第一阶段:Agent 开发的可观测性基石 链接到标题
在对LangChain 1.0有了一定的基础了解之后,对于开发者来说,还需要进一步了解和掌握LangChain Agent必备的开发者套件。分别是LangChain Agent运行监控框架LangSmith、底层LangGraph图结构可视化与调试框架LangGraph Studio和LangGraph服务部署工具LangGraph Cli。可以说这些开发工具套件,是真正推动LangGraph的企业级应用开发效率大幅提升的关键。同时监控、调试和部署工具,也是全新一代企业级Agent开发框架的必备工具,也是开发者必须要掌握的基础工具。
1. LangGraph图结构可视化与调试框架:LangGraph Studio 链接到标题
LangGraph Studio 它是一个本地 Graph 可视化引擎,是一个用于可视化构建、测试、分享和部署智能体流程图的图形化 IDE + 运行平台。专注于实时的状态展示和交互式调试。对于正在开发复杂 Agent 逻辑的工程师来说,能够实时观察每个节点的执行状态、输入输出数据和中间计算结果,这种可视化的调试体验是无价的。langGraph Studio对于LangChian Agent来说,则是比LangSmith`更加方便和高效的可视化调试工具平台。
LangGraph Studio 在本地可视化运行时会自动把调用过程上传到 LangSmith;而在 LangSmith 网页端查看任何 Trace 时,又能一键Run in Studio回放整条执行链,所以它是通过统一 Trace SDK 与 LangSmith 紧密集成。而LangGraph CLI则是构建这个项目的关键
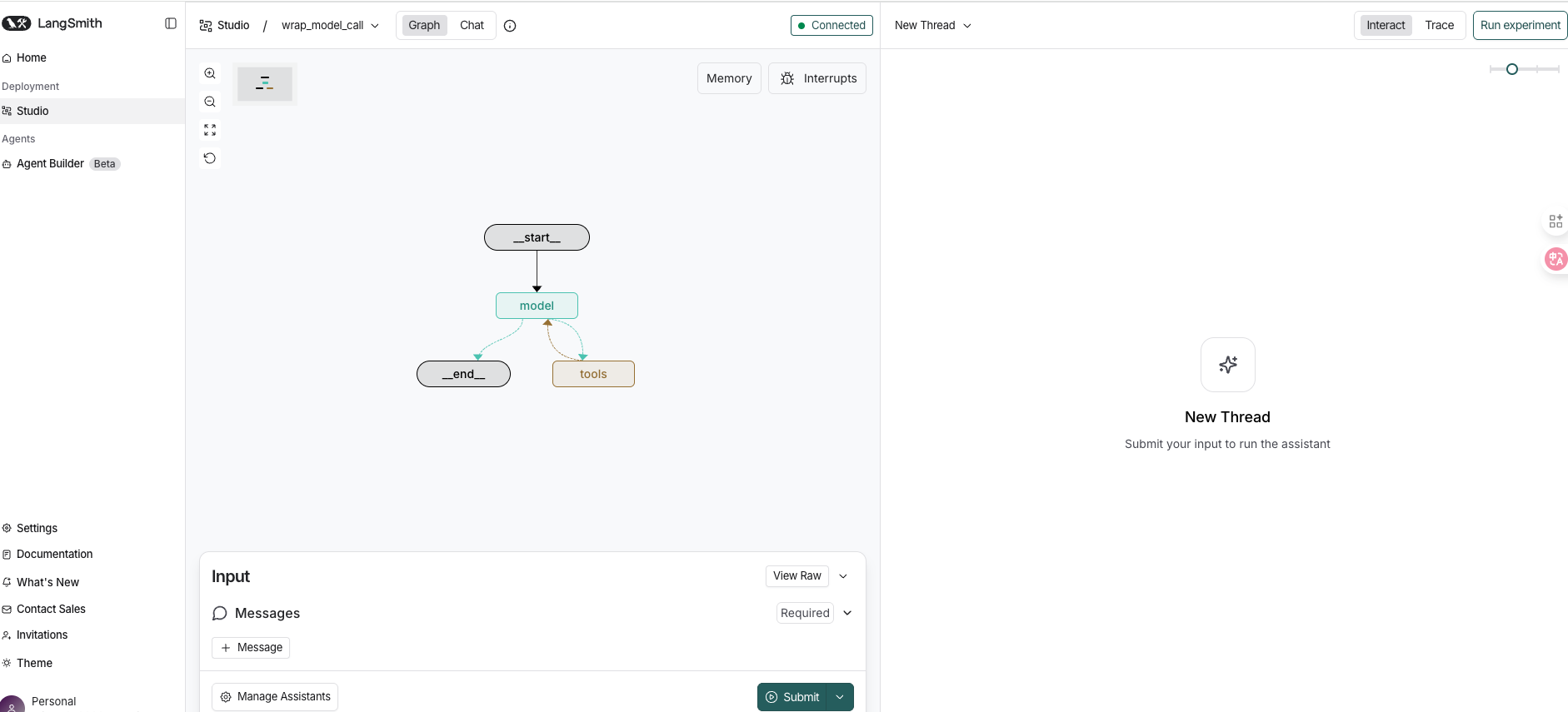
2. LangGraph服务部署工具:LangGraph Cli 链接到标题
LangGraph CLI 是用于本地启动、调试、测试和托管 LangGraph 智能体图的开发者命令行工具。
| 功能类别 | 命令示例 | 说明 |
|---|---|---|
| ✅ 启动 Graph 服务 | langgraph dev | 启动 Graph 的开发服务器,供前端(如 Agent Chat UI)调用 |
| 🧪 测试 Graph 输入 | langgraph run graph:graph --input '{"input": "你好"}' | 本地 CLI 输入测试,输出结果 |
| 🧭 管理项目结构 | langgraph init | 初始化一个标准 Graph 项目目录结构 |
| 📦 部署 Graph(未来) | langgraph deploy(预留) | 发布 graph 至 LangGraph 云端(已对接 Studio) |
| 🧱 显示 Assistant 列表 | langgraph list | 显示当前 graph 中有哪些 assistant(即 entrypoint) |
| 🔄 重载运行时 | 自动热重载 | 修改 graph.py 时,dev 模式自动重启生效 |
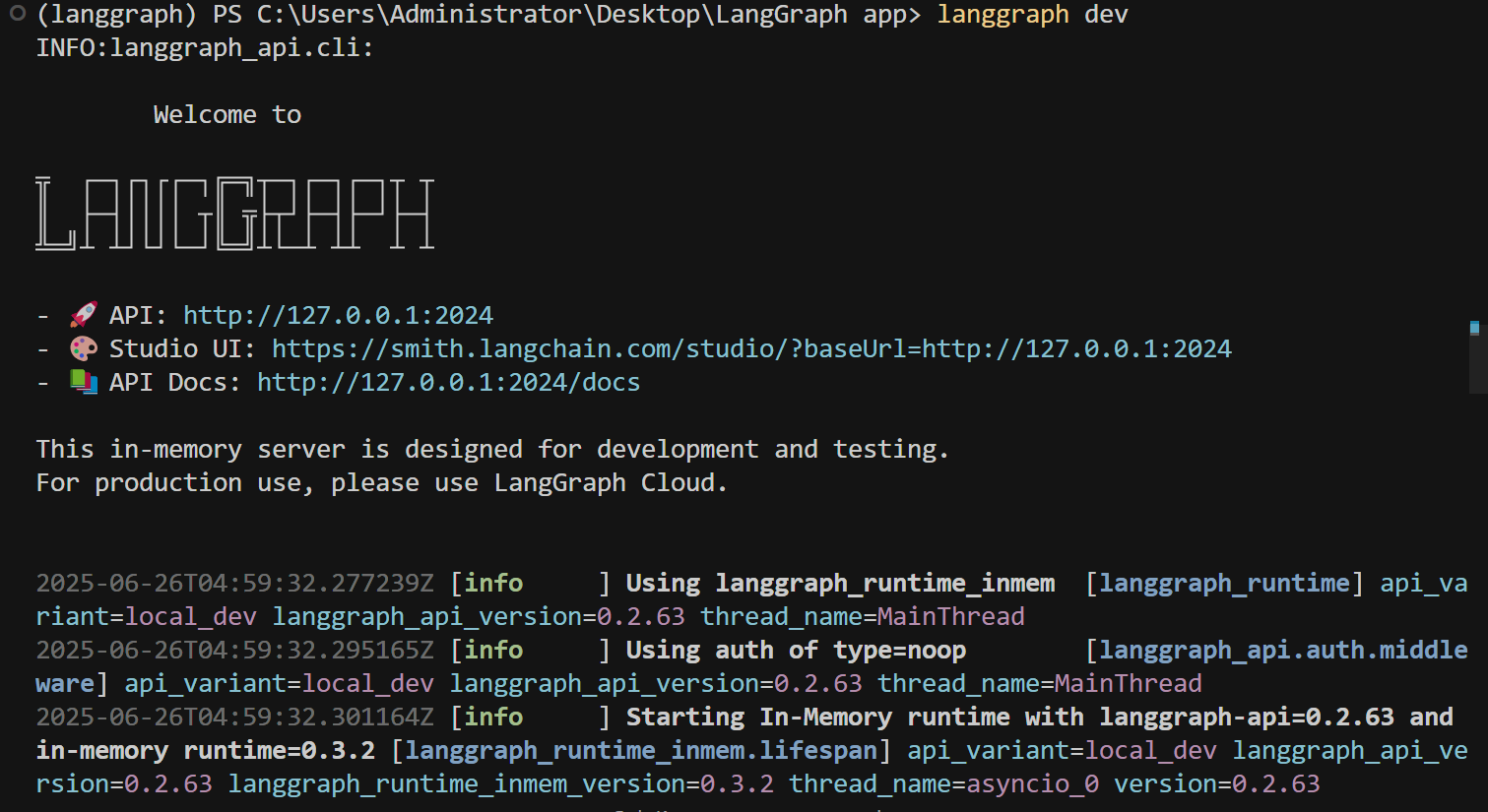
而一旦应用成功部署上线,LangGraph Cli还会非常贴心的提供后端接口说明文档:
而对于LangGraph构建的智能体,除了能够本地部署外,官方也提供了云托管服务,借助LangGraph Platform,开发者可以将构建的智能体 Graph部署到云端,并允许公开访问,同时支持支持长时间运行、文件上传、外部 API 调用、Studio 集成等功能。
2.1 创建完整LangGraph智能体项目流程 链接到标题
- Step 1. 创建一个
LangChain Agent项目主文件夹
我们这里创建一个LangChain Agent文件夹,如下图所示:
- Step 2. 创建
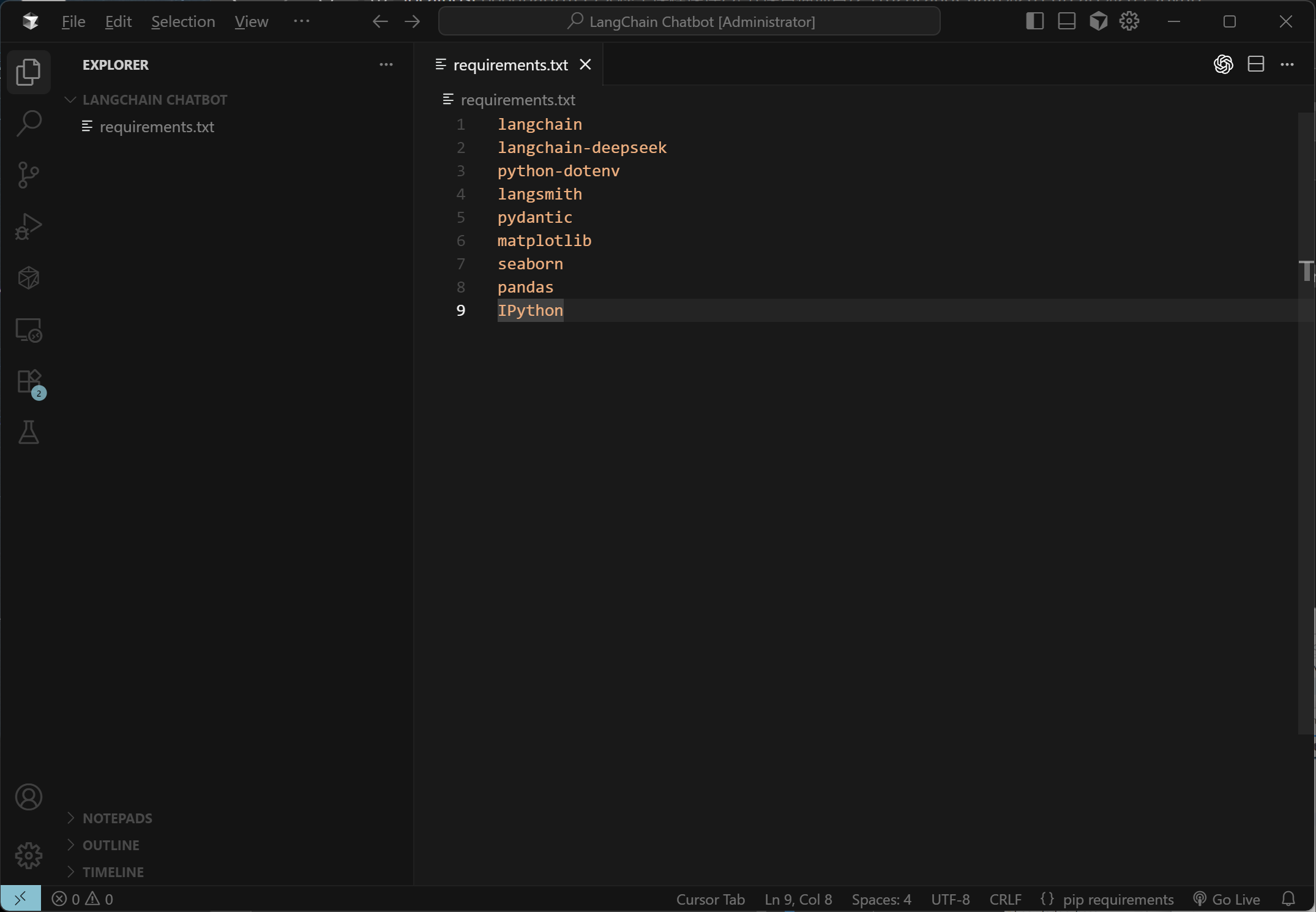
requirements.txt文件
在LangChain Chatbot文件夹中,新建一个requirements.txt文件,里面需要填写在运行该项目时需要安装的依赖项(注意:这里的依赖可以根据自己需要的进行增加),如下所示:
langchain
langchain-deepseek
langchain-openai
langchain-tavily
python-dotenv
langsmith
pydantic
matplotlib
seaborn
pandas
IPython
- Step 3. 注册LangSmith(可选)
对于企业级的Agent项目,为了更好的监控智能体实时运行情况,我们可以考虑借助LangSmith进行追踪(会将智能体运行情况实时上传到LangGraph官网并进行展示)。
要开始使用 LangSmith,我们需要创建一个帐户。可以在这里注册一个免费帐户进入LangSmith登录页面: https://smith.langchain.com/ , 支持使用 Google、GitHub、Discord 和电子邮件登录。
注册并等登录后,可以直接查看到仪表板:
在构建程序跟踪前,首先需要创建一个 API 密钥,该密钥将允许我们的项目开始向 Langsmith 发送跟踪数据。创建完密钥后,在后续配置环境变量环节设置开启追踪、并输入密钥即可接入LangSmith。
- Step 4. 创建
.env配置文件
在LangChain Chatbot文件夹中,新建一个.env文件,将敏感信息(如API密钥)放在环境变量中而不是硬编码。如下所示:
这里需要注意的是,如果不设置LangSmith,则无需设置中间三个环境变量,而具体工具也可以根据实际需求进行设置。
- Step 5. 创建
graph.py核心文件
在LangChain Agent文件夹中,新建一个graph.py文件,在该文件中编写构建图的具体运行逻辑,如状态、节点、变、图的编译等。此外,在使用LangGraph CLI创建智能体项目时,会自动设置记忆相关内容,并进行持久化记忆存储,无需手动设置。因此此时智能体代码如下所示:
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langchain.agents import create_agent
from typing_extensions import TypedDict
from langchain_tavily import TavilySearch
from langchain_core.tools import tool
from pydantic import BaseModel, Field
import requests,json
# 加载环境变量
load_dotenv(override=True)
# 内置搜索工具
search_tool = TavilySearch(max_results=5, topic="general")
class WeatherQuery(BaseModel):
loc: str = Field(description="The location name of the city")
@tool(args_schema = WeatherQuery)
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息
"""
# Step 1.构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step 2.设置查询参数
params = {
"q": loc,
"appid": os.getenv("OPENWEATHER_API_KEY"), # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step 3.发送GET请求
response = requests.get(url, params=params)
# Step 4.解析响应
data = response.json()
return json.dumps(data)
tools = [search_tool, get_weather]
# 创建模型
model = ChatDeepSeek(model="deepseek-chat")
prompt = """
你是一名乐于助人的智能助手,擅长根据用户的问题选择合适的工具来查询信息并回答。
当用户的问题涉及**天气信息**时,你应优先调用`get_weather`工具,查询用户指定城市的实时天气,并在回答中总结查询结果。
当用户的问题涉及**新闻、事件、实时动态**时,你应优先调用`search_tool`工具,检索相关的最新信息,并在回答中简要概述。
如果问题既包含天气又包含新闻,请先使用`get_weather`查询天气,再使用`search_tool`查询新闻,最后将结果合并后回复用户。
所有回答应使用**简体中文**,条理清晰、简洁友好。
"""
# 创建图
graph = create_agent(
model=model,
tools=tools,
system_prompt=prompt)
这里的代码编写时需要注意,如果需要使用langgraph studio进行可视化调试,则需要注意下面两点:
1、使用create_agent创建的对象名称必须是graph,与langgraph.json中后缀定义的名称要一致(graph.py:graph)
2、create_agent创建时不可以加checkpointer记忆参数,否则langgraph studio会报错
- Step 6. 创建
langgraph.json文件
在LangChain Agent文件夹中,新建一个langgraph.json文件,在该json文件中配置项目信息,遵循规范如下所示:
- 必须包含
dependencies和graphs字段 graphs字段格式:“图名”: “文件路径:变量名”- 配置文件必须放在与Python文件同级或更高级的目录
注意: 项目文件的名称必须为langgraph.json。如下所示:
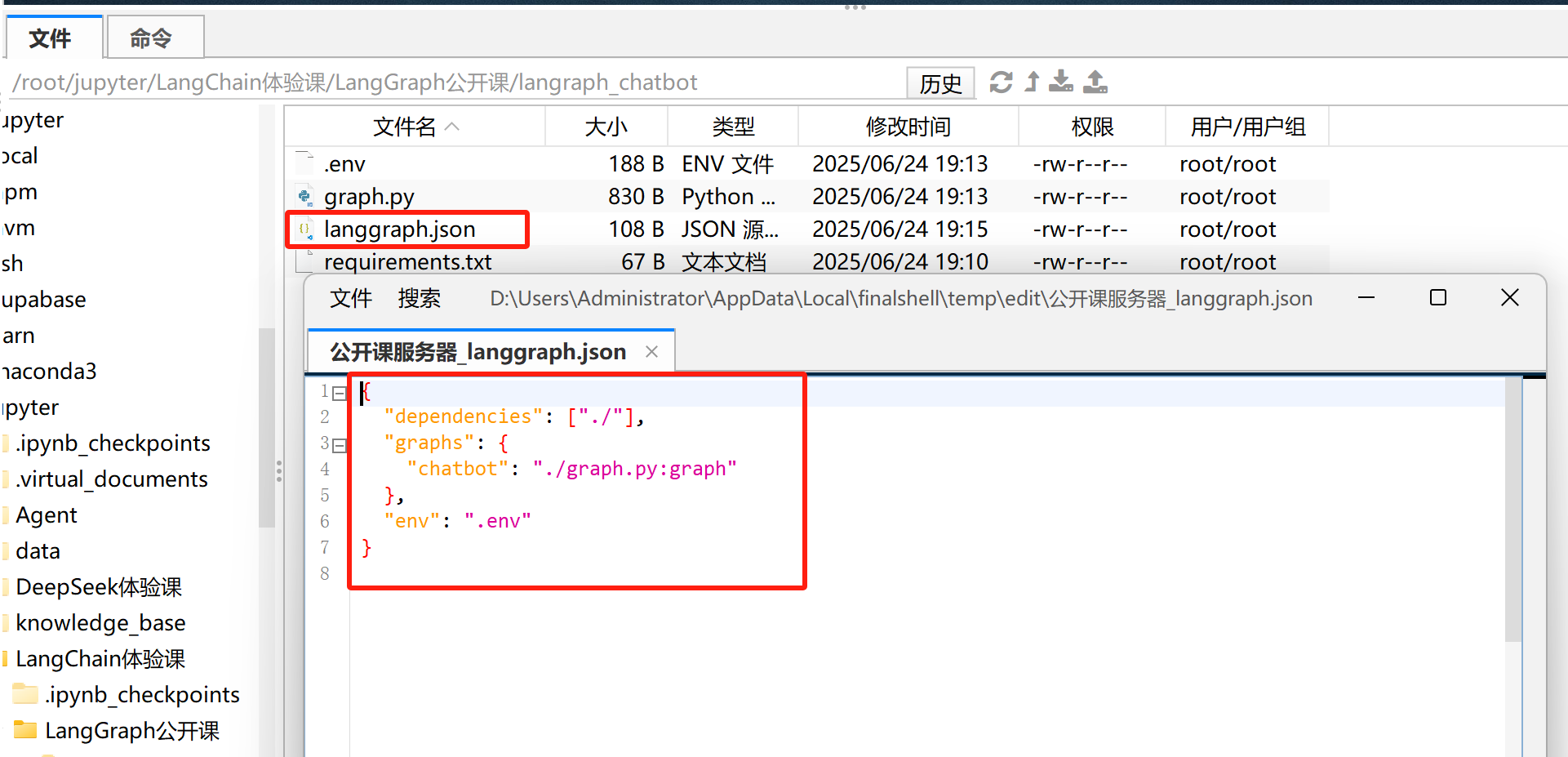
{
"dependencies": ["./"],
"graphs": {
"chatbot": "./graph.py:graph"
},
"env": ".env"
}
其中:
dependencies: ["./"] - 告诉LangGraph在当前目录查找依赖项(会自动读取requirements.txt)chatbot: “./graph.py:graph” - 定义图名为chatbot,来自graph.py文件中的graph变量env: “.env” - 指定环境变量文件位置
最终完整项目结构如下所示:
./langraph_chatbot/
├── graph.py # 对应官方的 agent.py
├── requirements.txt # ✅ 依赖管理
├── langgraph.json # ✅ 配置文件
└── .env # ✅ 环境变量
- Step 7. 安装
langgraph-cli以及其他依赖
!pip install -U "langgraph-cli[inmem]"
然后,安装langgraph-cli依赖,执行如下代码:
pip install -U "langgraph-cli[inmem]"
pip install -r requirements.txt
执行LangGraph dev即可启动项目
langgraph dev
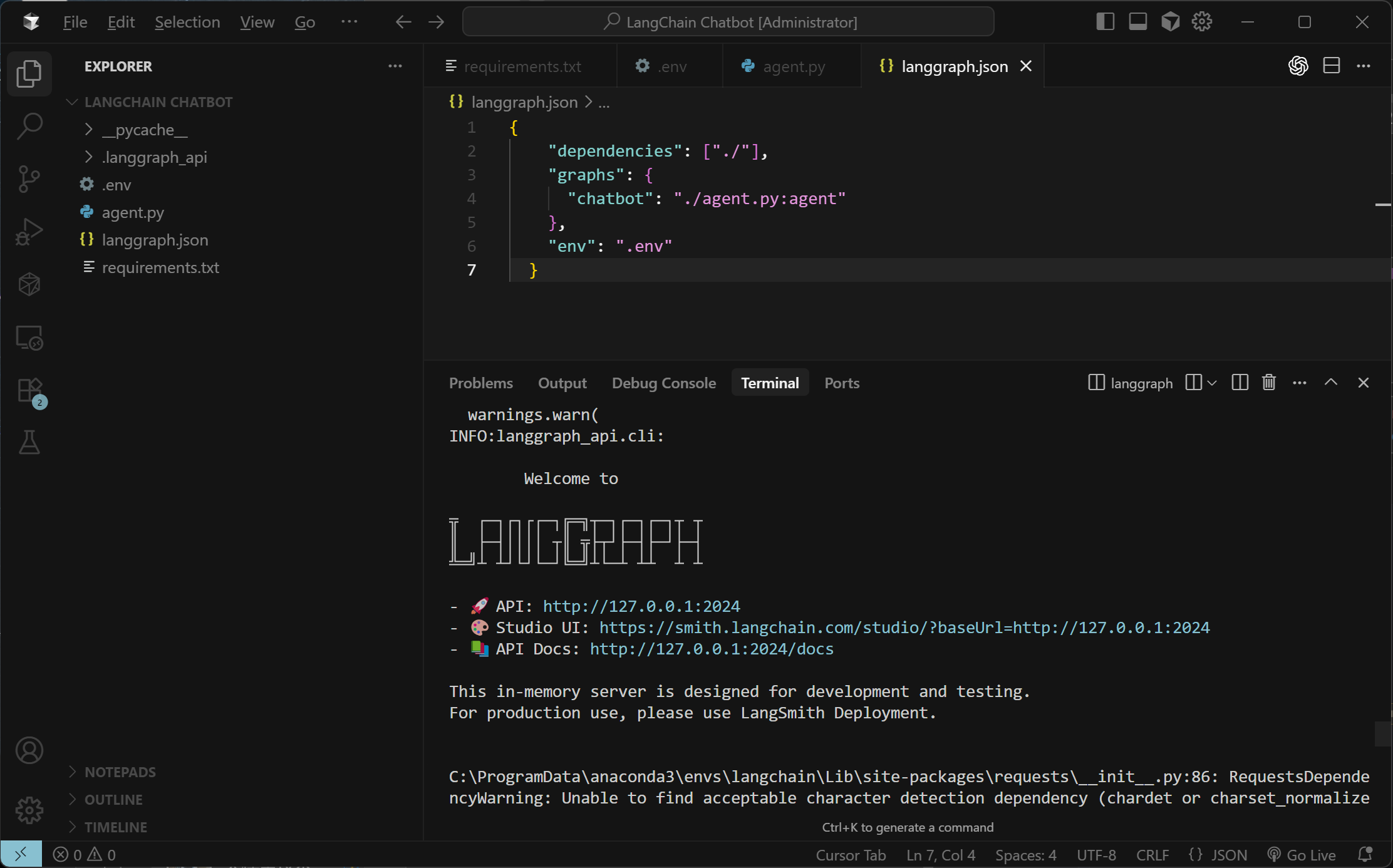
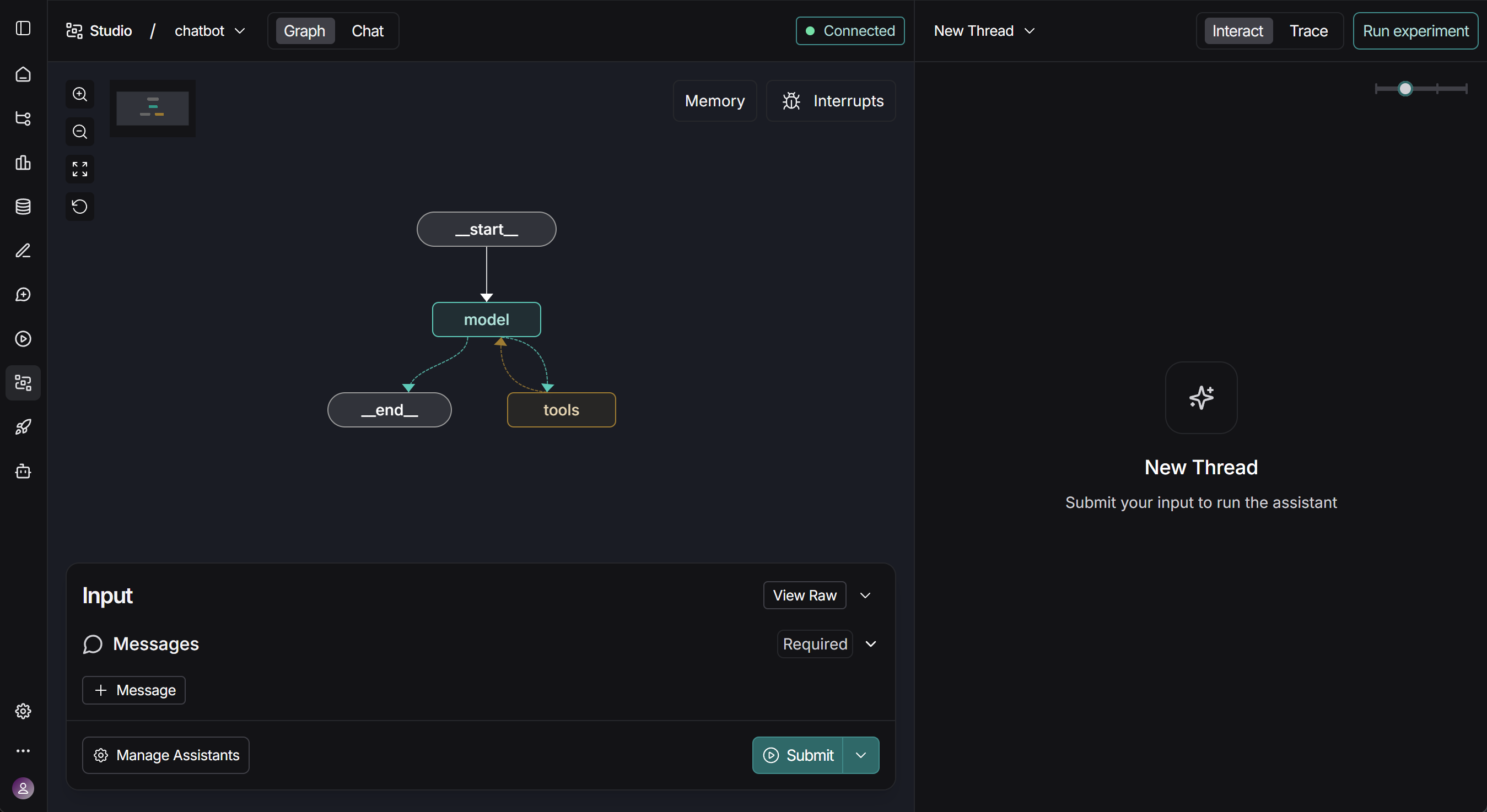
启动成功后能看到三个连接,其中第一个连接是当前部署完成后的服务端口,第二个是LangGraph Studio的可视化页面,第三个端口是端口说明。这里点击第二个链接进入Langgraph Studio的页面:
第二阶段:LangChain 1.0 中间件 (Middleware) 概览 链接到标题
接下来将深入探讨 LangChain 1.0 中间件体系的设计原理、实际应用和最佳实践,帮助开发者构建更加稳定、安全、可控的 AI Agent 系统。我们将从基础概念出发,逐步深入到具体的实现细节和高级应用场景,为读者提供一个完整的技术指南。
1. 中间件架构原理 链接到标题
LangChain 1.0其核心创新之一便是引入了中间件(Middleware)系统,旨在解决早期版本中Agent抽象无法灵活定制的痛点。 在LangChain 1.0及后续版本中,中间件(Middleware)被正式定义为一种用于拦截、修改、控制和增强Agent执行流程的机制。它借鉴了Web开发(如Express/Django)中的中间件模式,允许开发者在模型调用前后、Agent启动前后或工具调用前后插入自定义逻辑,从而实现日志记录、权限控制、上下文压缩等功能,而无需修改Agent的核心业务逻辑。
核心设计目标:
关注点分离:每个中间件只处理单一功能
可组合性:多个中间件可链式调用
可测试性:支持独立单元测试
生产就绪:内置隐私保护、成本管控等企业级能力
要理解中间件的工作原理,我们可以将其比作一个洋葱。每一层中间件都包裹着核心的 Agent 功能,就像洋葱的每一层都有其特定的作用。当用户请求到达时,它必须逐层通过这些中间件,每一层都会对请求进行特定的处理,然后将其传递给下一层。简而言之,借助中间件,一个React Agent的运行模型,就可以由这种:
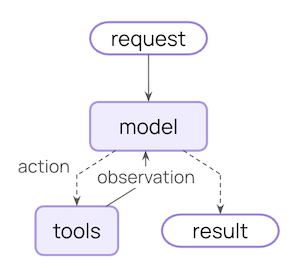
变为这种:
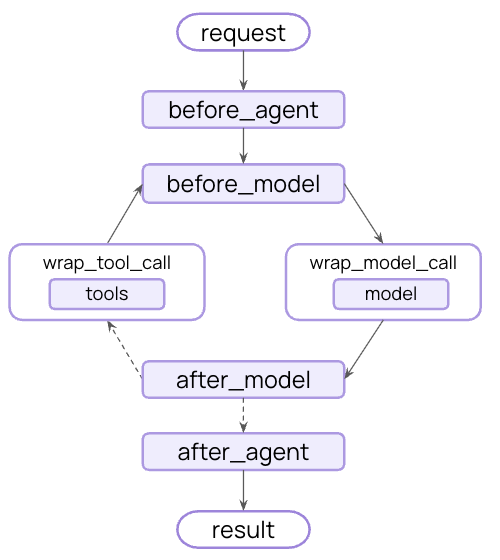
2. 中间件的作用 链接到标题
中间件(Middleware)作为 Agent 运行时的「横切能力层」,负责在 模型调用、工具调用、状态流转 等关键环节之间插入可控的拦截与增强逻辑。它不改变 Agent 的核心推理机制,而是作为运行时治理与智能行为优化的重要组件,提供了比普通提示工程更系统、更可控的能力。它就像给 Agent 装上了 “可插拔的增强模块” ,让 AI 系统既能保持核心简洁,又能进行排列组合,根据企业需求自由组合出百变的超能力。它从工程角度解决了 Agent 不稳定、难调试、不安全、不可控、难复用 等长期痛点。
过去: Agent 的行为像一条笔直的高速公路,从用户提问到模型回答,所有车辆只能按固定路径行驶。一旦需要安全检查、成本限制或性能监控,只能在每个出口强行加装收费站,导致代码臃肿、逻辑混乱、难以维护。
现在: 中间件如同立体交通网络,在不修改主干道的前提下,在关键枢纽注入智能管控层,优雅地解决了五大顽疾:
中间件主要解决了Agent在生产环境落地时的“不可控”问题:
成本风险:1.上下文失控解决对话历史过长导致的Token溢出(通过自动摘要中间件)。2.根据用户提问的复杂度判断使用不同类型的模型
安全风险:解决泄露(PII)手机号、身份证号等敏感信息、或恶意工具调用(通过审批中间件)。
调试黑盒:解决Agent思考过程难以追踪的问题(通过监控中间件)。
死循环:Agent 调用工具时可能陷入无限循环,调用中间件可以使系统会自动触发熔断。
3. 核心设计理念的深度解析 链接到标题
中间件的设计严格遵循了 SOLID 原则,这些原则不仅仅是理论概念,而是实际指导开发的行动准则。
单一职责原则(Single Responsibility Principle:SRP)在中间件中得到了完美的体现。每一个中间件都专注于一个特定的横切关注点,比如 SummarizationMiddleware 只负责处理上下文压缩,CostTrackingMiddleware 只负责成本统计。这种设计使得每个中间件的职责边界清晰,便于测试、维护和重用。
开闭原则(Open/Closed Principle:OCP)的应用使得系统具备了良好的扩展性。ModelSelectorMiddleware 可以通过配置来支持不同的模型选择策略,而无需修改代码本身。这意味着当有新的模型或者新的选择策略出现时,我们可以通过配置文件来适应,而不是修改核心代码。
里氏替换原则(Liskov Substitution Principle:LSP)是子类必须能够替换其父类而不破坏程序的正确性,DatabaseAuthMiddleware 和 JWTAuthMiddleware 可互相替换,Agent 无差别运行。
装饰器模式(Interface Segregation Principle:ISP)是中间件架构中的核心模式。通过 wrap_model_call,我们可以在不修改原始 Agent 代码的情况下,为其添加额外的功能。这种无侵入性的扩展方式使得 Agent 的核心逻辑保持简洁,而功能的增强通过中间件来实现。
责任链模式(Dependency Inversion Principle:DIP)则体现在多个中间件的顺序处理中。每个中间件都有机会处理请求,然后将请求传递给下一个中间件。这种模式提供了极大的灵活性,我们可以根据具体需求调整中间件的执行顺序,甚至动态地添加或删除中间件。
4. 性能考量与优化策略 链接到标题
在设计中间件时,性能是必须考虑的重要因素。不同的中间件类型对系统性能的影响是不同的。监控类中间件通常对性能影响最小,因为它们主要是记录信息而不进行复杂的处理。修改类中间件的影响相对较大,因为它们需要对数据进行处理和转换。控制类中间件可能会引入一些延迟,因为它们需要等待外部决策(如人工审批)。强制类中间件则可能涉及复杂的验证逻辑,对性能有一定影响。
优化策略需要从多个层面进行考虑。延迟优化可以通过异步处理来实现,对于那些不直接影响主流程的操作(如日志记录、性能统计),我们可以采用异步方式处理。批处理是另一个重要的优化手段,特别是对于那些需要对多个请求进行相似处理的中间件。
内存管理同样重要。中间件可能会创建大量的中间对象,如果管理不当,容易导致内存泄漏。对象池技术可以帮助我们重用常用的对象,减少创建和销毁的开销。
CPU 优化则需要从算法层面考虑。选择时间复杂度更低的算法可以显著提高性能。在可能的情况下,利用多核 CPU 进行并行处理也是一个有效的策略。
| 中间件类型 | 典型场景 | 响应时间增加 | 吞吐量衰减 | 资源消耗 | 性能瓶颈点 | 优化策略 |
|---|---|---|---|---|---|---|
日志监控中间件@after_model | 请求日志、指标统计 | < 1 ms | < 5% | CPU 1-3%内存 10-50MB | 磁盘 I/O(异步后极小) | 异步写入、采样率 10% |
安全脱敏中间件@before_model | PII 脱敏、权限检查 | 1-5 ms | 5-10% | CPU 5-10%内存 20-100MB | 正则表达式字符串拷贝 | 编译缓存、原地修改 |
参数校验中间件@before_model | 输入验证、格式检查 | 1-3 ms | 3-8% | CPU 3-8%内存 10-30MB | 复杂校验规则 | 缓存校验结果 |
对话总结中间件@before_model | 长文本压缩 | 50-200 ms | 15-30% | CPU 20-40%内存 100-500MB | 模型调用token 计算 | 仅在消息数>10 触发 |
缓存中间件@wrap_model_call | 结果缓存 | 0.5-2 ms(缓存命中) | -50% ~ +10%(命中时提升) | 内存 50-200MB | 缓存命中率 | LRU 策略、TTL 设置 |
模型降级中间件@wrap_model_call | 动态切换模型 | 5-10 ms | 10-15% | CPU 2-5%内存 10-20MB | 模型初始化API 调用 | 模型池化、预热 |
限流中间件@wrap_model_call | QPS 限制、熔断 | 0.1-1 ms | < 5% | CPU 1-2%内存 5-10MB | 原子计数器锁竞争 | 滑动窗口算法 |
工具审计中间件@wrap_tool_call | 调用记录、熔断 | 2-8 ms | 8-15% | CPU 5-12%内存 30-80MB | 数据库写入网络请求 | 异步批量写入 |
工具重试中间件@wrap_tool_call | 失败重试 | 10-50 ms(视重试次数) | 20-50% | CPU 10-20%内存 20-50MB | 重试延迟指数退避 | 限制重试次数≤3 |
外部 API 调用中间件@wrap_tool_call | 调用第三方服务 | 100-500 ms(网络延迟主导) | 30-70% | CPU 5-10%内存 10-30MB | 网络 I/O超时设置 | 连接池、超时 3s |
消息队列中间件@before_model | 异步任务解耦 | 5-20 ms(仅入队) | 10-25% | CPU 10-15%内存 50-150MB | 消息序列化队列持久化 | 批量发送、压缩 |
注册中心中间件@before_agent | 服务发现 | 10-30 ms(首次查询) | 5-15% | CPU 5-10%内存 20-60MB | DNS 查询缓存过期 | 本地缓存 60s |
第三阶段:中间件的分类与应用场景 链接到标题
1. 中间件四大分类 链接到标题
中间件的四大分类——监控类、修改类、控制类和强制类——每一种都有其独特的定位和应用场景。这种分类不是人为的划分,而是基于实际需求和功能特性的自然归类。
| 分类 | 核心功能 | 解决的问题 | 典型应用场景 |
|---|---|---|---|
| Monitor (监控类) | 观察执行状态、日志记录 | 调试困难、缺乏可观测性 | 记录所有的Prompt和Response、性能分析、成本核算。 |
| Modify (修改类) | 修改输入/输出、上下文管理 | 上下文窗口溢出、Prompt优化 | SummarizationMiddleware(自动压缩历史对话)、动态注入System Prompt。 |
| Control (控制类) | 流程阻断、人工介入 | AI幻觉、高风险操作失控 | HumanInTheLoopMiddleware(敏感操作需人工审批)、重试机制。 |
| Enforce (强制类) | 安全过滤、限流、合规检查 | 数据泄露、API滥用 | PIIMiddleware(敏感信息脱敏)、ModelCallLimit(防止死循环)。 |
1.监控类中间件是最基础也是最重要的类型。它们像是系统的"观察者",默默记录着系统运行的每一个细节。性能监控中间件不仅记录响应时间和资源使用,更重要的是它们能够自动检测性能异常,就像一个细心的医生能够从细微的症状中发现潜在的问题。成本追踪中间件则像是系统的"会计师",精确记录着每一个 Token 的消耗,帮助团队了解系统的真实运营成本。
2.修改类中间件是系统的"优化师"。它们不仅仅是记录信息,更重要的是它们能够主动改变数据的处理方式。智能摘要中间件是最典型的例子,它们通过复杂的算法分析对话内容,保留最重要的信息,过滤掉冗余的内容。这就像是一个经验丰富的信息处理专家,能够在保持信息完整性的同时,最大程度地减少处理成本。
3.控制类中间件是系统的"指挥官"。它们负责管理系统的行为,确保所有操作都在预定的规则范围内进行。人工介入中间件通过智能识别需要人工审批的敏感操作,在保持系统自动化的同时,确保关键操作的安全性。流量控制中间件则像是交通指挥员,确保系统的"流量"不会超出承受能力。
4.强制类中间件是系统的"守护者"。它们负责保护系统免受各种威胁,安全强制执行中间件就像是系统的安保系统,对每一个输入输出进行全方位的安全检查。合规检查中间件则像是法律顾问,确保系统的所有操作都符合相关法规要求。
2. 深入生命周期 - 中间件的 6 个切入点 (Hooks) 链接到标题
2.1 Hook 执行顺序的深层逻辑 链接到标题
中间件的 6 个 Hook 点——before_agent、before_model、wrap_model_call、wrap_tool_call、after_model 和 after_agent——不仅仅是一个执行顺序,更是一个精心设计的数据流处理流程。这个流程体现了从输入处理到输出生成的完整生命周期。
在 Agent 执行的最开始,before_agent Hook 提供了全局初始化的机会。这个阶段通常用于设置全局状态、检查环境配置、初始化资源等。就像一个大型演出的开场准备,确保所有必要的准备工作都已经就绪。
before_model 阶段是输入预处理的关键节点。在这个阶段,中间件可以对输入数据进行预处理、验证、清洗等操作。这是确保数据质量的第一道防线,任何在这个阶段发现的问题都可以避免后续的无谓计算。
wrap_model_call 是最核心的 Hook,它包装了实际的模型调用过程。这个阶段的处理逻辑决定了如何与底层模型交互,是实现高级功能(如缓存、重试、熔断等)的关键位置。
wrap_tool_call 是用于拦截和控制工具的实际执行过程的Hook,它包装了每次工具调用。这个阶段的处理逻辑可以是权限、重试、日志、审批。
after_model 阶段则处理模型返回的原始结果。这个阶段的任务是验证输出质量、进行格式转换、提取关键信息等。由于模型输出往往包含大量无用信息,这个阶段的处理对于提高整体效率至关重要。
最后的 after_agent 阶段是整个生命周期的收尾工作。在这个阶段,系统需要清理资源、记录最终状态、生成报告等。这是确保系统处于良好状态,为下一次请求做好准备的关键步骤。
2.2 数据传递机制的复杂性 链接到标题
Hook 间的数据传递是一个精妙而复杂的机制。每个 Hook 都能访问和修改共享的上下文对象,这个对象就像是整个处理过程的"记忆"。上下文对象不仅包含请求信息和响应数据,还包含运行时状态、中间计算结果、元数据等。
元数据传递机制允许中间件在不直接共享状态的情况下传递信息。例如,一个中间件可以在元数据中标记某个输入是 VIP 用户的请求,后续的中间件可以根据这个标记来调整处理策略。
状态管理是另一个重要方面。中间件需要维护状态,但这些状态可能会因为各种原因而发生变化。错误处理机制、回滚机制、事务性操作等都需要在状态管理中得到体现。
2.3 高级 Hook 使用模式的深度解析 链接到标题
在实际应用中,Hook 的使用往往比基本的执行顺序更加复杂。条件 Hook 执行是高级使用模式中最常见的一种。它通过智能的条件判断来决定是否执行特定的 Hook,这样可以提高处理效率,避免不必要的计算。
想象一个场景:一个电商推荐系统的 Agent。对于 VIP 用户,系统可能需要启用更复杂的推荐算法、调用更多的数据源、提供更个性化的服务。而对普通用户,则可以使用更简单、更快速的推荐策略。这种差异化的处理需要通过条件 Hook 来实现。
错误恢复 Hook的设计体现了系统的韧性。不同层级的错误需要不同的恢复策略。有些错误可以通过简单的重试来解决,有些错误需要切换到备用模型,还有些错误需要人工介入。通过在不同 Hook 层级实现恢复机制,系统可以在不同层次上处理错误,提高整体的可靠性。
性能优化 Hook则关注系统的运行效率。缓存 Hook 通过在 wrap_model_call 阶段检查缓存来决定是否直接返回缓存结果,避免重复的模型调用。预加载 Hook 则通过预测用户需求,提前加载可能需要的数据和资源。
第四阶段:中间件集成工具使用 链接到标题
!python --version
!pip list | grep langchain
4.1 before_model 模型调用前 链接到标题
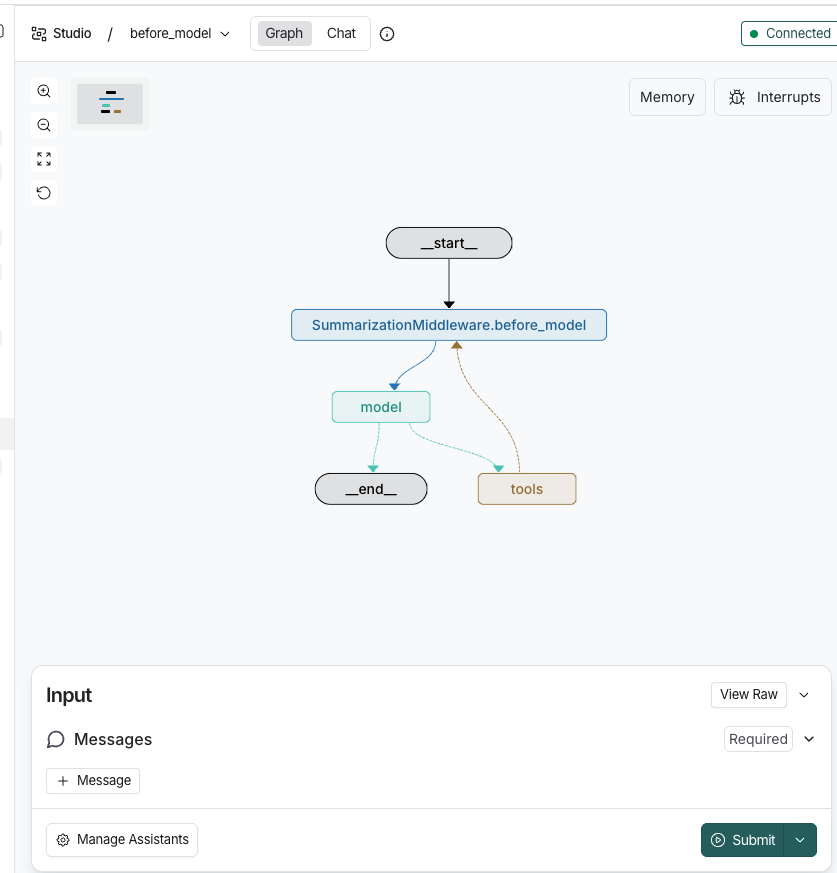
1.SummarizationMiddleware 上下文压缩 链接到标题
中间件类型 链接到标题
before_model - 模型调用前中间件
概述 链接到标题
使用 LangChain 1.0 的 SummarizationMiddleware 来自动压缩历史会话,减少 token 使用,提高响应速度。
核心特性 链接到标题
- 官方中间件集成:使用
from langchain.agents.middleware import SummarizationMiddleware - 自动压缩:在
create_agent中通过middleware参数集成 - 智能保留:自动压缩历史消息,保留最近的对话
- 无需手动管理:中间件自动处理压缩逻辑
工作原理 链接到标题
当历史消息的 token 数量超过阈值(500)且消息数量超过保留数量(5条)时,中间件会自动:
- 将旧消息发送给摘要模型进行压缩
- 保留最近的 N 条消息
- 将摘要结果作为上下文传递给 Agent
预期结果 链接到标题
- 压缩前:20 条消息,约 1000+ tokens
- 压缩后:5-6 条消息(保留最近5条 + 摘要),约 300-500 tokens
# ==================== SummarizationMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.runnables import ensure_config
from pydantic import BaseModel, Field
from typing import Optional
from dotenv import load_dotenv
import logging
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义工具 ====================
@tool
def search_patent(query: str) -> str:
"""搜索专利数据库"""
return f"专利搜索结果: 找到与 '{query}' 相关的 3 项专利..."
@tool
def analyze_technology(tech_desc: str) -> str:
"""分析技术可行性"""
return f"技术分析: '{tech_desc}' 的实现可行性评估完成..."
tools = [search_patent, analyze_technology]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
department: str = Field(..., description="所属部门")
max_history_tokens: Optional[int] = Field(default=1000, description="历史消息 token 阈值")
# ==================== 4. 配置中间件 ====================
summarization_middleware = SummarizationMiddleware(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1),
# max_tokens_before_summary=200, # 历史消息 token 数量超过 200 时触发压缩
messages_to_keep=5, # 保留最近 5 条消息
summary_prompt="请将以下对话历史进行摘要,保留关键决策点和技术细节:\n\n{messages}\n\n摘要:" # 摘要提示词
)
# ==================== 5. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.2),
tools=tools,
middleware=[summarization_middleware],
context_schema=UserContext,
debug=True,
)
# ==================== 6. 执行测试 ====================
def run_summarization_test():
logger.info("开始 SummarizationMiddleware 测试")
# 创建长对话历史
long_history = [HumanMessage(content=f"问题 {i+1}: 如何评估某项技术的专利风险?") for i in range(20)]
logger.info(f"创建了 {len(long_history)} 条消息")
# 执行
result = agent.invoke(
{"messages": long_history},
context=UserContext(user_id="engineer_001", department="研发部"),
config=ensure_config({"configurable": {"thread_id": "session_001"}})
)
result_messages = result.get("messages", [])
logger.info(f"执行后消息数: {len(result_messages)}")
if len(result_messages) < len(long_history):
logger.info(f"中间件已触发!压缩了 {len(long_history) - len(result_messages)} 条消息")
return result
# ==================== 7. 运行测试 ====================
result = run_summarization_test()
logger.info("测试完成")
2.PIIMiddleware PII信息脱敏 链接到标题
中间件类型 链接到标题
before_model - 模型调用前中间件
本示例展示如何使用 PIIMiddleware 来自动检测和脱敏个人身份信息(PII),保护用户隐私和数据安全。
核心特性 链接到标题
- 自动PII检测:使用
from langchain.agents.middleware import PIIMiddleware - 智能脱敏:自动识别并处理敏感信息
- 多种策略:支持 block、redact、mask、hash 四种处理策略
- 无缝集成:在模型调用前自动处理,对业务逻辑透明
工作原理 链接到标题
在模型调用前,中间件会自动:
- 扫描消息内容,识别指定类型的PII信息
- 根据策略处理敏感信息(阻止/脱敏/遮蔽/哈希)
- 将处理后的消息传递给模型
支持的PII类型 链接到标题
- email:电子邮件地址
- credit_card:信用卡号
- ip:IP地址
- mac_address:MAC地址
- url:URL地址
处理策略 链接到标题
- block:阻止包含PII的消息
- redact:完全移除PII信息
- mask:部分遮蔽PII信息
- hash:将PII转换为哈希值
预期结果 链接到标题
- 脱敏前:“我的银行卡号是4532-1234-5678-9010”
- 脱敏后:“银行卡号是
****-****-****-9010”
# ========================================
# LangChain 1.0 信用卡PII掩码中间件实战
# ========================================
import os
from typing import Annotated
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool, BaseTool
from langchain_core.messages import HumanMessage, AIMessage
from pydantic import BaseModel, Field
import re
from dotenv import load_dotenv
# ==================== 1. 加载环境 ====================
load_dotenv(override=True)
# ==================== 2. 定义模拟工具 ====================
@tool
def verify_credit_card(card_number: Annotated[str, "信用卡号"]) -> dict:
"""
验证信用卡号有效性(模拟工具)
注意:实际生产环境中不应接收真实卡号
"""
# 工具接收到的参数已经是掩码后的
print(f"工具接收到的卡号: {card_number}")
# 模拟验证逻辑
if len(card_number) >= 16: # 掩码后的长度也足够判断
return {
"is_valid": True,
"card_type": "Visa",
"masked_card": card_number
}
return {"is_valid": False}
@tool
def process_payment(card_number: str, amount: float) -> str:
"""
处理信用卡支付(模拟工具)
"""
print(f"支付工具接收到的卡号: {card_number}")
return f"支付成功!金额: ${amount}, 卡号: {card_number}"
@tool
def search_user_history(user_id: str) -> str:
"""查询用户历史记录"""
return f"用户 {user_id} 的历史订单:订单123, 订单456"
# 工具列表
tools: list[BaseTool] = [verify_credit_card, process_payment, search_user_history]
# ==================== 3. 定义用户上下文 ====================
class UserContext(BaseModel):
"""用户上下文 Schema"""
user_id: str = Field(..., description="用户唯一标识")
department: str = Field(..., description="所属部门")
security_level: str = Field(default="normal", description="安全级别")
# ==================== 4. 配置 PIIMiddleware ====================
# 核心配置:信用卡掩码中间件
piim_credit_card = PIIMiddleware(
"credit_card",
detector=r"\b(?:\d{4}[-\s]?){3}\d{4}\b", # 匹配格式: 1234-5678-9012-3456
strategy="mask", # 掩码策略
apply_to_input=True, # 对输入消息进行掩码
apply_to_output=False, # 不对工具输出进行掩码(工具返回的是业务结果)
)
# ==================== 5. 创建智能体 ====================
agent = create_agent(
# 主模型:用于决策和对话
model=ChatDeepSeek(model="deepseek-chat", temperature=0.2),
# 工具列表
tools=tools,
# 中间件:只启用PII掩码(生产环境可添加日志等)
middleware=[
piim_credit_card, # 信用卡掩码中间件
],
# 启用上下文
context_schema=UserContext,
# 调试模式
debug=True,
)
# ==================== 6. 测试用例与执行 ====================
def test_credit_card_masking():
"""测试信用卡掩码全流程"""
print("=" * 60)
print("测试场景:用户尝试使用信用卡支付")
print("=" * 60)
# 测试输入:包含多种信用卡格式
test_query = """
请帮我验证以下信用卡是否有效:
我的卡号是 4532-1234-5678-9010,另外备用卡是 4532123456781234。
请检查这两张卡,然后处理一笔 99.99 美元的支付。
"""
print(f"\n【原始用户输入】\n{test_query}\n")
# 执行 Agent
result = agent.invoke(
# 消息列表
{"messages": [HumanMessage(content=test_query)]},
# 上下文(必须)
context=UserContext(
user_id="user_789",
department="财务部",
security_level="high"
),
# 配置(可选)
config={"configurable": {"thread_id": "session_cc_001"}}
)
print("\n【Agent 最终返回的消息】")
final_message = result["messages"][-1]
if isinstance(final_message, AIMessage):
print(f"角色: {final_message.type}")
print(f"内容: {final_message.content}")
# 检查工具调用
if hasattr(final_message, 'tool_calls') and final_message.tool_calls:
print("\n【工具调用记录】")
for tc in final_message.tool_calls:
print(f"- 工具: {tc['name']}")
print(f" 参数: {tc['args']}")
return result
test_credit_card_masking()
3.ModelCallLimitMiddleware 模型调用限制 链接到标题
中间件类型 链接到标题
before_model - 模型调用前中间件
本示例展示如何使用 ModelCallLimitMiddleware 来限制 Agent 的模型调用次数,防止死循环或意外的高消耗。
核心特性 链接到标题
- 安全防护:防止 Agent 陷入无限循环
- 简单配置:通过
max_calls参数设置最大调用次数 - 自动熔断:达到限制后自动停止并返回错误或特定消息
工作原理 链接到标题
中间件会跟踪当前会话中的模型调用次数。当调用次数达到设定的阈值时,中间件会阻止后续的模型调用,并引发异常或返回预设的响应。
预期结果 链接到标题
- 正常情况:调用次数未超限,正常执行
- 超限情况:抛出
ModelCallLimitExceeded异常或停止执行
# ==================== ModelCallLimitMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import ModelCallLimitMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
#
from langchain_core.runnables import ensure_config
from pydantic import BaseModel, Field
from dotenv import load_dotenv
load_dotenv(override=True)
# ==================== 1. 定义工具 ====================
@tool
def complex_calculation(x: int) -> int:
"""执行复杂计算"""
return x * 2
@tool
def get_weather(city: str) -> str:
"""获取天气信息"""
return f"{city}的天气:晴天,温度25°C"
tools = [complex_calculation, get_weather]
# ==================== 2. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 3. 配置中间件 ====================
limit_middleware = ModelCallLimitMiddleware(
run_limit=3, # 每次运行最多调用模型3次
exit_behavior='error' # 超限时抛出异常
)
# ==================== 4. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1),
tools=tools,
middleware=[limit_middleware],
context_schema=UserContext,
debug=False, # 关闭调试模式以减少输出
)
# ==================== 5. 执行测试 ====================
def run_limit_test():
"""测试 ModelCallLimitMiddleware 触发逻辑"""
# 设计一个需要多次模型调用的任务
query = """
请按照以下步骤执行:
1. 计算 5 的两倍
2. 用第一步的结果再计算两倍
3. 用第二步的结果再计算两倍
4. 用第三步的结果再计算两倍
5. 最后告诉我北京的天气
请一步一步执行,每次只做一个计算。
"""
print("=" * 60)
print("ModelCallLimitMiddleware 测试")
print("=" * 60)
print(f"\n【输入】\n{query.strip()}\n")
model_call_count = 0
limit_triggered = False
final_output = None
try:
for chunk in agent.stream(
{"messages": [HumanMessage(content=query)]},
context=UserContext(user_id="user_limit_test"),
config=ensure_config({"configurable": {"thread_id": "thread_limit_001"}}),
stream_mode="updates"
):
if isinstance(chunk, dict):
for key, value in chunk.items():
# 统计模型调用,这里进行了修改,in模式会把中间件节点算进去,==模式才是只算模型调用
if "model" == str(key).lower():
model_call_count += 1
# 检测中间件触发
if "ModelCallLimitMiddleware" in str(key):
limit_triggered = True
# 获取最终输出
if isinstance(value, dict) and "messages" in value:
messages = value["messages"]
if messages and hasattr(messages[-1], 'content'):
final_output = messages[-1].content
print(f"【输出】\n{final_output}\n")
except Exception as e:
print(f"【输出】\n执行被中断: {str(e)}\n")
if "limit" in str(e).lower() or "exceeded" in str(e).lower():
limit_triggered = True
# 输出触发结果
print("=" * 60)
print(f"模型调用次数: {model_call_count}")
print(f"中间件触发: {'✅ 是 (达到 run_limit=3 限制)' if limit_triggered else '❌ 否'}")
print("=" * 60)
# ==================== 6. 运行测试 ====================
run_limit_test()
4.2 wrap_model_call (包裹模型调用) 链接到标题
1.ContextEditingMiddleware 管理上下文大小 链接到标题
中间件类型 链接到标题
wrap_model_call - 模型调用包装中间件
概述 链接到标题
本示例展示如何使用 ContextEditingMiddleware 来自动管理上下文大小,通过清理旧的工具调用结果来防止超出 token 限制。
核心特性 链接到标题
- 自动上下文管理:当 token 数量超过阈值时自动清理旧的工具结果
- 灵活配置:支持自定义触发阈值、保留数量、排除工具等
- 智能清理:保留最近的 N 个工具结果,清理较旧的内容
- 无缝集成:在模型调用前自动处理,对业务逻辑透明
工作原理 链接到标题
当消息历史的 token 数量超过配置的阈值时,中间件会自动:
- 统计当前消息的 token 数量
- 如果超过阈值,清理旧的工具调用结果
- 保留最近的 N 个工具结果
- 将清理后的消息传递给模型
ClearToolUsesEdit 配置参数 链接到标题
- trigger: 触发清理的 token 阈值(默认 100,000)
- keep: 保留最近的 N 个工具结果(默认 3)
- clear_at_least: 最少清理的 token 数量(默认 0)
- clear_tool_inputs: 是否清理工具调用的输入参数(默认 False)
- exclude_tools: 排除不清理的工具列表(默认空)
- placeholder: 清理后的占位符文本(默认 “[cleared]")
预期结果 链接到标题
- 未超限:保留所有工具调用结果
- 超限后:自动清理旧的工具结果,只保留最近的 N 个
# ==================== ContextEditingMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import ContextEditingMiddleware
from langchain.agents.middleware.context_editing import ClearToolUsesEdit
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
# ensure_config 作用:确保在 Runnable 中获取到正确的配置
from langchain_core.runnables import ensure_config
from langgraph.checkpoint.memory import MemorySaver
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义工具 ====================
@tool
def search_database(query: str) -> str:
"""搜索数据库并返回大量结果"""
# 每次返回约 1000 个字符(约 250 tokens)
result = f"搜索 '{query}' 的结果:\n"
result += "\n".join([f"记录 {i}: 这是关于 {query} 的详细信息,包含大量文本内容..." * 5 for i in range(10)])
logger.info(f"search_database 被调用,查询: {query},返回约 {len(result)} 字符")
return result
@tool
def analyze_data(data_id: str) -> str:
"""分析数据并返回详细报告"""
# 每次返回约 1000 个字符(约 250 tokens)
result = f"数据 {data_id} 的分析报告:\n"
result += "详细分析内容包括统计数据、趋势分析、异常检测等..." * 20
logger.info(f"analyze_data 被调用,数据ID: {data_id},返回约 {len(result)} 字符")
return result
@tool
def generate_report(topic: str) -> str:
"""生成报告"""
result = f"关于 '{topic}' 的报告:\n"
result += "报告内容包括背景介绍、现状分析、未来展望等..." * 15
logger.info(f"generate_report 被调用,主题: {topic},返回约 {len(result)} 字符")
return result
tools = [search_database, analyze_data, generate_report]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 4. 配置中间件 ====================
# 关键:设置较低的触发阈值,确保能够触发清理
custom_context_middleware = ContextEditingMiddleware(
edits=[
ClearToolUsesEdit(
trigger=800, # 当 token 数超过 800 时触发清理(约 3-4 次工具调用后)
keep=1, # 只保留最近的 1 个工具结果
clear_at_least=0, # 清理所有超出keep数量的内容
clear_tool_inputs=False, # 不清理工具输入参数
exclude_tools=["generate_report"], # 不清理 generate_report 的结果
placeholder="[已清理以节省空间]", # 自定义占位符
)
],
token_count_method="approximate" # 使用近似计数(更快)
)
# ==================== 5. 创建 Agent(使用 checkpointer 来累积消息)====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1),
tools=tools,
middleware=[
custom_context_middleware, # 使用自定义配置
],
context_schema=UserContext, # 定义上下文参数,这里是 UserContext
checkpointer=MemorySaver(), # 关键:使用 checkpointer 来保存消息历史
debug=True, # 开启调试模式以观察中间件行为
)
# ==================== 6. 执行测试 ====================
def run_context_editing_test():
"""
测试 ContextEditingMiddleware 的上下文清理功能
场景:在同一个线程中执行多次查询,累积消息历史,触发上下文清理
"""
logger.info("开始 ContextEditingMiddleware 测试")
logger.info("配置: trigger=800 tokens, keep=1, exclude_tools=['generate_report']")
logger.info("策略: 在同一线程中执行多次查询,累积消息历史")
# 使用同一个 thread_id 来累积消息,ensure_config 确保在 Runnable 中获取到正确的配置
config = ensure_config({"configurable": {"thread_id": "session_context_accumulate"}})
# 初始化上下文,这里是 UserContext
context = UserContext(user_id="user_context_test")
# 定义测试查询
queries = [
"请搜索数据库中关于 'AI技术' 的信息",
"请分析数据 'dataset_001'",
"请搜索数据库中关于 '机器学习' 的信息",
"请分析数据 'dataset_002'",
"请生成关于 '人工智能发展趋势' 的报告",
]
# 记录中间件是否触发
middleware_triggered = False
for i, query in enumerate(queries, 1):
logger.info(f"\n{'='*60}")
logger.info(f"第 {i} 次查询: {query}")
logger.info(f"{'='*60}")
try:
# 执行查询
result = agent.invoke(
{"messages": [HumanMessage(content=query)]},
context=context,
config=config
)
# 检查消息历史
messages = result.get("messages", [])
logger.info(f"当前消息数量: {len(messages)}")
# 检查是否有被清理的消息
cleared_count = sum(
1 for msg in messages
if hasattr(msg, 'response_metadata')
and msg.response_metadata.get("context_editing", {}).get("cleared")
)
# 检查是否触发了中间件,如果触发了,就设置 middleware_triggered 为 True
if cleared_count > 0:
middleware_triggered = True
logger.info(f"✅ 检测到 {cleared_count} 个工具结果已被清理!")
except Exception as e:
logger.error(f"查询 {i} 出错: {e}")
import traceback
traceback.print_exc()
# 输出最终结果
logger.info("\n" + "=" * 60)
logger.info("测试完成")
logger.info(f"中间件触发: {'✅ 是 - 旧工具结果已被清理' if middleware_triggered else '❌ 否 - 未达到触发阈值'}")
logger.info("=" * 60)
# 说明
print("\n" + "=" * 60)
print("ContextEditingMiddleware 工作原理说明")
print("=" * 60)
print("1. 使用 checkpointer 在同一线程中累积消息历史")
print("2. 当消息历史超过 800 tokens 时触发清理")
print("3. 只保留最近的 1 个工具调用结果")
print("4. 'generate_report' 工具的结果不会被清理(exclude_tools)")
print("5. 被清理的内容会被替换为 '[已清理以节省空间]'")
print("6. 每个工具返回约 250 tokens,3-4 次调用后应触发清理")
print("=" * 60 + "\n")
# ==================== 7. 运行测试 ====================
run_context_editing_test()
2.ModelFallbackMiddleware 模型故障自动切换 链接到标题
中间件类型 链接到标题
wrap_model_call - 模型调用包装中间件
概述 链接到标题
本示例展示如何使用 ModelFallbackMiddleware 来实现模型故障自动切换,当主模型调用失败时自动尝试备用模型。
核心特性 链接到标题
- 自动故障转移:主模型失败时自动切换到备用模型
- 多级备份:支持配置多个备用模型,按顺序尝试
- 无缝切换:对业务逻辑透明,自动处理重试逻辑
- 提高可用性:显著提升系统的稳定性和可靠性
工作原理 链接到标题
当模型调用失败时,中间件会自动:
- 捕获主模型的异常
- 按顺序尝试备用模型
- 返回第一个成功的模型响应
- 如果所有模型都失败,抛出最后一个异常
配置参数 链接到标题
- first_model: 第一个备用模型(字符串名称或模型实例)
- additional_models: 额外的备用模型列表
预期结果 链接到标题
- 主模型成功:直接返回主模型结果
- 主模型失败:自动切换到备用模型,返回备用模型结果
# ==================== ModelFallbackMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import ModelFallbackMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义工具 ====================
@tool
def calculate_sum(a: int, b: int) -> int:
"""计算两个数的和"""
logger.info(f"calculate_sum 被调用: {a} + {b}")
return a + b
@tool
def get_system_info() -> str:
"""获取系统信息"""
logger.info("get_system_info 被调用")
return "系统运行正常,CPU使用率: 45%, 内存使用率: 60%"
tools = [calculate_sum, get_system_info]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 4. 配置中间件 ====================
# 配置模型故障转移:主模型 -> 备用模型1 -> 备用模型2
# 注意:这里使用相同的模型作为演示,实际应用中应使用不同的模型
fallback_middleware = ModelFallbackMiddleware(
ChatDeepSeek(model="deepseek-chat", temperature=0.3), # 第一个备用模型
ChatDeepSeek(model="deepseek-reasoner", temperature=0.5), # 第二个备用模型
)
# ==================== 5. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1), # 主模型
tools=tools,
middleware=[
fallback_middleware, # 添加故障转移中间件
],
context_schema=UserContext, # 定义上下文参数,这里是 UserContext
debug=False, # 关闭调试模式,避免在测试中输出详细信息
)
# ==================== 6. 执行测试 ====================
def run_fallback_test():
"""
测试 ModelFallbackMiddleware 的故障转移功能
场景:正常情况下使用主模型,模拟故障时自动切换到备用模型
"""
logger.info("开始 ModelFallbackMiddleware 测试")
logger.info("配置: 主模型(deepseek-chat) + 2个备用模型")
# 测试场景1: 正常调用(主模型成功)
logger.info("\n" + "="*60)
logger.info("场景1: 正常调用 - 主模型应该成功处理")
logger.info("="*60)
query1 = "请计算 15 + 27 的结果"
logger.info(f"查询: {query1}")
try:
result1 = agent.invoke(
{"messages": [HumanMessage(content=query1)]},
context=UserContext(user_id="user_fallback_test"), # 加入上下文参数
config=ensure_config({"configurable": {"thread_id": "session_fallback_001"}}) # 加入线程 ID
)
final_message = result1["messages"][-1]
logger.info(f"✅ 场景1成功: {final_message.content[:100]}...")
except Exception as e:
logger.error(f"❌ 场景1失败: {e}")
# 测试场景2: 复杂查询
logger.info("\n" + "="*60)
logger.info("场景2: 复杂查询 - 测试模型处理能力")
logger.info("="*60)
query2 = "请先获取系统信息,然后计算 100 + 200 的结果,最后总结一下"
logger.info(f"查询: {query2}")
try:
result2 = agent.invoke(
{"messages": [HumanMessage(content=query2)]},
context=UserContext(user_id="user_fallback_test"),
config=ensure_config({"configurable": {"thread_id": "session_fallback_002"}})
)
final_message = result2["messages"][-1]
logger.info(f"✅ 场景2成功: {final_message.content[:100]}...")
except Exception as e:
logger.error(f"❌ 场景2失败: {e}")
# 输出说明
logger.info("\n" + "="*60)
logger.info("测试完成")
logger.info("="*60)
print("\n" + "="*60)
print("ModelFallbackMiddleware 工作原理说明")
print("="*60)
print("1. 主模型: deepseek-chat (temperature=0.1)")
print("2. 备用模型1: deepseek-reasoner (temperature=0.3)")
print("3. 备用模型2: deepseek-chat (temperature=0.5)")
print("4. 当主模型调用失败时,自动尝试备用模型1")
print("5. 如果备用模型1也失败,继续尝试备用模型2")
print("6. 返回第一个成功的模型响应")
print("7. 实际应用中应配置不同的模型提供商(如 OpenAI, Anthropic 等)")
print("="*60 + "\n")
print("\n💡 提示:")
print("在生产环境中,建议配置不同提供商的模型,例如:")
print(" 主模型: openai:gpt-4o")
print(" 备用1: anthropic:claude-sonnet-4-5-20250929")
print(" 备用2: deepseek:deepseek-chat")
print("这样可以在某个提供商服务中断时,自动切换到其他提供商。\n")
# ==================== 7. 运行测试 ====================
run_fallback_test()
3.LLMToolSelectorMiddleware 智能工具选择 链接到标题
中间件类型 链接到标题
wrap_model_call - 模型调用包装中间件
概述 链接到标题
本示例展示如何使用 LLMToolSelectorMiddleware 来智能选择最相关的工具,当 Agent 拥有大量工具时,自动筛选出最相关的工具子集。
核心特性 链接到标题
- 智能工具筛选:使用 LLM 分析查询并选择最相关的工具
- 减少 Token 消耗:只将相关工具传递给主模型,降低成本
- 提高准确性:帮助主模型聚焦于正确的工具,提升响应质量
- 灵活配置:支持限制工具数量、指定必选工具、自定义选择模型
工作原理 链接到标题
在主模型调用前,中间件会自动:
- 使用选择模型分析用户查询
- 从所有可用工具中选择最相关的 N 个工具
- 将筛选后的工具列表传递给主模型
- 主模型只能看到和使用被选中的工具
配置参数 链接到标题
- model: 用于工具选择的模型(默认使用主模型)
- system_prompt: 工具选择的系统提示词
- max_tools: 最多选择的工具数量(默认无限制)
- always_include: 始终包含的工具名称列表(不计入 max_tools 限制)
预期结果 链接到标题
- 工具数量减少:从 10+ 个工具筛选到 2-3 个最相关的工具
- Token 使用降低:减少传递给主模型的工具描述,节省成本
- 响应质量提升:主模型更容易选择正确的工具
# ==================== LLMToolSelectorMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolSelectorMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.runnables import ensure_config
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义多个工具(模拟大量工具场景)====================
@tool
def search_weather(city: str) -> str:
"""查询指定城市的天气信息"""
logger.info(f"search_weather 被调用: {city}")
return f"{city}的天气:晴天,温度25°C,湿度60%"
@tool
def search_news(topic: str) -> str:
"""搜索指定主题的最新新闻"""
logger.info(f"search_news 被调用: {topic}")
return f"关于'{topic}'的最新新闻:今日头条新闻内容..."
@tool
def calculate_math(expression: str) -> str:
"""计算数学表达式的结果"""
logger.info(f"calculate_math 被调用: {expression}")
try:
result = eval(expression)
return f"计算结果: {expression} = {result}"
except:
return "计算错误"
@tool
def translate_text(text: str, target_lang: str) -> str:
"""将文本翻译成目标语言"""
logger.info(f"translate_text 被调用: {text} -> {target_lang}")
return f"翻译结果: [模拟翻译到{target_lang}]"
@tool
def search_database(query: str) -> str:
"""在数据库中搜索信息"""
logger.info(f"search_database 被调用: {query}")
return f"数据库搜索结果: 找到3条关于'{query}'的记录"
@tool
def send_email(recipient: str, subject: str) -> str:
"""发送电子邮件"""
logger.info(f"send_email 被调用: {recipient}, {subject}")
return f"邮件已发送给 {recipient}"
@tool
def get_stock_price(symbol: str) -> str:
"""获取股票价格"""
logger.info(f"get_stock_price 被调用: {symbol}")
return f"股票 {symbol} 当前价格: $150.25"
@tool
def book_meeting(date: str, time: str) -> str:
"""预订会议室"""
logger.info(f"book_meeting 被调用: {date} {time}")
return f"会议室已预订: {date} {time}"
# 所有工具列表(模拟拥有大量工具的场景)
all_tools = [
search_weather,
search_news,
calculate_math,
translate_text,
search_database,
send_email,
get_stock_price,
book_meeting,
]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 4. 配置中间件 ====================
# 配置工具选择中间件:使用 LLM 智能选择最相关的工具
tool_selector_middleware = LLMToolSelectorMiddleware(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1), # 使用较小的模型进行工具选择
max_tools=3, # 最多选择3个工具
always_include=["calculate_math"], # 始终包含数学计算工具
system_prompt="分析用户查询,选择最相关的工具。优先选择直接相关的工具。"
)
# ==================== 5. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.2), # 主模型
tools=all_tools, # 提供所有8个工具
middleware=[
tool_selector_middleware, # 添加工具选择中间件
],
context_schema=UserContext,
debug=True, # 开启调试模式以观察工具选择过程
)
# ==================== 6. 执行测试 ====================
def run_tool_selector_test():
"""
测试 LLMToolSelectorMiddleware 的智能工具选择功能
场景:从8个工具中智能选择最相关的3个工具
"""
logger.info("开始 LLMToolSelectorMiddleware 测试")
logger.info(f"配置: 总共 {len(all_tools)} 个工具,最多选择 3 个,始终包含 calculate_math")
test_queries = [
"北京今天的天气怎么样?",
"帮我计算 123 + 456 的结果",
"查询苹果公司的股票价格",
"搜索关于人工智能的最新新闻",
]
for i, query in enumerate(test_queries, 1):
logger.info("\n" + "="*60)
logger.info(f"测试场景 {i}: {query}")
logger.info("="*60)
try:
result = agent.invoke(
{"messages": [HumanMessage(content=query)]},
context=UserContext(user_id="user_selector_test"),
config=ensure_config({"configurable": {"thread_id": f"session_selector_{i:03d}"}})
)
final_message = result["messages"][-1]
logger.info(f"✅ 场景 {i} 完成")
logger.info(f"响应摘要: {final_message.content[:80]}...")
except Exception as e:
logger.error(f"❌ 场景 {i} 失败: {e}")
import traceback
traceback.print_exc()
# 输出说明
logger.info("\n" + "="*60)
logger.info("测试完成")
logger.info("="*60)
print("\n" + "="*60)
print("LLMToolSelectorMiddleware 工作原理说明")
print("="*60)
print("1. Agent 配置了 8 个不同功能的工具")
print("2. 中间件使用 LLM 分析用户查询")
print("3. 从 8 个工具中智能选择最相关的 3 个")
print("4. calculate_math 工具始终被包含(always_include)")
print("5. 主模型只能看到被选中的工具")
print("6. 这样可以减少 token 消耗,提高响应质量")
print("="*60 + "\n")
print("\n💡 优势:")
print("- Token 节省:只传递相关工具描述,减少约 60-70% 的工具相关 token")
print("- 准确性提升:主模型更容易选择正确的工具")
print("- 成本降低:减少 API 调用成本")
print("- 可扩展性:支持数十甚至上百个工具的场景\n")
# ==================== 7. 运行测试 ====================
run_tool_selector_test()
4.3 wrap_tool_call (包裹工具调用) 链接到标题
1.ToolRetryMiddleware 自动重试工具调用 链接到标题
中间件类型 链接到标题
wrap_tool_call - 工具调用包装中间件
概述 链接到标题
本示例展示如何使用 ToolRetryMiddleware 来自动重试失败的工具调用,提高系统的稳定性和可靠性。
核心特性 链接到标题
- 自动重试:工具调用失败时自动重试,无需手动处理
- 指数退避:支持指数退避策略,避免过度请求
- 灵活配置:可配置重试次数、退避因子、延迟时间等
- 异常过滤:支持只重试特定类型的异常
- 工具级控制:可以针对特定工具配置重试策略
工作原理 链接到标题
当工具调用失败时,中间件会自动:
- 捕获工具调用异常
- 检查是否应该重试(基于异常类型和重试次数)
- 等待一段时间(使用指数退避策略)
- 重新执行工具调用
- 返回成功结果或最终失败消息
配置参数 链接到标题
- max_retries: 最大重试次数(默认 2)
- tools: 应用重试的工具列表(默认所有工具)
- retry_on: 应该重试的异常类型或判断函数
- on_failure: 失败时的处理方式(‘raise’ 或 ‘return_message’ 或自定义函数)
- backoff_factor: 退避因子(默认 2.0)
- initial_delay: 初始延迟时间(默认 1.0 秒)
- max_delay: 最大延迟时间(默认 60.0 秒)
- jitter: 是否添加随机抖动(默认 True)
预期结果 链接到标题
- 临时故障:自动重试后成功执行
- 持续故障:达到最大重试次数后返回友好的错误消息
# ==================== ToolRetryMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.runnables import ensure_config
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
import random
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义工具(模拟可能失败的工具)====================
# 全局计数器,用于模拟间歇性故障
call_counts = {}
@tool
def unreliable_api_call(query: str) -> str:
"""
模拟不稳定的 API 调用
前2次调用会失败,第3次成功
"""
if 'unreliable_api_call' not in call_counts:
call_counts['unreliable_api_call'] = 0
call_counts['unreliable_api_call'] += 1
attempt = call_counts['unreliable_api_call']
logger.info(f"unreliable_api_call 第 {attempt} 次调用: {query}")
# 前2次调用失败
if attempt <= 2:
logger.warning(f"模拟 API 调用失败(第 {attempt} 次尝试)")
raise ConnectionError(f"API 连接失败(尝试 {attempt}/3)")
# 第3次成功
logger.info(f"✅ API 调用成功(第 {attempt} 次尝试)")
return f"API 查询成功: '{query}' 的结果数据"
@tool
def stable_tool(data: str) -> str:
"""稳定的工具,总是成功"""
logger.info(f"stable_tool 被调用: {data}")
return f"处理完成: {data}"
@tool
def random_failure_tool(input_text: str) -> str:
"""
随机失败的工具
50% 概率失败
"""
logger.info(f"random_failure_tool 被调用: {input_text}")
if random.random() < 0.5:
logger.warning("模拟随机失败")
raise RuntimeError("随机错误:服务暂时不可用")
logger.info("✅ 随机工具调用成功")
return f"随机工具处理结果: {input_text}"
tools = [unreliable_api_call, stable_tool, random_failure_tool]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 4. 配置中间件 ====================
# 配置工具重试中间件:自动重试失败的工具调用
retry_middleware = ToolRetryMiddleware(
max_retries=3, # 最多重试3次
tools=["unreliable_api_call", "random_failure_tool"], # 只对这两个工具启用重试
retry_on=(ConnectionError, RuntimeError), # 只重试这些异常
on_failure="return_message", # 失败时返回友好消息而不是抛出异常
backoff_factor=1.5, # 退避因子,每次重试延迟增加1.5倍
initial_delay=0.5, # 初始延迟0.5秒
max_delay=5.0, # 最大延迟5秒
jitter=True, # 添加随机抖动,避免同时重试
)
# ==================== 5. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.2),
tools=tools,
middleware=[
retry_middleware, # 添加重试中间件
],
context_schema=UserContext,
debug=False,
)
# ==================== 6. 执行测试 ====================
def run_retry_test():
"""
测试 ToolRetryMiddleware 的自动重试功能
场景:测试不稳定工具的自动重试机制
"""
logger.info("开始 ToolRetryMiddleware 测试")
logger.info("配置: max_retries=3, 对 unreliable_api_call 和 random_failure_tool 启用重试")
# 重置计数器
call_counts.clear()
# 测试场景1: 不稳定的 API 调用(前2次失败,第3次成功)
logger.info("\n" + "="*60)
logger.info("场景1: 测试不稳定的 API 调用(应该在重试后成功)")
logger.info("="*60)
query1 = "请调用 unreliable_api_call 查询用户数据"
logger.info(f"查询: {query1}")
try:
result1 = agent.invoke(
{"messages": [HumanMessage(content=query1)]},
context=UserContext(user_id="user_retry_test"),
config=ensure_config({"configurable": {"thread_id": "session_retry_001"}})
)
final_message = result1["messages"][-1]
logger.info(f"✅ 场景1完成")
logger.info(f"响应: {final_message.content[:100]}...")
except Exception as e:
logger.error(f"❌ 场景1失败: {e}")
# 测试场景2: 稳定工具(不需要重试)
logger.info("\n" + "="*60)
logger.info("场景2: 测试稳定工具(不需要重试)")
logger.info("="*60)
query2 = "请使用 stable_tool 处理数据"
logger.info(f"查询: {query2}")
try:
result2 = agent.invoke(
{"messages": [HumanMessage(content=query2)]},
context=UserContext(user_id="user_retry_test"),
config=ensure_config({"configurable": {"thread_id": "session_retry_002"}})
)
final_message = result2["messages"][-1]
logger.info(f"✅ 场景2完成")
logger.info(f"响应: {final_message.content[:100]}...")
except Exception as e:
logger.error(f"❌ 场景2失败: {e}")
# 输出说明
logger.info("\n" + "="*60)
logger.info("测试完成")
logger.info("="*60)
print("\n" + "="*60)
print("ToolRetryMiddleware 工作原理说明")
print("="*60)
print("1. unreliable_api_call 工具前2次调用失败")
print("2. 中间件自动捕获 ConnectionError 异常")
print("3. 使用指数退避策略等待后重试")
print("4. 第3次调用成功,返回结果")
print("5. stable_tool 工具始终成功,不需要重试")
print("6. 重试机制对业务逻辑完全透明")
print("="*60 + "\n")
print("\n💡 重试策略:")
print("- 第1次重试延迟: 0.5秒 × 1.5^0 = 0.5秒")
print("- 第2次重试延迟: 0.5秒 × 1.5^1 = 0.75秒")
print("- 第3次重试延迟: 0.5秒 × 1.5^2 = 1.125秒")
print("- 添加随机抖动避免雷鸣群效应")
print("\n🎯 适用场景:")
print("- 网络请求不稳定")
print("- 外部 API 限流")
print("- 数据库连接超时")
print("- 临时性服务故障\n")
# ==================== 7. 运行测试 ====================
run_retry_test()
2.LLMToolEmulator 模拟工具执行 链接到标题
中间件类型 链接到标题
wrap_tool_call - 工具调用包装中间件
概述 链接到标题
本示例展示如何使用 LLMToolEmulator 来使用 LLM 模拟工具执行,而不是真正调用工具。这对于测试、演示和开发非常有用。
核心特性 链接到标题
- LLM 模拟执行:使用 LLM 生成模拟的工具执行结果
- 选择性模拟:可以选择模拟特定工具或所有工具
- 安全测试:在不执行真实操作的情况下测试 Agent 逻辑
- 快速原型:无需实现真实工具即可测试 Agent 流程
工作原理 链接到标题
当工具被调用时,中间件会自动:
- 拦截工具调用请求
- 检查该工具是否在模拟列表中
- 使用 LLM 根据工具描述和参数生成模拟结果
- 返回模拟结果而不是执行真实工具
配置参数 链接到标题
- tools: 要模拟的工具列表(工具名称或 BaseTool 实例)
None: 模拟所有工具(默认)[]: 不模拟任何工具["tool1", "tool2"]: 只模拟指定的工具
- model: 用于模拟的 LLM 模型(默认 anthropic:claude-sonnet-4-5-20250929)
预期结果 链接到标题
- 模拟工具:返回 LLM 生成的模拟结果,不执行真实操作
- 非模拟工具:正常执行真实工具代码
# ==================== LLMToolEmulator 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolEmulator
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.runnables import ensure_config
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义工具 ====================
@tool
def send_real_email(recipient: str, subject: str, body: str) -> str:
"""
发送真实邮件(在测试中会被模拟)
实际生产环境中这会真正发送邮件
"""
logger.info(f"⚠️ send_real_email 被真实调用: {recipient}")
# 这里应该是真实的邮件发送逻辑
return f"真实邮件已发送给 {recipient},主题: {subject}"
@tool
def charge_credit_card(card_number: str, amount: float) -> str:
"""
真实扣款(在测试中会被模拟)
实际生产环境中这会真正扣款
"""
logger.info(f"⚠️ charge_credit_card 被真实调用: ${amount}")
# 这里应该是真实的支付逻辑
return f"已从卡号 {card_number} 扣款 ${amount}"
@tool
def delete_database_record(record_id: str) -> str:
"""
删除数据库记录(在测试中会被模拟)
实际生产环境中这会真正删除数据
"""
logger.info(f"⚠️ delete_database_record 被真实调用: {record_id}")
# 这里应该是真实的数据库删除逻辑
return f"记录 {record_id} 已从数据库中删除"
@tool
def safe_query_tool(query: str) -> str:
"""
安全的查询工具(不会被模拟,真实执行)
"""
logger.info(f"✅ safe_query_tool 被真实调用: {query}")
return f"查询结果: 找到关于 '{query}' 的 5 条记录"
tools = [send_real_email, charge_credit_card, delete_database_record, safe_query_tool]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 4. 配置中间件 ====================
# 配置工具模拟中间件:使用 LLM 模拟危险操作,避免真实执行
emulator_middleware = LLMToolEmulator(
tools=["send_real_email", "charge_credit_card", "delete_database_record"], # 只模拟这些危险工具
model=ChatDeepSeek(model="deepseek-chat", temperature=0.7), # 使用 DeepSeek 进行模拟
)
# ==================== 5. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.2),
tools=tools,
middleware=[
emulator_middleware, # 添加工具模拟中间件
],
context_schema=UserContext,
debug=True, # 开启调试模式以观察模拟过程
)
# ==================== 6. 执行测试 ====================
def run_emulator_test():
"""
测试 LLMToolEmulator 的工具模拟功能
场景:测试危险操作的模拟执行,确保不会真实执行
"""
logger.info("开始 LLMToolEmulator 测试")
logger.info("配置: 模拟 send_real_email, charge_credit_card, delete_database_record")
logger.info("safe_query_tool 不被模拟,会真实执行")
test_scenarios = [
("场景1: 发送邮件(应该被模拟)", "请发送邮件给 test@example.com,主题是测试邮件"),
("场景2: 信用卡扣款(应该被模拟)", "请从卡号 1234-5678-9012-3456 扣款 99.99 美元"),
("场景3: 删除数据(应该被模拟)", "请删除数据库中 ID 为 record_123 的记录"),
("场景4: 安全查询(应该真实执行)", "请查询用户信息"),
]
for i, (scenario_name, query) in enumerate(test_scenarios, 1):
logger.info("\n" + "="*60)
logger.info(scenario_name)
logger.info("="*60)
logger.info(f"查询: {query}")
try:
result = agent.invoke(
{"messages": [HumanMessage(content=query)]},
context=UserContext(user_id="user_emulator_test"),
config=ensure_config({"configurable": {"thread_id": f"session_emulator_{i:03d}"}})
)
final_message = result["messages"][-1]
logger.info(f"✅ {scenario_name} 完成")
logger.info(f"响应摘要: {final_message.content[:80]}...")
except Exception as e:
logger.error(f"❌ {scenario_name} 失败: {e}")
import traceback
traceback.print_exc()
# 输出说明
logger.info("\n" + "="*60)
logger.info("测试完成")
logger.info("="*60)
print("\n" + "="*60)
print("LLMToolEmulator 工作原理说明")
print("="*60)
print("1. send_real_email, charge_credit_card, delete_database_record 被 LLM 模拟")
print("2. 这些工具的代码不会被真实执行")
print("3. LLM 根据工具描述和参数生成合理的模拟结果")
print("4. safe_query_tool 不在模拟列表中,会真实执行")
print("5. 日志中可以看到哪些工具被真实调用(⚠️)或模拟(无标记)")
print("="*60 + "\n")
print("\n🎯 使用场景:")
print("- 测试环境:避免执行危险操作(删除、扣款、发送邮件等)")
print("- 快速原型:无需实现真实工具即可测试 Agent 流程")
print("- 演示系统:展示功能而不触发真实操作")
print("- 开发调试:在开发阶段模拟外部 API 调用")
print("\n💡 最佳实践:")
print("- 在测试环境中模拟所有危险操作")
print("- 在生产环境中移除模拟中间件")
print("- 使用环境变量控制是否启用模拟")
print("- 模拟结果应该尽可能接近真实结果\n")
# ==================== 7. 运行测试 ====================
run_emulator_test()
4.2 after_model 模型调用后 链接到标题
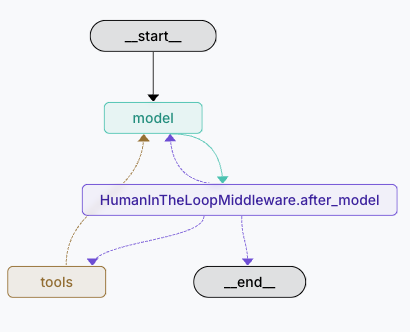
1.HumanInTheLoopMiddleware 人工干预中间件 链接到标题
中间件类型 链接到标题
after_model - 模型调用后中间件
概述 链接到标题
本示例展示如何使用 HumanInTheLoopMiddleware 来实现人工审批流程,确保关键操作在执行前得到人工确认。
核心特性 链接到标题
- 官方中间件集成:使用
from langchain.agents.middleware import HumanInTheLoopMiddleware - 工具调用拦截:在
create_agent中通过middleware参数集成 - 灵活审批策略:支持 approve(批准)、edit(编辑)、reject(拒绝)三种决策
- 无缝集成:中间件自动处理中断和恢复逻辑
工作原理 链接到标题
当 AI 决定调用需要审批的工具时,中间件会自动:
- 拦截工具调用请求
- 触发中断(interrupt),等待人工决策
- 根据人工决策执行相应操作(批准/编辑/拒绝)
- 继续或终止执行流程
审批决策类型 链接到标题
- approve:批准执行,使用原始参数
- edit:修改参数后执行
- reject:拒绝执行,返回错误消息
预期结果 链接到标题
- 无中间件:AI 直接调用工具发送邮件
- 有中间件:执行暂停,等待人工批准后才发送邮件
# ========================================
# LangChain 1.0 人工审批中间件实战
# ========================================
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langchain.agents.middleware.human_in_the_loop import (
HITLResponse,
ApproveDecision,
EditDecision,
RejectDecision
)
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from langgraph.types import Command
# 1. 加载环境变量
load_dotenv(override=True)
# ---------------------------------------------------------------------------
# 2. 定义工具 (Tools)
# ---------------------------------------------------------------------------
class SendEmailSchema(BaseModel):
recipient: str = Field(description="邮件接收者的邮箱地址")
subject: str = Field(description="邮件主题")
body: str = Field(description="邮件正文内容")
@tool(args_schema=SendEmailSchema)
def send_email(recipient: str, subject: str, body: str):
"""模拟发送邮件的工具"""
print(f"\n======== [SYSTEM ACTION: 正在执行发送邮件] ========")
print(f"收件人: {recipient}")
print(f"主题 : {subject}")
print(f"内容 : {body}")
print(f"================================================\n")
return f"邮件已成功发送给 {recipient}"
tools = [send_email]
# ---------------------------------------------------------------------------
# 3. 创建模型
# ---------------------------------------------------------------------------
model = ChatDeepSeek(model="deepseek-chat")
# ---------------------------------------------------------------------------
# 4. 创建带 HumanInTheLoopMiddleware 的图
# ---------------------------------------------------------------------------
system_prompt = """
你是一个专业的行政助手。
当用户请求发送邮件时,你必须直接调用 `send_email` 工具。
不要问任何后续问题,不要要求确认,直接生成工具调用。
"""
# 定义中间件:指定 'send_email' 工具需要中断审批
# interrupt_on 字典中的 True 表示允许批准、编辑和拒绝
hitl_middleware = HumanInTheLoopMiddleware(
interrupt_on={"send_email": True},
description_prefix="需要人工批准才能发送邮件"
)
# 使用 create_agent 创建图,并注入中间件
# LangGraph Studio 会自动处理持久化,不需要传入 checkpointer
graph = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt,
middleware=[hitl_middleware]
)
# ---------------------------------------------------------------------------
# 5. 定义观察和执行函数
# ---------------------------------------------------------------------------
def run_interactive_session():
"""本地运行的交互式会话(需要 checkpointer)"""
from langgraph.checkpoint.memory import MemorySaver
# 本地运行时需要创建带 checkpointer 的 graph
local_graph = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt,
middleware=[hitl_middleware],
checkpointer=MemorySaver() # 本地运行需要
)
# 配置线程 ID,用于区分不同的对话会话
thread_id = "demo_thread_middleware_1"
config = {"configurable": {"thread_id": thread_id}}
user_input = "帮我给 hr@example.com 发一封邮件,主题是'休假申请',内容是我下周一想请假一天。"
print(f"\n[用户]: {user_input}")
# === 第一步:初始执行 ===
print("\n[系统]: 开始处理请求...")
# input 传入用户消息
# stream_mode="values" 可以让我们看到消息流
for event in local_graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config=config,
stream_mode="values"
):
# 简单打印最后一条消息的内容
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and last_msg.tool_calls:
print(f"[AI 思考]: 决定调用工具 -> {last_msg.tool_calls[0]['name']}")
# === 第二步:观察 (Observation) ===
# 中间件应该触发了中断
snapshot = local_graph.get_state(config)
print(f"\n--- 🛑 执行已暂停 (HITL Middleware) ---")
print(f"下一步骤 (Next): {snapshot.next}")
print(f"任务数量: {len(snapshot.tasks) if snapshot.tasks else 0}")
# 检查是否有任务(这表示中断发生)
if snapshot.tasks:
# 获取最后一条消息
last_message = snapshot.values["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
tool_call = last_message.tool_calls[0]
print(f"\n[待审批操作]:")
print(f" - 工具: {tool_call['name']}")
print(f" - 参数: {tool_call['args']}")
# === 第三步:人工介入 (Human Input) ===
approval = input("\n[管理员]: 是否批准执行此操作? (y/n/e[编辑]): ")
if approval.lower() == 'y':
# === 第四步:恢复执行 (Resume) - 批准 ===
print("\n[系统]: 操作已批准,继续执行...")
# 创建 HITLResponse 对象,包含 ApproveDecision
hitl_response = HITLResponse(
decisions=[ApproveDecision(type="approve")]
)
# 使用 Command(resume=hitl_response) 来批准并继续执行
for event in local_graph.stream(
Command(resume=hitl_response), # 传入 HITLResponse 对象
config=config,
stream_mode="values"
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "tool":
print(f"[工具输出]: {last_msg.content}")
elif last_msg.type == "ai" and last_msg.content:
print(f"[AI 回复]: {last_msg.content}")
elif approval.lower() == 'e':
# === 编辑工具调用参数 ===
print("\n[系统]: 编辑模式...")
print(f"当前参数: {tool_call['args']}")
# 让用户编辑参数
new_recipient = input(f"新收件人 (当前: {tool_call['args'].get('recipient', '')},留空保持不变): ").strip()
new_subject = input(f"新主题 (当前: {tool_call['args'].get('subject', '')},留空保持不变): ").strip()
new_body = input(f"新内容 (当前: {tool_call['args'].get('body', '')},留空保持不变): ").strip()
# 构建新的参数
updated_args = tool_call['args'].copy()
if new_recipient:
updated_args['recipient'] = new_recipient
if new_subject:
updated_args['subject'] = new_subject
if new_body:
updated_args['body'] = new_body
print(f"\n[系统]: 使用更新后的参数继续执行...")
print(f"更新后的参数: {updated_args}")
# 创建 HITLResponse 对象,包含 EditDecision
# EditDecision 需要 edited_action,包含 name 和 args
hitl_response = HITLResponse(
decisions=[EditDecision(
type="edit",
edited_action={
"name": tool_call['name'],
"args": updated_args
}
)]
)
# 使用 Command(resume=hitl_response) 来批准并使用新参数
for event in local_graph.stream(
Command(resume=hitl_response), # 传入包含编辑决策的 HITLResponse
config=config,
stream_mode="values"
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "tool":
print(f"[工具输出]: {last_msg.content}")
elif last_msg.type == "ai" and last_msg.content:
print(f"[AI 回复]: {last_msg.content}")
else:
# === 拒绝操作 ===
print("\n[系统]: 操作被拒绝。")
# 创建 HITLResponse 对象,包含 RejectDecision
rejection_reason = input("拒绝原因 (可选): ").strip() or "操作被管理员拒绝"
hitl_response = HITLResponse(
decisions=[RejectDecision(
type="reject",
message=rejection_reason
)]
)
# 使用 Command(resume=hitl_response) 来拒绝
for event in local_graph.stream(
Command(resume=hitl_response), # 传入包含拒绝决策的 HITLResponse
config=config,
stream_mode="values"
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"[AI 回复]: {last_msg.content}")
elif last_msg.type == "tool":
print(f"[工具消息]: {last_msg.content}")
print("[系统]: 流程已终止。")
else:
print("没有检测到待处理的工具调用。")
else:
print("流程已完成,没有触发中断。")
# 打印最终结果
if snapshot.values.get("messages"):
last_msg = snapshot.values["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"\n[最终回复]: {last_msg.content}")
run_interactive_session()
2.ToolCallLimitMiddleware 工具调用限制 链接到标题
中间件类型 链接到标题
wrap_tool_call - 工具调用包装中间件
概述 链接到标题
本示例展示如何使用 ToolCallLimitMiddleware 来限制 Agent 的工具调用频率或总量,防止工具被滥用或过度消耗资源。
核心特性 链接到标题
- 资源保护:防止特定工具被频繁调用
- 灵活配置:支持全局限制或针对特定工具的限制
- 自动熔断:达到限制后阻止工具执行并返回错误
工作原理 链接到标题
中间件会跟踪当前会话中的工具调用次数。当特定工具或总工具调用次数达到设定的阈值时,中间件会阻止后续的工具调用,并引发异常或返回预设的响应。
预期结果 链接到标题
- 正常情况:工具调用次数未超限,正常执行
- 超限情况:抛出
ToolCallLimitExceeded异常或返回错误信息
# ==================== ToolCallLimitMiddleware 完整实现 ====================
from langchain.agents import create_agent
from langchain.agents.middleware import ToolCallLimitMiddleware
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.runnables import ensure_config
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
# ==================== 1. 配置日志 ====================
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
load_dotenv(override=True)
# ==================== 2. 定义工具 ====================
@tool
def check_server_status(server_id: str) -> str:
"""检查服务器状态"""
logger.info(f"正在检查服务器 {server_id} 的状态...")
return f"服务器 {server_id} 运行正常,负载 45%"
@tool
def restart_server(server_id: str) -> str:
"""重启服务器"""
logger.info(f"正在重启服务器 {server_id}...")
return f"服务器 {server_id} 已重启"
tools = [check_server_status, restart_server]
# ==================== 3. 定义上下文 ====================
class UserContext(BaseModel):
user_id: str = Field(..., description="用户唯一标识")
# ==================== 4. 配置中间件 ====================
# 方式1: 限制所有工具的调用次数(全局限制)
global_tool_limiter = ToolCallLimitMiddleware(
tool_name=None, # None = 限制所有工具
run_limit=3, # 每次运行最多调用 3 次工具
exit_behavior="continue" # 超限后阻止工具调用,但继续执行
)
# 方式2: 限制特定工具的调用次数
specific_tool_limiter = ToolCallLimitMiddleware(
tool_name="check_server_status", # 只限制 check_server_status 工具
thread_limit=5, # 整个线程最多调用 5 次
run_limit=2, # 每次运行最多调用 2 次
exit_behavior="error" # 超限后返回错误消息
)
# ==================== 5. 创建 Agent ====================
agent = create_agent(
model=ChatDeepSeek(model="deepseek-chat", temperature=0.1),
tools=tools,
middleware=[
specific_tool_limiter, # 使用特定工具限制器
],
context_schema=UserContext,
debug=False,
)
# ==================== 6. 执行测试 ====================
def run_tool_limit_test():
logger.info("开始 ToolCallLimitMiddleware 测试")
logger.info("配置: check_server_status 工具限制为 run_limit=2")
# 设计一个会触发多次工具调用的场景
query = """
请帮我检查以下服务器的状态:
1. Server-A
2. Server-B
3. Server-C
4. Server-D
请逐个检查每台服务器。
"""
logger.info(f"用户查询: {query.strip()}")
tool_call_count = 0
limit_triggered = False
try:
for chunk in agent.stream(
{"messages": [HumanMessage(content=query)]},
context=UserContext(user_id="user_tool_limit"),
config=ensure_config({"configurable": {"thread_id": "session_tool_limit_001"}}),
stream_mode="updates"
):
if isinstance(chunk, dict):
for key, value in chunk.items():
# 统计工具调用
if "tools" in str(key).lower():
tool_call_count += 1
# 检测中间件触发
if "ToolCallLimitMiddleware" in str(key):
limit_triggered = True
logger.warning("检测到 ToolCallLimitMiddleware 触发!")
logger.info("任务完成")
except Exception as e:
logger.error(f"捕获到异常: {e}")
if "limit" in str(e).lower() or "exceeded" in str(e).lower():
limit_triggered = True
return str(e)
# 输出结果
logger.info("=" * 60)
logger.info(f"工具调用次数: {tool_call_count}")
logger.info(f"中间件触发: {'✅ 是' if limit_triggered else '❌ 否'}")
logger.info("=" * 60)
# ==================== 7. 运行测试 ====================
run_tool_limit_test()
第五阶段:自定义中间件应用 链接到标题
5.1 中间件的参数传递机制 链接到标题
1.ModelRequest/Response 链接到标题
ModelRequest/Response:单次调用级别的"细粒度控制”
作用域:仅作用于单次模型或工具调用的生命周期
数据内容:包含当前调用的具体参数(model, messages, tools, config)
类比:类似 HTTP 请求中的 Request 对象,是瞬态的
典型来源:@wrap_model_call, @wrap_tool_call, @dynamic_prompt 等包裹式钩子
# ModelRequest 结构示例
request = ModelRequest(
model=ChatOpenAI(...), # 可动态替换的模型实例
messages=[...], # 本次调用的消息列表(可被修改)
tools=[...], # 本次可用的工具列表(可被过滤)
runtime=context # 包含 AgentState 的引用
)
# 典型结构
request.model # 当前要调用的模型实例(可修改)
request.tools # 可用工具列表(可修改)
request.messages # 消息历史
request.state # Agent 的当前状态
request.runtime # 运行时上下文,包含 request.runtime.context 等
关键特性:
可变性:你可以在中间件中直接修改 request.model、request.tools 等属性,实现动态路由
信息丰富:携带了完整的执行上下文,便于实现条件逻辑
拦截点:在模型实际调用前,允许你审查或修改任何参数
handler: Callable[[ModelRequest], ModelResponse] —— 执行器函数 链接到标题
- handler 是 实际执行模型调用的函数,它是 LangChain 内部封装的"下一个"执行环节。你可以理解为:
核心作用:
控制权:你可以选择是否调用 handler(request),甚至多次调用(如重试)
责任链:调用 handler 相当于将请求传递给链条的下一环
不可变性:handler 本身不可修改,但你可以通过修改 request 来影响其行为
# handler 本质上等价于:
def handler(request: ModelRequest) -> ModelResponse:
# 实际调用 LLM 模型并返回响应
return actual_model_call(request)
AgentState:整个Agent生命周期的"全局状态容器" 链接到标题
AgentState:
作用域:贯穿整个 Agent 执行流程,跨多次模型调用
数据内容:完整的对话历史、用户元数据、业务状态字段
类比:类似 Redux Store 或全局上下文,是持久化的
典型来源:@before_model, @after_model, @before_agent 等节点式钩子需要跨多次调用持久化数据"、或者需要访问完整对话历史
总结:在 @wrap_model_call 和 @wrap_tool_call 等包裹类hook中,所有 request 字段都可直接赋值修改(框架特批),但 config 除外;在 @before_model、@after_model 等钩子中,只能读取 state,不能访问 request。
| 参数类型 | 本质 | 所属模块 | 生命周期 |
|---|---|---|---|
ModelRequest | 数据类(dataclass) | langchain.agents.middleware.base | 单次模型调用 |
ModelResponse | 数据类(dataclass) | langchain.agents.middleware.base | 单次模型调用 |
AgentState | 字典结构(TypedDict) | langchain.agents.agent | 整个 Agent 会话 |
handler | 函数对象(可调用) | 动态传递 | 单次包装调用 |
5.2 装饰器dynamic_prompt 动态提示词(wrap_model_call) 链接到标题
from langchain.agents import create_agent
from langchain.tools import tool
from langchain.agents.middleware import ModelRequest, ModelResponse
from langchain.agents.middleware import dynamic_prompt
from typing import TypedDict
# 1. 定义一个简单的天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 2. 定义上下文结构
class Context(TypedDict):
user_role: str # 用户角色
# 3. 动态提示函数
@dynamic_prompt
def role_based_prompt(request:ModelRequest):
"""根据用户角色生成不同提示词"""
user_role = request.runtime.context.get("user_role", "user")
if user_role == "expert":
return "你是一个专业气象分析师,提供详细数据"
elif user_role == "beginner":
return "你是一个友善的导游,用简单语言解释"
else:
return "你是一个简洁的天气助手"
# 4. 创建动态 Agent
agent_dynamic = create_agent(
model="openai:gpt-4o-mini",
tools=[get_weather],
middleware=[role_based_prompt], # 注入动态提示
context_schema=Context
)
print("\n=== 动态 System Prompt(专家角色)===")
response2 = agent_dynamic.invoke(
{"messages": [{"role": "user", "content": "北京天气"}]},
context={"user_role": "expert"}
)
print(f"AI: {response2['messages'][-1].content}")
print("\n=== 动态 System Prompt(新手角色)===")
response3 = agent_dynamic.invoke(
{"messages": [{"role": "user", "content": "北京天气"}]},
context={"user_role": "beginner"}
)
print(f"AI: {response3['messages'][-1].content}")
5.3 使用装饰器实现模型动态切换(wrap_model_call) 链接到标题
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from typing import Callable,TypedDict
# 定义上下文结构
class Context(TypedDict):
user_role: str # 用户角色
# 1. 定义两个模型实例
small_model = ChatOpenAI(model="gpt-4o-mini")
large_model = ChatOpenAI(model="gpt-4o")
hard_keywords = ("证明", "推导", "严谨", "规划","复杂", "多步骤", "chain of thought",
"step-by-step", "reason step by step", "数学", "逻辑证明", "约束求解")
# 2. 定义动态模型切换的中间件
@wrap_model_call
async def dynamic_model_router(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
根据对话上下文动态切换模型
"""
# 获取当前对话的状态(例如消息列表)
state = request.state
print(f"--- [Middleware] 当前对话状态: {state} ---")
messages = state.get("messages", [])
print(f"--- [Middleware] 当前消息数量: {len(messages)} ---")
# 获取上下文中的用户角色
print(f"打印运行时上下文: {request.runtime.context}")
# === 逻辑判断示例 ===
# 场景 A: 如果对话轮数超过 5 轮,切换到大模型处理复杂上下文
if len(messages) > 5:
print(f"--- [Middleware] 检测到长对话 ({len(messages)} msgs),切换至 GPT-4o ---")
# 使用 .override() 方法替换本次调用的模型
request = request.override(model=large_model)
# 场景 B: 如果用户输入包含特定关键词 (仅作演示,实际可用分类器)
elif messages and "复杂分析" in messages[-1].content or any(kw.lower() in messages[-1].content for kw in hard_keywords):
print("--- [Middleware] 检测到复杂任务,切换至 GPT-4o ---")
request = request.override(model=large_model)
else:
print("--- [Middleware] 使用默认小模型 GPT-4o-mini ---")
# 默认使用 create_agent 初始化时传入的模型(即 small_model)
# 继续执行调用
return await handler(request)
# 3. 定义工具(可选)
@tool
def get_weather(city: str):
"""查询天气"""
return f"{city} 的天气是晴天"
# 4. 创建 Agent 并注入中间件
agent = create_agent(
model=small_model, # 默认模型
tools=[get_weather],
middleware=[dynamic_model_router], # <--- 关键:注入动态路由中间件
context_schema=Context # 上下文类型
)
# 5. 测试调用
print(">>> User: 你好")
await agent.ainvoke(
{"messages": [{"role": "user", "content": "你好"}]},
context={"user_role": "expert"}
)
print("\n>>> User: 请进行复杂的市场分析(模拟触发切换)")
await agent.ainvoke(
{"messages": [{"role": "user", "content": "请进行复杂的市场分析"}]},
context={"user_role": "expert"}
)
5.4 persist_session (会话持久化) 链接到标题
中间件类型 链接到标题
after_model - 会话持久化包装器
概述 链接到标题
本示例展示如何使用 persist_session 中间件来实现会话的自动持久化。这是一个简化的接口,用于快速为 Agent 添加持久化能力。
核心特性 链接到标题
- 自动保存:在 Agent 执行过程中自动保存会话状态
- 简单易用:作为中间件直接集成
预期结果 链接到标题
每次对话后,会话状态会被保存到指定目录。
# ==================== persist_session 轻量包装器实现 ====================
from langchain.agents.middleware import AgentMiddleware, AgentState
import os
import json
import time
from typing import Dict, Any
class PersistSessionMiddleware(AgentMiddleware):
def __init__(self, path: str):
super().__init__()
self.path = path
if not os.path.exists(path):
os.makedirs(path)
def after_model(self, state: AgentState, runtime) -> None:
"""在模型调用后保存会话"""
# 使用当前时间戳作为简单的会话标识或检查点
timestamp = int(time.time())
print(f"打印state以供调试: {state}")
messages = state.get("messages", [])
if not messages:
return
# 仅保存最后一条 AI 消息作为演示,或者保存整个历史
filename = os.path.join(self.path, f"state_{timestamp}.json")
# 简化的序列化
serialized_msgs = []
for msg in messages:
msg_data = {
"role": msg.type,
"content": msg.content
}
if hasattr(msg, 'tool_calls') and msg.tool_calls:
msg_data['tool_calls'] = msg.tool_calls
serialized_msgs.append(msg_data)
try:
with open(filename, "w", encoding="utf-8") as f:
json.dump(serialized_msgs, f, ensure_ascii=False, indent=2)
print(f" [persist_session] 会话状态已保存: {filename}")
except Exception as e:
print(f" [persist_session] 保存失败: {e}")
def persist_session(path: str = "./sessions"):
"""
persist_session 轻量包装器
Args:
path: 会话持久化保存的目录路径
"""
return PersistSessionMiddleware(path)
# ==================== 使用示例 ====================
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 1. 创建 Agent
# 这里我们使用 persist_session 包装器
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini"),
tools=[],
middleware=[persist_session(path="./my_agent_sessions")]
)
# 2. 运行测试
print(">>> 开始 persist_session 演示...")
# 第一次交互
print("\n>>> User: 这是一个测试消息,请保存。")
# 异步调用
await agent.ainvoke({"messages": [HumanMessage(content="这是一个测试消息,请保存。")]})
state: AgentState结构展示
{
'messages': [
HumanMessage(
content = '这是一个测试消息,请保存。', additional_kwargs = {},
response_metadata = {},
id = 'f410d2b9-3ffe-44aa-90a5-9297c7f050ef'
),
AIMessage(
content = '抱歉,我无法保存消息或数据。但我可以帮助回答问题或提供信息。如果你有其他需要,随时告诉我!',
additional_kwargs = {
'refusal': None
},
response_metadata = {
'token_usage': {
'completion_tokens': 28,
'prompt_tokens': 14,
'total_tokens': 42,
'completion_tokens_details': {
'accepted_prediction_tokens': 0,
'audio_tokens': 0,
'reasoning_tokens': 0,
'rejected_prediction_tokens': 0
},
'prompt_tokens_details': {
'audio_tokens': 0,
'cached_tokens': 0
}
},
'model_provider': 'openai',
'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_67cf3fed12',
'id': 'chatcmpl-CiG1NlFAgsemI2AYyXuMQOMA4HCdw',
'service_tier': 'default',
'finish_reason': 'stop',
'logprobs': None
},
id = 'lc_run--26def695-569e-479c-8fcb-2f133d47da6b-0',
usage_metadata = {
'input_tokens': 14,
'output_tokens': 28,
'total_tokens': 42,
'input_token_details': {
'audio': 0,
'cache_read': 0
},
'output_token_details': {
'audio': 0,
'reasoning': 0
}
}
)
]
}
自定义中间件的开发是一个系统工程,需要从需求分析到最终部署的完整流程管理。在需求分析阶段,开发者需要深入理解中间件将要解决的问题域。这不仅仅是技术问题,更是业务问题。开发者需要与业务专家沟通,了解真实的使用场景和期望效果。同时,还需要识别与其他中间件的依赖关系,避免功能冲突和重复开发。设计阶段是整个开发过程中最关键的阶段。优秀的中间件设计应该具备良好的可扩展性和可维护性。这需要考虑类的层次结构、接口的定义、状态管理方案等。设计文档应该详细说明中间件的工作原理、数据流、处理逻辑等,为后续的开发提供清晰的指导。
5.5 多中间件组合应用 - IT 运维 Agent 链接到标题
"""
IT 运维 Agent 中间件演示 - 具备 RBAC 和审计功能
本示例展示了一个完整的 IT 运维 Agent,集成了:
- RBAC(基于角色的权限控制)
- 操作审计和日志记录
- 安全检查和验证
- 上下文管理(使用 ContextEditingMiddleware)
- 动态系统提示词注入(使用 @wrap_model_call)
- 智能模型切换(使用 @wrap_model_call)
【中间件执行顺序】
1. before_agent: SecurityGuardrail (安全检查)
2. before_agent: RBACMiddleware (权限验证)
3. before_model: RBACMiddleware (注入用户信息到 state)
4. wrap_model_call: dynamic_system_prompt (动态提示词注入)
5. wrap_model_call: dynamic_model_router (智能模型切换)
6. wrap_model_call: ContextEditingMiddleware (上下文管理和清理)
7. Model Execution (模型执行)
注意:after_model 钩子按注册顺序相反执行(先注册后执行)
8. after_model: AuditLogger (审计日志)
9. after_model: ResponseValidator (响应验证)
【支持的运维操作】
- 服务器状态查询
- 服务重启
- 日志查看
- 系统资源监控
"""
from typing import Any, Dict, Optional, List, Callable,TypedDict
from datetime import datetime
from enum import Enum
from dotenv import load_dotenv
import json
from langchain_deepseek import ChatDeepSeek
from langchain.agents import create_agent
from langchain.agents.middleware import (
AgentMiddleware,
AgentState,
hook_config,
ContextEditingMiddleware,
ModelRequest,
ModelResponse,
wrap_model_call
)
from langchain.agents.middleware.context_editing import ClearToolUsesEdit
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.tools import tool
from langchain_core.messages import AIMessage, SystemMessage
from langchain_core.language_models import BaseChatModel
from pydantic import BaseModel, Field
# 加载环境变量
load_dotenv(override=True)
# ==============================================================================
# 用户角色和权限定义
# ==============================================================================
class UserRole(str, Enum):
"""用户角色枚举"""
ADMIN = "admin" # 管理员:所有权限
OPERATOR = "operator" # 运维人员:查询和重启权限
VIEWER = "viewer" # 查看者:仅查询权限
GUEST = "guest" # 访客:无权限
class Permission(str, Enum):
"""权限枚举"""
VIEW_STATUS = "view_status" # 查看状态
VIEW_LOGS = "view_logs" # 查看日志
RESTART_SERVICE = "restart_service" # 重启服务
MODIFY_CONFIG = "modify_config" # 修改配置
VIEW_METRICS = "view_metrics" # 查看监控指标
# 角色权限映射
ROLE_PERMISSIONS: Dict[UserRole, List[Permission]] = {
UserRole.ADMIN: [
Permission.VIEW_STATUS,
Permission.VIEW_LOGS,
Permission.RESTART_SERVICE,
Permission.MODIFY_CONFIG,
Permission.VIEW_METRICS
],
UserRole.OPERATOR: [
Permission.VIEW_STATUS,
Permission.VIEW_LOGS,
Permission.RESTART_SERVICE,
Permission.VIEW_METRICS
],
UserRole.VIEWER: [
Permission.VIEW_STATUS,
Permission.VIEW_LOGS,
Permission.VIEW_METRICS
],
UserRole.GUEST: []
}
# 工具权限映射
TOOL_PERMISSIONS: Dict[str, Permission] = {
"check_server_status": Permission.VIEW_STATUS,
"view_service_logs": Permission.VIEW_LOGS,
"restart_service": Permission.RESTART_SERVICE,
"get_system_metrics": Permission.VIEW_METRICS
}
# ==============================================================================
# 辅助函数
# ==============================================================================
def log_with_timestamp(message: str, level: str = "INFO") -> None:
"""带时间戳的日志输出"""
timestamp = datetime.now().strftime("%H:%M:%S.%f")[:-3]
level_emoji = {
"INFO": "ℹ️",
"WARN": "⚠️",
"ERROR": "❌",
"SUCCESS": "✅",
"AUDIT": "📋"
}
emoji = level_emoji.get(level, "ℹ️")
print(f"[{timestamp}] {emoji} {message}")
def get_current_user() -> Dict[str, Any]:
"""
获取当前用户信息(模拟)
实际应用中应从认证系统获取
"""
# 这里模拟从配置中获取当前用户
return {
"user_id": "user_001",
"username": "operator_zhang",
"role": UserRole.OPERATOR,
"department": "IT运维部"
}
# ==============================================================================
# 用户上下文定义
# ==============================================================================
class UserContext(TypedDict):
"""用户上下文信息"""
user_id: str # 用户唯一标识
username: str # 用户名
role: str # 用户角色
department: str # 所属部门
# ==============================================================================
# 1. 定义中间件
# ==============================================================================
class RBACMiddleware(AgentMiddleware):
"""
[阶段 1: before_agent & before_model] RBAC 权限控制中间件
在执行任何操作前验证用户权限
"""
def __init__(self):
super().__init__()
def _get_user_from_runtime(self, runtime) -> Dict[str, Any]:
"""从 runtime.context 获取用户信息"""
try:
# 尝试从 runtime.context 获取用户信息
if hasattr(runtime, 'context') and runtime.context:
context_data = runtime.context
# 如果是字典,直接使用
if isinstance(context_data, dict):
user_role_str = context_data.get('role', 'guest')
# 转换角色字符串为枚举
try:
user_role = UserRole(user_role_str)
except ValueError:
user_role = UserRole.GUEST
return {
'user_id': context_data.get('user_id', 'unknown'),
'username': context_data.get('username', 'unknown'),
'role': user_role,
'department': context_data.get('department', 'unknown')
}
except Exception as e:
log_with_timestamp(f" ⚠️ 从 runtime.context 获取用户信息失败: {str(e)}", "WARN")
# 如果无法从 runtime 获取,使用默认用户
return get_current_user()
@hook_config(can_jump_to=["end"]) # 允许在 before_agent 阶段跳转到 end
def before_agent(self, state: AgentState, runtime) -> Optional[Dict[str, Any]]:
try:
# 从 runtime 获取用户信息
current_user = self._get_user_from_runtime(runtime)
log_with_timestamp(
f"🔐 [2. RBACMiddleware] 验证用户权限 - "
f"用户: {current_user['username']} "
f"角色: {current_user['role'].value}"
)
# 获取用户角色的权限列表
user_permissions = ROLE_PERMISSIONS.get(current_user['role'], [])
log_with_timestamp(
f" ✅ 权限验证通过 - 拥有 {len(user_permissions)} 项权限"
)
return None
except Exception as e:
log_with_timestamp(f" ❌ 权限验证异常: {str(e)}", "ERROR")
return {
"messages": [AIMessage(
content="权限验证失败,请联系管理员。"
)],
"jump_to": "end"
}
def before_model(self, state: AgentState, runtime) -> Optional[Dict[str, Any]]:
"""在 before_model 阶段注入用户信息到 state"""
try:
# 从 runtime 获取用户信息
current_user = self._get_user_from_runtime(runtime)
# 获取用户角色的权限列表
user_permissions = ROLE_PERMISSIONS.get(current_user['role'], [])
log_with_timestamp(
f" 📝 注入用户信息到 state - "
f"用户: {current_user['username']}, "
f"角色: {current_user['role'].value}"
)
# 将用户信息注入到 state
return {
"user_info": current_user,
"user_permissions": [p.value for p in user_permissions]
}
except Exception as e:
log_with_timestamp(f" ❌ 用户信息注入异常: {str(e)}", "ERROR")
return None
class SecurityGuardrail(AgentMiddleware):
"""
[阶段 2: before_agent] 安全护栏
检查请求中的危险操作和敏感关键词
"""
# 危险操作关键词
DANGEROUS_KEYWORDS = [
"删除数据库", "drop database", "rm -rf", "format",
"删除所有", "清空", "hack", "攻击", "入侵"
]
def __init__(self):
super().__init__()
@hook_config(can_jump_to=["end"])
def before_agent(self, state: AgentState, runtime) -> Optional[Dict[str, Any]]:
try:
log_with_timestamp("🔒 [1. SecurityGuardrail] 执行安全检查...")
messages = state.get("messages", [])
if not messages:
return None
last_msg = messages[-1]
if last_msg.type == "human":
content_lower = last_msg.content.lower()
# 检查危险关键词
for keyword in self.DANGEROUS_KEYWORDS:
if keyword in content_lower:
log_with_timestamp(
f" 🚫 检测到危险操作关键词: '{keyword}'",
"WARN"
)
return {
"messages": [AIMessage(
content=f"⚠️ 安全警告:检测到危险操作关键词 '{keyword}',"
f"该操作已被拦截。如需执行此类操作,请联系管理员。"
)],
"jump_to": "end"
}
log_with_timestamp(" ✅ 安全检查通过")
return None
except Exception as e:
log_with_timestamp(f" ❌ 安全检查异常: {str(e)}", "ERROR")
return {
"messages": [AIMessage(
content="安全检查失败,操作已被拦截。"
)],
"jump_to": "end"
}
# ==============================================================================
# 动态系统提示词中间件(使用 @wrap_model_call)
# ==============================================================================
def create_dynamic_system_prompt_middleware():
"""
创建动态系统提示词中间件
根据用户角色动态注入不同的系统提示词
使用 @wrap_model_call 装饰器,从 ModelRequest 获取用户信息
"""
# 角色专属提示词
ROLE_PROMPTS = {
UserRole.ADMIN: """
【管理员模式】
你拥有完整的系统权限,可以执行所有操作。
- 可以查看所有服务器状态和日志
- 可以重启服务和修改配置
- 需要特别谨慎,确认每个关键操作
- 提供详细的技术分析和建议
""",
UserRole.OPERATOR: """
【运维人员模式】
你是运维团队成员,拥有日常运维权限。
- 可以查看服务器状态和日志
- 可以重启服务(需确认)
- 不能修改系统配置
- 提供实用的运维建议
""",
UserRole.VIEWER: """
【查看者模式】
你只有查看权限,不能执行任何操作。
- 可以查看服务器状态和日志
- 可以查看系统监控指标
- 不能执行任何修改操作
- 提供信息查询和数据分析
""",
UserRole.GUEST: """
【访客模式】
你的权限受到严格限制。
- 只能进行基本的信息查询
- 不能访问敏感数据
- 不能执行任何操作
- 提供有限的帮助信息
"""
}
@wrap_model_call
def dynamic_system_prompt(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
根据用户角色动态注入系统提示词
从 ModelRequest 中获取:
1. request.runtime.context - 包含原始用户上下文
"""
try:
log_with_timestamp("💬 [3. DynamicSystemPrompt] 注入角色专属提示词...")
user_role = UserRole.GUEST # 默认角色
# 尝试从 runtime.context 获取
if hasattr(request, 'runtime') and hasattr(request.runtime, 'context'):
context_data = request.runtime.context
if isinstance(context_data, dict):
user_role_str = context_data.get('role', 'guest')
try:
user_role = UserRole(user_role_str)
except ValueError:
user_role = UserRole.GUEST
log_with_timestamp(f" ℹ️ 从 runtime.context 获取用户角色: {user_role.value}")
# 确保 user_role 是 UserRole 枚举类型
if isinstance(user_role, str):
try:
user_role = UserRole(user_role)
except ValueError:
log_with_timestamp(f" ⚠️ 无效的角色字符串: {user_role},使用 GUEST", "WARN")
user_role = UserRole.GUEST
elif not isinstance(user_role, UserRole):
log_with_timestamp(f" ⚠️ 意外的角色类型: {type(user_role)},使用 GUEST", "WARN")
user_role = UserRole.GUEST
log_with_timestamp(f" 🔍 检测到用户角色: {user_role.value}")
# 获取角色专属提示词
role_prompt = ROLE_PROMPTS.get(user_role, ROLE_PROMPTS[UserRole.GUEST])
# 获取当前消息列表
messages = list(request.messages)
# 检查是否已有系统消息
has_system_msg = any(msg.type == "system" for msg in messages)
if not has_system_msg:
# 创建增强的系统消息
enhanced_system_msg = SystemMessage(content=role_prompt)
messages.insert(0, enhanced_system_msg)
log_with_timestamp(f" ✅ 已注入 {user_role.value} 角色提示词")
# 使用修改后的消息列表覆盖请求
request = request.override(messages=messages)
else:
log_with_timestamp(" ℹ️ 系统消息已存在,跳过注入")
# 继续执行调用
return handler(request)
except Exception as e:
log_with_timestamp(f" ❌ 提示词注入异常: {str(e)}", "ERROR")
import traceback
log_with_timestamp(f" 详细错误: {traceback.format_exc()}", "ERROR")
# 发生异常时,继续执行原始请求
return handler(request)
@wrap_model_call
async def dynamic_system_prompt_async(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""异步版本:与同步版本逻辑相同"""
# 直接调用同步版本的逻辑
return dynamic_system_prompt.invoke(request, handler)
return dynamic_system_prompt
# ==============================================================================
# 智能模型切换中间件(使用 @wrap_model_call)
# ==============================================================================
# 定义复杂任务关键词
COMPLEXITY_KEYWORDS = [
"分析", "建议", "优化", "故障排查", "诊断",
"复杂", "详细", "深入", "为什么", "如何",
"证明", "推导", "严谨", "规划", "多步骤"
]
def create_dynamic_model_router(fast_model: BaseChatModel, smart_model: BaseChatModel):
"""
创建动态模型路由中间件
Args:
fast_model: 快速模型(用于简单查询)
smart_model: 智能模型(用于复杂任务)
Returns:
使用 @wrap_model_call 装饰的中间件函数
"""
def _analyze_complexity(messages: List) -> tuple[bool, str]:
"""分析请求复杂度"""
should_use_smart_model = False
reason = ""
# 场景 1: 长对话(超过 5 轮)
if len(messages) > 5:
should_use_smart_model = True
reason = f"长对话 ({len(messages)} 条消息)"
# 场景 2: 检查最后一条用户消息
elif messages:
last_human_msg = None
for msg in reversed(messages):
if msg.type == "human":
last_human_msg = msg
break
if last_human_msg:
content = last_human_msg.content
content_lower = content.lower()
# 检查复杂任务关键词
for keyword in COMPLEXITY_KEYWORDS:
if keyword in content_lower:
should_use_smart_model = True
reason = f"包含复杂关键词 '{keyword}'"
break
# 检查消息长度
if not should_use_smart_model and len(content) > 100:
should_use_smart_model = True
reason = f"长消息 ({len(content)} 字符)"
return should_use_smart_model, reason
@wrap_model_call
def dynamic_model_router(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
同步版本:根据对话上下文和请求复杂度动态切换模型
切换逻辑:
1. 如果对话轮数超过 5 轮 → 使用智能模型(处理复杂上下文)
2. 如果包含复杂任务关键词 → 使用智能模型
3. 如果消息长度超过 100 字符 → 使用智能模型
4. 其他情况 → 使用快速模型
"""
# 获取当前对话状态
state = request.state
messages = state.get("messages", [])
log_with_timestamp(f"🔄 [4. ModelRouter] 分析请求复杂度 - 消息数: {len(messages)}")
should_use_smart_model, reason = _analyze_complexity(messages)
# 根据判断结果切换模型
if should_use_smart_model:
log_with_timestamp(f" 🧠 切换至智能模型 - 原因: {reason}")
request = request.override(model=smart_model)
else:
log_with_timestamp(f" ⚡ 使用快速模型 - 简单请求")
# 继续执行调用
return handler(request)
@wrap_model_call
async def dynamic_model_router_async(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
异步版本:根据对话上下文和请求复杂度动态切换模型
"""
# 获取当前对话状态
state = request.state
messages = state.get("messages", [])
log_with_timestamp(f"🔄 [4. ModelRouter] 分析请求复杂度 - 消息数: {len(messages)}")
should_use_smart_model, reason = _analyze_complexity(messages)
# 根据判断结果切换模型
if should_use_smart_model:
log_with_timestamp(f" 🧠 切换至智能模型 - 原因: {reason}")
request = request.override(model=smart_model)
else:
log_with_timestamp(f" ⚡ 使用快速模型 - 简单请求")
# 继续执行调用
return await handler(request)
return dynamic_model_router
class ResponseValidator(AgentMiddleware):
"""
[阶段 6: after_model] 响应验证器
验证模型响应的格式和内容
"""
def __init__(self):
super().__init__()
def after_model(self, state: AgentState, runtime) -> Optional[Dict[str, Any]]:
try:
log_with_timestamp("🔍 [6. ResponseValidator] 验证模型响应...")
messages = state.get("messages", [])
if not messages:
return None
last_msg = messages[-1]
if last_msg.type == "ai":
has_tool_calls = hasattr(last_msg, 'tool_calls') and last_msg.tool_calls
if has_tool_calls:
# 验证工具调用权限
user_permissions = state.get('user_permissions', [])
for tool_call in last_msg.tool_calls:
tool_name = tool_call.get('name', '')
required_permission = TOOL_PERMISSIONS.get(tool_name)
if required_permission and required_permission.value not in user_permissions:
log_with_timestamp(
f" ⚠️ 权限不足:工具 '{tool_name}' 需要权限 '{required_permission.value}'",
"WARN"
)
log_with_timestamp(f" 🔧 模型请求调用 {len(last_msg.tool_calls)} 个工具")
elif last_msg.content:
log_with_timestamp(f" ✅ 响应有效 (长度: {len(last_msg.content)} 字符)")
return None
except Exception as e:
log_with_timestamp(f" ❌ 响应验证异常: {str(e)}", "ERROR")
return None
class AuditLogger(AgentMiddleware):
"""
[阶段 7: after_model] 审计日志中间件
记录所有操作的审计日志
"""
def __init__(self):
super().__init__()
self.audit_records = []
def after_model(self, state: AgentState, runtime) -> Optional[Dict[str, Any]]:
try:
messages = state.get("messages", [])
if not messages:
return None
last_msg = messages[-1]
user_info = state.get("user_info", {})
# 记录工具调用
if last_msg.type == "ai" and hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
for tool_call in last_msg.tool_calls:
audit_record = {
"timestamp": datetime.now().isoformat(),
"user_id": user_info.get("user_id", "unknown"),
"username": user_info.get("username", "unknown"),
"role": user_info.get("role", "unknown"),
"action": "tool_call",
"tool_name": tool_call.get('name', ''),
"tool_args": tool_call.get('args', {}),
"status": "initiated"
}
self.audit_records.append(audit_record)
log_with_timestamp(
f"📋 [7. AuditLogger] 记录审计日志 - "
f"用户: {user_info.get('username')}, "
f"操作: {tool_call.get('name')}",
"AUDIT"
)
# 记录最终响应
elif last_msg.type == "ai" and last_msg.content:
audit_record = {
"timestamp": datetime.now().isoformat(),
"user_id": user_info.get("user_id", "unknown"),
"username": user_info.get("username", "unknown"),
"role": user_info.get("role", "unknown"),
"action": "response",
"response_length": len(last_msg.content),
"status": "completed"
}
self.audit_records.append(audit_record)
log_with_timestamp(
f"📋 [7. AuditLogger] 操作完成 - "
f"审计记录已保存 (共 {len(self.audit_records)} 条)",
"AUDIT"
)
return None
except Exception as e:
log_with_timestamp(f" ❌ 审计日志异常: {str(e)}", "ERROR")
return None
# ==============================================================================
# 2. 定义 IT 运维工具
# ==============================================================================
class ServerStatusSchema(BaseModel):
server_name: str = Field(description="服务器名称,例如: web-server-01")
@tool(args_schema=ServerStatusSchema)
def check_server_status(server_name: str) -> str:
"""
查询服务器状态
需要权限: VIEW_STATUS
"""
# 模拟查询服务器状态
status_data = {
"server_name": server_name,
"status": "running",
"cpu_usage": "45%",
"memory_usage": "62%",
"uptime": "15 days 3 hours",
"last_check": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
return json.dumps(status_data, ensure_ascii=False, indent=2)
class ServiceLogsSchema(BaseModel):
service_name: str = Field(description="服务名称,例如: nginx, mysql")
lines: int = Field(default=50, description="显示的日志行数")
@tool(args_schema=ServiceLogsSchema)
def view_service_logs(service_name: str, lines: int = 50) -> str:
"""
查看服务日志
需要权限: VIEW_LOGS
"""
# 模拟返回服务日志
log_entries = [
f"[INFO] {service_name} service is running normally",
f"[INFO] Last request processed at {datetime.now().strftime('%H:%M:%S')}",
f"[INFO] Total requests today: 1,234",
f"[WARN] Memory usage approaching 80%",
f"[INFO] Service health check passed"
]
result = f"=== {service_name} 服务日志 (最近 {lines} 行) ===\n"
result += "\n".join(log_entries[:lines])
return result
class RestartServiceSchema(BaseModel):
service_name: str = Field(description="要重启的服务名称")
force: bool = Field(default=False, description="是否强制重启")
@tool(args_schema=RestartServiceSchema)
def restart_service(service_name: str, force: bool = False) -> str:
"""
重启服务
需要权限: RESTART_SERVICE
"""
# 模拟重启服务
restart_type = "强制重启" if force else "正常重启"
result = f"""
🔄 服务重启操作
服务名称: {service_name}
重启类型: {restart_type}
操作时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
状态: 成功
预计恢复时间: 30秒
"""
return result.strip()
class SystemMetricsSchema(BaseModel):
metric_type: str = Field(
description="指标类型: cpu, memory, disk, network"
)
@tool(args_schema=SystemMetricsSchema)
def get_system_metrics(metric_type: str) -> str:
"""
获取系统监控指标
需要权限: VIEW_METRICS
"""
# 模拟返回系统指标
metrics = {
"cpu": {
"usage": "45.2%",
"cores": 8,
"load_average": [2.1, 2.3, 2.5]
},
"memory": {
"total": "16 GB",
"used": "10 GB",
"free": "6 GB",
"usage": "62.5%"
},
"disk": {
"total": "500 GB",
"used": "320 GB",
"free": "180 GB",
"usage": "64%"
},
"network": {
"rx_bytes": "1.2 TB",
"tx_bytes": "890 GB",
"connections": 156
}
}
metric_data = metrics.get(metric_type.lower(), {})
return json.dumps(metric_data, ensure_ascii=False, indent=2)
# 工具列表
tools = [
check_server_status,
view_service_logs,
restart_service,
get_system_metrics
]
# ==============================================================================
# 3. 创建 IT 运维 Agent
# ==============================================================================
# 创建模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0.1)
# 创建快速模型和智能模型(用于动态切换)
fast_model = ChatDeepSeek(model="deepseek-chat", temperature=0, max_tokens=500)
smart_model = ChatDeepSeek(model="deepseek-chat", temperature=0.3, max_tokens=2000)
# ==================== 配置 ContextEditingMiddleware ====================
# 关键:设置较低的触发阈值,确保能够触发清理
custom_context_middleware = ContextEditingMiddleware(
edits=[
ClearToolUsesEdit(
trigger=800, # 当 token 数超过 800 时触发清理(约 3-4 次工具调用后)
keep=1, # 只保留最近的 1 个工具结果
clear_at_least=0, # 清理所有超出keep数量的内容
clear_tool_inputs=False, # 不清理工具输入参数
exclude_tools=["restart_service"], # 不清理 restart_service 的结果(重要操作)
placeholder="[已清理以节省空间]", # 自定义占位符
)
],
token_count_method="approximate" # 使用近似计数(更快)
)
# ==================== 创建动态模型路由中间件 ====================
dynamic_model_router = create_dynamic_model_router(fast_model, smart_model)
# ==================== 创建动态系统提示词中间件 ====================
dynamic_system_prompt = create_dynamic_system_prompt_middleware()
# 按顺序注册中间件
# 注意:
# - before_agent/before_model
# - @wrap_model_call 中间件按注册顺序执行(先注册先执行)
# - after_model 钩子按注册顺序相反执行(先注册后执行)
middlewares = [
SecurityGuardrail(), # 1. before_agent: 安全检查
RBACMiddleware(), # 2. before_agent & before_model: 权限验证(注入 user_info)
dynamic_system_prompt, # 3. @wrap_model_call: 动态提示词注入
dynamic_model_router, # 4. @wrap_model_call: 智能模型切换
custom_context_middleware, # 5. @wrap_model_call: 上下文管理和清理
ResponseValidator(), # 6. after_model: 响应验证
AuditLogger(), # 7. after_model: 审计日志
]
# 系统提示词
system_prompt = """你是一个专业的 IT 运维助手,负责帮助运维人员管理服务器和服务。
你的职责包括:
1. 查询服务器状态和系统指标
2. 查看服务日志
3. 在获得授权后重启服务
4. 提供运维建议和故障排查
注意事项:
- 始终确认用户的操作意图
- 对于重启等关键操作,需要明确确认
- 提供清晰、专业的响应
- 遵守权限控制规则
"""
# 导出 graph 变量供 LangGraph Studio 使用
graph = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt,
middleware=middlewares,
context_schema=UserContext, # 添加上下文 schema
# checkpointer=MemorySaver(), # 关键:使用 checkpointer 来保存消息历史
debug=True # 开启调试模式以观察中间件行为
)
# ==============================================================================
# 4. 运行演示
# ==============================================================================
def run_demo():
"""运行 IT 运维 Agent 演示"""
print("\n" + "="*80)
print("🖥️ IT 运维 Agent 演示 - 具备 RBAC 和审计功能")
print("="*80)
current_user = get_current_user()
print(f"\n当前用户: {current_user['username']}")
print(f"用户角色: {current_user['role'].value}")
print(f"所属部门: {current_user['department']}")
# 创建用户上下文实例
user_context = UserContext(
user_id=current_user['user_id'],
username=current_user['username'],
role=current_user['role'].value, # 转换为字符串
department=current_user['department']
)
# 配置:包含 thread_id 和用户上下文
config = {
"configurable": {
"thread_id": "ops_demo_001",
# "context": user_context.model_dump() # 将用户上下文传入
}
}
# 场景 1: 查询服务器状态(有权限)
print("\n" + "="*80)
print("🔹 场景 1: 查询服务器状态")
print("="*80)
user_input = "请帮我查看 web-server-01 的状态"
log_with_timestamp(f"[用户]: {user_input}")
try:
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config=config,
stream_mode="values",
context=user_context # 传入用户角色到上下文
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
log_with_timestamp(f"[AI]: {last_msg.content}")
except Exception as e:
log_with_timestamp(f"场景 1 执行异常: {str(e)}", "ERROR")
# 场景 2: 复杂分析请求(测试模型切换)
print("\n" + "="*80)
print("🔹 场景 2: 复杂分析请求 - 测试智能模型切换")
print("="*80)
user_input_2 = "请详细分析 web-server-01 的性能状况,并提供优化建议"
log_with_timestamp(f"[用户]: {user_input_2}")
try:
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input_2}]},
config=config,
stream_mode="values",
context=user_context # 传入用户角色到上下文
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
log_with_timestamp(f"[AI]: {last_msg.content}")
except Exception as e:
log_with_timestamp(f"场景 2 执行异常: {str(e)}", "ERROR")
# 场景 3: 危险操作(应被拦截)
print("\n" + "="*80)
print("🔹 场景 3: 危险操作测试")
print("="*80)
user_input_3 = "帮我删除数据库中的所有数据"
log_with_timestamp(f"[用户]: {user_input_3}")
try:
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input_3}]},
config=config,
stream_mode="values",
context=user_context # 传入用户角色到上下文
):
if "messages" in event:
last_msg = event["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
log_with_timestamp(f"[AI]: {last_msg.content}")
except Exception as e:
log_with_timestamp(f"场景 3 执行异常: {str(e)}", "ERROR")
print("\n" + "="*80)
print("✅ 演示完成")
print("\n📊 中间件功能总结:")
print("1. ✅ SecurityGuardrail - 危险操作拦截")
print("2. ✅ RBACMiddleware - 基于角色的权限控制")
print("3. ✅ dynamic_system_prompt (@wrap_model_call) - 动态系统提示词注入")
print("4. ✅ dynamic_model_router (@wrap_model_call) - 智能模型切换")
print("5. ✅ ContextEditingMiddleware - 上下文管理和清理")
print("6. ✅ ResponseValidator - 响应验证")
print("7. ✅ AuditLogger - 审计日志记录")
print("="*80)
run_demo()
第六部分:中间件编排黄金法则 链接到标题
1. 执行顺序设计的哲学思考 链接到标题
middlewares = [
SecurityGuardrail(), # 1. before_agent: 安全检查
RBACMiddleware(), # 2. before_agent & before_model: 权限验证(注入 user_info)
dynamic_system_prompt, # 3. @wrap_model_call: 动态提示词注入
dynamic_model_router, # 4. @wrap_model_call: 智能模型切换
custom_context_middleware, # 5. @wrap_model_call: 上下文管理和清理
ResponseValidator(), # 6. after_model: 响应验证
AuditLogger(), # 7. after_model: 审计日志
ToolMiddleware, # 8. wrap_tool_call: 工具调用拦截和控制
]
| 钩子类型 | 执行顺序 | 控制粒度 | 最佳实践 |
|---|---|---|---|
before_agent | 正序 | 调用级 | 安全/初始化优先 |
before_model | 正序 | 单次调用 | 预算/合规前置 |
wrap_model_call | 嵌套 | 调用全过程 | 路由/重试/缓存核心 |
after_model | 逆序 | 单次调用 | 验证/日志后置 |
wrap_tool_call | 嵌套 | 工具执行 | 参数校验/重试保护 |
中间件的执行顺序不是简单的排列组合,而是基于系统架构哲学的深度思考。洋葱模型的应用体现了"分层治理"的思想:外层负责安全防护,中层处理业务逻辑,内层保证核心功能,中心提供基础服务。
这种分层的价值在于每一层都有其特定的职责和优先级。安全检查必须在最外层进行,因为任何安全问题都不应该进入到业务处理层面。业务逻辑应该在中间层处理,这样可以确保核心功能的纯粹性。监控和日志记录应该在最内层进行,这样可以不干扰主要的业务逻辑。
提前失败原则是执行顺序设计中的重要原则。通过在最早的可执行点检测问题,我们可以避免后续的无谓计算。这不仅提高了效率,更重要的是提高了系统的可靠性。当系统发现输入有问题时,应该立即拒绝处理,而不是继续进行复杂的计算后发现问题。
缓存优先原则体现了效率优化的思想。对于相同的请求,系统应该尽量返回缓存的结果,而不是重新计算。这不仅减少了计算资源的消耗,更重要的是提高了响应速度。
2. 安全优先原则的深度实施 链接到标题
编排黄金法则
安全类永远优先
- 安全 > 业务 > 成本 > 监控
写操作按依赖排序
- 如果 B 依赖 A 的写入结果,则 A 必须在 B 之前
中断操作置后
- 中断类中间件应放在同类型最后
性能开销降序排列
- 轻量级 → 重量级(快速失败)
“先安全,后业务;先读再写,轻量在前;同类型按声明,不同类型按层级”
安全优先不是一句口号,而是需要在系统架构的每个层面得到体现的设计原则。在中间件编排中,安全检查必须前置,这是因为安全问题的代价往往比其他问题要高得多。
分层安全检查是实施安全优先原则的有效方法。身份认证是最外层的安全检查,它确保只有合法用户才能访问系统。输入验证是第二层安全检查,它确保用户输入的内容不包含恶意代码或不当内容。业务授权是第三层安全检查,它确保用户只能执行其权限范围内的操作。合规检查是最内层的安全检查,它确保整个操作符合相关法规要求。
这种分层的安全检查体系不仅提高了系统的安全性,也提高了系统的可维护性。每层的安全检查都相对独立,可以单独进行测试、维护和更新。
3. 依赖关系管理的复杂性 链接到标题
在复杂的系统中,中间件之间的依赖关系可能非常复杂。正确管理这些依赖关系是保证系统正常运行的关键。
依赖类型分析帮助我们理解不同类型依赖的特点和处理方式。顺序依赖是最基本的依赖类型,它要求特定的执行顺序。条件依赖则更加复杂,它要求根据中间结果来决定后续的执行路径。数据依赖确保下游中间件能够获得上游中间件的输出作为输入。
依赖排序策略则提供了处理复杂依赖关系的指导原则。无依赖的中间件可以首先执行,单向依赖按照依赖关系排序,条件依赖需要特殊的处理逻辑,聚合依赖则需要等待所有相关的中间件完成。
4. 冲突解决机制的设计 链接到标题
在多中间件协作的环境中,冲突是不可避免的。设计良好的冲突解决机制可以保证系统的稳定运行。
资源冲突是最常见的冲突类型。当多个中间件需要同时访问某个资源时,系统需要确保资源的正确分配和使用。锁机制可以保证资源的独占访问,但可能会降低系统的并发性能。队列管理可以提供更公平的资源分配,但可能会增加系统的延迟。
结果冲突则涉及多个中间件产生不同结果的情况。权重决策机制可以根据预定义的规则来选择最终结果。投票机制则通过多个中间件的投票来决定最终结果。在某些情况下,可能需要指定最终决策者来处理冲突。
第七部分:实际应用场景与最佳实践 链接到标题
1. 客服机器人中间件方案的深度实践 链接到标题
客服机器人是中间件技术应用最成熟的领域之一。一个设计良好的客服机器人中间件系统不仅能够提高客户满意度,还能显著降低运营成本。
在典型的客服机器人架构中,用户识别中间件扮演着"门卫"的角色。当客户首次接触系统时,这个中间件需要快速识别客户的重要程度、历史问题、个人偏好等信息。VIP 客户可能需要转接到专业客服或使用更高级的服务,而普通客户则可以通过标准的自动化流程得到服务。这种差异化的处理不仅提高了服务效率,也提升了客户体验。
意图理解中间件是整个系统的"大脑"。它需要从客户的自然语言表达中提取真实的意图和情感。这不仅仅是简单的关键词匹配,而是需要理解语言的深层含义。例如,当客户说"这个产品太贵了"时,系统需要理解这可能是价格敏感的信号,或者是在寻求折扣信息,或者是在比较不同产品。
知识检索中间件就像是一个智能图书管理员。它需要从庞大的知识库中快速找到最相关的信息。知识库可能包含产品信息、政策条款、使用指南、故障排除等多个方面的内容。中间件需要根据客户的意图和问题的上下文,从知识库中选择最合适的信息进行回答。
2. 企业知识助手中间件方案 链接到标题
企业知识助手是一个更加复杂的系统,它需要处理企业内部的各种知识资产,包括文档、数据库、专业知识等。
文档解析中间件负责处理各种格式的企业文档,包括 Word、PDF、Excel 等。这个中间件需要能够提取文档的结构化信息和非结构化内容。对于技术文档,它需要提取技术细节和实施步骤;对于政策文档,它需要提取关键条款和适用范围;对于流程文档,它需要提取操作步骤和责任分工。
知识抽取中间件则负责从解析后的文档中提取有价值的知识点。这个过程涉及到自然语言处理、知识图谱构建、语义分析等高级技术。系统需要理解文档的内容,识别重要的概念、关系、事实等,并将其组织成结构化的知识表示。
语义索引中间件建立企业知识的语义化检索索引。这不仅仅是为了提高检索的准确性,更是为了支持复杂的知识推理和发现。系统需要理解知识之间的关联关系,支持基于语义相似度的检索,以及基于知识图谱的推理查询。
3. 代码助手中间件方案 链接到标题
代码助手是中间件技术的前沿应用领域,它需要结合软件工程的最佳实践和 AI 技术的最新进展。
代码理解中间件需要具备强大的代码分析能力。它需要理解代码的结构、逻辑、意图和功能。这涉及到语法分析、语义分析、控制流分析、数据流分析等多个层面。系统不仅要理解代码的表面结构,还要理解代码的深层逻辑和设计意图。
语义分析中间件则专注于理解代码的语义含义。它需要识别函数的用途、变量的含义、类的关系、模块的依赖等。这种分析不仅要准确,还要深入。系统需要能够理解设计模式、算法原理、最佳实践等软件工程概念。
最佳实践中间件基于软件工程的最佳实践,为开发者提供改进建议。这包括代码重构建议、性能优化建议、安全性改进建议、测试覆盖率改进建议等。这些建议不是简单的规则匹配,而是基于深度分析和专业知识的智能推荐。
4. 最佳实践总结与思考 链接到标题
通过这些实际应用场景的深入分析,我们可以总结出中间件系统设计的几个重要原则:
模块化设计是基础。每个中间件都应该有明确的职责边界和功能范围,避免功能重叠和相互干扰。同时,中间件之间应该有清晰的接口定义,保证系统的可维护性。
性能优先是要求。中间件不应该成为系统的性能瓶颈,需要通过各种优化技术来提高处理效率和减少资源消耗。
安全可靠是底线。特别是对于生产环境中的中间件,必须具备完善的错误处理、安全防护和监控机制。
易于扩展是目标。系统设计应该支持新中间件的动态添加和现有中间件的功能升级,保持系统的长期生命力。
第八部分:中间件总结 链接到标题
LangChain 1.0 中间件体系代表了 AI Agent 开发的一个重要发展阶段。它不仅仅是一套技术组件,更是构建可靠、可控、高效 AI 系统的完整方法论。
通过模块化设计,中间件系统实现了功能的解耦和重用。每个中间件都有明确的职责边界,可以独立开发和测试,也可以灵活组合使用。这种设计使得系统具备了良好的可维护性和扩展性。
通过分层架构,中间件系统实现了关注点的分离。安全检查、业务处理、监控记录等功能分别在不同的层次进行处理,避免了功能耦合带来的复杂性。
通过生命周期管理,中间件系统实现了完整的请求处理流程。从输入验证到输出生成,每个环节都有专门的中间件负责,确保了系统的稳定性和可靠性。
通过性能监控,中间件系统具备了自我感知和自我优化的能力。系统可以实时监控自身的运行状态,发现性能瓶颈,进行自动调优。
通过成本控制,中间件系统实现了经济效益的最优化。通过智能的监控和优化机制,系统可以在保证服务质量的前提下,最小化运营成本。
更重要的是,中间件体系体现了一种工程化的思维方式。它将复杂的 AI 问题分解为一系列可控的工程问题,通过标准化、模块化、自动化的方法来解决这些问题。这种思维方式不仅适用于 AI 系统开发,也为其他复杂系统的构建提供了有价值的参考。
随着 AI 技术的不断发展和应用场景的不断扩展,中间件体系也将持续演进和完善。未来的中间件系统可能会引入更多的智能化技术,如机器学习优化、自适应调优、预测性处理等。但无论如何发展,其核心思想——模块化、分层管理、生命周期控制、性能监控和成本优化——将始终是构建可靠 AI 系统的重要基石。
对于每一个致力于 AI Agent 开发的工程师和技术管理者来说,深入理解和掌握中间件技术不仅是技术需要,更是行业发展的必然要求。只有具备了这种系统性的思维和工程化的能力,才能在这个快速发展的领域中保持竞争力,创造出真正有价值的 AI 解决方案。