函数式编排,构建“流水线(pipeline)”的工具
LangGraph:在LCEL基础上增加状态管理(State)、循环控制(Cycles)、持久化(Checkpoints),是有状态的图结构编排,构建“流程图(workflow/graph)”的工具
1.4 Runnable底层执行引擎 链接到标题
Runnable 是 LangChain 1.0 的“统一接口标准”,任何可以运行的组件——模型、Prompt、工具、解析器、Memory、Graph 节点——在 1.0 中都被抽象为 Runnable。
Runnable 使所有 LangChain 组件能够以统一接口组合、执行、链式调用,并支撑 LCEL(LangChain Expression Language)的整个运行语义,支撑可组合、可并行、可路由的链式执行,是 LangChain 1.0 的核心底座之一。
核心思想:Runnable 抽象与可组合链(Composable Chains)
LangChain 1.0 将所有链式元素统一为 Runnable(执行模型):
LLM(OpenAI、vLLM、Ollama……)
Prompt
Parser
Retriever
Tool
Agent
自定义函数
所有对象都可以 .invoke()、.batch()、.stream()、.astream_events(),这实现了真正的统一调用接口。
工程价值:
链路清晰。
任意组件之间可无缝组合。
所有执行方式(同步 / 异步 / 批处理 / 事件流)统一。
这是 LangChain 1.0 最具革命性的改变,使其成为“模型调用管道”的事实标准。
Prompt Runnable 链接到标题
from langchain_core.prompts import ChatPromptTemplate
# 1. 定义一个 Prompt (Runnable)
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
# Prompt 也可以调用 invoke/stream
print(prompt.invoke({"topic": "ice cream"}))
Tool Runnable 链接到标题
from langchain_core.tools import tool
# 2. 定义一个简单的 Tool (Runnable)
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
# Tool 也可以调用 invoke/batch
print(multiply.invoke({"a": 2, "b": 3}))
# Tool 也可以调用 batch (自动并行)
print(multiply.batch([{"a": 2, "b": 3}, {"a": 4, "b": 5}]))
# 输出: [6, 20]
Runnable = LCEL 的语法基础 链接到标题
LCEL(| 运算符)是由 Runnable 定义的组合语义:
chain = prompt | model | StrOutputParser()
output = chain.invoke({"topic": "LangChain"})
这三者本质都是 Runnable:
PromptTemplate → Runnable
Model → Runnable
Parser → Runnable
任何 LCEL chain = 多个 Runnable 的组合。
| 技术 | 在 LangChain 1.0 的角色 |
|---|---|
| LangChain | 构建 LLM + prompt + tool + outputparser 的组件生态 |
| LangGraph | 构建 Agent / 多步工作流 / 状态机的框架 |
| LCEL / Runnable | LangChain 的底层执行引擎,依然核心 |
第二阶段、LangChain 模块化管理的定位与描述 链接到标题
LangChain 把“核心抽象”与“具体实现/第三方集成/历史实现”拆分成多个包,以实现更清晰的 API 边界、减小核心包体积、并把社区贡献与厂商集成模块化管理。主要目标是:核心更稳定、可维护;集成可按需安装。
2.1 LangChain 1.0 核心依赖包及作用 链接到标题
| 依赖包名称 | 核心作用 | 详细功能介绍 |
|---|---|---|
| langchain-core | 核心抽象层和 LCEL | 定义所有组件(如模型、消息、提示词模板、工具、运行环境)的标准接口和基本抽象。它包含了 LangChain 表达式语言 (LCEL),这是构建链式应用的基础。这是一个轻量级、不含第三方集成的基石包。 |
| langchain | 应用认知架构(主包) | 包含构建 LLM 应用的通用高阶逻辑,如 Agents (如新的 create_agent() 函数)、Chains 和通用的检索策略 (Retrieval Strategies)。它建立在 langchain-core 之上,是用于组合核心组件的“胶水”层。 |
| langchain-community | 社区第三方集成 | 包含由 LangChain 社区维护的非核心或不太流行的第三方集成,例如:大部分的文档加载器 (Document Loaders)、向量存储 (Vector Stores)、不太流行的 LLM/Chat Model 集成等。为了保持包的轻量,所有依赖项都是可选的。 |
| langchain-openai / langchain-[厂商名称] | 特定厂商深度集成 | 针对 关键合作伙伴 的集成包(如 langchain-openai, langchain-anthropic)。它们被单独分离出来,以提供更好的支持、可靠性和更轻量级的依赖。它们只依赖于 langchain-core。 |
| langchain-classic | 旧版本兼容 | 包含 LangChain v0.x 版本中的已弃用 (deprecated) 或旧版功能,如旧的 LLMChain、旧版 Retrievers、Indexing API 和 Hub 模块。它的主要作用是为用户提供一个平稳的迁移期,确保旧代码在升级到 v1.0 后仍能运行。 |
1. langchain-core 链接到标题
包含 核心抽象与接口:LLM/ChatModel 抽象、Prompt 抽象、Chain/Agent 的基类、schema、消息格式等。
不包含具体厂商的实现(例如没有 OpenAI client 的封装),而是定义“合同(interfaces)”,其他包在此之上实现具体功能。
这是构建 LangChain 应用生态的最小公共底座。
# 安装:pip install langchain
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"为生产{product}的公司起一个好名字?"
)
formatted_prompt = prompt_template.format(product="智能水杯")
response = model.invoke(formatted_prompt)
2. langchain 主包 链接到标题
对外的主入口包:把
langchain-core的核心抽象与“常用实现”组合在一起,便于快速上手。在 v1.0 中,
langchain的命名空间被 显著精简,只保留构建 agent 的关键 API(更轻、更专注)。官方建议大多数用户直接使用此主包以获得“开箱即用”的体验。
| 模块 | 核心内容 | 来源说明 |
|---|---|---|
langchain.agents | create_agent, AgentState | 智能体创建核心 |
langchain.messages | AIMessage, HumanMessage, trim_messages | 从langchain-core重新导出 |
langchain.tools | @tool, BaseTool | 从langchain-core重新导出 |
langchain.chat_models | init_chat_model, BaseChatModel | 统一模型初始化 |
langchain.embeddings | init_embeddings | 嵌入模型管理 |
from langchain.agents import create_agent
# 创建智能体
agent_executor = create_agent(llm, tools)
result = agent.invoke({
"messages": [{
"role": "user",
"content": "会议决定:张三需要在下周一前完成项目报告"
}]
})
3. langchain-community 第三方集成库 链接到标题
langchain-community 作为 LangChain 1.0 的“功能扩展层”,通过社区贡献的非官方集成组件显著扩展了主包的功能边界,其核心价值体现在工具类组件与平台集成两大维度。工具类组件覆盖文档处理全流程,包括 DirectoryLoader 文档加载器(支持 PDF、文本等多格式文件批量导入)、RecursiveCharacterTextSplitter 文本分割器(按语义边界将文档切分为检索友好的 Chunk)、PGVector 向量存储(PostgreSQL 生态的向量数据库适配)及 HuggingFaceEmbeddings 嵌入模型(本地部署模型的向量化能力),这些组件共同构成了 RAG 应用的技术基础。平台集成方面,支持与 DeepSeek、阿里云通义千问等模型的对接,例如通过 langchain_community.chat_models.ChatTongyi 类初始化通义千问模型,或利用 Ollama 类调用本地部署的 DeepSeek-R1 模型。
- 收集并维护 社区/第三方贡献的集成(例如某些云厂商、开源向量库、特殊工具适配器等)。这些集成实现了
langchain-core定义的接口,但不属于主包维护范畴。官方会把这些放到langchain-community仓库/包,便于社区共同维护。
包含内容:
数据库:MySQL, PostgreSQL, MongoDB, Neo4j等连接器
存储服务:AWS S3, 阿里云OSS, Google Cloud Storage
工具集成:Slack, Notion, GitHub, ArXiv, YouTube等API
向量数据库:Chroma, Pinecone, Qdrant, Milvus等
文档加载器:PDF, CSV, HTML, Markdown解析器
特点:
质量参差不齐:社区贡献,需自行验证稳定性
更新滞后:依赖社区维护,响应速度慢于官方包
功能丰富:覆盖95%的第三方服务集成需求
# 安装:pip install langchain-community
from langchain_community.document_loaders import NotionDBLoader
# 从Notion数据库加载文档
loader = NotionDBLoader(
integration_token="secret_...",
database_id="your-db-id"
)
documents = loader.load()
print(f"加载了{len(documents)}条文档")
4. langchain-openai(厂商/提供者集成包) 链接到标题
厂商特定集成包(如 langchain-openai、langchain-anthropic、langchain-google 等)通过封装 API 细节,为开发者提供“零适配成本”的模型对接方案,其核心价值在于简化特定 API 对接流程,使开发者能够直接使用厂商特有功能。以 langchain-openai 为例,其关键组件包括模型客户端、工具调用适配和多模型支持三大模块。
此外,该类还支持通过配置 openai_api_base 和 openai_api_key 参数对接兼容 OpenAI API 格式的第三方模型,如 DeepSeek 模型
专门负责把 OpenAI 的 SDK 与 LangChain 抽象连接起来:提供
ChatOpenAI、OpenAIEmbeddings、OpenAI等类的实现。这类包通常是 “按厂商拆分”:
langchain-openai、langchain-azure、langchain-anthropic、langchain-deepseek等。官方深度集成特定LLM提供商,更新频繁,功能最全.
#!pip install langchain-openai
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
主流厂商包列表:
langchain-openai:OpenAI, Azure OpenAIlangchain-anthropic:Claude系列langchain-google:Gemini, Vertex AIlangchain-deepseek:DeepSeek模型langchain-ollama:本地Ollama部署
与langchain-community的区别:
| 维度 | langchain-openai | langchain-community中的OpenAI |
|---|---|---|
| 维护方 | OpenAI官方 + LangChain团队 | 社区维护 |
| 更新频率 | 即时跟进API更新 | 延迟数周 |
| 功能完整性 | 支持所有新特性(如音频、视觉) | 仅基础功能 |
| 生产可用性 | ✅ 强烈推荐 | ⚠️ 谨慎使用 |
为什么要单独拆出来?
让
langchain主包保持轻量(不强制安装所有厂商 SDK);用户按需安装对应厂商,例如你只用 OpenAI,就只装
langchain-openai。
最佳实践:
生产环境务必使用厂商包:享受最新功能
开发环境可用community:快速验证想法
多厂商切换用
init_chat_model:业务代码无需改动
5. langchain-classic 链接到标题
兼容包 / 迁移包:把 LangChain v0.x 中的“老 API / legacy 功能”搬到单独包里,以便 v1.0 保持精简,但仍给用户向后兼容的迁移通道。
包含如:老的 Chain 实现、旧版 retrievers、索引 API、hub 模块等被标记为“legacy”的功能。
旧版
AgentExecutorLegacy Chains(
LLMChain,SequentialChain等)
#!pip intsall langchain-classic
from langchain_classic.chat_models import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
res = model.invoke("请介绍一下你自己")
第三阶段、核心概念与组件 链接到标题
环境依赖:
LangChain 1.0+
Python 3.10+ (官方推荐)
我这里使用的是python 3.11版本
!python --version
!pip list | grep langchain
3.1 LLM / ChatModel 大模型接口 链接到标题
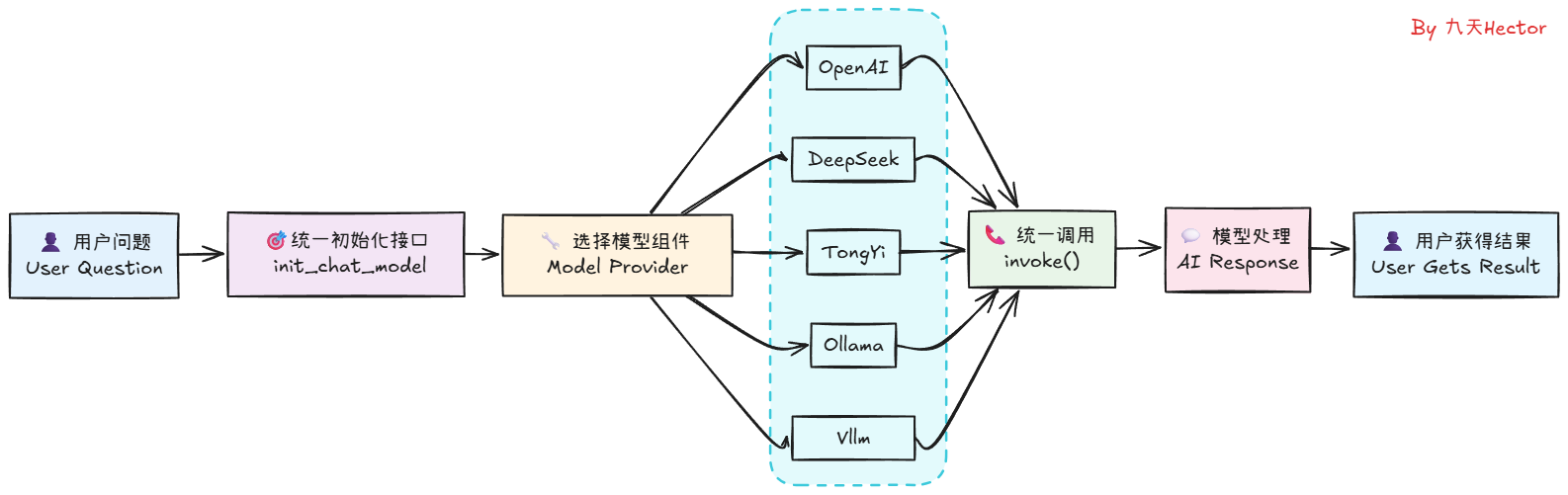
LangChain区分两种模型类型:
LLM:传统的文本进-文本出模型
ChatModel:基于消息的对话模型,更适合构建聊天机器人
封装具体的 LLM 提供者(OpenAI、Anthropic、local LLM),统一调用接口(sync/async、streaming)。
学习要点:如何配置 provider、温控、并发与 retry 策略。
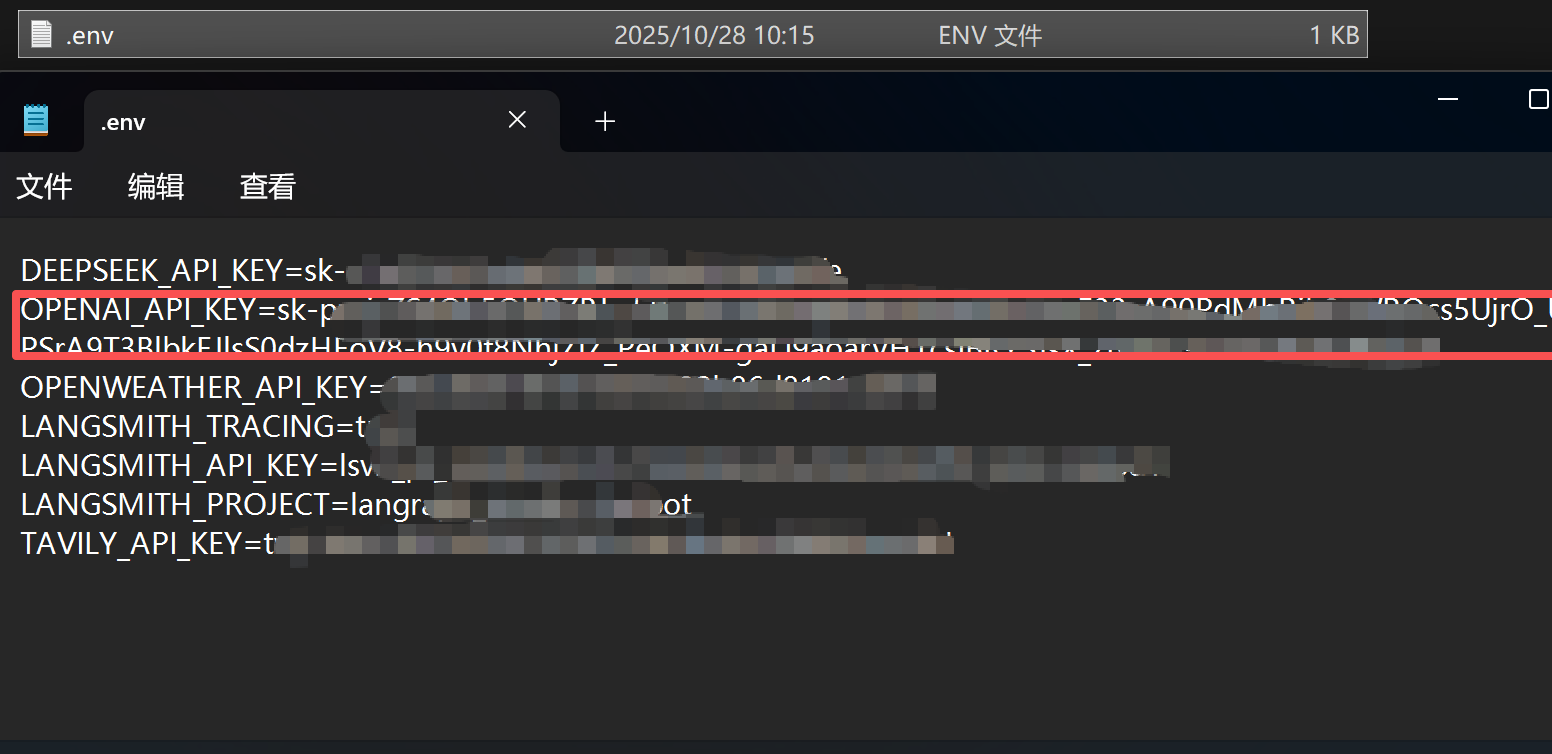
# 1 导入 os 与 dotenv
import os
from dotenv import load_dotenv
# 2 加载 .env 环境变量
load_dotenv(override=True)
# 3 读取密钥与地址
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DeepSeek_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 4 可选:打印密钥
# print(DeepSeek_API_KEY) # 可以通过打印查看
1. DeepSeek 链接到标题
# 1 导入 OpenAI 客户端
from openai import OpenAI
# 2 初始化 DeepSeek API 客户端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")
# 3 创建对话消息并发起请求
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"},
{"role": "user", "content": "你好,请你介绍一下你自己。"},
],
)
# 4 打印模型最终的响应结果
print(response.choices[0].message.content)
#!pip install langchain-deepseek
# 1 导入 ChatDeepSeek
from langchain_deepseek import ChatDeepSeek
# 2 初始化模型参数
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=512, # 最大生成token数
timeout=30, # 超时时间,单位秒
base_url=DeepSeek_BASE_URL # 默认为https://api.deepseek.com
)
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
# 5 输出结果
print(result.content)
2. DashScope 链接到标题
阿里云百炼API获取方式也非常简单,只需注册阿里云账号,然后前往我的API页面:https://bailian.console.aliyun.com/?tab=model#/api-key 进行充值和注册即可:
#!pip install dashscope
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi() # 默认qwen-turbo模型
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
3. OpenAI 链接到标题
# 1 导入 OpenAI
from langchain_openai import OpenAI
# 2 初始化模型
llm = OpenAI(model="gpt-4o-mini")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = llm.invoke(question)
# 5 打印结果
print(result)
# 1 导入 ChatOpenAI
from langchain_openai import ChatOpenAI
# 2 初始化模型
model = ChatOpenAI(model="gpt-4o-mini")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
# 5 打印内容
print(result.content)
4. Ollama 链接到标题
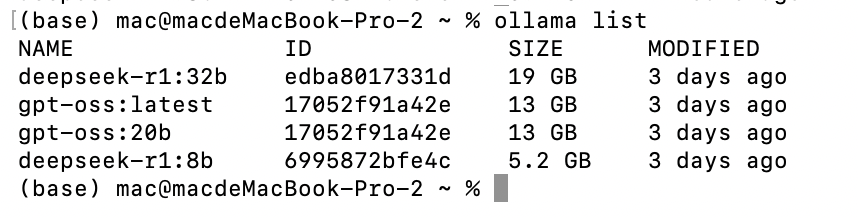
#!pip install langchain-ollama
# 1 导入 OllamaLLM
from langchain_ollama import OllamaLLM
# 2 初始化本地模型
llm = OllamaLLM(model="deepseek-r1:8b")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = llm.invoke(question)
# 5 打印结果
print(result)
# 1 导入 ChatOllama
from langchain_ollama import ChatOllama
# 2 初始化本地聊天模型
model = ChatOllama(model="deepseek-r1:8b")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
# 5 打印内容
print(result.content)
5. Vllm 链接到标题
# 安装 vLLM(推荐用阿里云镜像加速)
#!pip install vllm -i https://mirrors.aliyun.com/pypi/simple/
# 连接本地vLLM服务
from langchain_openai import ChatOpenAI
# 连接到本地 vLLM 服务,配置长连接池,减少握手开销
model = ChatOpenAI(
model="qwen-32b-chat", # 指定使用的模型名称
base_url="http://localhost:8000/v1", # vLLM 的 OpenAI API 地址
api_key="EMPTY", # vLLM 不验证 key,可以随便写
max_retries=5, # 增加重试次数
timeout=120.0, # 超时时间设长
http_client={ # 自定义 HTTP 客户端
"limits": {
"max_connections": 100, # 最大连接数
"max_keepalive_connections": 20 # 最大保持活动连接数
}
}
)
6. init_chat_model() 链接到标题
# 使用init_chat_model初始化DeepSeek模型
from langchain.chat_models import init_chat_model
# 1. 初始化模型(自动识别供应商)
model = init_chat_model(
"deepseek-chat", # 指定DeepSeek的聊天模型
model_provider="deepseek", # 指定模型提供商为deepseek
)
# 一行代码切换模型,业务代码0改动
# model = init_chat_model("gpt-4o", model_provider="openai")
# model = init_chat_model("claude-3-5-sonnet", model_provider="anthropic")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
其中:
model代表具体模型名称(gpt-4o、claude-3-haiku、gemini-pro 等)model_provider代表模型来源(openai、anthropic、google)
| provider | 模型来源(厂商) | 默认使用的环境变量 |
|---|---|---|
openai | OpenAI(GPT-4.1, GPT-4o, o3-mini 等) | OPENAI_API_KEY |
anthropic | Anthropic(Claude 3 系列) | ANTHROPIC_API_KEY |
google | Google(Gemini 系列) | GOOGLE_API_KEY |
cohere | Cohere(Command 系列) | COHERE_API_KEY |
ollama | 本地模型(LLaMA、Qwen、Mistral 等) | 本地无需 API Key |
你可以让一个应用只换 provider,而不改逻辑:
RateLimit 模型速率限制器 链接到标题
# 1. 定义带速率限制的load_chat_model函数
from langchain.chat_models import init_chat_model
from langchain_core.rate_limiters import InMemoryRateLimiter
# 2. 配置速率限制器
rate_limiter = InMemoryRateLimiter(
requests_per_second=5, # 每秒最多5个请求
check_every_n_seconds=1.0 # 每1秒检查一次是否超过速率限制
)
# 3. 对模型调用进行封装,后续直接调用传参数就行
def load_chat_model(
model: str,
provider: str,
temperature: float = 0.7,
max_tokens: int | None = None,
base_url: str | None = None,
):
return init_chat_model(
model=model, # 模型名称
model_provider=provider, # 模型供应商
temperature=temperature, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=max_tokens, # 最大生成token数
base_url=base_url, # 专用于自定义 API Server 或代理
rate_limiter=rate_limiter # 自动限速
)
# 调用load_chat_model函数初始化gpt-4o-mini模型
model = load_chat_model(
model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
provider="openai", # 指定模型提供商为openai
)
res = model.invoke("请介绍一下你自己")
res
.with_retry()模型重试机制 链接到标题
使用重试机制:通过 .with_retry() 方法为模型调用添加指数退避重试策略,在遇到临时性故障(如速率限制错误)时自动重试
指数退避的等待时间:
1s → 2s → 4s → 8s → 16s → …
每次失败都指数增加等待时间,避免快速重复打爆 API。
抖动 = 在等待时间上随机增加/减少一点随机数
防止集群中的多个客户端在相同时间重复同时回退,造成更大拥堵
失败的请求不会同时发起,极大降低 API 或本地模型的压力。
# 为模型添加指数退避重试策略
model = model.with_retry(
stop_after_attempt=3, # 最多重试3次
wait_exponential_jitter=True # 指数退避 + 随机抖动
)
7. init_embeddings() 链接到标题
# 1. 使用init_embeddings初始化嵌入模型
from langchain.embeddings import init_embeddings
# 2. 初始化OpenAI的text-embedding-3-small嵌入模型
embedding = init_embeddings(model="text-embedding-3-small",provider="openai")
# 3. 将文本转换为向量表示
res = embedding.embed_query("Hello world")
# 4. 打印向量的前10个元素
print(res[:10])
# 定义load_embedding函数封装嵌入模型初始化逻辑
# 该函数用于根据指定的模型名称、提供商和可选的自定义API地址,快速初始化并返回一个嵌入模型实例
from langchain.embeddings import init_embeddings
def load_embedding(
model: str, # 模型名称
provider: str, # 模型提供商
base_url: str | None = None, # 自定义API服务器地址
):
# 调用init_embeddings完成嵌入模型的初始化
return init_embeddings(
model=model, # 模型名称
provider=provider, # 模型提供商
base_url=base_url # 自定义API服务器地址
)
# 加载指定的文本嵌入模型(text-embedding-3-small)并指定提供商为 openai
load_embedding("text-embedding-3-small","openai")
# 使用已加载的嵌入模型对文本 "Hello world" 进行向量化,返回一个向量列表
res = embedding.embed_query("Hello world")
# 打印该向量列表的前 10 个元素,方便快速查看结果
print(res[:10])
- 更多模型接入流程,详见:https://docs.langchain.com/oss/python/integrations/chat
3.2 消息列表messages 链接到标题
messages与:
OpenAI ChatCompletion API
Anthropic Claude Messages API
Google Gemini API
Llama/Ollama 的 Chat 模式
完全一致。
# 导入OpenAI官方SDK,用于调用兼容OpenAI接口的模型服务
from openai import OpenAI
# 初始化DeepSeek的API客户端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")
# 指定模型为deepseek-chat,构造系统提示和用户提问
response = client.chat.completions.create(
model="deepseek-chat", # 使用的模型名称
messages=[
{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"}, # 系统角色,定义助手行为
{"role": "user", "content": "你好,请你介绍一下你自己。"}, # 用户提问内容
],
)
messages 模板被称为 “消息管道”:
每一条 message 都能放变量
每一条 message 都能单独渲染
messages 最后被组装成一个列表传给模型
messages = 构造上下文 + 定义模型行为 + 填充历史 + 控制推理流程
这是 LangChain 最核心的思想:让 prompt 模块化、结构化、可维护。模型需要清楚:谁在说话?哪句是历史内容?哪句是现在的请求?哪些是规则?哪些不能被忽略?仅靠纯文本 Prompt是无法做到的。
| role | 作用 |
|---|---|
| system | 设定模型的身份、风格、规则,是“最高优先级” |
| user | 表示用户提问内容,是本轮对话的主体输入 |
| assistant/ai | 表示模型历史回答,有助于形成上下文记忆 |
| tool | 工具调用结果(用于 Agent) |
| developer | 开发者提示(OpenAI 新增 role),模型的功能逻辑 / 工程约束 |
# 构建对话历史,依次包含系统设定、助手开场白和用户问题
messages = [
{"role": "system", "content": "你是技术专家,回答要专业。"}, # 系统角色:设定助手为技术专家
{"role": "assistant", "content": "我准备好了,请问您遇到什么问题?"}, # 助手角色:主动询问用户问题
{"role": "user", "content": "我的电脑会自动重启。"} # 用户角色:描述电脑故障
]
# 调用模型生成回复
resp = model.invoke(messages)
# 打印模型返回的回复内容
print(resp.content)
messages 的执行顺序与优先级(非常关键)
LLM 按如下顺序解析:
1.system(最高优先级)
2.developer(模型的功能逻辑 / 工程约束)
3.user/human 用户当前输入的 query
4.assistant 历史对话
5.tool 调用
模型永远会参考全部 messages 才得出最终输出。
# 导入所需的消息类型
from langchain.messages import HumanMessage, SystemMessage
# 创建系统消息,设定模型角色为编程专家
system_msg = SystemMessage("你是一个编程专家。")
# 创建用户消息,请求生成一段3行的Python示例代码
human_msg = HumanMessage("给我写一段 3 行的 Python 示例。")
# 将系统消息和用户消息组合成消息列表
messages = [system_msg, human_msg]
# 调用模型,传入消息列表并获取响应
resp = model.invoke(messages)
# 提取并返回模型生成的内容
resp.content
- 更多message管理,详见https://docs.langchain.com/oss/python/langchain/messages
3.3 Prompt提示词模版 链接到标题
变量化 prompt 的模板化工具,支持输入插值与简单逻辑。
学习要点:模板管理、prompt engineering 的组织方式。
1. PromptTemplate 链接到标题
from langchain_core.prompts import PromptTemplate
# 创建一个带有{product}占位符变量的模板,{} 中的变量会被动态替换
prompt_template = PromptTemplate.from_template(
"为生产{product}的公司起一个好名字?"
)
# 使用具体值格式化模板
formatted_prompt = prompt_template.format(product="智能水杯")
# 输出: "为生产智能水杯的公司起一个好名字?"
# 将格式化后的提示词直接传递给模型
response = model.invoke(formatted_prompt)
print(f"打印生成的提示词:{formatted_prompt}")
print("=" * 60)
print(response.content)
# 导入 PromptTemplate 类,用于构建可复用的提示词模板
from langchain_core.prompts import PromptTemplate
# 创建模板:{} 中的变量会被动态替换
# 类比:邮件模板中的{{姓名}}占位符
template = PromptTemplate(
input_variables=["product", "feature"], # 明确声明变量名,确保模板知道需要哪些输入
template="请为{product}的{feature}功能写一段宣传文案。" # 定义模板字符串,占位符将在运行时被替换
)
# 格式化:填充变量,将具体值传入模板生成最终提示词
prompt_text = template.format(
product="智能手机", # 替换模板中的 {product}
feature="AI摄影" # 替换模板中的 {feature}
)
print("生成的提示词:")
print(prompt_text)
# 输出:请为智能手机的AI摄影功能写一段宣传文案。
partial_variables固定变量 链接到标题
partial_variables = 提前填充固定变量,使 PromptTemplate 成为“半成品模版”
让模板更简洁,锁定系统设定、风格角色、不变提示词,它仍可以进行覆盖操作,可用于动态函数变量,强烈建议用于 RAG / Agent 中的系统指令管理!
一些变量通常是 固定不变 的(例如:风格、角色、系统设定)
另一些变量由 用户输入决定(如用户问题、上下文、消息)
如果全部变量都在 .format() 填,会很啰嗦,还容易丢变量。
因此 LangChain 允许你把不变的变量“预填”到模板中,变成一个 partial prompt。
# 1. 创建 PromptTemplate 对象,指定需要填充的变量为 user_question
template = PromptTemplate(
input_variables=["user_question"],
template="""
你是一个专业的技术支持,回答风格:{style}。
请先复述用户问题,然后提供解决方案。
用户问题:{user_question}
解决方案:""",
partial_variables={"style": "简洁明了"} # 可选:部分变量固定,这里预设 style 为“简洁明了”,后续可覆盖
)
# 2. 使用 partial 方法覆盖 style 为“通俗易懂”,再填充用户问题
prompt = template.partial(style="通俗易懂").format(user_question="电脑无法开机")
# 3. 调用模型生成回复
response = model.invoke(prompt)
# 4. 打印最终生成的提示词
print(f"打印生成的提示词:{prompt}")
print("=" * 60)
# 5. 打印模型返回的内容
print(response.content)
| 项目 | input_variables | partial_variables |
|---|---|---|
| 是不是用户必须提供? | 是 | 否 |
| 何时填入? | .format() 时 | Template 定义时/.partial()覆盖 |
| 是否可覆盖? | 是 | 是 |
| 是否支持函数? | 否 | 支持(动态变量) |
| 适合场景 | 用户输入内容 | prompt 预设、系统指令 |
2. ChatPromptTemplate 链接到标题
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage, HumanMessage
# 使用messages模板字符串(最常用)
chat_template = ChatPromptTemplate.from_messages([
# SystemMessage: 定义AI角色和行为准则
("system", "你是一个专业的Python代码审查助手。请严格检查代码风格、潜在Bug和性能问题。"),
# HumanMessage: 用户输入
("human", "请审查以下代码:\n\n{code_snippet}"),
# AIMessage: 可选,提供示例输出(Few-shot)
("ai", "我发现了以下问题:1. 缺少类型注解 2. 使用全局变量"),
# HumanMessage: 用户的后续指令
("human", "{follow_up_instruction}")
])
# 格式化:生成消息列表
messages = chat_template.format_messages(
code_snippet="def add(a,b):\n return a+b",
follow_up_instruction="请给出优化后的代码"
)
print("生成的消息结构:")
for i, msg in enumerate(messages):
print(f"\n--- 消息 {i+1} ---")
print(f"角色: {msg.schema}")
print(f"内容: {msg.content}")
# 直接传递给模型
response = model.invoke(messages)
print("\n 模型审查结果:")
print(response.content_blocks[0]["text"])
3. LangChain Hub 模版库 链接到标题
使用提示词模版库之前需要先到LangSmith官网上申请一个api_key,官网地址:https://smith.langchain.com/
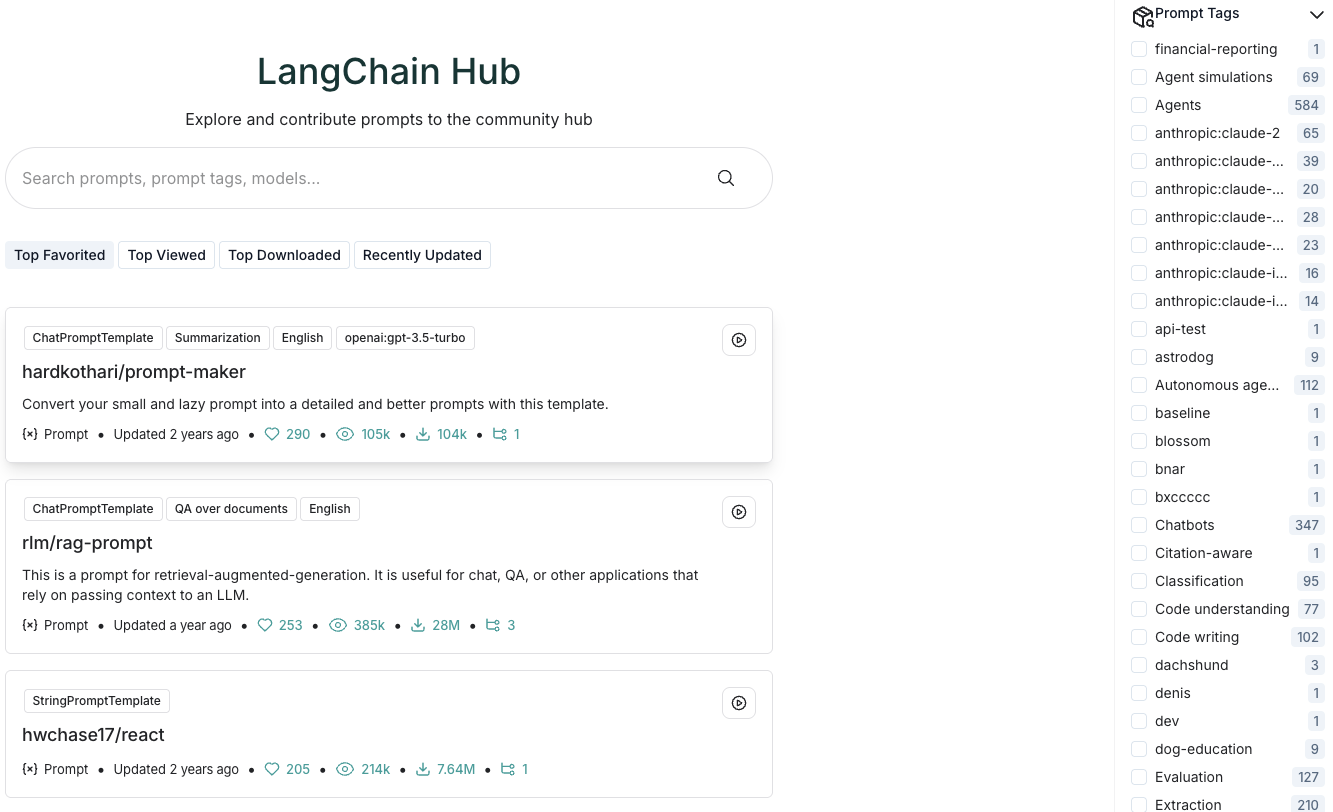
- hub提示词模版库地址:https://smith.langchain.com/hub/
import os
from dotenv import load_dotenv
load_dotenv()
# 从langsmith库引入Client类
from langsmith import Client
# 通过LangSmith的LANGSMITH_API_KEY创建Client实例化
client = Client(api_key=os.getenv("LANGSMITH_API_KEY"))
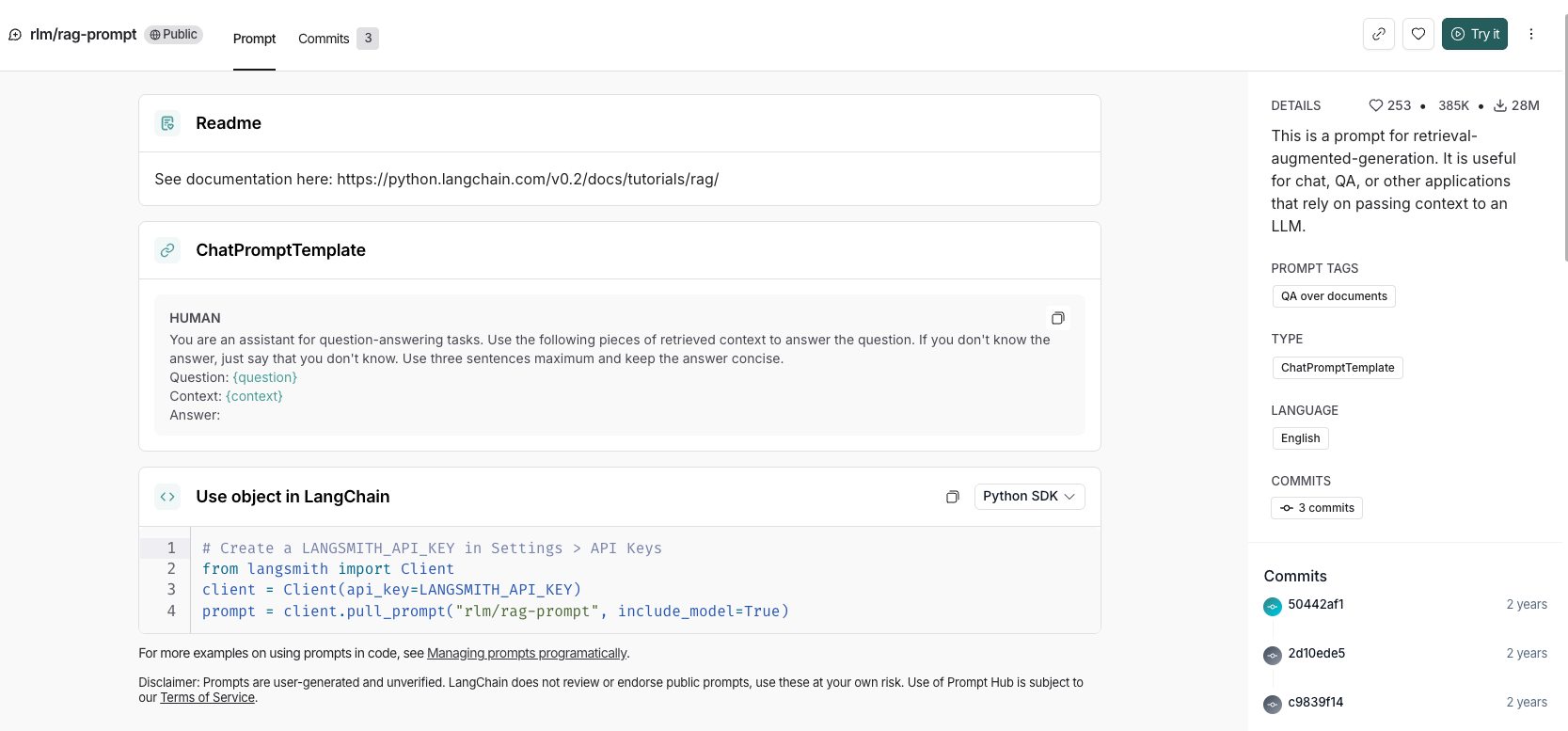
# 从hub上拉取对应的prompt模版
# 指定prompt标识符"rlm/rag-prompt",获取可用于RAG场景的提示模板
prompt = client.pull_prompt("rlm/rag-prompt", include_model=True)
print(prompt)
# 使用模板
formatted = prompt.format(
context="""
LangChain 是一个构建 LLM 应用的框架,
目标是把 LLM 与外部工具、数据源和复杂工作流连接起来 —— 支持从简单的 prompt 封装到复杂的 Agent
(能够调用工具、做决策、执行多步任务)""", # 模板中定义的上下文变量,用于填充到模板中
question="什么是LangChain?") # 模板中定义的问题变量,用于填充到模板中
print("\n格式化后:")
print(formatted)
response = model.invoke(formatted)
print(response.content)
# 打印输出内容块
response.content_blocks
3.4 标准化内容块Content Blocks 链接到标题
统一所有模型厂商的输出格式,解决"换模型就要重写解析代码"的痛点:
LangChain 1.0 引入了 provider-agnostic与厂商无关 的 standard content blocks标准化内容块,使得消息中的多模态数据(图片、音频、PDF、视频等)能以统一、类型化的方式被构造与阅读。通过 content blocks 属性实现多模态统一处理,封装 TextBlock、ToolCallBlock、ImageBlock 等结构,扩展 LLM 应用至图片理解、语音交互等场景。其核心优势在于标准化内容流转与跨平台兼容性,可通过 langchain-openai 等厂商包直接初始化多模态模型,支持图片输入生成描述、语音转文本问答等功能,依赖 Model I/O 模块完成格式化与解析
支持类型:text 、 tool_call 、 image 、 audio 、 video
| 场景 | 内容块作用 |
|---|---|
| 📄 文档解析(PDF / 图片 / 表格) | 用 image block 把 Document OCR 图像传给模型 |
| 🔊 语音问答(ASR) | 用 audio block 发送语音样本 |
| 🎞 多模态 RAG | 将检索到的图片、图表、视频帧作为 input blocks 传给模型 |
| 🤖 多工具 Agent | 工具返回的媒体统一包装成 block 再传回模型 |
| 🧪 模型评估(LangSmith / LangChain Playground) | 进行 multimodal prompt 测试与 A/B,对 content blocks 标注与评估。 |
输出提取content_blocks 链接到标题
# 加载 DeepSeek 提供的推理模型 deepseek-reasoner
deepseek_model = load_chat_model(
model="deepseek-reasoner", # 指定模型名称
provider="deepseek", # 指定模型提供商
)
# 调用模型
res = deepseek_model.invoke("请介绍一下你自己")
# 输出模型返回的结果
res
# 从模型返回的结果中提取内容块
res.content_blocks
多模态输入content_blocks 链接到标题
# 如果需要把本地文件以 base64 形式发送,建议安装 pillow/ffmpeg 等按需工具
#!pip install pillow
base64 形式触及了网络传输与数据序列化的底层原理。 简单来说,将图片或音频转换为 Base64,主要是为了解决 “在纯文本协议(HTTP/JSON)中传输二进制数据(Binary Data)” 的兼容性问题。
绝大多数大模型 API(OpenAI, Anthropic, Google Gemini 等)都是基于 RESTful API,数据载荷(Payload)格式通常是 JSON。
JSON 的本质:JSON 是一种纯文本格式。它只能理解字符串(String)、数字、布尔值等文本数据。
图片/音频的本质:它们是二进制数据(Binary Bytes)。如果你直接用文本编辑器打开一张 JPG 图片,你会看到乱码,其中包含了大量的不可见字符、控制字符(如换行符、空字符 \0 等)。
冲突点:如果你直接把这些二进制乱码塞进 JSON 的字符串字段里(例如 {“image”: “ÿØÿà…"}),这些特殊字符会破坏 JSON 的语法结构,导致服务端无法解析,或者被 HTTP 协议拦截。
解决方案:Base64 编码可以将任意二进制数据,映射为 64 个标准的、可打印的 ASCII 字符(A-Z, a-z, 0-9, +, /)。这样,原本的二进制图片就变成了普通的字符串,可以完美地嵌入到 JSON 中。
content_blocks 是 LangChain v1 的标准化多模态消息单元,你可以用 dict 结构把图片与音频纳入消息里,框架会把它们转换为各 provider 可识别的格式;在实际使用时务必确认目标模型/provider 对 multimodal 的支持和所需的 mime_type / metadata 字段。
from langchain_core.messages import HumanMessage, SystemMessage
# 创建系统提示
system_msg = SystemMessage("你是一个专业的问答专家。")
# 构造用户消息:文本+图像
human_msg = HumanMessage(content=[
{"type": "text", "text": "请描述图像:"},
{"type": "image_url",
"image_url": {"url": "https://zrj18330672592.oss-cn-beijing.aliyuncs.com/20251015134735612.png",
"mime_type": "image/jpeg",
"metadata": "RAG基础流程图"}
},
])
# 形成消息列表
messages = [system_msg, human_msg]
# 框架会懒解析 content -> content_blocks
for cb in human_msg.content_blocks:
print(cb) # content block 对象视图
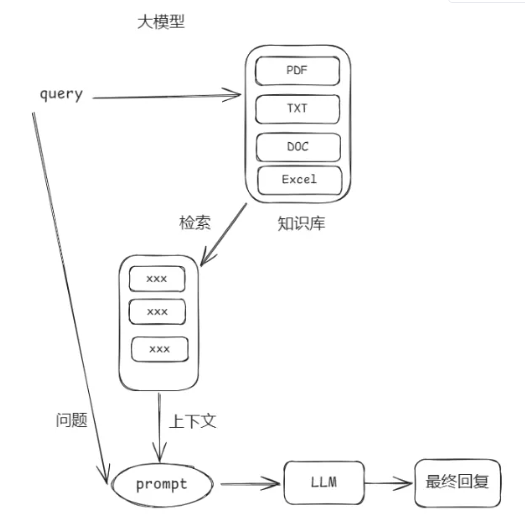
# 使用具有多模态能力的模型
model = load_chat_model(
model="gpt-4o-mini",
provider="openai",
)
res = model.invoke(messages)
print(res.content)
内容块创建标准格式 链接到标题
comparison = """
┌─────────────┬──────────────────────────────────────────────────────┐
│ 内容块类型 │ 标准格式(LangChain 1.0) │
├─────────────┼──────────────────────────────────────────────────────┤
│ 文本 │ {"type": "text", "text": "..."} │
│ 图像 │ {"type": "image", "url": "...", "mime_type": "..."} │
│ 音频 │ {"type": "audio", "url": "...", "mime_type": "..."} │
│ 视频 │ {"type": "video", "url": "...", "mime_type": "..."} │
│ 文件 │ {"type": "file", "url": "...", "mime_type": "..."} │
│ Base64 图像 │ {"type": "image", "base64": "...", "mime_type": "..."} │
│ Base64 音频 │ {"type": "audio", "base64": "...", "mime_type": "..."} │
│ OpenAI 图像 │ {"type": "image_url", "image_url": {"url": "..."}} │
└─────────────┴──────────────────────────────────────────────────────┘
"""
#OpenAI 内容块支持对比表:
support_table = """
┌─────────────┬──────────┬─────────────────────────────────────┐
│ 内容块类型 │ 支持情况 │ 说明 │
├─────────────┼──────────┼─────────────────────────────────────┤
│ text │ ✅ 支持 │ 纯文本内容 │
│ image_url │ ✅ 支持 │ 图像 URL(支持 jpg, png, gif, webp)│
│ audio │ ❌ 不支持│ 需要先用 Whisper 转录为文本 │
│ video │ ❌ 不支持│ 需要提取关键帧或转录音频 │
│ file │ ❌ 不支持│ 需要提取文本内容 │
└─────────────┴──────────┴─────────────────────────────────────┘
"""
3.5 批处理流程 链接到标题
在使用大模型时,如果需要同时处理多条独立请求(例如多个问题或多段文本),则可以使用 批量调用(Batch) 方法一次性提交这些请求。LangChain 中的 batch() 方法允许你同时发送一组请求,模型会在后台并行处理,然后返回所有结果:
import time
from datetime import datetime
# 记录开始时间
start_time = time.time()
print(f"⏱️ 开始时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
# 批量提问
responses = model.batch([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
])
# 记录结束时间
end_time = time.time()
total_duration = end_time - start_time
print(f"⏱️ 结束时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
print(f"📊 总耗时: {total_duration:.2f}s")
for response in responses:
print(response)
| 特性 | 说明 |
|---|---|
| 执行位置 | batch() 在客户端(Client-side)并行调用模型,而非调用模型提供商的批量API(如OpenAI或Anthropic自带的batch API)。 |
| 返回结果 | 默认会在所有任务完成后,统一返回完整结果列表。 |
| 并行优势 | 多条独立请求可同时执行,无需等待彼此完成。 |
| 适用场景 | 文档摘要、批量问答、数据预处理、多样本分类等。 |
当然,我们也可以进行流式批处理,也就是每个每个任务完成后就立即获取结果(而不是等待全部完成),可以使用 batch_as_completed() 方法。
# 使用 model.batch_as_completed 批量提交多个问题,并逐个获取回答
for response in model.batch_as_completed([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
]):
print(response)
异步并发处理RunnableConfig 链接到标题
而为了更好的控制并发,我们还可以在config参数中设置批处理的并发数,例如
import time
from datetime import datetime
#import asyncio
#设置并发数为3
config = RunnableConfig(max_concurrency=3)
# 记录开始时间
start_time = time.time()
print(f"⏱️ 开始时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
# 并发调用模型,批量处理三个问题
# Jupyter 已经支持顶级 await,无需 asyncio.run()
responses = await model.abatch([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
],config=config)
# 记录结束时间
end_time = time.time()
total_duration = end_time - start_time
print(f"⏱️ 结束时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
print(f"📊 总耗时: {total_duration:.2f}s")
# for response in responses:
# print(response)
特别注意
RunnableConfig(max_concurrency=N) 只是告诉 LangChain 在执行 abatch/batch 时最多并发 N 个子任务。
是否能提速,取决于整个 pipeline 是否为 I/O-bound(等待网络/模型服务)或 CPU/GPU-bound(单次推理占满资源)。
如果单次推理把 GPU/CPU 占满(例如单卡的 vLLM 同步推理),增加并发不会变快,甚至更慢(资源竞争)。
如果调用的是远端云 API(有网络延迟)或能并行处理多请求的模型服务,且客户端/服务端都允许并发,则会明显提速。
框架内部可能会在某些组件对并发做序列化(例如某些 LLM 客户端在后端使用同步 HTTP 会阻塞),这也会导致看起来并发无效。
确认你使用的是 abatch(异步)而不是 batch(同步)
from langchain_core.runnables import RunnableConfig
# 配置:最多 2 个并发任务
config = RunnableConfig(
max_concurrency=2, # 最大并发数:限制同时运行的任务数量,防止资源耗尽
abstimeout=8.0, # 单个任务超时时间(秒):超过此时间未完成的任务将被强制终止
metadata={"request_id": "abc123", "task": "query"}, # 元数据:记录请求ID和任务类型,便于追踪和日志分析
)
# 创建一个带有{product}占位符变量的模板
prompt_template = PromptTemplate.from_template(
"为生产{product}的公司起一个好名字?"
)
# 准备一个输入列表
inputs = ["彩色袜子", "环保咖啡杯", "智能水杯"]
formatted_prompts = [prompt_template.format(product=product) for product in inputs]
# Jupyter 已经支持顶级 await,无需 asyncio.run()
results = await model.abatch(formatted_prompts, config=config)
for i, r in enumerate(results):
print(f"=== Query {i+1} ===")
print(r.content)
print(r.model_config)
# 可能输出: ['Fun Socks Co.', 'Green Cup Co.', 'HydraSmart']
更多config参数解释如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
max_concurrency | int | 最大并行执行数 |
timeout | float | 每个请求的最大超时时间(秒) |
callbacks | list | 触发事件回调,用于日志或监控 |
metadata | dict | 额外的上下文信息,可用于追踪 |
3.6 流式传输 (Streaming) 链接到标题
需要注意的是:
流式输出依赖于整个程序链路都支持“逐块处理”。如果程序中的某个环节必须等待完整输出(如需一次性写入数据库),则无法直接使用 Streaming;
LangChain 1.0 进一步优化了流式机制,引入 自动流式模式(Auto-streaming)。例如在Agent中,如果整体程序处于 streaming 模式,即便节点中调用 model.invoke(),LangChain 也会自动流式化模型调用。
# 使用.stream()方法进行流式传输
for chunk in model.stream("用一段话描述大海。"):
print(chunk.content, end="", flush=True) # 逐块打印
# 输出会像真正的打字效果一样,一个一个词地出现。
每个 AIMessageChunk 都可以通过加法 + 操作符拼接。LangChain 内部为此设计了“消息块相加(chunk summation)”机制。
# 初始化变量,用于累积模型返回的完整内容
full = None # 初始值为空
# 使用流式方式调用模型,逐块接收返回内容
for chunk in model.stream("你好,好久不见"):
# 如果是第一块内容,则直接赋值;否则拼接到已有内容
full = chunk if full is None else full + chunk
# 打印当前累积的文本内容
print(full.text)
print(full.content_blocks)
astream_events() 链接到标题
此外,LangChain 还支持通过 astream_events() 对语义事件进行异步流式监听,适合需要过滤不同事件类型的复杂场景。
你能看到 完整语义生命周期事件,包括:
on_chain_start
on_prompt_start / on_prompt_end
on_llm_start
on_llm_stream(逐 Token)
on_llm_end
on_chain_end
非常适合:
调试 LLM 推理过程
了解 LangChain pipeline 的执行顺序
构建 UI(如 web 前端的逐 token streaming)
实现日志、可观测性、监控系统
import asyncio
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 1. 构建最简单的 Prompt + LLM
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的 AI 助手。"),
("human", "{question}")
])
# 2. 初始化 ChatOpenAI 实例,指定使用 gpt-3.5-turbo 模型
llm = ChatOpenAI(
model="gpt-3.5-turbo",
)
# 3. 使用管道符将 prompt 模板与 llm 连接,构建可运行的链
chain = prompt | llm
# 4. 使用 astream_events() 监听所有语义事件
events = chain.astream_events(
{"question": "请用一句话介绍一下 LangChain 1.0 的核心思想。"},
version="v1", # 必须指明版本,v1 才有语义事件
)
async for event in events:
# 打印事件类型
print(f"""[Event] type={event["event"]}""")
# 展示关键字段
if "data" in event:
print(" data:", event["data"])
print("-----------------------------")
3.7 结构化输出解析 链接到标题
很多时候,我们需要模型返回结构化的数据(如JSON),以便程序后续处理。输出解析器 (Output Parsers) 正是为此而生。
最强大的是 StructuredOutputParser,它可以与 Zod(TypeScript)或 Pydantic(Python)等模式定义工具结合使用,确保输出符合预定格式。
目标:让大模型返回可程序解析的数据
任务:学习Pydantic模型,使用with_structured_output()
产出:一个信息抽取器(提取电影信息/新闻摘要)
关键点:ToolStrategy兼容所有模型,ProviderStrategy更可靠
with_structured_output() 链接到标题
使用 Pydantic 的 BaseModel 定义一个严格的数据结构。每个字段都明确了类型(如 str、int、float),并用 Field(…, description=”…”) 提供语义描述。据此,模型回复时,LangChain 会要求 LLM 的输出必须能填充这些字段。然后使用with_structured_output即可引导模型进行结构化输出。
from typing import List
from langchain_core.utils.pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
# 1. 定义期望的输出结构 (Pydantic 模型)
class Person(BaseModel):
"""Information about a person."""
name: str = Field(description="人的姓名")
age: int = Field(description="人的年龄")
high: int = Field(description="人的身高")
hobbies: List[str] = Field(description="人的爱好列表")
# 2. 初始化模型并绑定结构化输出格式
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm = llm.with_structured_output(Person)
# 3. 调用模型并获取 Pydantic 对象,构造提示:要求提取约翰·多伊的姓名、年龄和兴趣爱好
prompt = "提取名为约翰·多伊的人的信息,提取不到的数据就为空值。他30岁,喜欢阅读、远足和弹吉他."
result = structured_llm.invoke(prompt)
# 4. 验证结果
print(f"Type of result: {type(result)}")
print(f"Result object: {result}")
# 5.判断result是否属于Person类
assert isinstance(result, Person)
- 而如果想要获得模型的完整回复,则可以设置
include_raw=True
# 1. 配置结构化输出:指定返回 Pydantic 模型 Person,并保留原始响应
structured_llm = llm.with_structured_output(Person, include_raw=True)
# 2. 调用模型并获取 Pydantic 对象
prompt = "提取名为约翰·多伊的人的信息。他30岁,喜欢阅读、远足和弹吉他."
# 3. 调用模型,返回结构化结果(包含解析后的 Person 对象和原始文本)
result = structured_llm.invoke(prompt)
# 4. 验证结果:打印返回值的类型与内容,便于调试
print(f"Type of result: {type(result)}")
print(f"Result object: {result}")
agent中结构化输出 链接到标题
from pydantic import BaseModel, Field,field_validator
from typing import Literal
from langchain.agents import create_agent
# 1. 定义天气结构化输出模型
class WeatherForecast(BaseModel):
"""天气预报结构化输出"""
city: str = Field(description="城市名称")
temperature: int = Field(description="温度(摄氏度)")
condition: Literal["晴", "雨", "多云", "雪"] = Field(description="天气状况")
# 2. 加载模型
model = load_chat_model(
model="gpt-4o-mini",
provider="openai",
)
# 3. 创建智能体
agent = create_agent(
model=model, # 加载的模型
tools=[], # 工具列表,这里为空
response_format=WeatherForecast # 指定结构化输出格式
)
# 4. 调用智能体解析天气描述
result = agent.invoke({
"messages": [{
"role": "user",
"content": "北京今天阳光明媚,温度10度"
}]
})
# 5. 提取并打印结果
forecast = result["structured_response"]
print(f"{forecast.city}天气: {forecast.condition}, {forecast.temperature}°C")
带判断的结构 链接到标题
from pydantic import BaseModel
# 1. 定义年龄模型,限制范围 0-150
class AgeProfile(BaseModel):
name: str
age: int = Field(ge=0, le=150) # 年龄必须在0-150之间
# 2. 定义模型
model = load_chat_model(
model="gpt-4o-mini",
provider="openai",
)
# 3. 创建智能体agent
agent = create_agent(
model=model,
tools=[],
response_format=AgeProfile
)
# 4. 模型返回age=999(非法值)
result = agent.invoke({
"messages": [{
"role":"user",
"content": "张三的年龄是999岁" # 明显不合理的数据
}]
})
# LangChain会自动:
# 1. 捕获ValidationError
# 2. 在ToolMessage中反馈错误详情
# 3. 让模型重新生成
# 最终返回合法值
print(result["structured_response"])
JsonOutputParser 链接到标题
from langchain_core.output_parsers import JsonOutputParser
import json
from pydantic import BaseModel, Field
# 1. 定义输出结构
class WeatherInfo(BaseModel):
"""天气信息"""
city: str = Field(description="城市名称")
temperature: int = Field(description="温度(摄氏度)")
condition: str = Field(description="天气状况")
# 2. 创建 JSON 输出解析器
json_parser = JsonOutputParser(pydantic_object=WeatherInfo)
# 3. 创建提示模板(关键:必须包含 "json" 这个词)
prompt = ChatPromptTemplate.from_template(
"""请根据以下信息提取天气数据,并以 JSON 格式返回。
信息:{weather_info}
请返回包含以下字段的 JSON:
- city: 城市名称
- temperature: 温度(摄氏度)
- condition: 天气状况
必须返回以下 JSON 格式(不要包含任何其他文本):
{{"city": "城市名称", "temperature": 温度数字, "condition": "天气状况"}}
例如:{{"city": "北京", "temperature": 25, "condition": "晴"}}
JSON 格式:
""")
# 4. 定义模型
model = load_chat_model(
model="gpt-4o-mini",
provider="openai",
)
# 5. 构建链
runnable = prompt | model | json_parser
# 6. 调用
result = runnable.invoke({"weather_info": "北京今天晴,温度25度"})
print(result)
print(result["city"])
| 分类 | 常用解析器 | 作用 |
|---|---|---|
| 基础解析 | StrOutputParser | 将模型输出解析成纯字符串(默认) |
| JSON 结构化解析 | JsonOutputParser | 将 LLM 输出强制解析为 JSON |
PydanticOutputParser | 使用 Pydantic v1 模型进行结构化输出 | |
PydanticOutputFunctionsParser | 用于 Function Calling 的 Pydantic 结构化解析 | |
| 列表解析 | CommaSeparatedListOutputParser | 输出如 "a,b,c" → ["a", "b", "c"] |
ListOutputParser | 更通用的列表解析 | |
| 布尔/数值解析 | BooleanOutputParser | 输出 “yes” / “no” → True/False |
FloatOutputParser | 输出模型内容转 float | |
IntOutputParser | 输出模型内容转 int | |
| 复杂结构化 | EnumOutputParser | 让模型输出固定几个选项之一 |
DataclassOutputParser | 使用 Python dataclass 进行结构化输出 |
结构化输出关键要点:
输出json格式提示词必须包含 “json” 关键词
- DeepSeek API 要求提示词中包含 “json” 这个词
- 否则会报错:
Prompt must contain the word 'json'
推荐方案对比
- 方案 1 (JsonOutputParser):最简洁,推荐使用
- 方案 2 (with_structured_output):需要提示词包含 “json”
- 方案 3 (可选手动 JSON 解析):最稳定,适合关键应用
配置建议
- 设置
temperature=0.0获得更稳定的输出 - 最好提供清晰的 JSON 格式示例
- 设置
常见错误
- 提示词中没有 “json” 关键词
- 没有设置低温度参数
- 没有提供 JSON 格式示例
- 没有处理解析异常
第四阶段、 简单问答机器人 链接到标题
from langchain_deepseek import ChatDeepSeek
from langchain.messages import HumanMessage, AIMessage, SystemMessage
# 1️⃣ 初始化模型(LangChain 1.0 接口)
model = load_chat_model(
model="gpt-4o-mini",
provider="openai",
)
# 2️⃣ 初始化系统提示词(System Prompt)
system_message = SystemMessage(
content="你叫小智,是一名乐于助人的智能助手。请在对话中保持温和、有耐心的语气。"
)
# 3️⃣ 初始化消息历史
messages = [system_message]
print("🔹 输入 exit 退出对话\n")
# 4️⃣ 主循环(支持多轮对话 + 流式输出)
while True:
user_input = input("👤 你:")
if user_input.lower() in {"exit", "quit"}:
print("🧩 对话结束,再见!")
break
# 追加用户消息
messages.append(HumanMessage(content=user_input))
# 实时输出模型生成内容
print("🤖 小智:", end="", flush=True)
full_reply = ""
# ✅ LangChain 1.0 标准写法:流式输出
for chunk in model.stream(messages):
if chunk.content:
print(chunk.content, end="", flush=True)
full_reply += chunk.content
print("\n" + "-" * 40) # 分隔线
# 追加 AI 回复消息
messages.append(AIMessage(content=full_reply))
# 保持消息长度(只保留最近50轮)
messages = messages[-50:]
gradio界面搭建 链接到标题
# 安装 Gradio
!pip install gradio
#AutoDL中需要映射端口后,才能通过本地浏览器进行访问
#ssh -L 7860:127.0.0.1:7860 -p 25660 root@connect.westc.gpuhub.com
import gradio as gr
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
# ──────────────────────────────────────────────
# 1. 初始化模型与系统设定
# ──────────────────────────────────────────────
model = ChatDeepSeek(model="deepseek-chat")
system_message = SystemMessage(
content="你叫小智,是一名乐于助人的智能助手。请在对话中保持友好、有耐心、温和的语气。"
)
# ──────────────────────────────────────────────
# 2. 定义 Gradio 界面
# ──────────────────────────────────────────────
CSS = """
.main-container {max-width: 1200px; margin: 0 auto; padding: 20px;}
.header-text {text-align: center; margin-bottom: 20px;}
"""
def create_chatbot() -> gr.Blocks:
with gr.Blocks(title="DeepSeek Chat", css=CSS) as demo:
with gr.Column(elem_classes=["main-container"]):
gr.Markdown("# 🤖 LangChain 1.0 × DeepSeek Chatbot", elem_classes=["header-text"])
gr.Markdown("基于 LangChain 1.0 标准接口的流式对话机器人", elem_classes=["header-text"])
chatbot = gr.Chatbot(
height=500,
show_copy_button=True,
avatar_images=(
"https://cdn.jsdelivr.net/gh/twitter/twemoji@v14.0.2/assets/72x72/1f464.png",
"https://cdn.jsdelivr.net/gh/twitter/twemoji@v14.0.2/assets/72x72/1f916.png",
),
)
msg = gr.Textbox(placeholder="请输入您的问题...", container=False, scale=7)
submit = gr.Button("发送", scale=1, variant="primary")
clear = gr.Button("清空", scale=1)
# 状态:保存消息历史(LangChain Message 对象)
state = gr.State([])
# ─────────────── 主响应函数(流式输出) ───────────────
def respond(user_msg: str, chat_hist: list, messages_list: list):
# 1️⃣ 输入为空则直接返回
if not user_msg.strip():
yield "", chat_hist, messages_list
return
# 2️⃣ 构建消息上下文(包括系统提示)
if not messages_list:
messages_list = [system_message]
messages_list.append(HumanMessage(content=user_msg))
# 3️⃣ 添加用户消息到聊天历史
chat_hist = chat_hist + [(user_msg, "")]
# 4️⃣ 流式生成模型回复
partial = ""
for chunk in model.stream(messages_list):
if chunk.content:
partial += chunk.content
# 每次更新最后一条消息
chat_hist[-1] = (user_msg, partial)
# 立即 yield,让 UI 实时更新
# 返回空字符串给 msg,清空输入框
yield "", chat_hist, messages_list
# 5️⃣ 保存完整 AI 回复并截断历史(保留50轮)
messages_list.append(AIMessage(content=partial))
messages_list = messages_list[-50:]
# 6️⃣ 最后一次 yield 确保状态同步
yield "", chat_hist, messages_list
# ─────────────── 清空对话函数 ───────────────
def clear_history():
return "", [], []
# ─────────────── Gradio 事件绑定 ───────────────
# 返回 msg、chatbot 和 state
# msg 返回空字符串来清空输入框
msg.submit(respond, [msg, chatbot, state], [msg, chatbot, state])
submit.click(respond, [msg, chatbot, state], [msg, chatbot, state])
clear.click(clear_history, outputs=[msg, chatbot, state])
return demo
# ──────────────────────────────────────────────
# 3. 启动 Gradio 应用
# ──────────────────────────────────────────────
print("\n🚀 启动 Gradio 应用...")
demo = create_chatbot()
demo.launch(server_name="0.0.0.0", server_port=7860, share=False, debug=True)
总结 链接到标题
LangChain 在 1.0 版本完成了一次真正意义上的“工程化重塑”。1.0 通过统一抽象、简化接口、强化生态与扩展性,使其正式进入 可用于企业生产级大模型应用开发 的阶段。通过统一 Runnable 抽象、标准化模型接口、强化结构化输出能力、完善事件与回调体系,以及与 LangSmith/LangGraph 的深度融合,LangChain 已建立完整的 AI 应用全栈生态(模型调用、数据处理、RAG、Agent、工作流、监控评估)。如果你需要构建高可靠、可观测、结构化输出、支持本地模型、可扩展的 AI 应用——LangChain 1.0 是当下最成熟、最工程化的选择之一。
LangChain 官方地址:https://docs.langchain.com/
LangChain 中文版 TypeScript版本:https://docs.langchain.org.cn/oss/javascript/langchain/overview