第一阶段 项目简介 链接到标题
DeepAgents 是一个基于大语言模型(LLM)和 Docker 沙箱环境的企业级智能爬虫开发框架。它能够自动分析网页结构、生成高质量的 Python 爬虫代码、在安全的隔离环境中执行代码,并验证抓取结果。系统的核心优势在于实现了代码生成与执行环境的解耦,利用 Docker 容器确保生成的爬虫代码在隔离环境中运行,既安全又易于依赖管理。
一、 系统架构 链接到标题
一、核心组件 链接到标题
系统采用模块化设计,主要由以下部分组成:
Agent Core (
agent.py): 基于 LangGraph 的智能体编排中心,负责任务规划、工具调度和状态管理。它定义了智能体的思考流程和决策逻辑。Tools (
tools.py): 提供网页抓取、HTML 分析、代码生成等核心能力的工具集。这些工具是 Agent 与外部世界交互的手脚。Sandbox Environment (
docker_backend.py,sandbox.py): 基于 Docker 的安全执行环境。它提供了一个隔离的 Linux 环境来运行生成的 Python 代码,并支持文件系统操作。Configuration (
agent_config.py): 集中化配置管理,确保开发环境与生产环境配置的一致性。CLI Entry (
spider_demo.py): 命令行交互入口,负责组装各个组件并启动用户交互循环。
二、 核心模块详解 (Module Details) 链接到标题
本部分深入解析 DeepAgents 的六大核心文件,详细说明其设计思路、关键实现细节及使用场景。
2.1 全局配置中心 (agent_config.py)
链接到标题
- 核心作用:
作为项目的“控制塔”,集中管理所有环境相关、模型相关和路径相关的常量。确保项目在不同环境(开发/生产)下的行为一致性。
关键配置项:
model_name: 指定后端使用的 LLM (如deepseek-chat)。workspace_dir: 本地工作目录 (默认./spider_workspace),所有的代码生成、日志和数据文件都存储于此。docker_container_id: 最重要的复用参数。设置为具体 ID 或配合逻辑实现容器复用,避免每次运行都重新启动 Docker,节省数秒的启动时间。container_mount_path: 容器内部的挂载点 (默认/workspace),与本地workspace_dir保持同步。
使用场景:
当需要切换 LLM 模型时。
当需要手动指定复用某个正在运行的 Docker 容器进行调试时。
2.2 命令行入口 (spider_demo.py)
链接到标题
- 核心作用:
用户与系统交互的唯一入口。负责参数解析、环境初始化、以及调度模式的选择(全自动 vs 快速管道)。
- 双模式机制 (Dual-Mode Execution):
标准智能体模式 (Standard Mode): 完整的 “规划 -> 分析 -> 编码 -> 调试” 流程。适用于新任务。
快速管道模式 (Fast Pipeline Mode) (
_run_fast_pipeline): 跳过 LLM 规划和编码阶段,直接在 Docker 中运行现有的spider.py,并执行数据清洗。适用于代码已生成,仅需重新运行或调试数据处理的场景。
- 常用命令:
# 1. 标准全流程模式 (默认)
# 适用于新任务,系统会自动规划、生成代码并执行
python spider_demo.py --task "爬取豆瓣Top250" --container-id auto
# 2. 指定容器复用
# 适用于开发调试,复用已启动的容器 (节省启动时间)
python spider_demo.py --task "..." --container-id 5236cf3f3150
# 3. 快速调试模式 (--fast)
# 跳过 LLM 生成,直接在容器中运行现有的 spider.py,并进行数据处理
# 等价于: --use-existing-spider --resume-from run --container-id auto
python spider_demo.py --fast
# 4. 指定脚本运行
# 在快速模式下运行特定的脚本文件 (默认为 spider.py)
python spider_demo.py --fast --spider-relpath "spider_v2.py"
# 5. 仅执行数据清洗
# 跳过爬虫运行,仅对现有的 raw_data.json 进行清洗和验证
# 适用于调整清洗逻辑而不重新抓取
python spider_demo.py --use-existing-spider --resume-from clean
```
### 2.3 智能体编排核心 (`agent.py`)
- **核心作用**:
  基于 LangGraph 构建的“大脑”。定义了 Orchestrator (指挥官) 和 Sub-Agents (专家) 的协作拓扑结构。
- **子智能体架构 (Sub-Agents)**:
- `web_analyzer`: 负责 DOM 分析,输出选择器建议。
- `code_generator`: **最严格的 Agent**。System Prompt 中强制要求 OOP 结构、`@dataclass` 定义、`logging` 配置和 `requests.Session` 使用。
- `debug_agent`: 拥有在沙箱中执行代码并读取错误日志的权限,具备“自我修正”能力 (Max Retries = 3)。
- `data_processor`: 负责数据清洗和质量校验。
- **关键技术**:
- **CompositeBackend**: 混合了 Docker 执行环境和本地文件系统访问权限,让 Agent 既能安全执行代码,又能方便地读写本地文件。
### 2.4 Docker 后端 (`docker_backend.py`)
- **核心作用**:
  与 Docker 通信的底层驱动。实现了容器的生命周期管理和文件流传输。
- **底层实现细节**:
- **流式文件传输**: 使用 `tarfile` 流在内存中打包/解包文件,实现了宿主机与容器间的高效文件同步 (`upload_files`, `download_files`),无需临时文件。
- **执行与捕获**: 封装 `exec_run`,不仅返回 stdout/stderr,还处理了特殊的退出码逻辑。
- **安全与资源限制**:
- `cpu_quota`: 限制 CPU 使用率 (默认 50% ~ 100ms),防止爬虫死循环卡死宿主机。
- `memory_limit`: 限制内存 (默认 1GB),防止内存泄漏。
### 2.5 沙箱工具封装 (`sandbox.py`)
- **核心作用**:
  连接配置层 (`agent_config`) 和底层驱动 (`docker_backend`) 的胶水层,并为 Agent 提供可调用的 LangChain Tool。
- **关键逻辑**:
- **初始化逻辑 (`initialize_docker_backend`)**: 智能判断是 "Attach" 到现有容器还是 "Run" 新容器。如果 `agent_config.docker_container_id` 为 "auto",它会自动管理这一过程。
- **闭包工厂模式**: `create_execute_in_sandbox_tool` 函数通过闭包将 `docker_backend` 实例注入到 Tool 中,使得 Agent 可以直接调用 `execute_in_sandbox(command="...")` 而无需关心底层 Docker 连接。
### 2.6 原子工具集 (`tools.py`)
- **核心作用**:
  提供给 Agent 使用的原子能力 (Atomic Capabilities)。每个函数都被 `@tool` 装饰。
- **关键工具**:
- `fetch_url`: 智能网页抓取。
- `analyze_html_structure`: 使用 BeautifulSoup 分析 DOM 树。
- `generate_spider_code`: 基于 Jinja2 模板生成代码(虽然目前更多依赖 LLM 直接生成,但保留了模板能力)。
- **Context Window 上下文优化 (关键技巧)**:
  在 `fetch_url` 中,系统**不会**直接将几十 KB 的 HTML 源码返回给 LLM(这会瞬间撑爆 Context Window)。
**做法**: 将 HTML 保存为本地文件 `source_page.html`,只返回“文件路径”和“简短的 DOM 预览”。Sub-Agent (如 `web_analyzer`) 读取文件路径进行分析,从而实现了对超长网页的处理能力。
## 三、 运行逻辑与流程
### 一、架构图
<img src="https://typora-photo1220.oss-cn-beijing.aliyuncs.com/DataAnalysis/ZhiJie/20251224004016267.png" width=70%>
1. **环境启动**:
  运行 `spider_demo.py` 时,系统首先检查 Docker 环境。如果指定的容器不存在,它会基于配置的镜像启动一个新容器,并将本地的 `spider_workspace` 目录挂载到容器内的 `/workspace`。
2. **任务接收**:
  用户输入目标(例如:“爬取豆瓣电影 Top250”)。
3. **网页获取 (`fetch_url`) 网页分析子智能体**:
- Agent 识别需求,调用 `fetch_url`。
- 工具下载网页,保存为 `spider_workspace/source_page.html`。
- Agent 获得文件路径,而不是巨大的 HTML 字符串。
4. **结构分析 (`analyze_html_structure`)网页分析子智能体**:
- Agent 调用分析工具读取 `source_page.html`。
- 工具利用 BeautifulSoup 提取页面特征(如 `` 是电影条目)。
5. **代码生成 (`generate_spider_code`)代码生成子智能体**:
- LLM 结合分析结果,编写 `spider.py`。
- 代码中会自动包含对 `source_page.html` 的解析逻辑(开发阶段)或直接请求逻辑(生产阶段)。
6. **沙箱执行 (`execute_spider_code`)Docker沙箱执行子智能体**:
- 生成的 `spider.py` 被保存。
- Agent 指令 Docker 容器运行 `python /workspace/spider.py`。
- 容器内生成的 `data.json` 通过挂载卷直接出现在本地 `spider_workspace/` 目录中。
7. **数据处理 (`process_data`)数据处理子智能体**:
- Agent 调用处理工具读取 `data.json`。
- 工具利用 Json 处理数据(如去除空值、格式化、去重)。
- 处理后的 `data_cleaned.json` 也通过挂载卷直接出现在本地 `spider_workspace/` 目录中。
8. **结果反馈**:
* Agent 读取执行日志和数据文件预览,确认抓取成功后向用户汇报,并进行数据爬取的总结。
**爬取原始HTML文件展示**
<img src="https://typora-photo1220.oss-cn-beijing.aliyuncs.com/DataAnalysis/ZhiJie/20251224004016251.png" width=70%>
**生成爬虫代码展示**
<img src="https://typora-photo1220.oss-cn-beijing.aliyuncs.com/DataAnalysis/ZhiJie/20251224004018190.png" width=70%>
**执行爬虫代码结果展示**
<img src="https://typora-photo1220.oss-cn-beijing.aliyuncs.com/DataAnalysis/ZhiJie/20251224004016234.png" width=70%>
# 第二阶段、 网络爬虫概述
## 一、 什么是网络爬虫?
  **网络爬虫**(Web Crawler),又被称为网页蜘蛛(Web Spider)或网络机器人(Web Robot),是一种按照一定规则,自动抓取万维网信息的程序或脚本。
### 通俗理解
如果把互联网比作一张巨大的**蜘蛛网**,那么爬虫就是一只在网上爬行的**小蜘蛛**。
- **Web (网)**:就是互联网上的一个个网页。
- **Crawl (爬)**:通过网页之间的链接(URL),从一个页面跳到另一个页面。
- **抓取**:当蜘蛛爬到一个网页时,把它看到的内容(文字、图片、视频等)搬运回自己的“仓库”(数据库或本地文件)。
### 核心流程
1. **发送请求 (Request)**:模拟浏览器向服务器发送数据请求(就像在浏览器地址栏输入网址并回车)。
2. **获取响应 (Response)**:服务器返回网页的源代码(HTML, JSON 等)。
3. **解析数据 (Parse)**:从源代码中提取出我们需要的数据(如电影名称、评分、评论)。
4. **存储数据 (Store)**:将提取的数据保存起来(JSON, CSV, 数据库)。
## 二、 爬虫的应用场景 (Application Scenarios)
爬虫技术在各行各业都有广泛应用:
1. **搜索引擎 (Search Engines)**
- Google、百度等通过爬虫抓取全网网页,建立索引,让你能搜到内容。
2. **数据分析与市场调研**
- 抓取电商平台(淘宝、京东)的商品价格、销量、评论,分析竞品或市场趋势。
3. **舆情监控**
- 监控微博、知乎、新闻网站,实时了解公众对某个品牌或事件的看法。
4. **大模型训练 (LLM Training)**
- ChatGPT、DeepSeek 等大模型的训练数据,绝大部分来自于对互联网公开数据的抓取。
5. **聚合平台**
- 比如“去哪儿网”抓取各大航空公司的机票信息,进行比价。
6. **自动化测试**
- 模拟用户操作,测试网站的功能是否正常。
## 三、 Python 爬虫核心工具箱 (Python Ecosystem)
  Python 是爬虫领域的王者语言,拥有极其丰富的生态。以下是常用的库:
### 1. 发送请求 (Requesting)
- **`requests`** (入门必备):
- **特点**:同步库,语法极简,"HTTP for Humans"。
- **用途**:处理简单的 HTTP 请求(GET, POST),适合大多数中小规模爬虫。
- **代码示例**:
```python
#!pip install requests
import requests
# 发送 GET 请求
response = requests.get('https://www.python.org')
print(f"状态码: {response.status_code}")
print(f"网页标题: {response.text[:50]}...")
aiohttp(高阶):特点:异步库,基于
asyncio。用途:高并发抓取。当需要同时爬取成千上万个页面时,它比
requests快得多。代码示例:
#!pip install aiohttp
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
print(f"状态码: {response.status}")
return await response.text()
await fetch('https://www.python.org')
httpx:特点:同时支持同步和异步,支持 HTTP/2。
代码示例:
#!pip install httpx
import httpx
# 同步模式
r = httpx.get('https://www.python.org')
r
# 异步模式
# async with httpx.AsyncClient() as client:
# r = await client.get('https://www.python.org')
2. 数据解析 (Parsing) 链接到标题
BeautifulSoup(bs4):特点:将复杂的 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象。
用途:即便是格式混乱的 HTML 也能解析,API 非常人性化(如
find,find_all)。代码示例:
#!pip install bs4
from bs4 import BeautifulSoup
html_doc = "<html><body><h1>Hello, Spider!</h1></body></html>"
soup = BeautifulSoup(html_doc, 'html.parser')
# 提取 h1 标签文本
print(soup.h1.text) # 输出: Hello, Spider!
lxml:特点:基于 C 语言开发,解析速度极快,支持 XPath 语法。
代码示例:
#!pip install lxml
from lxml import etree
html = etree.HTML("<html><body><h1>Hello, Spider!</h1></body></html>")
# 使用 XPath 提取
result = html.xpath('//h1/text()')
print(result[0]) # 输出: Hello, Spider!
regex(正则表达式):特点:强大的文本匹配工具。
用途:当数据隐藏在非结构化的文本中,或者 HTML 结构极其复杂时,正则往往是“核武器”。
代码示例:
#!pip install re
import re
text = "Email: contact@example.com, Phone: 123-456-7890"
email = re.search(r'[\w\.-]+@[\w\.-]+', text).group()
print(email) # 输出: contact@example.com
3. 浏览器自动化 (Browser Automation) 链接到标题
Selenium/Playwright:特点:可以直接控制真实的浏览器(Chrome, Firefox)。
用途:对付动态渲染的网页(JavaScript 生成的内容)。它可以模拟点击、滚动、输入等用户操作。
代码示例 (Playwright):
!pip install playwright -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装浏览器驱动
!python -m playwright install chromium
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto('https://www.python.org')
print(await page.title())
await browser.close()
# 在 Jupyter 中直接运行
await main()
4. 爬虫框架 (Frameworks) 链接到标题
Scrapy:特点:功能强大的异步爬虫框架,内置了去重、管道存储、中间件等机制。
用途:构建大规模、高性能的工程化爬虫项目。
代码结构示例:
!pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
}
result = QuotesSpider()
result
四、 高阶爬虫技术 (Advanced Techniques) 链接到标题
当面对复杂的反爬虫机制或海量数据需求时,需要掌握更高级的技术:
1. 异步并发 (Asynchronous Concurrency) 链接到标题
利用
async/await协程机制(如aiohttp),在等待网络响应时处理其他任务,将爬取速度提升几十倍。并发逻辑示例:
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ['http://example.com/page1', 'http://example.com/page2']
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
results = await asyncio.gather(*tasks)
print(f"Grabbed {len(results)} pages")
await main()
2. 动态渲染与逆向工程 (JS Reverse Engineering) 链接到标题
Headless Browser: 使用无头浏览器(无界面模式)运行 JS,获取最终渲染的 HTML。
JS 逆向: 直接分析网站的 JavaScript 代码,破解加密参数(如签名 sign, token),直接调用 API 接口。
JS 逆向思路 (伪代码):
# 1. 在浏览器控制台定位加密函数
# function encrypt(data) { return md5(data + "salt"); }
# 2. 使用 Python 复现
import hashlib
def get_sign(data):
salt = "salt"
return hashlib.md5((data + salt).encode()).hexdigest()
3. 反爬虫对抗 (Anti-Crawling Evasion) 链接到标题
IP 代理池: 轮换 IP 地址,防止因请求过频被封禁。
User-Agent 伪装: 模拟不同浏览器、不同设备的身份。
Cookie 池: 维护大量登录态 Cookie。
验证码识别: 使用 OCR 技术或打码平台自动识别验证码。
4. 分布式爬虫 (Distributed Crawling) 链接到标题
- 利用 Redis 等中间件作为任务队列,多台服务器协同工作,抓取亿级数据。
五、 下一代爬虫:DeepAgents 智能化实战 链接到标题
在 DeepAgents 课程案例中,我们展示了 AI 时代爬虫的新形态:Agentic Workflow(智能体工作流)。
1. 传统 vs DeepAgents 链接到标题
传统爬虫:程序员人工分析网页 DOM -> 编写代码 -> 调试 -> 运行。一旦网页改版,代码失效,需要人工重写。
DeepAgents:
自主分析:
WebAnalyzer智能体自动读取 HTML,分析数据结构。自主编码:
CodeGenerator智能体根据分析结果,利用 LLM 自动编写 Python 代码。自主纠错:
DebugAgent运行代码,如果报错,自动读取错误日志并修正代码。
2. 核心技术栈 链接到标题
DeepAgents 项目融合了以下前沿技术:
| 技术模块 | 使用库/工具 | 作用 |
|---|---|---|
| 大模型编排 | LangGraph, LangChain | 构建智能体大脑,管理任务规划、工具调用和状态流转。 |
| 沙箱环境 | Docker, docker-py | 核心亮点。为生成的代码提供隔离的 Linux 运行环境,防止恶意代码破坏主机,同时解决依赖冲突。 |
| 网络请求 | requests, aiohttp | 智能体生成的代码中使用的基础抓取库。 |
| 网页分析 | BeautifulSoup (bs4) | 辅助智能体理解 DOM 树结构。 |
| 终端交互 | Rich | 提供漂亮的命令行交互界面和日志展示。 |
3. 为什么需要 Docker 沙箱? 链接到标题
在 AI 生成代码的场景下,安全性至关重要。DeepAgents 通过 Docker 容器运行生成的爬虫脚本:
隔离性:生成的代码无论如何操作(如删除文件),仅限于容器内部,不会影响宿主机。
环境一致性:容器内预装了
python:3.11-slim和必要的依赖,确保代码在任何机器上都能运行,避免“在我电脑上能跑”的问题。沙箱运行示例(在docker_backend.py文件中都有这部分逻辑):
import docker
# 连接本地 Docker 守护进程
client = docker.from_env()
# 在隔离的容器中运行不可信代码
output = client.containers.run(
image="python:3.11-slim",
command='python -c "import os; print(os.uname().sysname)"',
remove=True # 运行后自动销毁容器
)
print(f"来自沙箱的输出: {output.decode().strip()}")
爬虫技术从简单的脚本(Scripting)进化到了工程化框架(Scrapy),现在正迈向**智能化代理(AI Agents)**的新阶段。
对于初学者:
先掌握
requests+BeautifulSoup,理解 HTTP 协议和 HTML 结构。遇到动态网页学习
Playwright或Selenium。进阶学习
Scrapy框架和反爬策略。最终尝试将 LLM 引入爬虫工作流,像 DeepAgents 一样实现自动化数据获取。
第三阶段、 核心功能运行流程 链接到标题
版本依赖检查 链接到标题
# 没有安装的话,再安装一遍核心的依赖,本地可以测试使用,主要是Docker环境的依赖
!pip install aiohttp bs4 requests docker rich regex
# 检查 Python 版本
!python --version
# 检查已安装的 依赖 包
!pip list
辅助函数定义 链接到标题
import os
import json
import time
import random
import asyncio
import aiohttp
import traceback
import textwrap
import ast
from typing import Dict, Any, List
from collections import Counter
from langchain.tools import tool
from bs4 import BeautifulSoup
import agent_config as config
# ============================================
# 辅助函数
# ============================================
def write_file_sync(filepath: str, content: str):
"""同步写入文件 (用于 asyncio.to_thread)"""
with open(filepath, "w", encoding="utf-8") as f:
f.write(content)
def read_file_sync(filepath: str) -> str:
"""同步读取文件 (用于 asyncio.to_thread)"""
with open(filepath, 'r', encoding='utf-8', errors='ignore') as f:
return f.read()
def get_safe_headers(url: str) -> Dict[str, str]:
"""获取安全的请求头 (包含随机的高质量 Desktop UA)
逻辑说明:
1. 随机选择一个主流浏览器的 User-Agent (Chrome, Edge, Firefox, Safari) 以模拟真实用户。
2. 设置标准的 Accept, Accept-Language 等头部信息。
3. 特别注意 Accept-Encoding 包含 gzip, deflate 以支持压缩,但不包含 br (Brotli) 以免如果没有相应库导致解压失败。
"""
pc_user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/20100101 Firefox/123.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.3 Safari/605.1.15"
]
return {
'User-Agent': random.choice(pc_user_agents),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Referer': url,
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
Docker 容器初始化 链接到标题
from sandbox import create_execute_in_sandbox_tool, DockerBackend,initialize_docker_backend
from deepagents.backends import CompositeBackend
from deepagents.backends.filesystem import FilesystemBackend
import docker_backend
# 实例化Docker沙箱执行工具
sandbox_tool = create_execute_in_sandbox_tool(docker_backend)
# 实例化文件系统后端,用于挂载工作目录到容器
fs_backend = FilesystemBackend(root_dir=config.workspace_dir, virtual_mode=True)
# 实现路由,将容器挂载路径与文件系统后端关联
routes = {config.container_mount_path: fs_backend}
# 初始化 Docker 后端,指定容器 ID 并启用文件持久化
docker = initialize_docker_backend(requested_container_id=config.docker_container_id,persist_runtime_files=True)
# 配置 CompositeBackend,将默认 DockerBackend 与文件系统后端合并,确保容器内路径与挂载路径一致
backend = CompositeBackend(default=docker, routes=routes)
1.WebAnalyzer 子智能体 链接到标题
核心职责: 网站分析专家。负责访问目标 URL,深度分析 HTML DOM 结构,识别列表页、详情页特征及分页机制。
核心工具:
fetch_url: 获取网页内容并持久化为文件(防止 Context Window 溢出)。analyze_html_structure: 提取 Tag 分布、识别容器 Class、采样链接和图片。detect_anti_scraping: 检测 Cloudflare/Captcha 等反爬机制。
运行周期: 任务启动后的第一步。
关键产出: 包含 CSS/XPath 选择器建议、数据提取规则和反爬策略的 JSON 分析报告。
# ============================================
# WebAnalyzer 工具
# ============================================
import aiohttp
@tool
async def fetch_url(url: str, use_selenium: bool = False) -> Dict[str, Any]:
"""获取网页内容
思路梳理:
1. **请求准备**: 生成随机 User-Agent 和安全请求头,防止被轻易识别为爬虫。
2. **发送请求**: 使用 aiohttp 异步发送 GET 请求,设置 15秒超时。
3. **处理响应**:
- 检查是否发生了重定向。
- 检查 HTTP 状态码,如果是 4xx/5xx 则抛出异常。
4. **内容解码**: 尝试自动解码,如果失败 (UnicodeDecodeError) 则回退到 gbk 编码 (常见于中文老网站)。
5. **文件持久化**: 将获取到的完整 HTML 内容保存到本地文件 (source_page.html),供后续分析工具读取,避免大文本在 Agent 上下文中传递导致 Token 溢出。
6. **返回结果**: 返回预览信息、文件路径和状态码。
Args:
url: 目标网址
use_selenium: 是否使用 Selenium (用于动态网页)
Returns:
{"html_preview": "...", "html_file": "path/to/file", "status_code": 200, "success": True}
"""
try:
print(f"🌍 [fetch_url] 正在请求: {url}")
# 1. 获取伪装的请求头
headers = get_safe_headers(url)
async with aiohttp.ClientSession() as session:
# 2. 发起异步 GET 请求
async with session.get(url, headers=headers, timeout=15) as response:
final_url = str(response.url)
if final_url != url:
print(f"⚠️ [fetch_url] 发生重定向: {url} -> {final_url}")
else:
print(f"✅ [fetch_url] 请求成功: {final_url} (Status: {response.status})")
if response.status >= 400:
response.raise_for_status()
print(f"⬇️ [fetch_url] 正在下载响应内容...")
# 3. 获取并解码文本内容
try:
text = await response.text()
except UnicodeDecodeError:
# 备用解码方案:针对 GBK/GB2312 编码的网站
text = await response.text(encoding='gbk', errors='ignore')
print(f"✅ [fetch_url] 内容下载完成 ({len(text)} 字符)")
# 4. 保存到文件 (关键步骤:避免 Context Window 爆炸)
filename = "source_page.html"
filepath = os.path.join(config.workspace_dir, filename)
print(f"💾 [fetch_url] 正在保存文件: {filepath}")
await asyncio.to_thread(write_file_sync, filepath, text)
print(f"✅ [fetch_url] 文件保存完成")
# 5. 构造返回结果
return {
"html_preview": text[:1000] + "... (完整内容已保存到文件)",
"html_file": filepath,
"status_code": response.status,
"url": final_url,
"encoding": response.get_encoding(),
"success": True,
"error": None
}
except Exception as e:
return {
"html_preview": "",
"html_file": "",
"status_code": 0,
"url": url,
"success": False,
"error": str(e)
}
# 测试 fetch_url 工具
response = await fetch_url.ainvoke("https://movie.douban.com/")
print(response)
response["html_file"]
@tool
async def analyze_html_structure(html: str = "", html_file: str = "", url: str = "") -> Dict[str, Any]:
"""分析 HTML 结构,识别数据元素
思路梳理:
1. **读取内容**: 优先从文件读取 HTML 内容 (因为 fetch_url 会保存文件),如果未提供文件则使用传入的 html 字符串。
2. **解析 DOM**: 使用 BeautifulSoup (lxml 解析器) 解析 HTML。
3. **基础信息提取**: 提取网页标题、统计标签分布 (Tag Distribution) 以了解页面复杂度。
4. **容器识别 (关键)**:
- 扫描常见的容器标签 (div, article, section, li)。
- 提取其 class 属性和文本预览,帮助 LLM 识别列表项 (List Items) 的特征。
5. **样本提取**: 提取部分链接 (a) 和图片 (img) 作为样本,供 LLM 分析 URL 模式。
6. **分页检测**: 简单的关键词匹配 (next, 下一页) 来推测是否存在分页机制。
7. **返回 JSON**: 将所有分析结果打包成 JSON 格式返回给 LLM。
Args:
html: HTML 内容 (可选)
html_file: HTML 文件路径 (可选,推荐)
url: 原始 URL(可选)
Returns:
结构化的分析结果
"""
try:
content = html
# 1. 优先读取文件
if html_file and os.path.exists(html_file):
with open(html_file, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
if not content:
return {"success": False, "error": "No HTML content provided"}
# 2. 初始化 BeautifulSoup
soup = BeautifulSoup(content, 'lxml')
title = soup.title.string if soup.title else ""
# 3. 统计标签分布
all_tags = [tag.name for tag in soup.find_all()]
tag_counter = Counter(all_tags)
# 4. 识别通用容器 (寻找列表项模式)
common_containers = []
for tag in ['div', 'article', 'section', 'li']:
elements = soup.find_all(tag, class_=True)
for elem in elements[:5]: # 仅取前5个样本
classes = ' '.join(elem.get('class', []))
if classes:
common_containers.append({
'tag': tag,
'class': classes,
'text_preview': elem.get_text()[:50].strip()
})
# 5. 提取链接样本
links = []
for a in soup.find_all('a', href=True)[:10]:
links.append({
'href': a['href'],
'text': a.get_text().strip()[:30]
})
# 6. 提取图片样本
images = []
for img in soup.find_all('img', src=True)[:10]:
images.append({
'src': img['src'],
'alt': img.get('alt', '')[:30]
})
# 7. 组装分析报告
analysis = json.dumps({
"title": title,
"url": url,
"total_tags": len(all_tags),
"tag_distribution": dict(tag_counter.most_common(10)),
"links_count": len(soup.find_all('a')),
"images_count": len(soup.find_all('img')),
"common_containers": common_containers[:10],
"sample_links": links,
"sample_images": images,
"has_pagination": bool(soup.find_all(['a', 'button'], string=lambda t: t and ('next' in t.lower() or '下一页' in t))),
"success": True
}
)
return analysis
except Exception as e:
return json.dumps({
"success": False,
"error": str(e),
"traceback": traceback.format_exc()
})
result_json = await analyze_html_structure.ainvoke({
"html_file": response["html_file"],
"url": response["url"]
})
json.loads(result_json)
@tool
async def detect_anti_scraping(url: str, html: str = "", html_file: str = "") -> Dict[str, Any]:
"""检测反爬虫机制
思路梳理:
1. **加载内容**: 同样优先从文件读取 HTML。
2. **关键词匹配**:
- 检查是否包含 "cloudflare" -> 可能有 5秒盾或 WAF。
- 检查 "captcha", "recaptcha", "验证码" -> 存在人机验证。
3. **启发式检测**:
- 如果页面包含 script 标签但文本内容极少 (<500字符) -> 可能是纯 JS 渲染页面 (SPA),需要 Selenium/Playwright。
4. **生成建议**: 根据检测结果提供相应的反爬策略建议 (如使用 cloudscraper, 增加延迟, 切换 User-Agent)。
Args:
url: 目标网址
html: HTML 内容(可选)
html_file: HTML 文件路径(可选,推荐)
Returns:
反爬虫检测结果和建议
"""
try:
content = html
if html_file and os.path.exists(html_file):
with open(html_file, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
# 定义建议列表
recommendations = []
# 定义检测到的反爬机制列表
detected_mechanisms = []
if content:
soup = BeautifulSoup(content, 'lxml')
# 检测 Cloudflare
if 'cloudflare' in content.lower():
detected_mechanisms.append("Cloudflare")
recommendations.append("使用 cloudscraper 库")
# 检测验证码
if any(keyword in content.lower() for keyword in ['captcha', 'recaptcha', '验证码']):
detected_mechanisms.append("CAPTCHA")
recommendations.append("需要人工验证或使用验证码识别服务")
# 检测 JS 渲染 (内容过短且有大量脚本)
if soup.find_all('script') and len(soup.get_text().strip()) < 500:
detected_mechanisms.append("JavaScript Rendering")
recommendations.append("使用 Selenium 或 Playwright")
# 默认建议
if not recommendations:
recommendations = [
"添加随机延迟 (1-3秒)",
"使用随机 User-Agent",
"设置合理的请求头"
]
return {
"url": url,
"detected_mechanisms": detected_mechanisms,
"has_anti_scraping": len(detected_mechanisms) > 0,
"recommendations": recommendations,
"success": True
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
# 调用检测反爬虫机制
# 会报错 TypeError: BaseTool.invoke() missing 1 required positional argument: 'input'
# detect_anti_scraping.invoke(url="https://movie.douban.com/",html=response["html"])
# 当工具需要多个参数时,建议使用字典格式调用
result = await detect_anti_scraping.ainvoke({
# 使用小鹅通网址测试
#"url": "https://study.xiaoe-tech.com/t_l/learnIndex?type=wx#/muti_index",
"url":"https://movie.douban.com/",
"html_file": response["html_file"]
})
result
from deepagents import create_deep_agent
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import BaseMessage, ToolMessage
from dotenv import load_dotenv
load_dotenv()
# 初始化 DeepSeek 模型
llm = ChatDeepSeek(model="deepseek-chat",temperature=0)
# 定义系统提示
prompt = """
你是网站结构分析专家。
任务:分析目标网站的 HTML 结构,识别数据元素。
注意:
- 使用 fetch_url 获取网页,它会保存为文件并返回 html_file 路径
- 调用 analyze_html_structure 和 detect_anti_scraping 时,必须传入 fetch_url 返回的 html_file 参数,而不是 html 内容
- 严禁在工具输出中包含完整的 HTML 内容,以防止上下文溢出
- 只返回关键信息(选择器、数据模式)
"""
# 创建智能体
agent = create_deep_agent(
model=llm,
tools=[fetch_url, analyze_html_structure, detect_anti_scraping],
backend=backend,
system_prompt=prompt
)
task = "分析 https://movie.douban.com/ 这个网站,如果本地已经有 source_page.html 文件,就直接分析这个文件,让大模型返回分析的结果即可"
step = 0
print("\n开始流式输出...")
try:
async for event in agent.astream({"messages": [("user", task)]}):
for node_name, node_data in event.items():
# debug: print(f"DEBUG: Node: {node_name}")
if not node_data: continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
msgs = node_data["messages"]
if hasattr(msgs, "value"):
msgs = msgs.value
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
# 1. 打印 Agent 的思考 (AIMessage with tool_calls)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}] Agent 决定调用工具 (Node: {node_name}):")
for tc in msg.tool_calls:
name = tc['name']
args = tc['args']
print(f" >>> 工具: {name}")
if name == "read_file":
offset = args.get('offset', 0)
limit = args.get('limit', 'Default')
path_val = args.get('path') or args.get('file_path')
print(f" >>> 参数: path='{path_val}', offset={offset}, limit={limit}")
print(f" (说明: 正在读取从第 {offset} 行开始的 {limit} 行数据)")
else:
print(f" >>> 参数: {args}")
# 2. 打印工具的输出 (ToolMessage)
elif isinstance(msg, ToolMessage):
content = msg.content
line_count = len(content.splitlines())
preview = content[:100].replace('\n', ' ') + "..."
print(f"\n[Tool Output] (Node: {node_name}) 读取了 {line_count} 行数据")
print(f" 内容预览: {preview}")
# 3. 打印 Agent 的最终回复 (AIMessage without tool_calls)
elif isinstance(msg, BaseMessage) and msg.type == "ai" and msg.content:
print(f"\n[Agent 最终回复] (Node: {node_name}):")
print("-" * 40)
print(msg.content)
print("-" * 40)
except KeyboardInterrupt:
print("\n[bold yellow]用户中断任务[/bold yellow]")
except Exception as e:
print(f"\n[bold red]❌ 发生错误: {e}[/bold red]")
2.CodeGenerator 子智能体 链接到标题
核心职责: 资深 Python 架构师。基于分析报告编写生产级爬虫代码。
核心工具:
save_spider_code: 保存代码文件。validate_code_syntax: AST 语法检查。
运行周期: 在分析完成后执行。
关键产出: 符合 OOP 规范、包含
logging/requests.Session/@dataclass的spider.py源文件。严格规范: 禁止脚本式编程,强制要求容错处理(
try-except)和标准化数据存储接口。
# ============================================
# CodeGenerator 工具
# ============================================
@tool
async def validate_code_syntax(code: str) -> Dict[str, Any]:
"""验证 Python 代码语法
思路梳理:
1. 使用 Python 内置的 `ast.parse` 解析代码。
2. 如果抛出 `SyntaxError`,捕获异常并返回具体的行号和错误信息。
3. 如果没有异常,则认为语法有效。
Args:
code: Python 代码字符串
Returns:
验证结果
"""
try:
cleaned_code = textwrap.dedent(code).strip()
ast.parse(cleaned_code)
return {
"valid": True,
"errors": [],
"message": "代码语法正确"
}
except SyntaxError as e:
return {
"valid": False,
"errors": [{
"line": e.lineno,
"message": e.msg,
"text": e.text
}],
"message": f"语法错误: {e.msg}"
}
except Exception as e:
return {
"valid": False,
"errors": [str(e)],
"message": f"验证失败: {str(e)}"
}
result_code = await validate_code_syntax.ainvoke({
"code":"""
def main():
target_url = "target_url"
data = scrape_data(target_url)
if data:
with open("scraped_data.json", 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("数据已保存")
if __name__ == "__main__":
main()"""
})
print(result_code)
@tool
async def save_spider_code(code: str, filename: str = "spider.py") -> str:
"""保存爬虫代码到文件
思路梳理:
1. 去除代码前后缩进和空白。
2. 确保工作目录存在。
3. 将代码写入指定文件 (默认 utf-8 编码)。
Args:
code: 完整的 Python 代码
filename: 文件名 (默认 spider.py)
Returns:
保存结果信息
"""
try:
final_code = textwrap.dedent(code).strip()
file_path = os.path.join(config.workspace_dir, filename)
os.makedirs(config.workspace_dir, exist_ok=True)
with open(file_path, "w", encoding="utf-8") as f:
f.write(final_code)
return f"✅ 代码已成功保存到: {file_path}"
except Exception as e:
return f"❌ 保存代码失败: {str(e)}"
await save_spider_code.ainvoke({
"code":"""
def main():
target_url = "target_url"
data = scrape_data(target_url)
if data:
with open("scraped_data.json", 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("数据已保存")
if __name__ == "__main__":
main()"""
})
from deepagents import create_deep_agent
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import BaseMessage, ToolMessage
from dotenv import load_dotenv
load_dotenv(override=True)
# 初始化 DeepSeek 模型
llm = ChatDeepSeek(model="deepseek-chat",temperature=0)
# 定义系统提示
prompt = """你是 Python 爬虫架构师。
任务:根据分析结果生成**企业级、高可用、高鲁棒性**的 Python 爬虫代码。
参考标准:代码质量需达到 `spider_test.py` 的水平,逻辑严密,提取字段丰富。
核心开发规范 (Strict Guidelines):
1. **OOP 架构设计**:
- 必须封装为 `Spider` 类 (如 `MyWebsiteSpider`)。
- 职责清晰分离:`__init__` (配置), `fetch_page` (请求), `parse_*` (解析), `save_to_json` (存储)。
- 入口函数 `run()` 负责调度全流程。
2. **高级数据提取策略 (Critical)**:
- **优先利用 DOM 属性**: 现代网页常将结构化数据隐藏在标签属性中 (如 `data-title`, `data-rate`, `data-actors`, `data-id`)。**必须优先检查并提取这些属性**,比解析文本更准确!
- **多区域解析**: 能够识别页面中的不同板块 (如"正在热映", "口碑榜", "热门影评"),并分别编写独立的解析方法 (e.g., `parse_screening`, `parse_ranking`)。
- **防御性提取**: 所有的 `find/find_all` 和属性获取必须包含判空逻辑 (`if elem: ...`)。
3. **丰富的数据模型 (@dataclass)**:
- 使用 `@dataclass` 定义强类型数据模型 (如 `MovieData`, `ReviewData`)。
- 字段应尽可能全面 (不仅是标题/链接,还要包含评分、导演、演员、时长、地区、发布日期等)。
- 字段类型必须准确 (`Optional[float]`, `List[str]`)。
4. **生产级健壮性**:
- **网络层**: 使用 `requests.Session()`,配置 `User-Agent` 池,**Accept-Encoding 严禁包含 'br'** (只用 gzip, deflate)。
- **容错层**: 关键解析循环 (`for item in items`) 内部必须有 `try-except`,确保**单条数据解析失败不会导致整个程序崩溃**。
- **日志层**: 配置完整的 `logging` (Console + File),记录关键步骤和错误堆栈。
5. **标准化交付**:
- 必须包含 `if __name__ == "__main__":` 和 `main()` 函数。
- `save_to_json` 方法需支持 `ensure_ascii=False` 和 `datetime` 序列化。
注意:
- 编写完整的代码。
- 必须使用 `save_spider_code` 工具将编写好的代码保存到文件。
- 不要只在对话中输出代码,必须调用`save_spider_code`工具保存!
- 只返回文件路径。"""
# 创建智能体
code_agent = create_deep_agent(
model=llm,
tools=[save_spider_code, validate_code_syntax],
backend=backend, # 只传入了Filesystem的文件系统
system_prompt=prompt
)
task = """请根据本地文件 HTML 代码 ./spider_workspace/source_page.html,
生成一个 Python 爬虫代码,这个是https://movie.douban.com/ 这个网站的正在热映电影的爬虫,
请必须将生成后的代码文件输出到 ./spider_workspace/spider.py 路径下
"""
step = 0
print("\n开始流式输出...")
try:
async for event in code_agent.astream({"messages": [("user", task)]}):
for node_name, node_data in event.items():
# debug: print(f"DEBUG: Node: {node_name}")
if not node_data: continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
msgs = node_data["messages"]
if hasattr(msgs, "value"):
msgs = msgs.value
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
# 1. 打印 Agent 的思考 (AIMessage with tool_calls)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}] Agent 决定调用工具 (Node: {node_name}):")
for tc in msg.tool_calls:
name = tc['name']
args = tc['args']
print(f" >>> 工具: {name}")
if name == "read_file":
offset = args.get('offset', 0)
limit = args.get('limit', 'Default')
path_val = args.get('path') or args.get('file_path')
print(f" >>> 参数: path='{path_val}', offset={offset}, limit={limit}")
print(f" (说明: 正在读取从第 {offset} 行开始的 {limit} 行数据)")
else:
print(f" >>> 参数: {args}")
# 2. 打印工具的输出 (ToolMessage)
elif isinstance(msg, ToolMessage):
content = msg.content
line_count = len(content.splitlines())
preview = content[:100].replace('\n', ' ') + "..."
print(f"\n[Tool Output] (Node: {node_name}) 读取了 {line_count} 行数据")
print(f" 内容预览: {preview}")
# 3. 打印 Agent 的最终回复 (AIMessage without tool_calls)
elif isinstance(msg, BaseMessage) and msg.type == "ai" and msg.content:
print(f"\n[Agent 最终回复] (Node: {node_name}):")
print("-" * 40)
print(msg.content)
print("-" * 40)
except KeyboardInterrupt:
print("\n[bold yellow]用户中断任务[/bold yellow]")
except Exception as e:
print(f"\n[bold red]❌ 发生错误: {e}[/bold red]")
3.DebugAgent 工具 链接到标题
核心职责: 沙箱测试员。在安全的 Docker 环境中运行代码,并具备自我修复能力。
核心工具:
execute_in_sandbox: 调用 Docker 容器执行 Shell 命令。parse_error: 智能分析 Traceback,区分网络/解析/权限错误并提供修复建议。
运行周期: 代码生成后执行。若失败,会自动进入 “运行 -> 报错 -> 分析 -> 修复” 的闭环(Max Retries=3)。
关键产出:
scraped_data.json(原始数据) 和spider.log(执行日志)。
# ============================================
# DebugAgent 工具
# ============================================
@tool
async def parse_error(error_message: str, code: str = "") -> Dict[str, Any]:
"""分析错误信息,提供修复建议
思路梳理:
1. **错误归类**: 根据错误信息中的关键词 (case-insensitive) 将错误归类。
- NetworkError: connection, timeout, network
- ParseError: parse, beautifulsoup, lxml
- PermissionError: 403, forbidden, 401
- NotFoundError: 404
- EncodingError: encode, decode, unicode
- ImportError: import, module
2. **生成建议**: 针对每一类错误,提供预定义的修复建议列表 (如增加超时、更换 UA、检查选择器)。
3. **返回结构化数据**: 供 Agent 决策使用。
Args:
error_message: 错误信息
code: 出错的代码(可选)
Returns:
错误分析和修复建议
"""
error_lower = error_message.lower()
error_type = "Unknown"
cause = ""
suggestions = []
# 1. 网络类错误
if any(keyword in error_lower for keyword in ['connection', 'timeout', 'network']):
error_type = "NetworkError"
cause = "网络连接问题"
suggestions = [
"增加超时时间 (timeout=30)",
"添加重试逻辑",
"检查网络连接",
"使用代理"
]
# 2. 解析类错误
elif any(keyword in error_lower for keyword in ['parse', 'beautifulsoup', 'lxml']):
error_type = "ParseError"
cause = "HTML 解析失败"
suggestions = [
"检查 HTML 内容是否完整",
"尝试使用不同的解析器 (html.parser/lxml)",
"检查选择器是否正确"
]
# 3. 权限类错误 (反爬虫)
elif any(keyword in error_lower for keyword in ['403', 'forbidden', '401', 'unauthorized']):
error_type = "PermissionError"
cause = "访问被拒绝"
suggestions = [
"添加或更换 User-Agent",
"添加 Cookie 或认证信息",
"降低请求频率",
"使用代理 IP"
]
# 4. 资源不存在
elif '404' in error_lower:
error_type = "NotFoundError"
cause = "页面不存在"
suggestions = [
"检查 URL 是否正确",
"检查页面是否已被删除或移动"
]
# 5. 编码错误
elif any(keyword in error_lower for keyword in ['encode', 'decode', 'unicode']):
error_type = "EncodingError"
cause = "字符编码问题"
suggestions = [
"指定正确的编码 (utf-8/gbk)",
"使用 errors='ignore' 忽略错误字符"
]
# 6. 依赖错误
elif 'import' in error_lower or 'module' in error_lower:
error_type = "ImportError"
cause = "模块导入失败"
suggestions = [
"安装缺失的依赖包",
"检查包名是否正确"
]
else:
suggestions = [
"检查代码逻辑",
"添加异常处理",
"查看完整的错误堆栈"
]
return {
"error_type": error_type,
"cause": cause,
"suggestions": suggestions,
"original_error": error_message[:500]
}
await parse_error.ainvoke({
"error_message": "import",
"code": """
def main():
target_url = "target_url"
data = scrape_data(target_url)
if data:
with open("scraped_data.json", 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("数据已保存")
if __name__ == "__main__":
main()"""
})
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import BaseMessage, ToolMessage
from deepagents import create_deep_agent
# 初始化 DeepSeek 模型
llm = ChatDeepSeek(model="deepseek-chat",temperature=0)
# 定义系统提示
prompt = """
你是代码调试专家。
任务:在 Docker 沙箱中执行代码并调试。
你可以使用 `execute_command` 工具运行 Shell 命令 (如 `ls -la`, `cat spider.log`) 来检查环境或查看日志。
不要尝试使用不存在的 `ls` 工具。
可以执行以下步骤:
1. 运行 'cat /etc/os-release' 查看容器操作系统。
2. 运行 'python --version' 确认 Python 环境。
3. 运行 ls 来查看当前目录下的文件。
注意:
- 工具返回的是简化输出
- 完整日志已保存到文件
- 最多重试 3 次
- 不要使用复杂的组合shell命令!
"""
# 创建智能体
docker_agent = create_deep_agent(
model=llm,
backend=backend,
tools=[sandbox_tool, parse_error],
system_prompt=prompt
)
task = """任务要求: │
│ 1. 首先检查是否存在爬虫代码文件 `/spider_workspace/spider.py` │
│ 2. 在安全的Docker沙箱中运行爬虫脚本 │
│ 3. 如果报错,自动分析错误日志并尝试修改代码重试(最多3次) │ │
│ │
│ 期望产出: │
│ 1. 爬取到的原始数据文件(如 `spider_scraped_data.json`) │
│ 2. 执行日志 │
│ 3. 如果代码需要修改,请提供修改后的代码文件 │
│ │
│ 请确保爬虫代码符合以下规范: │
│ - 面向对象的Spider类 │
│ - 使用@dataclass定义数据模型 │
│ - 完整的logging配置 │
│ - 随机延迟1-3秒 │
│ - 防御性编程 │
│ - 标准化JSON输出 """
step = 0
print("\n开始流式输出...")
try:
async for event in docker_agent.astream({"messages": [("user", task)]}):
for node_name, node_data in event.items():
# debug: print(f"DEBUG: Node: {node_name}")
if not node_data: continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
msgs = node_data["messages"]
if hasattr(msgs, "value"):
msgs = msgs.value
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
# 1. 打印 Agent 的思考 (AIMessage with tool_calls)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}] Agent 决定调用工具 (Node: {node_name}):")
for tc in msg.tool_calls:
name = tc['name']
args = tc['args']
print(f" >>> 工具: {name}")
if name == "read_file":
offset = args.get('offset', 0)
limit = args.get('limit', 'Default')
path_val = args.get('path') or args.get('file_path')
print(f" >>> 参数: path='{path_val}', offset={offset}, limit={limit}")
print(f" (说明: 正在读取从第 {offset} 行开始的 {limit} 行数据)")
else:
print(f" >>> 参数: {args}")
# 2. 打印工具的输出 (ToolMessage)
elif isinstance(msg, ToolMessage):
content = msg.content
line_count = len(content.splitlines())
preview = content[:100].replace('\n', ' ') + "..."
print(f"\n[Tool Output] (Node: {node_name}) 读取了 {line_count} 行数据")
print(f" 内容预览: {preview}")
# 3. 打印 Agent 的最终回复 (AIMessage without tool_calls)
elif isinstance(msg, BaseMessage) and msg.type == "ai" and msg.content:
print(f"\n[Agent 最终回复] (Node: {node_name}):")
print("-" * 40)
print(msg.content)
print("-" * 40)
except KeyboardInterrupt:
print("\n用户中断任务")
except Exception as e:
print(f"\n❌ 发生错误: {e}")
4.DataProcessor 工具 链接到标题
核心职责: 数据质检专家。对原始数据进行格式化、去噪和完整性验证。
核心工具:
clean_data: 去除空字段、去重、标准化格式。validate_data: 校验必填字段(如 Title, URL),生成质量报告。
运行周期: 爬虫成功执行并产出数据后。
关键产出:
cleaned_data.json(最终交付数据) 和数据质量统计报告。关键技术:
CompositeBackend: 混合了 Docker 执行环境和本地文件系统访问权限,让 Agent 既能安全执行代码,又能方便地读写本地文件。
# ============================================
# DataProcessor 工具
# ============================================
@tool
async def clean_data(raw_data: str) -> str:
"""清洗数据:去除空值、格式化、去重
思路梳理:
1. **数据加载**: 支持传入 JSON 字符串或文件路径。如果传入的是文件路径,先尝试读取文件。
2. **标准化**: 将数据统一转换为列表格式。
3. **去重与清洗**:
- 遍历每条数据。
- 移除值为空的字段 (None, "", [], {})。
- 使用 JSON 字符串序列化作为去重键 (Seen Set)。
4. **结果保存**: 将清洗后的数据保存到 `cleaned_data.json`。
Args:
raw_data: 原始数据(JSON字符串 或 文件路径)
Returns:
清洗后的数据(JSON字符串)
"""
try:
# 1. 加载数据
if isinstance(raw_data, str):
if os.path.exists(raw_data) and (raw_data.endswith('.json') or os.path.isfile(raw_data)):
try:
with open(raw_data, 'r', encoding='utf-8') as f:
data = json.load(f)
except:
data = json.loads(raw_data)
else:
data = json.loads(raw_data)
else:
data = raw_data
# 2. 统一格式
if not isinstance(data, list):
data = [data]
cleaned = []
seen = set()
# 3. 清洗循环
for item in data:
if not item:
continue
# 移除空字段
cleaned_item = {k: v for k, v in item.items() if v}
# 去重
item_str = json.dumps(cleaned_item, sort_keys=True)
if item_str not in seen:
seen.add(item_str)
cleaned.append(cleaned_item)
result_json = json.dumps(cleaned, ensure_ascii=False, indent=2)
# 4. 保存结果
try:
os.makedirs(config.workspace_dir, exist_ok=True)
with open(os.path.join(config.workspace_dir, "cleaned_data.json"), "w", encoding="utf-8") as f:
f.write(result_json)
except Exception as e:
print(f"⚠️ 保存清洗数据失败: {e}")
return result_json
except Exception as e:
return json.dumps({"error": str(e)})
await clean_data.ainvoke({
"raw_data": """
[
{
"text": "阿凡达:火与...",
"url": "https://movie.douban.com/subject/5348089/?from=showing"
},
{
"text": "疯狂动物城2...",
"url": "https://movie.douban.com/subject/26817136/?from=showing"
},
{
"text": "得闲谨制",
"url": "https://movie.douban.com/subject/26671336/?from=showing"
}
]
"""
})
@tool
async def validate_data(data: str, required_fields: List[str] = None) -> Dict[str, Any]:
"""验证数据完整性
思路梳理:
1. **数据准备**: 解析输入的 JSON 数据。
2. **规则校验**: 如果指定了 `required_fields`,则遍历所有记录,检查这些字段是否存在且非空。
3. **统计问题**: 记录验证失败的记录索引和缺失字段。
4. **返回报告**: 返回验证是否通过 (valid),以及详细的统计信息 (总数、有效数、无效数、问题样本)。
Args:
data: 数据(JSON字符串)
required_fields: 在数据中必须包含的字段列表,判断该字段是否为空
Returns:
验证结果
"""
try:
if isinstance(data, str):
data_list = json.loads(data)
else:
data_list = data
if not isinstance(data_list, list):
data_list = [data_list]
total_records = len(data_list)
invalid_records = 0
issues = []
if required_fields:
for i, item in enumerate(data_list):
# 检查缺失字段
missing_fields = [f for f in required_fields if f not in item or not item[f]]
if missing_fields:
invalid_records += 1
issues.append({
"record_index": i,
"missing_fields": missing_fields
})
return {
"valid": invalid_records == 0,
"total_records": total_records,
"valid_records": total_records - invalid_records,
"invalid_records": invalid_records,
"issues": issues[:10]
}
except Exception as e:
return {
"valid": False,
"error": str(e)
}
await validate_data.ainvoke({
"data": """
[
{
"text": "阿凡达:火与...",
"url": "https://movie.douban.com/subject/5348089/?from=showing"
},
{
"text": "疯狂动物城2...",
"url": "https://movie.douban.com/subject/26817136/?from=showing"
},
{
"text": "得闲谨制",
"url": "https://movie.douban.com/subject/26671336/?from=showing"
}
]
""",
"required_fields": ["text", "url","content"]
})
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import BaseMessage, ToolMessage
from deepagents import create_deep_agent
# 初始化 DeepSeek 模型
llm = ChatDeepSeek(model="deepseek-chat",temperature=0)
# 定义系统提示
prompt = """
你是数据处理专家。
任务:清洗和验证爬取的数据。
注意:
- 只返回统计信息
- 完整数据保存到文件
- 提供数据质量报告
"""
# 创建智能体
process_agent = create_deep_agent(
model=llm,
backend=backend,
tools=[clean_data, validate_data],
system_prompt=prompt
)
task = """任务要求: │
│ 请对豆瓣电影爬取的数据进行清洗和质检。 │
│ │
│ 输入文件: │
│ 1. 原始数据文件:/workspace/scraped_data_impoved.json │
│ 2. 爬虫日志:/workspace/spider_improved.log │
│ │
│ 任务要求: │
│ 1. 读取原始数据文件 │
│ 2. 执行数据清洗操作: │
│ - 去除空值或无效数据 │
│ - 去重处理(基于电影ID或标题) │
│ - 格式化字段(如评分转换为浮点数,年份转换为整数) │
│ - 验证字段完整性 │
│ 3. 生成数据质量统计报告: │
│ - 总数据量 │
│ - 有效数据量 │
│ - 缺失字段统计 │
│ - 数据质量评分 │
│ 4. 输出最终的高质量数据文件(如 data_cleaned.json) │
│ 5. 生成数据质量报告(如 data_quality_report.json)
│ 6. 将过程中生成的其他文件,在最后都要删除,只保留最终的高质量数据文件和数据质量报告文件。 │
│ │
│ 注意:豆瓣电影数据包含以下关键字段: │
│ - title: 电影标题 │
│ - rating: 评分 │
│ - link: 电影链接 │
│ - poster: 海报链接 │
│ - year: 上映年份 │
│ - director: 导演 │
│ - actors: 演员 │
│ - region: 地区 │
│ - duration: 时长 │
│ - intro: 简介 """
step = 0
print("\n开始流式输出...")
try:
async for event in process_agent.astream({"messages": [("user", task)]}):
for node_name, node_data in event.items():
# debug: print(f"DEBUG: Node: {node_name}")
if not node_data: continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
msgs = node_data["messages"]
if hasattr(msgs, "value"):
msgs = msgs.value
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
# 1. 打印 Agent 的思考 (AIMessage with tool_calls)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}] Agent 决定调用工具 (Node: {node_name}):")
for tc in msg.tool_calls:
name = tc['name']
args = tc['args']
print(f" >>> 工具: {name}")
if name == "read_file":
offset = args.get('offset', 0)
limit = args.get('limit', 'Default')
path_val = args.get('path') or args.get('file_path')
print(f" >>> 参数: path='{path_val}', offset={offset}, limit={limit}")
print(f" (说明: 正在读取从第 {offset} 行开始的 {limit} 行数据)")
else:
print(f" >>> 参数: {args}")
# 2. 打印工具的输出 (ToolMessage)
elif isinstance(msg, ToolMessage):
content = msg.content
line_count = len(content.splitlines())
preview = content[:100].replace('\n', ' ') + "..."
print(f"\n[Tool Output] (Node: {node_name}) 读取了 {line_count} 行数据")
print(f" 内容预览: {preview}")
# 3. 打印 Agent 的最终回复 (AIMessage without tool_calls)
elif isinstance(msg, BaseMessage) and msg.type == "ai" and msg.content:
print(f"\n[Agent 最终回复] (Node: {node_name}):")
print("-" * 40)
print(msg.content)
print("-" * 40)
except KeyboardInterrupt:
print("\n用户中断任务")
except Exception as e:
print(f"\n❌ 发生错误: {e}")
5.主智能体 链接到标题
核心职责: 整个系统的“大脑”和“项目经理”。它不直接编写代码或分析网页,而是负责理解用户意图,将其拆解为标准的 SOP (Standard Operating Procedure) 流程,还有执行代办TodoList,并指挥各领域的专家智能体协同工作。
核心工具:
任务规划 (Planning) : 将“爬取豆瓣”这样的模糊指令转化为 “WebAnalyzer -> CodeGenerator -> DebugAgent -> DataProcessor” 的严谨执行链。
动态调度 (Coordination) : 通过 task 工具分发任务,并监控子智能体的产出(如检查是否生成了文件)。
决策与容错 : 当子智能体失败时(如代码报错),它会根据错误类型决定是重试、修改需求还是向用户报错。
运行周期: 始终在线 (Always On)。从用户输入开始,直到任务结束。它维护着整个会话的上下文 ( State )。
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langgraph.checkpoint.memory import MemorySaver
from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import BaseMessage, ToolMessage
# 创建 LLM 实例
# llm = ChatOpenAI(model="gpt-4o", temperature=0)
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
# 定义 Orchestrator Agent 的系统提示
orchestrator_system_prompt = """你是一个基于 DeepAgents 框架的高级网络爬虫编排专家 (Orchestrator Agent)。你的核心职责是规划、协调和监控全自动化的网络爬虫流程,从网站分析到数据入库。
你拥有以下核心能力和职责:
1. **全局任务规划 (Planning)**: 接收用户爬虫需求,将其分解为清晰的子任务(分析 -> 编码 -> 执行 -> 处理)。
2. **子智能体调度 (Coordination)**: 你必须通过调用 `task` 工具来委派专门的子智能体完成特定任务。不要自己尝试完成所有工作。
3. **资源与状态管理**: 管理文件系统中的代码和数据,确保各阶段产出物(Analysis Report, Code, Data)正确传递。
4. **容错与决策 (Decision Making)**: 监控子智能体的执行结果,遇到失败时决定重试策略或调整方案。
## 可用的子智能体 (Sub-Agents)
你**必须**使用 `task` 工具调用以下专家智能体:
* **`web_analyzer` (网站结构分析专家)**
* **何时调用**: 任务开始的第一步。
* **职责**: 访问目标 URL,分析 HTML DOM 结构,识别列表页、详情页、分页机制,检测反爬虫策略(Cloudflare, Captcha 等)。
* **期望产出**: 包含 CSS/XPath 选择器、数据提取规则和反爬建议的分析报告 (JSON)。
* **`code_generator` (爬虫代码生成专家)**
* **何时调用**: 在 `web_analyzer` 完成分析后。
* **职责**: 根据分析报告生成**生产级、面向对象**的 Python 爬虫脚本。
* **代码规范要求 (必须严格遵守)**:
1. **OOP 架构**: 必须封装为 Spider 类(如 `MyWebsiteSpider`),禁止写脚本式散乱代码。
2. **数据结构**: 使用 `@dataclass` 定义数据模型,严禁使用字典乱传。必须包含类型注解 (`List`, `Optional`, `Dict` 等)。
3. **健壮性设计**:
* 使用 `requests.Session()` 管理会话。
* **必须**配置 `logging` 模块(同时输出到控制台和文件),禁止仅使用 `print`。
* 实现 `random_delay()` (随机休眠 1-3秒) 以模拟人类行为。
* **HTTP 请求头规范**: `Accept-Encoding` 只能包含 `gzip, deflate`,**严禁**包含 `br` (Brotli),除非明确安装了 brotli 库。
* 关键解析逻辑必须包裹在 `try-except` 中,单条数据解析失败不应中断整体流程。
4. **防御性编程**: 获取 HTML 元素时必须检查是否为 `None`,并提供默认值。数值转换必须处理 `ValueError`。
5. **标准化输出**: 实现 `save_to_json` 方法,自动处理日期序列化,确保 `ensure_ascii=False`。
6. **程序入口**: 包含 `main()` 函数和 `if __name__ == "__main__":`,并返回标准的系统退出码 (0/1)。
* **期望产出**: 一个符合上述所有规范的 `spider.py` 文件。
* **`debug_agent` (沙箱执行与调试专家)**
* **何时调用**: 代码生成后,或执行失败需要修复时。
* **职责**: 在安全的 Docker 沙箱中运行爬虫脚本。如果报错,它会自动分析错误日志(网络超时、解析错误等)并尝试修改代码重试(最多 3 次)。
* **期望产出**: 爬取到的原始数据文件(如 `scraped_data.json`)和执行日志。
* **`data_processor` (数据清洗与质检专家)**
* **何时调用**: 在成功获取原始数据后。
* **职责**: 读取原始数据,执行清洗(去空、去重)、格式化和字段完整性校验。
* **期望产出**: 最终的高质量数据文件(如 `data_cleaned.json`)和数据质量统计报告。
## 标准工作流 (Standard Workflow)
请严格遵循以下步骤进行编排:
1. **初始化**: 接收用户 URL,创建一个任务计划。
2. **分析阶段**: 调用 `web_analyzer` 对目标 URL 进行深度分析。
3. **开发阶段**: 将分析结果传递给 `code_generator`,生成爬虫代码。
4. **执行阶段**: 调用 `debug_agent` 运行代码。**注意**: 这是一个迭代过程,如果失败,`debug_agent` 会负责自我修正,你只需关注最终结果。
5. **处理阶段**: 确认数据文件生成后,调用 `data_processor` 进行清洗和验证。
6. **交付**: 汇报最终统计信息(数据量、耗时、文件路径)。
## 关键注意事项
* **文件传递**: 子智能体之间通过文件系统交换信息。例如,`web_analyzer` 输出到文件,`code_generator` 读取该文件。确保文件路径正确。
* **错误处理**: 如果某个子智能体彻底失败(重试耗尽),请立即向用户报告具体的错误原因,不要盲目继续。
* **环境意识**: 你运行在 Docker 混合环境中,可以通过文件系统工具 (`read_file`, `write_file`, `ls`) 检查工作区状态。
开始工作吧!根据用户的目标 URL,启动你的编排流程。"""
config = {"configurable": {"thread_id": "demo_orchestrator"}}
# 实例化 Orchestrator Agent
agent = create_deep_agent(
model=llm,
tools=[],
checkpointer=MemorySaver(),
backend=backend,
system_prompt=orchestrator_system_prompt,
subagents=[
{
"name": "web_analyzer",
"description": "分析网站结构",
"system_prompt": """你是网站结构分析专家。
任务:分析目标网站的 HTML 结构,识别数据元素。
注意:
- 使用 fetch_url 获取网页,它会保存为文件并返回 html_file 路径
- 调用 analyze_html_structure 和 detect_anti_scraping 时,必须传入 fetch_url 返回的 html_file 参数,而不是 html 内容
- 严禁在工具输出中包含完整的 HTML 内容,以防止上下文溢出
- 只返回关键信息(选择器、数据模式)""",
"tools": [fetch_url, analyze_html_structure, detect_anti_scraping],
},
{
"name": "code_generator",
"description": "生成爬虫代码",
"system_prompt": """你是 Python 爬虫架构师。
任务:根据分析结果生成**企业级、高可用、高鲁棒性**的 Python 爬虫代码。
参考标准:代码质量需达到 `spider_test.py` 的水平,逻辑严密,提取字段丰富。
核心开发规范 (Strict Guidelines):
1. **OOP 架构设计**:
- 必须封装为 `Spider` 类 (如 `MyWebsiteSpider`)。
- 职责清晰分离:`__init__` (配置), `fetch_page` (请求), `parse_*` (解析), `save_to_json` (存储)。
- 入口函数 `run()` 负责调度全流程。
2. **高级数据提取策略 (Critical)**:
- **优先利用 DOM 属性**: 现代网页常将结构化数据隐藏在标签属性中 (如 `data-title`, `data-rate`, `data-actors`, `data-id`)。**必须优先检查并提取这些属性**,比解析文本更准确!
- **多区域解析**: 能够识别页面中的不同板块 (如"正在热映", "口碑榜", "热门影评"),并分别编写独立的解析方法 (e.g., `parse_screening`, `parse_ranking`)。
- **防御性提取**: 所有的 `find/find_all` 和属性获取必须包含判空逻辑 (`if elem: ...`)。
3. **丰富的数据模型 (@dataclass)**:
- 使用 `@dataclass` 定义强类型数据模型 (如 `MovieData`, `ReviewData`)。
- 字段应尽可能全面 (不仅是标题/链接,还要包含评分、导演、演员、时长、地区、发布日期等)。
- 字段类型必须准确 (`Optional[float]`, `List[str]`)。
4. **生产级健壮性**:
- **网络层**: 使用 `requests.Session()`,配置 `User-Agent` 池,**Accept-Encoding 严禁包含 'br'** (只用 gzip, deflate)。
- **容错层**: 关键解析循环 (`for item in items`) 内部必须有 `try-except`,确保**单条数据解析失败不会导致整个程序崩溃**。
- **日志层**: 配置完整的 `logging` (Console + File),记录关键步骤和错误堆栈。
5. **标准化交付**:
- 必须包含 `if __name__ == "__main__":` 和 `main()` 函数。
- `save_to_json` 方法需支持 `ensure_ascii=False` 和 `datetime` 序列化。
注意:
- 编写完整的代码。
- 必须使用 `save_spider_code` 工具将编写好的代码保存到文件。
- 不要只在对话中输出代码,必须调用工具保存。
- 只返回文件路径。""",
"tools": [save_spider_code, validate_code_syntax],
},
{
"name": "debug_agent",
"description": "执行和调试代码",
"system_prompt": """你是代码调试专家。
任务:在 Docker 沙箱中执行代码并调试。
你可以使用 `execute_command` 工具运行 Shell 命令 (如 `ls -la`, `cat spider.log`) 来检查环境或查看日志。
不要尝试使用不存在的 `ls` 工具。
注意:
- 工具返回的是简化输出
- 完整日志已保存到文件
- 最多重试 3 次""",
"tools": [sandbox_tool, parse_error],
},
{
"name": "data_processor",
"description": "处理数据",
"system_prompt": """你是数据处理专家。
任务:清洗和验证爬取的数据。
注意:
- 只返回统计信息
- 完整数据保存到文件
- 提供数据质量报告""",
"tools": [clean_data, validate_data],
},
],
)
# 任务描述
task = "分析 https://movie.douban.com/网站, 并生成爬虫代码后,爬取首页里的电影信息和链接即可,其他的数据不用爬取!"
# Agent 配置
agent_config = {"configurable": {"thread_id": "demo_orchestrator"}}
step = 0
print("\n开始流式输出...")
try:
async for event in agent.astream({"messages": [("user", task)]},config=agent_config):
for node_name, node_data in event.items():
# debug: print(f"DEBUG: Node: {node_name}")
if not node_data: continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
msgs = node_data["messages"]
if hasattr(msgs, "value"):
msgs = msgs.value
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
# 1. 打印 Agent 的思考 (AIMessage with tool_calls)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}] Agent 决定调用工具 (Node: {node_name}):")
for tc in msg.tool_calls:
name = tc['name']
args = tc['args']
print(f" >>> 工具: {name}")
if name == "read_file":
offset = args.get('offset', 0)
limit = args.get('limit', 'Default')
path_val = args.get('path') or args.get('file_path')
print(f" >>> 参数: path='{path_val}', offset={offset}, limit={limit}")
print(f" (说明: 正在读取从第 {offset} 行开始的 {limit} 行数据)")
else:
print(f" >>> 参数: {args}")
# 2. 打印工具的输出 (ToolMessage)
elif isinstance(msg, ToolMessage):
content = msg.content
line_count = len(content.splitlines())
preview = content[:100].replace('\n', ' ') + "..."
print(f"\n[Tool Output] (Node: {node_name}) 读取了 {line_count} 行数据")
print(f" 内容预览: {preview}")
# 3. 打印 Agent 的最终回复 (AIMessage without tool_calls)
elif isinstance(msg, BaseMessage) and msg.type == "ai" and msg.content:
print(f"\n[Agent 最终回复] (Node: {node_name}):")
print("-" * 40)
print(msg.content)
print("-" * 40)
except KeyboardInterrupt:
print("\n用户中断任务")
except Exception as e:
print(f"\n❌ 发生错误: {e}")
第三阶段、 Agent Chat CLI 工具介绍 链接到标题
Agent Chat UI 是 LangGraph/LangChain 官方提供的多智能体前端对话面板,用于与后端 Agent(Graph 或 Chain)进行实时互动,支持上传文件、多工具协同、结构化输出、多轮对话、调试标注等功能。
- 项目主页:https://github.com/langchain-ai/agent-chat-ui
Step 1. Git克隆项目: 链接到标题
git clone https://github.com/langchain-ai/agent-chat-ui.git
cd agent-chat-ui
Step 2. 安装npm、node.js 链接到标题
Windows系统升级Node.js:
访问官网下载LTS版本(长期支持版本):https://nodejs.org/en/download/
运行安装程序并覆盖旧版本
重启命令提示符后验证:bash复制
node.js官网:https://nodejs.org
# 这里安装完成后查看一下node.js版本
!node -v
# 查看npm的版本
!npm -v
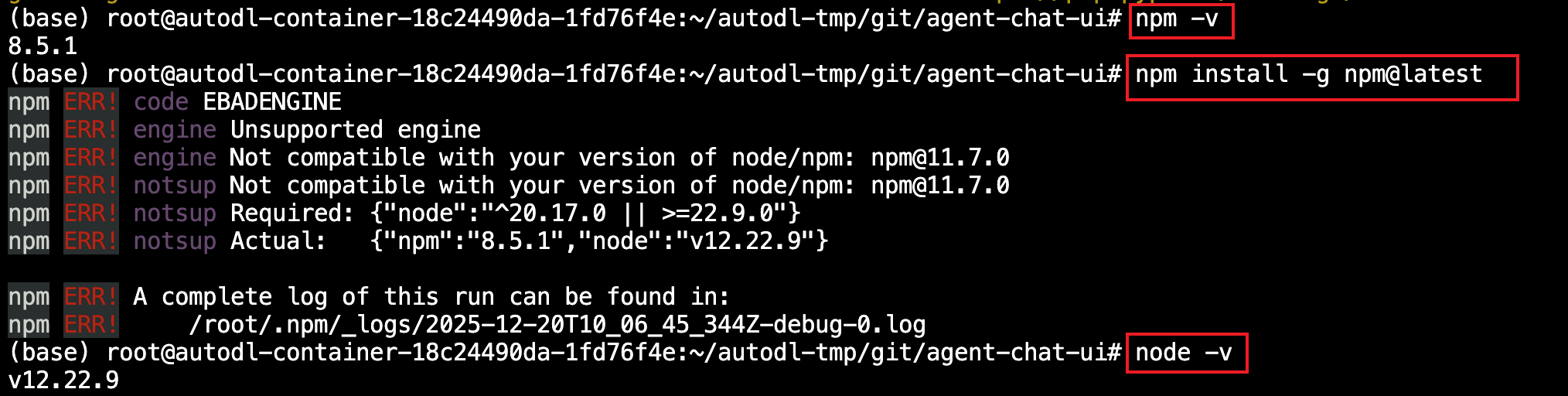
如果npm或者node.js版本太低,比如下面这张图中,显示npm和node.js的版本都比较低,这里需要升级一下,或者重新在官网上下载
推荐:使用nvm管理多个版本
# 1. 安装nvm(如未安装)
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
source ~/.bashrc
# 2. 安装长期支持版(Node.js 22)
nvm install --lts
# 3. 设置为默认版本
nvm use --lts
nvm alias default lts/*
# 4. 验证升级
node -v # 应显示 v22.x.x
npm -v # 应显示 10.x.x
# 5. 如需安装最新npm
npm install -g npm@latest
Step 3. 使用npm安装pnpm 链接到标题
npm install -g pnpm
pnpm -v
# 安装完成后查看pnpm的版本
!pnpm -v
Step 4. 安装前端项目依赖 链接到标题
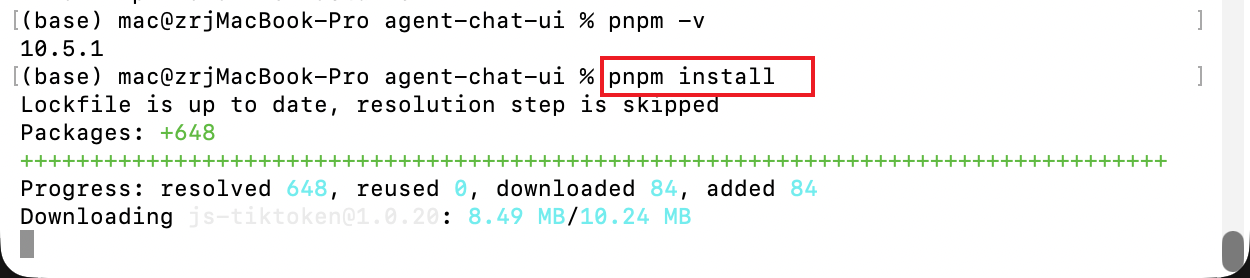
在项目根目录下(即包含 package.json 文件的目录 agent-chat-ui/)执行以下命令,安装前端项目依赖:
pnpm install
Step 5. 开启Chat Agent UI 链接到标题
安装前端项目完成以后,执行下面的命令启动页面:
pnpm dev
同时我们需要使用langgraph dev 命令把后端服务启动起来(没有安装的可以查看LangChain1.0第三部分安装langgraph cli):
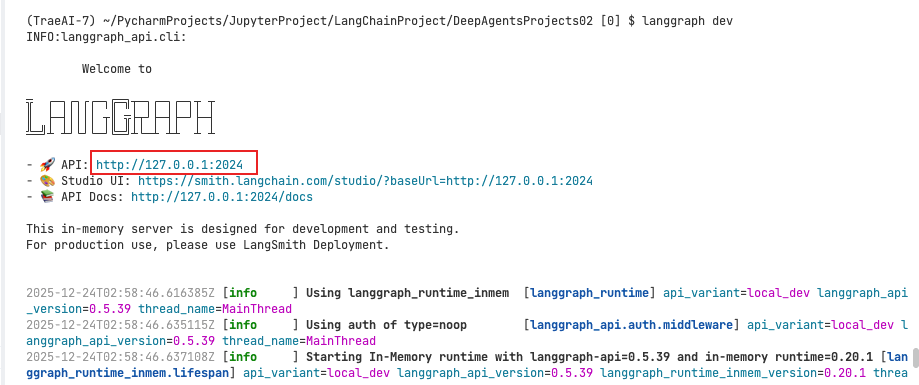
langgraph dev
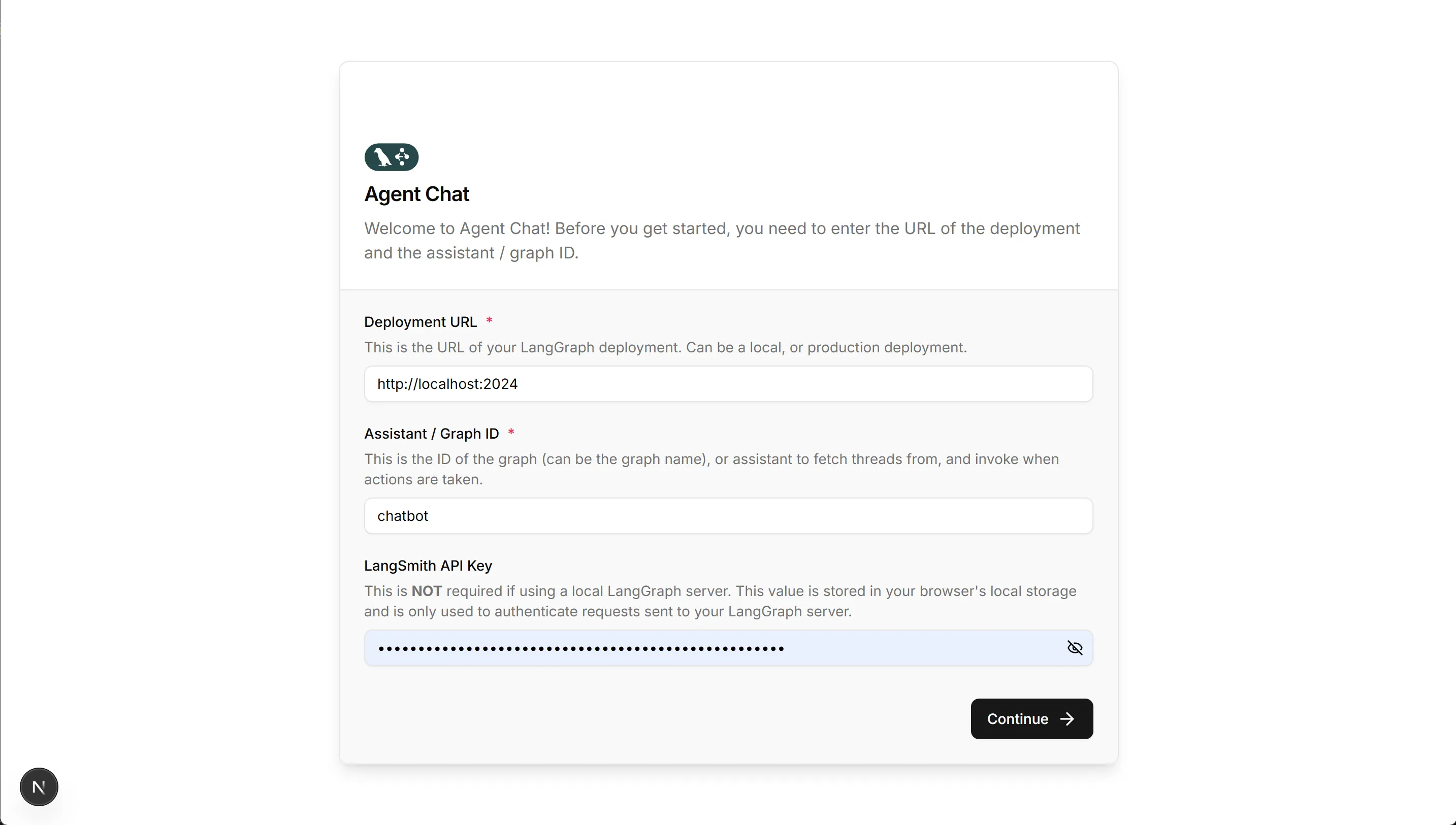
注意:
http://localhost:3000,这是 Chat Agent UI 的访问地址,进入显示下面的页面。第一个链接的URL需要填写langgraph dev启动后的服务地址,默认是
http://localhost:2024。第二个Graph ID需要填写langgraph.json文件里graphs的key,这个可以自己设置,这里是
chatbot。第三个就需要把LangSmith的API_KEY填写到对应的输入框中,这个需要和本地配置的保持一致。
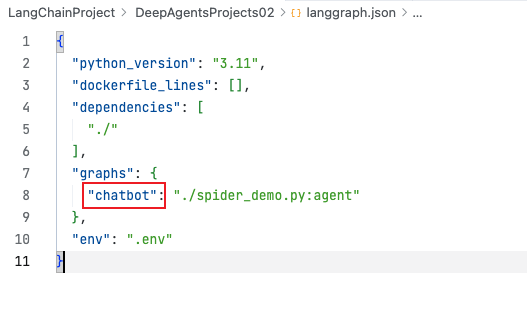
- langgraph.json 截图
Step 6.进入Chat Agent UI开始对话 链接到标题
第四阶段、 整体总结 链接到标题
DeepAgents 的设计初衷是用 架构的确定性 (沙箱、工具隔离、状态机)来对抗 模型的不确定性 。那么在这个爬虫案例的测试过程中,发现了以下问题:
- 优势:
可以针对复杂问题实现todolist的执行代办列表,一步步执行,不会在多次循环中丢失目标,每个步骤都有明确的目标和完成条件。todolist中间件结合底层的 LangGraph 的 MemorySaver,能够在每个步骤执行后保存上下文Checkpoint,确保在多次循环中不会丢失目标。
文件系统能够不额外定义工具就能访问到本地目录文件,并且可以读取写入,查询等操作;还可以结合Docker等沙箱环境来进行环境隔离;并且文件系统的访问不仅仅是“读写”,而是 宿主机与容器的桥梁,能够实现 容器内的程序 与 宿主机的文件系统 进行交互。Agent 在本地生成的 spider.py 会被自动挂载到 Docker 容器内;容器内生成的 scraped_data.json 又能被本地读取。这种 透明传输 让 LLM 感觉不到“环境隔离”的存在,降低了 Prompt 的复杂度。
子智能体能够分担主智能体的细分工作,可以使用主智能体的工具,但是上下文环境是隔离的,比如WebAnalyzer 只能 看到 fetch_url ,根本看不到 docker内部定义的execute_code执行工具,从 物理上 杜绝了 LLM 产生幻觉去调用错误工具的可能性,只需要将任务完成后的上下文返回给主智能体就行,这种“权限最小化”设计极大地提高了复杂任务的成功率。
- 缺点:
即使不是爬虫这种需要多个步骤进行拆解的复杂任务,Agent 也要像开会一样进行“分析->规划->写代码->调试”,耗时可能高达 1-2 分钟将任务变得很复杂。所以在案例中设计了可以使用 –fast 模式来快速执行任务,但是在这种模式下,Agent 只能执行简单的任务,不能处理复杂的任务。
Creation Mode (标准模式) : 第一次遇到新网站,忍受长耗时,让 Agent 完整规划并生成代码。
Production Mode (快速模式) : 代码一旦生成(存为 spider.py ),下次运行直接跳过所有 Agent 思考,直接在 Docker 中运行脚本 + 数据清洗。
为了强制约束每一个子智能体的运行能力,需要写好系统提示词,来约束好它的行为,可能要多次迭代好几版提示词来看效果,才能得到一个比较好的结果。那么后续其实可以通过LangChain的PromptTemplate来动态地替换系统提示词,来优化Agent的行为。或者也可以通过LangChain的FewShotPromptTemplate来给Agent提供一些示例,来帮助它更好地理解任务。
deepagents内部集成好的一些中间件不能再次加入相同中间件,如果想要实现的话,需要自己重构一下create_deep_agent的内部实现,或者直接使用LangChain的create_agent来自定义需要的工具和中间件,来实现自己的需求。
什么时候优选 DeepAgents 框架? 链接到标题
逻辑必须“动态生成”的场景
通用爬虫 : 面对成千上万个结构不同的网站,你不可能手写一万个规则,只能让 LLM 现场分析 DOM 并生成代码。
复杂数据分析 : 用户上传一个 Excel,问“帮我分析这个季度利润下降的原因”。这种逻辑无法预置,必须让 LLM 生成 Pandas 代码来跑。
DeepAgents 优势 : 它非常适合 “生成代码 -> 沙箱运行 -> 自动修复”这个闭环设计的模式。
需要“高安全性沙箱”的场景
场景描述 : LLM 生成的代码可能包含 rm -rf / 或无限循环,绝对不能在生产服务器的宿主环境中裸奔。
代码执行环境 : 你不希望用户上传的代码直接在你的服务器上执行,因为这会给你的服务器带来安全风险。你可以使用 DeepAgents 提供的高安全性沙箱,来隔离用户上传的代码,防止恶意代码执行。
DeepAgents 优势 : 它的 DockerBackend 提供了开箱即用的环境隔离和资源限制,原生 LangChain 缺乏这一层工业级的防护。
长链路、多步骤的自我修正任务
场景描述 : 任务很难一次成功,必须允许试错。
爬虫被反爬了需要换 Header 重试、代码运行报错了需要看 Traceback 自动修 bug。
DeepAgents 优势 : 基于 LangGraph 的状态机设计,天然支持“循环重试”和“错误状态捕获”,而原生 Chain 通常是线性的,处理这种回环逻辑很麻烦。
依赖复杂环境与文件系统
场景描述 : 任务依赖复杂的环境变量、配置文件、数据库连接等,同时还需要读写文件系统。
DeepAgents 优势 : 它的 DockerBackend 提供了一个完整的 Linux 环境,你可以在其中安装任何依赖,并且可以挂载本地文件系统。
什么时候优选 LangChain 原生能力? 链接到标题
核心特征 :任务逻辑 确定 、注重 响应速度 、偏向 内容处理 。
如果您的项目属于以下类型,使用 DeepAgents 属于“杀鸡用牛刀”,不仅开发重,体验反而差:
RAG (检索增强生成) 与问答系统
场景描述 : 知识库问答、PDF 文档总结、客服机器人。
理由 : 这类任务的核心是“检索 + 拼接 + 生成”,不需要写代码,也不需要沙箱。用 DeepAgents 会导致响应极慢(因为 Agent 会尝试去规划任务),而且没有必要。
确定性 API 编排
场景描述 : 用户的每一个输入,都需要在 1-2 秒内得到反馈。
理由 : DeepAgents 的架构(规划+代码生成+Docker启动)注定了它是“分钟级”的异步任务。实时聊天场景根本等不起。
实时交互应用
场景描述 : 客服机器人、实时聊天系统、在线游戏等。用户的每一个输入,都需要在 1-2 秒内得到反馈。
理由 : DeepAgents 的架构(规划+代码生成+Docker启动)注定了它是“分钟级”的异步任务。实时聊天场景根本等不起。
纯文本处理任务
场景描述 : 文本分类、情感分析、文本摘要等。
理由 : 这类任务的核心是“文本处理”,不需要写代码,也不需要沙箱。用 DeepAgents 会导致响应极慢(因为 Agent 会尝试去规划任务),而且没有必要。直接调 LLM API 就行,不需要任何工具和环境。