第一阶段、 DeepAgents 框架定位与核心价值 链接到标题
一、 什么是 DeepAgents ? 链接到标题
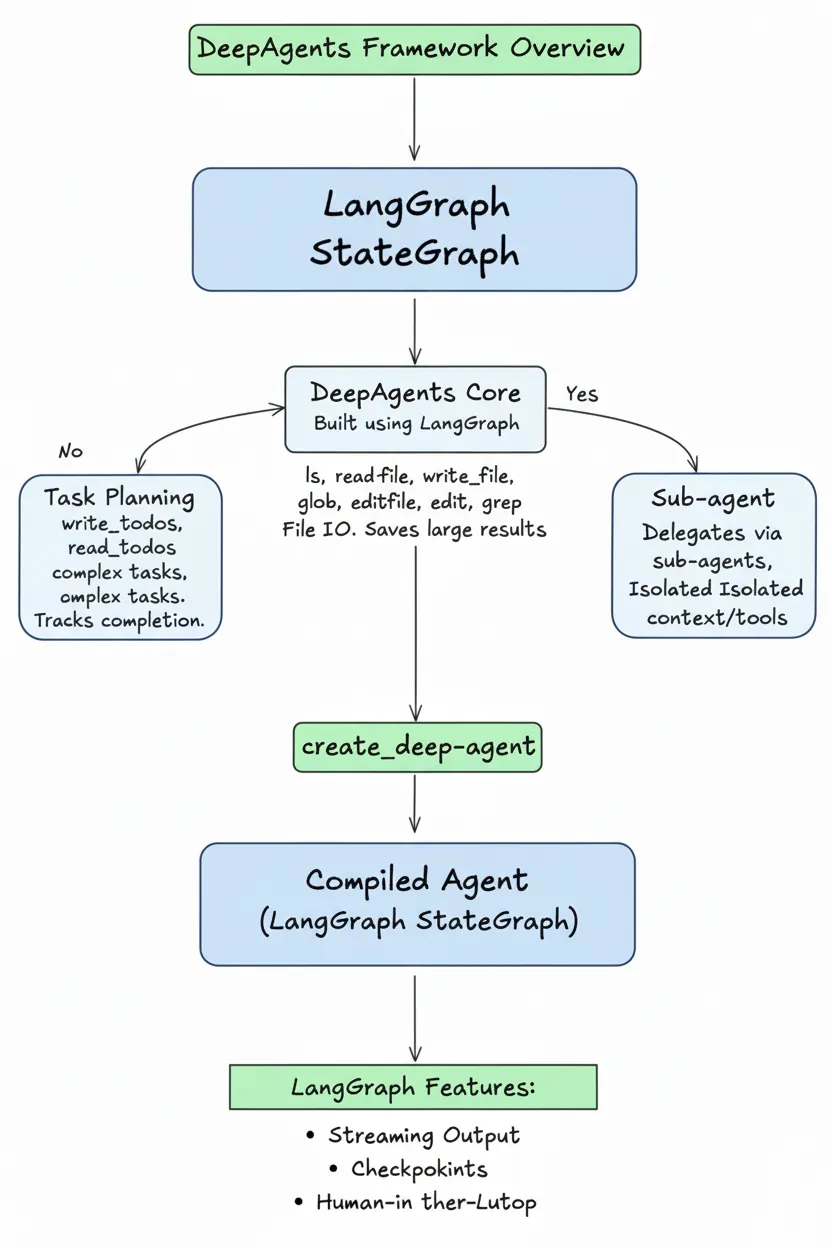
DeepAgents(代码库名为 deepagents)是一个基于 LangChain 和 LangGraph 构建的企业级高级智能体框架。它建立在 LangGraph(底层运行时)和 LangChain(工具/模型层)之上,是一个高阶的Agent Harness(智能体装备/套件)。
定位:它旨在简化长运行自主智能体 (Long-running Autonomous Agents) 的开发过程,通过内置的最佳实践和中间件,解决复杂任务中的规划、记忆、工具使用和环境交互问题。
核心理念:如果说 LangChain 提供了积木,LangGraph 提供了地基,那么 DeepAgents 就是一套成品级的框架。它预设了最佳实践(规划、文件系统、子智能体),让你能快速构建类似 “OpenAI Deep Research” 或 “Claude Code” 的应用。
论文地址:https://arxiv.org/pdf/2510.21618
DeepAgents 开源地址:https://github.com/langchain-ai/deepagents
二、 解决的核心问题 链接到标题
传统的 Agent 开发通常运行一个简单的循环:思考→调用工具→观察→重复。这种模式在处理多小时或多天的任务时,容易遇到以下"浅层陷阱"(Shallow Agent Problem)
规划能力缺失:原生 Agent 倾向于“走一步看一步”,缺乏全局视角的任务拆解,容易在多步任务中迷失方向。
遗忘与混乱:在执行超过 10-20 步的长任务时,由于 Context Window(上下文窗口)限制,传统 Agent 容易忘记初始目标或陷入死循环。
环境交互困难:文件系统操作、代码执行环境(沙箱)的配置和安全管理复杂。
上下文污染:所有工具返回结果都堆积在一个对话历史中,导致噪声过大。
协作编排复杂:多智能体(Multi-Agent)之间的任务分发和上下文隔离难以实现。
DeepAgents 通过引入"类人"的工作流解决了这些问题:先做计划(Plan),再执行,利用文件系统管理记忆,遇到复杂子任务时"外包"给子 Agent。将规划工具、文件系统访问、子代理和详细提示词等关键机制整合在一起,以支持复杂的深度任务 。
import deepagents
print(dir(deepagents))
三、 应用场景 链接到标题
DeepAgents 不适合用来做简单的聊天机器人(Chatbot),它是为重任务设计的,它适用于任务需规划、上下文海量、需多专家协作、要求持久记忆的场景,将LangChain生态从单步响应提升至自主完成复杂项目的高度:
深度调研 (Deep Research):自动进行多轮网页搜索、阅读文档、整理笔记并生成长篇报告(如分析某个行业的市场格局)。
全栈代码生成 (Coding Assistant):类似 Claude Code,在沙箱环境中编写、运行、测试和修复代码,甚至重构整个代码库。
复杂数据分析:自动连接数据库,生成 SQL,执行查询,将中间数据存为 CSV 文件(在虚拟文件系统中),最后生成图表。
自动化运维 (DevOps Automation):操作文件系统、执行 Shell 命令、管理服务器状态。
复杂工作流编排:需要多角色协作(如产品经理-程序员-测试员)的复杂业务流程。
当然这个描述相对来说比较抽象,因此我们这里对适用于DeepAgents的场景进行一个总结:
DeepAgents 适用场景
| 场景类型 | 能力说明 | 工作逻辑 / 技术特点 | 代表性案例 |
|---|---|---|---|
| 深度调研与报告生成 | 支持长周期、多步骤、多来源信息整合的研究任务 | • 自动生成研究计划(Todo)• 调用搜索工具获取资料• 将关键信息写入文件系统(长期记忆)• 使用子代理(Sub-Agents)深入研究子课题• 主代理统一规划、整合结果 | • LangChain Deep Research 示例(Tavily 搜索 + 多子代理拆分研究)• OpenAI Deep Research(官方生产级深度调研助理) |
| 自动编程与代码助理 | 理解代码、修改代码、生成新文件、执行工具链 | • 代理可读写虚拟文件系统• 自动分析源码并输出 diff• 人工审批(Human-in-the-Loop)保证安全写入• 调用 Shell / 测试工具执行流程• 可将项目规范写入 /memories 用作长期记忆 | • LangChain DeepAgents CLI(终端自动编码)• Anthropic Claude Code(深度自动重构与编程)• Manus(多步骤代码智能体) |
| 复杂流程自动化(业务流程 Orchestration) | 将多个步骤串联为可控流程,适合企业级自动化任务 | • 任务分解 → 多步骤规划 → 调用不同工具• 搜索、筛选、处理、生成等多环节协作• 使用文件系统存储中间数据(如列表、分析结果等)• 支持多工具、多子任务并行处理 | • DeepAgents 求职助手(职位搜索 → 筛选排序 → 求职信生成 → 打包结果)• 企业场景如:自动生成分析报告 / 客服知识库构建 / 数据采集+处理流 |
第二阶段、 与 LangChain 及 LangGraph 的区别 链接到标题
从技术定位看,LangChain 适用于需要自定义提示与工具的基础智能体搭建;LangGraph 更适合构建复杂的多智能体系统与工作流;而 DeepAgents 面向希望省去底层开发、直接采用深度自主机制的用户,可快速实现 AutoGPT 类应用。因此,DeepAgents 本质上是基于 LangChain 的深度模式封装——它并非替代 LangChain 或 LangGraph,而是将其常用抽象与运行时封装为开箱即用的组件,可视为一层“开发加速器”。
| 特性 | LangChain | LangGraph | DeepAgents |
|---|---|---|---|
| 层级 | 基础组件库 (Foundation) | 编排引擎 (Orchestration) | 应用框架 (Application Framework) |
| 核心抽象 | Chain, Runnable, Tool | StateGraph, Node, Edge | DeepAgent, Middleware, Backend |
| 灵活性 | 极高 (积木块) | 高 (自定义图结构) | 中 (Opinionated / 约定优于配置) |
| 开箱即用 | 低 (需自行组装) | 中 (需定义图逻辑) | 高 (内置规划、文件系统、子代理) |
| 适用对象 | 库开发者/底层构建 | 复杂流程序列化开发者 | 应用开发者/企业级解决方案 |
LangChain:提供 Prompt, Models, Tools 等积木。
LangGraph:提供 State, Nodes, Edges 等地基和连接逻辑。
DeepAgents:LangGraph 的一种“最佳实践实现”。它底层使用 LangGraph 来管理状态和循环,但向上提供了更高级的 API (
create_deep_agent),隐藏了底层的图构建细节。
第三阶段、 DeepAgents 核心功能介绍 链接到标题
- 注意: 没有学习LangChain的用户,建议先学习LangChain1.0的基础内容,再学习DeepAgents。
一、安装环境与依赖 链接到标题
!python --version
# 安装deepagents依赖
!pip install deepagents
# 查看版本
!pip list | grep -E 'langchain|deepagents'
# from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
from dotenv import load_dotenv
# 1. 加载.env环境变量
load_dotenv(override=True)
# 2. 初始化模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0)
model.invoke("你好")
二、 核心入口:create_deep_agent()
链接到标题
这是整个框架的核心函数,它创建了一个功能完整的深度智能体。
默认配置:
使用 Claude Sonnet 4 或 GPT-4o 作为默认模型(推荐)。
集成 7 个核心文件操作工具。
提供待办事项管理功能。
支持子代理调用。
关键参数:
model: 支持自定义语言模型。tools: 自定义工具集。system_prompt: 系统提示词subagents: 子代理配置。backend: 文件存储后端。interrupt_on: 人机交互配置 (Human-in-the-Loop)。允许在特定节点暂停 Agent 执行,等待人工干预。这对于安全审核(删除文件)、成本控制(调用昂贵 API)和质量保证至关重要。
from deepagents import create_deep_agent
create_deep_agent?
# 安装网络搜索工具
!pip install langchain-tavily
from deepagents import create_deep_agent
from langchain_tavily import TavilySearch
from langgraph.checkpoint.memory import InMemorySaver
# 1. 初始化 Tavily 搜索工具
tavily = TavilySearch(max_results=3)
# 2. 编写系统提示词
research_instructions = """
您是一位资深的研究人员。您的工作是进行深入的研究,然后撰写一份精美的报告。
您可以通过互联网搜索引擎作为主要的信息收集工具。
## 可用工具
### `互联网搜索`
使用此功能针对给定的查询进行互联网搜索。您可以指定要返回的最大结果数量、主题以及是否包含原始内容。
### `写入本地文件`
使用此功能将研究报告保存到本地文件。当您完成研究并生成报告后,请使用此工具将完整的报告内容保存到文
件中。
- 文件路径建议使用 .md 格式(Markdown),例如 "research_report.md" 或 "./reports/报告名
称.md"
- 请确保报告内容完整、结构清晰,包含所有章节和引用来源
## 工作流程
在进行研究时:
1. 首先将研究任务分解为清晰的步骤
2. 使用互联网搜索来收集全面的信息
3. 将信息整合成一份结构清晰的报告
4. **重要**:完成报告后,务必使用 `写入本地文件` 工具将完整报告保存到本地文件
5. 务必引用你的资料来源
**注意**:请确保在完成研究后,将完整的报告内容保存到文件中,这样用户可以方便地查看和保存报告。
"""
# 2. 创建 DeepAgents 智能体
agent = create_deep_agent(
name="DeepAgents_Agent", # 智能体名称
tools=[tavily], # 可调用工具Tool
model=model, # 模型Model
system_prompt=research_instructions, # 系统提示词
checkpointer=InMemorySaver(), # 检查点Checkpointer,内存检查点
)
# 3. 配置线程 ID
config = {"configurable": {"thread_id": "1"}}
result = agent.invoke({"messages": [{"role": "user", "content": "帮我查询一下有关deepagents框架的最新动态"}]}, config=config)
print(result["messages"][-1].content)
三、 create_deep_agent 内部结构
链接到标题
- 源码参数截图
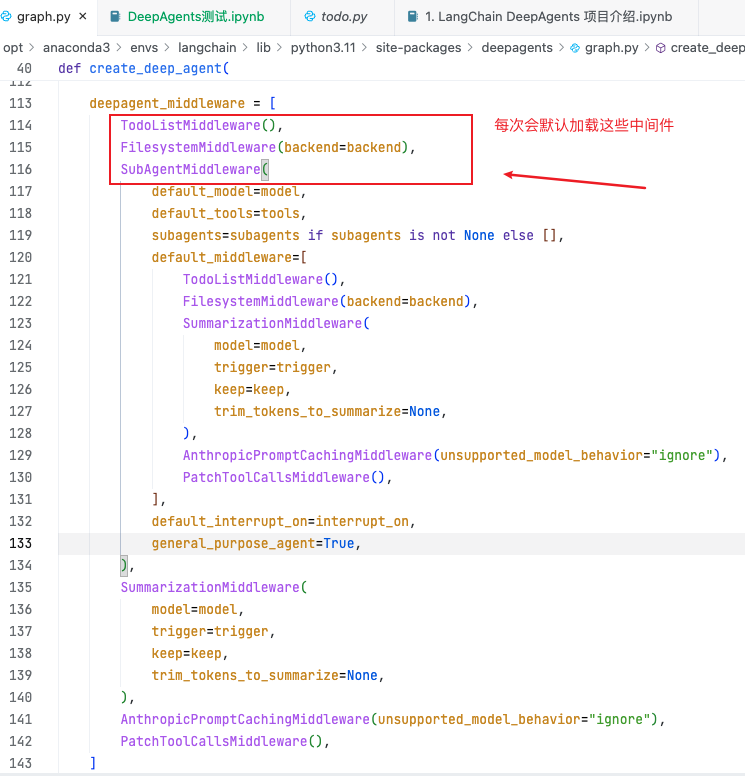
# 安装美化代码库Rich
!pip install rich
# 导入Rich库,用于美化代码
from rich.console import Console
from rich.table import Table
from rich.panel import Panel
RICH_AVAILABLE = True
console = Console()
def print_agent_tools(agent):
"""
打印 Agent 中加载的所有工具
包括用户自定义工具、文件系统工具、系统工具等
"""
# 获取 agent 的 nodes (LangGraph 的节点)
if hasattr(agent, 'nodes') and 'tools' in agent.nodes:
tools_node = agent.nodes['tools']
# tools_node 是 PregelNode,真正的 ToolNode 在 bound 属性中
if hasattr(tools_node, 'bound'):
tool_node = tools_node.bound
# 从 ToolNode 获取工具
if hasattr(tool_node, 'tools_by_name'):
tools = tool_node.tools_by_name
# 分类工具
user_tools = []
filesystem_tools = []
system_tools = []
for tool_name, tool in tools.items():
tool_info = {
'name': tool_name,
'description': getattr(tool, 'description', '无描述')
}
# 分类
if tool_name in ['ls', 'read_file', 'write_file', 'edit_file', 'glob', 'grep', 'execute']:
filesystem_tools.append(tool_info)
elif tool_name in ['write_todos', 'task']:
system_tools.append(tool_info)
else:
user_tools.append(tool_info)
# 打印加载工具的输出
_print_tools_rich(user_tools, filesystem_tools, system_tools)
else:
print("无法获取工具列表 (tools_by_name 不存在)")
else:
print("无法获取工具列表 (bound 属性不存在)")
else:
print("无法获取工具列表 (nodes 结构不符合预期)")
def _print_tools_rich(user_tools, filesystem_tools, system_tools):
"""使用 Rich 库美化打印工具列表"""
console.print()
# 创建表格
table = Table(title="Agent 加载的工具列表", show_header=True, header_style="bold magenta")
table.add_column("类别", style="cyan", width=20)
table.add_column("工具名称", style="green", width=20)
table.add_column("描述", style="white", width=60)
# 添加用户工具
for i, tool in enumerate(user_tools):
category = "用户工具" if i == 0 else ""
desc = tool['description'][:80] + "..." if len(tool['description']) > 80 else tool['description']
table.add_row(category, tool['name'], desc)
# 添加文件系统工具
for i, tool in enumerate(filesystem_tools):
category = "文件系统工具" if i == 0 else ""
desc = tool['description'][:80] + "..." if len(tool['description']) > 80 else tool['description']
table.add_row(category, tool['name'], desc)
# 添加系统工具
for i, tool in enumerate(system_tools):
category = "系统工具" if i == 0 else ""
desc = tool['description'][:80] + "..." if len(tool['description']) > 80 else tool['description']
table.add_row(category, tool['name'], desc)
console.print(table)
# 打印统计
total = len(user_tools) + len(filesystem_tools) + len(system_tools)
console.print(Panel(
f"[bold green]共计 {total} 个工具[/bold green]\n\n"
f"• 用户工具: {len(user_tools)} 个\n"
f"• 文件系统工具: {len(filesystem_tools)} 个\n"
f"• 系统工具: {len(system_tools)} 个",
title="统计信息",
border_style="green"
))
console.print()
print_agent_tools(agent)
这里可以看到,除了自己定义的工具(如 Tavily 搜索),DeepAgents 还默认添加了一些其他工具:
文件系统中间件(FileSystemMiddleware): 用于读写、查询、执行文件系统中的文件。
待办事项中间件(TodoListMiddleware): write_todos 用于写入待办事项,task 用于创建子agent来执行待办事项。
这些都是 DeepAgents 特有的功能,用于支持智能体在实际应用中的各种场景。那么,接下来我们来看看这些功能的具体应用。
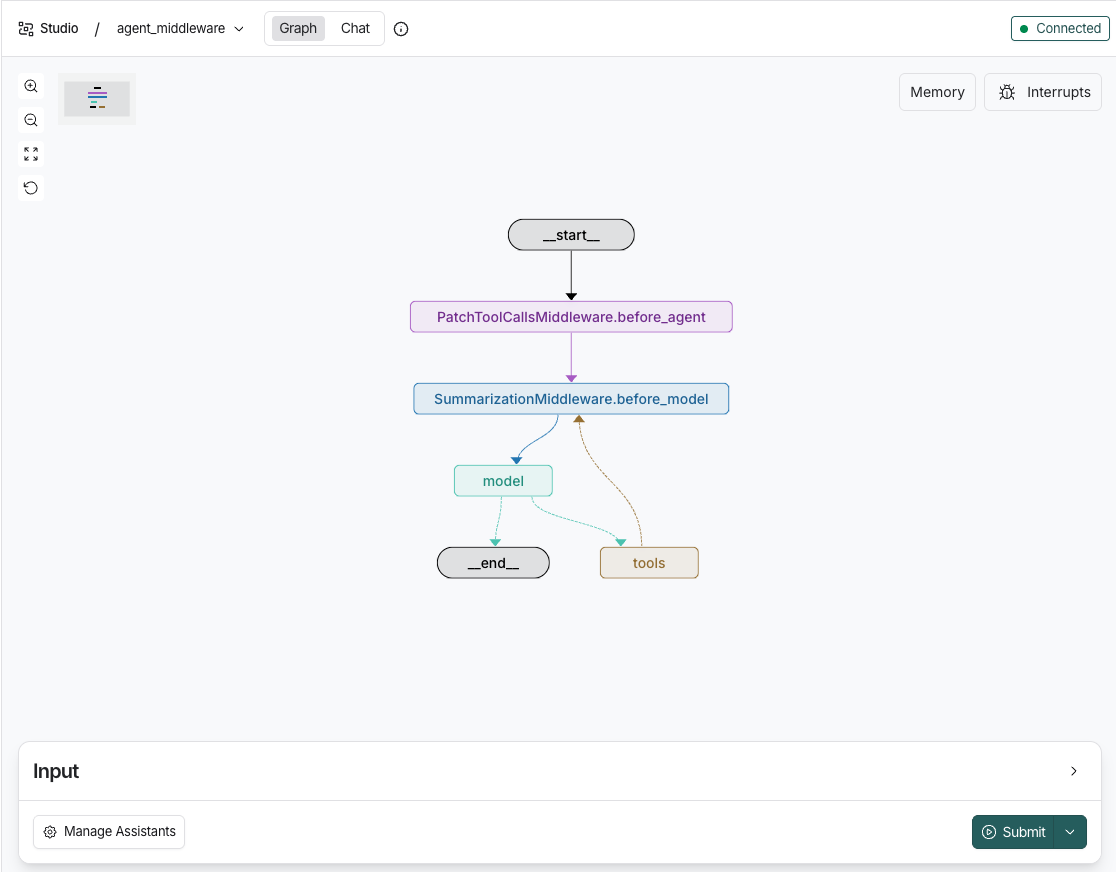
Langgraph Studio 中可视化结构图:能看到
PatchToolCallsMiddleware用于 自动检测并修复“悬空”的工具调用 的关键中间件,确保工具调用的完整性和正确性。
SummarizationMiddleware上下文压缩中间件,防止上下文过长
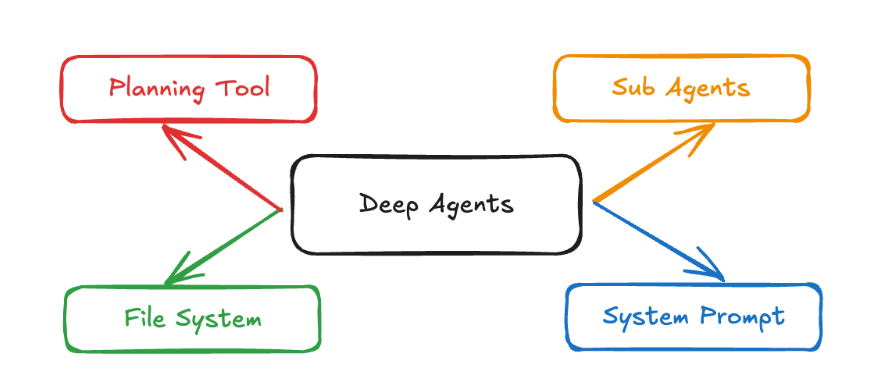
第四阶段、 四大核心内置工具与组件详解 链接到标题
DeepAgents 通过中间件 (Middleware) 的形式,为智能体注入了四项核心能力,构成了框架的四大支柱(Four Pillars):
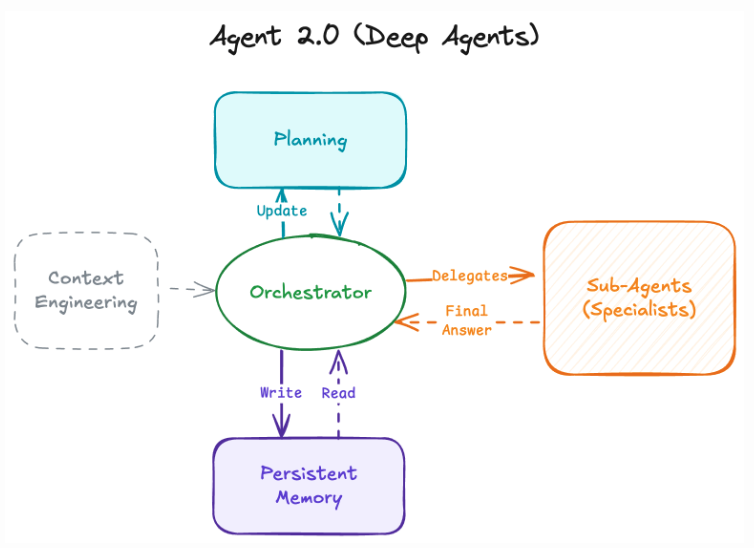
DeepAgents四大内置工具通过角色分离、状态贯通、成本优化的设计哲学,将长周期Agent的开发复杂度降低70%以上,同时通过LangGraph运行时保障生产级可靠性。其核心价值在于将原本需要手动编排的规划-存储-委托-执行流程,固化为中心化、可复用、可观测的中间件体系,标志着AI Agent从"脚本化"向"产品化"的关键演进。
- 协同价值:系统提示词确保质量,规划工具保证进度,文件系统实现数据共享,子代理隔离分析风险,四者形成高可靠、可追溯、可恢复的完整闭环。
| 维度 | 系统提示词 (System Prompt) | 规划工具 (Planning Tool) | 文件系统 (File System) | 子代理 (Sub Agents) |
|---|---|---|---|---|
| 角色定位 | 行为总导演:定义Agent的"世界观"与工具使用范式,确保三大中间件协同不偏离目标 | 任务架构师:将模糊需求转化为可执行、可追踪、可动态调整的结构化任务蓝图 | 上下文仓库:虚拟化存储引擎,解决长任务中的信息溢出与状态持久化难题 | 执行特派员:实现上下文隔离与专业分工,防止主Agent因深层递归导致状态混乱 |
| 核心功能 | 内置Claude Code风格指令,涵盖规划逻辑、文件操作规范、子代理调用协议;支持场景化自定义覆盖 | write_todos: 生成带优先级/依赖关系的JSON任务列表read_todos: 实时查询任务执行进度与状态 | ls/glob: 文件浏览与模式匹配read/write/edit: CRUD操作grep: 内容检索execute: 沙箱命令执行 | task: 动态生成同构或异构子Agent支持独立上下文窗口与工具集配置结果通过文件系统回传 |
| 技术实现 | 字符串模板,在create_deep_agent时注入;默认提示词约2000 tokens,包含ReAct循环与三大中间件调用示例 | TodoListMiddleware:拦截LLM输出中的todo_list字段,解析为agent_state.todos字典,状态变更触发图节点重计算 | FilesystemMiddleware:基于LangGraph State的files字段实现内存级虚拟文件系统,大工具结果(>2KB)自动触发write_file落盘 | SubAgentMiddleware:将task调用编译为独立的StateGraph子图,通过命名空间隔离状态,父图通过files读取子图输出 |
| 状态管理 | 静态配置,单次会话内不可变;可通过configurable_agent实现热更新 | 动态状态机:每个todo含id/description/status/priority/dependencies字段,执行后状态从pending→completed,支持update_todos动态调整 | 持久化存储:默认存储在LangGraph State,支持切换StateBackend(内存/Redis/Postgres)实现跨会话文件共享 | 完全隔离:子Agent拥有独立的messages和files命名空间,异常不会污染父Agent状态;支持max_iterations限制防止无限递归 |
| 使用场景 | ① 垂直领域定制:金融研究/医疗诊断等需强化专业约束的场景② 多Agent协作:统一多个子Agent的行为规范③ 安全合规:注入数据脱敏、权限检查等硬性规则 | ① 长周期研究:自动拆解为文献检索→数据收集→分析→撰写的阶段性任务② 故障恢复:崩溃后通过read_todos快速定位断点续跑③ 动态重规划:执行中发现信息不足时新增补充任务 | ① 大结果处理:搜索返回100KB内容自动落盘,避免上下文溢出② 知识沉淀:中间分析结果写入文件供后续步骤复用③ 多Agent数据共享:父Agent与子Agent通过文件交换数据,无需序列化传递 | ① 高风险操作隔离:网页抓取/代码执行等易失败任务委托给子Agent② 专业化分工:主Agent负责任务编排,子Agent专注领域执行(如专门的数据分析Agent)③ 资源优化:子Agent可使用轻量化模型,降低整体token成本 |
一、 系统提示词 (System Prompts) 链接到标题
功能:定义 Agent 的“人设”、行为准则和核心目标。
机制:框架会自动将用户定义的
system_prompt与内置的BASE_AGENT_PROMPT结合。作用:确保 Agent 始终遵循指令,理解其可用的工具集,并保持一致的输出风格。
角色本质:系统提示词是DeepAgents三大中间件协同的"契约",其默认版本包含:
规划指令:要求LLM在任务开始前必须调用write_todos,输出格式为JSON Schema
文件操作规范:明确write_file用于新内容,edit_file用于局部修改,避免覆盖冲突
子代理调用协议:规定task工具的参数结构及结果通过/subagent_results/.md回传
安全底线:禁止直接执行删除、格式化等危险命令,必须通过execute沙箱
FileSystem_System_prompt 文件系统提示词 链接到标题
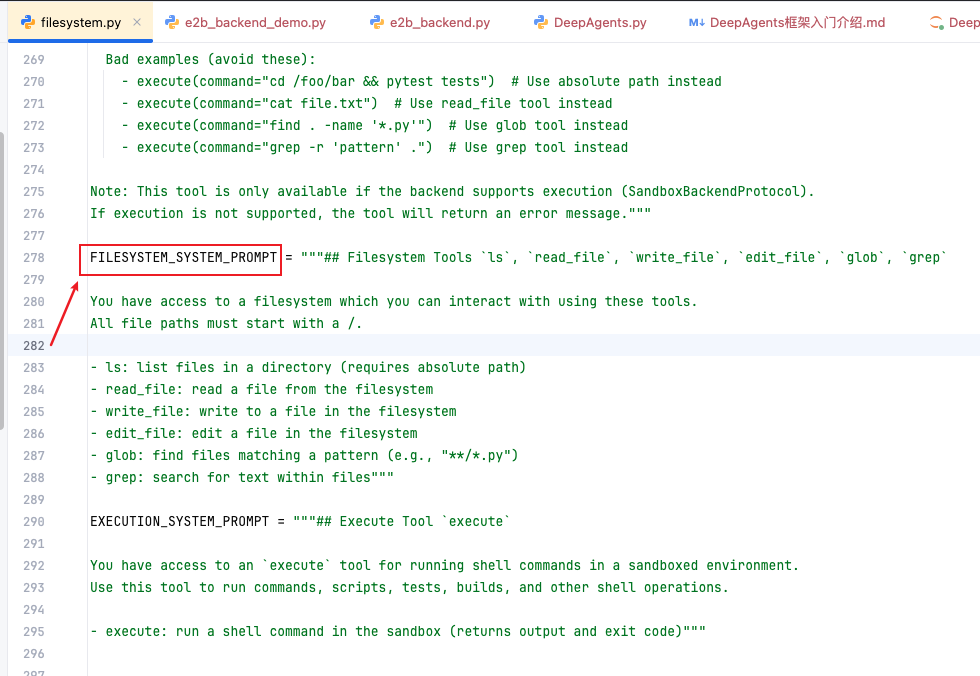
Execute_Tool_Descriptition 执行工具提示词 链接到标题
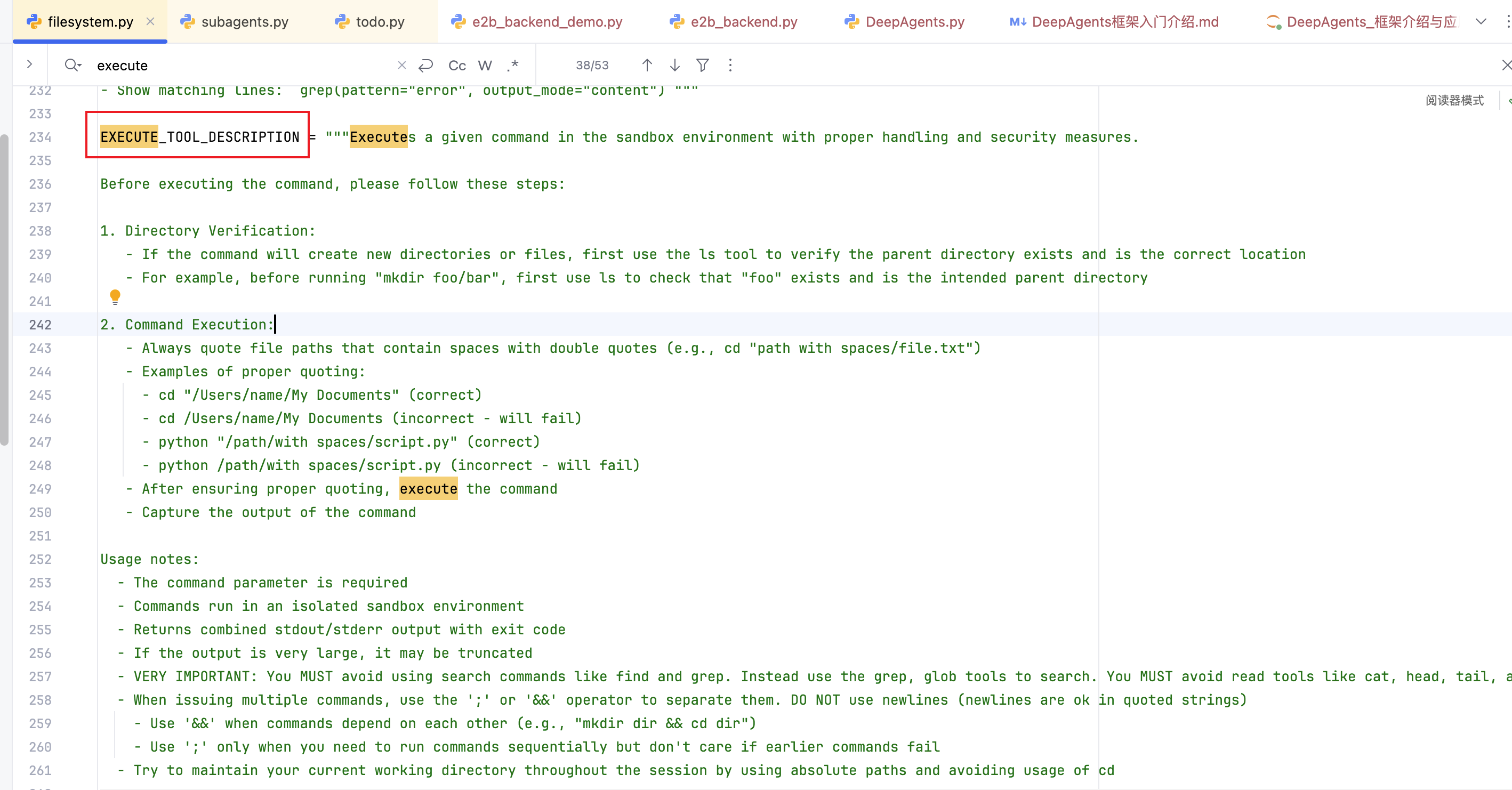
文件系统中间件提示词(FileSystemMiddleWare)
文件路径:deepagents/middleware/filesystem.py
Write_Todos_System_prompt 写执行任务提示词 链接到标题
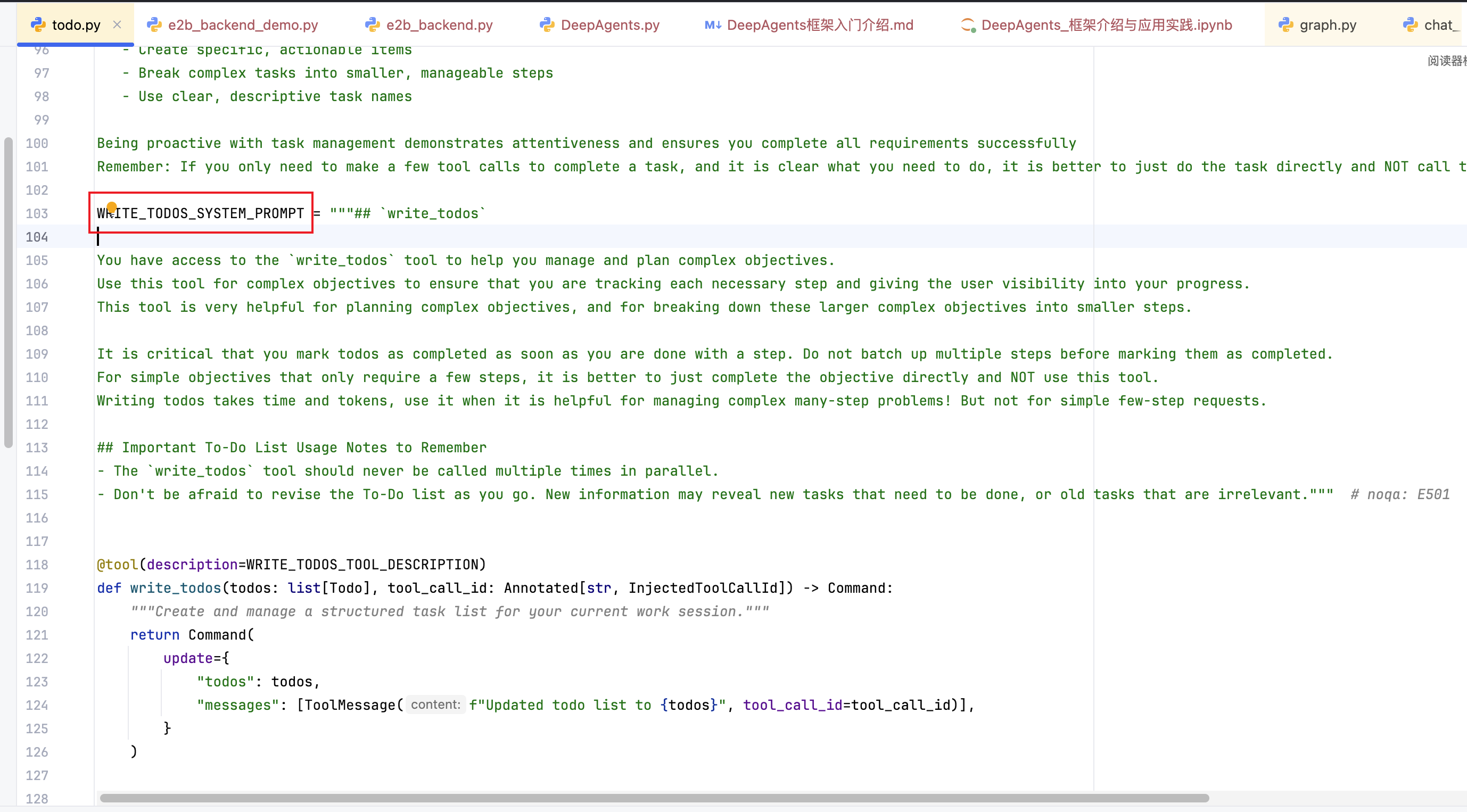
TodoList中间件提示词(TodoListMiddleware)
文件路径:deepagents/middleware/todo.py
Task_System_prompt Task执行器提示词 链接到标题
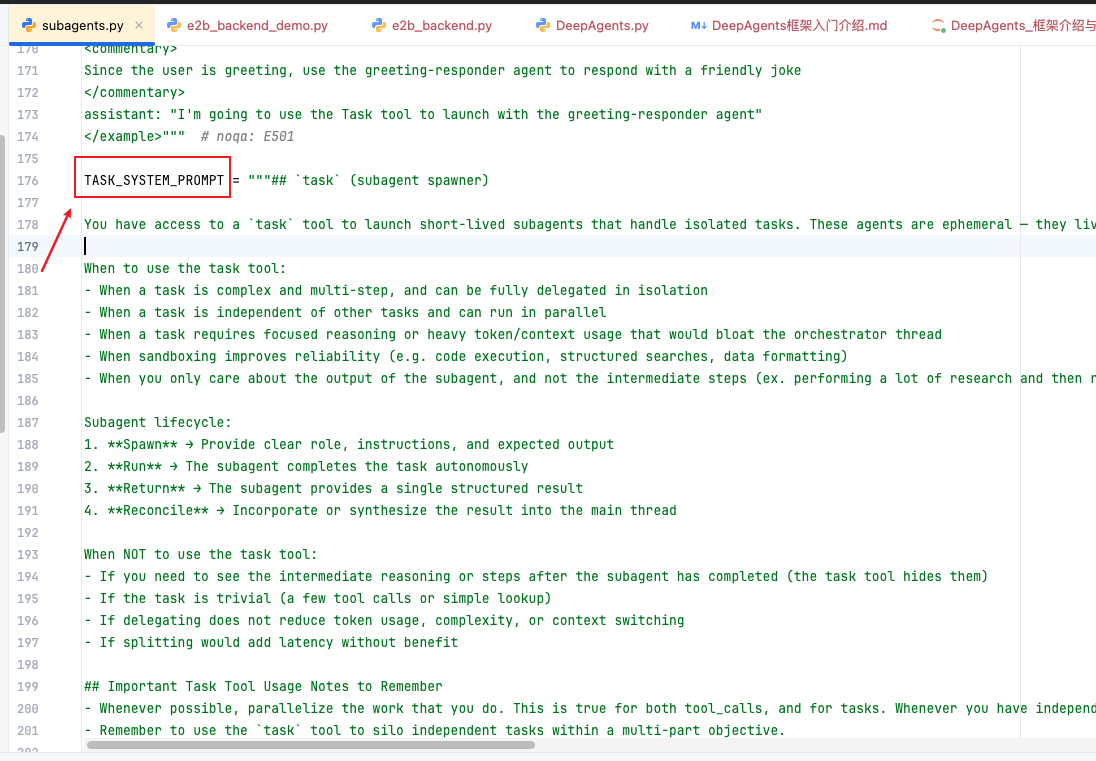
子智能体中间件提示词(SubAgentMiddleware)
文件路径:deepagents/middleware/subagent.py
二、 规划工具 (Planning System / Todo List) 链接到标题
组件:
TodoListMiddleware工具名:
write_todos功能:Agent 在行动前先生成 Markdown 格式的待办事项列表 (Todo List),并在执行过程中更新状态(完成/进行中)。
工作流:
Agent 接收复杂任务(简单短期的任务不会触发todolist)。
调用
write_todos将任务拆解为子步骤 (Pending)。每完成一步,更新状态为 (Completed)。
自我反思:在每一步行动前,Agent 都会看到当前的 Todo List,从而避免迷失方向。这强制模型进行"思维链"的显性化管理。
- 类似编程工具中的待执行项

import json
from rich.json import JSON
def debug_agent(query: str, save_to_file: str = None):
"""
运行智能体并打印中间过程(使用 Rich 美化输出)
参数:
query: 用户查询
save_to_file: 保存最终输出到文件(可选)
返回:
str: 最终的研究报告
"""
console.print(Panel.fit(
f"[bold cyan]查询:[/bold cyan] {query}",
border_style="cyan"
))
step_num = 0
final_response = None
config = {"configurable": {"thread_id": "2"}}
# 实时流式输出
for event in agent.stream(
{"messages": [{"role": "user", "content": query}]},
stream_mode="values",
config=config
):
step_num += 1
console.print(f"\n[bold yellow]{'─' * 80}[/bold yellow]")
console.print(f"[bold yellow]步骤 {step_num}[/bold yellow]")
console.print(f"[bold yellow]{'─' * 80}[/bold yellow]")
if "messages" in event:
messages = event["messages"]
if messages:
msg = messages[-1]
# 保存最终响应
if hasattr(msg, 'content') and msg.content and not hasattr(msg,'tool_calls'):
final_response = msg.content
# AI 思考
if hasattr(msg, 'content') and msg.content:
# 如果内容太长,只显示前300字符作为预览
content = msg.content
if len(content) > 300 and not (hasattr(msg, 'tool_calls') and msg.tool_calls):
preview = content[:300] + "..."
console.print(Panel(
f"{preview}\n\n[dim](内容较长,完整内容将在最后显示)[/dim]",
title="[bold green]AI 思考[/bold green]",
border_style="green"
))
else:
console.print(Panel(
content,
title="[bold green]AI 思考[/bold green]",
border_style="green"
))
# 工具调用
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tool_call in msg.tool_calls:
tool_info = {
"工具名称": tool_call.get('name', 'unknown'),
"参数": tool_call.get('args', {})
}
console.print(Panel(
JSON(json.dumps(tool_info, ensure_ascii=False)),
title="[bold blue]工具调用[/bold blue]",
border_style="blue"
))
# 工具响应
if hasattr(msg, 'name') and msg.name:
response = str(msg.content)[:500]
if len(str(msg.content)) > 500:
response += f"\n... (共 {len(str(msg.content))} 字符)"
console.print(Panel(
response,
title=f"[bold magenta]工具响应: {msg.name}[/bold magenta]",
border_style="magenta"
))
console.print("\n[bold green]任务完成![/bold green]\n")
return final_response
print("调试函数已创建")
# 示例:使用调试函数运行研究任务
query = "详细调研 LangChain DeepAgents 框架的核心特性,并写一份结构化的总结报告。"
# 使用调试函数)
result = debug_agent(query)
三、 子代理 (Sub-Agent Delegation) 链接到标题
组件:
SubAgentMiddleware工具名:
task(delegate_task)核心概念:
任务隔离:每个子代理有独立的上下文窗口。
并行执行:支持同时启动多个子代理。
结果聚合:智能整合多个子代理的输出。
机制:
当任务过于具体(如"爬取并分析这篇长论文")时,主 Agent 会生成一个隔离环境的子 Agent 去执行。
子 Agent 启动时,只继承必要的环境配置,但拥有全新的、空白的消息历史。
子 Agent 执行完毕后只返回一个总结性的结果。这保证了主 Agent 的时间线(Context)保持干净,极大地节省了 Token。
自动触发默认的 SubAgentMiddleware 链接到标题
import asyncio
import os
from dotenv import load_dotenv
from rich.console import Console
from rich.panel import Panel
from rich.tree import Tree
from deepagents import create_deep_agent
from langchain_openai import ChatOpenAI
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import ToolMessage, BaseMessage
# 加载环境变量
load_dotenv(override=True)
# 配置 Rich Console
console = Console()
async def run_auto_subagent_demo():
"""
演示:不显式传入 subagents 参数,自动触发默认的 SubAgentMiddleware
"""
console.print(Panel.fit("[bold magenta]DeepAgents 自动 SubAgent 中间件演示[/bold magenta]", border_style="magenta"))
console.print("[dim]本演示验证:即使不传入 subagents 参数,Agent 默认也会启用 'general-purpose' 子 Agent。[/dim]")
# 1. 初始化模型
# 使用 GPT-4o 以确保对复杂指令的理解和工具调用的准确性
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 2. 定义工具
# 给 Agent 一些工具,以便子 Agent 也有工具可用
tools = [TavilySearchResults(max_results=2)]
# 3. 创建 Agent (不传入 subagents)
# create_deep_agent 默认会加载 SubAgentMiddleware(general_purpose_agent=True)
# 这意味着 Agent 会自动获得一个名为 'task' 的工具,可以调用 'general-purpose' 子 Agent
console.print("[bold cyan]正在创建 Agent (subagents=None)...[/bold cyan]")
agent = create_deep_agent(
model=llm,
tools=tools,
# subagents=[], # 故意不传或传空
system_prompt="""你是一个能够高效处理并发任务的智能助手。
对于包含多个独立部分的复杂任务,你必须使用 'task' 工具来创建 'general-purpose' 子 Agent 进行处理。
不要自己在主线程中串行执行所有操作。利用子 Agent 来隔离上下文并提高效率。"""
)
# 4. 定义一个适合并行/隔离的任务
task = """请同时调研以下两个完全不同的主题,并分别给出简短总结:
1. Python 语言的历史起源。
2. Rust 语言的内存安全机制。
请务必使用子 Agent 分别处理这两个任务。"""
console.print(f"\n[bold green]用户任务:[/bold green] {task}\n")
# 5. 运行并可视化
step = 0
# 检查 API Key
if not os.getenv("OPENAI_API_KEY"):
console.print("[bold red]❌ 错误: 未找到 OPENAI_API_KEY,请检查 .env 文件[/bold red]")
return
console.print("[dim]开始流式输出...[/dim]")
try:
async for event in agent.astream({"messages": [("user", task)]}):
step += 1
# 遍历所有节点输出 (e.g., 'agent', 'tools')
for node_name, node_data in event.items():
if node_data is None:
continue
if "messages" in node_data:
msgs = node_data["messages"]
# 确保是列表
if not isinstance(msgs, list):
msgs = [msgs]
for msg in msgs:
# 0. 过滤非消息对象
if not isinstance(msg, BaseMessage):
continue
# 1. 检测工具调用 (期望看到 'task' 工具)
if hasattr(msg, "tool_calls") and msg.tool_calls:
tree = Tree(f"[bold yellow]Step {step}: 决策与调用 (Node: {node_name})[/bold yellow]")
for tc in msg.tool_calls:
tool_name = tc['name']
tool_args = tc['args']
if tool_name == "task":
# 验证成功!
branch = tree.add(f"[bold red]🚀 触发 'task' 工具 (Sub-Agent)[/bold red]")
branch.add(f"[cyan]子 Agent 类型:[/cyan] {tool_args.get('subagent_type')}")
branch.add(f"[cyan]任务指令:[/cyan] {tool_args.get('description')}")
else:
tree.add(f"[blue]普通工具调用:[/blue] {tool_name}")
console.print(tree)
# 2. 检测工具输出 (Sub-Agent 的返回结果)
elif isinstance(msg, ToolMessage):
if msg.name == "task":
# Sub-Agent 完成任务返回
panel = Panel(
msg.content,
title=f"[bold magenta]Sub-Agent 完成任务 (Node: {node_name})[/bold magenta]",
border_style="magenta"
)
console.print(panel)
else:
console.print(f"[dim]Tool Output ({msg.name}): {msg.content[:100]}...[/dim]")
# 3. 检测 AI 最终回复
elif msg.content and not msg.tool_calls:
title = f"[bold green]Agent 回复 (Node: {node_name})[/bold green]"
console.print(Panel(msg.content, title=title, border_style="green"))
except Exception as e:
console.print(f"[bold red]❌ 运行时错误: {e}[/bold red]")
console.print("\n[bold magenta]演示结束[/bold magenta]")
if __name__ == "__main__":
await run_auto_subagent_demo()
显示传入subAgent参数 链接到标题
# 安装 MCP 适配器(关键依赖)\MCP 服务器开发库(如需自定义工具)
#!pip install langchain-mcp-adapters mcp
检查 Node.js
- node –version
检查 npm/npx
- npx –version
手动安装 MCP 服务器包
- npm install -g @amap/amap-maps-mcp-server
import asyncio
import os
from dotenv import load_dotenv
from rich.console import Console
from rich.panel import Panel
from rich.tree import Tree
from deepagents import create_deep_agent
from langchain_deepseek import ChatDeepSeek
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import ToolMessage, BaseMessage
# 加载环境变量
load_dotenv(override=True)
# 1. 配置 Rich Console
console = Console()
# 2. 配置 Context7 MCP (连接官方文档)
async def setup_mcp_tools():
console.print("[dim]正在连接 Context7 MCP 服务器...[/dim]")
# 检查 node 环境
try:
client = MultiServerMCPClient({
"context7": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"],
}
})
# 获取工具
tools = await client.get_tools()
console.print(f"[green]成功加载 {len(tools)} 个 MCP 工具[/green]")
return client, tools
except Exception as e:
console.print(f"[red]连接 MCP 失败: {e}[/red]")
console.print("[yellow]将使用模拟工具继续...[/yellow]")
return None, []
# 3. 定义子 Agent 配置
def get_subagents_config(mcp_tools):
# 子 Agent 1: 官方文档专家
doc_tools = mcp_tools if mcp_tools else [TavilySearchResults(max_results=3)]
docs_researcher = {
"name": "DocsResearcher",
"description": "负责查阅官方文档和技术规范的专家 Agent。",
"system_prompt": "你是一名专门查阅官方文档的技术专家。请使用工具获取准确的技术细节。不要猜测。",
"tools": doc_tools,
"model": "deepseek-chat"
}
# 子 Agent 2: 社区生态专家
community_researcher = {
"name": "CommunityResearcher",
"description": "负责搜索社区博客、教程和最佳实践的专家 Agent。",
"system_prompt": "你是一名关注社区动态的开发者。请搜索博客、论坛和 GitHub 讨论。",
"tools": [TavilySearchResults(max_results=3)],
"model": "deepseek-chat"
}
return [docs_researcher, community_researcher]
# 4. 主运行逻辑
async def run_parallel_demo():
console.print(Panel.fit("[bold blue]DeepAgents 并行子 Agent 演示[/bold blue]", border_style="blue"))
# 初始化 MCP
mcp_client, mcp_tools = await setup_mcp_tools()
# 获取子 Agent 配置
subagents = get_subagents_config(mcp_tools)
# 创建主 Agent
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
agent = create_deep_agent(
model=llm,
tools=[],
subagents=subagents, # 传入子 Agent 配置
system_prompt="""你是一名技术总监。你的任务是协调 DocsResearcher 和 CommunityResearcher 完成调研任务。
请根据用户需求,将任务拆解并分发给这两个子 Agent。
如果任务允许,请务必并行调用它们以提高效率。
最后汇总它们的报告。"""
)
task = "请详细调研 'LangChain DeepAgents' 框架。我需要官方的技术架构说明(来自文档)以及社区的最佳实践案例。请对比两者。"
console.print(f"\n[bold green]任务指令:[/bold green] {task}\n")
# 运行并可视化
step = 0
try:
async for event in agent.astream({"messages": [("user", task)]}):
step += 1
# 遍历所有节点输出 (e.g., 'agent', 'tools')
for node_name, node_data in event.items():
if node_data is None:
continue
if "messages" in node_data:
msgs = node_data["messages"]
# 确保是列表
if not isinstance(msgs, list):
msgs = [msgs]
for msg in msgs:
# 0. 过滤非消息对象
if not isinstance(msg, BaseMessage):
continue
# 1. 检测工具调用 (期望看到 'task' 工具)
if hasattr(msg, "tool_calls") and msg.tool_calls:
tree = Tree(f"[bold yellow]Step {step}: 决策与调用 (Node: {node_name})[/bold yellow]")
for tc in msg.tool_calls:
tool_name = tc['name']
tool_args = tc['args']
if tool_name == "task":
# 验证成功!
branch = tree.add(f"[bold red]🚀 触发 'task' 工具 (Sub-Agent)[/bold red]")
branch.add(f"[cyan]子 Agent 类型:[/cyan] {tool_args.get('subagent_type')}")
branch.add(f"[cyan]任务指令:[/cyan] {tool_args.get('description')}")
else:
tree.add(f"[blue]普通工具调用:[/blue] {tool_name}")
console.print(tree)
# 2. 检测工具输出 (Sub-Agent 的返回结果)
elif isinstance(msg, ToolMessage):
if msg.name == "task":
# Sub-Agent 完成任务返回
panel = Panel(
msg.content,
title=f"[bold magenta]Sub-Agent 完成任务 (Node: {node_name})[/bold magenta]",
border_style="magenta"
)
console.print(panel)
else:
console.print(f"[dim]Tool Output ({msg.name}): {msg.content[:100]}...[/dim]")
# 3. 检测 AI 最终回复
elif msg.content and not msg.tool_calls:
title = f"[bold green]Agent 回复 (Node: {node_name})[/bold green]"
console.print(Panel(msg.content, title=title, border_style="green"))
except Exception as e:
console.print(f"[bold red]❌ 运行时错误: {e}[/bold red]")
console.print("\n[bold blue]演示结束[/bold blue]")
# 运行演示
if __name__ == "__main__":
await run_parallel_demo()
第四阶段、 文件系统集成 (Filesystem & Sandbox) 链接到标题
组件:
FilesystemMiddleware&Backend功能:这是 DeepAgent 的核心"外挂大脑"。Agent 不再将所有检索到的长文塞入上下文(Context),而是将其写入 Filesystem(如
/workspace),仅在需要时读取。这极大地扩展了 Agent 的"工作记忆"。核心工具集:
ls: 浏览目录结构。read_file: 读取文件内容。关键封装:支持offset(偏移量)和limit(行数),强制 Agent 对大文件进行分页读取,避免一次性读爆上下文。write_file: 创建新文件。edit_file: 修改文件。支持精确的字符串替换和replace_all模式,并有防呆设计(要求先读后改)。glob: 通配符模糊查找文件。grep: 正则表达式搜索文件内容,像命令行一样在代码库中定位目标。execute: 执行 Shell 命令(需 Sandbox 支持),用于运行代码、安装依赖等。
亮点功能:大结果自动转存
- 当 Agent 调用工具产生的结果过长时,系统会自动拦截,将完整结果写入文件系统(如
/large_tool_results/{id}),并只给 Agent 返回一个摘要和文件路径。这完美解决了搜索结果或日志文件过长导致 Agent 崩溃的问题。
- 当 Agent 调用工具产生的结果过长时,系统会自动拦截,将完整结果写入文件系统(如
后端支持 (Backends):
FilesystemBackend: 直接操作本地磁盘。
DockerBackend: 在 Docker 容器中执行,提供隔离环境。
StoreBackend: 存储在数据库中,支持查询和检索。
E2BBackend: 使用 E2B 云端沙箱。
CompositeBackend: 混合模式(如:本地存文件,Docker 跑代码)。
一、 核心工具集测试 链接到标题
# --- FilesystemMiddleware 工具测试 ---
print("\n" + "="*50)
print("🚀 开始测试 FilesystemMiddleware 工具集")
print("="*50 + "\n")
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
# 1. 初始化环境
load_dotenv(override=True)
model = ChatOpenAI(model="gpt-4o", temperature=0)
# 使用本地文件系统后端,根目录设为 ./workspace
# 这样我们可以看到真实文件的创建
# 注意:设置 virtual_mode=True 以支持绝对路径 (如 /hello_world.py) 映射到 ./workspace
backend = FilesystemBackend(root_dir="./workspace", virtual_mode=True)
# 创建 Agent
# 注意:create_deep_agent 默认会自动包含 FilesystemMiddleware
agent = create_deep_agent(
model=model,
backend=backend,
system_prompt="你是一个文件系统操作助手。请根据用户指令使用相应的工具。"
)
# 辅助函数:运行并打印结果
def run_test(task_name, instruction):
print(f"\n🔹 [测试: {task_name}]")
print(f"指令: {instruction}")
try:
# 使用 invoke 而不是 stream 以简化输出
result = agent.invoke({"messages": [("user", instruction)]})
last_msg = result["messages"][-1]
print(f"🤖 Agent 回复: {last_msg.content}")
# 打印工具调用详情 (如果有)
for msg in result["messages"]:
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tool in msg.tool_calls:
print(f"🛠️ 调用工具: {tool['name']} args={tool['args']}")
except Exception as e:
print(f"❌ 发生错误: {e}")
write_file 测试 链接到标题
# 2. 依次测试各个工具
# 案例 1: write_file
# 创建一个 Python 脚本文件
run_test("write_file",
"请在当前目录下创建一个名为 'hello_world.py' 的文件,内容是:\nprint('Hello from DeepAgents!')")
ls 测试 链接到标题
# 案例 2: ls
# 查看目录内容,确认文件创建成功
run_test("ls", "请列出当前目录下的所有文件,确认 hello_world.py 是否存在。")
read_file 测试 链接到标题
# 案例 3: read_file
# 读取刚才创建的文件内容
run_test("read_file", "请读取 'hello_world.py' 的内容并展示给我。")
edit_file 测试 链接到标题
# 案例 4: edit_file
# 修改文件内容
run_test("edit_file",
"请修改 'hello_world.py' 文件,将 print 内容改为 'Hello from Modified File!'。")
grep 测试 链接到标题
# 案例 5: grep
# 搜索文件中的特定字符串
run_test("grep", "请在当前目录下搜索包含 'Modified' 字符串的文件。")
glob 测试 链接到标题
# 案例 6: glob
# 使用通配符查找文件
run_test("glob", "请找出当前目录下所有的 .py 文件。")
execute 测试 链接到标题
# 案例 7: execute
# 尝试执行脚本
# 注意:execute 工具通常需要 SandboxBackend 支持。
# 如果当前使用的 FilesystemBackend 不支持执行,Agent 会收到错误提示或无法调用。
print("\n🔹 [测试: execute]")
print("指令: 尝试运行 hello_world.py 脚本")
try:
# 我们尝试强行要求 Agent 运行,看它如何反应
# 如果没有 execute 工具,Agent 可能会说无法执行
response = agent.invoke({"messages": [("user", "请使用 execute 工具运行 python hello_world.py")]})
print(f"🤖 Agent 回复: {response['messages'][-1].content}")
except Exception as e:
print(f"⚠️ 测试说明: execute 工具可能不可用 (取决于 Backend 支持): {e}")
print("\n" + "="*50)
print("✅ 测试结束")
能看到在FilesystemBackend下,没有execute方法,因为FilesystemBackend是一个文件系统后端,不支持执行Shell命令。接下来,我们测试一下其他后端。
二、Backend 后端应用 链接到标题
1、默认模式(内存沙箱) 链接到标题
- 内存沙箱,支持在内存中执行代码,防止代码注入攻击。代码执行结果会被存储在内存中,不会对本地环境造成影响。执行结束后,内存中的数据会被清除。
from deepagents import create_deep_agent
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# 加载环境变量
load_dotenv(override=True)
# 定义 LLM
model = ChatOpenAI(model="gpt-4o", temperature=0)
# 默认情况下,DeepAgent 会自动加载 FilesystemMiddleware 并使用内存后端
agent = create_deep_agent(
model=model,
system_prompt="你是一个数据处理助手。"
)
# Agent 可以自由创建文件、读取文件,但这些文件只存在于内存中
# 任务结束后,这些文件会自动消失
agent.invoke({"messages": [("user", "创建一个名为 test.txt 的文件并写入 'Hello, World!'")]})
result = agent.invoke({"messages": [("user", "读取 test.txt 文件的内容")]})
print(result["messages"][-1].content)
2、持久化模式(操作真实文件) 链接到标题
- 持久化沙箱,支持将代码执行结果持久化到本地磁盘,防止代码执行过程中数据丢失。代码执行结束后,内存中的数据会被清除,但是磁盘上的文件会被保留。
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o", temperature=0)
# 将 Agent 的根目录映射到本地的 "./workspace" 文件夹,virtual_mode=True 表示启用虚拟文件系统,作用是将 Agent 执行的所有文件操作都映射到本地的 "./workspace" 文件夹,而不是直接操作本地文件系统。
backend = FilesystemBackend(root_dir="./workspace", virtual_mode=True)
agent = create_deep_agent(
model=model,
backend=backend # 传入后端,中间件会自动使用它
)
# 此时 Agent 执行 write_file("/readme.md", ...) 会在本地 ./workspace/readme.md 创建文件
agent.invoke({"messages": [("user", "创建一个名为 readme.md 的文件并写入 'Hello, World!'")]})
result = agent.invoke({"messages": [("user", "读取 readme.md 文件的内容")]})
print(result["messages"][-1].content)
3、演示大文件读取分页 链接到标题
- 在FilesystemBackend分页的参数是固定死的,默认每次读取500行,我们可以在系统提示词中指定每次读取的行数。
import asyncio
import os
import shutil
from pathlib import Path
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, ToolMessage
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
load_dotenv(override=True)
# 定义工作目录
WORK_DIR = Path("workspace/pagination_demo").resolve()
LARGE_FILE_NAME = "server_logs.txt"
LARGE_FILE_PATH = WORK_DIR / LARGE_FILE_NAME
TARGET_SECRET = "CRITICAL_ERROR_CODE_998877"
async def run_pagination_demo():
print("\n" + "="*80)
print("DeepAgents FilesystemMiddleware 分页读取演示")
print("="*80)
# 2. 初始化 FilesystemBackend
# 将 backend 指向我们的测试目录
# virtual_mode=True 确保 Agent 只能访问该目录下的文件,不能访问宿主机其他目录
backend = FilesystemBackend(root_dir=WORK_DIR, virtual_mode=True)
# 3. 创建 Agent
# 我们明确指示 Agent 使用分页读取,每次读取 300 行,Agent默认每次读取500行(DEFAULT_READ_LIMIT)
system_prompt = """
你是一个专业的系统管理员。
你的任务是从日志文件中查找特定的错误代码。
注意:日志文件可能非常大,为了避免上下文溢出,你必须使用 `read_file` 工具的分页功能。
每次读取请限制在 300 行以内 (limit=300),并使用 offset 参数向后滚动。
直到找到目标信息为止。
"""
llm = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_deep_agent(
model=llm,
backend=backend,
system_prompt=system_prompt
)
task = f"请在 '/{LARGE_FILE_NAME}' 中查找包含 '{TARGET_SECRET}' 的行,并告诉我它的具体内容。"
print(f"\n任务: {task}")
print("-" * 60)
# 4. 执行任务并观察分页行为
step = 0
print("\n开始流式输出...")
try:
async for event in agent.astream({"messages": [("user", task)]}):
for node_name, node_data in event.items():
# debug: print(f"DEBUG: Node: {node_name}")
if not node_data: continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
msgs = node_data["messages"]
if hasattr(msgs, "value"):
msgs = msgs.value
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
# 1. 打印 Agent 的思考 (AIMessage with tool_calls)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}] Agent 决定调用工具 (Node: {node_name}):")
for tc in msg.tool_calls:
name = tc['name']
args = tc['args']
print(f" >>> 工具: {name}")
if name == "read_file":
offset = args.get('offset', 0)
limit = args.get('limit', 'Default')
path_val = args.get('path') or args.get('file_path')
print(f" >>> 参数: path='{path_val}', offset={offset}, limit={limit}")
print(f" (说明: 正在读取从第 {offset} 行开始的 {limit} 行数据)")
else:
print(f" >>> 参数: {args}")
# 2. 打印工具的输出 (ToolMessage)
elif isinstance(msg, ToolMessage):
content = msg.content
line_count = len(content.splitlines())
# 检查是否包含目标 Secret
found_secret = TARGET_SECRET in content
preview = content[:100].replace('\n', ' ') + "..."
print(f"\n[Tool Output] (Node: {node_name}) 读取了 {line_count} 行数据")
print(f" 内容预览: {preview}")
if found_secret:
print(f" ✨ 成功: 在此分块中发现了目标 Secret: {TARGET_SECRET}")
# 3. 打印 Agent 的最终回复 (AIMessage without tool_calls)
elif isinstance(msg, BaseMessage) and msg.type == "ai" and msg.content:
print(f"\n[Agent 最终回复] (Node: {node_name}):")
print("-" * 40)
print(msg.content)
print("-" * 40)
except Exception as e:
print(f"❌ 运行出错: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
await run_pagination_demo()
4、 E2BBackend 使用E2B云沙箱 链接到标题
E2B (Environment To Be) 是一个 专为 AI 智能体设计的云端安全执行环境 。
你可以把它想象成一台 云端电脑 或 远程服务器 ,DeepAgents 将其作为“外挂大脑”和“执行手脚”。当 AI 需要写代码、运行脚本或操作文件时,它不会在你的本地机器上操作,而是连接到 E2B 的云端环境中进行。
- 核心特性
安全性与隔离性 (Security & Isolation) :
- AI 生成的代码(可能包含错误或恶意逻辑)完全运行在云端沙箱中, 绝不会破坏你本地的电脑环境 。
- 演示代码中,Agent 即使执行了 rm -rf / ,也只是删除了云端临时的沙箱,对宿主机毫发无损。
持久化会话 (Long-running Sessions) :
- 沙箱可以保持运行状态。Agent 可以先创建一个文件(如演示中的 /home/user/hello.py ),然后在后续步骤中运行它。环境状态在会话期间是保持的。
标准 Linux 环境 :
- 它提供标准的 Linux Shell。演示中 Agent 执行了 uname -a 和 python –version ,就像在真实的服务器上一样。
step1: 访问 https://e2b.dev 注册登陆,然后并获取 API_Key
登陆后进入首页
在左侧选择API Keys选项,创建API
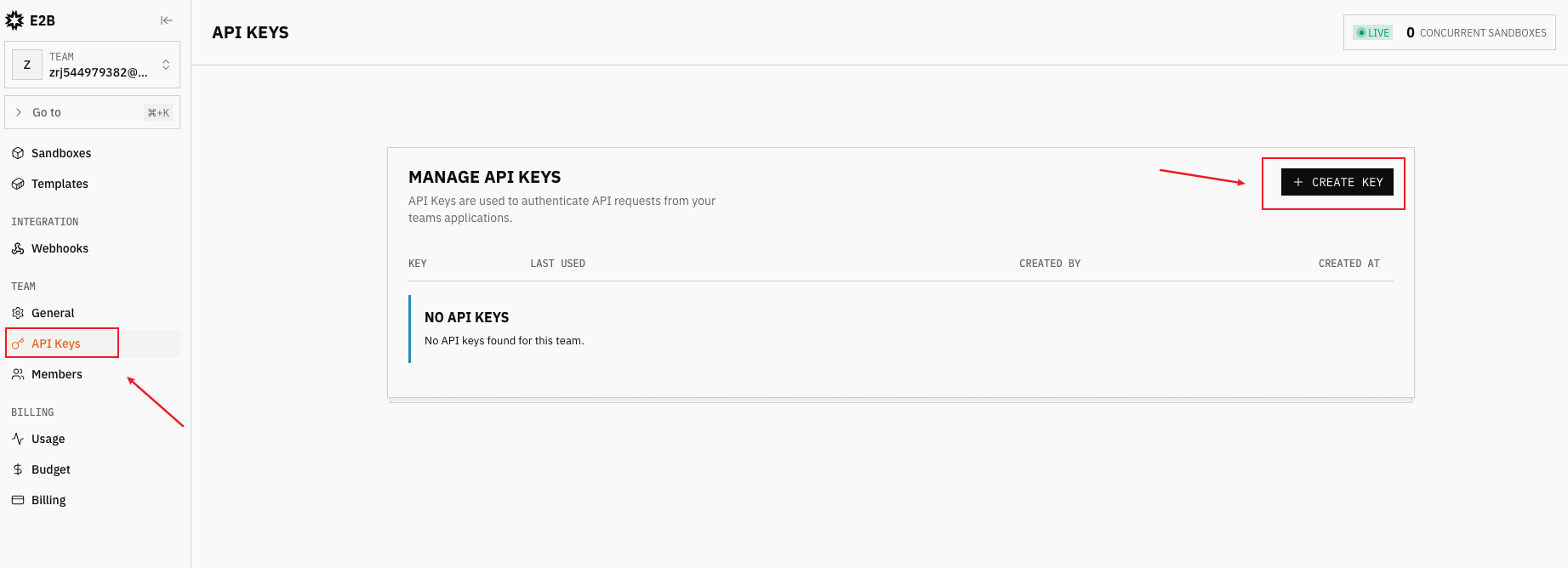
- 创建API Key后记得保存好,保存到.env文件中,作为:E2B_API_KEY
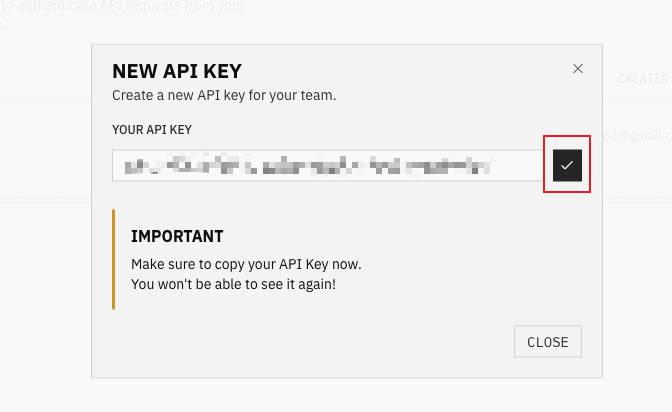
step2: 安装依赖
!pip install e2b
# 定义 E2B 沙箱后端类
# 该类继承自 BaseSandbox,实现了在 E2B 沙箱中执行命令的功能
import base64
from typing import Any, Optional
# 导入 DeepAgents 后端协议,定义了沙箱后端的接口
from deepagents.backends.protocol import (
ExecuteResponse,
FileDownloadResponse,
FileUploadResponse,
SandboxBackendProtocol,
)
# 导入基础沙箱类,用于实现沙箱后端的基本功能
from deepagents.backends.sandbox import BaseSandbox
try:
from e2b import Sandbox
except ImportError:
Sandbox = None
class E2BBackend(BaseSandbox):
"""E2B 沙箱后端实现,用于 DeepAgents。
该后端使用 E2B(https://e2b.dev)提供安全、隔离的执行环境。
"""
def __init__(
self,
template: str = "base",
api_key: Optional[str] = None,
timeout: Optional[int] = None,
metadata: Optional[dict[str, str]] = None,
) -> None:
"""初始化 E2B 沙箱。
参数:
template: E2B 沙箱模板 ID(默认:"base")
api_key: E2B API 密钥(可选,默认使用 E2B_API_KEY 环境变量)
timeout: 沙箱超时时间(秒)
metadata: 自定义沙箱元数据
"""
if Sandbox is None:
raise ImportError(
"e2b package is not installed. "
"Please install it with `pip install e2b`."
)
self.sandbox = Sandbox.create(
template=template,
api_key=api_key,
timeout=timeout,
metadata=metadata,
)
@property
def id(self) -> str:
"""Unique identifier for the sandbox backend."""
return self.sandbox.sandbox_id
def execute(self, command: str) -> ExecuteResponse:
"""Execute a command in the sandbox."""
try:
# E2B commands.run returns CommandResult with stdout, stderr, exit_code
result = self.sandbox.commands.run(command)
# 返回执行结果,包含 stdout 是标准输出,stderr 是标准错误输出,exit_code 是退出码
return ExecuteResponse(
output=result.stdout + result.stderr,
exit_code=result.exit_code,
truncated=False,
)
except Exception as e:
return ExecuteResponse(
output=f"Error executing command: {str(e)}",
exit_code=1,
truncated=False,
)
def upload_files(self, files: list[tuple[str, bytes]]) -> list[FileUploadResponse]:
"""Upload multiple files to the sandbox."""
responses = []
for path, content in files:
try:
# Ensure directory exists before writing
# We can use execute to mkdir -p
parent_dir = path.rsplit("/", 1)[0]
if parent_dir:
self.sandbox.commands.run(f"mkdir -p {parent_dir}")
# Write file
self.sandbox.files.write(path, content)
responses.append(FileUploadResponse(path=path, error=None))
except Exception as e:
error_msg = str(e).lower()
error = "invalid_path"
if "permission" in error_msg:
error = "permission_denied"
responses.append(FileUploadResponse(path=path, error=error))
return responses
def download_files(self, paths: list[str]) -> list[FileDownloadResponse]:
"""Download multiple files from the sandbox."""
responses = []
for path in paths:
try:
content = self.sandbox.files.read(path)
# Ensure content is bytes
if isinstance(content, str):
content = content.encode("utf-8")
responses.append(FileDownloadResponse(path=path, content=content, error=None))
except Exception as e:
error_msg = str(e).lower()
error = "invalid_path"
if "not found" in error_msg:
error = "file_not_found"
elif "directory" in error_msg:
error = "is_directory"
elif "permission" in error_msg:
error = "permission_denied"
responses.append(FileDownloadResponse(path=path, content=None, error=error))
return responses
def close(self):
"""Close the sandbox session."""
self.sandbox.kill()
- 将自定义好的沙箱后端类注册到 DeepAgents 中
import asyncio
import os
import sys
from dotenv import load_dotenv
from deepagents import create_deep_agent
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_core.messages import BaseMessage, ToolMessage
# 假设 e2b_backend.py 在同一目录下
try:
from e2b_backend import E2BBackend
except ImportError:
# 尝试从当前路径导入
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from e2b_backend import E2BBackend
# 加载环境变量
load_dotenv(override=True)
async def setup_mcp_tools():
"""连接 Context7 MCP 服务器并获取工具"""
print("正在连接 Context7 MCP 服务器...")
try:
# 使用官方 Context7 MCP 配置
client = MultiServerMCPClient({
"context7": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"],
}
})
# 获取工具
tools = await client.get_tools()
print(f"成功加载 {len(tools)} 个 MCP 工具")
return client, tools
except Exception as e:
print(f"❌ 连接 MCP 失败: {e}")
return None, []
async def run_e2b_demo():
print("\n" + "="*80)
print("DeepAgents E2BBackend (Sandbox) 演示 ")
print("="*80)
# 1. 检查 API Key
if not os.getenv("E2B_API_KEY"):
print("❌ 错误: 未找到 E2B_API_KEY 环境变量。")
print("请在 .env 文件中设置 E2B_API_KEY,或直接导出该变量。")
return
# 2. 初始化 MCP (用于查询文档等辅助任务)
mcp_client, mcp_tools = await setup_mcp_tools()
# 3. 初始化 E2B Backend
print("正在初始化 E2B 沙箱 (Template: base)...")
try:
backend = E2BBackend(template="base")
print(f"沙箱已启动 (ID: {backend.id})")
except Exception as e:
print(f"❌ 沙箱启动失败: {e}")
return
try:
# 4. 创建 DeepAgent
llm = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_deep_agent(
model=llm,
tools=mcp_tools, # 赋予 MCP 工具能力
backend=backend, # 赋予 E2B 沙箱能力
system_prompt="""你是一个拥有云端沙箱环境的高级技术助手。
你的任务是演示如何在沙箱中进行操作。
请执行以下步骤:
1. 使用 'execute_command' 运行 'uname -a' 和 'python --version' 来展示环境信息。
2. 创建一个 Python 脚本 '/home/user/hello.py',内容是打印 'Hello from E2B Sandbox!'。
3. 运行这个 Python 脚本并显示输出。
"""
)
print(f"\n任务开始")
# 5. 执行任务
task = "请开始演示沙箱操作流程。"
step = 0
async for event in agent.astream({"messages": [("user", task)]}):
step += 1
for node_name, node_data in event.items():
if node_data is None: continue
if "messages" in node_data:
msgs = node_data["messages"]
if not isinstance(msgs, list): msgs = [msgs]
for msg in msgs:
if isinstance(msg, BaseMessage) and msg.content:
# 过滤掉空的工具调用消息
is_tool_call_msg = getattr(msg, "tool_calls", None)
if not is_tool_call_msg:
print(f"\n[Agent ({node_name})]")
print("-" * 40)
print(msg.content)
print("-" * 40)
if hasattr(msg, "tool_calls") and msg.tool_calls:
print(f"\n[Step {step}: 工具调用]")
for tc in msg.tool_calls:
args_str = str(tc['args'])
if len(args_str) > 500:
args_str = args_str[:500] + "..."
print(f" • {tc['name']}: {args_str}")
if isinstance(msg, ToolMessage):
content_preview = str(msg.content)
if len(content_preview) > 200:
content_preview = content_preview[:200] + "..."
print(f"[Tool Output ({msg.name})]: {content_preview}")
except Exception as e:
print(f"❌ 运行时错误: {e}")
import traceback
traceback.print_exc()
finally:
# 6. 清理资源
print("\n正在关闭沙箱...")
backend.close()
print("沙箱已关闭")
print("演示结束")
if __name__ == "__main__":
try:
# asyncio.run(run_e2b_demo())
await run_e2b_demo()
except RuntimeError as e:
if "asyncio.run() cannot be called from a running event loop" in str(e):
print("请在 Jupyter 中使用 await run_e2b_demo()")
else:
raise e
5、DockerBackend 使用Docker容器 链接到标题
DockerBackend 的核心作用是为 AI 智能体提供一个 安全沙箱(Sandbox) 。
如果不使用 Docker,Agent 执行的每一条命令(如 rm -rf 、 pip install )都会直接发生在您的宿主机(Mac)上,这极其危险且环境不可控。
作用与优势
安全隔离 (Security & Isolation)
作用 :Agent 的所有操作(文件读写、代码执行、系统命令)都被限制在 Docker 容器内部。
优势 :即使 Agent 产生幻觉执行了恶意代码(如删除系统文件),也只会破坏容器, 您的 Mac 宿主机毫发无损 。演示代码中的 auto_remove=True 确保任务结束后容器自动销毁,不留痕迹。
环境一致性 (Reproducibility)
作用 :代码指定了镜像 image=“python:3.11-slim” 。
优势 :无论您的电脑安装的是 Python 3.9 还是 3.12,Agent 永远在一个干净、标准的 Python 3.11 环境中运行。这解决了“在我的机器上能跑”的经典依赖问题。
生命周期管理 (Lifecycle Management)
作用 : DockerBackend 自动处理容器的 启动 -> 连接 -> 执行 -> 销毁 全过程。
优势 :开发者无需手动编写复杂的 Docker 命令,像使用本地对象一样简单地调用 backend.execute() 或 backend.write_file() 。
# 需要先安装一下docker依赖
#!pip install docker
#这个 Backend 会在本地启动一个 Docker 容器,并将会话隔离在容器内部。
# - 核心功能 :
# - 自动生命周期管理 :初始化时启动容器,结束时自动销毁 ( auto_remove=True )。
# - 高效文件传输 :使用 tar 流在宿主机和容器之间传输文件,支持批量操作。
# - 资源限制 :支持设置 CPU ( cpu_quota ) 和内存 ( memory_limit ) 限制,防止 Agent 耗尽本机资源。
# - 网络控制 :可选禁用网络 ( network_disabled=True ) 以增强安全性。
import io
import tarfile
import time
import uuid
from typing import Optional
# 加载 DeepAgents 后端协议
from deepagents.backends.protocol import (
ExecuteResponse,
FileDownloadResponse,
FileUploadResponse,
SandboxBackendProtocol,
)
# 加载 DeepAgents 基础沙箱类
from deepagents.backends.sandbox import BaseSandbox
try:
import docker
from docker.errors import NotFound, APIError
except ImportError:
docker = None
class DockerBackend(BaseSandbox):
"""Docker 沙箱后端实现,用于 DeepAgents。
该后端使用本地 Docker 守护进程提供隔离的执行环境。
需要安装 `docker` Python 包,并确保 Docker 守护进程正在运行。
"""
def __init__(
self,
image: str = "python:3.11-slim",
auto_remove: bool = True,
cpu_quota: int = 50000, # 50% CPU
memory_limit: str = "512m",
network_disabled: bool = False,
working_dir: str = "/workspace",
volumes: dict[str, dict[str, str]] | None = None,
) -> None:
"""初始化 Docker 沙箱。
参数:
image: 使用的 Docker 镜像(默认:"python:3.11-slim")
auto_remove: 是否在关闭时移除容器(默认:True)
cpu_quota: CPU 配额,单位为微秒(默认:50000)
memory_limit: 内存限制(默认:"512m")
network_disabled: 是否禁用网络访问(默认:False)
working_dir: 容器内的工作目录(默认:"/workspace")
volumes: Docker 卷配置,例如 {'/宿主机路径': {'bind': '/容器路径', 'mode': 'rw'}}
"""
if docker is None:
raise ImportError(
"docker package is not installed. "
"Please install it with `pip install docker`."
)
# 初始化 Docker 客户端,from_env() 会自动从环境变量中读取 Docker 配置
self.client = docker.from_env()
self.image = image
self.auto_remove = auto_remove
self.working_dir = working_dir
self.volumes = volumes or {}
self._container = None
# Start container
try:
# Ensure image exists
try:
self.client.images.get(image)
except NotFound:
print(f"Pulling image {image}...")
self.client.images.pull(image)
self._container = self.client.containers.run(
image,
command="tail -f /dev/null", # Keep container running
detach=True,
tty=True,
cpu_quota=cpu_quota,
mem_limit=memory_limit,
network_disabled=network_disabled,
working_dir=working_dir,
volumes=self.volumes,
)
# Ensure working directory exists
self.execute(f"mkdir -p {working_dir}")
except Exception as e:
raise RuntimeError(f"Failed to start Docker container: {e}")
@property
def id(self) -> str:
"""Unique identifier for the sandbox backend."""
return self._container.id if self._container else "unknown"
def execute(self, command: str) -> ExecuteResponse:
"""Execute a command in the sandbox."""
if not self._container:
return ExecuteResponse(
output="Container not running",
exit_code=1,
truncated=False
)
try:
# Docker exec_run 返回 (exit_code, output)
# output 是字节类型
# 使用列表形式的 cmd 以避免 shell 转义问题
exit_code, output = self._container.exec_run(
cmd=["bash", "-c", command],
workdir=self.working_dir,
demux=False # Combine stdout and stderr
)
return ExecuteResponse(
output=output.decode("utf-8", errors="replace"),
exit_code=exit_code,
truncated=False,
)
except Exception as e:
return ExecuteResponse(
output=f"Error executing command: {str(e)}",
exit_code=1,
truncated=False,
)
def upload_files(self, files: list[tuple[str, bytes]]) -> list[FileUploadResponse]:
"""Upload multiple files to the sandbox using tar archive."""
if not self._container:
return [FileUploadResponse(path=p, error="permission_denied") for p, _ in files]
responses = []
# Create a tar archive in memory
tar_stream = io.BytesIO()
with tarfile.open(fileobj=tar_stream, mode='w') as tar:
for path, content in files:
# Docker put_archive expects relative paths inside the tar to be relative to the destination
# But here we want absolute paths to be respected.
# Actually put_archive extracts to a directory.
# To support absolute paths, we should probably upload to root /?
# Or handle relative paths relative to working_dir.
# Let's handle paths:
# If path is absolute, we strip leading / and upload to root.
# If path is relative, we upload to working_dir.
# Simplification: We will create a tar with full structure and extract to /
# Normalize path
if path.startswith("/"):
arcname = path.lstrip("/")
dest_path = "/"
else:
arcname = path
dest_path = self.working_dir
info = tarfile.TarInfo(name=arcname)
info.size = len(content)
info.mtime = time.time()
tar.addfile(info, io.BytesIO(content))
responses.append(FileUploadResponse(path=path, error=None))
tar_stream.seek(0)
try:
# We extract to / to support absolute paths in the tar
# Note: This assumes all files in the batch can be extracted to the same root.
# If mixed absolute/relative, this might be tricky.
# For robustness, we might need to upload one by one if paths are mixed,
# or group them.
# Strategy: Always extract to / (root), and ensure arcnames are full paths (without leading /)
self._container.put_archive(
path="/",
data=tar_stream
)
except Exception as e:
# Mark all as failed if batch fails
return [FileUploadResponse(path=p, error="permission_denied") for p, _ in files]
return responses
def download_files(self, paths: list[str]) -> list[FileDownloadResponse]:
"""Download multiple files from the sandbox."""
if not self._container:
return [FileDownloadResponse(path=p, error="permission_denied") for p in paths]
responses = []
for path in paths:
try:
# get_archive returns a tuple (generator, stat)
bits, stat = self._container.get_archive(path)
# Reconstruct tar from bits
file_content = io.BytesIO()
for chunk in bits:
file_content.write(chunk)
file_content.seek(0)
# Extract file from tar
with tarfile.open(fileobj=file_content, mode='r') as tar:
# There should be only one file/dir
member = tar.next()
if member.isdir():
responses.append(FileDownloadResponse(path=path, error="is_directory"))
continue
f = tar.extractfile(member)
if f:
content = f.read()
responses.append(FileDownloadResponse(path=path, content=content, error=None))
else:
responses.append(FileDownloadResponse(path=path, error="file_not_found"))
except NotFound:
responses.append(FileDownloadResponse(path=path, error="file_not_found"))
except Exception as e:
error_msg = str(e).lower()
error = "invalid_path"
if "permission" in error_msg:
error = "permission_denied"
responses.append(FileDownloadResponse(path=path, content=None, error=error))
return responses
def close(self):
"""Close the sandbox session."""
if self._container:
try:
if self.auto_remove:
self._container.remove(force=True)
else:
self._container.stop()
except Exception:
pass
self._container = None
- 使用自定义的DockerBackend实现沙箱环境
import asyncio
import os
import sys
from dotenv import load_dotenv
from deepagents import create_deep_agent
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage
# 尝试导入 DockerBackend
try:
from docker_backend import DockerBackend
except ImportError:
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from docker_backend import DockerBackend
load_dotenv(override=True)
async def run_docker_demo():
print("\n" + "="*80)
print("DeepAgents DockerBackend 演示 (极简版)")
print("="*80)
# 1. 检查 Docker 环境
try:
import docker
docker.from_env().ping()
except Exception as e:
print(f"❌ Docker 未运行或未安装: {e}")
print("请确保 Docker Desktop 已启动。")
return
# 2. 初始化 Docker Backend
print("正在启动 Docker 容器 (Image: python:3.11-slim)...")
try:
backend = DockerBackend(
image="python:3.11-slim",
auto_remove=True
)
print(f"容器已启动 (ID: {backend.id[:12]})")
except Exception as e:
print(f"❌ 启动失败: {e}")
return
try:
# 3. 创建 Agent
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = create_deep_agent(
model=llm,
backend=backend,
system_prompt="""你是一个运行在 Docker 容器中的 AI 助手。
你的任务是演示环境隔离性。
请执行以下步骤:
1. 运行 'cat /etc/os-release' 查看容器操作系统。
2. 运行 'python --version' 确认 Python 环境。
3. 创建文件 '/workspace/hello_docker.py',内容为打印 'Hello from Docker Container!'。
4. 运行该脚本。
"""
)
print(f"\n任务开始")
# 4. 执行任务
async for event in agent.astream({"messages": [("user", "请开始演示。")]}):
for node_name, node_data in event.items():
if not node_data:
continue
# 处理 Overwrite 对象
if hasattr(node_data, "value"):
node_data = node_data.value
# 再次检查是否为字典
if not isinstance(node_data, dict):
continue
if "messages" in node_data:
messages = node_data["messages"]
if hasattr(messages, "value"):
messages = messages.value
if isinstance(messages, list) and messages:
last_msg = messages[-1]
if isinstance(last_msg, BaseMessage) and last_msg.content:
print(f"\n[Agent ({node_name})]")
print("-" * 40)
print(last_msg.content)
print("-" * 40)
except Exception as e:
print(f"❌ 运行时错误: {e}")
import traceback
traceback.print_exc()
finally:
print("\n正在清理容器...")
backend.close()
print("容器已移除")
print("\n演示结束")
if __name__ == "__main__":
await run_docker_demo()
- 这里可以看一下DockerBackend和E2BBackend的区别
| 特性 | DockerBackend | E2BBackend |
|---|---|---|
| 核心定位 | 本地轻量级容器化沙箱 | 云端安全沙箱环境 (SaaS) |
| 部署位置 | 运行在本地机器 (Localhost) | 运行在 E2B 云端集群 (Remote Cloud) |
| 依赖环境 | 需要本地安装并运行 Docker Desktop/Daemon | 仅需安装 e2b Python SDK,无需本地 Docker |
| 资源消耗 | 消耗本地 CPU/内存资源 | 消耗 E2B 云端资源 (不占用本地算力) |
| 启动速度 | 快 (本地镜像启动,毫秒-秒级) | 较快 (云端冷启动约 1-3秒) |
| 网络隔离 | 可配置 (支持完全离线 network_disabled=True) | 默认联网 (支持访问公网 API) |
| 持久化 | 支持挂载本地卷 (Volumes) 实现数据持久化 | 临时环境 (会话结束即销毁),数据需手动导出 |
| 适用场景 | • 本地开发/调试• 数据隐私敏感 (不想数据出本地)• 离线环境使用 | • 生产环境部署 (无需维护 Docker)• 多租户隔离 (每个用户一个云沙箱)• 本地资源受限设备 |
| 成本 | 免费 (使用自有硬件) | 付费 (按使用时长/资源计费) |
| 配置复杂度 | 中 (需管理镜像、卷挂载、Docker 进程) | 低 (API Key 开箱即用) |
6、StoreBackend 使用数据库存储 链接到标题
step1 : 这里我们使用postgresql数据库进行数据的存储,所以需要先系统安装postgresql在本地环境
brew install postgresql(mac系统)
sudo apt-get install postgresql(Linux系统)
https://blog.csdn.net/weixin_54787369/article/details/141348101(windows系统)
step2 : 安装完成之后,可以使用Docker来部署启动postgresql数据库,我这里使用的docker-compose.yml文件启动的,需要把password密码,user用户名,database数据库名称修改为自己的,使用docker-compose up -d启动数据库,如下所示:
#docker-compose.yml 文件:
services:
postgres:
image: postgres:15
container_name: my-postgres
environment:
- POSTGRES_PASSWORD=123456
- POSTGRES_USER=myuser
- POSTGRES_DB=mydatabase
ports:
- "5432:5432"
volumes:
- pg_data:/data/db
- ./conf.d:/data/conf.d
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
restart: unless-stopped
volumes:
pg_data:
driver: local
#!pip install langgraph-checkpoint-postgres # 生产环境使用
# 测试数据库是否连接正常,-U 指定用户名,-d 指定数据库名称
!psql -U myuser -d mydatabase -c "SELECT version();"
import asyncio
import os
import uuid
import traceback
from dotenv import load_dotenv
# LangChain / LangGraph Imports
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_core.messages import BaseMessage, ToolMessage
from langgraph.store.postgres import PostgresStore
from langgraph.checkpoint.memory import MemorySaver
from psycopg_pool import ConnectionPool
# DeepAgents Imports
from deepagents import create_deep_agent
from deepagents.backends import StoreBackend
# 加载环境变量
load_dotenv(override=True)
# 数据库连接字符串 (请根据实际情况修改)
DB_URI = "postgresql://myuser:123456@localhost:5432/mydatabase"
def print_header():
print("\n" + "="*80)
print("DeepAgents StoreBackend (PostgreSQL) 演示 (极简版)")
print("="*80)
async def setup_mcp_tools():
"""
连接 Context7 MCP 服务器并获取工具。
"""
print("Step 1.1: 正在连接 Context7 MCP 服务器...")
try:
# 使用官方 Context7 MCP 配置
client = MultiServerMCPClient({
"context7": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"],
}
})
# 获取工具列表
tools = await client.get_tools()
print(f"Step 1.2: 成功加载 {len(tools)} 个 MCP 工具")
return client, tools
except Exception as e:
print(f"ERROR: 连接 MCP 失败: {e}")
return None, []
async def run_store_backend_demo():
"""
运行 StoreBackend 演示:
展示如何使用 PostgreSQL 作为 DeepAgents 的文件系统后端。
"""
print_header()
# =================================================================================================
# Step 1. 初始化 MCP 工具 (Connect to Context7 MCP Server)
# =================================================================================================
mcp_client, mcp_tools = await setup_mcp_tools()
# =================================================================================================
# Step 2. 初始化 PostgreSQL 连接池和存储组件 (Init DB & Store)
# =================================================================================================
print(f"\nStep 2: 连接数据库 {DB_URI} 并初始化存储...")
# 使用 ConnectionPool 管理数据库连接
# StoreBackend 需要同步的 ConnectionPool (因为它在线程中运行同步操作)
try:
with ConnectionPool(conninfo=DB_URI, kwargs={"autocommit": True}) as pool:
# 2.1 初始化 Checkpointer (用于保存会话状态/聊天记录)
# 注意: 这里使用 MemorySaver 是为了避开 langgraph-checkpoint-postgres 在某些环境下的异步兼容性问题
checkpointer = MemorySaver()
# 2.2 初始化 Store (用于保存文件/长期记忆)
# DeepAgents 的 StoreBackend 会将文件系统操作映射到这个 PostgresStore
store = PostgresStore(pool)
# 2.3 执行数据库迁移 (首次运行需要初始化表结构)
# 这会在数据库中创建 'store' 表,用于存储 JSON 数据 (即我们的文件)
with pool.connection() as conn:
with conn.cursor() as cur:
for migration in store.MIGRATIONS:
cur.execute(migration)
print("Step 2: 数据库表结构就绪")
# =================================================================================================
# Step 3. 创建基于 StoreBackend 的 Agent (Create Agent)
# =================================================================================================
# StoreBackend 将文件系统操作映射到 LangGraph 的 Store
# 这意味着文件将持久化存储在 PostgreSQL 数据库中,跨重启可用
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 定义 Backend Factory
# 这是一个工厂函数,用于在运行时(runtime)把 StoreBackend 实例化。
# create_deep_agent 会在内部把 LangGraph 的 runtime 对象作为参数 rt 传进来,
# 这样 StoreBackend 就能拿到 store/checkpointer 等资源,实现文件系统到 PostgreSQL 的映射。
backend_factory = lambda rt: StoreBackend(rt)
print("Step 3: 正在初始化 DeepAgent (Backend: StoreBackend -> PostgresStore)...")
agent = create_deep_agent(
model=llm,
tools=mcp_tools,
backend=backend_factory,
store=store, # 关键: 必须传入 store 实例
checkpointer=checkpointer, # 关键: 传入 checkpointer 实例
system_prompt="""你是一个高级技术助手。
你的任务是使用 Context7 工具查询关于 'DeepAgents StoreBackend' 的用法。
查询后,创建一个总结文件 '/knowledge/store_backend_notes.md',并写入关键信息。
由于你使用的是 StoreBackend,这个文件将直接存储在 PostgreSQL 数据库中。
最后,请读取该文件以验证存储成功。"""
)
# =================================================================================================
# Step 4. 执行任务 (Execute Task)
# =================================================================================================
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
task = "请查询 StoreBackend 的用法,并将总结写入 /knowledge/store_backend_notes.md,最后读取它验证。"
# --- UI Display ------------------------------------------------------------------------------
print(f"Session Thread ID: {thread_id}")
print("\n" + "-"*40)
print(f"Step 4: 开始执行任务: {task}")
print("-"*40)
# ---------------------------------------------------------------------------------------------
step = 0
message_history_len = 0
try:
# 使用 astream 观察执行过程
async for event in agent.astream({"messages": [("user", task)]}, config=config):
if "messages" in event:
current_messages = event["messages"]
if len(current_messages) > message_history_len:
for i in range(message_history_len, len(current_messages)):
msg = current_messages[i]
# 1. 显示普通文本消息 (Agent 回复)
if isinstance(msg, BaseMessage) and msg.content:
is_tool_call = getattr(msg, "tool_calls", None)
if not is_tool_call:
print(f"\n[Agent]:\n{msg.content}")
# 2. 显示工具调用 (Agent 请求工具)
if hasattr(msg, "tool_calls") and msg.tool_calls:
step += 1
print(f"\n[Step {step}: 工具调用]:")
for tc in msg.tool_calls:
print(f" • 工具: {tc['name']}")
print(f" • 参数: {tc['args']}")
# 3. 显示工具输出 (Tool 执行结果)
if isinstance(msg, ToolMessage):
content_preview = msg.content[:200] + "..." if len(msg.content) > 200 else msg.content
print(f"\n[Tool Output ({msg.name})]: {content_preview}")
message_history_len = len(current_messages)
except Exception as e:
print(f"❌ 运行时错误: {e}")
traceback.print_exc()
# =================================================================================================
# Step 5. 验证持久化存储 (Verify Persistence)
# =================================================================================================
print("\n" + "="*50)
print("Step 5: 验证 StoreBackend (Postgres) 持久化")
print("="*50)
print("\n验证操作: 使用新 Agent 实例 (模拟重启) 读取同一文件...")
# 模拟重启:创建一个新的 Agent 实例,但连接同一个 Database Store
# 只要 DB 连接不变,文件系统状态就是持久的
verify_agent = create_deep_agent(
model=llm,
backend=backend_factory,
store=store,
checkpointer=checkpointer,
system_prompt="验证助手"
)
# 读取之前创建的文件
verify_result = await verify_agent.ainvoke({
"messages": [("user", "请读取 /knowledge/store_backend_notes.md 的内容")]
}, config=config)
last_msg = verify_result["messages"][-1]
# --- UI Display ------------------------------------------------------------------------------
print("\n[数据库读取验证结果]:")
print("-" * 20)
print(last_msg.content)
print("-" * 20)
print("\n说明: 'prefix' 对应 StoreBackend 的 namespace (默认为 'filesystem'),'key' 对应文件绝对路径。")
# SQL 查询提示
print("\n提示: 你可以使用以下 SQL 在数据库中直接查询此文件:")
sql_query = """
SELECT
key,
value->>'content' as content,
updated_at
FROM store
WHERE prefix = 'filesystem'
AND key = '/knowledge/store_backend_notes.md';
"""
print(sql_query.strip())
# ---------------------------------------------------------------------------------------------
print("\n演示结束")
except Exception as e:
print(f"❌ 数据库连接或初始化失败: {e}")
print("请检查 PostgreSQL 是否正在运行,以及 DB_URI 是否正确。")
if __name__ == "__main__":
# 确保 asyncio.run 兼容 Jupyter 环境
try:
# asyncio.run(run_store_backend_demo())
await run_store_backend_demo()
except RuntimeError as e:
if "asyncio.run() cannot be called from a running event loop" in str(e):
print("请在 Jupyter 中使用 await run_store_backend_demo()")
else:
raise e
# 查看存入数据库中的结果
!psql -U myuser -d mydatabase -c "SELECT key, value->>'content' as content,updated_at FROM store WHERE prefix = 'filesystem' AND key = '/knowledge/store_backend_notes.md';"
- 这里看一下Backend vs Checkpointer vs Store 这三者的区别
| 参数组件 | Backend (后端) | Checkpointer (检查点) | Store (存储) |
|---|---|---|---|
| 核心定义 | 环境层 (Environment) | 状态层 (State / Short-term Memory) | 记忆层 (Memory / Long-term Memory) |
| 负责什么? | “外部世界” 的交互能力。即:文件存在哪?代码在哪跑? | “当前对话” 的上下文。即:刚才说了什么?现在运行到哪一步了? | “跨会话” 的知识积累。即:用户叫什么名字?上次任务学到了什么? |
| 数据类型 | 非结构化文件 (.py, .md, .txt)运行时环境 (Shell, Process) | BaseMessage 列表 (User/AI/Tool Message)Graph 节点状态 | 结构化 JSON 数据 (Key-Value)用户偏好、长期笔记 |
| 典型实现 | DockerBackend (容器)FilesystemBackend (磁盘)E2BBackend (云沙箱) | MemorySaver (内存)PostgresSaver (数据库)SqliteSaver (本地DB) | InMemoryStore (内存)PostgresStore (数据库) |
| 生命周期 | 任务级(任务结束容器可能销毁) | 线程级 (Thread)(换个 thread_id 就没了) | 全局级 (Global)(所有 thread 都能查到) |
| 形象比喻 | 工作台 / 电脑 | 大脑的工作记忆 (只会死记硬背当前对话) | 日记本 / 知识库 (记录永久信息) |
7、CompositeBackend 使用混合模式 链接到标题
CompositeBackend是 Agent 文件操作的“智能路由器” 。
在单一后端模式下,Agent 所有的文件操作(读、写、列出目录)都只能去往同一个地方(要么全是本地磁盘,要么全是 Docker 容器内)。而 CompositeBackend 允许你根据 文件路径前缀 ,将请求分发给不同的后端。
- 核心优势
性能与开销优化 (Performance) 这是最关键的技术优势。
DockerBackend 的局限 : 向 Docker 容器内读写文件(尤其是大文件)需要经过 Docker Daemon 的 API (如 put_archive / get_archive ),涉及网络通信和打包解包,开销较大。
CompositeBackend 的解法 : 对于数据文件( /data ),直接通过 FilesystemBackend 进行本地 I/O 操作, 完全绕过了 Docker API ,读写速度是操作系统原生的速度。
计算与存储分离 (Decoupling)
计算是临时的 : 你的 processor.py 脚本可能只需要运行一次,运行环境(Python 依赖)可能很复杂且容易冲突。放在 Docker 里最合适。
数据是永恒的 : 你的 raw_metrics.txt 和 health_report.txt 是业务资产。通过路由直接落盘到宿主机,即使 Docker 容器崩溃、被删除或重启, 数据毫发无损 且立即可在宿主机访问(如代码 Line 212-222 所示的验证步骤)。
给予 Agent “混合云” 的能力,Agent 可以像人类工程师一样工作:
“我在临时的沙箱里写代码测试(Docker)。”
“测试好了,我把结果保存到公司的共享网盘里(Filesystem/Mount)。”
import asyncio
import shutil
import os
import time
from pathlib import Path
from dotenv import load_dotenv
# DeepAgents 导入
from deepagents import create_deep_agent
from deepagents.backends.composite import CompositeBackend
from deepagents.backends.filesystem import FilesystemBackend
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_core.messages import BaseMessage, ToolMessage
# 导入 DockerBackend
try:
from docker_backend import DockerBackend
except ImportError:
try:
from deepagents.backends.docker import DockerBackend
except ImportError:
DockerBackend = None
def print_header():
print("\n" + "="*80)
print("DeepAgents CompositeBackend 混合后端演示 (极简版)")
print("架构:混合云原生模式 (Docker 执行 + 本地持久化)")
print("="*80)
async def setup_mcp_tools():
print(" → 正在连接 Context7 MCP 服务器...")
try:
client = MultiServerMCPClient({
"context7": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"],
}
})
tools = await client.get_tools()
print(" → MCP 工具加载成功")
return client, tools
except Exception as e:
print(f"ERROR: MCP 连接失败: {e}")
return None, []
async def run_composite_demo():
load_dotenv(override=True)
print_header()
if DockerBackend is None:
print("严重错误: 未找到 DockerBackend。请确保 docker_backend.py 存在。")
return
# Step 1
print("\n" + "-"*40)
print("步骤 1: 配置混合环境")
print("-"*40)
host_work_dir = Path("workspace/data_analysis_project").resolve()
if host_work_dir.exists():
shutil.rmtree(host_work_dir)
host_work_dir.mkdir(parents=True, exist_ok=True)
print(f" • 宿主机持久层: {host_work_dir}")
container_mount_path = "/data"
docker_volumes = {
str(host_work_dir): {'bind': container_mount_path, 'mode': 'rw'}
}
print(f" • 容器挂载: {host_work_dir} ↔ {container_mount_path}")
# Step 2
print("\n" + "-"*40)
print("步骤 2: 初始化混合后端 (Composite Backend)")
print("-"*40)
fs_backend = FilesystemBackend(root_dir=host_work_dir, virtual_mode=True)
print(" • 正在启动 Docker 容器 (python:3.11-slim)...")
docker_backend = DockerBackend(
image="python:3.11-slim",
auto_remove=True,
volumes=docker_volumes
)
routes = {
container_mount_path: fs_backend
}
backend = CompositeBackend(default=docker_backend, routes=routes)
print("\n[路由表配置]")
print(f"1. 默认路由 (/): DockerBackend (临时执行)")
print(f"2. 持久化路由 ({container_mount_path}/*): FilesystemBackend (宿主机存储)")
# Step 3
print("\n" + "-"*40)
print("步骤 3: 部署 Agent")
print("-"*40)
mcp_client, mcp_tools = await setup_mcp_tools()
system_prompt = f"""你是一名在混合环境中工作的高级数据工程师。
环境地图:
1. 执行层 (根目录 `/`):
- 临时的 Docker 容器。
- 用于创建脚本 (`.py`) 和运行命令。
- 这里的文会在会话结束后消失。
2. 存储层 (`{container_mount_path}`):
- 从宿主机挂载的持久化存储。
- 用于存放 输入 数据和 输出 报告。
- 这里的文件会永久保存。
你的任务:
1. **摄入**: 创建一个文件 `{container_mount_path}/raw_metrics.txt`,内容为 "CPU: 45%, Mem: 60%"。
(注意: 这使用了 'write_file' 工具,该工具通过路由直接写入宿主机文件系统)。
2. **处理**: 创建一个 Python 脚本 `/processor.py` (在根目录),该脚本:
- 读取 `{container_mount_path}/raw_metrics.txt`。
- 计算 "健康分数" (模拟一下即可)。
- 将报告写入 `{container_mount_path}/health_report.txt`。
- 打印 "Analysis Complete"。
3. **执行**: 使用 `python /processor.py` 运行脚本。
(注意: 这在 Docker 内部运行。Docker 因为卷挂载能看到这些文件)。
4. **验证**: 读取 `{container_mount_path}/health_report.txt` 并显示它。
"""
agent = create_deep_agent(
model=ChatOpenAI(model="gpt-4o", temperature=0),
tools=mcp_tools,
backend=backend,
system_prompt=system_prompt
)
# Step 4
print("\n" + "-"*40)
print("步骤 4: 任务执行")
print("-"*40)
task_input = "开始工程流水线。"
config = {"configurable": {"thread_id": "composite_demo_simple_v1"}}
step_count = 0
try:
message_history_len = 0
async for event in agent.astream({"messages": [("user", task_input)]}, config=config):
if "messages" in event:
current_messages = event["messages"]
if len(current_messages) > message_history_len:
for i in range(message_history_len, len(current_messages)):
msg = current_messages[i]
# Agent Thinking
if isinstance(msg, BaseMessage) and msg.content and not getattr(msg, "tool_calls", None):
step_count += 1
print(f"\n[🧠 Agent 思考 (步骤 {step_count})]:\n{msg.content}")
# Tool Calls
if hasattr(msg, "tool_calls") and msg.tool_calls:
step_count += 1
for tc in msg.tool_calls:
tool_name = tc['name']
args = tc['args']
# Routing logic visualization
target = "Docker 容器 🐳"
path_arg = args.get('file_path') or args.get('path')
if path_arg and str(path_arg).startswith(container_mount_path):
target = "宿主机文件系统 💾"
print(f"\n[🛠️ 工具执行 (步骤 {step_count})]:")
print(f" • 工具: {tool_name}")
# Special handling for code content
if tool_name == "write_file" and path_arg and str(path_arg).endswith(".py"):
code_content = args.get("content", "")
# Print args without content first
args_copy = args.copy()
args_copy['content'] = "(代码内容如下...)"
print(f" • 参数: {args_copy}")
print(f" • 路由: → {target}")
print(f" • 📝 写入代码内容:\n")
print("-" * 20)
print(code_content)
print("-" * 20)
else:
print(f" • 参数: {str(args)[:200] + '...' if len(str(args)) > 200 else args}")
print(f" • 路由: → {target}")
# Tool Outputs
if isinstance(msg, ToolMessage):
content = msg.content
if len(content) > 300:
content = content[:300] + "... [已截断]"
print(f"\n[↳ 输出]: {content}")
message_history_len = len(current_messages)
except Exception as e:
print(f"\n运行时错误: {e}")
# Step 5
print("\n" + "-"*40)
print("步骤 5: 宿主机侧验证")
print("-"*40)
report_path = host_work_dir / "health_report.txt"
raw_path = host_work_dir / "raw_metrics.txt"
if raw_path.exists():
print(f"✅ 原始数据已找到: {raw_path} (通过直接 FS 路由创建)")
else:
print(f"❌ 原始数据丢失: {raw_path}")
if report_path.exists():
content = report_path.read_text()
print(f"\n🏆 持久化验证成功! 文件: {report_path}")
print("内容:")
print("-" * 20)
print(content)
print("-" * 20)
else:
print(f"❌ 报告丢失: {report_path}")
# Step 6
print("\n正在关闭基础设施...")
if 'docker_backend' in locals() and hasattr(docker_backend, "close"):
docker_backend.close()
print(" • Docker 容器已终止")
print("\n✨ 演示圆满完成!")
if __name__ == "__main__":
try:
# asyncio.run(run_composite_demo())
await run_composite_demo()
except RuntimeError as e:
if "asyncio.run() cannot be called from a running event loop" in str(e):
print("检测到正在运行的事件循环。请在单元格中使用 'await run_composite_demo()'。")
else:
raise e
三、interrupt_on 参数 链接到标题
Human-in-the-loop(HITL) 人工干预 链接到标题
Human-in-the-loop (HITL):对于
write_file或delegate_task等关键操作,利用 LangGraph 的中断机制加入人工审批。异步运行:DeepAgent 的任务通常耗时较长,务必使用异步 Webhooks 接收结果。
监控与调试:强烈建议结合 LangSmith 使用。由于 DeepAgent 内部有复杂的子 Agent 递归调用,使用 LangSmith 的 Tracing 功能是排查问题的有效手段。
后端挂载:在生产环境中,建议将 VFS 挂载到云端存储(如 S3),以防止容器重启导致 Agent 的"记忆"丢失。
interrupt_on:这个参数其实是一个HITL的开关,就是把HITL的中间件插入到DeepAgent的执行流程中,当DeepAgent执行到需要人工审批的操作时,就会中断执行,等待人工审批。
类型 : dict[str, bool | InterruptOnConfig]
作用 : 映射“工具名称”到“中断配置”。
示例 : interrupt_on={“write_file”: True} 表示当 Agent 试图调用 write_file 工具时,程序会暂停(Suspend),等待人工(Human)在 LangGraph 层面进行 Approve 、 Reject 或 Edit 操作后才能继续。
import os
import asyncio
from typing import Optional, Set
from langchain_openai import ChatOpenAI
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langgraph.checkpoint.memory import InMemorySaver
from dotenv import load_dotenv
from langchain_tavily import TavilySearch
from langchain.agents.middleware.human_in_the_loop import (
HITLResponse,
ApproveDecision,
EditDecision,
RejectDecision
)
from langgraph.types import Command
from langchain_core.messages import BaseMessage, ToolMessage, AIMessage
load_dotenv(override=True)
async def run_interrupt_test():
"""
示例 1: 基础中断功能 (封装版)
在工具调用前中断,让用户确认是否继续执行
"""
print("\n" + "="*80)
print("📚 示例 1: interrupt_on 使用")
print("="*80)
print("\n功能:在工具调用前暂停,等待人工确认\n")
# 创建 LLM 和工具
llm = ChatOpenAI(model="gpt-4o", temperature=0)
search_tool = TavilySearch(max_results=2)
# 创建 Agent,设置在 "tools" 节点中断
agent = create_deep_agent(
model=llm,
tools=[search_tool],
backend=FilesystemBackend(root_dir="./workspace",virtual_mode=True),
checkpointer=InMemorySaver(), # 必需!用于支持中断和恢复
interrupt_on={"tavily_search": True}, # 在特定工具调用时中断
)
# 定义任务
task = "搜索 'Python 异步编程' 的最新信息,并创建一个总结文件"
# 配置会话 ID
# 为了避免之前的状态干扰,我们使用一个新的 thread_id
config = {"configurable": {"thread_id": "demo_basic_refactored_v1"}}
print(f"📋 任务: {task}\n")
print("🚀 开始执行...\n")
# 追踪已打印的消息数量,避免重复打印
message_history_len = 0
# --- 第一次执行 ---
print("【第一次执行 - 预期会中断】")
async for event in agent.astream({"messages": [("user", task)]}, config=config):
if "messages" in event:
current_messages = event["messages"]
if len(current_messages) > message_history_len:
# 打印新增的消息
for i in range(message_history_len, len(current_messages)):
msg = current_messages[i]
if msg.type == "ai":
if hasattr(msg, 'tool_calls') and msg.tool_calls:
print(f"🔧 AI 决定调用工具: {msg.tool_calls[0]['name']}")
print(f" 参数: {msg.tool_calls[0]['args']}")
elif msg.content:
print(f"💬 AI: {msg.content}")
elif msg.type == "tool":
print(f"✅ 工具输出: {msg.content[:100]}..." if len(msg.content) > 100 else f"✅ 工具输出: {msg.content}")
message_history_len = len(current_messages)
# 检查是否中断
# 使用 aget_state (async) 获取状态
state = await agent.aget_state(config)
print(f"\n⏸️ 执行状态: {state.next}")
if state.tasks:
print(f"\n--- 🛑 执行已暂停 (HITL Middleware) ---")
print(f"下一步骤 (Next): {state.next}")
last_message = state.values["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
tool_call = last_message.tool_calls[0]
print(f"\n[待审批操作]:")
print(f" - 工具: {tool_call['name']}")
print(f" - 参数: {tool_call['args']}")
# === 人工介入 ===
approval = input("\n[管理员]: 是否批准执行此操作? (y/n/e[编辑]): ")
if approval.lower() == 'y':
print("\n[系统]: 操作已批准,继续执行...")
hitl_response = HITLResponse(
decisions=[ApproveDecision(type="approve")]
)
# === 恢复执行 ===
# 使用 Command(resume=...)
async for event in agent.astream(
Command(resume=hitl_response),
config=config,
stream_mode="values"
):
if "messages" in event:
current_messages = event["messages"]
if len(current_messages) > message_history_len:
for i in range(message_history_len, len(current_messages)):
msg = current_messages[i]
# 优化打印逻辑,清晰展示 AI 回复
if msg.type == "tool":
print(f"\n[工具输出]:\n{msg.content[:300]}..." if len(msg.content) > 300 else f"\n[工具输出]:\n{msg.content}")
elif msg.type == "ai":
if msg.content:
print(f"\n[AI 回复]:\n{msg.content}\n")
elif msg.tool_calls:
print(f"\n🔧 AI 决定调用工具: {msg.tool_calls[0]['name']}")
print(f" 参数: {msg.tool_calls[0]['args']}")
message_history_len = len(current_messages)
else:
print("\n[系统]: 操作被拒绝或您选择了其他选项 (本演示仅处理 'y')。")
else:
print("流程已完成,没有触发中断。")
if state.values.get("messages"):
last_msg = state.values["messages"][-1]
if last_msg.type == "ai" and last_msg.content:
print(f"\n[最终回复]: {last_msg.content}")
if __name__ == "__main__":
try:
# asyncio.run(run_interrupt_test())
await run_interrupt_test()
except KeyboardInterrupt:
print("\n程序已停止")
第五阶段、总结 链接到标题
DeepAgents 采用 中间件模式 来增强 Agent 能力,这些中间件在 create_deep_agent 时自动装配:
FilesystemMiddleware :
提供 ls , read_file , write_file , edit_file , glob , grep , execute 等标准工具。
亮点功能 : 大结果自动转存 。当工具(如搜索或爬虫)返回内容过长时,自动截断并保存到文件系统,仅返回文件路径给 LLM,极大节省 Token 并防止 Crash。
TodoListMiddleware :
拦截 LLM 输出的 todo_list ,将其解析为结构化状态。
支持任务的增删改查(CRUD)和状态流转(Pending -> Completed)。
SubAgentMiddleware :
自动创建 task 工具。
支持 General Purpose Agent (通用分身)和 Custom Agent (专家分身)。
实现父子 Agent 间通过文件系统交换数据,无需序列化传递大量文本。
HumanInTheLoopMiddleware :
通过 interrupt_on 参数配置。
支持在特定工具调用前(如 write_file , execute )暂停,等待人工审批、修改或拒绝。
PatchToolCallsMiddleware :
- 自动检测并修复 LLM 产生的“悬空”工具调用(Dangling Tool Calls),增强稳定性。
一句话总结 :DeepAgents 是 LangGraph 的 最佳实践参考实现 ,它将构建“类人智能体”所需的规划、记忆、工具使用等复杂逻辑,封装成了标准化的基础设施,让开发者专注于业务逻辑而非底层编排。