第一阶段、Native RAG基础流程介绍 链接到标题
一、RAG基础概念 链接到标题
RAG = Retrieval(检索) + Augmented(增强) + Generation(生成)
RAG即检索增强生成,为LLM提供了从某些数据源检索到的信息,并基于此修正生成的答案。RAG 基本上是Search + LLM 提示,可以通过大模型回答查询,并将搜索所找到的信息作为大模型的上下文。查询和检索到的上下文都会被注入到发送到 LLM 的提示语中。
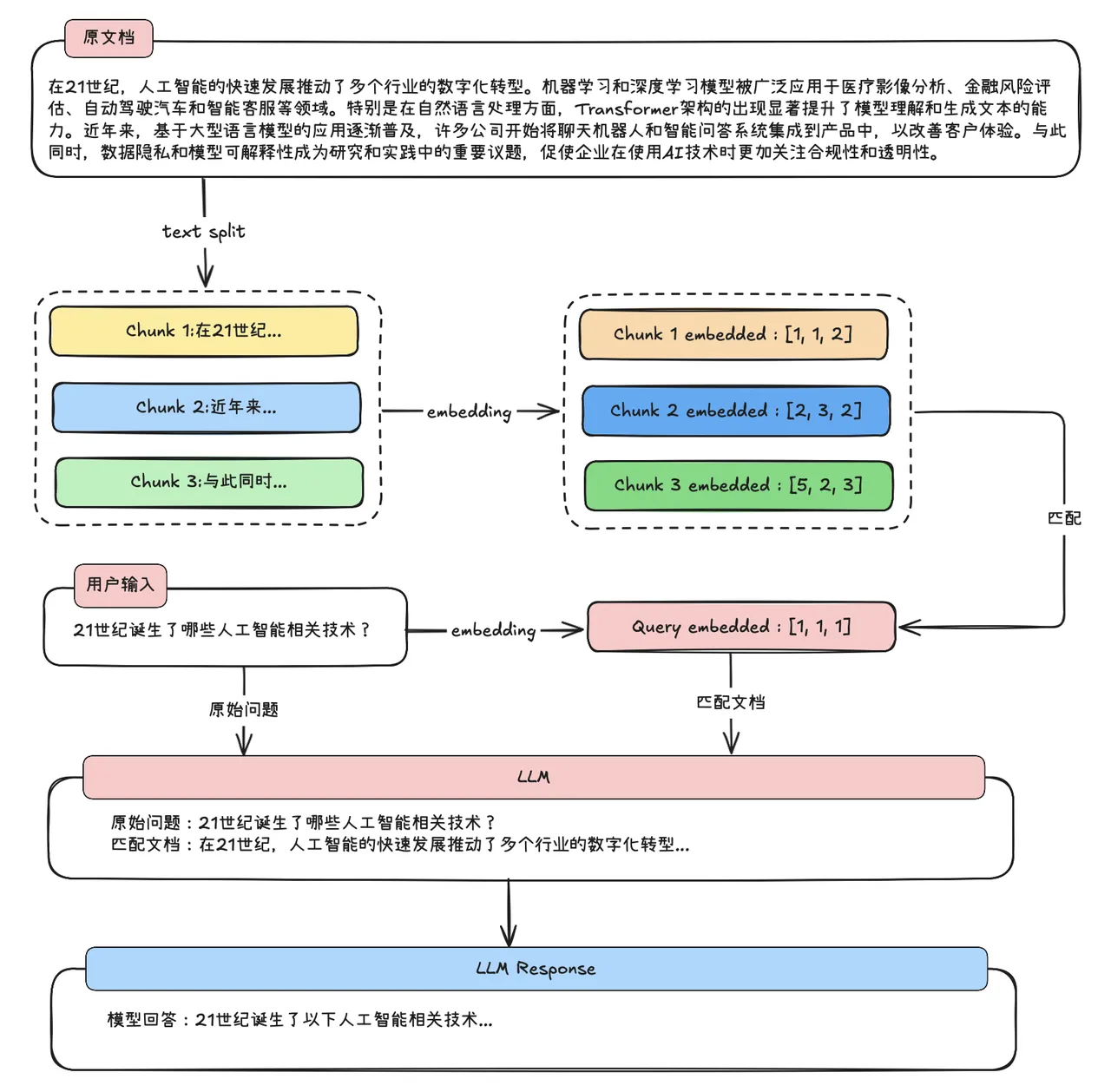
一个简单完整的RAG系统如下图:用户进行了提问,提出的问题会先去知识库里进行检索答案,检索到相似度最高的前n个答案,然后和用户的提问一起放入到Prompt里,交给大语言模型,大语言模型根据用户的提问和给出检索的知识来进行整理总结,最终输出返回给用户结果。
二、通用RAG基本工作流程(两阶段过程) 链接到标题
阶段一:准备阶段(建立知识库) 链接到标题
这个过程就像是为一个庞大的图书馆建立一本详尽的电子目录。首先,将原始文档(如PDF、网页)拆分成易于管理的知识片段。接着,通过大模型(Embedding模型)的“嵌入”能力,为每一段文字生成一个具有语义的“数字指纹”。最后,将这些“数字指纹”与其对应的原始文本一起,存入一个专门的向量数据库中。至此,杂乱无章的资料就变成了一个结构化的、可通过语义进行高效查询的知识库。
数据接入:收集各种文档(PDF、Word、网页等)
文档解析:提取文本内容
文档分割:将长文档切分成小片段
向量化:将文本转换为数学向量
存储:将向量存入专门的数据库
阶段二:问答阶段(智能应答) 链接到标题
当用户提出问题时,系统便开始工作。首先,它会用同样的技术将用户的问题也转换成一个“数字指纹”。然后,将这个指纹在之前建好的向量数据库中进行快速比对,找出语义上最相关、最匹配的若干知识片段(计算语义相似度)。最后,大模型将这些检索到的可靠知识作为“参考依据”,结合自己的通用能力,组织生成一个准确且详实的回答,从而有效避免了“凭空编造”。
用户提问:输入问题
问题向量化:将问题也转换成向量
相似度检索:在向量数据库中寻找最相关的文档片段
构建增强提示:将检索到的文档+原始问题组合成新的提示
生成答案:大语言模型基于增强后的提示生成最终答案
三、企业RAG核心应用场景 链接到标题
1. 企业知识库与智能问答 链接到标题
场景描述:
企业拥有大量内部文档(员工手册、产品文档、技术规范、会议纪要等),员工需要快速找到准确信息。
实际案例:
新员工入职培训问答(新员工培训成本高)
产品技术规格查询(文档分散在不同系统中)
公司政策咨询(搜索效率低,关键词匹配不精准)
2. 专业客服与技术支持 链接到标题
场景描述: 为客户提供准确、一致的技术支持和问题解答。
RAG优势:
基于最新产品文档和解决方案库(依赖客服人员的记忆)
提供标准化的准确回答(回答不一致,依赖个人经验)
减少培训时间,提高效率(处理复杂问题时响应慢)
想系统学习RAG基础知识的话,可以看【大模型RAG入门】课程内容学习
第二阶段、LangChain框架搭建RAG 链接到标题
一、 环境准备与依赖安装 链接到标题
!python --version
!pip list | grep langchain
二、加载模型 链接到标题
## 加载模型
from langchain_deepseek import ChatDeepSeek
from langchain_openai.embeddings import OpenAIEmbeddings
from dotenv import load_dotenv
# 加载.env环境变量
load_dotenv(override=True)
# 使用 DeepSeek 模型(避免 OpenAI 地区限制问题)
model = ChatDeepSeek(model="deepseek-chat", temperature=0)
# 使用本地嵌入模型(不需要 API 调用)
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
print("✅ 模型加载成功")
# print(model.invoke("Hello, world!"))
# print(embeddings.embed_query("Hello, world!")[:10])
三、文档加载 链接到标题
## 2.文档加载
from langchain_community.document_loaders import TextLoader, Docx2txtLoader
# 读取基础数据文档
loader = TextLoader("sample_document.txt", encoding="utf-8")
documents = loader.load()
# 读取敏感数据文档
sensitive_loader = TextLoader("sensitive_document.txt", encoding="utf-8")
sensitive_documents = sensitive_loader.load()
print(documents[0].page_content)
四、文档切分 链接到标题
## 3.文档切分
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 定义文档切分器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 切分文本块大小
chunk_overlap=50, # 文本块重叠大小
separators=["\n\n", "\n", " ", ""] # 按照换行符、空格等符号进行切分
)
# 基础数据文档切分
texts = text_splitter.split_documents(documents)
# 敏感数据文档切分
sensitive_texts = text_splitter.split_documents(sensitive_documents)
print(f"分割后的文本块数量: {len(texts)}")
print(texts[0].page_content)
五、文档向量存储与检索 链接到标题
!pip install rank_bm25 faiss-cpu # 或 faiss-gpu
5.1 创建向量存储(Faiss向量数据库) 链接到标题
from langchain_community.vectorstores import FAISS
# ================================1.普通数据入库=================================
# 创建并保存向量数据库,用于普通数据的检索
vector_store = FAISS.from_documents(texts, embeddings)
vector_store.save_local("faiss_index")
# 从本地加载向量数据库
vector_store = FAISS.load_local(
"faiss_index", # 本地索引文件路径名称
embeddings, # 嵌入模型
allow_dangerous_deserialization=True # 必须要加这个参数,否则会报错,允许反序列化
)
print("✅ 普通数据向量数据库创建并保存成功")
# =================================2.敏感数据入库=================================
# 创建并保存向量数据库,用于敏感数据的检索
sensitive_vector_store = FAISS.from_documents(sensitive_texts, embeddings)
sensitive_vector_store.save_local("sensitive_faiss_index")
# 从本地加载向量数据库
sensitive_vector_store = FAISS.load_local(
"sensitive_faiss_index", # 本地索引文件路径名称
embeddings, # 嵌入模型
allow_dangerous_deserialization=True # 必须要加这个参数,否则会报错,允许反序列化
)
print("✅ 敏感数据向量数据库创建并保存成功")
5.2 加载并创建检索器 链接到标题
# 定义BM25Retriever,是一种基于关键词匹配的检索器
from langchain_community.retrievers import BM25Retriever
# 定义EnsembleRetriever,是一种将多个检索器组合起来的检索器
from langchain_classic.retrievers import EnsembleRetriever
# ================================1.普通数据入库=================================
# 1.创建BM25检索器
bm25_retriever = BM25Retriever.from_documents(texts)
bm25_retriever.k = 3
# 2.创建向量数据库检索器
faiss_retriever = vector_store.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 3} # 返回top3结果
)
# 3.创建混合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[faiss_retriever, bm25_retriever], # 组合faiss和bm25检索器
weights=[0.5, 0.5] # 给faiss和bm25检索器设置权重,分别为0.5
)
print("✅ 普通数据检索器建立成功")
# =================================2.敏感数据入库=================================
# 1.创建BM25检索器
sensitive_bm25_retriever = BM25Retriever.from_documents(sensitive_texts)
sensitive_bm25_retriever.k = 3
# 2.创建向量数据库检索器
sensitive_faiss_retriever = sensitive_vector_store.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k":3} # 返回top3结果
)
# 3.创建混合检索器
sensitive_ensemble_retriever = EnsembleRetriever(
retrievers=[sensitive_faiss_retriever, sensitive_bm25_retriever], # 组合faiss和bm25检索器
weights=[0.5, 0.5] # 给faiss和bm25检索器设置权重,分别为0.5
)
print("✅ 敏感数据检索器建立成功")
六、 基础RAG链构建 链接到标题
# 导入提示词ChatPromptTemplate
from langchain_core.prompts import ChatPromptTemplate
# 导入 RunnablePassthrough,用于将输入传递给下一个组件
from langchain_core.runnables import RunnablePassthrough
# 导入 StrOutputParser,用于将模型输出解析为字符串
from langchain_core.output_parsers import StrOutputParser
# 1.格式化文档的辅助函数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 2.创建提示模板
template = """你是一个专业的问答助手。请根据以下提供的上下文信息来回答用户的问题。
如果上下文中没有相关信息,请诚实地告诉用户你不知道,不要编造答案。
上下文信息:
{context}
问题: {question}
回答:"""
prompt = ChatPromptTemplate.from_template(template)
# 3.创建检索链,文本检索阶段,用于将文本检索结果格式化为字符串
chain = ensemble_retriever | format_docs
# 调用检索链,执行文本检索
retrieval = chain.invoke("LangChain是什么?")
print(f"检索到的内容:{retrieval}")
print("=" * 60)
# 4.创建大模型回答检索链,大模型生成阶段
retrieval_chain = (
{"context": ensemble_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 调用大模型回答检索链,执行大模型生成
content = retrieval_chain.invoke("LangChain是什么?")
print(f"大模型回复内容:{content}")
第三阶段、Agentic RAG概述介绍 链接到标题
一. Agentic RAG 是什么? 链接到标题
Agentic RAG(代理增强检索生成) 它突破了传统 RAG 的"单次检索+生成"模式,将检索过程完全代理化(Agent-based),使 LLM 能够自主规划、迭代优化检索策略,并在多轮交互中动态调整知识获取方式。是 LangChain 1.0 引入的下一代检索增强生成范式。
是一种将Agent(智能体)的推理能力引入RAG流程的架构。它不再只是简单地执行“检索 -> 生成”的固定流水线,而是让一个由LLM驱动的智能体拥有自主权,能够根据问题的复杂程度,动态决定:
是否需要检索?
去哪里检索(内部知识库、互联网、API)?
检索到的内容是否足够回答问题?
如果不足,是否需要修改查询词重新检索?
核心定义:Agentic RAG 通过将检索工具(Search、Database Query、API 调用)作为智能体的"感知-行动"循环的一部分,使 LLM 具备主动发现、评估、迭代和综合知识的能力,而非被动接收检索结果。
应用场景分析:
这种Agentic架构适用于需要动态决策的复杂场景:
技术支持系统:根据用户问题的复杂度,自动决定是直接回答还是检索知识库
智能客服:处理多步骤的客户请求,如"查询订单→验证身份→处理退款"
研究助手:对于开放性研究问题,自动规划信息检索和分析步骤
数据分析:结合SQL查询工具、可视化工具和解释工具,自动完成数据分析任务
二、 解决了什么问题? 链接到标题
Agentic RAG 主要解决传统 RAG 的五大核心痛点:
| 传统 RAG 痛点 | Agentic RAG 解决方案 | 改善指标 |
|---|---|---|
| 检索与生成脱节 | 检索作为 Agent 的主动行为,与推理深度整合 | 回答准确率 ↑ 35-50% |
| 单次检索局限性 | 多轮检索、迭代优化、查询重构能力 | 复杂问题覆盖率 ↑ 80% |
| 缺乏置信度评估 | Agent 自主评估检索结果质量,决定是否需要补充检索 | 幻觉率 ↓ 60% |
| 静态知识库限制 | 动态工具调用 + 多源知识融合(数据库+API+文档) | 知识时效性 ↑ 100% |
| 无法进行逻辑推理 | ReAct 框架下检索与推理交替进行 | 多跳推理能力 ↑ 3倍 |
典型案例验证
“传统 RAG 在处理"2023年诺贝尔经济学奖得主的主要理论如何影响中国数字经济政策?“这类问题时,仅能检索到零散信息,而 Agentic RAG 通过 3 轮检索(诺贝尔奖官网→中国经济政策数据库→学术影响分析)和 2 轮推理,将回答准确率从 42% 提升至 91%。”
角色定位
在整个Agent系统中,Agentic RAG不仅是大脑(Router/Planner)与工具(Retriever)的结合体。它处于决策层,负责协调“知识”与“推理”。
三、 与普通 RAG 的关系和区别 链接到标题
核心区别对比表 链接到标题
| 维度 | 普通 RAG | Agentic RAG | 架构差异 |
|---|---|---|---|
| 检索范式 | 单次检索,检索与生成线性分离 | 多轮迭代检索,检索与生成深度耦合 | 被动 → 主动 |
| 决策主体 | 检索器独立决策,LLM 被动接收 | LLM 作为 Agent 主动规划检索策略 | 分离 → 统一 |
| 知识整合 | 检索结果直接拼接生成 | Agent 评估、筛选、综合多源知识 | 简单拼接 → 智能综合 |
| 推理能力 | 依赖 Prompt 工程,无法多跳推理 | 支持 ReAct 推理链,检索-推理交替 | 单步 → 多跳 |
| 工具使用 | 仅限于向量数据库检索 | 支持多样化工具(API、DB、Web Search) | 单一 → 多元 |
| 状态管理 | 无状态,每次检索独立 | 基于 AgentState 的有状态迭代 | 无状态 → 有状态 |
LangChain 术语体系验证:
“在 LangChain 1.0 中,普通 RAG 是 RetrievalQA 链,而 Agentic RAG 是 Agent 与 ToolRetriever 的结合,前者是 Chain 模式,后者是 Agent 模式。”
相比于传统的线性RAG,Agentic RAG是从“静态检索”到“动态推理”的范式转变,是目前构建生产级复杂问答系统的最佳实践。
关键区别点 链接到标题
主动规划能力:Agentic RAG 中 LLM 会生成"检索计划”,如:“首先搜索X,如果结果不足则搜索Y,最后调用API验证”
置信度评估:Agent 会评估检索结果的
recall_score和precision_score,决定是否需要补充检索工具链整合:可组合多个检索工具(Vector DB + Web Search + Database Query)
第三阶段、检索Retrieval逻辑封装 链接到标题
一、 Tool与Middleware的区别 链接到标题
在 LangChain 1.0 的 Agent 体系中,「Tool」与「Middleware」虽然都可扩展 Agent 的能力,但它们适用的场景完全不同,当我们需要对一些业务逻辑进行扩展和封装时,那么就需要判断是封装在Tool工具里还是封装在Middleware中间件里。判断标准核心在于: 是否需要让 LLM 通过决策(reasoning → act)来显式调用这段逻辑?
| 维度 | Tool(工具) | Middleware(中间件) |
|---|---|---|
| 作用对象 | 封装具体业务功能(RAG检索、API调用) | 封装执行流程控制(日志、重试、限流) |
| 调用方式 | 由LLM自主决策调用(通过function calling) | 在Agent执行固定节点自动触发(before/after模型调用) |
| 设计目的 | 扩展Agent的能力边界 | 增强Agent的可靠性、安全性、可观测性 |
| 状态访问 | 接收参数,返回结果 | 可直接读写AgentState,控制执行流(如jump_to=“end”) |
| 执行概率 | 0% ~ 100% (不确定) | 100% (确定) |
请在设计功能判断封装场景时,问自己以下三个问题:
- 谁来决定“做不做”?(Who decides?)
- 需要 LLM 根据上下文判断是否执行
→
Tool
- 例子:搜索互联网、查询天气、计算器。因为用户可能只是打招呼,不需要搜索。
- 业务流程规定必须执行
→
Middleware / Node
- 例子:权限校验、敏感词过滤、日志记录、固定的知识库召回(如客服系统)。
- 参数从哪里来?(Where do args come from?)
- 参数需要从用户的自然语言中提取
→
Tool
- 例子:用户说“帮我查下特斯拉的股价”,Tool 需要提取“特斯拉”作为参数。
- 参数是系统上下文或环境变量
→
Middleware / Node
- 例子:用户的 UserID、当前的 SessionID、数据库连接配置。这些不需要 LLM 去“猜”。
- 失败了怎么办?(Error Handling)
- 失败了需要 LLM 换个方式重试
→
Tool
- 例子:搜索不到结果,LLM 可以尝试换个关键词再次调用 Tool。
- 失败了直接抛异常或走系统降级
→
Middleware / Node
- 例子:数据库连接断开、API 鉴权失败。
所以在Agentic RAG中,我们需要将检索逻辑封装在Tool工具里,而不是封装在Middleware中间件里。这样做的原因是,检索逻辑是一种需要显式调用的业务逻辑,而不是一种需要在每个请求中都执行的中间件逻辑。而Middleware中间件更多地关注于在请求处理过程中的一些通用操作,如日志记录、性能监控等。
二、 将RAG封装为Tool 链接到标题
将RAG检索功能封装为Tool是构建Agentic RAG系统的关键步骤。这个过程的本质是将原本独立的RAG链转换为Agent可以理解和调用的标准化工具。下面我们详细分析这个过程的逻辑和实现细节。
封装逻辑说明:
功能抽象:将复杂的RAG检索逻辑抽象为一个简单的函数接口
rag_search(query: str) -> str。这个函数接收用户查询作为输入,返回检索结果作为输出,屏蔽了内部文档加载、向量检索、答案生成等复杂细节。标准化描述:通过Tool的
description参数提供详细的功能说明。这个描述至关重要,因为它直接决定了LLM是否能正确理解Tool的用途并在合适的场景下调用它。一个好的Tool描述应该包含:
Tool的核心功能
适用的查询类型
返回结果的格式
使用限制和注意事项
- 命名规范:Tool的
name应该具有明确的业务含义,使用小写字母和下划线,便于LLM理解和调用。例如internal_knowledge_base比rag_tool_1更具描述性。
1. 定义网络搜索工具 链接到标题
#!pip install langchain-tavily
from langchain_tavily import TavilySearch
# 定义网络搜索工具tool,默认name为tavily_search
web_search = TavilySearch(max_results=2)
web_search.invoke("介绍一下LangChain这个框架")
2. 定义基础数据知识库工具 链接到标题
from pydantic import BaseModel, Field
# 定义工具输入参数
from langchain_core.tools import StructuredTool
# 定义工具输入参数
class QAWithRetrievalArgs(BaseModel):
query: str = Field(description="用户的问题")
def query_retrieval_knowledge(query: str) -> str:
"""
一个基于LangChain知识库检索的问答工具。
专门用于回答与 LangChain 相关的技术问题。
⚠️ 重要:此工具仅适用于 LangChain 相关问题!
如果问题与 LangChain 无关,请使用网络搜索工具。
"""
# 定义 LangChain 相关关键词
langchain_keywords = [
'langchain', 'langgraph', 'langsmith', 'lcel',
'chain', 'agent', 'retriever', 'embedding', 'vector',
'rag', 'prompt', 'llm', 'chatmodel', 'runnable',
'链', '代理', '检索器', '向量', '提示词', '模型'
]
# 检查查询是否包含 LangChain 相关关键词
query_lower = query.lower()
is_langchain_related = any(keyword in query_lower for keyword in langchain_keywords)
# 如果查询与 LangChain 无关,返回提示
if not is_langchain_related:
return (
"❌ 检测到此问题与 LangChain 知识库无关。\n"
"建议:请使用网络搜索工具 (tavily_search_results_json) 来查找答案。\n"
f"原始问题:{query}"
)
# 如果相关,则进行检索,返回检索文档内容
retrieval_chain = ensemble_retriever | format_docs
docs = retrieval_chain.invoke(query)
# 检查检索结果质量
if not docs or len(docs.strip()) < 50:
return (
f"⚠️ 知识库中未找到关于 '{query}' 的充分信息。\n"
"建议:可以尝试使用网络搜索工具获取更多信息。"
)
return docs
# 定义工具StructuredTool
qa_tool = StructuredTool.from_function(
func=query_retrieval_knowledge, # 工具函数
name="query_retrieval_knowledge", # 工具名称
description=(
"🎯 专用于回答 LangChain 技术相关问题的知识库检索工具。\n"
"适用范围:LangChain、LangGraph、LangSmith、LCEL、Agent、RAG、Retriever、Embedding、Prompt 等相关技术。\n"
"⚠️ 限制:仅包含 LangChain 相关文档,不适用于其他领域问题(如烹饪、历史、科学等)。\n"
"如果问题与 LangChain 无关,请使用网络搜索工具 tavily_search_results_json。"
), # 工具描述
args_schema=QAWithRetrievalArgs, # 工具输入参数
return_direct=False # 是否直接返回工具输出,而不是作为消息内容
)
result = qa_tool.invoke("LangChain这个框架是什么?")
print(result)
3. 定义敏感数据知识库工具 链接到标题
# 定义高风险知识库敏感数据查询工具
class SensitiveKnowledgeQueryArgs(BaseModel):
query: str = Field(description="查询的敏感主题或关键词")
data_category: str = Field(
description="数据类别:confidential(机密), internal(内部), sensitive(敏感)",
default="confidential"
)
def query_sensitive_knowledge(query: str, data_category: str = "confidential") -> str:
"""
⚠️ 高风险操作:基于 RAG 的敏感知识库检索
使用向量检索 + BM25 混合检索敏感文档。
包含机密文档、内部资料、敏感信息等。
风险等级:🔴 高风险
- 访问机密文档和敏感信息
- 可能涉及商业机密、个人隐私
- 需要权限验证和人工审核批准
"""
print(f"\n🔴 [高风险操作] 敏感知识库 RAG 检索")
print(f" 数据类别: {data_category}")
print(f" 查询内容: {query}")
# 1.定义敏感数据类别标签
sensitive_categories = {
"confidential": "🔴 机密级",
"internal": "🟡 内部级",
"sensitive": "🟠 敏感级"
}
# 2.获取类别标签
category_label = sensitive_categories.get(data_category, "未知级别")
# 3.使用敏感数据混合检索器进行 RAG 检索
print(f" 正在检索敏感知识库...")
retrieval_chain = sensitive_ensemble_retriever | format_docs
docs = retrieval_chain.invoke(query)
# 检查检索结果质量
if not docs or len(docs.strip()) < 50:
return (
f"⚠️ 敏感知识库中未找到关于 '{query}' 的相关信息。\n"
f"数据类别:{category_label}\n"
f"提示:请确认查询关键词是否准确,或尝试使用不同的关键词。\n"
f"可查询的类别:机密(confidential)、内部(internal)、敏感(sensitive)"
)
# 根据数据类别过滤结果(可选:基于文档内容中的密级标记)
# 这里简单处理,返回所有检索结果
# 格式化输出
output = f"{category_label} 检索结果\n"
output += "="*70 + "\n\n"
output += "📋 检索到的敏感信息:\n\n"
output += docs
output += "\n\n" + "="*70
output += f"\n\n⚠️ 安全警告:\n"
output += f"- 以上为{category_label}信息,请妥善保管,不得外泄!\n"
output += f"- 访问已记录,将用于安全审计\n"
output += f"- 如需分享,请确保接收方具有相应权限\n"
output += f"- 查询时间:{__import__('datetime').datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
return output
# 定义工具StructuredTool.from_function
sensitive_knowledge_tool = StructuredTool.from_function(
func=query_sensitive_knowledge, # 工具函数
name="query_sensitive_knowledge", # 工具名称
description=(
"🔴 高风险操作:敏感知识库查询工具\n"
"用于查询知识库中的机密文档、内部资料、敏感信息等受限数据。\n"
"⚠️ 警告:此操作需要人工审核批准!\n"
"适用场景:\n"
"- 查询财务数据、战略规划等机密信息\n"
"- 访问技术文档、人事信息等内部资料\n"
"- 获取用户数据、客户信息等敏感数据\n"
"安全提示:仅在必要时使用,确保有相应权限。"
), # 工具描述
args_schema=SensitiveKnowledgeQueryArgs, # 工具输入参数
return_direct=False # 是否直接返回工具输出,而不是作为消息内容
)
result = sensitive_knowledge_tool.invoke("查询一下2024年Q4财务报告数据")
print(result)
# 定义工具列表,将工具添加到列表中
tools = [qa_tool, web_search, sensitive_knowledge_tool]
4. Agent执行工具 链接到标题
from typing import TypedDict
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 创建并运行 Agent
class Context(TypedDict):
user_role: str
# 创建线程ID
config = {"configurable": {"thread_id": "test-thread-final"}}
# 创建Agent
agent = create_agent(
tools=tools, # 工具列表
model=model, # 模型
debug=False, # 是否开启调试模式,开启后会打印详细信息
checkpointer=InMemorySaver(), # 检查点保存器,用于保存和恢复Agent状态
context_schema=Context # 上下文模式,定义了Agent在运行时的上下文信息
)
# 执行Agent,使用流式输出模式
for event in agent.stream(
{"messages": [{"role": "user", "content": "LangChain支持哪些模型?"}]},
config=config,
stream_mode="values",
context={"user_role": "大模型工程师"}
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai":
if hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
tool_call = last_msg.tool_calls[0]
print(f"🤖 [AI 决策]: 调用工具 -> {tool_call['name']}")
print(f" 参数: {tool_call.get('args', {})}")
elif last_msg.content:
print(f"\n💬 [AI 回复]:\n{last_msg.content}")
5. 询问复杂问题,需要多个工具协作完成 链接到标题
# 执行Agent,使用流式输出模式
for event in agent.stream(
{"messages": [{"role": "user", "content": "比较RAG和Agentic RAG的区别,并推荐使用场景"}]},
config=config,
stream_mode="values",
context={"user_role": "大模型工程师"}
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai":
if hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
tool_call = last_msg.tool_calls[0]
print(f"🤖 [AI 决策]: 调用工具 -> {tool_call['name']}")
print(f" 参数: {tool_call.get('args', {})}")
elif last_msg.content:
print(f"\n💬 [AI 回复]:\n{last_msg.content}")
当Agent执行时,我们可以观察到以下效果:
智能路由:对于"LangChain支持哪些模型?“这类知识性问题,Agent会自动选择
query_retrieval_knowledge工具多工具协作:对于复杂问题如"比较RAG和Agentic RAG的区别,并推荐使用场景”,Agent可能会:
首先调用知识库工具获取技术细节
然后基于检索到的信息进行分析和推理,是否符合预期,是否需要调用其他工具
所有检索到的信息都符合预期,最后给出综合性的回答和建议
- 错误处理:如果Tool调用失败(如知识库中无相关内容),Agent会根据错误信息调整策略,可能尝试重新表述查询或告知用户限制
第四阶段、构建Agentic RAG系统 链接到标题
一、 Agentic RAG系统 链接到标题
LangChain 1.0引入了强大的中间件系统,允许在Agent执行的关键节点插入自定义逻辑。在创建Agentic RAG系统是将Tool与LLM智能体结合的核心环节。这个过程涉及提示词工程、Agent创建和执行器中间件配置三个关键步骤,每个步骤都对最终系统的表现有重要影响。在实现Agentic RAG系统时,需要注意以下几个方面:
提示词工程:精心设计的提示词能够引导LLM生成符合预期的输出。在Agentic RAG系统中,提示词应包含必要的上下文信息,以便LLM能够理解用户意图并生成相关内容。
Agent创建:使用LangChain 1.0的Agent类创建智能体。在创建时,需要指定LLM模型、工具列表和中间件配置。
执行器中间件配置:在执行器中配置中间件,以便在Agent执行过程中插入自定义逻辑。例如,在RAG系统中,中间件可以用于检索相关文档、生成上下文信息等。
二、 定义中间件 链接到标题
本次实验将实现一个基于LangChain 1.0的Agentic RAG系统,该系统能够根据用户输入的问题,从知识库中检索相关信息,并使用LLM生成符合预期的回答。一共加入了以下几个组件:
知识库:用于存储和检索相关信息的文档集合。
LLM模型:用于生成文本回答的语言模型。
智能体(Agent):负责接收用户输入、调用工具(如检索知识库)、执行LLM生成回答的组件。
中间件(Middleware):在智能体执行过程中插入自定义逻辑的组件,用于处理输入、输出、错误等情况。
before_model(SummarizationMiddleware上下文压缩):在LLM模型调用之前执行的中间件,用于压缩上下文信息,减少输入 tokens 数量。
wrap_tool_model(ToolRetryMiddleware工具自动重试):在调用工具(如知识库检索)时执行的中间件,用于自动重试工具调用,直到成功或达到最大重试次数。
after_model(ToolLoggingMiddleware 日志记录):在LLM模型调用之后执行的中间件,用于记录模型输出和调用信息,方便调试和分析。
after_model(ToolCallLimitMiddleware 工具调用次数限制):在LLM模型调用之后执行的中间件,用于限制工具调用次数,防止无限循环调用。
after_model(HumanInTheLoopMiddleware 人工干预):在LLM模型调用之后执行的中间件,用于人工干预模型输出,如检查回答是否符合预期、修正错误等。
1. 上下文压缩中间件(before_model) 链接到标题
- 核心作用:在上下文信息中压缩和提取关键信息,减少输入 tokens 数量,提高模型生成效率。
from langchain.agents.middleware import SummarizationMiddleware
# 定义摘要中间件
summarization_middleware = SummarizationMiddleware(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1), # 摘要模型
max_tokens_before_summary=500, # 触发摘要的最大 tokens 数量
messages_to_keep=3, # 保留的对话历史消息数量
summary_prompt="请将以下对话历史进行摘要,保留关键决策点和技术细节:\n\n{messages}\n\n摘要:" # 摘要提示
)
2. 自动工具重试中间件(wrap_tool_call) 链接到标题
- 核心作用:当调用工具失败或者出错时,可以自动重试调用,直到达到最大重试次数或者成功为止。
from langchain.agents.middleware import ToolRetryMiddleware
# 定义重试中间件
retry_middleware = ToolRetryMiddleware(
max_retries=3, # 最大重试次数
tools=["query_retrieval_knowledge", "tavily_search_results_json","query_sensitive_knowledge"], # 要重试的工具列表
retry_on=(ConnectionError, RuntimeError), # 要重试的异常类型
on_failure="return_message", # 失败时的处理方式,这里是返回失败信息
backoff_factor=1.5 # 重试间隔因子,每次重试间隔会增加这个因子倍
)
3. Tool 调用日志中间件(after_model) 链接到标题
- 核心作用:对Tool工具调用时收集调用信息,如调用次数、调用参数、调用结果等日志信息。
"""
Tool 调用日志中间件
功能:
1. 记录所有工具调用的详细信息
2. 性能统计和分析
3. JSON 文件持久化
4. 异常检测和告警
"""
import json
import time
from datetime import datetime
from pathlib import Path
from typing import Any, Dict, List, Optional, Callable
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse, AgentState
class ToolCallLogger:
"""工具调用日志记录器"""
def __init__(self, log_dir: str = "LangChain_AgenticRAG/logs"):
self.log_dir = Path(log_dir)
self.log_dir.mkdir(parents=True, exist_ok=True)
self.current_session_logs: List[Dict[str, Any]] = []
self.session_start_time = datetime.now()
self.tool_call_times: Dict[str, float] = {} # 记录工具调用开始时间
# Token 使用统计
self.total_input_tokens = 0
self.total_output_tokens = 0
self.total_tokens = 0
self.cache_hit_tokens = 0
def get_log_file_path(self) -> Path:
"""获取当前日志文件路径"""
date_str = datetime.now().strftime("%Y%m%d")
return self.log_dir / f"tool_calls_{date_str}.json"
def log_tool_call(
self,
tool_name: str,
tool_input: Any,
tool_output: Any,
success: bool,
error: Optional[str] = None,
metadata: Optional[Dict[str, Any]] = None,
token_usage: int = 0,
):
"""记录单次工具调用"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"tool_name": tool_name,
"input": str(tool_input)[:500], # 限制长度
"output": str(tool_output)[:1000] if success else None,
"success": success,
"error": error,
"metadata": metadata or {},
"token_usage": token_usage,
}
self.current_session_logs.append(log_entry)
# 实时写入文件
self._append_to_file(log_entry)
# 打印日志
status = "✅" if success else "❌"
if not success and error:
print(f" Error: {error}")
def accumulate_tokens(
self,
input_tokens: int,
output_tokens: int,
total_tokens: int,
cache_hit: int = 0
):
"""累计 token 使用量"""
self.total_input_tokens += input_tokens
self.total_output_tokens += output_tokens
self.total_tokens += total_tokens
self.cache_hit_tokens += cache_hit
print(f"📊 [Token Usage] 输入: {input_tokens}, 输出: {output_tokens}, 总计: {total_tokens}")
if cache_hit > 0:
print(f" 缓存命中: {cache_hit} tokens")
def _append_to_file(self, log_entry: Dict[str, Any]):
"""追加日志到文件"""
log_file = self.get_log_file_path()
# 读取现有日志
if log_file.exists():
with open(log_file, 'r', encoding='utf-8') as f:
try:
logs = json.load(f)
except json.JSONDecodeError:
logs = []
else:
logs = []
# 添加新日志
logs.append(log_entry)
# 写回文件
with open(log_file, 'w', encoding='utf-8') as f:
json.dump(logs, f, indent=2, ensure_ascii=False)
def get_statistics(self) -> Dict[str, Any]:
"""获取统计信息"""
if not self.current_session_logs:
return {"message": "No logs yet"}
total_calls = len(self.current_session_logs)
successful_calls = sum(1 for log in self.current_session_logs if log["success"])
failed_calls = total_calls - successful_calls
# 统计工具使用次数
tool_counts = {}
for log in self.current_session_logs:
tool_name = log["tool_name"]
tool_counts[tool_name] = tool_counts.get(tool_name, 0) + 1
return {
"total_calls": total_calls,
"successful_calls": successful_calls,
"failed_calls": failed_calls,
"success_rate": f"{(successful_calls/total_calls*100):.1f}%" if total_calls > 0 else "0%",
"tool_usage": tool_counts,
"token_usage": {
"total_input_tokens": self.total_input_tokens,
"total_output_tokens": self.total_output_tokens,
"total_tokens": self.total_tokens,
"cache_hit_tokens": self.cache_hit_tokens
},
"session_duration": str(datetime.now() - self.session_start_time)
}
def print_statistics(self):
"""打印统计信息"""
stats = self.get_statistics()
print("\n" + "="*70)
print("📊 Tool Call Statistics")
print("="*70)
for key, value in stats.items():
print(f" {key}: {value}")
print("="*70)
class ToolLoggingMiddleware(AgentMiddleware):
"""
创建工具日志中间件
使用 @wrap_model_call 装饰器从 ModelRequest 获取消息历史
"""
def __init__(self, log_dir: str = "LangChain_AgenticRAG/logs"):
super().__init__()
self.logger = ToolCallLogger()
def after_model(self,state: AgentState, runtime) -> None:
"""
从 ModelRequest 中获取消息历史,记录工具调用信息
Args:
request: ModelRequest 包含 state (包括 messages)
handler: 处理函数,执行实际的模型调用
Returns:
ModelResponse 模型响应
"""
# 从 state 获取消息历史
messages = state.get("messages", [])
# print(f"🔍 [Tool Logging] 分析消息历史,{messages} 消息")
# 检查消息历史中的工具调用和结果
for msg in messages:
# 检测 AI 消息并提取 token 使用信息
if hasattr(msg, 'type') and msg.type == 'ai':
# 优先从 usage_metadata 获取
if hasattr(msg, 'usage_metadata') and msg.usage_metadata:
input_tokens = msg.usage_metadata.get('input_tokens', 0)
output_tokens = msg.usage_metadata.get('output_tokens', 0)
total_tokens = msg.usage_metadata.get('total_tokens', 0)
# 获取缓存命中信息
cache_hit = 0
if 'input_token_details' in msg.usage_metadata:
cache_hit = msg.usage_metadata['input_token_details'].get('cache_read', 0)
# 累计 token
self.logger.accumulate_tokens(input_tokens, output_tokens, total_tokens, cache_hit)
# 备选:从 response_metadata 获取
elif hasattr(msg, 'response_metadata') and msg.response_metadata:
token_usage = msg.response_metadata.get('token_usage', {})
if token_usage:
input_tokens = token_usage.get('prompt_tokens', 0)
output_tokens = token_usage.get('completion_tokens', 0)
total_tokens = token_usage.get('total_tokens', 0)
cache_hit = token_usage.get('prompt_cache_hit_tokens', 0)
# 累计 token
self.logger.accumulate_tokens(input_tokens, output_tokens, total_tokens, cache_hit)
# 检测 AI 消息中的工具调用请求
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tool_call in msg.tool_calls:
# tool_call 可能是字典或对象,需要兼容两种方式
if isinstance(tool_call, dict):
tool_name = tool_call.get('name', 'unknown')
tool_args = tool_call.get('args', {})
tool_id = tool_call.get('id', 'unknown_id')
else:
tool_name = getattr(tool_call, 'name', 'unknown')
tool_args = getattr(tool_call, 'args', {})
tool_id = getattr(tool_call, 'id', 'unknown_id')
# 记录工具调用开始时间
if tool_id not in self.logger.tool_call_times:
self.logger.tool_call_times[tool_id] = time.time()
print(f"\n🔧 [Tool Logging] 检测到工具调用: {tool_name}")
print(f" 工具ID: {tool_id}")
print(f" 参数: {str(tool_args)[:200]}...")
# 检测工具返回消息
if hasattr(msg, 'type') and msg.type == 'tool':
tool_name = getattr(msg, 'name', 'unknown')
tool_content = getattr(msg, 'content', '')
tool_call_id = getattr(msg, 'tool_call_id', 'unknown_id')
token_usage = getattr(msg, 'token_usage', 0)
# 判断是否成功
success = not tool_content.startswith('❌') and not tool_content.startswith('Error')
error_msg = tool_content if not success else None
# 记录日志
self.logger.log_tool_call(
tool_name=tool_name,
tool_input="[从消息历史提取]",
tool_output=tool_content,
success=success,
error=error_msg,
metadata={
"tool_call_id": tool_call_id,
"timestamp": datetime.now().isoformat(),
"message_type": msg.type
},
token_usage=token_usage
)
# 打印当前统计信息
self.logger.print_statistics()
# 实例化日志中间件
logging_middleware = ToolLoggingMiddleware(log_dir="./logs")
4. 工具调用限制中间件(after_model) 链接到标题
核心作用:对工具调用设置最大次数限制,避免对工具的滥用。
注意:一个ToolCallLimitMiddleware里面的tool_name只能限制一个工具,如果想要限制多个工具的话就需要定义多个中间件来实现!
from langchain.agents.middleware import ToolCallLimitMiddleware
# 限制 query_retrieval_knowledge 工具调用次数
retrieval_limit_middleware = ToolCallLimitMiddleware(
tool_name="query_retrieval_knowledge",
run_limit=3, # 每次运行最多调用 3 次
exit_behavior="continue" # 超限后继续执行,但阻止工具调用
)
# 限制 query_sensitive_knowledge 工具调用次数
sensitive_limit_middleware = ToolCallLimitMiddleware(
tool_name="query_sensitive_knowledge",
run_limit=3, # 每次运行最多调用 3 次
exit_behavior="continue" # 超限后继续执行,但阻止工具调用
)
5. HITL 人工干预中间件(after_model) 链接到标题
- 核心作用:监控敏感知识库查询时,可以通过人工干预进行审核,确保查询结果的准确性和安全性。
from langchain.agents.middleware import HumanInTheLoopMiddleware
# 创建官方 HITL 中间件,监控敏感知识库查询工具
official_hitl_middleware = HumanInTheLoopMiddleware(
interrupt_on={"query_sensitive_knowledge": True}, # 监控敏感知识库查询工具
description_prefix="需要人工批准才能查询敏感知识库" # 提示前缀
)
6. 动态提示词中间件(wrap_model_call) 链接到标题
核心作用:能够根据检索次数来动态调整系统提示词,以提高检索效果。
注意:这里使用的装饰器dynamic_prompt,其实是wrap_model_call类型的中间件,包裹在model运行的生命周期里!
执行时机:在模型调用时动态修改 system prompt
from langchain.agents.middleware import dynamic_prompt
@dynamic_prompt
def rag_optimized_prompt(request: ModelRequest) -> str:
"""
根据检索状态动态生成提示词
核心逻辑:通过分析消息历史中的工具调用次数,确定当前所处的 RAG 阶段
"""
messages = request.messages if hasattr(request, 'messages') else []
# 统计所有工具调用中的知识库查询次数(包括检索和敏感查询)
retrieval_count = 0
for msg in messages:
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tool_call in msg.tool_calls:
name = tool_call.name if hasattr(tool_call, 'name') else tool_call.get('name')
# 统计知识库查询次数(包括检索和敏感查询)
if name == 'query_retrieval_knowledge' or name == 'tavily_search_results_json' or name == 'query_sensitive_knowledge':
retrieval_count += 1
print(f"DEBUG: 当前累计检索次数: {retrieval_count}")
# 基础提示词
base_prompt = """你是一个智能知识助手,能够自主检索信息并回答问题。
🔧 可用工具说明:
1. query_retrieval_knowledge: 专门用于 LangChain 技术问题(LangChain、LangGraph、Agent、RAG、Retriever 等)
2. tavily_search_results_json: 用于通用问题的网络搜索(烹饪、历史、科学、新闻等)
3. query_sensitive_knowledge: 🔴 高风险工具 - 查询敏感知识库(财务数据、战略规划、客户信息等机密资料)
⚠️ 工具选择原则:
- 如果问题涉及 LangChain 相关技术 → 使用 query_retrieval_knowledge
- 如果问题与 LangChain 无关(如烹饪、历史、科学等) → 直接使用 tavily_search_results_json
- 如果问题涉及敏感数据查询(财务、战略、客户、人事等) → 使用 query_sensitive_knowledge
- 不要对非 LangChain 问题调用知识库检索工具
🔴 高风险工具使用注意事项:
- query_sensitive_knowledge 需要人工审核批准才能执行
- 仅在用户明确请求查询机密/敏感信息时使用
- 调用此工具后,系统会暂停等待管理员批准
- 适用场景:财务报告、战略规划、客户档案、人事薪资、技术文档等
请遵循以下流程:
1. 分析用户问题的类型和复杂度
2. 判断问题是否与 LangChain 相关,或是否涉及敏感数据
3. 选择合适的检索工具
4. 评估检索结果的质量(覆盖率、完整性、相关性)
5. 如果结果不足,主动进行补充检索
6. 综合所有信息生成最终回答
"""
# 初始状态:未进行任何知识库查询
if retrieval_count == 0:
return base_prompt + """
【当前状态:初始阶段】
⚠️ 重要:你还没有进行任何检索!
请先判断问题类型:
- 如果是 LangChain 相关问题 → 使用 query_retrieval_knowledge
- 如果是其他领域问题 → 使用 tavily_search_results_json
- 如果涉及敏感数据查询 → 使用 query_sensitive_knowledge(需人工批准)
❌ 禁止在没有检索的情况下直接回答问题。
"""
# 信息评估阶段:已进行 1-2 次知识库查询
elif retrieval_count < 3:
return base_prompt + f"""
【当前状态:信息评估(已检索 {retrieval_count} 次)】
请检查上一步工具返回的搜索结果:
1. 信息是否覆盖了用户问题的全部维度?
2. 多个来源的信息是否一致?
👉 决策路径:
- 如果信息不足或有歧义 -> 请换个关键词或角度进行补充检索。
- 如果信息已经充分 -> 请根据上下文生成最终回答。
"""
# 最终回答阶段:已进行 3 次及以上知识库查询
else:
return base_prompt + f"""
【当前状态:最终回答(已检索 {retrieval_count} 次)】
🛑 已达到最大检索次数限制,请停止检索!
请必须基于当前已有的所有信息,生成最终的回答。
如果检索到的信息仍不能完全回答问题,请诚实地说明信息的局限性或缺失部分。
"""
三、 集成中间件到Agent 链接到标题
- 注意:after_model的注册顺序与最终执行顺序相反,是逆序执行,所以需要注意注册顺序,HITL人工干预中间件能够中断程序的要放在执行的最后,注册顺序为第一位置,下面顺序和截图都做过了修改!
# 中间件列表 (注意顺序)
middlewares = [
# before_model: 准备阶段,上下文压缩中间件
summarization_middleware,
# wrap_model_call: 模型调用包裹,智能切换系统提示词
rag_optimized_prompt,
# after_model: 后处理(逆序执行,所以倒着写)
official_hitl_middleware, # 最后执行:人工审核(可能中断)
logging_middleware, # 倒数第二:记录日志
sensitive_limit_middleware, # 倒数第三:限制敏感工具
retrieval_limit_middleware, # 最先执行:限制检索工具
# wrap_tool_call: 工具调用包裹
retry_middleware,
]
from typing import TypedDict
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 创建并运行 Agent
class Context(TypedDict):
user_role: str
# 配置线程 ID
config = {"configurable": {"thread_id": "test-thread-final"}}
# 创建 Agent
agent = create_agent(
tools=tools,
model=model,
middleware=middlewares,
debug=False, # 关闭调试模式
checkpointer=InMemorySaver(), # 内存检查点,用于存储状态
context_schema=Context # 上下文模式,定义了状态的结构
)
- 通过
langgraph studio可视化调试,观察Agent的运行状态和行为
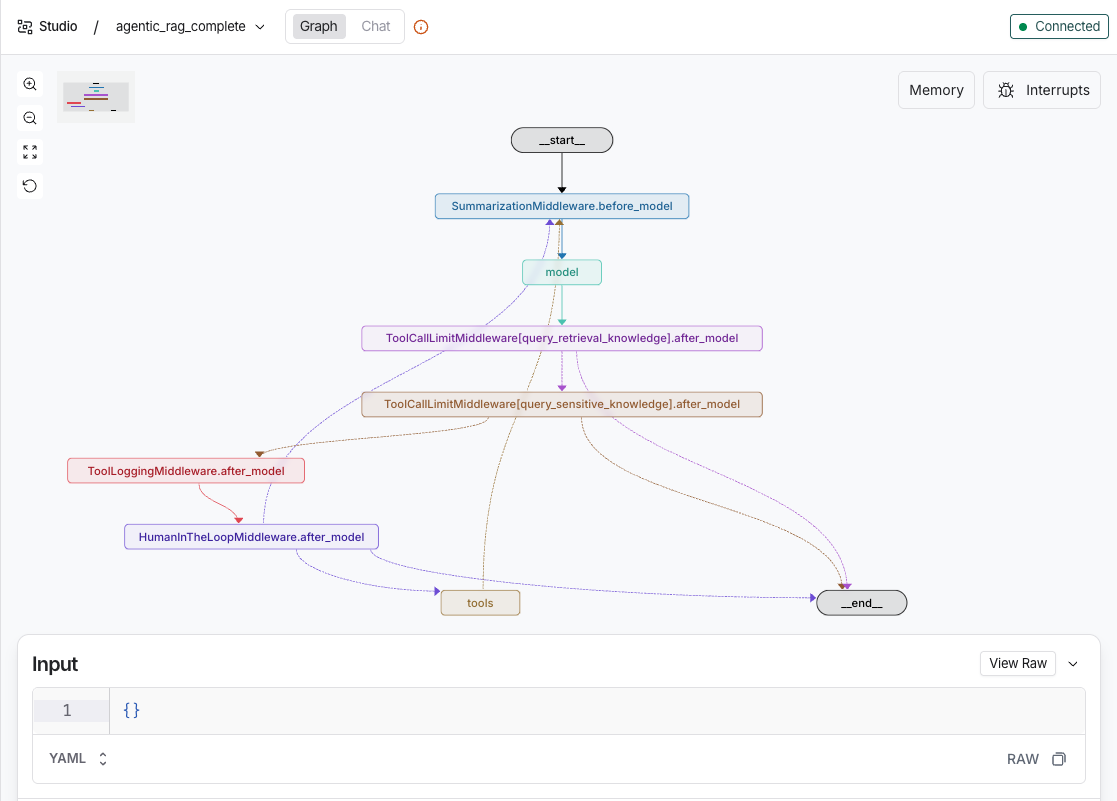
1. 测试HITL中间件触发 链接到标题
# 导入 Command 用于恢复执行
from langgraph.types import Command
# 导入 HITL 相关类
from langchain.agents.middleware.human_in_the_loop import (
HITLResponse,
ApproveDecision,
EditDecision,
RejectDecision
)
def run_hitl_interactive_test():
"""
运行 HITL 人工干预交互式测试
参考 HITL_demo.py 的完整流程
"""
print("\n" + "="*70)
print("🚀 开始执行 Agentic RAG 测试 (HITL 人工干预模式)")
print("="*70)
# 测试提示词:触发敏感知识库查询
user_input = "帮我查询一下2024年Q4财务报告数据的详细内容。"
print(f"\n[用户]: {user_input}")
# === 第一步:初始执行 ===
print("\n[系统]: 开始处理请求...")
for event in agent.stream(
{"messages": [{"role": "user", "content": user_input}]},
config=config,
stream_mode="values",
context={"user_role": "财务分析师"}
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
print(f"[AI 决策]: 准备调用工具 -> {last_msg.tool_calls[0]['name']}")
# === 第二步:观察中断状态 ===
snapshot = agent.get_state(config)
print(f"\n--- 🛑 执行已暂停 (HITL Middleware 触发) ---")
print(f"下一步骤: {snapshot.next}")
print(f"任务数量: {len(snapshot.tasks) if snapshot.tasks else 0}")
# 检查是否有待处理的任务(表示中断发生)
if snapshot.tasks:
last_message = snapshot.values["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
tool_call = last_message.tool_calls[0]
print(f"\n{'='*70}")
print("🔴 检测到高风险操作:敏感知识库查询")
print(f"{'='*70}")
print(f"工具名称: {tool_call['name']}")
print(f"查询内容: {tool_call['args'].get('query', 'N/A')}")
print(f"数据类别: {tool_call['args'].get('data_category', 'confidential')}")
print(f"{'='*70}")
# === 第三步:人工决策 ===
approval = input("\n[管理员]: 是否批准此操作? (y/n/e[编辑]): ").strip().lower()
if approval == 'y':
# === 批准操作 ===
print("\n[系统]: ✅ 操作已批准,继续执行...")
hitl_response = HITLResponse(
decisions=[ApproveDecision(type="approve")]
)
# 第四步:恢复执行
for event in agent.stream(
Command(resume=hitl_response),
config=config,
stream_mode="values"
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "tool":
print(f"\n[工具输出]:\n{last_msg.content}")
elif last_msg.type == "ai" and last_msg.content:
print(f"\n[AI 最终回复]: {last_msg.content}")
elif approval == 'e':
# === 编辑操作 ===
print("\n[系统]: ✏️ 编辑模式...")
print(f"当前参数: {tool_call['args']}")
new_query = input(f"新查询内容 (当前: {tool_call['args'].get('query', '')},留空保持不变): ").strip()
new_category = input(f"新数据类别 (当前: {tool_call['args'].get('data_category', 'confidential')},留空保持不变): ").strip()
updated_args = tool_call['args'].copy()
if new_query:
updated_args['query'] = new_query
if new_category:
updated_args['data_category'] = new_category
print(f"\n[系统]: 使用更新后的参数继续执行...")
print(f"更新后的参数: {updated_args}")
hitl_response = HITLResponse(
decisions=[EditDecision(
type="edit",
edited_action={
"name": tool_call['name'],
"args": updated_args
}
)]
)
for event in agent.stream(
Command(resume=hitl_response),
config=config,
stream_mode="values"
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "tool":
print(f"\n[工具输出]:\n{last_msg.content}")
elif last_msg.type == "ai" and last_msg.content:
print(f"\n[AI 最终回复]: {last_msg.content}")
else:
# === 拒绝操作 ===
print("\n[系统]: ❌ 操作被拒绝")
rejection_reason = input("拒绝原因 (可选): ").strip() or "操作被管理员拒绝,权限不足"
hitl_response = HITLResponse(
decisions=[RejectDecision(
type="reject",
message=rejection_reason
)]
)
for event in agent.stream(
Command(resume=hitl_response),
config=config,
stream_mode="values"
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"\n[AI 回复]: {last_msg.content}")
elif last_msg.type == "tool":
print(f"\n[工具消息]: {last_msg.content}")
print("\n[系统]: 流程已终止")
else:
print("⚠️ 没有检测到待处理的工具调用")
else:
print("ℹ️ 流程已完成,没有触发中断")
if snapshot.values.get("messages"):
last_msg = snapshot.values["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"\n[最终回复]: {last_msg.content}")
print("\n" + "="*70)
print("✅ HITL 测试完成!")
print("="*70)
# 打印统计信息
print("\n📊 中间件统计信息:")
logging_middleware.logger.print_statistics()
run_hitl_interactive_test()
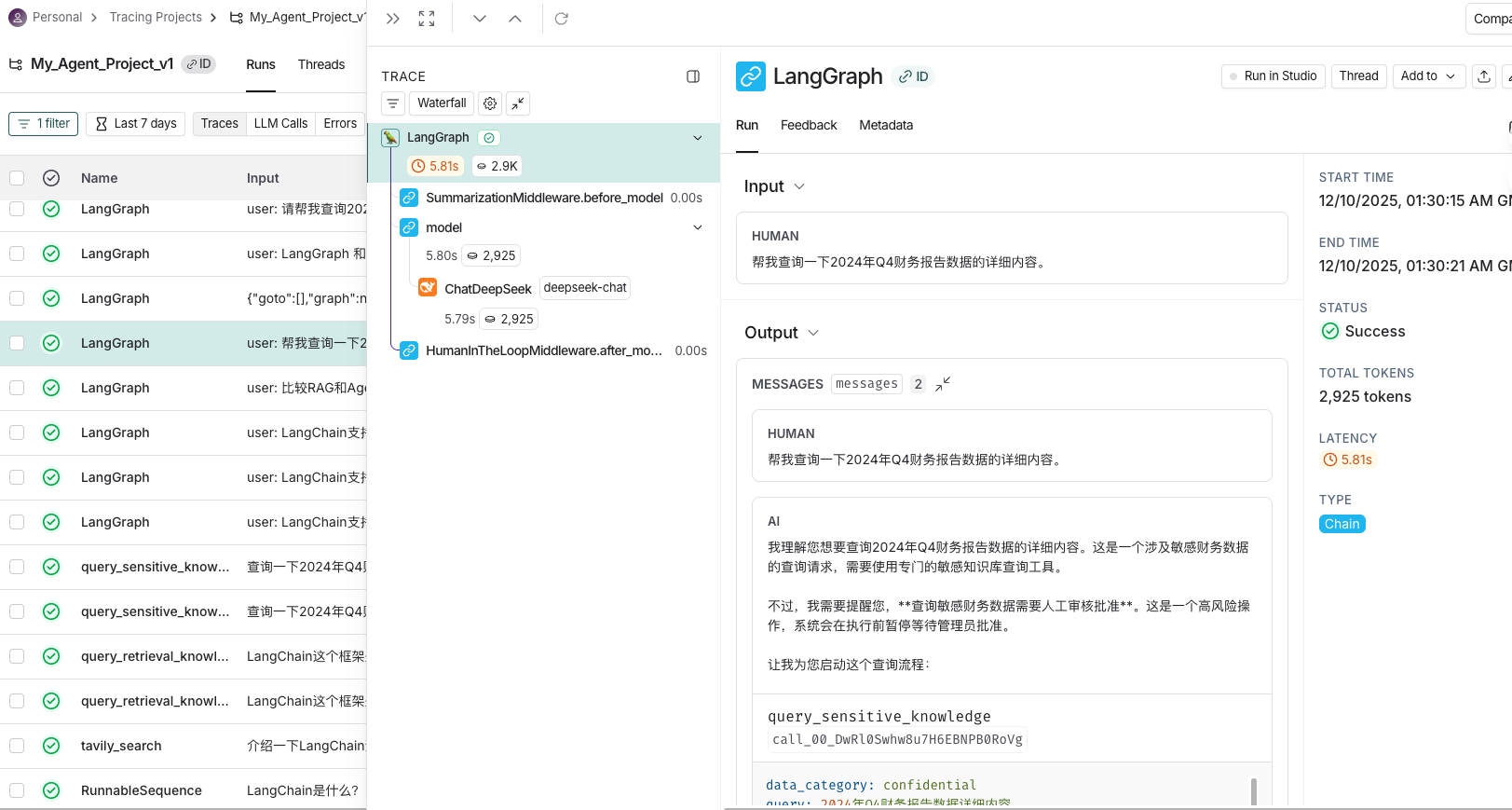
- 在LangSmith页面中观察运行流程:
2. 测试普通 RAG 检索测试 链接到标题
def run_normal_rag_test():
"""
运行普通 RAG 检索测试
测试 query_retrieval_knowledge 工具的检索流程
"""
print("\n" + "="*70)
print("🚀 开始执行普通 RAG 检索测试")
print("="*70)
# 测试提示词:触发 LangChain 知识库检索
test_queries = [
"LangChain 中的 Agent 是什么?它有哪些核心组件?",
"如何在 LangChain 中使用 RAG 进行问答?",
"LangGraph 和 LangChain 有什么区别?"
]
print("\n可用的测试问题:")
for i, query in enumerate(test_queries, 1):
print(f"{i}. {query}")
choice = input("\n请选择测试问题 (1-3) 或输入自定义问题: ").strip()
if choice.isdigit() and 1 <= int(choice) <= len(test_queries):
user_input = test_queries[int(choice) - 1]
else:
user_input = choice if choice else test_queries[0]
print(f"\n[用户]: {user_input}")
print("\n[系统]: 开始处理请求...\n")
# 使用新的 thread_id 避免与 HITL 测试冲突
rag_config = {"configurable": {"thread_id": "rag-test-thread"}}
# 用于跟踪已打印的消息,避免重复
printed_message_ids = set()
# 执行 Agent 流程
for event in agent.stream(
{"messages": [{"role": "user", "content": user_input}]},
config=rag_config,
stream_mode="values",
context={"user_role": "开发者"}
):
if "messages" in event:
last_msg = event["messages"][-1]
# 使用消息 ID 来避免重复打印
msg_id = getattr(last_msg, 'id', None)
if msg_id and msg_id in printed_message_ids:
continue
if msg_id:
printed_message_ids.add(msg_id)
# 显示 AI 的思考过程
if last_msg.type == "ai":
if hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
tool_call = last_msg.tool_calls[0]
print(f"🤖 [AI 决策]: 调用工具 -> {tool_call['name']}")
print(f" 参数: {tool_call.get('args', {})}")
elif last_msg.content:
print(f"\n💬 [AI 回复]:\n{last_msg.content}")
# 显示工具执行结果
elif last_msg.type == "tool":
tool_name = getattr(last_msg, 'name', 'unknown')
print(f"\n🔧 [工具执行]: {tool_name}")
print(f"📄 [检索结果]:\n{'-'*70}")
# 只显示前500个字符,避免输出过长
content = last_msg.content
if len(content) > 500:
print(f"{content[:500]}...\n(结果已截断,共 {len(content)} 字符)")
else:
print(content)
print(f"{'-'*70}\n")
print("\n" + "="*70)
print("✅ 普通 RAG 检索测试完成!")
print("="*70)
# 打印统计信息
print("\n📊 中间件统计信息:")
logging_middleware.logger.print_statistics()
run_normal_rag_test()
- 下面是通过LangSmith可视化调试的截图,可以清晰地看到Agent的运行状态和行为,包括状态的变化、工具的使用、模型的调用等。
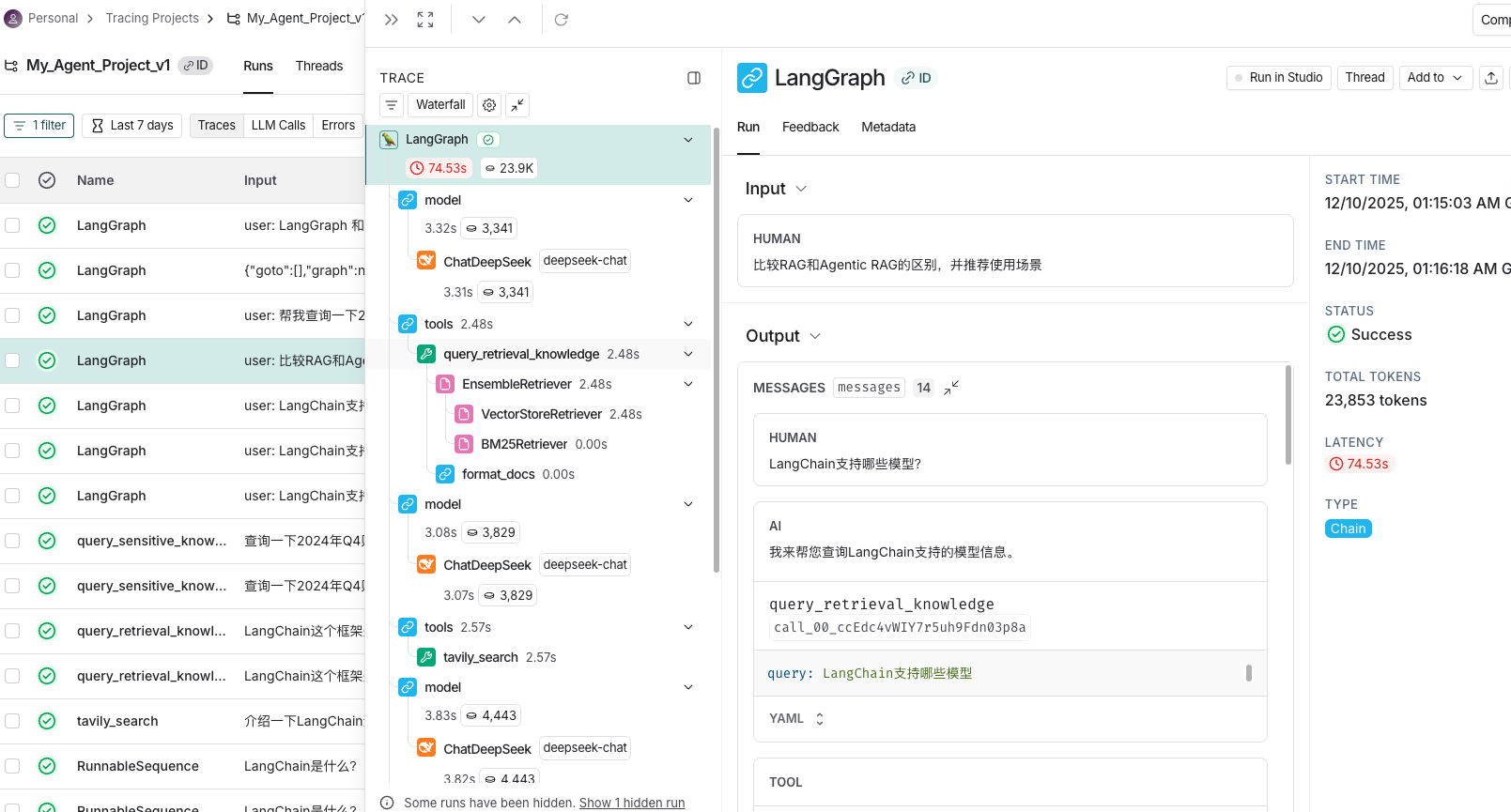
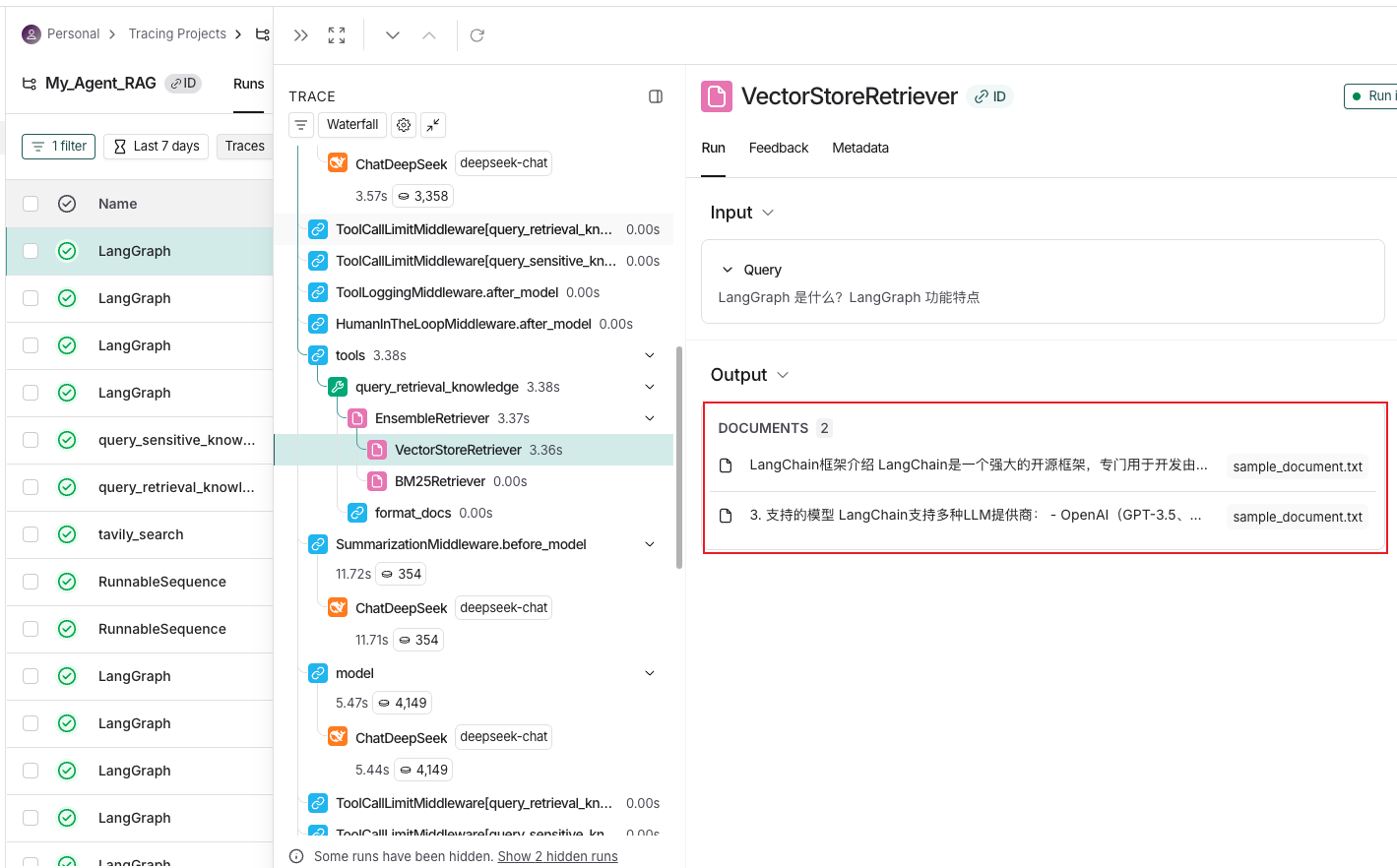
- 也可以通过LangSmith可视化调试的截图,可以清晰地看到能将RAG检索到的文本块信息查询出来!
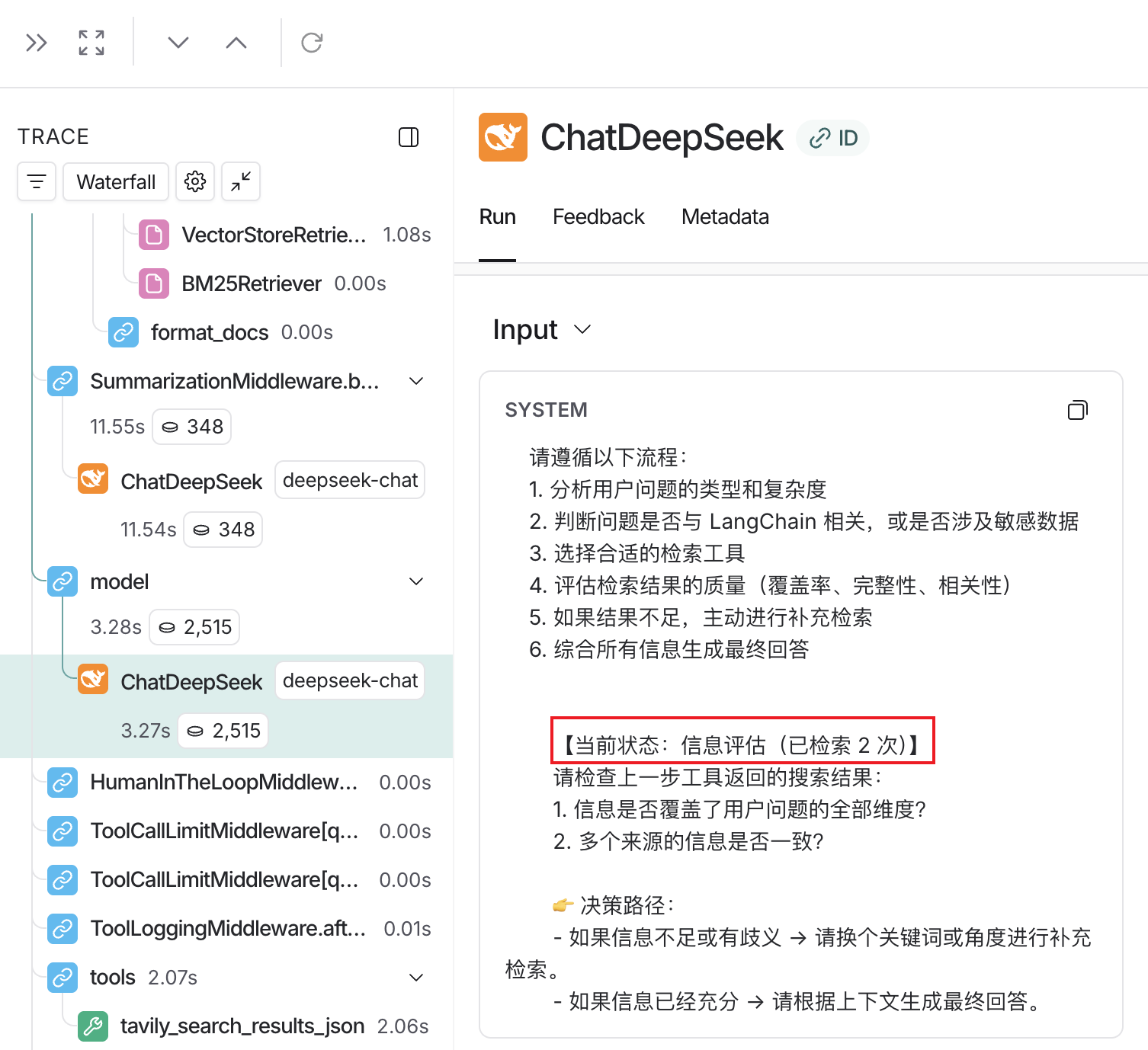
- 智能切换提示词中间件日志打印
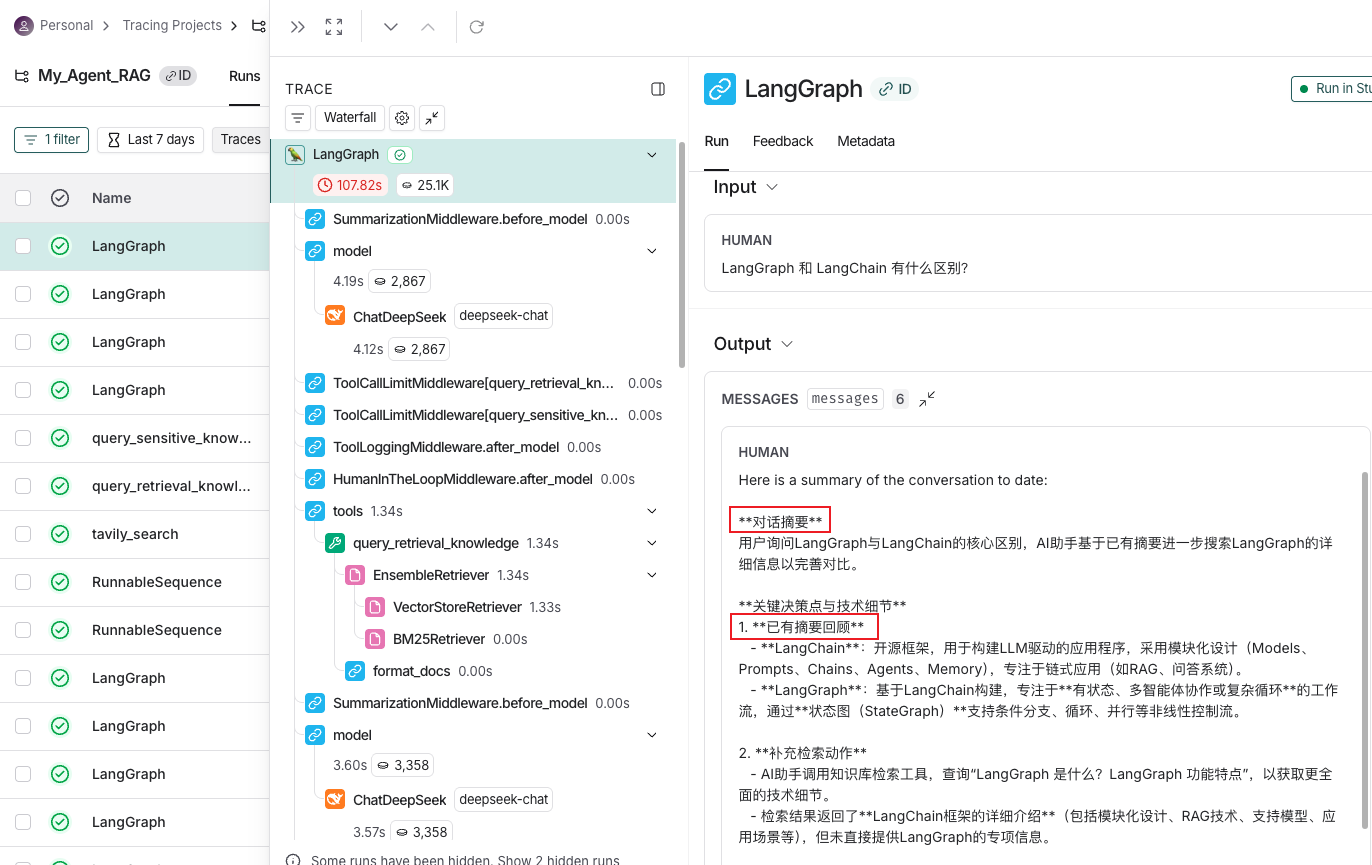
- 上下文压缩中间件日志打印
第五阶段、LangSmith监控工具 链接到标题
一、 LangSmith核心概念详解 链接到标题
大模型的行为往往存在不确定性,尤其在开发复杂的AI Agent应用程序时,过程中常包含众多子步骤。若希望掌握每一步的执行状态与结果,一方面可采用Debug方式实现实时控制,另一方面也可借助特定工具来观察和调试中间的交互流程。Langsmith 就是为应对这一挑战而设计的工具平台,由 LangChain 和 LangGraph 的团队创建。其核心目标是赋予LLM应用全面的可观测性,具体通过两大功能支柱实现:一是提供覆盖全链路的跟踪、日志与实时分析能力;二是构建集成的监控与调试环境,让每一个中间步骤都清晰可见。
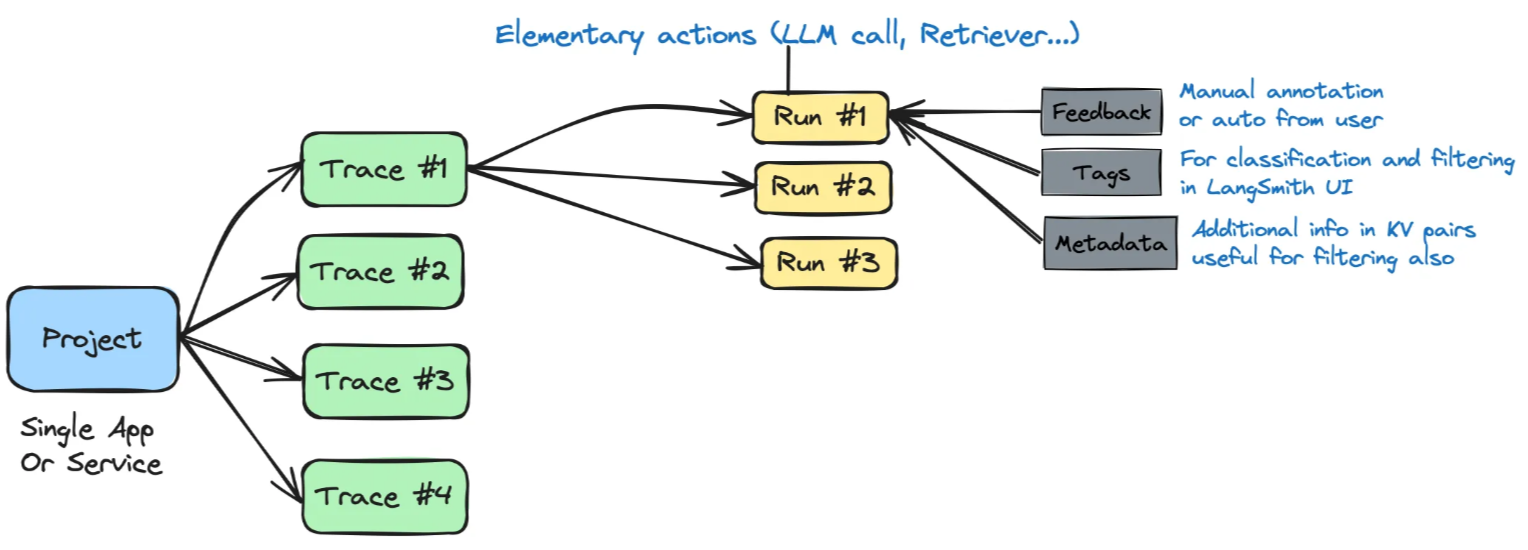
Project (项目):蓝色方块代表整个项目,可能是一个单独的应用程序或服务。
Traces (轨迹):绿色方块代表项目在不同条件或配置下的执行路径。每个轨迹可以是一个特定的用户会话、一个功能的执行,或者应用在特定输入下的行为。
Runs (运行):每个轨迹下的黄色方块表示特定轨迹的单次执行。这些是执行的实例,每个实例都是轨迹在特定条件下的实际运行。
Feedback, Tags, Metadata (反馈、标签、元数据):这部分显示了系统如何利用用户或自动化工具生成的反馈、标签和元数据来增强轨迹的管理和过滤。反馈可以用于改进未来的运行,标签和元数据可用于分类和筛选特定的轨迹或运行,以便在LangSmith的用户界面中更容易地管理和审查
1. Trace(追踪) 链接到标题
一次完整应用执行的全链路记录,从用户输入到最终输出的整个调用树。它可视化LLM应用的执行路径,帮助开发者快速定位问题。
- 作用:提供端到端的可见性,捕获所有输入、输出和中间步骤,是调试和性能分析的基础。
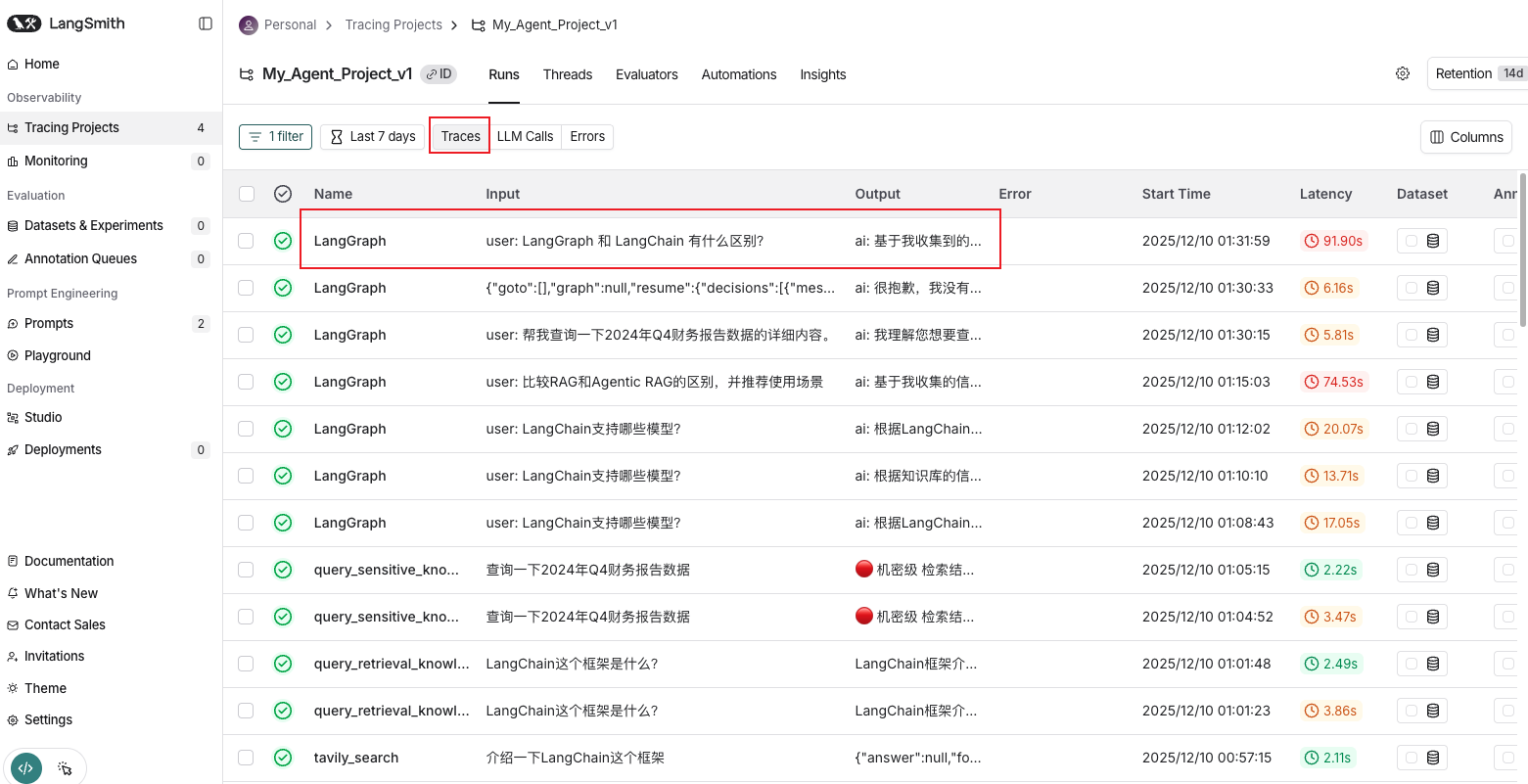
LangSmith可以追踪从用户输入到最终输出的完整流程,只要执行了invoke或者stream方法,就会自动记录一条Trace。包括:
Agent决策过程
工具调用详情
LLM调用参数和响应
检索结果质量
执行耗时分析
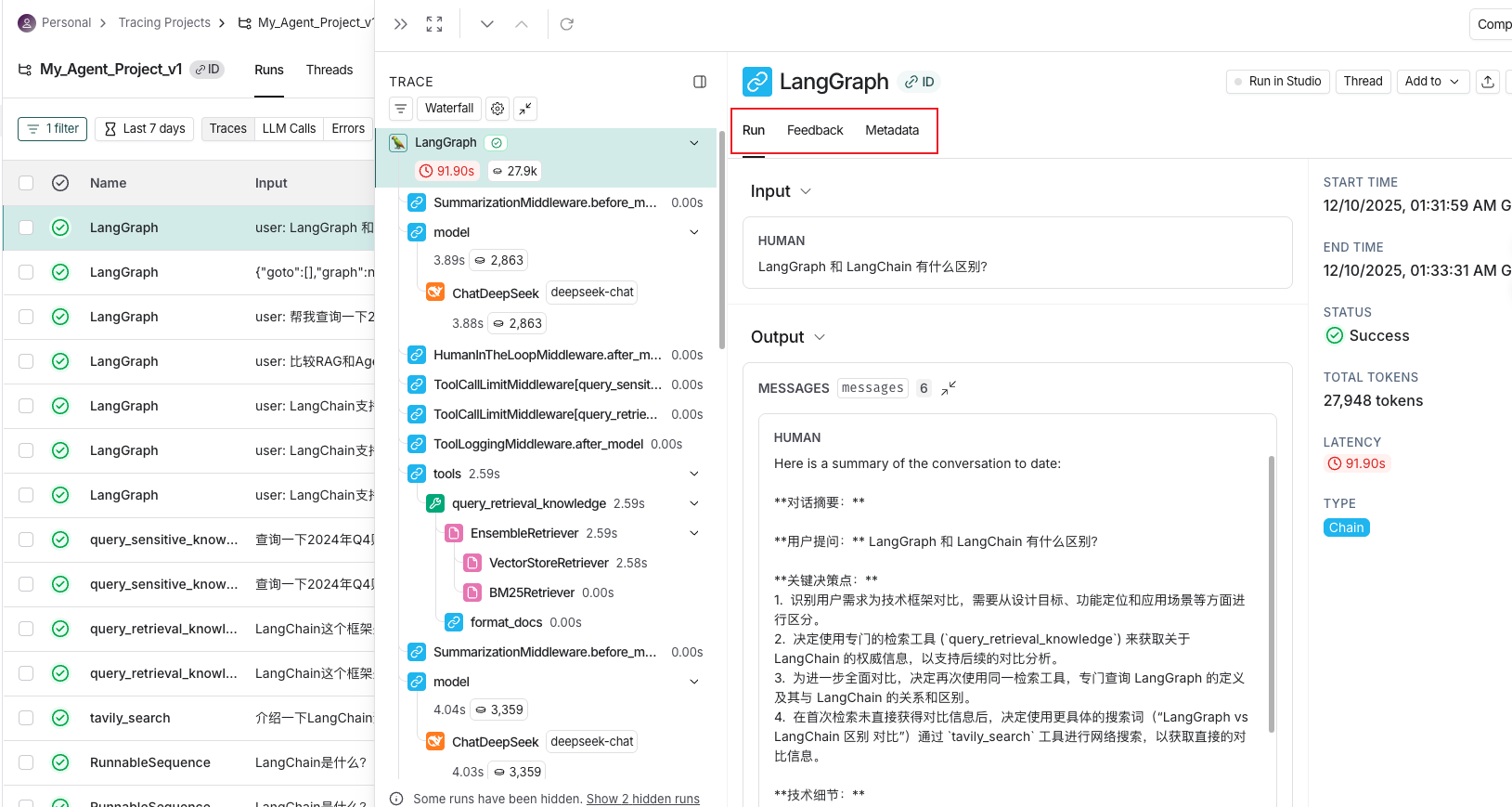
2. Run(运行单元)、Feedback(反馈)、Metadata(元数据) 链接到标题
Run:Trace中的单个执行节点,每个LLM调用、工具调用或函数执行都会生成一个Run,形成父子关系的树状结构。
- 作用:记录具体操作细节(如token消耗、延迟、参数), granular 级别的监控和成本分析。
Feedback:对单个Run的质量评估,包含标签(如"answer_correctness")和分数(0-1或分类),可人工标注或自动计算。
作用:构建评估数据集,驱动持续优化。支持在线(实时用户反馈)和离线(批量评估)两种模式。
注意:LangSmith不会自动生成Feedback,必须由开发者主动在代码中调用API显式创建反馈记录。
Metadata:附加在Run上的键值对信息(如{“version”: “v1.2”, “env”: “production”}),用于标记运行环境、模型版本等。
- 作用:支持跨维度筛选、分组分析(如对比不同版本的性能差异)。
二、 LangSmith配置步骤 链接到标题
- Step 1. 创建一个 LangSmith 帐户
要开始使用 LangSmith,我们需要创建一个帐户。可以在这里注册一个免费帐户进入LangSmith登录页面: https://smith.langchain.com/, 支持使用 Google、GitHub、Discord 和电子邮件登录。
注册并等登录后,可以直接查看到仪表板:
在构建程序跟踪前,首先需要创建一个 API 密钥,该密钥将允许我们的项目开始向 Langsmith 发送跟踪数据,务必保存好api_key!
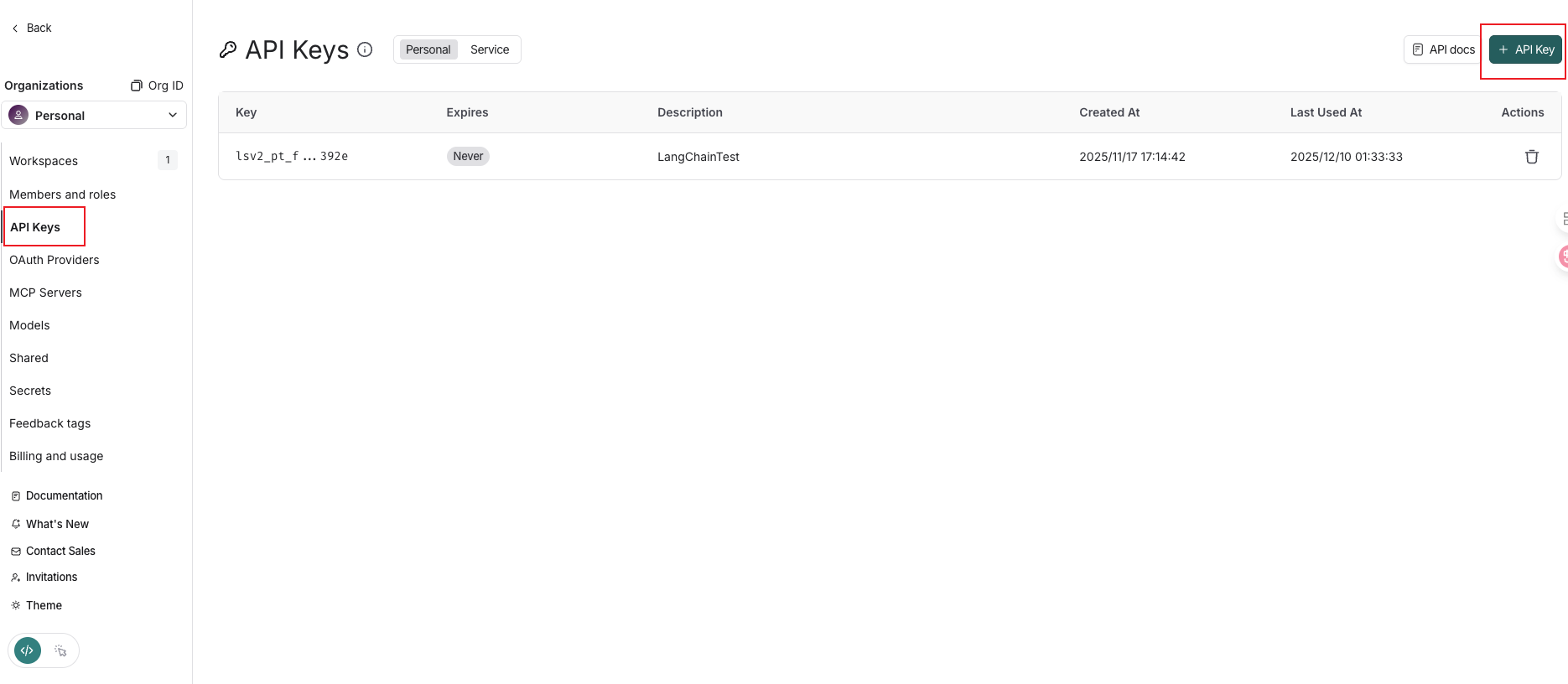
LangSmith 支持两种类型的 API 密钥:服务密钥和个人访问令牌。两种类型的令牌都可用于验证对 LangSmith API 的请求,但它们有不同的用例。这里选择“密钥类型令牌的个人访问” ,因为我们将使用此密钥作为用户进行个人访问。
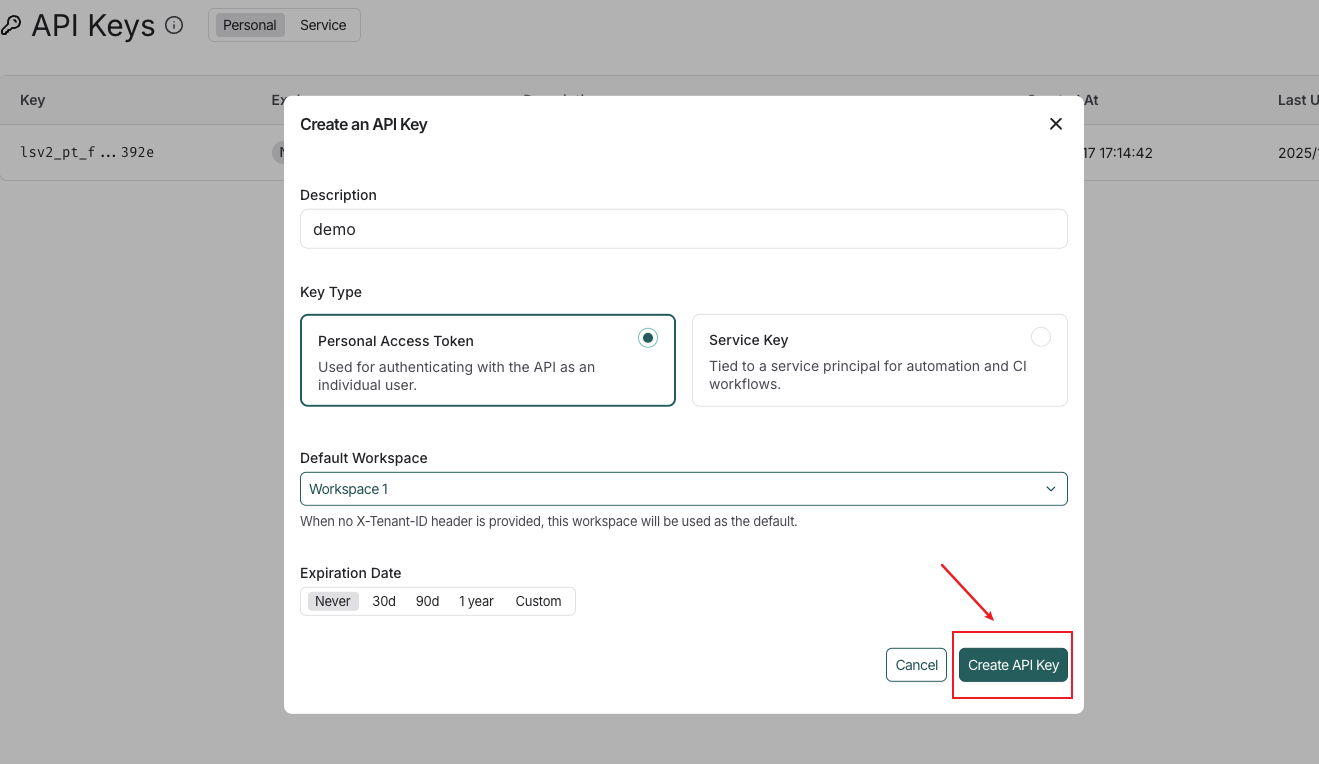
单击“创建 API 密钥” ,复制并确认已保存。这和OpenAI的API密钥一样,一旦创建完成,则不允许再次复制。
现在,就可以将其集成到我们的项目中了。
- Step 3. 创建环境变量
将LANGCHAIN_API_KEY替换为我们刚刚创建的 API 密钥,或者直接放到.env文件中保存(推荐)。
import os
# 设置环境变量
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# 设置LangSmith的API密钥
os.environ["LANGSMITH_API_KEY"] = "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"
# 设置LangSmith的项目名称
os.environ["LANGSMITH_PROJECT"] = "My_project"
# 验证环境变量是否设置成功
print(os.getenv("LANGCHAIN_TRACING_V2"))
print(os.getenv("LANGSMITH_API_KEY"))
print(os.getenv("LANGSMITH_PROJECT"))
# 1.导入相关库
from langchain.agents import create_agent
from langchain_tavily import TavilySearch
from langchain_deepseek import ChatDeepSeek
from dotenv import load_dotenv
load_dotenv(override=True)
# 2.导入模型和工具
web_search = TavilySearch(max_results=2)
# 3.创建模型
model = ChatDeepSeek(model="deepseek-chat")
# 4.创建Agent
agent = create_agent(
model=model,
tools=[web_search],
system_prompt="你是一名多才多艺的智能助手,可以调用工具帮助用户解决问题。"
)
# 5.运行Agent获得结果
result = agent.invoke(
{"messages": [{"role": "user", "content": "请帮我查询2024年诺贝尔物理学奖得主是谁?"}]}
)
print(result['messages'][-1].content)
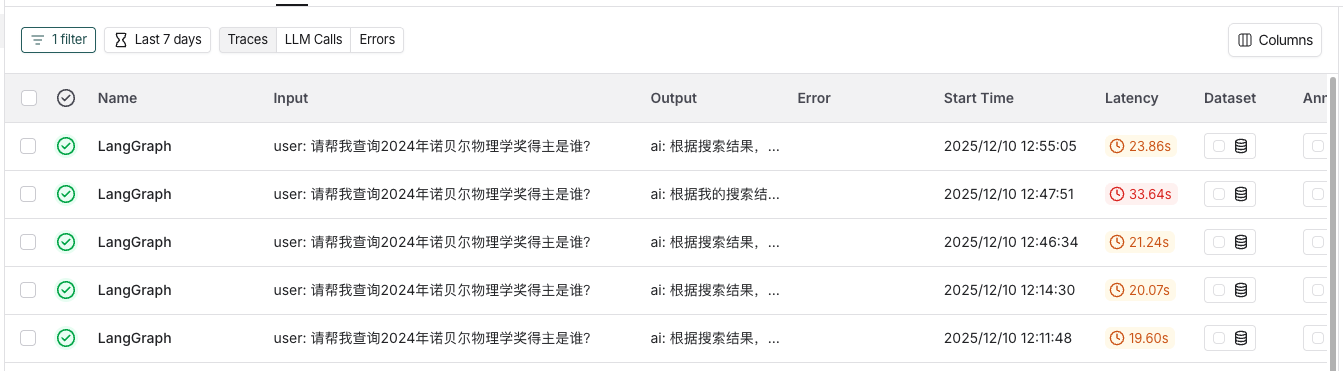
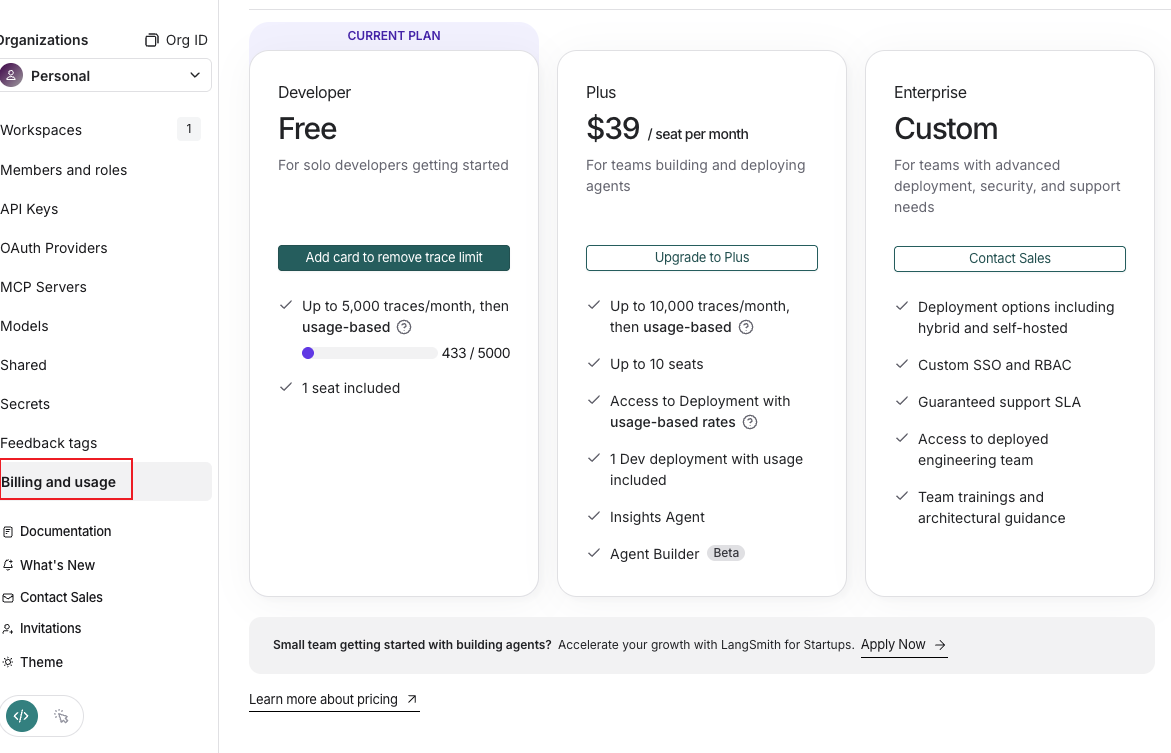
5.2 免费Developer Plan容量限制 链接到标题
对于免费的Developer Plan,具体的容量限制如下:
Trace 额度:每月 5,000 条 (5k) 免费 Base Traces
- 注:如果绑定了信用卡,超过5000条后不会停止服务,而是自动按 $0.50/1k 条收费;未绑定信用卡则会停止接收新数据
数据保留期 (Retention):默认为 14天
- 14天前的运行日志会被自动清除,除非手动将其添加到Dataset(数据集)中
并发/速率限制:
- 每小时最多接收 500MB 的数据包或 50,000 个事件,防止滥用
席位限制:仅限 1 个用户(不能邀请团队成员)
具体费用查看,还是先进入到settings设置中,然后点击Billing and usage来进行查看