第一阶段、 Agent核心概念与技术架构 链接到标题
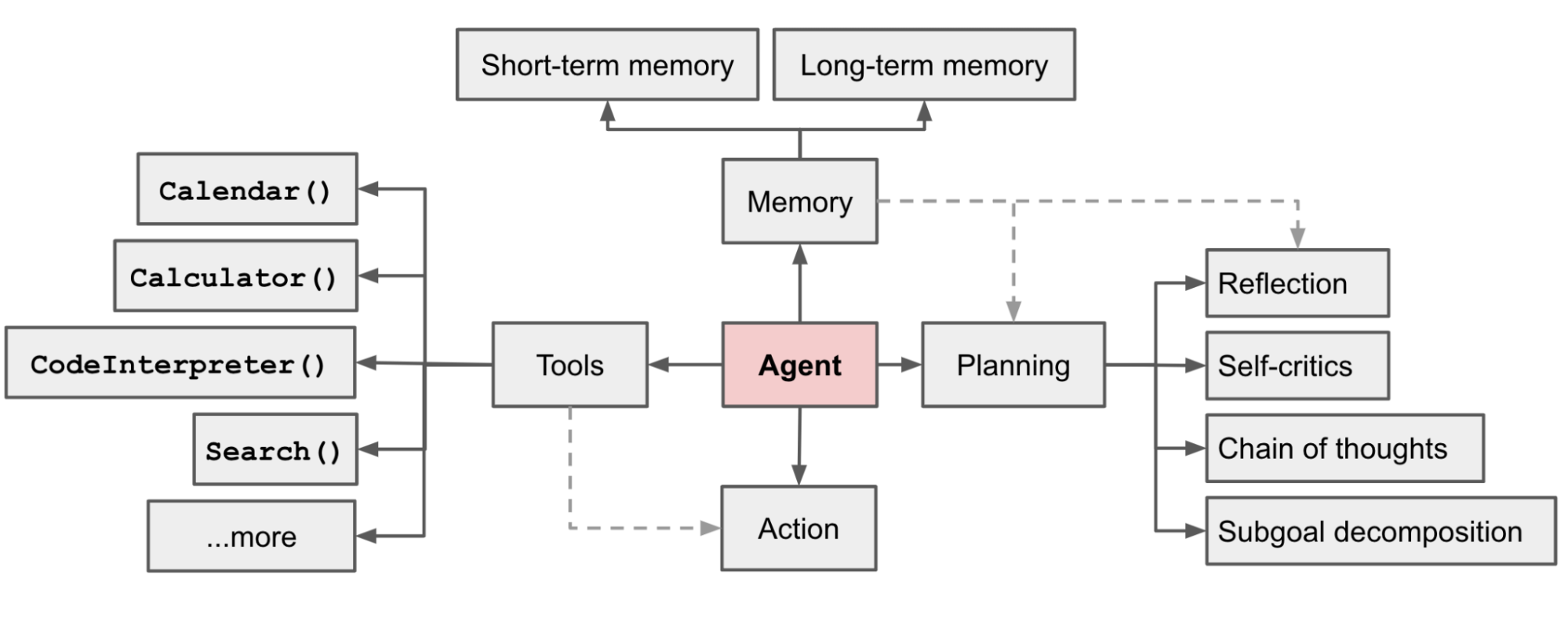
Agent智能体是一种以大语言模型(LLM)为"大脑",能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain框架的定义,Agent的核心是以大语言模型(LLM)作为其推理引擎,并依据LLM的推理结果来决定如何与外部工具进行交互以及采取何种具体行动。这种架构将LLM的强大语言理解与生成能力,与外部工具的实际执行能力相结合,从而突破了单一LLM的知识限制和功能边界。Agent的本质可以被理解为一种高级的提示工程(Prompt Engineering)应用范式,开发者通过精心设计的提示词模板,引导LLM模仿人类的思考与执行方式,使其能够自主地分解任务、选择工具、调用工具并整合结果,最终完成复杂的任务。
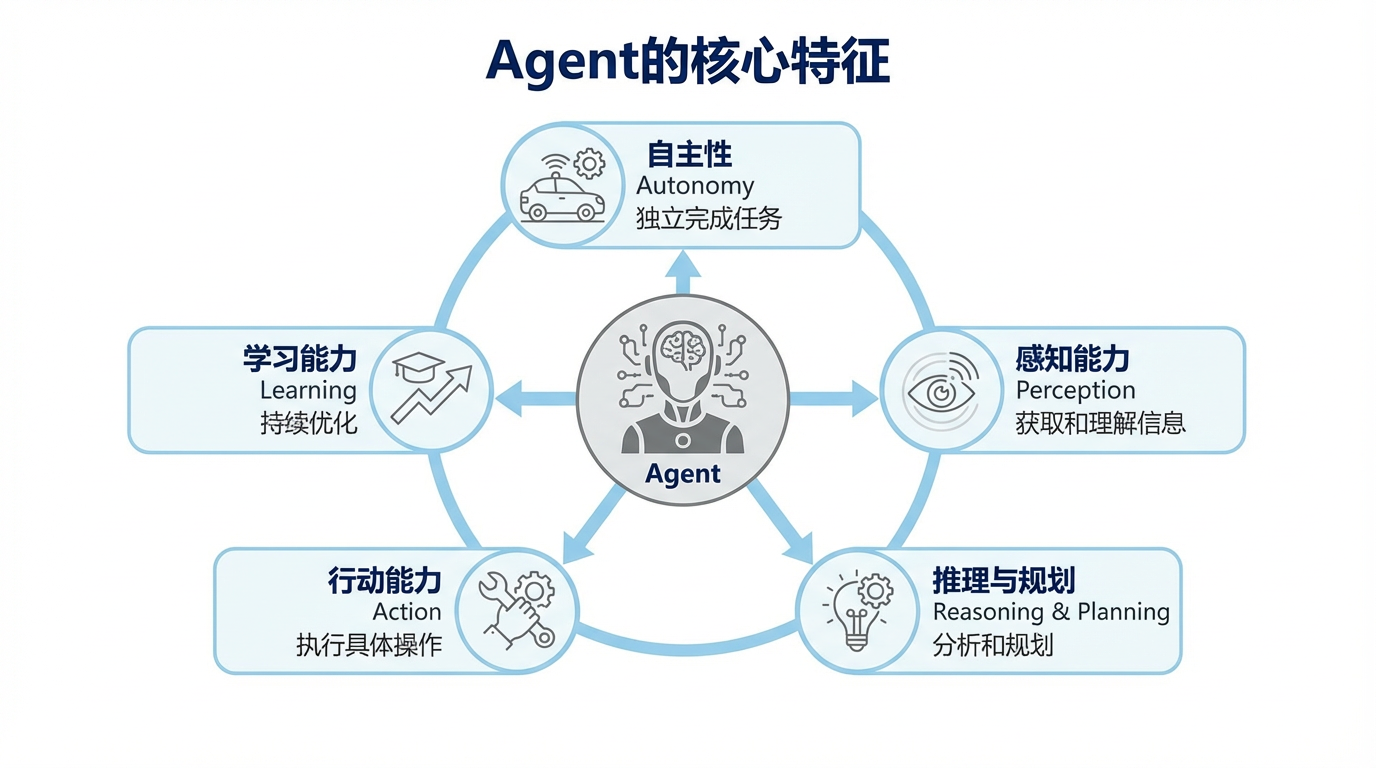
Agent(智能体)已超越传统AI模型,成为能够自主完成多步骤复杂任务的智能数字助手。其核心特征在于自主性增强、执行能力和持续学习。
1. 能力维度对比 链接到标题
| 对比维度 | 传统AI模型 | Agent智能体 |
|---|---|---|
| 交互能力 | 被动响应用户输入 | 主动感知环境变化 |
| 决策模式 | 基于概率预测 | 基于目标导向的主动规划 |
| 执行能力 | 仅生成文本/内容 | 能够调用工具、访问外部系统 |
| 学习方式 | 静态知识更新 | 动态记忆积累和经验反思 |
| 任务处理 | 单次对话完成 | 支持多步骤、复杂任务序列 |
| 自主程度 | 高度依赖人类指导 | 具备一定程度的自主决策能力 |
第二阶段、 Agent的核心特征 链接到标题
Agent智能体通常具备以下几个核心特征,这些特征共同构成了其强大的能力基础:
2.1 自主性 (Autonomy) 链接到标题
自主性是Agent最核心的特征之一,指的是Agent能够在没有人类直接干预的情况下,独立地完成任务的感知、规划、决策和行动的全过程。在LangChain框架中,这种自主性体现在Agent能够根据用户的输入,自动判断是否需要调用外部工具,选择哪个工具,以及如何组织调用参数。例如,当用户询问"北京的天气怎么样?“时,Agent能够自主识别出这是一个需要实时信息查询的任务,并自动调用天气查询工具来获取答案,而无需开发者显式地编写"如果问题是关于天气,则调用天气API"这样的硬编码逻辑。这种自主性使得Agent能够处理更加开放和动态的问题,极大地提升了应用的灵活性和智能水平。
2.2 感知能力 (Perception) 链接到标题
感知能力是指Agent获取和理解环境信息的能力。在基于LLM的Agent中,环境信息主要以文本形式存在,包括用户的输入、工具的输出以及系统状态等。Agent通过其底层的LLM来解析和理解这些文本信息,从中提取关键指令、实体和上下文。例如,在接收到用户问题后,Agent需要感知问题的意图和关键实体(如地点、时间、人物),以便决定后续的行动。LangChain框架通过提供标准化的消息格式(如HumanMessage, AIMessage)和工具描述机制,为Agent的感知能力提供了坚实的基础,使其能够清晰地理解来自不同来源的信息。
2.3 推理与规划 (Reasoning & Planning) 链接到标题
推理与规划是Agent智能的核心。Agent需要能够分析任务目标,并将其分解为一系列可执行的子步骤。LangChain中的Agent,特别是基于ReAct(Reasoning and Acting)范式的Agent,展现了强大的推理和规划能力。ReAct框架要求LLM在每一步都生成一个"思考”(Thought)过程,解释其当前的理解和下一步的计划,然后生成一个"行动"(Action),即调用某个工具。这个过程会循环进行,直到Agent认为已经收集了足够的信息来回答原始问题。例如,面对一个复杂的多步骤数学问题,Agent会先规划出解题步骤,如"首先计算A,然后用A的结果计算B",并按此规划逐步调用计算工具来完成任务。
2.4 行动能力 (Action) 链接到标题
行动能力是指Agent执行具体操作以影响环境的能力。在LangChain框架中,Agent的行动能力主要通过调用外部工具(Tools)来实现。这些工具可以是API调用、数据库查询、代码执行器,甚至是其他Agent。Agent通过LLM来决定调用哪个工具,并生成符合工具要求的输入参数。工具执行后,其输出结果会作为新的环境信息反馈给Agent,供其进行下一步的推理和决策。这种"思考-行动-观察"的循环,使得Agent能够与外部世界进行有效的交互,从而完成各种复杂的实际任务,如信息检索、数据处理和自动化流程控制。
2.5 学习能力 (Learning) 链接到标题
一个真正的智能体不仅仅是执行预设的程序,它还应该具备从经验中学习并不断优化自身行为的能力。这种学习能力通常通过强化学习、反馈机制或记忆系统来实现。智能体在每次行动后,会观察行动的结果,并根据结果(例如,用户的反馈或环境的奖励/惩罚信号)来调整其内部的决策模型或策略。例如,如果一个智能体推荐的商品被用户频繁购买,它就会学习到这种推荐是有效的;反之,如果推荐被用户忽略或拒绝,它就会调整其推荐策略。这种持续学习和优化的能力使得智能体能够随着时间的推移变得越来越"聪明",更好地适应复杂多变的环境。
第三阶段、 Agent技术架构核心 链接到标题
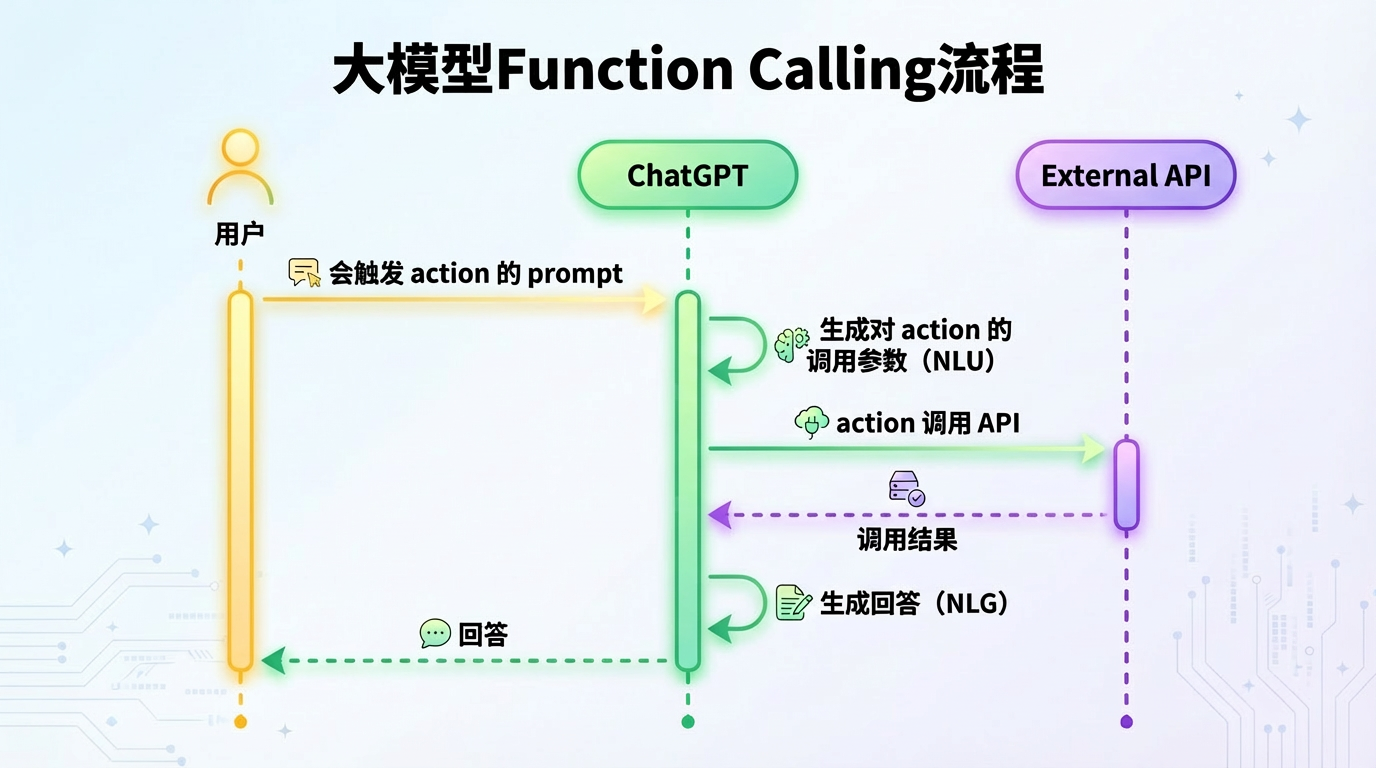
理解 Agent(智能体) 最难的地方在于理解它"如何自主决策"。在LangChain 1.0框架中,Agent不再只是一个简单的问答机器人,它更像是一个"拥有万能工具箱的超级项目经理"。
LLM(大模型) = 大脑(项目经理):它负责思考、规划、决定下一步做什么,但它不能联网,也不能算复杂的数学(如果不借助工具)。
Tools(工具) = 手脚(执行专员):比如谷歌搜索(负责看世界)、计算器(负责算数)、数据库(负责查档案)。
Agent = 大脑 + 手脚 + 循环机制:把大脑和手脚结合起来,通过不断的"思考-行动-观察"循环来解决问题。
现代Agent的技术架构由五个核心模块构成,形成完整的"感知-思考-行动"闭环。
感知模块 (Perception):负责接收文本、图像、语音等多模态输入。
认知中枢 (Brain/Planning):基于大语言模型(LLM)和检索增强生成(RAG)技术,进行推理和决策,弥补LLM无法获取实时信息和执行具体操作的缺陷。
记忆系统 (Memory):通过短期记忆维持对话连贯,长期记忆积累经验与偏好。
工具生态 (Tools):通过API调用、数据库访问等方式与外部系统交互。
执行引擎 (Action):负责执行具体任务并反馈结果。
这一机制使得Agent能够构建一个完整的执行闭环:环境感知 → 任务规划 → 工具调用 → 执行反馈 → 自我反思 → 优化调整,从而在复杂环境中持续学习和改进。
第四阶段、 Agent与LangChain结合机制 链接到标题
LangChain 1.0通过将Agent的决策与LangGraph的图式执行相结合,提供了生产级的Agent运行时。其结合机制体现在以下几个方面:
4.1 核心结合点:create_agent + LangGraph
链接到标题
create_agent作为上层统一入口,其内部实现依赖于LangGraph。当调用create_agent时,LangChain会自动构建一个基于ReAct(推理+行动)范式的图结构。这个图包含了Agent决策、工具调用、状态更新等核心节点,并通过边来控制逻辑流转。这种设计将Agent的"思考"过程映射为图的遍历,使得整个执行流程变得透明、可控。
LangChain 1.0 的 create_agent 通过这 9 个核心参数,实现了从快速原型到生产部署的全覆盖,开发者可根据场景灵活组合。
create_agent 的核心价值在于它通过 “三要素 + 三扩展” 的极简抽象,彻底重构了 Agent 的开发范式。所谓三要素,即模型(Model)、工具(Tools)与提示词(System Prompt),这三者构成了 Agent 的"灵魂"——决定了它能思考什么、能做什么以及行为边界何在。而三扩展——中间件(Middleware)、内存管理(Memory)与状态管理(State)——则构建了 Agent 的"神经系统",使其具备生产级应用所需的可靠性、可观测性与可维护性。
这一设计将开发者从繁琐的 ReAct 循环手写、工具调用异常处理、上下文压缩等底层细节中解放出来,转而采用声明式编程模式:只需描述"Agent 应该做什么",框架自动编译为高效、可靠、安全的执行计划。其本质是 LangGraph 的编译器前端 ,将高层意图转换为优化的图结构,自动集成持久化、流式输出、断点恢复等运行时能力。 这种架构带来了三重革命性影响:首先,开发效率提升 10 倍,10 行代码即可构建一个可投产的智能客服或数据分析 Agent;其次,运维成本降低 60%,中间件机制将 PII 检测、人工审批、自动重试等横切关注点解耦,无需侵入业务代码;最后,可扩展性实现质的飞跃,通过 TypedDict 扩展 State,可无缝集成用户画像、多模态输入、性能监控等复杂场景。
| 参数 | 类型 | 必填 | 默认值 | 核心作用 | 最佳实践 |
|---|---|---|---|---|---|
model | str/实例 | ✅ | - | 推理引擎 | 生产环境实例化配置 |
tools | list | ✅ | [] | 执行能力 | 描述清晰,按需添加 |
system_prompt | str | ❌ | None | 行为准则 | 明确角色和约束 |
middleware | list | ❌ | [] | 功能扩展 | 组合日志、安全、摘要 |
checkpointer | Saver | ❌ | None | 短期记忆 | 生产用 PostgresSaver |
store | Store | ❌ | None | 长期记忆 | 跨会话用 PostgresStore |
state_schema | TypedDict | ❌ | AgentState | 扩展状态 | 用 TypedDict 非 Pydantic |
context_schema | TypedDict | ❌ | None | 动态上下文 | 配合 middleware 使用 |
response_format | BaseModel | ❌ | None | 结构化输出 | API 对接场景启用 |
from langchain.agents import create_agent
agent = create_agent(
model=model, # 模型
tools=[order_query_tool], # 工具
system_prompt="你是一个订单查询助手,能够查询订单状态和明细。" , # 系统提示
middlewares=[order_query_middleware], # 中间件
checkpointer=checkpointer, # 检查点短期记忆
store=store, # 状态存储长期记忆
state_schema=OrderQueryState, # 扩展状态(如需要)
context_schema=AgentContext, # 上下文状态(如需要)
response_format=ResponseModel # 结构化输出(如需要)
)
# ============ 限制最大 3 次循环 ============
config = {
"configurable": {"thread_id": "limit_demo"}, # 限制thread_id 线程ID
"recursion_limit": 3 # 最多 3 次迭代,或使用中间件进行精确跟踪和终止循环
}
result = agent.invoke(
{"messages": [{"role": "user", "content": "LangChain 1.0 发布日期"}]},
config=config
)
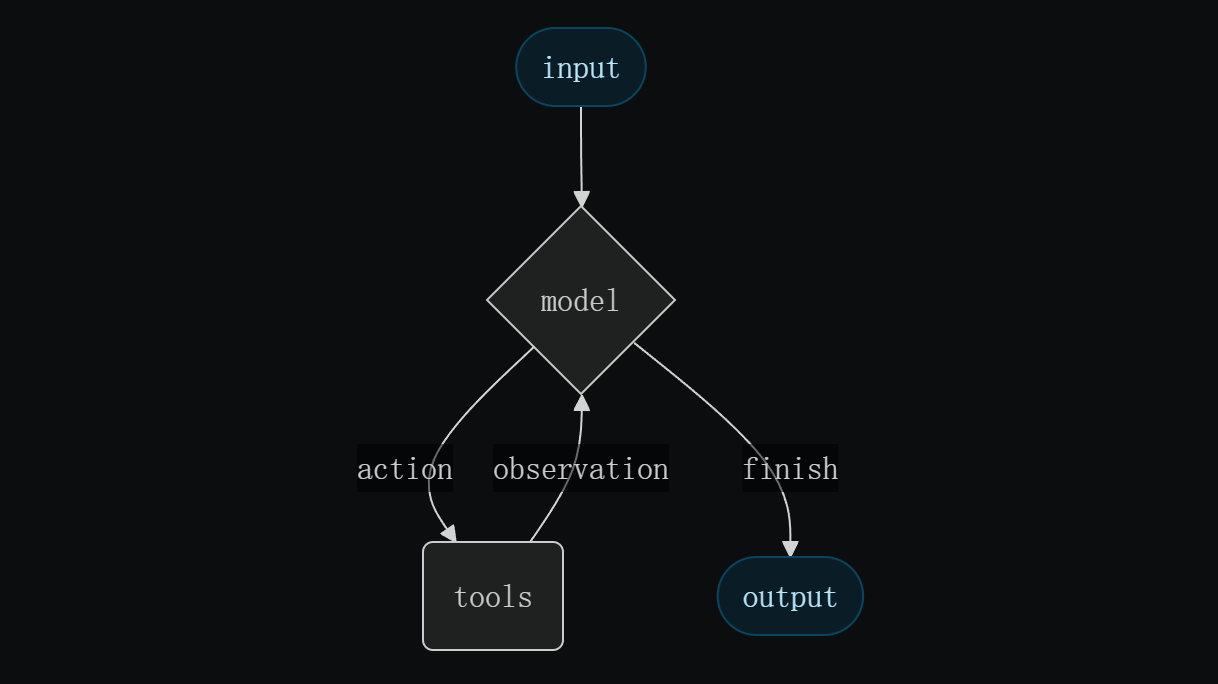
4.2 ReAct范式与执行循环 链接到标题
ReAct(Reasoning + Acting)范式强调"推理—行动—观察"的闭环:Agent先形成Thought(推理),据此选择并调用工具(Action),再吸收工具返回的Observation(观察),进入下一轮决策。闭环在达到最终答案、迭代上限或时间上限时终止。在LangGraph中,这一闭环由状态机与检查点驱动,保证每次行动的原子性、状态的可见性与轨迹的可回放性。并且推理与规划不是代码逻辑,而是LLM的生成行为,关键的 Thought: 步骤并非由确定性算法执行,而是prompt触发LLM生成推理文本。模型能力是ReAct性能的天花板
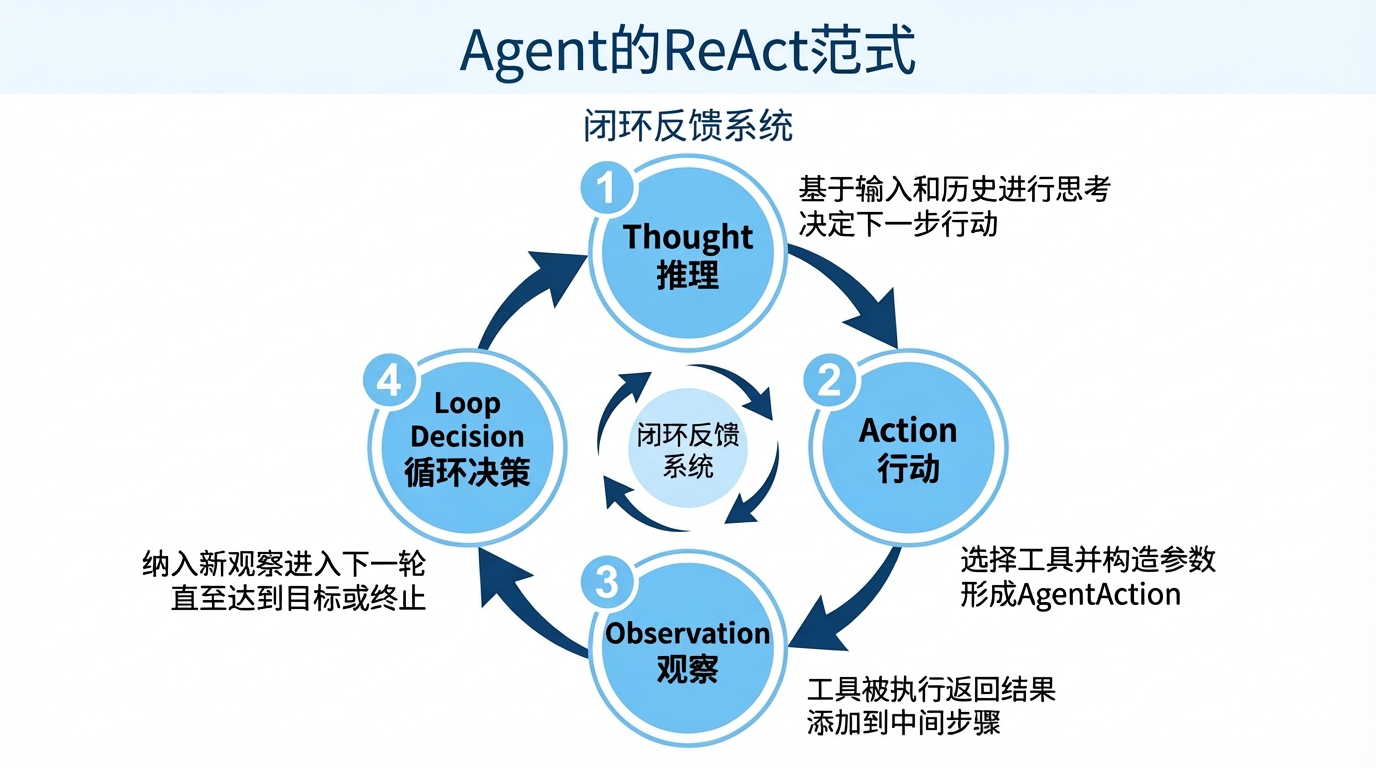
Agent的认知循环本质上是一个闭环反馈系统。每一次"行动"的执行结果都会作为新的输入反馈到系统,影响下一轮的"思考"和"行动"。这种反馈机制使得Agent能够动态调整策略,应对不确定的环境和复杂任务。在LangChain中,这一循环被实现为:
Thought (推理):大模型基于当前输入和历史记录进行思考,决定下一步行动。
Action (行动):大模型选择一个工具并构造输入参数,形成一个
AgentAction。Observation (观察):工具被执行,其返回结果作为观察值,并与
AgentAction一起被添加到中间步骤(intermediate_steps)中。循环决策:Agent将新的观察结果纳入上下文,进入下一轮"推理-行动"循环,直至达到最终目标或触发终止条件(如达到最大迭代次数)。
第四阶段、 工具(Tools)的集成与调用 链接到标题
工具是Agent与外部世界交互的桥梁。在LangChain中,工具的name、description和args_schema至关重要,它们共同决定了模型是否以及如何选择和调用工具。一个设计良好的工具描述是提示工程的关键部分。
工具注册:通过
@tool装饰器或继承BaseTool类来定义工具。工具调用:Agent在决策时,会根据工具描述选择最合适的工具。执行引擎负责调用该工具并处理其返回结果或异常。
安全与治理:在生产环境中,应对工具的调用进行严格的风险控制,如速率限制、权限隔离、输入校验等,这些可以通过中间件或在工具实现中直接加入。
LangChain内置工具列表:https://python.langchain.com/docs/integrations/tools/
| 工具名 | Python 类 | 作用 |
|---|---|---|
| python_repl | PythonREPLTool | 执行 Python |
| shell | ShellTool | 执行命令行 |
| human | HumanTool | 人工输入 |
| requests_get | RequestsGetTool | GET 请求 |
| requests_post | RequestsPostTool | POST 请求 |
| bing_search | BingSearchRun | Bing 搜索 |
| serper | GoogleSerperRun | Google 搜索 |
| tavily_search | TavilySearchResults | Tavily 搜索 |
| web_loader | WebBaseLoader | 网页加载 |
| apify | ApifyActorTool | 网页爬虫 |
| gmail | Gmail 工具 | 邮件管理 |
| google_calendar | GoogleCalendar 工具 | 日程管理 |
| python_ast | PythonAstREPLTool | 数据分析安全执行器 |
| read_file | ReadFileTool | 读取文件 |
| write_file | WriteFileTool | 写入文件 |
| sql_db_query | QuerySQLDatabaseTool | SQL 查询 |
| retriever | VectorStoreTool | RAG 检索 |
# 环境依赖版本
!pip list | grep langchain
#python 版本
!python --version
# 加载环境
from dotenv import load_dotenv
# 加载 .env 环境变量
load_dotenv(override=True)
# 1. 定义带速率限制的load_chat_model函数
from langchain.chat_models import init_chat_model
from langchain_core.rate_limiters import InMemoryRateLimiter
# 2. 配置速率限制器
rate_limiter = InMemoryRateLimiter(
requests_per_second=5, # 每秒最多5个请求
check_every_n_seconds=1.0 # 每1秒检查一次是否超过速率限制
)
# 3. 对模型调用进行封装,后续直接调用传参数就行
def load_chat_model(
model: str,
provider: str,
temperature: float = 0.7,
max_tokens: int | None = None,
base_url: str | None = None,
):
return init_chat_model(
model=model, # 模型名称
model_provider=provider, # 模型供应商
temperature=temperature, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=max_tokens, # 最大生成token数
base_url=base_url, # 专用于自定义 API Server 或代理
rate_limiter=rate_limiter # 自动限速
)
1.使用网络搜索工具 链接到标题
#!pip install langchain-tavily
优先使用支持 Function Calling 的模型(如 GPT-4o、Qwen)
# 1.导入相关库
from langchain.agents import create_agent
from langchain_community.tools.tavily_search import TavilySearchResults # 导入第三方社区集成 Tavily 搜索工具
from langchain_tavily import TavilySearch
# 2.导入模型和工具
web_search = TavilySearchResults(max_results=2)
# 3.创建模型
model = load_chat_model(model="deepseek-chat",provider="deepseek")
# 4.创建Agent
agent = create_agent(
model=model,
tools=[web_search],
system_prompt="你是一名多才多艺的智能助手,可以调用工具帮助用户解决问题。"
)
# 5.运行Agent获得结果
result = agent.invoke(
{"messages": [{"role": "user", "content": "请帮我查询2024年诺贝尔物理学奖得主是谁?"}]}
)
result['messages'][-1].content
2.自定义tool工具使用 链接到标题
#!pip install langchain-experimental
2.1 使用@tool装饰器来定义工具 链接到标题
@tool装饰器是LangChain中最简单、最直观的工具创建方式。它通过装饰器语法将普通Python函数转换为Agent可调用的工具,适合快速原型开发和简单工具实现。
技术概述:
自动参数推断:基于函数签名自动生成工具的参数schema
简化配置:只需提供工具名称和描述即可快速创建
同步执行:默认支持同步函数调用,异步需要单独定义
快速验证:适合概念验证和快速迭代开发
核心优势:
代码简洁,一行装饰器即可完成工具注册
无需复杂的类继承和配置
与Python函数无缝集成,开发效率高
适用场景:
快速原型验证
简单工具实现
开发测试阶段
from langchain_core.tools import tool
from langchain.agents import create_agent
# 1. 定义一个简单的 Tool (Runnable)
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
# 2.导入模型
model = load_chat_model(
model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
provider="openai", # 指定模型提供商为openai
)
# 3.创建Agent
agent = create_agent(model=model,tools=[multiply])
# 4. 调用Agent
response = agent.invoke({
"messages": [{
"role": "user",
"content": "帮我计算12乘以6等于多少?"
}]
})
response["messages"]
response["messages"][-1].content
- 使用LangGraph Studio 查看Agent结构
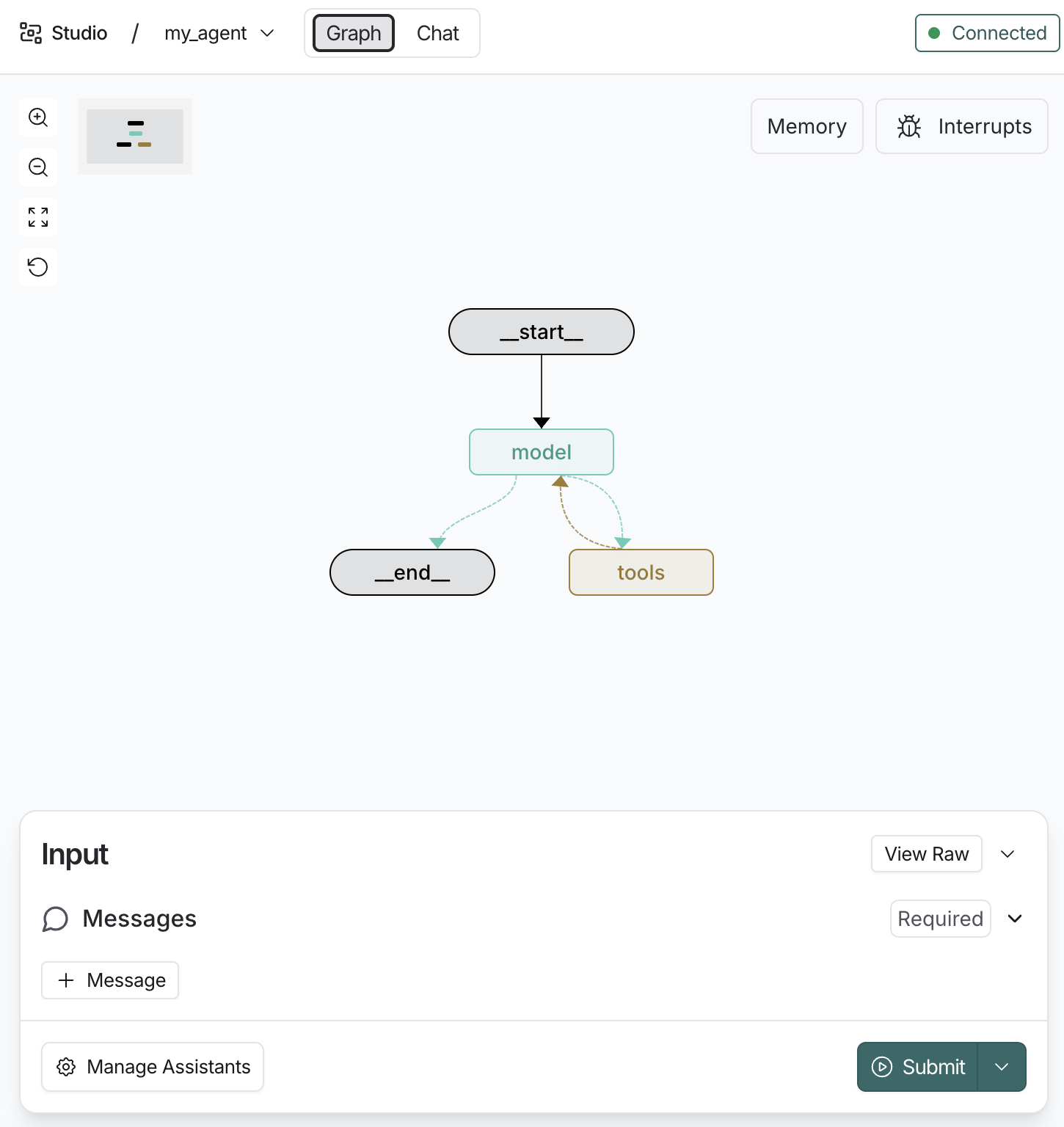
2.2 基础用法:StructuredTool.from_function() 链接到标题
- 这是最常用的方式,通过函数直接创建结构化工具,支持同步和异步双重实现。
StructuredTool.from_function()方法提供了更强大的工具创建能力,支持完整的参数校验和异步执行,适合生产环境使用。
技术概述:
强类型校验:支持Pydantic模型进行参数验证
异步支持:通过
coroutine参数支持异步函数完整元数据:支持name、description、return_direct等完整配置
生产就绪:内置错误处理和参数校验机制
核心特性:
参数schema完全可控,支持复杂数据结构
异步执行支持,适合I/O密集型操作
完整的工具元数据配置
生产环境级别的错误处理
适用场景:
生产环境工具开发
需要严格参数校验的场景
异步操作需求
企业级应用
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
"""
1. 通过 Pydantic BaseModel 定义参数,提供:
- 参数描述(description)
- 必填/可选约束
- 更清晰的 Schema 文档
"""
class DivideInput(BaseModel):
"""除法工具输入参数"""
dividend: float = Field(description="被除数")
divisor: float = Field(description="除数,不能为零")
def divide(dividend: float, divisor: float) -> float:
"""执行除法运算,支持浮点数"""
if divisor == 0:
raise ValueError("除数不能为零")
return dividend / divisor
# 2. 创建带参数校验的工具
division_tool = StructuredTool.from_function(
func=divide,
name="DivisionTool",
description="安全执行除法运算,自动处理除零错误",
args_schema=DivideInput, # 显式指定参数模式
return_direct=False, # 是否直接返回工具结果(不经过 LLM 再次处理)
)
# 3. 测试参数校验(触发 Pydantic 验证)
try:
division_tool.invoke({"a": 10, "b": 2}) # 错误:参数名不匹配
except Exception as e:
print(f"参数校验失败:{e}")
# 4. 正确调用
result = division_tool.invoke({"dividend": 10, "divisor": 2})
print(f"除法结果:{result}")
2.3 继承StructuredTool 链接到标题
通过继承StructuredTool类创建工具提供了最大的灵活性和控制力,适合复杂业务逻辑和状态管理需求。
技术概述:
完全自定义:可以完全控制工具的所有行为
状态管理:支持工具内部状态维护
复杂逻辑:适合实现复杂的业务逻辑
企业级特性:支持完整的生命周期管理
核心能力:
完整的Pydantic集成和类型系统
自定义错误处理和重试机制
工具内部状态管理
复杂的业务逻辑封装
适用场景:
企业级复杂工具开发
需要状态管理的工具
复杂的业务逻辑封装
高性能要求的场景
import os
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
from typing import Type
# 1. 定义包含业务逻辑的工具
class OrderQueryInput(BaseModel):
"""订单查询参数"""
order_id: str = Field(description="订单编号,格式:ORD-2024-XXXX")
include_details: bool = Field(default=False, description="是否包含商品明细")
class OrderQueryTool(StructuredTool):
"""订单查询工具"""
name: str = "query_order"
description: str = "查询电商平台订单状态和物流信息"
args_schema: Type[BaseModel] = OrderQueryInput
return_direct: bool = False
def _run(self, order_id: str, include_details: bool = False) -> dict:
# 模拟数据库查询
order_db = {
"ORD-2024-1234": {"status": "已发货", "express": "顺丰", "amount": 299},
"ORD-2024-5678": {"status": "待付款", "express": "", "amount": 149},
}
# 处理查询逻辑
if order_id not in order_db:
return {"error": f"订单 {order_id} 不存在"}
result = order_db[order_id]
# 处理包含明细的情况
if include_details:
result["items"] = ["商品A × 2", "商品B × 1"]
return result
# 2. 初始化模型
model = init_chat_model(
model="openai:gpt-4o-mini",
temperature=0,
api_key=os.getenv("OPENAI_API_KEY")
)
# 3. 创建 ReAct Agent(自动处理工具调用)
agent = create_agent(
model=model,
tools=[OrderQueryTool()], # 直接传入 StructuredTool 实例
system_prompt="你是一个电商客服助手,使用工具查询订单信息,回答要友好且准确",
checkpointer=InMemorySaver()
)
# 4. 执行并观察 ReAct 过程
async def run_agent():
config = {"configurable": {"thread_id": "customer_001"},"recursion_limit": 15}# 最大 15 次迭代
query = "请帮我查订单 ORD-2024-1234 的详细状态,包括商品明细"
async for step in agent.astream(
{"messages": [{"role": "user", "content": query}]},
config=config,
stream_mode="values" # 流式输出模式,返回每一步的完整状态
):
message = step["messages"][-1]
message.pretty_print()
print("-" * 50)
# 运行
await run_agent()
核心要点总结
参数校验:始终使用 args_schema 定义 Pydantic 模型,确保输入合法
异步优先:为网络 I/O 操作提供 _arun 实现,提升 Agent 并发性能
文档清晰:description 字段是 LLM 选择工具的唯一依据,必须详细描述功能和参数
返回值控制:return_direct=True 适合无需 LLM 润色的确定性格式数据
调试友好:使用 tool.invoke() 单独测试工具,确保逻辑正确后再集成到 Agent
三种方法对比与选择 链接到标题
| 特性 | @tool装饰器 | StructuredTool.from_function() | 继承StructuredTool |
|---|---|---|---|
| 代码简洁度 | ⭐⭐⭐⭐⭐(极简) | ⭐⭐⭐⭐(简洁) | ⭐⭐(较繁琐) |
| 参数控制 | 自动推断,弱控制 | 支持args_schema,强校验 | 完全自定义 Schema |
| 异步支持 | ❌(需单独定义 async 函数) | ✅(通过coroutine参数) | ✅(实现_arun方法) |
| 元数据定制 | 有限(name, description) | 中等(name, description, return_direct) | 完全定制(所有属性) |
| 适用场景 | 快速原型、简单工具 | 生产环境、需要参数校验的场景 | 复杂业务逻辑、状态管理 |
| 类型提示 | 依赖函数签名 | 结合 Pydantic 强类型 | 完整的 Pydantic 集成 |
3.多工具使用 链接到标题
from langchain.agents import create_agent
from langchain_core.tools import tool
# 定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 定义数学计算工具
@tool
def calculate(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
result = eval(expression)
return f"计算结果是:{result}"
except Exception as e:
return f"计算出错:{str(e)}"
# 1. 初始化LLM
llm = load_chat_model(model="gpt-4o-mini",provider="openai")
# 2. 创建Agent
agent = create_agent(
model=llm,
tools=[get_weather, calculate],
system_prompt="你是一个多功能的助手,可以查询天气和进行数学计算。"
)
# 3. 测试多工具调用
user_queries = [
"北京和上海的天气怎么样?",
"如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?"
]
# 4. 执行测试
for query in user_queries:
print(f"用户: {query}")
response = agent.invoke({
"messages": [{"role": "user", "content": query}]
})
print(f"Agent: {response['messages'][-1].content}")
print("-" * 50)
查看运行流程 链接到标题
import getpass
import operator
from typing import Annotated, List, Union
import os
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
from langchain.agents import create_agent
# 引入 UI 库
from rich.console import Console
from rich.panel import Panel
from rich.text import Text
from rich.markdown import Markdown
# 初始化控制台
console = Console()
# --- 第一步:定义工具 (和以前一样,这是 Core 标准) ---
# 定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 定义数学计算工具
@tool
def add(a: float, b: float) -> float:
"""计算两个数的和"""
return a + b
tools = [get_weather, add]
# --- 第二步:初始化模型 (必须绑定工具) ---
model = ChatOpenAI(model="gpt-4o", temperature=0)
# --- 第三步:构建图 (使用 prebuilt 的 ReAct Agent) ---
# 在 LangChain 1.0+ 中,这是 AgentExecutor 的官方替代品
# 它自动构建了:State -> Model Node -> Tool Node -> Loop 逻辑
graph = create_agent(model, tools=tools)
# --- 第四步:编写“教学专用”的可视化流式运行器 ---
def run_demo_with_visualization(user_input: str):
print("\n" + "="*50)
console.print(f"[bold yellow]开始任务:[/bold yellow] {user_input}")
messages = [HumanMessage(content=user_input)]
# graph.stream 是 LangGraph 的核心
# 它可以让我们看到状态流转的每一步 (step-by-step)
step_count = 1
# values 模式会返回当前的 message 列表状态
for event in graph.stream({"messages": messages}, stream_mode="values"):
# 获取最新的一条消息
current_message = event["messages"][-1]
# 1. 如果是人类的消息 (初始状态)
if isinstance(current_message, HumanMessage):
continue # 跳过,这是输入
# 2. 如果是 AI 的消息 (思考与决策)
if isinstance(current_message, AIMessage):
# 检查是否有工具调用
if current_message.tool_calls:
# 提取工具调用的细节
for tool_call in current_message.tool_calls:
console.print(Panel(
Text(f"🤔 AI 思考决定:需要调用外部工具\n"
f"🔧 工具名称: {tool_call['name']}\n"
f"📥 输入参数: {tool_call['args']}", style="bold cyan"),
title=f"Step {step_count}: 决策 (Decision)",
border_style="cyan"
))
else:
# 如果没有工具调用,说明是最终回复
console.print(Panel(
Markdown(current_message.content),
title=f"Step {step_count}: 最终回复 (Final Answer)",
border_style="green"
))
step_count += 1
# 3. 如果是工具的消息 (观察与结果)
if isinstance(current_message, ToolMessage):
console.print(Panel(
Text(f"👀 工具返回结果 (Observation):\n{current_message.content}", style="italic white"),
title=f"Step {step_count}: 执行与观察",
border_style="magenta"
))
step_count += 1
# --- 第五步:运行演示 ---
if __name__ == "__main__":
# 这是一个多步任务:先算乘法,再查属性
run_demo_with_visualization("查询一下北京和上海气温,并且计算一下北京的温度比上海低多少度?")
4. mcp接入LangChain 链接到标题
# 安装 MCP 适配器(关键依赖)\MCP 服务器开发库(如需自定义工具)
#!pip install langchain-mcp-adapters mcp
检查 Node.js
- node –version
检查 npm/npx
- npx –version
手动安装 MCP 服务器包
- npm install -g @amap/amap-maps-mcp-server
1. 本地部署的mcp服务 链接到标题
from langchain_mcp_adapters.client import MultiServerMCPClient # 导入 MCP 客户端
import os
from langchain_core.tools import tool
from langchain.agents import create_agent
# 1. 初始化 MCP 客户端,只连接本地 MCP 服务器
# 获取当前文件所在目录的绝对路径
mcp_server_path = os.path.join("mcp_server.py")
print(mcp_server_path)
# 2. 初始化 MCP 客户端,只连接本地 MCP 服务器
mcp_client = MultiServerMCPClient(
{
# 本地 Python MCP 服务器(stdio 传输)
"math": {
"transport": "stdio",
"command": "python",
"args": [mcp_server_path], # 使用绝对路径
},
# 如果需要其他服务器,可以在这里添加
# 注意:只添加确实在运行的服务器!否则会导致连接失败,需要先运行mcp_server.py文件!!!
}
)
# 3. 加载 MCP 工具
try:
mcp_tools = await mcp_client.get_tools()
print(f"✅ 成功加载 {len(mcp_tools)} 个 MCP 工具: {[t.name for t in mcp_tools]}")
except Exception as e:
print(f"❌ 加载 MCP 工具失败: {e}")
print("将只使用本地工具")
mcp_tools = []
# 4. 定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 5. 合并所有工具
all_tools = [get_weather] + mcp_tools
# 6. 加载 ChatOpenAI 模型
llm = load_chat_model(model="gpt-4o-mini",provider="openai")
# 7. 创建Agent
agent = create_agent(
model=llm,
tools=all_tools,
system_prompt="你是一个多功能的助手,可以查询天气和进行数学计算。"
)
# 8. 测试Agent,多个工具就可以使用ainvoke异步调用
response = await agent.ainvoke({
"messages": [{"role": "user", "content": "查询一下北京和上海气温,并且计算一下北京的温度比上海低多少度?"}]
})
print(f"Agent: {response['messages'][-1].content}")
2. 远程连接mcp服务器 链接到标题
魔搭社区高德地图mcp服务器:https://www.modelscope.cn/mcp/servers/@amap/amap-maps/tools
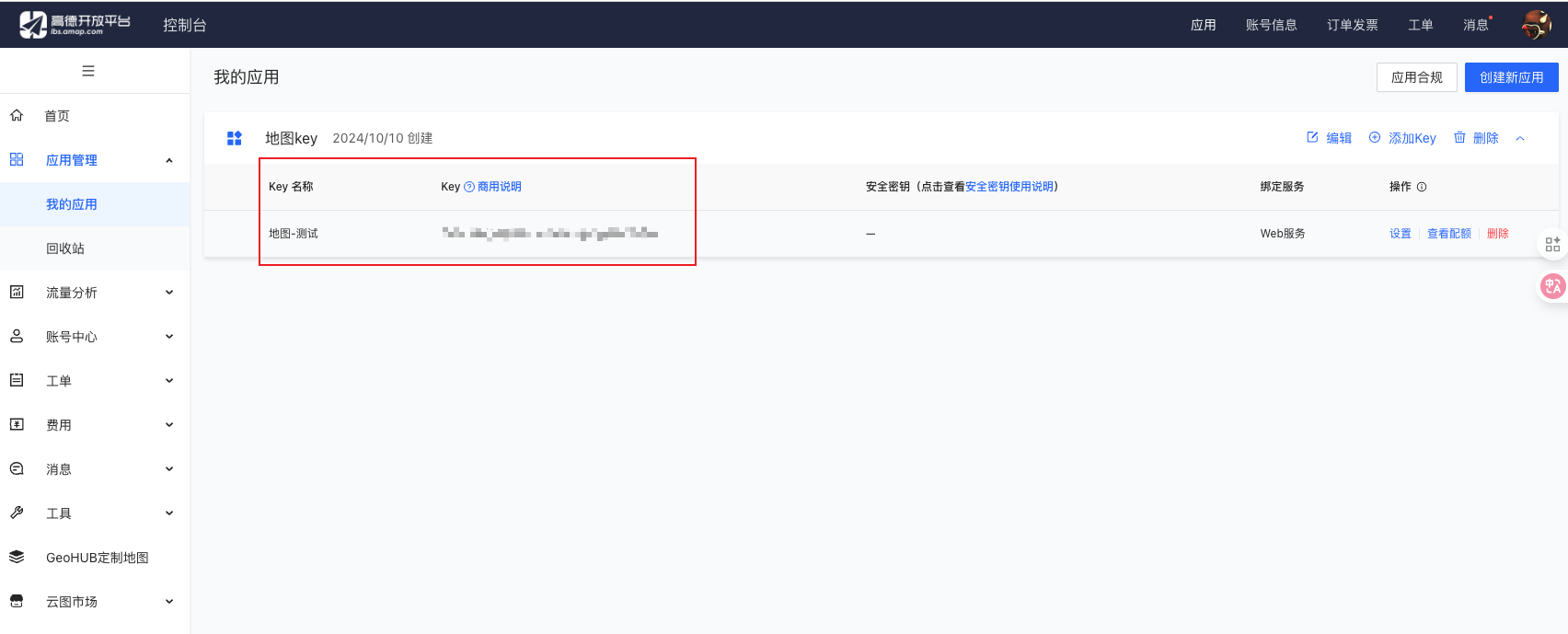
申请高德地图的api地址:https://console.amap.com/dev/key/app
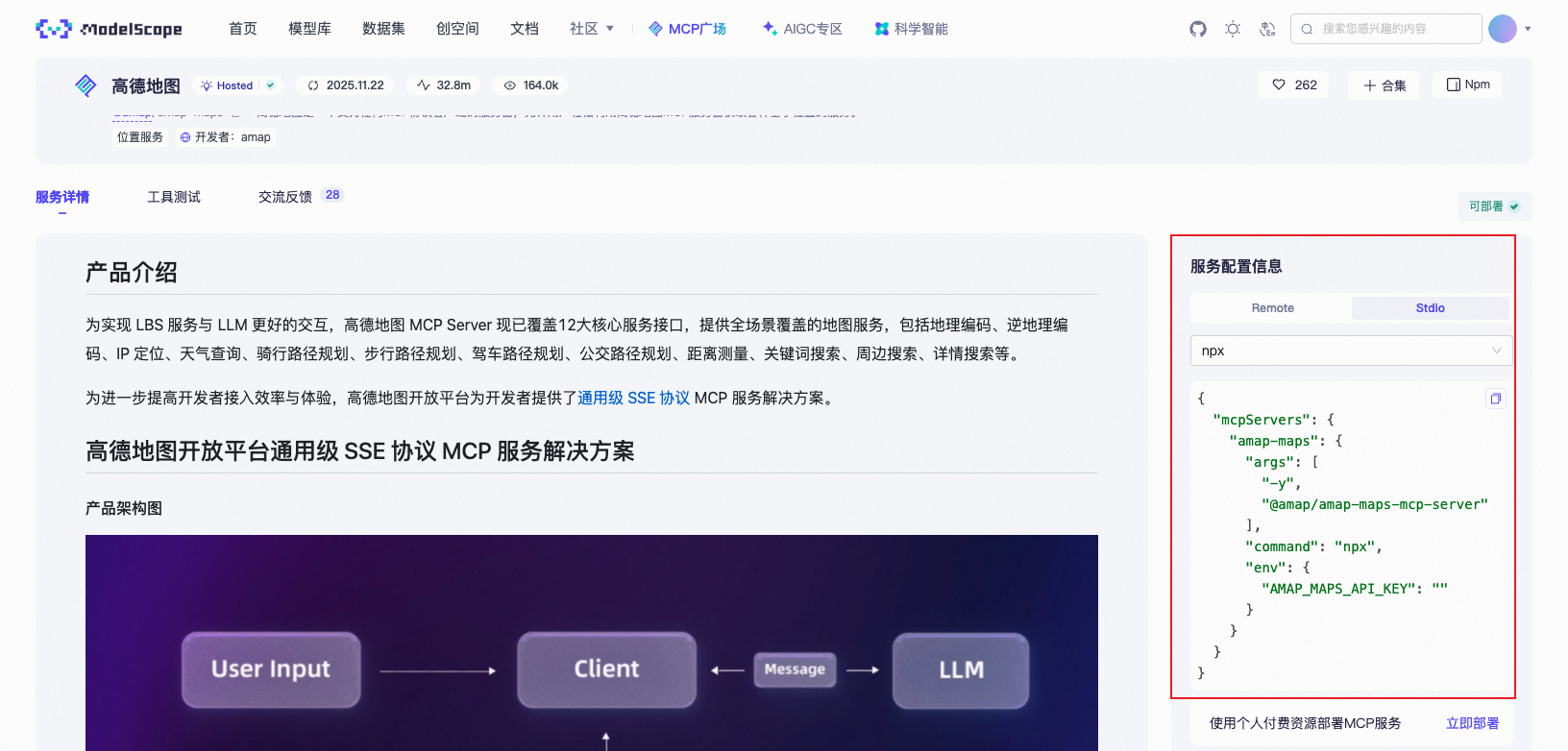
| 字段 | 类型 | 说明 | 示例 |
|---|---|---|---|
transport | string | 传输方式 | "stdio","streamable_http" , "SSE" |
command | string | 启动命令 | "python", "npx", "node" |
args | list | 命令参数 | ["mcp_server.py"] |
- LangChain官网mcp接入连接:https://docs.langchain.com/oss/javascript/langchain/mcp#model-context-protocol-mcp
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain.agents import create_agent
# 1. 正确的 MCP 配置格式(适用于 langchain_mcp_adapters)
# MultiServerMCPClient 需要的是扁平的字典结构,每个服务器是一个键值对
mcp_config = {
# 本地 Python MCP 服务器
"math": {
"transport": "stdio",
"command": "python",
"args": ["mcp_server.py"]
},
# 高德地图 MCP 服务器
"amap-maps": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {
"AMAP_MAPS_API_KEY": os.getenv("AMAP_MAPS_API_KEY"),
}
}
}
# 2. 创建 MCP 客户端
client = MultiServerMCPClient(mcp_config)
print("正在连接 MCP 服务器...")
# 3. client.get_tools() 会自动:
# 1. 调用所有服务器的 list_tools 接口
# 2. 将 MCP Tool Schema 转换为 LangChain StructuredTool
tools = await client.get_tools()
print(f"成功加载 {len(tools)} 个工具: {[t.name for t in tools]}")
# 4. 创建 Agent
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 直接将转换好的 tools 传给 create_agent
agent = create_agent(llm, tools,system_prompt="你是会调用工具进行天气查询、地图查询、网页部署的智能助手")
# 5. 运行 Agent
print("\n--- 开始测试 Agent ---")
# 6. 这里我们模拟一个请求(具体 prompt 取决于你的工具功能)
query = "请帮我搜索查询一下北京市今天的天气,并计算一下最大温差是多少度?"
inputs = {"messages": [HumanMessage(content=query)]}
async for chunk in agent.astream(inputs, stream_mode="values"):
last_msg = chunk["messages"][-1]
print(f"\n[{type(last_msg).__name__}]:")
print(last_msg.content)
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
print(f">>> 调用工具详情: {last_msg.tool_calls}")
3. HTTP 传输配置 链接到标题
MCP_CONFIG = {
"weather": {
"transport": "streamable_http",
"url": "http://localhost:8000/mcp" # HTTP 服务器地址
}
}
4. 对比表 链接到标题
| 特性 | 标准 MCP 配置 | MultiServerMCPClient 配置 |
|---|---|---|
| 顶层结构 | {"mcpServers": {...}} | {"server_name": {...}} |
| 服务器配置 | 嵌套在 stdio 字段中 | 直接在服务器对象中 |
command 位置 | server.stdio.command | server.command |
args 位置 | server.stdio.args | server.args |
| 适用场景 | Claude Desktop 等应用 | LangChain MCP 适配器 |
5 工具调用错误或者乱调情况 链接到标题
5.1 使用Tool Router(最有效) 链接到标题
Tool Router是解决工具调用混乱的最有效方法,它通过专门的工具路由机制来精确匹配用户意图与可用工具。
技术实现:
意图识别:使用专门的分类器识别用户意图
工具匹配:基于意图选择最合适的工具
参数验证:在调用前验证参数有效性
错误处理:提供优雅的降级策略
# 定义意图分类系统提示
INTENT_SYSTEM_PROMPT = """
你是一个专业的意图分类器,请只返回以下类别之一:
- search
- pdf
- database
- math
- none
并严格只返回类别名,不要输出其它内容。
"""
5.2 引入"意图分类模型"(工程最佳方案) 链接到标题
意图分类模型通过机器学习方法识别用户请求的真实意图,从根本上解决工具误用问题。
技术优势:
高精度识别:基于大量训练数据的准确意图识别
动态适应:能够适应新的用户表达方式
多维度分析:综合考虑语义、上下文、用户历史等因素
# 创建一个意图识别模型
intent_llm = load_chat_model(
model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
provider="openai", # 指定模型提供商为openai
)
5.3 动态加载工具(避免上下文过长) 链接到标题
动态工具加载机制根据当前对话上下文和用户意图,按需加载相关工具,避免一次性加载所有工具导致的上下文过长问题。
- 模型根据"意图"动态读取特定工具,不把所有工具一次性喂给模型。
实现策略:
```plain tools/ search.yaml finance.yaml pdf.yaml
```python
# 通过Tool 工具分组
TOOL_GROUPS = {
"search": [search_web],
"pdf": [extract_pdf_text],
"database": [query_database],
"math": [calculate],
}
5.4 统一工具规范(提高准确率) 链接到标题
通过强制化Schema和规范化提示词,建立统一的工具使用规范。
规范要求:
✔ 工具名称必须动词开头
✔ 每个工具使用标准化schema
✔ 工具描述必须包含三件事:能干什么、不能干什么、典型输入示例
@tool
def query_database(sql: str) -> str:
"""
执行 SQL 查询,仅限内部业务数据库。
参数:sql Sql语句。
示例:如 select * from users limit 5
"""
return f"模拟 SQL 执行:{sql}"
5.5 采用"工具过滤Prompt"修饰模型行为(成本最低) 链接到标题
通过系统Prompt显式指导模型行为,设置工具使用边界。
Prompt示例:
```plain 你必须严格根据工具描述选择工具。 不能猜测工具功能。 如果没有合适的工具,请回答"无合适工具"。
```python
agent = create_agent(
model=model,
tools=tools,
system_prompt="你是一个 helpful assistant,可以使用工具回答问题。你必须严格根据工具描述选择工具!如果没有合适的工具,请回答“无合适工具”"
)
5.6 层次化/多级Agent架构 链接到标题
通过层次化Agent架构降低单个Agent的工具复杂度,提高系统稳定性。
架构优势:
模块化设计:每个Agent专注于特定领域
降低复杂度:单个Agent工具数量可控
提高稳定性:错误隔离和容错能力更强
from langchain.tools import tool
@tool
def search_web(query: str) -> str:
"""Web 搜索工具,用于查询网络公开信息,不适用于内部数据.参数:query 用户查询,如 OpenAI发布会"""
return f"模拟搜索结果:你搜索了 {query}"
@tool
def extract_pdf_text(path: str) -> str:
"""解析 PDF 文本文件。参数为文件的本地路径.参数:path 文件路径,如 /files/contract.pdf"""
return f"模拟 PDF 内容:从 {path} 中解析出的内容"
@tool
def query_database(sql: str) -> str:
"""执行 SQL 查询,仅限内部业务数据库.参数:sql Sql语句,如 select * from users limit 5"""
return f"模拟 SQL 执行:{sql}"
@tool
def calculate(expr: str) -> str:
"""计算数学表达式。适用于算式运算.参数:expr 数学表达式,如 (12+3)*(8-2)"""
return str(eval(expr))
# 1.Tool 工具分组
TOOL_GROUPS = {
"search": [search_web],
"pdf": [extract_pdf_text],
"database": [query_database],
"math": [calculate],
}
# 2.创建一个意图识别模型
intent_llm = load_chat_model(
model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
provider="openai", # 指定模型提供商为openai
)
# 3. 定义意图分类系统提示
INTENT_SYSTEM_PROMPT = """
你是一个专业的意图分类器,请只返回以下类别之一:
- search
- pdf
- database
- math
- none
并严格只返回类别名,不要输出其它内容。
"""
# 4. 定义意图分类函数
def classify_intent(user_query: str) -> str:
result = intent_llm.invoke(
[
("system", INTENT_SYSTEM_PROMPT),
("user", user_query)
]
)
return result.content.strip()
from langchain.agents import create_agent
import os
from dotenv import load_dotenv
load_dotenv()
# 5. 创建智能体函数
def create_agent_for_group(group: str):
tools = TOOL_GROUPS.get(group, [])
if not tools:
return None
model = load_chat_model(
model="deepseek-chat",
provider="deepseek",
)
agent = create_agent(
model=model,tools=tools,system_prompt="你是一个 helpful assistant,可以使用工具回答问题。你必须严格根据工具描述选择工具!如果没有合适的工具,请回答“无合适工具”"
)
return agent
# 6. 路由智能体函数
def router_agent(user_query: str):
# 1. 识别意图
intent = classify_intent(user_query)
print(f"[Router] 检测到意图: {intent}")
# 2. 创建对应子 Agent
sub_agent = create_agent_for_group(intent)
if sub_agent is None:
return "无法为该问题找到合适的工具或 Agent。"
# 3. 调用子 Agent 执行任务
result = sub_agent.invoke({
"messages": [{"role": "user", "content": user_query}]
})
return result
res = router_agent("请帮我搜索一下今年Google最新的大模型版本的发布会")
# 7. 测试智能体
queries = [
"请帮我搜索一下今年Google最新的大模型版本的发布会",
"帮我解析一下这个PDF:/root/files/contract.pdf",
"执行一个SQL:select * from products limit 5",
"计算 (17+3)*(8-1)",
]
for q in queries:
print("\n====== 用户问题 ======")
print(q)
print("====== Agent 回复 ======")
print(router_agent(q)["messages"][2])
System Prompt 系统提示词 链接到标题
system_prompt 是 create_agent 中定义 Agent 角色、行为准则、输出格式和约束 的核心参数,相当于 Agent 的"人格说明书"。LangChain 1.0 将其设计为唯一的顶层提示词入口。LangChain 1.0 不支持在 system_prompt 中直接嵌入 {variable} 占位符(这是旧版 PromptTemplate 的做法)。如需动态内容,应使用 dynamic_prompt 中间件。
#system_prompt 在 ReAct 循环中的位置:
# System Prompt (固定前缀)
# ↓
# 用户输入 → 模型推理 (Thought) → 工具调用 (Action) → 观察结果 (Observation)
# ↓
# 循环直到满足终止条件 → 最终回答
通过精心设计的提示词,您可以:
定义角色:从客服到专家,从教师到顾问
约束输出:控制长度、格式、语言
引导工具:强制或可选使用工具
保障安全:防止数据泄露和违规操作
实现个性化:通过动态提示支持多租户
记住:在 LangChain 1.0 中,system_prompt 的设计质量直接决定了 Agent 的表现上限。投入时间打磨提示词,远比调整模型参数更有效。
from langchain.agents import create_agent
from langchain.tools import tool
# 1. 定义一个简单的天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 2. 静态 system_prompt(固定不变)
agent_static = create_agent(
model="openai:gpt-4o-mini",
tools=[get_weather],
system_prompt=(
"你是一个天气助手,回答不超过20字。\n"
"调用工具时,严格按照以下格式:\n"
"1. 使用 `get_weather(city: str)` 获取天气;\n"
"2. 仅返回天气结果,不解释过程。"
)
)
print("=== 静态 System Prompt ===")
response1 = agent_static.invoke({
"messages": [{"role": "user", "content": "北京天气"}]
})
print(f"AI: {response1['messages'][-1].content}")
# 3. 动态提示词(通过中间件实现)
from langchain.agents.middleware import dynamic_prompt
from typing import TypedDict
# 4. 定义上下文结构
class Context(TypedDict):
user_role: str # 用户角色
# 5. 动态提示函数
@dynamic_prompt
def role_based_prompt(request):
"""根据用户角色生成不同提示词"""
user_role = request.runtime.context.get("user_role", "user")
if user_role == "expert":
return "你是一个专业气象分析师,提供详细数据"
elif user_role == "beginner":
return "你是一个友善的导游,用简单语言解释"
else:
return "你是一个简洁的天气助手"
# 6. 创建动态 Agent
agent_dynamic = create_agent(
model="openai:gpt-4o-mini",
tools=[get_weather],
middleware=[role_based_prompt], # 注入动态提示
context_schema=Context
)
print("\n=== 动态 System Prompt(专家角色)===")
response2 = agent_dynamic.invoke(
{"messages": [{"role": "user", "content": "北京天气"}]},
context={"user_role": "expert"}
)
print(f"AI: {response2['messages'][-1].content}")
print("\n=== 动态 System Prompt(新手角色)===")
response3 = agent_dynamic.invoke(
{"messages": [{"role": "user", "content": "北京天气"}]},
context={"user_role": "beginner"}
)
print(f"AI: {response3['messages'][-1].content}")
流式输出 链接到标题
stream_mode 模式的对比
| 模式 | 输出内容 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
"values" | 每步后的完整状态 | 调试Agent执行流程 | ⭐ 状态完整,可追溯⭐ 无需拼接历史 | 数据量大(重复传输) |
"updates" | 仅状态变更部分 | 前端增量更新UI | 数据量小,传输快 | 需手动维护完整状态 |
"messages" | LLM生成的token流 | 实时显示打字效果 | 响应即时,用户体验好 | 不包含工具调用信息 |
"custom" | 工具函数自定义输出 | 插入业务日志 | 灵活控制输出内容 | 需手动调用stream writer |
from langchain.agents import create_agent
from langchain_core.tools import tool
# 1. 定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 2. 定义数学计算工具
@tool
def calculate(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
result = eval(expression)
return f"计算结果是:{result}"
except Exception as e:
return f"计算出错:{str(e)}"
# 3. 初始化LLM
llm = load_chat_model(model="gpt-4o-mini",provider="openai")
# 4. 创建Agent
agent = create_agent(
model=llm,
tools=[get_weather, calculate],
system_prompt=("""
你是一个多功能的 AI 助手,能够调用以下工具:
1. `get_weather(city)`:查询指定城市的天气信息。参数 city 为城市名称(如“北京”)。
2. `calculate(expression)`:计算数学表达式。参数 expression 为合法的 Python 表达式(如“25 - 28”)。
请始终遵循以下最佳实践:
• 当用户询问天气时,先提取城市名,再调用 `get_weather`,并返回自然语言总结。
• 当用户需要计算时,先提取表达式,再调用 `calculate`,并给出易读的结果说明。
• 若问题同时涉及天气与计算,按顺序依次调用对应工具,最后整合答案。
• 禁止编造数据,必须调用工具获取结果后再回答。
• 所有数字、单位、符号务必与工具返回保持一致,避免主观臆断。
"""
)
)
# 5. 测试多工具调用
user_queries = [
"北京和上海的天气怎么样?",
"如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?"
]
# 6. 配置会话 ID
config = {"configurable": {"thread_id": "user_123"}} # 会话 ID
# 7. 流式输出,实时观察推理过程
for step in agent.stream(
{"messages": [{"role": "user", "content": "北京和上海的天气怎么样?"}]},
config=config,
stream_mode="values" # 返回每个step步骤的完整消息列表,便于调试和观察
):
# 获取最新消息并格式化打印
message = step["messages"][-1]
message.pretty_print()
print("-" * 50)
# 监控Agent执行时间
# for chunk in agent.stream(..., stream_mode="values"):
# steps += 1
# elapsed = time.time() - start
# print(f"步骤 {steps} 耗时:{elapsed:.2f}s")
#
# print(f"总耗时:{time.time() - start:.2f}s,总步骤:{steps}")
# 捕获中间步骤的错误
# for chunk in agent.stream(..., stream_mode="values"):
# messages = chunk["messages"]
# if messages[-1].type == "error":
# print(f"步骤出错:{messages[-1].content}")
# # 回滚到上一步的状态
# last_valid_state = messages[-2]
# # 重新执行...
常见误区与注意事项
误区1:stream_mode=“values” 会流式返回 LLM token
- 真相:它返回的是步骤级的完整状态,不是字符级token。想看token需用 stream_mode=“messages”
误区2:values 和 updates 返回数据量差不多
- 真相:values 在每一步都返回所有历史消息,数据量线性增长;updates 只返回增量,适合网络传输
误区3:可以混用多种 stream_mode
- 真相:可以同时指定多个模式(如 stream_mode=[“values”, “custom”]),但返回的是元组,需分别处理
第五阶段、 Agent记忆管理 链接到标题
LangChain 1.0的记忆管理与LangGraph的状态机制深度绑定,在 LangGraph 中,记忆就是"持久化的状态(Persisted State)"。
你需要掌握三个核心要素:
State (状态): 定义用来存储消息的结构(通常是
MessagesState)。Checkpointer (检查点保存器): 负责在每一步结束后把状态保存下来(短期记忆通常用
MemorySaver)。Thread ID (线程ID): 在调用时通过
config传入,用来隔离不同用户的对话上下文。
短期 vs 长期记忆的分界标准
- 误区:存储介质 = 记忆类型?
错误认知:
“内存 = 短期记忆”
“数据库 = 长期记忆”
正确标准:
短期记忆:数据与会话(thread进程)生命周期绑定,随会话结束而被清理或遗忘
长期记忆:数据与用户/业务实体生命周期绑定,跨会话持久保留并可主动检索
5.1 短期记忆管理 链接到标题
短期记忆通过LangGraph的AgentState(一个TypedDict)来管理。对话历史、中间步骤等信息被保存在状态中,并通过检查点(Checkpoints)机制在每次迭代后持久化。这使得长对话和失败恢复成为可能。
1. Checkpointer机制 链接到标题
这是 LangGraph 记忆的灵魂。
不加这一行:Agent 是无状态的。每次
invoke都是全新的开始。加上这一行:LangGraph 会在每一步执行后,把
state序列化并存入MemorySaver。原理:当你再次 invoke 并传入
thread_id时,LangGraph 会先去内存里查"这个 ID 上次停在哪里?状态是什么?",然后加载状态,把你的新消息append进去,再继续运行。
2 Thread ID配置 链接到标题
这是短期记忆的"钥匙"。
在 Web 开发中,这就是 Session ID。
你需要为每个用户或每个会话生成一个唯一的 ID。
不同的 ID 之间内存是完全隔离的(如代码中
session_user_123和session_user_999的区别)。
InMemorySaver() 内存记忆管理 链接到标题
import os
from langchain.agents import create_agent
from langchain_core.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.messages import HumanMessage, SystemMessage, trim_messages
# ============ 初始化 LLM ============
model = load_chat_model(model="gpt-4o-mini",provider="openai")
# ============ 定义工具函数 ============
@tool
def get_user_info(name: str) -> str:
"""查询用户信息,返回姓名、年龄、爱好"""
user_db = {
"陈明": {"age": 28, "hobby": "旅游、滑雪、喝茶"},
"张三": {"age": 32, "hobby": "编程、阅读、电影"}
}
info = user_db.get(name, {"age": "未知", "hobby": "未知"})
return f"姓名: {name}, 年龄: {info['age']}岁, 爱好: {info['hobby']}"
# ============ 1. 基础短期记忆:InMemorySaver ============
"""
开发环境使用内存存储,重启后记忆丢失。
关键参数:
- checkpointer: 记忆存储对象
- thread_id: 会话唯一标识(用户级隔离)
"""
def demo_inmemory_memory():
print("=" * 60)
print("场景 1: 内存记忆(开发环境)")
print("=" * 60)
# 创建内存检查点
memory = InMemorySaver()
# 创建 Agent(自动继承对话记忆能力)
agent = create_agent(
model=model,
tools=[get_user_info],
checkpointer=memory # 启用短期记忆
)
# 配置:thread_id 作为会话 ID
config = {"configurable": {"thread_id": "user_123"}}
# 第一轮对话:自我介绍
response1 = agent.invoke(
{"messages": [{"role": "user", "content": "你好,我叫陈明,好久不见!"}]},
config=config
)
print(f"用户:你好,我叫陈明,好久不见!")
print(f"AI: {response1['messages'][-1].content}")
print("-" * 40)
# 第二轮对话:测试记忆
response2 = agent.invoke(
{"messages": [{"role": "user", "content": "请问你还记得我叫什么名字吗?"}]},
config=config # 使用相同 thread_id,自动携带上下文
)
print(f"用户:请问你还记得我叫什么名字吗?")
print(f"AI: {response2['messages'][-1].content}")
print("-" * 40)
# 验证记忆状态
state = agent.get_state(config)
print(f"当前记忆轮次: {len(state.values['messages'])} 条消息")
# 新开一个会话(不同 thread_id)
config2 = {"configurable": {"thread_id": "user_456"}}
response3 = agent.invoke(
{"messages": [{"role": "user", "content": "我们之前聊过吗?"}]},
config=config2
)
print(f"新会话 AI: {response3['messages'][-1].content}") # 应无记忆
demo_inmemory_memory()
PostgresSaver() 数据库持久化记忆 链接到标题
PostgresSaver 即使存储到数据库,仍然属于短期记忆。仍然属于短期记忆的原因:
作用域限制:它只检索和加载当前 thread_id 的数据
生命周期管理:默认不会主动清理,但数据语义上属于"本次会话"
无跨会话检索能力:无法在新会话中自动访问旧会话数据(除非手动指定旧 thread_id)
#系统安装postgresql
#brew install postgresql
#!pip install langgraph-checkpoint-postgres # 生产环境使用
# 测试数据库是否连接正常
!psql -U myuser -d mydatabase -c "SELECT version();"
from langgraph.checkpoint.postgres import PostgresSaver
"""
生产环境使用数据库存储,支持:
- 持久化(重启不丢失)
- 多实例共享(分布式部署)
- 大规模并发
"""
print("\n" + "=" * 60)
print("场景 2: Postgres 持久化记忆(生产环境)")
print("=" * 60)
# 定义工具函数:查询用户信息
@tool
def get_user_info(name: str) -> str:
"""查询用户信息,返回姓名、年龄、爱好"""
user_db = {
"陈明": {"age": 28, "hobby": "旅游、滑雪、喝茶"},
"张三": {"age": 32, "hobby": "编程、阅读、电影"}
}
info = user_db.get(name, {"age": "未知", "hobby": "未知"})
return f"姓名: {name}, 年龄: {info['age']}岁, 爱好: {info['hobby']}"
# 创建模型
model = load_chat_model(model="gpt-4o-mini",provider="openai")
# 数据库连接字符串
DB_URI = "postgresql://myuser:123456@localhost:5432/mydatabase"
# 使用上下文管理器确保连接正确关闭
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 自动创建表结构(仅首次运行)
checkpointer.setup()
# 创建智能体
agent = create_agent(
model=model,
tools=[get_user_info],
checkpointer=checkpointer
)
# 配置线程 ID(用于区分不同用户)
config = {"configurable": {"thread_id": "production_user_001"}}
# 模拟用户注册流程
agent.invoke(
{"messages": [{"role": "user", "content": "我是新用户张三,请记录我的信息"}]},
config=config
)
response = agent.invoke(
{"messages": [{"role": "user", "content": "我是谁?"}]},
config=config
)
print(f"AI: {response['messages'][-1].content}")
!psql -U myuser -d mydatabase -c "SELECT * FROM checkpoints WHERE thread_id = 'production_user_001' LIMIT 3;"
| 特性维度 | InMemorySaver | PostgresSaver |
|---|---|---|
| 存储位置 | 内存(Python dict) | PostgreSQL 数据库 |
| 生命周期 | 会话级(与 thread_id 绑定) | 会话级(与 thread_id 绑定) |
| 作用域 | 单一会话(无法跨线程) | 单一会话(无法跨线程) |
| 持久化 | 进程重启后丢失 | 进程重启后保留 |
| 数据隔离 | thread_id | thread_id |
| 适用环境 | 开发、测试 | 生产、分布式部署 |
| 性能 | 极高(纳秒级) | 较高(毫秒级) |
| 扩展性 | 单进程限制 | 支持多实例、高并发 |
| 核心定位 | 短期记忆 | 短期记忆(持久化版) |
5.2 上下文裁剪 链接到标题
此外,真正的记忆管理还涉及"上下文窗口控制"(防止对话太长撑爆 Token),这需要配合 trim_messages 使用。
问题:如果不处理,随着对话进行,
state["messages"]会包含几千条消息。直接全部传给 LLM 会导致:1. 烧钱;2. 超过 128k/8k 限制报错。解决:我们在
call_model内部使用了 trimmer。State 中:依然保存了 100% 的完整历史(为了审计或回溯)。
传给 LLM 时:只传最近的 N 个 Token(或 N 条消息)。
start_on=“human”: 这是一个很细节的最佳实践。如果截断导致第一条消息是 AI 的回复(没有对应的 User 问题),某些模型会感到困惑。这个参数确保截断后的对话总是以 User 开始。
# ============ 核心模块导入 ============
import os
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langchain_core.tools import tool
from langgraph.checkpoint.memory import InMemorySaver # 短期记忆存储
from langchain_core.messages import trim_messages # 消息裁剪工具
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
# ============ 初始化 LLM 与工具 ============
model = init_chat_model(
model="gpt-4o-mini",
model_provider="openai",
temperature=0.7
)
# 1. 定义天气查询工具
@tool
def search_weather(city: str) -> str:
"""查询城市天气"""
return f"{city}天气:晴,25°C"
# ============ 配置裁剪参数 ============
MAX_TOKENS = 100 # 根据模型上下文长度调整,上下文128K的话,一般设置为4000左右
TRIM_STRATEGY = "last" # 保留最新消息
INCLUDE_SYSTEM = True # 系统消息不参与裁剪
"""
tiktoken 是 OpenAI 官方 token 编码库,支持精确计数。
不同模型需使用不同编码:
- gpt-4o, gpt-4o-mini: o200k_base
- gpt-4-turbo: cl100k_base
- text-davinci-003: p50k_base
"""
import tiktoken
# 2. 定义 Token 编码器获取函数
def get_token_encoder(model_name: str = "gpt-4o-mini"):
"""获取 tiktoken 编码器实例"""
try:
# 自动映射模型到编码器
encoding = tiktoken.encoding_for_model(model_name)
print(f"✅ 已加载模型 '{model_name}' 的 tiktoken 编码器")
return encoding
except KeyError:
# 如果模型不在官方列表,使用默认编码
print(f"⚠️ 模型 '{model_name}' 未在映射表中,使用默认编码 'o200k_base'")
return tiktoken.get_encoding("o200k_base")
# 3. 初始化编码器(全局复用提升性能)
TOKEN_ENCODER = get_token_encoder("gpt-4o-mini")
# ============ 2. 精确 Token 计数函数 ============
def count_tokens_tiktoken(messages):
"""
使用 tiktoken 精确计算消息列表的 token 总数
参数:
messages: List[BaseMessage] - 消息对象列表
返回:
int: 总 token 数
说明:
- 每个消息包含角色、内容和元数据,需完整编码
- 不同消息格式(Human/AI/System)的 token 开销不同
- 此函数模拟真实 API 调用的 token 计数逻辑
"""
total_tokens = 0
# 遍历每条消息,累加 token 数
for message in messages:
# 消息格式:role + content + 特殊标记
# 典型格式:<|im_start|>role<|im_end|>content<|im_end|>
# 角色 token(如 "user", "assistant", "system")
role_tokens = len(TOKEN_ENCODER.encode(message.type))
# 内容 token(消息正文)
content_tokens = len(TOKEN_ENCODER.encode(message.content))
# 格式开销(OpenAI 消息边界标记)
# 每条约 4 个特殊 token(开始、角色、结束、内容结束)
format_overhead = 4
total_tokens += role_tokens + content_tokens + format_overhead
return total_tokens
# ============ 创建Agent ============
def create_trimmed_agent():
"""创建 Agent 并配置 InMemorySaver"""
memory = InMemorySaver()
agent = create_agent(
model=model,
tools=[search_weather],
system_prompt="你是一个简洁的助手,记住用户提到的城市名称",
checkpointer=memory # 启用短期记忆
)
return agent
# ============ 手动裁剪并调用 Agent ============
def invoke_with_trim(agent, user_input: str, config: dict):
"""
在调用 Agent 前手动裁剪上下文
流程:
1. 获取当前状态(所有历史消息)
2. 使用 trim_messages 裁剪
3. 构建新输入(裁剪后的消息 + 新消息)
4. 调用 Agent
"""
# 1. 获取当前记忆状态
state = agent.get_state(config)
existing_messages = state.values.get("messages", []) if state else []
# 精确计算当前 token 数
current_tokens = count_tokens_tiktoken(existing_messages)
# 2. 如果有历史消息,先裁剪
if existing_messages:
print(f"裁剪前消息数: {len(existing_messages)}")
# 核心:调用 trim_messages 进行裁剪
trimmed_messages = trim_messages(
existing_messages, # 待裁剪的消息列表
max_tokens=MAX_TOKENS, # 允许的最大 token 数,超过则触发裁剪
token_counter=count_tokens_tiktoken, # token 计数函数
strategy=TRIM_STRATEGY, # 裁剪策略,"last" 保留最新消息,"first" 保留最早消息
include_system=INCLUDE_SYSTEM, # 是否保留系统消息(通常必须保留)
allow_partial=False, # False不允许部分消息,会尝试保留消息的完整性。如果无法在保持消息完整性的前提下将总token数裁剪到参数 max_tokens 以内,就会返回 空列表
start_on="human" # 从 human 消息开始裁剪
)
# 计算裁剪后的 token 数
new_tokens = count_tokens_tiktoken(trimmed_messages)
print(f"裁剪后 token: {new_tokens},裁剪后消息数: {len(trimmed_messages)}")
else:
trimmed_messages = []
# 3. 添加新消息
new_messages = trimmed_messages + [HumanMessage(content=user_input)]
# 4. 调用 Agent(checkpointer 会自动保存新状态)
response = agent.invoke(
{"messages": new_messages},
config=config
)
return response
# ============ 演示多轮对话与裁剪 ============
def demo_manual_trim():
"""演示手动裁剪上下文的多轮对话"""
print("=" * 60)
print("场景:手动 trim_messages + InMemorySaver")
print("=" * 60)
agent = create_trimmed_agent()
config = {"configurable": {"thread_id": "trim_user_001"}}
# 模拟多轮对话
conversations = [
"你好,我叫陈明",
"查询北京天气",
"上海呢?",
"明天北京天气如何?", # 此时会触发裁剪
"我是谁?", # 测试记忆是否保留
]
for i, query in enumerate(conversations, 1):
print(f"\n--- 第 {i} 轮 ---")
print(f"用户: {query}")
# 每次调用前自动裁剪
response = invoke_with_trim(agent, query, config)
print(f"AI: {response['messages'][-1].content}")
print("-" * 40)
# ============ 运行演示 ============
if __name__ == "__main__":
demo_manual_trim()
5.3 自定义 State 扩展 链接到标题
在 LangGraph 中,AgentState 是一个 TypedDict,定义了 Agent 执行过程中流转的数据结构。扩展 State = 在基础结构上增加自定义字段,用于携带更多上下文和业务数据。
- 扩展 State 的本质:在 LangGraph 中,State 是 Agent 的 “内存” 和 “消息总线” ,扩展它就像给程序增加新的全局变量,但这些变量随执行流自动流转、隔离、持久化,是实现复杂 Agent 逻辑的基础。
扩展 State 核心目的
跨步骤持久化上下文:Agent 执行是多步骤的(LLM调用 → 工具调用 → 结果解析),扩展的 State 字段能在所有步骤间共享。
实现条件分支与动态路由:根据 State 中的字段值,决定 Agent 的下一步走向。
支持多模态与复杂输入:现代 Agent 需要处理图片、文件等非文本数据,扩展到 State 中。
实现记忆与持久化:扩展字段用于存储长期记忆,跨会话保持。
性能监控与调试:扩展字段用于记录性能指标,便于分析优化。
class ExtendedState(TypedDict):
messages: list[BaseMessage]
user_id: str # 扩展:用户身份,用于权限控制和个性化
session_id: str # 扩展:会话标识,用于对话历史管理
retry_count: int # 扩展:重试次数,用于错误处理策略
original_query: str # 扩展:原始查询,用于日志和审计
使用 TypedDict 当且仅当:
性能极度敏感(如高频API响应,避免Pydantic序列化开销)
数据结构简单(无嵌套或浅层嵌套)
仅需类型提示(团队强制使用mypy,且信任数据输入)
外部库要求(如某些ORM返回TypedDict)
# ============ 自定义 State 扩展 ============
"""
通过 TypedDict 扩展 AgentState,添加业务字段(用户ID、偏好等)。
LangChain 1.0 推荐使用 TypedDict 而非 Pydantic。
"""
from typing import TypedDict, Optional
from langchain.agents import AgentState, create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 定义自定义 State 结构
class CustomAgentState(AgentState):
"""扩展的 Agent 状态,包含业务上下文"""
user_id: str # 用户唯一标识
preferences: dict # 用户偏好(主题、语言等)
visit_count: int # 访问次数
# ============ 定义带状态访问的工具 ============
from langchain.tools import ToolRuntime
from langgraph.types import Command
from langchain.messages import ToolMessage
# 定义工具函数:更新用户偏好
@tool
def update_user_preference(runtime: ToolRuntime, theme: str) -> Command:
"""
更新用户主题偏好,写入短期记忆
ToolRuntime 提供对 state 和 context 的访问能力:
- runtime.state: 当前状态(含自定义字段)
- runtime.context: 调用上下文
- runtime.tool_call_id: 工具调用ID
"""
# 从当前状态获取偏好(如果不存在则初始化)
current_prefs = runtime.state.get("preferences", {})
current_prefs["theme"] = theme
# 返回 Command 对象,指示状态更新
return Command(update={
"preferences": current_prefs,
"messages": [
ToolMessage(
content=f"成功更新主题为: {theme}",
tool_call_id=runtime.tool_call_id
)
]
})
# 定义工具函数:根据用户偏好生成问候
@tool
def greet_user(runtime: ToolRuntime) -> str:
"""根据用户偏好生成个性化问候"""
user_name = runtime.state.get("user_id", "访客")
prefs = runtime.state.get("preferences", {})
theme = prefs.get("theme", "默认")
return f"欢迎回来,{user_name}!当前主题: {theme}"
# ============ 创建带自定义状态的 Agent ============
def demo_custom_state():
print("\n" + "=" * 60)
print("场景 3: 自定义 State 扩展记忆维度")
print("=" * 60)
# 使用内存存储
checkpointer = InMemorySaver()
# 创建 Agent,指定自定义 state_schema
agent = create_agent(
model=model,
tools=[update_user_preference, greet_user],
state_schema=CustomAgentState, # 关键:传入自定义状态类型
checkpointer=checkpointer
)
# 配置线程 ID(用于区分不同用户)
config = {"configurable": {"thread_id": "custom_state_user"}}
# 第一轮:初始化用户信息
result1 = agent.invoke(
{
"messages": [{"role": "user", "content": "设置主题为暗黑模式"}],
"user_id": "user_789", # 自定义字段
"preferences": {"language": "zh-CN"}, # 初始偏好
"visit_count": 1
},
config=config
)
print(f"第一轮: {result1['messages'][-1].content}")
print("-" * 40)
# 第二轮:读取记忆
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "打个招呼"}]},
config=config
)
print(f"第二轮: {result2['messages'][-1].content}")
print("-" * 40)
# 查看完整状态
state = agent.get_state(config)
print("当前记忆状态:")
print(f" 用户ID: {state.values.get('user_id')}")
print(f" 偏好: {state.values.get('preferences')}")
print(f" 消息数: {len(state.values['messages'])}")
# ============ 运行自定义状态示例 ============
if __name__ == "__main__":
demo_custom_state()
| 场景 | TypedDict | Pydantic |
|---|---|---|
| FastAPI请求体 | ❌ 不推荐(需手动验证) | ✅ 最佳选择(原生集成) |
| GraphQL响应 | ✅ 适合(结构固定) | ⚠️ 可但较重 |
| 内部函数参数 | ✅ 轻量且有效 | ❌ 过度设计 |
| CLI工具配置 | ⚠️ 需手动校验 | ✅ 自动验证友好 |
| 数据处理流水线 | ✅ 零开销传递 | ⚠️ 频繁转换有成本 |
| 机器学习特征 | ✅ 快速定义结构 | ❌ 不必要 |
| 微服务DTO | ⚠️ 需结合mypy | ✅ 天然支持序列化 |
| 测试Mock数据 | ✅ 快速创建 | ⚠️ 验证可能碍事 |
记忆核心原则
隔离性:每个用户必须分配唯一 thread_id,避免串话
持久化:生产环境必须使用数据库检查点,支持服务重启和高可用
可控性:自定义 State 和中间件实现业务逻辑与记忆管理的分离
性能:长对话必须启用摘要机制,防止 token 超限和响应延迟
5.4 长期记忆 链接到标题
长期记忆通过与外部向量数据库或键值存储集成来实现。可以在Agent执行的关键节点(如对话结束时)提取关键信息、用户偏好等,并存入长期记忆库,供未来的对话使用。
1. 语义检索与向量数据库 链接到标题
向量数据库是实现长期记忆的核心技术,通过语义相似度搜索实现知识的长期存储和检索。
技术实现:
向量化存储:将对话内容、用户偏好等转换为向量表示
语义检索:基于向量相似度实现智能搜索
多模态支持:支持文本、图像、音频等多种数据类型
高性能查询:支持大规模数据的快速检索
典型实现:
Milvus:开源向量数据库,支持大规模向量检索
Qdrant:高性能向量搜索引擎
Pinecone:云原生向量数据库服务
Chroma: 轻量级向量数据库,可本地持久化
#!pip install langchain-chroma
import os
import uuid
from typing import List
# --- 1. 导入组件 ---
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_chroma import Chroma # 向量数据库
from langchain_core.documents import Document
from langchain.agents import AgentState, create_agent
from langgraph.checkpoint.memory import MemorySaver
# 确保配置了 OPENAI_API_KEY
# os.environ["OPENAI_API_KEY"] = "sk-..."
# ==========================================
# 2. 初始化向量数据库 (长期记忆的物理载体)
# ==========================================
# 在生产环境中,这里应该是连接到 Pinecone, Milvus 或本地持久化的 Chroma
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="agent_long_term_memory",
embedding_function=embeddings,
#persist_directory="./chroma_db" # 如果想存到硬盘,取消注释这一行
)
# ==========================================
# 3. 定义记忆工具 (Agent 的手)
# ==========================================
# 3.1 定义记忆保存工具
# ==========================================
@tool
def save_memory(content: str):
"""
将重要信息保存到长期记忆中。
当你获知用户的喜好、职业、计划或其他长期有效的事实时,调用此工具。
参数:
content (str): 要保存的记忆内容。
"""
print(f"\n[记忆操作] 正在保存记忆: '{content}'")
# 将文本封装为 Document
doc = Document(
page_content=content,
metadata={"source": "user_interaction", "timestamp": "simulated_time"}
)
# 写入向量库
vector_store.add_documents([doc])
return "记忆已成功保存。"
# 3.2 定义记忆搜索工具
# ==========================================
@tool
def search_memory(query: str):
"""
从长期记忆中搜索相关信息。
当你被问及关于用户过去的问题,或者你不确定答案时,使用此工具进行查找。
参数:
query (str): 要搜索的查询语句。
"""
print(f"\n[记忆操作] 正在搜索记忆: '{query}'")
# 执行语义搜索 (k=2 表示只取最相关的2条)
results = vector_store.similarity_search(query, k=2)
if not results:
return "没有找到相关的记忆。"
# 将搜索结果拼接成字符串返回给 Agent
memory_content = "\n".join([f"- {doc.page_content}" for doc in results])
return f"找到以下相关记忆:\n{memory_content}"
# 将工具放入列表
tools = [save_memory, search_memory]
# ==========================================
# 4. 创建 Agent
# ==========================================
# 定义系统提示词:教会 Agent 何时使用记忆工具
SYSTEM_PROMPT = """你是一个拥有长期记忆的私人助手。
你的目标是记住用户的喜好和重要信息,以便提供个性化服务。
1. 如果用户告诉你任何关于他们自己的事实(如名字、喜好、居住地),请务必调用 'save_memory' 工具保存。
2. 如果用户问你一个问题,而答案可能在你之前的记忆中,请先调用 'search_memory' 工具查找。
3. 如果只是闲聊,不需要调用工具。
"""
llm = ChatOpenAI(model="gpt-4o", temperature=0) # 建议使用 GPT-4 或更强的模型以保证工具调用准确率
# 使用 checkpointer 依然是必要的,用于维持当前这一轮对话的上下文
checkpointer = MemorySaver()
# 创建 Agent 应用
agent_app = create_agent(
llm,
tools,
system_prompt=SYSTEM_PROMPT, # 注入系统提示词
checkpointer=checkpointer
)
# ==========================================
# 5. 运行演示
# ==========================================
def run_demo():
# === 场景 A:存入记忆 ===
# 使用一个 thread_id,代表这是今天的对话
config_a = {"configurable": {"thread_id": "session_today"}}
print("--- 场景 A:用户告诉 Agent 喜好 ---")
user_input_1 = "你好,记住我最喜欢的水果是草莓,而且我对花生过敏。"
# 运行 Agent,stream_mode="values"参数,返回每个时间步的中间结果
for chunk in agent_app.stream({"messages": [HumanMessage(content=user_input_1)]}, config=config_a, stream_mode="values"):
# 只打印最后一条机器人的回复
pass
print(f"Agent: {chunk['messages'][-1].content}")
# === 场景 B:模拟遗忘 (开启新线程) ===
# 我们换一个 thread_id,这意味着 Agent 失去了“短期记忆” (MemorySaver 里的东西访问不到了)
# 但是,长期记忆在 VectorStore 里,是可以跨 thread 访问的!
config_b = {"configurable": {"thread_id": "session_tomorrow"}}
print("\n--- 场景 B:第二天 (新的 Session,短期记忆已清空) ---")
user_input_2 = "我想吃点零食,但我忘了我有什么忌口,你能帮我查查吗?"
print(f"User: {user_input_2}")
# 观察控制台输出,你会看到 Agent 自动调用 search_memory
final_response = None
for chunk in agent_app.stream({"messages": [HumanMessage(content=user_input_2)]}, config=config_b, stream_mode="values"):
final_response = chunk['messages'][-1]
print(f"Agent: {final_response.content}")
if __name__ == "__main__":
run_demo()
5.5 跨线程记忆 链接到标题
针对"跨线程记忆(Cross-Thread Memory)“的管理,在 LangChain 1.0 / LangGraph 体系中,这通常被称为"用户级状态(User-Level State)” 或"全局记忆"。
它与前两个问题的区别在于:
短期记忆 (
Checkpointer):只在thread_id(一次会话)内有效。长期记忆 (
VectorStore):存的是模糊的知识片段。跨线程记忆 (BaseStore):存的是结构化的用户档案(User Profile),例如用户的姓名、VIP等级、偏好设置等。无论用户开多少个新聊天窗口(Thread),这些信息都必须存在。
BaseStore结构化存储 链接到标题
BaseStore 是 LangGraph 提供的通用键值存储抽象接口,专为结构化长期记忆设计,核心特性包括:
命名空间(Namespace)机制
采用层次化元组路径组织数据,类似文件系统目录结构:
namespace = ("users", "user_123", "preferences")
# 对应逻辑路径:users/user_123/preferences
核心操作
put(namespace, key, value):存储键值对(支持TTL过期)get(namespace, key):精确检索单个记忆search(namespace, query):语义搜索(需子类支持)delete(namespace, key):删除记忆
import os
from dotenv import load_dotenv
import time
import uuid
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain.agents import create_agent, AgentState
from typing import Annotated
from pydantic import BaseModel, Field
# --- 核心组件:Postgres 持久化检查点 ---
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
from langgraph.store.base import BaseStore
from langgraph.prebuilt import InjectedStore,InjectedState
from psycopg_pool import ConnectionPool
#from langchain_community.storage import MongoDBStore
# 配置 API KEY
load_dotenv(override=True)
# ==========================================
# 1. 数据库配置
# ==========================================
# 对应上面 Docker 启动命令的配置
DB_URI = "postgresql://myuser:123456@localhost:5432/mydatabase"
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# ==========================================
# 2. 定义工具 (Tools)
# ==========================================
@tool
def magic_calculation(a: int, b: int) -> int:
"""进行一次特殊的加法计算"""
return (a + b) * 10
"""
跨线程记忆需要传递 user_id,通过自定义 State 实现
"""
class CrossThreadState(AgentState):
user_id: str # 跨线程记忆的唯一标识
# ============ 定义 Pydantic 模型用于提取用户信息 ===========
class UserInfo(BaseModel):
"""从文本中提取的用户信息"""
user_name: str = Field(description="用户的名字,例如:Alice、Bob、张三等")
additional_info: str = Field(description="关于用户的其他信息,例如职业、兴趣爱好等")
class QueryInfo(BaseModel):
"""从查询文本中提取的信息"""
user_name: str = Field(
description="要查询的用户名字。如果查询中包含'我的'、'我是'等第一人称,请从对话历史中提取用户名;如果没有明确的用户名,返回'all_users'"
)
query_content: str = Field(description="查询的具体内容,例如:职业、兴趣爱好等")
# ============ 定义记忆管理工具(使用 BaseStore)===========
# 注意:store 参数使用 InjectedStore 注解,由 LangGraph 自动注入
# InjectedStore() 标记会让 Pydantic 在生成 JSON Schema 时跳过这个参数
# LLM 不会看到 store 参数,只会看到 user_id 和 info
@tool
def remember_user_info(
info: str,
state: Annotated[dict, InjectedState()],
store: Annotated[BaseStore, InjectedStore()]
) -> str:
"""
将用户信息存入跨线程记忆
重要:此工具会自动从 state 中获取 user_id,并使用 Pydantic 提取用户信息
参数说明:
info: 要记忆的信息(例如:用户的名字、职业、偏好等)
示例:
- remember_user_info("用户名叫 Alice,是一名工程师")
- remember_user_info("我是 Bob,喜欢深度学习")
"""
# 使用 Pydantic 提取用户信息
structured_llm = llm.with_structured_output(UserInfo)
try:
# 从文本中提取结构化信息
extracted_info = structured_llm.invoke(
f"从以下文本中提取用户名和其他信息:{info}"
)
# 优先使用提取的用户名,如果提取失败则使用 state 中的 user_id
extracted_user_name = extracted_info.user_name.lower()
state_user_id = state.get("user_id", "unknown_user")
# 如果提取到的用户名不是 unknown,则使用提取的用户名
if extracted_user_name and extracted_user_name != "unknown":
user_id = extracted_user_name
else:
user_id = state_user_id
full_info = f"{extracted_info.user_name}: {extracted_info.additional_info}"
except Exception as e:
# 如果提取失败,使用 state 中的 user_id
user_id = state.get("user_id", "unknown_user")
full_info = info
# 命名空间设计:(用户ID, 信息类别)
namespace = (user_id, "profile")
# 生成唯一记忆ID
memory_id = str(uuid.uuid4())
# 存储到 BaseStore(自动持久化)
store.put(
namespace,
memory_id,
{
"info": full_info,
"timestamp": "2025-11-25",
"source": "user_input"
}
)
return f"✅ 已将信息存入长期记忆 (用户: {user_id}): {full_info}"
@tool
def recall_user_info(
query: str,
state: Annotated[dict, InjectedState()],
store: Annotated[BaseStore, InjectedStore()]
) -> str:
"""
从跨线程记忆中检索用户信息
重要:此工具会自动从 state 中获取 user_id
参数说明:
query: 查询关键词(用于描述要查找的信息,例如"我的职业"、"我的兴趣"等)
返回:用户的历史信息
"""
# 优先从 state 中获取 user_id
state_user_id = state.get("user_id", None)
# 如果 state 中没有 user_id,尝试使用 Pydantic 从查询中提取
if not state_user_id:
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm = llm.with_structured_output(QueryInfo)
try:
# 从查询文本中提取结构化信息
prompt = f"""从以下查询中提取用户名和查询内容。
查询文本:{query}
注意:
1. 如果查询中包含"我的"、"我是"等第一人称词汇,说明用户在询问自己的信息
2. 如果能从查询中推断出具体的用户名(如 Alice、Bob),请提取该用户名
3. 如果无法确定具体用户,返回 'all_users'
"""
extracted_query = structured_llm.invoke(prompt)
# 如果提取到的是 'all_users',则搜索所有用户
if extracted_query.user_name.lower() in ['all_users', 'current_user', 'unknown']:
user_id = None
else:
user_id = extracted_query.user_name.lower()
except Exception as e:
# 如果提取失败,搜索所有用户
user_id = None
else:
# 使用 state 中的 user_id
user_id = state_user_id
try:
if user_id:
# 使用 namespace_prefix 搜索该用户的所有记忆
namespace_prefix = (user_id,)
memories = store.search(namespace_prefix, limit=20)
else:
# 搜索所有已知用户的记忆
memories = []
# 先尝试获取所有可能的用户
for uid in ['alice', 'bob', 'unknown_user']:
namespace_prefix = (uid,)
user_memories = store.search(namespace_prefix, limit=20)
memories.extend(user_memories)
if not memories:
return f"未找到相关记忆。请先告诉我一些信息,我会记住它们。"
# 格式化返回
results = []
for item in memories:
info = item.value.get('info', '未知信息')
timestamp = item.value.get('timestamp', '未知时间')
results.append(f"- {info} (记录时间: {timestamp})")
return f"找到 {len(results)} 条记忆:\n" + "\n".join(results)
except Exception as e:
return f"检索记忆时出错: {str(e)}"
# ==========================================
# 3. 主程序逻辑
# ==========================================
def run_postgres_agent():
print("--- 正在连接 PostgreSQL 数据库 ---")
# 使用 ConnectionPool 管理数据库连接
# PostgresSaver 需要在这个上下文管理器中运行
with ConnectionPool(conninfo=DB_URI, max_size=20, kwargs={"autocommit": True}) as pool:
# --- A. 初始化 Checkpointer 和 Store ---
checkpointer = PostgresSaver(pool)
store = PostgresStore(pool)
# 注意:第一次运行时需要创建表结构,会检测数据库,如果不存在,会自动创建所需的表结构。
# 生产环境只需运行一次,但在脚本中加上是安全的(幂等操作)。
# checkpointer 会创建 'checkpoints', 'checkpoint_blobs' 等表
# store 会创建 'store' 表
print("🔧 初始化 Checkpointer 表结构...")
checkpointer.setup()
print("✅ Checkpointer 表结构初始化完成")
print("🔧 初始化 Store 表结构...")
store.setup()
print("✅ Store 表结构初始化完成")
# --- B. 创建 Agent ---
# 包含所有工具:计算工具 + 跨线程记忆工具
tools = [magic_calculation, remember_user_info, recall_user_info]
agent = create_agent(
model=llm,
tools=tools,
state_schema=CrossThreadState, # 自定义状态传递 user_id
system_prompt="""
你是一个具备跨线程记忆的智能助手。
你的能力:
1. 使用 remember_user_info 工具将用户的重要信息存入长期记忆(跨会话持久化)
2. 使用 recall_user_info 工具从长期记忆中检索用户信息
3. 使用 magic_calculation 工具进行特殊计算
工作流程:
- 当用户告诉你他的名字、职业、偏好等信息时,主动调用 remember_user_info 存储
- 当用户询问"你还记得我吗"或类似问题时,调用 recall_user_info 检索
- 记忆是跨会话的,即使在新的对话中也能记住用户信息
注意:调用 remember_user_info 和 recall_user_info 时,必须传入 user_id 参数(从 state 中获取)。
""",
store=store, # ✅ 注入 BaseStore 实现跨线程记忆
checkpointer=checkpointer # 注入数据库检查点(单会话记忆)
)
# ==========================================
# 4. 测试场景:跨线程记忆功能
# ==========================================
print("\n" + "="*70)
print("场景 1:用户 Alice 第一次对话(会话 1)")
print("="*70)
# 1. Alice 的第一个会话
thread1_config = {"configurable": {"thread_id": "session_alice_001"}}
print("\n👤 用户 Alice: 你好,我是 Alice,一名 Python 开发工程师,我喜欢深度学习。")
for chunk in agent.stream(
{
"messages": [HumanMessage(content="你好,我是 Alice,一名 Python 开发工程师,我喜欢深度学习。")],
"user_id": "alice" # 传入 user_id
},
config=thread1_config,
stream_mode="values"
):
last_msg = chunk["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"🤖 Agent: {last_msg.content}")
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
for tool_call in last_msg.tool_calls:
print(f" 🔧 [调用工具]: {tool_call['name']}")
print("\n" + "="*70)
print("场景 2:用户 Alice 第二次对话(会话 2 - 不同 thread_id)")
print("="*70)
print("💡 模拟:Alice 关闭浏览器,第二天重新打开,开始新会话")
time.sleep(1)
# 2. Alice 的第二个会话(不同的 thread_id)
thread2_config = {"configurable": {"thread_id": "session_alice_002"}}
print("\n👤 用户 Alice: 你还记得我是谁吗?我的职业是什么?")
for chunk in agent.stream(
{
"messages": [HumanMessage(content="你还记得我是谁吗?我的职业是什么?")],
"user_id": "alice" # ✅ 同样的 user_id
},
config=thread2_config,
stream_mode="values"
):
last_msg = chunk["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"🤖 Agent: {last_msg.content}")
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
for tool_call in last_msg.tool_calls:
print(f" 🔧 [调用工具]: {tool_call['name']}")
print("\n" + "="*70)
print("场景 3:用户 Bob 的对话(不同用户)")
print("="*70)
# 3. Bob 的会话
thread3_config = {"configurable": {"thread_id": "session_bob_001"}}
print("\n👤 用户 Bob: 你好,我是 Bob,一名产品经理,帮我算一下 10 + 20 的特殊结果。")
for chunk in agent.stream(
{
"messages": [HumanMessage(content="你好,我是 Bob,一名产品经理,帮我算一下 10 + 20 的特殊结果。")],
"user_id": "bob" # ✅ 不同的 user_id
},
config=thread3_config,
stream_mode="values"
):
last_msg = chunk["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"🤖 Agent: {last_msg.content}")
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
for tool_call in last_msg.tool_calls:
print(f" 🔧 [调用工具]: {tool_call['name']}")
print("\n" + "="*70)
print("场景 4:Alice 第三次对话(验证记忆隔离)")
print("="*70)
print("💡 验证:Alice 的记忆不会被 Bob 的信息污染")
# 4. Alice 的第三个会话
thread4_config = {"configurable": {"thread_id": "session_alice_003"}}
print("\n👤 用户 Alice: 我的兴趣爱好是什么?")
for chunk in agent.stream(
{
"messages": [HumanMessage(content="我的兴趣爱好是什么?")],
"user_id": "alice"
},
config=thread4_config,
stream_mode="values"
):
last_msg = chunk["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"🤖 Agent: {last_msg.content}")
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
for tool_call in last_msg.tool_calls:
print(f" 🔧 [调用工具]: {tool_call['name']}")
print("\n" + "="*70)
print("✅ 跨线程记忆测试完成!")
print("="*70)
print("\n 测试总结:")
print(" ✅ 场景 1: Alice 首次对话,Agent 自动存储用户信息到 Store")
print(" ✅ 场景 2: Alice 新会话(不同 thread_id),Agent 成功从 Store 检索记忆")
print(" ✅ 场景 3: Bob 的对话,Agent 为 Bob 创建独立的记忆空间")
print(" ✅ 场景 4: Alice 再次对话,记忆未被 Bob 的信息污染")
print("\n💡 关键特性:")
print(" - Checkpointer: 管理单个会话的对话历史(基于 thread_id)")
print(" - Store: 管理跨会话的长期记忆(基于 user_id)")
print(" - 记忆隔离: 不同用户的记忆完全隔离(通过 namespace)")
print(" - 持久化: 所有数据存储在 PostgreSQL,重启程序后依然可用")
print("="*70)
run_postgres_agent()
run_postgres_agent()
!psql -U myuser -d mydatabase -c "SELECT prefix, LEFT(key, 8) as key_prefix, value->>'info' as info FROM store ORDER BY created_at;"
# 测试过程中,如果数据错乱有问题,可以先清空再尝试;但在生成环境中慎重做此操作!!!
!psql -U myuser -d mydatabase -c "TRUNCATE TABLE checkpoints, checkpoint_blobs, checkpoint_writes, store CASCADE;"
| 维度 | BaseStore方案 | 向量数据库方案 |
|---|---|---|
| 依赖导入 | from langgraph.store.memory import InMemoryStore | from langchain.vectorstores import Chroma |
| 存储内容 | 结构化字典/列表(JSON序列化) | 非结构化文本(自动Embedding) |
| 检索方式 | get()精确匹配 + search()简单搜索 | similarity_search()语义相似 |
| 创建Agent | create_agent(llm, tools, system_message) | create_agent(llm, tools, system_message) |
| 工具定义 | 直接操作Python对象 | 需先转为Document再存储 |
| 查询灵活性 | ❌ 必须精确key或有限搜索 | ✅ 自然语言模糊查询 |
| 写入速度 | < 1ms(内存) | 50-200ms(含Embedding) |
| 更新成本 | O(1) 直接覆盖 | O(n) 需重新计算向量 |
第六阶段、 企业最佳组合 链接到标题
6.1 Checkpointer + KV Store组合架构 链接到标题
最佳实践架构如下:
身份标识 (
user_id):在配置中除了传入thread_id,必须传入user_id。双层存储:
会话层:使用
MemorySaver管理当前聊天的上下文。用户层:使用
BaseStore存储跨会话的用户档案。
6.2 记忆生命周期管理 链接到标题
记忆清理策略:
自动过期:设置TTL自动清理过期记忆
手动清理:提供管理接口手动清理无用记忆
压缩归档:对历史记忆进行压缩和归档
6.3 性能优化策略 链接到标题
查询优化:
索引优化:为常用查询字段建立索引
缓存策略:实现多级缓存提高查询性能
批量操作:支持批量读写操作减少I/O开销
第七阶段、 总结与展望 链接到标题
LangChain 1.0框架为Agent开发提供了完整的解决方案,从基础概念到高级特性都进行了系统性的设计。create_agent 有望成为 AI 应用的标准构建块,其地位堪比 React 之于前端开发。短期看,它将推动智能工具市场标准化,实现"工具即插即用";中期看,分布式状态同步与自我优化中间件将使其胜任金融交易、医疗诊断等高并发、低延迟场景;长期看,声明式 Agent 配置与多 Agent 联邦将催生"Agent 调用 Agent"的递归架构,构建起去中心化的 AI 服务网格。最终,开发者只需组合、配置与调优,而复杂推理的编排、优化与执行,将完全托付给这一新一代的智能计算框架。