今天我们聚焦的是 Agent Skills 的系统化设计与实施方法。在 AI Agent 快速普及的当下,越来越多的开发者开始为 Agent 编写 Skills(技能),但大多数人对"什么是好的 Skill 设计"缺乏系统认知,导致创建出来的 Skills 要么触发混乱、要么维护困难、要么根本无法复用。这不是个别现象,而是一个普遍存在的工程问题——当你的 Agent 拥有 10 个以上的 Skills 时,如果没有良好的设计规范,整个系统就会陷入"技能爆炸"的混乱状态。
结合业界最佳实践和真实踩坑案例,我们会重点抓住三个核心问题:什么是坏的 Skill(通过反面案例建立直觉)、如何搭建 Agent 实验环境(让你能够亲手验证好坏)、如何通过实战看到坏 Skill 的真实表现(从现象推导本质)。这门课程不是理论堆砌,而是从真实问题出发,带你走完从"搭建环境"到"执行坏案例"再到"理解设计原则"的完整路径。
为了把这些内容讲清楚,接下来我们会按"环境搭建 → 反面冲击"的主线展开。与传统的"先讲理论再看案例"不同,我们选择实战先行——先让你搭建一个可以执行 Skills 的 Agent 环境,然后让你亲手运行三个典型的"坏 Skill",看到它们的失败现象,最后再从反面推导出正面规则。这种教学方式能让你对"为什么要这样设计"有更深刻的理解,而不是死记硬背一堆规则。
时效性说明:本课程内容基于 LangChain 1.1、Claude Code 2.1 环境编写,测试时间为 2026年3月。课程中的 Skill 示例均来自真实项目的脱敏案例。
目标学员画像:本课程面向具备 Python 基础、了解 AI Agent 基本概念的 AI 应用开发者。学习前,建议先完成「LangChain Agent 基础」或「Claude Code 快速入门」课程。学完本课后,你将能够独立搭建 Agent 实验环境,并通过反面案例建立对"什么是坏设计"的直观认知。
第一章:搭建 Agent 实验环境 链接到标题
在正式学习 Agent Skills 设计方法之前,我们需要先搭建一个可以实际运行的 Agent 实验环境。这一章的目标很明确:让你能够在本地快速搭建一个具备 Skills 能力的 Agent,并通过基础测试验证它能够正常工作。
我们会从最基础的环境准备开始,逐步完成依赖安装、API Key 配置、Agent 初始化,最后通过多轮对话测试来验证整个系统的可用性。这个过程不仅是技术准备,更重要的是让你建立对 Agent 工作机制的直观认知——当你看到 Agent 如何扫描 Skills、如何触发工具调用、如何处理多轮对话时,后续章节中关于 Skill 设计的理论就会变得更加具体和可感知。
接下来我们会按照"环境准备 → 配置 → 理解 → 初始化 → 测试"的主线展开,每一步都会给出可执行的代码和验证方法。
在正式学习 Skill 设计方法之前,我们需要先搭建一个可以执行 Skills 的 Agent 实验环境。这个环境不仅是后续实战的基础,更重要的是,它能让你亲手验证每一个设计原则——当你看到一个坏 Skill 在真实环境中失败时,你对"为什么不能这样设计"的理解会比单纯阅读理论深刻得多。
本章的目标很明确:让你能够在本地搭建一个具备 Skills 能力的 Agent,并通过基础测试验证它能正常工作。我们会使用一个轻量级的 standalone_agent 模块,它封装了 Agent 初始化、Skills 扫描、对话管理等核心功能,让你可以专注于 Skill 设计本身,而不是陷入复杂的框架配置。
整个搭建过程分为五个步骤:环境准备、API Key 配置、模块理解、Agent 初始化、基础测试。每个步骤都会提供可执行的代码和验证方法,确保你能顺利完成环境搭建。
1.1 环境准备与依赖安装 链接到标题
首先,我们需要确认 Python 环境并安装必要的依赖包。本课程使用的核心依赖包括 langchain(Agent 框架)、python-dotenv(环境变量管理)、以及 openai(API 调用)。这些依赖已经整理在 requirements.txt 文件中,我们只需要一条命令就能完成安装。
在开始安装前,建议先检查 Python 版本。本课程要求 Python 3.10 或更高版本,因为 LangChain 1.1 依赖了一些较新的 Python 特性。
步骤一:检查 Python 版本
执行以下命令检查当前 Python 版本。如果版本低于 3.10,建议先升级 Python 环境。
import sys
print(f"Python 版本: {sys.version}")
print(f"版本信息: {sys.version_info}")
# 检查是否满足最低版本要求
if sys.version_info >= (3, 10):
print(" Python 版本满足要求(>= 3.10)")
else:
print("Python 版本过低,请升级至 3.10 或更高版本")
执行后,如果看到「Python 版本满足要求」,说明环境符合要求,可以继续后续步骤。
步骤二:安装依赖包
使用 pip 安装 requirements.txt 中列出的所有依赖包。这个过程可能需要几分钟,取决于网络速度和已安装的包。
!pip install -r requirements.txt
如果安装过程中出现错误,常见原因包括:网络连接问题(可以尝试使用国内镜像源)、权限不足(可以尝试添加 --user 参数)、依赖冲突(可以尝试在虚拟环境中安装)。
步骤三:验证安装成功
安装完成后,我们需要验证核心依赖包是否正确安装。执行以下代码导入关键模块,如果没有报错,说明安装成功。
# 验证核心依赖包
try:
import langchain
import dotenv
import openai
print(" 所有依赖包安装成功")
print(f"LangChain 版本: {langchain.__version__}")
except ImportError as e:
print(f" 依赖包导入失败: {e}")
执行后,如果看到「所有依赖包安装成功」以及 LangChain 的版本号,说明环境准备完成,可以进入下一步。
1.2 配置 API Key 链接到标题
Agent 需要调用大模型 API 来理解用户意图和执行任务,因此我们需要配置 API Key。为了保护敏感信息,我们使用 python-dotenv 库来管理环境变量,而不是在代码中硬编码 API Key。
本课程使用 DeepSeek API 作为示例(你也可以使用 OpenAI、Claude 或其他兼容 OpenAI 格式的 API)。如果你还没有 API Key,可以前往 DeepSeek 官网注册并获取。
步骤一:创建环境变量文件
在项目根目录创建 .env 文件,并添加以下内容。注意将 your-api-key-here 替换为你的真实 API Key。
DEEPSEEK_API_KEY=sk-your-api-key-here
注意 安全提醒:
.env文件包含敏感信息,切勿提交到 Git 仓库。建议在.gitignore中添加.env以防止意外提交。
步骤二:安装 python-dotenv
如果在步骤 1.1 中已经安装了 requirements.txt,这一步可以跳过。否则,单独安装 python-dotenv:
!pip install python-dotenv
步骤三:加载环境变量
使用 python-dotenv 库加载 .env 文件中的环境变量,这样可以在代码中安全地访问 API Key。
from dotenv import load_dotenv
import os
# 加载 .env 文件中的环境变量
load_dotenv()
# 读取 API Key
api_key = os.getenv("DEEPSEEK_API_KEY")
# 验证是否成功加载
if api_key:
print("API Key 加载成功")
print(f"API Key 前缀: {api_key[:10]}...") # 只显示前10个字符,保护隐私
else:
print(" API Key 未找到,请检查 .env 文件配置")
执行后,如果看到「API Key 加载成功」以及 API Key 的前缀,说明环境变量配置正确,可以继续后续步骤。如果看到「API Key 未找到」,请检查:.env 文件是否在正确的位置(项目根目录)、文件内容格式是否正确、变量名是否拼写正确。
1.3 理解 standalone_agent 模块 链接到标题
在开始使用 Agent 之前,我们需要先理解 standalone_agent 模块的核心功能。这个模块封装了 Agent 的初始化、Skills 扫描、对话管理等功能,让我们可以用几行代码就搭建一个完整的 Agent 系统。
standalone_agent 模块提供了四个核心函数,它们构成了 Agent 的完整生命周期:
standalone agent 核心函数说明
| 函数名 | 功能说明 | 使用场景 |
|---|---|---|
scan_skills(skills_dir) | 扫描指定目录下的所有 Skills | Agent 初始化前,获取可用 Skills 列表 |
initialize_agent(...) | 初始化 Agent 实例 | 配置模型、加载 Skills、准备工具 |
chat(agent, message, history) | 同步对话(阻塞式) | 简单问答、单次任务执行 |
chat_stream(agent, message, history) | 流式对话(异步) | 观察 Agent 思考过程、工具调用细节 |
这四个函数的调用顺序是固定的:先用 scan_skills 扫描 Skills 目录,然后用 initialize_agent 初始化 Agent,最后用 chat 或 chat_stream 进行对话。接下来我们会逐一演示这些函数的使用方法。
步骤一:导入模块
首先导入 standalone_agent 模块和必要的辅助库。Path 用于处理文件路径,确保跨平台兼容性。
from pathlib import Path
from standalone_agent import scan_skills, initialize_agent, chat, chat_stream
如果导入成功,说明 standalone_agent.py 文件在正确的位置。如果报错 ModuleNotFoundError,请检查文件路径是否正确。
步骤二:理解项目结构
standalone_agent 模块假设你的项目结构如下:
# project/
# ├── standalone_agent.py # Agent 核心模块
# ├── requirements.txt # 依赖列表
# ├── .env # 环境变量(API Key)
# └── skills/ # Skills 目录
# ├── skill_a/
# │ └── SKILL.md # Skill 定义文件
# └── skill_b/
# └── SKILL.md
每个 Skill 都是一个独立的目录,目录中必须包含 SKILL.md 文件。这个文件定义了 Skill 的名称、描述、执行步骤等信息。Agent 在初始化时会扫描 skills/ 目录,读取所有 SKILL.md 文件,并将它们注册为可用的 Skills。
这种设计的好处是:每个 Skill 都是独立的,可以单独开发、测试、维护。当你需要添加新 Skill 时,只需要在 skills/ 目录下创建一个新文件夹,放入 SKILL.md 文件即可,无需修改 Agent 代码。
1.4 初始化 Agent 链接到标题
现在我们已经准备好了所有前置条件:Python 环境、依赖包、API Key、模块理解。接下来,我们将正式初始化一个 Agent 实例,并验证它能正常工作。
步骤一:扫描 Skills 目录
首先,我们需要扫描 skills/ 目录,获取所有可用的 Skills。假设你的项目中已经有两个示例 Skills:get_weather(查询天气)和 search_web(搜索网页)。
# 指定 Skills 目录路径
skills_dir = Path("./skills")
# 扫描 Skills
skills_snapshot = scan_skills(skills_dir)
print("\n扫描结果:")
print(skills_snapshot)
这个输出展示了扫描到的所有 Skills,包括名称、描述和文件位置。如果你的 skills/ 目录是空的,输出会显示 0 skills found,这是正常的——我们会在第二章中添加反面案例 Skills。
步骤二:初始化 Agent 实例
使用 initialize_agent 函数创建 Agent 实例。这个函数需要传入 API Key、模型配置、Skills 目录等参数。
# 初始化 Agent
agent = initialize_agent(
api_key=api_key, # API Key(从环境变量加载)
base_url="https://api.deepseek.com", # API 基础 URL
model="deepseek-chat", # 模型名称
temperature=0.7, # 温度参数(控制随机性)
skills_dir=skills_dir, # Skills 目录
base_dir=Path(".") # 项目根目录
)
这里显示 Agent 初始化成功,并加载了 3 个工具。为什么是 3 个而不是 2 个?因为除了 2 个 Skills 对应的工具,Agent 还内置了一个 read_file 工具,用于读取 Skill 定义文件。
1.5 基础对话测试 链接到标题
Agent 初始化完成后,我们需要通过一系列测试来验证它能正常工作。这些测试包括:简单问答(验证基础对话能力)、工具调用(验证 Skill 执行能力)、多轮对话(验证上下文记忆能力)、流式输出(验证实时反馈能力)。
步骤一:简单问答测试
首先测试 Agent 的基础对话能力。我们问一个简单的问题,看 Agent 是否能正常回复。
# 简单问答
response = chat(agent, "你好,请介绍一下你自己")
print(response)
这个回复说明 Agent 能够正常理解问题并生成回复,基础对话能力正常。
步骤二:工具调用测试
接下来测试 Agent 的工具调用能力。我们让 Agent 读取一个 Skill 定义文件,看它是否能正确调用 read_file 工具。
# 测试工具调用
response = chat(agent, "请读取 skills/skill-creator/SKILL.md 文件")
print(response)
执行后,Agent 会调用 read_file 工具读取文件内容,并总结 Skill 的功能。
这个回复说明 Agent 能够正确调用工具并理解工具返回的内容,工具调用能力正常。
步骤三:多轮对话测试
测试 Agent 的上下文记忆能力。我们进行两轮对话,看 Agent 是否能记住第一轮的信息。
# 初始化对话历史
history = []
# 第一轮对话
user_msg_1 = "我叫张三"
response_1 = chat(agent, user_msg_1, history)
print(f"用户: {user_msg_1}")
print(f"Agent: {response_1}\n")
# 更新历史
history.append({"role": "user", "content": user_msg_1})
history.append({"role": "assistant", "content": response_1})
# 第二轮对话
user_msg_2 = "我叫什么名字?"
response_2 = chat(agent, user_msg_2, history)
print(f"用户: {user_msg_2}")
print(f"Agent: {response_2}")
Agent 能够正确回忆起第一轮对话中的信息,说明上下文记忆能力正常。
步骤四:流式对话测试
最后测试流式对话功能。流式对话可以让我们实时看到 Agent 的思考过程和工具调用细节,这对于调试和理解 Agent 行为非常有帮助。
import asyncio
async def test_stream():
print("用户: 1+1等于几?\n")
print("Agent: ", end="")
async for event in chat_stream(agent, "1+1等于几?"):
if event["type"] == "token":
print(event["content"], end="", flush=True)
elif event["type"] == "tool_start":
print(f"\n\n[[工具调用] 调用工具: {event['tool']}]")
elif event["type"] == "tool_end":
print(f"[[OK] 工具执行完成]\n")
elif event["type"] == "done":
print("\n\n[对话结束]")
# 在 Jupyter 中运行异步函数
await test_stream()
执行后,你会看到 Agent 的完整思考过程,包括每个 token 的生成、工具调用的开始和结束。这种实时反馈对于理解 Agent 的行为非常有帮助。
现在,你已经拥有了一个可以执行 Skills 的 Agent 环境。在下一章中,我们将利用这个环境来执行三个典型的"坏 Skill",通过真实的失败现象来理解"什么样的 Skill 设计是绝对不能这样做的"。这种从反面学习的方式,会让你对 Skill 设计原则有更深刻的理解。
第二章:反面冲击——用 Agent 执行三个坏 Skill 链接到标题
在第一章中,我们已经成功搭建了一个可以运行的 Agent 实验环境。现在,是时候让这个 Agent 去执行一些"坏 Skill"了。为什么要从坏的开始?因为只有亲眼看到设计糟糕的 Skill 会导致什么样的混乱,你才能真正理解"什么是好的设计"。
这一章我们会准备三个典型的反面案例:ai-dev-assistant(万能瑞士军刀)、code-bomb-deployer(厨房水槽)、encyclopedia-translator(复制粘贴文档)。我们不仅会看它们的 Skill 定义,更重要的是会用 Agent 实际执行它们,观察触发混乱、执行失败、性能低下等真实现象。通过这种"反面冲击",你会建立起对 Skill 设计原则的深刻认知。
接下来我们会按照"准备案例 → 执行案例1 → 执行案例2 → 执行案例3 → 总结规律"的主线展开,每个案例都会包含完整的执行过程和问题分析。
在第一章中,我们已经搭建好了一个可以执行 Skills 的 Agent 环境。现在,是时候让这个环境发挥作用了——我们将用它来执行三个典型的"坏 Skill",通过真实的失败现象来建立对"什么是坏设计"的直观认知。
为什么要从反面案例开始?因为看到失败比听到规则更有冲击力。当你亲眼看到一个设计糟糕的 Skill 导致 Agent 触发混乱、执行卡住、输出冗长时,你会对"为什么不能这样设计"有更深刻的理解。这种认知冲突会让你在后续学习正面规则时,自然而然地理解每条规则背后的原因。
本章将带你执行三个反面案例:ai-dev-assistant(万能瑞士军刀,职责不清)、code-bomb-deployer(厨房水槽,结构混乱)、encyclopedia-translator(复制粘贴文档,信息过载)。每个案例都会展示真实的执行过程、失败现象、以及背后的设计问题。
2.1 准备反面案例 Skills 链接到标题
在开始执行反面案例之前,我们需要先将这三个坏 Skill 放入 Agent 的 Skills 目录。这些 Skill 文件已经准备好,存放在 bad-skills/ 目录中。我们只需要将它们复制到 Agent 能够扫描的位置即可。
步骤一:查看反面案例文件
首先,让我们看看 bad-skills/ 目录中有哪些文件。这个目录包含了三个坏 Skill 的完整定义。
!ls -la bad-skills/
每个目录都包含一个 SKILL.md 文件,这是 Skill 的定义文件。接下来我们会逐一查看这些文件的内容,并执行它们。
步骤二:将反面案例复制到 Skills 目录
为了让 Agent 能够识别这些坏 Skill,我们需要将它们复制到 skills/ 目录。这里我们使用 Python 的 shutil 模块来完成复制操作。
import shutil
from pathlib import Path
# 源目录和目标目录
bad_skills_dir = Path("./bad-skills")
skills_dir = Path("./skills")
# 确保目标目录存在
skills_dir.mkdir(exist_ok=True)
# 复制三个坏 Skill (这里替换为硬盘上真实的文件夹名称)
real_bad_skills = [
"ai-dev-assistant",
"code-bomb-deployer",
"encyclopedia-translator"
]
for skill_name in real_bad_skills:
src = bad_skills_dir / skill_name
dst = skills_dir / skill_name
if src.exists():
# 如果目标已存在,先删除
if dst.exists():
shutil.rmtree(dst)
# 复制目录
shutil.copytree(src, dst)
print(f" 已复制真实案例: {skill_name}")
else:
print(f" 源文件不存在: {skill_name}")
print("\n所有反面案例已准备就绪!")
执行后,三个坏 Skill 就被复制到了 skills/ 目录,Agent 在下次初始化时就能扫描到它们。
步骤三:重新扫描 Skills
现在我们重新扫描 Skills 目录,确认这三个坏 Skill 已经被识别。
# 重新扫描 Skills
skills_snapshot = scan_skills(skills_dir)
print("\n扫描结果:")
print(skills_snapshot)
执行后,你会看到扫描结果中包含了这三个新增的 Skills。如果扫描结果显示 5 个 Skills(原有的 2 个 + 新增的 3 个),说明准备工作完成,可以开始执行反面案例了。
2.2 案例1:ai-dev-assistant(万能瑞士军刀) 链接到标题
第一个反面案例是 ai-dev-assistant,它的设计者希望创建一个"全能型"开发助手,能够完成所有软件开发任务。听起来很美好,但实际表现如何呢?让我们通过实战来看看。
步骤一:查看 Skill 定义
首先,让我们读取这个 Skill 的定义文件,看看它的触发描述和执行步骤。
# 读取 ai-dev-assistant 的 SKILL.md
skill_path = skills_dir / "ai-dev-assistant" / "SKILL.md"
with open(skill_path, 'r', encoding='utf-8') as f:
content = f.read()
# 只显示前 500 个字符,避免输出过长
print("=== ai-dev-assistant SKILL.md 内容(前 500 字符)===")
print(content[:500])
print("\n...")
print(f"\n文件总长度: {len(content)} 字符")
执行后,你会看到这个 Skill 的 description 非常宽泛,涵盖了代码审查、Bug 修复、重构、测试、文档编写、部署、性能优化、安全审计、项目管理等多个功能。这就是第一个问题:触发描述过于宽泛,导致 Agent 无法判断什么时候应该触发这个 Skill。
步骤二:测试触发混乱
现在让我们重新初始化 Agent(加载新的 Skills),然后测试这个 Skill 的触发行为。我们会用几个不同的请求来测试,看看是否都会触发 ai-dev-assistant。
# 重新初始化 Agent(加载新的 Skills)
agent = initialize_agent(
api_key=api_key,
base_url="https://api.deepseek.com",
model="deepseek-chat",
temperature=0.7,
skills_dir=skills_dir,
base_dir=Path(".")
)
print("\n=== 测试 1:代码审查请求 ===")
response1 = chat(agent, "帮我看看这段代码有没有问题")
print(f"Agent 回复: {response1[:200]}...\n")
print("\n=== 测试 2:Bug 修复请求 ===")
response2 = chat(agent, "这个函数报错了,帮我修复一下")
print(f"Agent 回复: {response2[:200]}...\n")
print("\n=== 测试 3:性能优化请求 ===")
response3 = chat(agent, "这段代码运行太慢了,能优化吗")
print(f"Agent 回复: {response3[:200]}...\n")
执行后,你会发现一个严重的问题:无论用户说什么,Agent 都倾向于触发 ai-dev-assistant 这个 Skill。因为它的描述太宽泛了,几乎任何与开发相关的请求都能匹配上。这就是"触发污染"——一个设计糟糕的 Skill 会干扰其他 Skills 的正常触发。
步骤三:观察执行失败
即使 ai-dev-assistant 被成功触发,它的执行过程也会遇到问题。让我们用流式对话来观察 Agent 的执行过程。
async def observe_swiss_army_knife():
print("用户: 帮我审查这段代码的安全性\n")
async for event in chat_stream(agent, "帮我审查这段代码的安全性"):
if event["type"] == "token":
print(event["content"], end="", flush=True)
elif event["type"] == "tool_start":
print(f"\n\n[[工具调用] 调用工具: {event['tool']}]")
elif event["type"] == "tool_end":
print(f"[[OK] 工具执行完成]\n")
elif event["type"] == "done":
print("\n\n[对话结束]")
await observe_swiss_army_knife()
执行后,本来你会看到 Agent 在执行过程中不断做决策分支判断:“这是代码审查任务吗?还是安全审计任务?还是性能优化任务?“类似情况,但是因为目前大模型的Agent能力还是不错的所以没有很明显的触发这种错误决策,但是还是可能会导致这种不断的分支判断导致执行效率极低,而且很容易在某个分支上卡住。需要注意
步骤四:总结问题
通过这个案例,我们看到了"万能 Skill"的两大问题:
ai-dev-assistant 核心问题总结
| 问题类型 | 具体表现 | 根本原因 |
|---|---|---|
| 触发混乱 | 几乎任何开发相关请求都会触发 | 描述过于宽泛,缺乏明确边界 |
| 执行低效 | 不断做分支判断,容易卡住 | 步骤爆炸,缺乏清晰的执行路径 |
| 维护困难 | 487 行 SKILL.md,改一处影响全局 | 违反单一职责原则 |
这个案例告诉我们第一个设计原则:一个 Skill 只做一件事,并把它做好(Single Responsibility Principle)。
2.3 案例2:code-bomb-deployer(厨房水槽) 链接到标题
第二个反面案例是 code-bomb-deployer,它的设计者犯了另一个典型错误:把代码、配置、文档、示例全部塞进一个 SKILL.md 文件,就像厨房水槽里堆满了各种杂物。
步骤一:查看 Skill 定义
让我们读取这个 Skill 的定义文件,看看它的内容结构。
# 读取 code-bomb-deployer 的 SKILL.md
skill_path = skills_dir / "code-bomb-deployer" / "SKILL.md"
with open(skill_path, 'r', encoding='utf-8') as f:
content = f.read()
print("=== code-bomb-deployer SKILL.md 结构分析 ===")
print(f"文件总长度: {len(content)} 字符")
print(f"文件总行数: {len(content.splitlines())} 行")
# 统计代码块数量
code_blocks = content.count("```")
print(f"代码块数量: {code_blocks // 2} 个")
# 显示前 800 字符
print("\n=== 文件内容(前 800 字符)===")
print(content[:1000])
print("\n...")
执行后,你会发现这个文件长达 312 行,包含了大量的 Python 代码示例、SQL 查询模板、可视化配置等内容。所有这些内容都混杂在一起,没有清晰的分离。
步骤二:测试执行混乱
现在让我们测试这个 Skill 的执行行为。我们让 Agent 执行一个数据分析任务,看看会发生什么。
print("=== 测试 code-bomb-deployer 执行 ===")
response = chat(agent, "帮我分析一下 data.csv 文件中的数据")
print(f"Agent 回复:\n{response}")
执行后,你会发现 Agent 的行为非常混乱。它可能会:
直接执行 SKILL.md 中的示例代码(但文件名是硬编码的
data.csv,可能不存在)把代码示例当成执行步骤的一部分,导致逻辑错误
在代码示例和执行指令之间反复横跳,不知道该做什么
这就是"结构混乱"的典型表现:Agent 无法区分哪些是"指令”、哪些是"参考资料”。
步骤三:观察失败现象
让我们用流式对话来观察 Agent 的详细执行过程,看看它是如何"迷失"在混乱的 SKILL.md 中的。
async def observe_kitchen_sink():
print("用户: 加载 sales.csv 并清洗数据\n")
async for event in chat_stream(agent, "加载 sales.csv 并清洗数据"):
if event["type"] == "token":
print(event["content"], end="", flush=True)
elif event["type"] == "tool_start":
print(f"\n\n[[工具调用] 调用工具: {event['tool']}]")
print(f"[参数: {str(event['input'])[:100]}...]")
elif event["type"] == "tool_end":
result = event['output'][:200] if event['output'] else "无输出"
print(f"[[OK] 工具输出: {result}...]\n")
elif event["type"] == "done":
print("\n\n[对话结束]")
await observe_kitchen_sink()
执行后,你会看到 Agent 可能会尝试执行 SKILL.md 中的示例代码,但由于文件名不匹配(示例中是 data.csv,用户请求的是 sales.csv),导致执行失败。这种不确定性导致了执行成功率极低。
步骤四:总结问题
通过这个案例,我们看到了"厨房水槽"式设计的核心问题:
code-bomb-deployer 核心问题总结
| 问题类型 | 具体表现 | 根本原因 |
|---|---|---|
| 结构混乱 | 代码、配置、文档混杂在一起 | 缺乏关注点分离 |
| 执行混乱 | Agent 无法区分指令和示例 | 没有明确的执行边界 |
| 维护困难 | 修改代码影响文档,修改文档影响流程 | 耦合度过高 |
这个案例告诉我们第二个设计原则:代码、配置、文档要分离,SKILL.md 只写执行流程(Separation of Concerns)。
2.4 案例3:encyclopedia-translator(复制粘贴文档) 链接到标题
第三个反面案例是 encyclopedia-translator,它的设计者犯了一个看似"聪明"实则"致命"的错误:直接把第三方 API 的官方文档复制粘贴到 SKILL.md 中。
步骤一:查看 Skill 定义
让我们先看看这个 Skill 的文件大小,感受一下"文档堆砌"的程度。
# 读取 encyclopedia-translator 的 SKILL.md
skill_path = skills_dir / "encyclopedia-translator" / "SKILL.md"
with open(skill_path, 'r', encoding='utf-8') as f:
content = f.read()
print("=== encyclopedia-translator SKILL.md 规模分析 ===")
print(f"文件总长度: {len(content)} 字符")
print(f"文件总行数: {len(content.splitlines())} 行")
print(f"文件大小: {len(content.encode('utf-8')) / 1024:.2f} KB")
# 显示前 1000 字符
print("\n=== 文件内容(前 1000 字符)===")
print(content[:1000])
print("\n...")
执行后,你会震惊地发现这个文件长达 2847 行,包含了大量从 Stripe、Twilio、SendGrid 等服务的官方文档中复制的内容。设计者的想法是:“把所有信息都给 Agent,它就能自己学会怎么用了。“但现实是:Agent 根本无法从 2847 行的文档中提取出"应该做什么”。
步骤二:测试执行缓慢
现在让我们测试这个 Skill 的执行速度。我们会记录 Agent 从接收请求到开始执行的时间,看看"信息过载"对性能的影响。
import time
print("=== 测试 encyclopedia-translator 执行速度 ===")
# 记录开始时间
start_time = time.time()
# 发送请求
response = chat(agent, "帮我用 Stripe 创建一个 100 美元的支付订单")
# 记录结束时间
end_time = time.time()
elapsed = end_time - start_time
print(f"\n总耗时: {elapsed:.2f} 秒")
print(f"\nAgent 回复:\n{response[:500]}...")
执行后,你会发现整个过程耗时远超正常水平(可能超过 3分钟)。这是因为 Agent 需要花费大量时间阅读和理解 2847 行的文档内容。
步骤三:观察 Agent 迷失
让我们用流式对话来观察 Agent 的详细行为,看看它是如何"迷失"在文档中的。
async def observe_copy_paste_doc():
print("用户: 创建一个 Stripe 支付订单\n")
token_count = 0
async for event in chat_stream(agent, "创建一个 Stripe 支付订单,金额 50 美元"):
if event["type"] == "token":
print(event["content"], end="", flush=True)
token_count += 1
# 只显示前 500 个 token,避免输出过长
if token_count > 500:
print("\n\n[输出过长,已截断...]")
break
elif event["type"] == "tool_start":
print(f"\n\n[[工具调用] 调用工具: {event['tool']}]")
elif event["type"] == "tool_end":
print(f"[[OK] 工具执行完成]\n")
elif event["type"] == "done":
print("\n\n[对话结束]")
await observe_copy_paste_doc()
执行后,你会看到 Agent 开始输出大量的 API 文档内容,而不是直接执行任务。它会先输出关于 Authentication 的说明、然后是 PaymentIntent 对象的详细字段说明、然后是各种可选参数的解释……这就是典型的"信息过载"导致的"迷失"现象。
步骤四:总结问题
通过这个案例,我们看到了"文档堆砌"的严重后果:
encyclopedia-translator 核心问题总结
| 问题类型 | 具体表现 | 根本原因 |
|---|---|---|
| 执行缓慢 | 触发判断耗时 18+ 秒 | 文档过长,Agent 需要大量时间理解 |
| Agent 迷失 | 输出文档内容而不是执行任务 | 无法区分背景知识和执行步骤 |
| 成功率低 | 经常因为信息过载而失败 | 关键信息被淹没在大量文档中 |
这个案例告诉我们第三个设计原则:信息要精炼,详细文档通过链接引用(Information Minimalism)。
2.5 从反面看本质 链接到标题
通过执行这三个反面案例,我们亲眼看到了坏 Skill 设计的真实表现。现在让我们从这些失败现象中提炼出核心教训。

让我们用一个对比表格来总结这三个案例的共性问题:
三大反面案例核心问题与设计原则
| 案例名称 | 核心问题 | 症状表现 | 根本原因 | 对应设计原则 |
|---|---|---|---|---|
| ai-dev-assistant | 职责不清 | 触发混乱、执行低效 | 违反单一职责原则 | 一个 Skill 只做一件事 |
| code-bomb-deployer | 结构混乱 | 代码与文档混杂 | 缺乏关注点分离 | 代码、配置、文档要分离 |
| encyclopedia-translator | 信息过载 | Agent 迷失在文档中 | 没有提炼执行要点 | 信息要精炼,文档用链接 |
这三个问题背后,隐藏着一个更深层的认知误区:很多人把 Skill 当成"给 AI 的知识库”,而不是"给 AI 的执行指令"。这导致他们在设计 Skill 时,总是想"塞进更多信息",而不是"提炼关键步骤"。
但 Agent Skill 的本质是什么?它是一个可执行的流程规范,而不是一个知识百科。一个好的 Skill 应该像一份"作战指令":清晰、简洁、可执行。而不是像一本"参考手册":详尽、冗长、需要理解。
在下一批次的课程中,我们会从这三个反面案例中提炼出正面的设计规则,并通过真实的好案例来展示:什么样的 Skill 才是真正可用、可维护、可扩展的。
2.6 三层架构概念 链接到标题
在结束这一章之前,我们再来看一个重要概念:Skill 的三层架构。这个架构是理解"为什么要脚本外置"“为什么要保持精简"的关键。
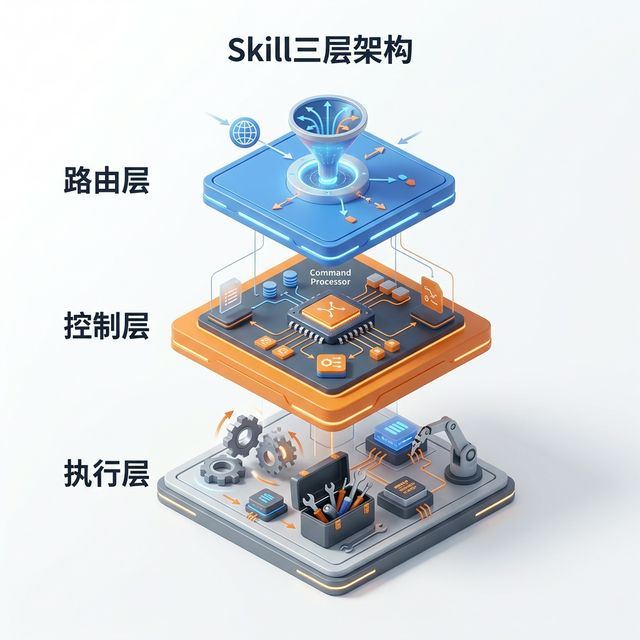
一个设计良好的 Skill,应该清晰地分为三层:
路由层(frontmatter):
- 位置:SKILL.md 文件顶部的 YAML 区域
- 职责:触发匹配(name、description)
- 大小:通常 3-5 行
控制层(SKILL.md 正文):
- 位置:SKILL.md 的 Markdown 正文
- 职责:决策和流程(Goal、Workflow、Decision Tree、Constraints、Validation)
- 大小:60-100 行
执行层(scripts/ + references/ + assets/):
- 位置:独立的子目录
- 职责:具体操作
- 大小:不限,按需扩展
这三层的关系是:路由层决定"要不要激活”,控制层决定"怎么做决策",执行层负责"具体怎么做"。
当你在设计 Skill 时,随时问自己:这段内容应该放在哪一层?如果你发现自己在 SKILL.md 里写了大量代码或详细文档,说明你混淆了控制层和执行层的职责。
本章小结
通过三个反面案例的实战执行,我们建立了对"坏 Skill"的直观认知。这些案例告诉我们:
ai-dev-assistant 教训:一个 Skill 只做一件事,触发描述要精准
code-bomb-deployer 教训:代码、配置、文档要分离,SKILL.md 只写执行流程
encyclopedia-translator 教训:信息要精炼,详细文档通过链接引用
这三个教训会成为我们后续设计 Skill 的基本原则。在下一批次的课程中,我们会看到:当这些原则被正确应用时,Skill 的质量会发生质的飞跃。
恭喜! 你已经完成了第一批次课程的学习。现在你不仅拥有了一个可以执行 Skills 的 Agent 环境,还通过反面案例建立了对"什么是坏设计"的深刻认知。这种从失败中学习的方式,会让你在后续学习正面规则时,自然而然地理解每条规则背后的原因。
在第一章和第二章中,我们完成了 Agent 实验环境的搭建,并通过三个典型的反面案例——ai-dev-assistant、code-bomb-deployer、encyclopedia-translator——建立了对“什么是坏 Skill”的直观认知。
现在,我们即将进入课程的第二阶段:从反面案例提炼正面规则,再将规则升华为可复用的设计范式。第二章将带你系统梳理单一职责原则(SRP)、关注点分离(SoC)和信息精炼原则这三条核心设计规则;第三章则进一步引入 7 种 Agent Skill 设计范式,帮助你在面对不同需求时快速选型、有据可依。接下来,让我们直接进入第二章。
第三章:规则提炼——从反面到正面 链接到标题
在第一章中,我们通过三个反面案例看到了 Agent Skill 设计中最常见的三类问题:职责不清、结构混乱、信息冗余。这些问题不是偶然的,它们背后反映的是设计原则的缺失。今天我们要做的,就是从这些反面案例中提炼出正面的设计规则,让你在设计 Skill 时有明确的判断标准。之所以先从反面案例出发,是因为错误往往比定义更容易暴露问题边界,也更能帮助我们建立稳定的判断感觉。
这一章的核心目标是回答三个问题:第一,如何判断一个 Skill 的职责是否单一?第二,如何合理划分 SKILL.md、代码实现、配置文件的边界?第三,如何从冗长的文档中提炼出执行要点?我们会从 ai-dev-assistant、code-bomb-deployer、encyclopedia-translator 三个反面案例出发,逐一提炼出单一职责原则(SRP)、关注点分离(SoC)、信息精炼原则这三条核心规则。
更重要的是,这三条规则不是孤立的,它们会协同作用。当你掌握了这三条规则之后,你会发现设计 Skill 不再是"凭感觉",而是有章可循的工程实践。你也可以把它们理解为分别作用在 3 个层面:边界是否清晰、结构是否合理、信息是否高效。接下来,我们先从第一条规则——单一职责原则开始。
3.1 单一职责原则(SRP) 链接到标题
回顾第一章的 ai-dev-assistant 案例,我们看到一个 Skill 试图同时处理代码审查、Bug 修复、重构、测试等多个任务,结果是 Agent 不知道该触发哪个功能,执行效率极低。这个问题的根源在于:一个 Skill 承担了多个职责。
单一职责原则(Single Responsibility Principle, SRP)最早由 Robert C. Martin 在软件工程领域提出,核心思想是"一个模块应该只有一个引起它变化的原因"。在 Agent Skill 的设计中,这条原则可以翻译为:一个 Skill 应该只解决一个明确的问题,只有一个清晰的调用理由。如果一个 Skill 同时承载多个调用理由,最直接的后果就是触发条件变模糊、维护边界变混乱,最后连评估它是否设计合理都会变得困难。
3.1.1 如何判断职责是否单一 链接到标题
判断一个 Skill 是否符合单一职责原则,可以用以下三个测试。这三个测试分别从功能描述、变更来源和使用场景三个角度交叉验证,能帮助我们更稳地看清职责边界:
测试一:一句话描述测试
尝试用一句话描述这个 Skill 的功能,如果需要用"和"、“或”、“以及"等连接词,说明职责不单一。
一句话描述测试对比
| Skill 名称 | 描述 | 是否单一 | 问题 |
|---|---|---|---|
project-init | 初始化项目结构 | 是 | 无 |
ai-dev-assistant | 创建项目和生成文档以及运行测试 | 否 | 包含三个独立职责 |
markdown-to-notebook | 将 Markdown 转换为 Jupyter Notebook | 是 | 无 |
测试二:变化原因测试
列举可能导致这个 Skill 需要修改的原因,如果超过一个,说明职责不单一。
以 ai-dev-assistant 为例,它可能因为以下原因需要修改:
项目模板结构变化 → 需要修改"创建项目"逻辑
文档生成规范变化 → 需要修改"生成文档"逻辑
测试框架升级 → 需要修改"运行测试"逻辑
三个不同的变化原因,意味着三个不同的职责。
测试三:调用场景测试
列举用户会在什么场景下调用这个 Skill,如果场景之间没有强关联,说明职责不单一。
ai-dev-assistant 的调用场景:
场景1:用户想快速搭建项目骨架 → 只需要"创建项目”
场景2:用户想为现有项目生成 API 文档 → 只需要"生成文档"
场景3:用户想验证代码质量 → 只需要"运行测试"
这三个场景是独立的,用户很少会同时需要这三个功能。
3.1.2 职责边界的划分方法 链接到标题
确定了职责不单一之后,下一步是如何划分边界。这里的拆分重点不是按文件、按技术栈去切,而是按用户真正要解决的问题去切。我们可以用问题域分解法来拆分:
步骤一:识别核心问题
从用户视角出发,这个 Skill 要解决的核心问题是什么?
ai-dev-assistant的核心问题:项目初始化、文档生成、测试执行
步骤二:检查问题独立性
这些问题是否可以独立存在?是否有强依赖关系?
“项目初始化"可以独立完成,不依赖文档和测试
“文档生成"可以独立完成,不依赖项目初始化
“测试执行"可以独立完成,不依赖项目初始化
结论:三个问题都是独立的,应该拆分为三个 Skill。
步骤三:定义清晰的输入输出
每个独立的问题都应该有明确的输入和输出:
拆分后的 Skill 输入输出定义
| Skill 名称 | 输入 | 输出 | 职责 |
|---|---|---|---|
project-init | 项目名称、模板类型 | 项目目录结构 | 初始化项目骨架 |
doc-generator | 代码路径、文档格式 | 文档文件 | 生成 API 文档 |
test-runner | 测试路径、测试框架 | 测试报告 | 执行测试并生成报告 |
常见误区:有些开发者认为"拆分会导致 Skill 数量爆炸”,实际上合理的拆分会让系统更清晰。记住:宁可多几个小 Skill,也不要一个大而全的 Skill。
3.2 关注点分离(SoC) 链接到标题
解决了职责单一的问题之后,我们来看第二个问题:如何组织 Skill 的内容。回顾第一章的 code-bomb-deployer 案例,我们看到 SKILL.md 中混杂了执行指令、代码实现、配置参数、使用文档,导致 Agent 无法快速定位执行要点。这个问题的根源在于:不同类型的信息没有分离。
关注点分离(Separation of Concerns, SoC)是软件工程中的经典原则,核心思想是"不同性质的信息应该放在不同的地方”。在 Agent Skill 的设计中,这条原则可以翻译为:SKILL.md 只包含执行指令,代码实现放在独立文件,配置参数放在配置文件。它真正要解决的,不是目录看起来是否整齐,而是避免执行指令、实现细节、运行参数混在一起,让 Agent 读不出重点,也让维护者很难快速定位问题。
3.2.1 三类信息的边界 链接到标题
在 Agent Skill 中,我们需要区分三类信息。如果把这些信息混放在一起,最常见的结果就是执行指令被实现细节淹没,真正需要 Agent 关注的重点反而最不突出:
类型一:执行指令(What & How)
这是 SKILL.md 的核心内容,回答"做什么"和"怎么做"两个问题:
Agent 应该执行哪些步骤
每个步骤的输入输出是什么
步骤之间的依赖关系
异常情况的处理方式
类型二:代码实现(Implementation)
这是具体的代码逻辑,应该放在独立的 .py 文件中:
数据处理函数
API 调用封装
工具类和辅助函数
类型三:配置参数(Configuration)
这是可变的参数,应该放在 assets/templates/ 目录或通过环境变量管理:
API 密钥(通过环境变量)
文件路径(通过环境变量或配置模板)
超参数(通过
assets/templates/中的配置模板)运行时参数(通过脚本参数传递)
三类信息的边界划分
| 信息类型 | 存放位置 | 变化频率 | 读取者 |
|---|---|---|---|
| 执行指令 | SKILL.md | 低(设计时确定) | Agent |
| 代码实现 | scripts/*.py | 中(功能迭代) | Python 解释器 |
| 配置参数 | assets/templates/ 或环境变量 | 高(每次使用可能不同) | 脚本运行时 |
| 领域知识 | references/ | 低(知识相对稳定) | Agent(按需引用) |
3.2.2 标准 Skill 目录结构 链接到标题
遵循关注点分离原则,一个标准的 Skill 目录结构应该是这样的(基于 skill-creator-pro 官方最佳实践):
my-skill/
├── SKILL.md # 主文件(路由层,100-500行)
├── scripts/ # 可执行脚本(自动化重复操作)
│ ├── process_data.py # 按功能拆分,不是单一文件
│ ├── validate.py
│ └── cleanup.sh
├── references/ # 参考文档(领域知识、详细规则)
│ ├── core/ # 核心参考(必读)
│ │ ├── api-guide.md
│ │ └── examples.md
│ ├── advanced/ # 高级参考(可选)
│ │ └── edge-cases.md
│ └── templates/ # 模板文件
│ └── config-template.yaml
├── assets/ # 输出素材(模板、配置、示例输出)
│ ├── templates/ # 输出模板
│ └── examples/ # 示例输出
├── agents/ # 子 Agent 定义(可选,复杂协作时使用)
│ └── reviewer.md
└── tests/ # 测试用例(可选)
└── test_skill.py
每个目录的职责:
SKILL.md:面向 Agent,作为路由层,包含 Goal、Workflow、Decision Tree、Constraints、Validation、Resources 六个核心部分,不是教科书,不包含详细领域知识
scripts/:面向自动化,存放可重复执行的脚本,按功能拆分为多个文件,不是单一的
skill.pyreferences/:面向知识管理,存放领域知识和详细规则,分为
core/(核心必读)和advanced/(高级可选)assets/:面向输出,存放模板和示例输出,是"输出素材"而非"输入文档”
agents/:面向协作,存放子 Agent 定义(仅在复杂协作场景使用,如多模式 Skill)
tests/:面向质量,存放测试用例
这个结构遵循 Claude Code 官方的 skill-creator 最佳实践,核心理念是:SKILL.md 是路由层,不是教科书。它的首要任务,是帮助 Agent 快速判断下一步该做什么、调用什么,而不是一次性吸收全部背景知识。详细的领域知识应该放在 references/ 中,可重复执行的脚本应该放在 scripts/ 中,输出素材应该放在 assets/ 中。
踩坑预警:很多人喜欢在 SKILL.md 中嵌入大量代码示例,认为这样"更详细"。但实际上,代码示例应该放在独立的文件中,SKILL.md 只需要说明"调用哪个函数、传入什么参数"。
3.3 信息精炼原则 链接到标题
解决了职责单一和关注点分离的问题之后,我们来看第三个问题:如何处理大量的背景知识和文档。回顾第一章的 encyclopedia-translator 案例,我们看到 SKILL.md 中直接复制粘贴了 2000+ 行的官方文档,导致 Agent 无法快速找到执行要点。这个问题的根源在于:没有区分"背景知识"和"执行要点"。
信息精炼原则的核心思想是:SKILL.md 只包含执行必需的信息,背景知识通过引用的方式提供。这里的"精炼"并不是删得越多越好,而是要把执行路径压缩到最短,同时确保关键参数、必要上下文和异常处理都还清晰可见。这样 Agent 既不会被背景材料淹没,也不会因为信息缺失而走错。这条原则可以用一个公式表达:
SKILL.md 内容 = 执行步骤 + 关键参数 + 异常处理 + 文档引用
3.3.1 如何提炼执行要点 链接到标题
从大量文档中提炼执行要点,可以用三步过滤法。它的目标不是把文档重新总结一遍,而是尽可能抽取出执行所需的最小信息集:
步骤一:识别执行路径
从文档中找出"用户要完成任务需要执行哪些步骤",忽略背景介绍、原理解释、历史演进等内容。
步骤二:提取关键参数
从文档中找出"哪些参数是必需的,哪些参数会影响执行结果",忽略可选参数和默认值。
步骤三:标注异常情况
从文档中找出"哪些情况会导致执行失败,如何处理",忽略边缘情况和理论分析。
3.3.2 文档引用 vs 文档嵌入的选择标准 链接到标题
文档引用 vs 文档嵌入的选择标准
| 信息类型 | 是否执行必需 | 处理方式 | 示例 |
|---|---|---|---|
| 执行步骤 | 是 | 嵌入 SKILL.md | “步骤一:定义 Prompt 模板” |
| 关键参数 | 是 | 嵌入 SKILL.md | “template:Prompt 模板字符串” |
| 异常处理 | 是 | 嵌入 SKILL.md | “模板变量未提供 → 报错” |
| 设计理念 | 否 | 引用外部文档 | “详见 LangChain 官方文档” |
| 完整 API | 否 | 引用外部文档 | “API 参考: https://…” |
| 示例代码 | 视情况 | < 20行嵌入, > 20行引用 | 最小示例嵌入,完整示例引用 |
常见误区:很多人认为"给 Agent 的信息越多越好",但实际上,信息过载会严重降低 Agent 的执行效率。一个好的 Skill 应该像"作战指令"一样简洁明确,而不是像"百科全书"一样详尽冗长。
3.4 三大规则的协同效应 链接到标题
到这里,我们已经分别学习了单一职责原则(SRP)、关注点分离(SoC)和信息精炼原则。但在实际设计中,这三条规则并不是孤立使用的,而是协同作用形成一个完整的设计体系。很多 Skill 出问题时,往往也不是只违反了其中一条:职责边界一旦模糊,结构就会跟着混乱,信息一多又会进一步掩盖真正的执行重点。
3.4.1 三条规则如何共同作用 链接到标题
三条规则的协同关系可以用一个设计漏斗来理解:

在这个漏斗中,三条规则按顺序发挥作用:
第一层:SRP(单一职责原则)
SRP 是设计的起点,它帮助我们确定 Skill 的边界。通过 SRP,我们将一个模糊的需求,明确为一个聚焦的 Skill。
第二层:SoC(关注点分离)
在确定了 Skill 的职责边界后,SoC 帮助我们组织 Skill 的内部结构。通过 SoC,我们将一个单一职责的 Skill,组织成了结构清晰的多个部分。
第三层:信息精炼原则
在结构清晰之后,信息精炼原则帮助我们优化每个部分的内容。通过信息精炼,我们将一个结构清晰的 Skill,优化为一个高效简洁的 Skill。
协同效应的本质:SRP 确定边界 → SoC 组织结构 → 信息精炼优化内容。
3.4.2 规则冲突时的优先级判断 链接到标题
当规则之间出现冲突时,我们需要一个优先级判断标准:
规则冲突时的优先级判断
| 冲突场景 | 优先规则 | 判断依据 | 示例 |
|---|---|---|---|
| SRP vs SoC | SRP | 职责边界 > 结构清晰 | 宁可拆分为两个 Skill,也不要在一个 Skill 中混合多个职责 |
| SoC vs 信息精炼 | SoC | 结构清晰 > 内容简洁 | 宁可保留必要的上下文信息,也不要为了精炼而丢失关键逻辑 |
| SRP vs 信息精炼 | SRP | 职责边界 > 内容简洁 | 宁可保持单一职责,也不要为了精炼而合并不相关的功能 |
从表格可以看出,SRP 的优先级最高。这是因为职责边界是 Skill 设计的基础,如果职责不清,后续的结构组织和信息精炼都会失去方向。换句话说,边界错了,后面做得越精致,往往只是把一个本来就不该放在一起的东西整理得更漂亮而已。
3.4.3 设计检查清单 链接到标题
为了确保设计质量,我们需要一个检查清单来验证 Skill 是否符合三大规则:
Agent Skills 设计检查清单
| 检查项 | 检查内容 | 通过标准 | 不通过示例 |
|---|---|---|---|
| SRP 检查 | |||
| 职责唯一性 | Skill 是否只负责一个明确的任务? | 可以用一句话描述 Skill 的职责 | “这个 Skill 负责数据处理、日志记录和邮件通知” |
| 变更原因单一 | 修改 Skill 的原因是否唯一? | 只有一类需求变更会影响这个 Skill | “需求变更、日志格式变更、邮件模板变更都会影响这个 Skill” |
| SoC 检查 | |||
| 结构完整性 | 是否包含必要的结构部分? | 至少包含执行指令部分 | 只有一段文字,没有任何结构标记 |
| 关注点独立 | 不同类型的信息是否分开表达? | 执行流程、上下文信息、外部依赖分别在不同部分 | 执行流程和上下文信息混在一起 |
| 信息精炼检查 | |||
| 长度合理性 | Skill 总长度是否在 100-500 行之间? | 核心 Skill 100-200 行,复杂 Skill 200-500 行 | 超过 1000 行 |
| 冗余消除 | 是否存在重复或冗余的信息? | 每条信息只出现一次 | 同一个配置项在多个地方重复说明 |
本章小结
通过本章的学习,我们从三个反面案例中提炼出了三条核心设计规则。这三条规则分别回答了 Skill 设计中最关键的 3 个问题:边界怎么定、结构怎么放、信息怎么收。
单一职责原则(SRP):一个 Skill 只做一件事,并把它做好
关注点分离(SoC):SKILL.md、代码实现、配置参数各司其职
信息精炼原则:只保留执行必需的信息,背景知识通过引用提供
这三条规则不是孤立的,而是按 SRP → SoC → 信息精炼的顺序协同作用。当规则冲突时,优先保证职责边界清晰,因为一旦边界划错了,后面无论是整理结构还是压缩内容,本质上都只是在优化一个方向错误的设计对象。在下一章中,我们将学习四种经典的 Skill 设计模式,看看如何将这三条规则应用到具体的设计场景中,也就是从"守住底线"进一步走向"正确选型"。
第四章:范式认知——四种核心设计模式 链接到标题
在理解了三条底线规则之后,我们现在进入最核心的部分:设计范式。如果说前两章告诉你"什么不该做",那么这一章将告诉你"应该怎么做"。
设计范式(Design Paradigm)是经过验证的设计模式,它们代表了业界在大量实践中总结出来的最佳实践。掌握这些范式,你就能在面对不同类型的任务时,快速选择合适的设计方案,而不是每次都从零开始摸索。更重要的是,范式的价值不只是提供一个名字,而是帮你在拿到新任务时,迅速判断这个任务的主矛盾是什么,应该先组织流程、先探索环境,还是先拉用户进入决策。
总结了 7 种设计范式,但根据使用频率统计,前 4 种范式覆盖了 85% 的实际场景。因此,本课程聚焦这 4 种核心范式:Operator(工具链封装)、Scout(环境不确定任务)、Partner(交互式任务)、Navigator(路由和查找)。它们基本对应了 4 类最高频任务:确定性执行、环境探索、人机协作、条件分流。掌握这 4 种,你就能先建立一套默认选型框架,在绝大多数 Skill 设计里先做出正确的第一判断。
4.1 范式概述与使用频率 链接到标题
在深入每个范式之前,我们先来看一个全局视图:7 种范式的使用频率分布。
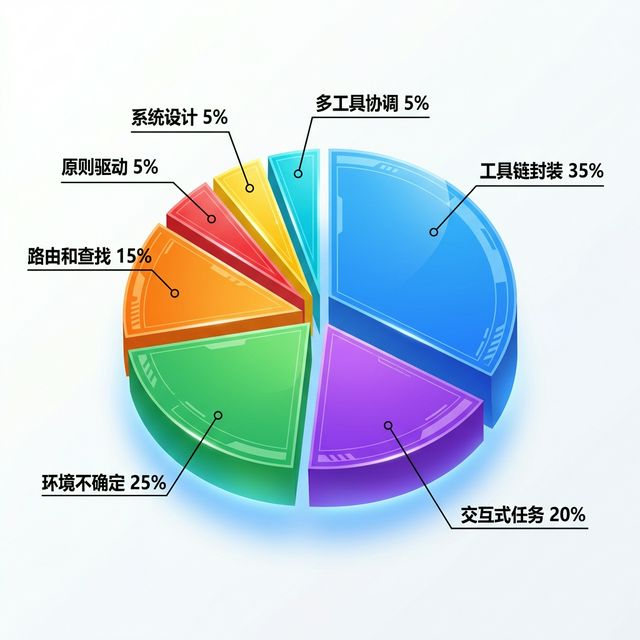
七种设计范式使用频率分布
| 范式 | 使用频率 | 适用场景 | 本课程覆盖 |
|---|---|---|---|
| Operator(工具链封装) | 35% | 文档处理、数据转换、部署流程 | 核心讲解 |
| Scout(环境不确定任务) | 25% | 代码分析、系统诊断、信息收集 | 核心讲解 |
| Partner(交互式任务) | 20% | 需求澄清、设计评审、风险决策 | 核心讲解 |
| Navigator(路由和查找) | 15% | 多阶段搜索、条件分发、资源导航 | 核心讲解 |
| Philosopher(原则驱动) | 进阶,5% | 设计宪法、质量评估、规范检查 | 课后扩展 |
| Architect(系统设计) | 进阶,5% | 学习路径、架构设计、系统规划 | 课后扩展 |
| Orchestrator(多工具协调) | 高级,5% | 多模型协作、复杂工作流、故障恢复 | 课后扩展 |
从这个分布可以看出,Operator 和 Scout 两种范式占据了 60% 的使用场景,这是因为大多数 Skill 要么是"封装确定性操作"(Operator),要么是"在不确定环境中探索"(Scout)。接下来我们会详细讲解这 4 种核心范式。
4.2 范式1:Operator(工具链封装) 链接到标题
Operator 是使用频率最高的范式(35%),它的核心思想是:将重复的工具操作封装为确定性流程。它最适合处理那些高频、稳定、可验证、又容易因为人工操作而出错的任务。换句话说,Operator 的重点不是让 Agent 临场自由发挥,而是把已经证明可行的操作路径沉淀为一条可复用的流水线,让执行更稳定、结果更一致。
4.2.1 定义与适用场景 链接到标题
当你的任务满足以下特征时,应该选择 Operator 范式。判断时不要先看你用了多少工具,而要先看流程本身是否已经足够稳定、可预测、可验证:
操作步骤是确定的(不需要探索或试错)
涉及工具链调用(脚本、命令、API)
需要严格验证(每一步都有明确的成功标准)
容易出现人为错误(手动操作容易遗漏步骤)
典型的 Operator 场景包括:文档格式转换、数据清洗、代码部署、测试执行、报告生成等。这些场景的共同点是,一旦流程被验证有效,最有价值的就不再是临场判断,而是减少遗漏、降低波动,并把重复劳动稳定交给工具链。
4.2.2 设计重点 链接到标题
Operator 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 脚本优先 | 所有确定性操作都应该脚本化 | scripts/extract_text.py、scripts/validate_output.sh |
| 严格验证 | 每一步都要检查执行结果 | 检查文件是否存在、API 返回码是否为 200 |
| 错误处理 | 明确定义失败场景和恢复策略 | 如果步骤 2 失败,回滚步骤 1 的变更 |
| 幂等性 | 重复执行不会产生副作用 | 多次运行同一个脚本,结果一致 |
4.2.3 真实案例分析:document-summarizer 链接到标题
让我们看一个典型的 Operator 范式案例:document-summarizer(文档摘要生成器)。这个案例很有代表性,因为它既包含多个明确的工具环节,又有清晰的验收标准,正好能体现 Operator 从输入到输出的闭环执行特征。
需求:用户上传一个长文档(PDF/Word/Markdown),系统自动生成结构化摘要。
为什么选择 Operator:
操作步骤确定:提取文本 → 分块 → 总结 → 格式化输出
涉及工具链:PDF 解析库、文本分块算法、LLM API
需要严格验证:每一步都要检查输出是否符合预期
目录结构:
document-summarizer/
├── SKILL.md # 控制层(80行)
├── scripts/
│ ├── extract_text.py # 提取文档文本
│ └── chunk_document.py # 分块处理大文档
├── references/
│ └── summarization-strategies.md # 总结策略(按需加载)
└── assets/
└── summary-template.md # 输出模板
SKILL.md 核心片段(简化展示):
## Workflow
1. **验证输入**:检查文档格式是否支持(PDF/DOCX/MD)
2. **提取文本**:调用 `scripts/extract_text.py`
3. **分块处理**:如果文档 >5000 字,调用 `scripts/chunk_document.py`
4. **生成摘要**:使用 LLM API 生成结构化摘要
5. **格式化输出**:应用 `assets/summary-template.md` 模板
6. **验证完整性**:检查摘要是否覆盖所有关键章节
## Validation
- 摘要长度应为原文的 10-15%
- 必须包含"核心观点""关键数据""结论"三个部分
- 如果原文有章节标题,摘要必须保留章节结构
4.2.4 反面对照:如果 code-bomb-deployer 用 Operator 范式重构 链接到标题
还记得第一章的 code-bomb-deployer 吗?它把 300 行 bash 代码直接写在 SKILL.md 里。如果用 Operator 范式重构,应该怎么做?
重构前(错误):
SKILL.md:387 行(包含 6 个完整脚本)
scripts/:无
评分:7/25
重构后(正确):
SKILL.md:60 行(只保留决策逻辑)
scripts/:6 个独立脚本(check_server.sh、install_docker.sh、build_image.sh、deploy.sh、setup_nginx.sh、setup_monitoring.sh)
评分:预计 20/25
重构的关键是:SKILL.md 只负责"什么时候调用哪个脚本",不负责"脚本里写什么代码"。
4.3 范式2:Scout(环境不确定任务) 链接到标题
Scout 是第二常用的范式(25%),它的核心思想是:在不确定环境中先侦察再行动。这类任务的难点通常不在于动作本身,而在于一开始信息不完整,如果直接下手,很容易建立在错误假设之上越走越远。Scout 的价值,就是先通过证据建立局部认知,再决定下一步往哪里深入。
4.3.1 定义与适用场景 链接到标题
当你的任务满足以下特征时,应该选择 Scout 范式。这里的关键不在于任务是否复杂,而在于环境是否已知、证据是否充足:
环境是不确定的(不知道代码库结构、不知道系统状态)
需要多轮探索(先看一部分,再决定下一步看什么)
依赖证据驱动(基于观察到的事实做决策,而不是假设)
可能需要回溯(发现走错路了,需要返回重新探索)
典型的 Scout 场景包括:代码分析、系统诊断、Bug 定位、依赖关系梳理、性能瓶颈排查等。这类任务最常见的难点不是不会执行,而是不知道第一步该相信什么、先查哪里,因此必须先把事实摸清楚。
4.3.2 设计重点 链接到标题
Scout 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 侦察优先 | 先用轻量级工具探测,再决定深入方向 | 先 ls 看目录结构,再 grep 搜索关键代码 |
| 证据驱动 | 每个结论都要有观察证据支持 | “发现 3 处调用 API X” → 证据:文件路径 + 行号 |
| 多轮探索 | 允许根据发现调整探索路径 | 发现 A 依赖 B → 转而探索 B 的实现 |
| 状态记录 | 记录已探索的路径,避免重复 | 已检查文件列表、已排除的假设 |
4.3.3 典型流程:探测 → 分析 → 验证 → 报告 链接到标题
Scout 范式的典型工作流是一个四阶段循环。需要注意的是,这四个阶段通常不是一遍走完,而是会随着新证据出现不断回跳和迭代:
探测(Probe):使用轻量级工具快速扫描环境
工具:
ls、find、grep、git log目标:建立初步认知,发现线索
分析(Analyze):深入研究发现的线索
工具:
Read文件、Grep搜索、Bash执行测试目标:理解机制,提出假设
验证(Verify):用证据验证假设
工具:运行测试、检查日志、对比输出
目标:确认或推翻假设
报告(Report):输出结构化发现
格式:问题 + 证据 + 结论 + 建议
目标:让用户快速理解发现
4.3.4 真实案例分析:code-explainer 链接到标题
让我们看一个典型的 Scout 范式案例:code-explainer(代码解释器)。
需求:用户指向一个代码库中的某个功能,系统自动分析并解释它的实现原理。
为什么选择 Scout:
环境不确定:不知道代码库的结构、不知道功能在哪些文件中实现
需要多轮探索:先找到入口函数 → 再追踪调用链 → 再理解依赖关系
证据驱动:每个结论都要引用具体的代码片段
典型执行流程:
用户: "解释一下用户登录功能是怎么实现的"
第1轮探测: grep -r "login" → 发现 auth.py、login_view.py、user_model.py
第2轮分析: Read auth.py → 发现核心函数 authenticate_user()
第3轮验证: grep "authenticate_user" → 确认调用关系
第4轮报告: 输出结构化解释(入口 → 验证 → 会话创建 → 返回)
4.4 范式3:Partner(交互式任务) 链接到标题
Partner 是第三常用的范式(20%),它的核心思想是:需要人机协作、多轮确认的任务。它的关键不只是"多问几个问题",而是把用户纳入关键决策链条:AI 负责组织过程、收敛选项、推进节奏,用户负责提供偏好、补充关键信息,并在高风险节点做最终判断。
4.4.1 定义与适用场景 链接到标题
当你的任务满足以下特征时,应该选择 Partner 范式。如果任务中存在主观偏好、风险承担,或者关键信息只掌握在用户手里,就不能把它当成纯自动化流程:
需求是模糊的(用户一开始说不清楚具体要什么)
涉及主观判断(没有唯一正确答案,需要用户选择)
有风险决策(可能产生不可逆的后果,需要人工确认)
需要状态保持(多轮对话中保持上下文)
典型的 Partner 场景包括:需求澄清、设计评审、方案选型、风险决策、配置向导等。这些场景的共同点是,成功标准通常不是一次性给出唯一答案,而是通过多轮交互逐步收敛到双方都认可的结果。
4.4.2 设计重点 链接到标题
Partner 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 对话契约 | 明确定义每一轮对话的目的和格式 | 第1轮:收集需求 / 第2轮:确认方案 / 第3轮:执行 |
| 人工检查点 | 在关键决策前暂停,等待用户确认 | “即将删除 3 个文件,是否继续?” |
| 状态保持 | 记录对话历史,避免重复询问 | 用户已选择方案 A,后续不再询问 |
| 渐进式澄清 | 从粗到细,逐步收敛需求 | 先问"做什么",再问"怎么做",最后问"细节" |
4.4.3 关键机制:AskUserQuestion 的使用时机 链接到标题
Partner 范式的核心工具是 AskUserQuestion,但什么时候该用、什么时候不该用?真正的难点不在提问本身,而在于只在必要时提问,避免把本来可以自动完成的工作重新推回给用户:
应该使用 AskUserQuestion 的场景:
需求有多种合理解释,需要用户选择
涉及风险操作,需要明确确认
需要用户提供只有他们知道的信息(如 API key、服务器地址)
不应该使用 AskUserQuestion 的场景:
可以通过探测自动获取的信息(如文件是否存在)
有明确的最佳实践,不需要用户选择
过于细节的技术问题(如"用 UTF-8 还是 GBK 编码?")
4.4.4 真实案例分析:frontend-design 链接到标题
让我们看一个典型的 Partner 范式案例:frontend-design(前端设计助手)。这个案例很典型,因为页面目标、审美偏好和风险取舍都带有明显主观性,AI 不能替用户直接拍板,只能通过交互把方案一步步收敛出来。
需求:用户想要创建一个网页,但一开始只有模糊的想法。
为什么选择 Partner:
需求模糊:用户可能只说"我想要一个产品展示页"
主观判断:配色、布局、风格都需要用户选择
多轮澄清:先确定页面类型 → 再确定风格 → 再确定具体元素
典型对话流程:
第1轮: "你想创建什么类型的页面?"
选项: A. 产品展示 / B. 个人博客 / C. 企业官网
第2轮: "选择一个设计风格"
选项: A. 现代简约 / B. 科技感 / C. 温馨亲和
第3轮: "确认页面结构"
预览: [显示布局草图]
选项: A. 确认 / B. 调整
第4轮: "开始生成代码..."
4.5 范式4:Navigator(路由和查找) 链接到标题
Navigator 是第四常用的范式(15%),它的核心思想是:根据条件路由到不同处理路径。它真正创造的价值,并不在于自己完成所有动作,而在于尽快判断问题属于哪一类,应该被送到哪条资源、工具或流程路径上。很多时候,任务最怕的不是慢,而是一开始就走错方向,后面越做越偏。
4.5.1 定义与适用场景 链接到标题
当你的任务满足以下特征时,应该选择 Navigator 范式。当一个任务不是单一路径,而是要先分类、筛选、分流时,就应该优先从路由视角来思考:
有多个子任务,需要根据条件选择
涉及多阶段搜索(先粗筛,再精筛)
需要资源导航(引导用户找到正确的文档/工具)
强调快速失败(尽早判断是否走对路径)
典型的 Navigator 场景包括:技能路由、文档查找、问题分类、多阶段搜索、条件分发等。这类场景最怕的往往不是处理速度慢,而是一开始就被送进错误分支,导致后续投入越来越多却离目标越来越远。
4.5.2 设计重点 链接到标题
Navigator 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 强分支规则 | 每个分支的条件必须清晰、可验证 | 如果文件扩展名是 .py → Python 路径 |
| 清晰引用导航 | 明确告诉用户"下一步去哪里" | “详细文档见 references/api-guide.md” |
| 快速失败 | 尽早判断是否满足条件,不满足立即返回 | 如果不是 Git 仓库 → 立即提示错误 |
| 漏斗式筛选 | 从宽到窄,逐步缩小范围 | 100个候选 → 20个初筛 → 5个精选 |
4.5.3 决策树设计:如何设计清晰的分支条件 链接到标题
Navigator 范式的核心是决策树。它的重点不是把分支设计得越多越好,而是让条件足够清晰、互斥、可验证。一个好的决策树应该满足:
互斥性:每个分支条件不重叠
完备性:覆盖所有可能的输入
可验证性:条件可以通过工具检查
早失败:不满足条件的路径尽早退出
示例决策树(文档查找场景):
输入: 用户查询
├─ 是否包含代码?
│ ├─ 是 → 路由到 code-search
│ └─ 否 → 继续
├─ 是否是 API 相关?
│ ├─ 是 → 路由到 api-docs
│ └─ 否 → 继续
├─ 是否是配置相关?
│ ├─ 是 → 路由到 config-guide
│ └─ 否 → 路由到 general-docs
4.5.4 真实案例分析:skill-scout 链接到标题
让我们看一个典型的 Navigator 范式案例:skill-scout(技能侦察器)。它的代表性在于,系统并不是直接替用户完成任务,而是先在大量候选中识别出最合适的解决路径,再把用户引导到正确资源上。
需求:用户想找一个 Skill 来完成某个任务,系统自动搜索并推荐最合适的 Skill。
为什么选择 Navigator:
多阶段搜索:先搜索本地 → 再搜索 GitHub → 最后搜索官方仓库
漏斗式筛选:100+ 候选 → 20 个初筛 → 5 个精选
资源导航:告诉用户"这个 Skill 在哪里、怎么安装"
典型执行流程:
第1阶段: 本地搜索(~/.claude/skills/)
→ 发现 3 个匹配的本地 Skill
第2阶段: GitHub 搜索(如果本地不够)
→ 发现 15 个开源 Skill
第3阶段: 三层漏斗筛选
→ 60-100 个候选 → 15-20 个初筛 → 5-8 个精选
第4阶段: 生成对比矩阵
→ 输出推荐列表 + 安装命令
4.6 进阶范式概览 链接到标题
到这里,我们已经完成了 4 种核心范式的学习:Operator 负责可靠执行,Scout 负责快速探索,Partner 负责协作共创,Navigator 负责在复杂路径中持续决策。换个角度看,它们也分别对应了任务推进中的 4 种基础能力:执行、侦察、协作、路由。
如果把真实工作场景看成一个完整光谱,那么这 4 种核心范式,已经足以覆盖大约 85% 的日常需求。从能力边界上看,我们已经掌握了”让 AI 去做事””让 AI 去看情况””让 AI 跟我们一起想””让 AI 在过程中持续判断”的基本方法。后面要讲的进阶范式,并不是推翻这些核心范式,而是在它们之上进一步补上规则裁决、全局规划和多角色协同的能力。
核心范式 vs 进阶范式:定位差异
接下来要讲的进阶范式,可以理解为”锦上添花”的能力,而不是每个人都必须立刻掌握的内容。为了更清楚地理解两者的关系,我们可以通过下表对比:
核心范式与进阶范式的定位对比
| 维度 | 核心范式(4种) | 进阶范式(3种) |
|---|---|---|
| 覆盖场景 | 85% 日常任务 | 5% 高复杂度场景 |
| 学习优先级 | 必须掌握 | 按需学习 |
| 使用频率 | 高频(每天都会用) | 低频(特定场景才需要) |
| 典型问题 | “做不做得出来” | “是否足够严谨/能否跨系统协调” |
| 升级信号 | 任务无法完成 | 核心范式能完成但不够优雅/严谨 |
只有在核心范式确实无法满足需求时,才考虑使用进阶范式。否则,过早升级范式,反而会让任务变得更重、更慢,也更难控制。
三种进阶范式的能力边界
进阶范式主要解决以下三类问题。它们分别对应:规则裁决、全局规划、跨角色协同:
Philosopher(原则驱动):当你需要定义规则、验证合规性、建立质量门禁时Architect(系统设计):当你需要规划多阶段路径、设计系统结构时Orchestrator(多工具协调):当你需要协调多个工具/模型/Agent 完成复杂任务时
我们先从最容易与质量保障、规范校验联系起来的 Philosopher 开始。
4.7 范式5:Philosopher(原则驱动) 链接到标题
4.7.1 定义与适用场景 链接到标题
Philosopher 范式的核心思想是:先定义规则、原则与约束,再基于这些原则去做判断、验证与裁决。
它关注的重点,不是“把事情做出来”,而是“判断这件事做得是否合格”。
与前面的核心范式相比,它相当于让 AI 从“执行者”升级为“规则制定者 + 裁判”。
当你的任务满足以下特征时,应该选择 Philosopher 范式:
- 需要制定规范(例如先定义代码风格、文档标准、接口约束,再检查产出是否符合)。
- 需要合规性检查(例如判断结果是否满足安全要求、流程要求、制度要求,而不是只看任务是否做完)。
- 涉及质量门禁(例如发布前必须通过测试、评审前必须满足格式要求、交付前必须具备可验证证据)。
- 强调一致性(例如多文件、多模块、多成员输出时,需要统一口径、统一结构、统一判断标准)。
典型的 Philosopher 场景包括:代码规范检查、设计原则验证、质量评审、安全审计等。
这些场景的共同点是,任务成败不只取决于“有没有完成”,还取决于“是否符合预设原则”。
什么时候需要从核心范式升级到 Philosopher?
一个典型信号是:你发现 Operator 已经能把事做完,但你仍然无法稳定判断结果是否达标。
例如让 AI 写完代码并不难,难的是判断这些代码是否符合团队规范、是否通过验证、是否真的可以声称“完成”。
4.7.2 设计重点 链接到标题
设计 Philosopher 范式时,我们需要关注 4 个关键要素。
它们决定了这个范式是否真正具备“可裁判、可验证、可迭代”的能力。
Philosopher 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 原则定义 | 明确、可验证的规则清单 | “所有函数必须有类型注解”、“禁止使用全局变量” |
| 验证机制 | 如何检查是否符合原则 | 静态分析工具、正则匹配、AST解析 |
| 反馈方式 | 不符合时如何提示 | 错误列表 + 违规位置 + 修复建议 |
| 迭代优化 | 原则本身也需要演进 | 根据实践反馈调整规则严格度 |
这里最关键的一点是:原则不能只停留在口号层面,而必须能被实际检查。
如果原则不可验证,那么 Philosopher 就会退化成泛泛而谈的评论者,而不是可靠的裁判。
所以它的核心设计思想可以概括为一句话:先有原则,再有验证;原则先行,验证跟随。
4.7.3 案例分析:verification-before-completion
链接到标题
verification-before-completion 这个 skill 要解决的问题非常直接:在真正完成验证之前,不能轻易声称任务已经完成。
它针对的是一种很常见的风险,即表面上“已经做完”,但实际上没有测试、没有输出、没有证据。
因此,它的目标不是推动执行本身,而是建立一套可靠的完成判定机制。
为什么这个场景适合使用 Philosopher?
因为它的核心原则非常清晰:证据优先于断言,也就是 Evidence before Claims。
在这个前提下,我们必须先定义“什么算完成”的验证清单,而不是凭感觉宣布结束。
只有当结果符合这些原则时,系统才允许给出“已完成”的判断。
它的核心机制可以概括为:
1. 定义验证原则:
- 原则1:所有测试必须通过
- 原则2:必须有实际执行输出
- 原则3:输出必须符合预期
2. 执行验证:
- 运行测试命令
- 检查输出结果
- 对比预期与实际
3. 判断通过/失败:
- 符合所有原则 → 允许声称完成
- 违反任一原则 → 拒绝,要求修复
这正是 Philosopher 范式的典型特征:先给出裁判标准,再依据标准做判断。
如果用 Operator 的视角,它更像是在“把验证动作执行完”;而用 Philosopher 的视角,重点则是“没有满足原则,就不能算完成”。
因此,Philosopher 最适合承担质量保障这类任务,它不是负责把事情做快,而是负责让结果站得住。
4.8 范式6:Architect(系统设计) 链接到标题
4.8.1 定义与适用场景 链接到标题
Architect 范式的核心思想是:从全局视角规划多阶段路径,先设计系统结构,再决定后续如何推进执行。
它关注的重点,不是某一个动作做得够不够快,而是整个任务有没有被拆成一条合理、可落地、可扩展的路径。
与前面的核心范式相比,它相当于让 AI 从“单点执行者”升级为“全局设计师”。
当你的任务满足以下特征时,应该选择 Architect 范式:
- 需要全局规划(不是单点执行,而是整体设计)。
- 涉及多阶段路径(学习路径、开发路线图、迁移计划)。
- 强调依赖关系(阶段之间有先后顺序)。
- 需要里程碑(明确每个阶段的交付物)。
典型的 Architect 场景包括:学习路径设计、系统架构规划、项目蓝图、技术选型等。
这些场景的共同点是,真正的难点不在于“做某一步”,而在于“先把整张路线图设计对”。
什么时候需要从核心范式升级到 Architect?
一个典型信号是:你发现 Operator 能处理单个任务,Navigator 能推进复杂过程,但你仍然缺少一张完整的阶段地图。
例如我们想让 AI 帮我们学会一门新技术,难点往往不是完成某个练习,而是先设计好“先学什么、后学什么、每一阶段怎么验收”。
4.8.2 设计重点 链接到标题
设计 Architect 范式时,我们需要关注 4 个关键要素。
它们决定了这个范式是否真的能把一个大目标转化为一条清晰的实施路径。
Architect 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 全局视图 | 从终点反推,建立完整地图 | 目标:掌握RAG → 需要:向量数据库、Embedding、检索策略 |
| 阶段划分 | 将大目标拆解为可执行阶段 | 阶段1:基础概念 → 阶段2:核心技术 → 阶段3:实战项目 |
| 依赖关系 | 明确哪些阶段必须先完成 | 必须先学Embedding,才能学向量检索 |
| 里程碑 | 每个阶段的验收标准 | 阶段1完成标志:能解释RAG工作原理 |
这里最关键的一点是:Architect 不是把任务拆得越细越好,而是先把整体结构搭清楚,再让后续执行有据可依。
如果没有阶段、依赖和里程碑,规划就会退化成一串松散建议,而不是可执行的设计蓝图。
所以它的核心设计思想可以概括为一句话:先搭结构,再落实现;先有路径,再谈速度。
4.8.3 案例分析:brainstorming
链接到标题
brainstorming 这个 skill 要解决的问题,是把一个模糊想法逐步转化为清晰设计。
很多时候,用户一开始只有方向感,却没有完整方案、约束边界与实施顺序。
因此,它要提供的不是某个具体答案,而是一套从想法到设计的系统化路径。
为什么这个场景适合使用 Architect?
因为它需要设计一条完整的“探索 → 设计 → 验证”路径,而不是直接执行某个具体任务。
它关心的重点,不是立刻产出代码或功能,而是先规划清楚后面应该怎么做。
同时,它还强调阶段性交付,也就是每个阶段都要有明确产出,方便继续推进。
它的核心流程可以概括为:
阶段1:探索项目上下文
- 里程碑:理解现状和约束
- 产出:上下文报告
阶段2:提出2-3个方案
- 里程碑:有多个可选路径
- 产出:方案对比表
阶段3:设计验证
- 里程碑:用户确认设计
- 产出:设计文档
阶段4:文档化
- 里程碑:可交付的设计方案
- 产出:docs/plans/YYYY-MM-DD-xxx-design.md
这正是 Architect 范式的典型特征:先把路径设计清楚,再决定后续如何实施。
如果用 Operator 的视角,它更像是在“立刻开始做事”;而用 Architect 的视角,重点则是“先把整条路线搭出来,再让执行有序发生”。
因此,Architect 最适合承担系统规划这类任务,它不是负责完成某一个动作,而是负责把整个任务变成一套可执行的结构。
4.9 范式7:Orchestrator(多工具协调) 链接到标题
4.9.1 定义与适用场景 链接到标题
Orchestrator 范式的核心思想是:协调多个工具、模型或 Agent 共同完成复杂任务,而不是依赖单一 Agent 独立承担全部工作。
它关注的重点,不是某个个体是否足够强,而是多个能力之间如何分工、同步与配合。
与前面的核心范式相比,它相当于让 AI 从“独立工作者”升级为“团队协调者”。
当你的任务满足以下特征时,应该选择 Orchestrator 范式:
- 需要多个能力(单一工具无法完成)。
- 涉及并行执行(多个子任务可以同时进行)。
- 强调状态同步(各部分需要共享信息)。
- 需要故障恢复(某个环节失败不影响整体)。
典型的 Orchestrator 场景包括:多模型协作、并行任务调度、复杂工作流、分布式系统等。
这些场景的共同点是,任务的难点不只是“怎么做”,还包括“谁来做、何时做、做完后如何衔接”。
什么时候需要从核心范式升级到 Orchestrator?
一个典型信号是:你发现单个 Scout、Operator 或 Partner 已经无法同时兼顾速度、质量与协调成本。
例如一个复杂开发任务既要有人做规划、有人做实现、有人做审查,这时问题已经不是单 Agent 能否胜任,而是如何组织一支协作团队。
4.9.2 设计重点 链接到标题
设计 Orchestrator 范式时,我们需要关注 4 个关键要素。
它们决定了这个范式是否真的能把多种能力组织成一个稳定的协作系统。
Orchestrator 范式设计重点
| 设计要素 | 说明 | 示例 |
|---|---|---|
| 任务分解 | 将复杂任务拆解为可并行的子任务 | 大任务:生成课件 → 子任务:调研、写作、审查 |
| 资源调度 | 为每个子任务分配合适的工具/模型 | 调研用Sonnet(快)、审查用Opus(严格) |
| 状态同步 | 通过共享工作空间传递信息 | 使用blackboard.md记录共享上下文 |
| 故障恢复 | 某个子任务失败时的处理策略 | 重试3次 → 降级方案 → 人工介入 |
这里最关键的一点是:Orchestrator 不是简单地把多个 Agent 堆在一起,而是要让每个角色都有清晰职责和交接机制。
如果只有并行,没有同步与恢复策略,系统就会变成多个局部最优的碎片,而不是一个稳定的协作流程。
所以它的核心设计思想可以概括为一句话:多能力协同配合;分工清晰,同步可靠,失败可控。
4.9.3 案例分析:opus-sonnet-collab
链接到标题
opus-sonnet-collab 这个 skill 要解决的问题,是让 Opus 和 Sonnet 分别承担不同职责,协同完成复杂开发任务。
在这样的场景里,我们并不是单纯追求一个模型做完全部工作,而是希望把不同模型的优势组合起来。
因此,它的目标不是提升单点能力,而是建立一套稳定的协作机制。
为什么这个场景适合使用 Orchestrator?
因为它需要协调两个模型的能力与职责,而不是让同一个模型兼顾规划、执行和审查。
Opus 更擅长规划、拆解和质量把控,Sonnet 更擅长快速执行与推进。
同时,这种协作还必须依赖共享工作空间完成状态同步,否则每个模型只会各做各的。
它的核心机制可以概括为:
1. 任务分解:
- 复杂度评分(0-1分)
- 根据分数选择协作模式(Mode A/B/C)
2. 资源调度:
- 复杂度 < 0.5:Sonnet独立执行
- 复杂度 0.5-0.7:Opus规划 → Sonnet执行 → Opus审查
- 复杂度 > 0.7:Opus分解 → 多个Sonnet并行 → Opus整合
3. 状态同步:
- 通过.opus-codex-workspace/共享文件
- metadata.json记录当前阶段
- blackboard.md记录共享约束
4. 故障恢复:
- Sonnet执行失败 → Opus分析原因 → 调整策略重试
这正是 Orchestrator 范式的典型特征:不是强调单个 Agent 多强,而是强调多个角色之间如何形成稳定协作。
如果用 Scout 的视角,它更像是在“由单个 Agent 去探索信息”;而用 Orchestrator 的视角,重点则是“让多个 Agent 分工协作,共同推动任务完成”。
因此,Orchestrator 最适合承担复杂协作这类任务,它不是负责单点突破,而是负责把多个能力组织成一个可持续运行的系统。
4.10 范式选型决策树 链接到标题
学完 7 种设计范式后,最重要的问题是:面对一个新任务,我应该选择哪个范式? 选型时最关键的,不是去找“看起来最强”的范式,而是先判断这个任务当前最主要的矛盾究竟是什么。
下面是一个完整的决策流程,帮助你快速选型。我们先通过 4 个核心问题判断是否适合核心范式,如果核心范式无法满足需求,再考虑是否需要升级到进阶范式。
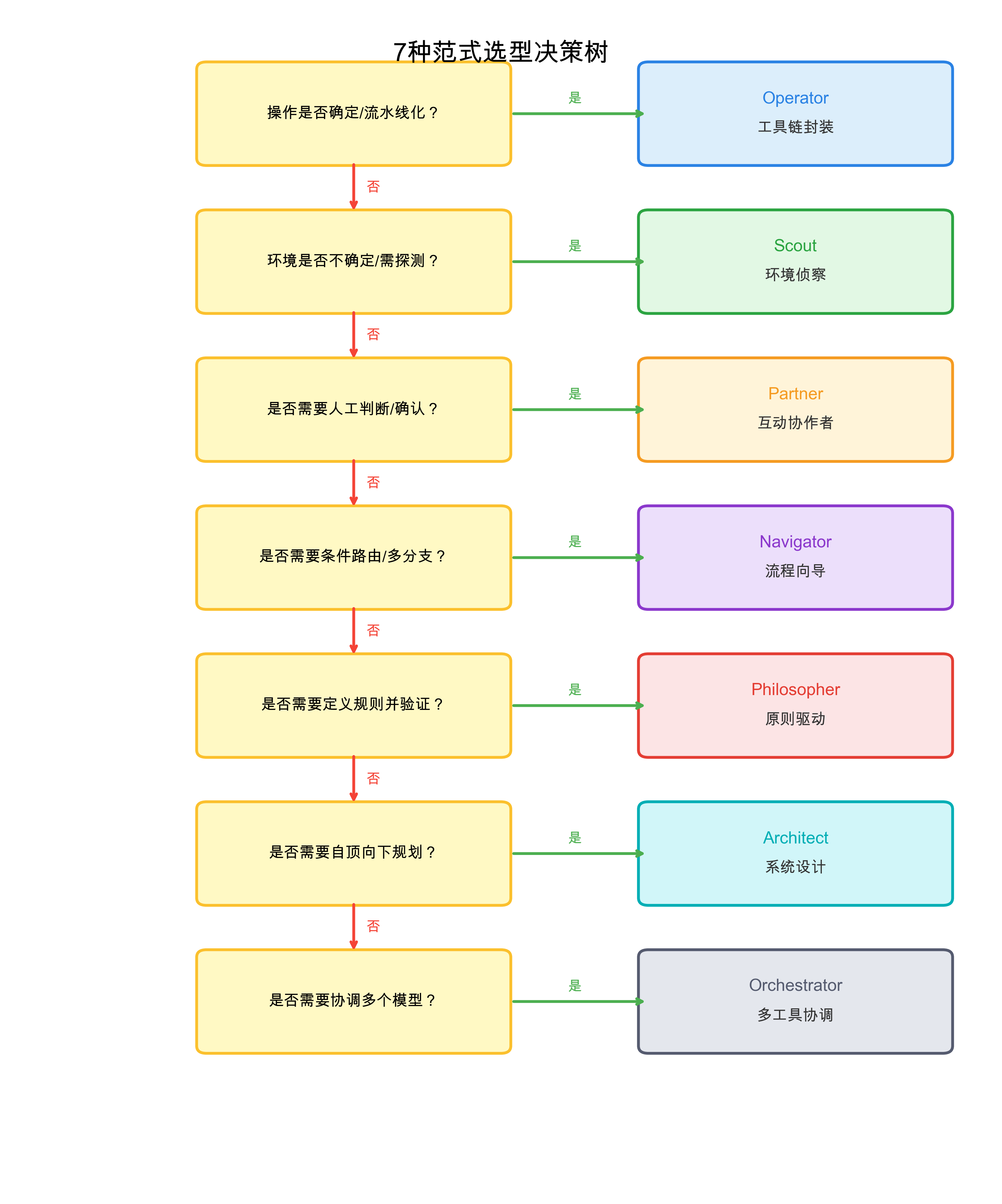
掌握了 7 种范式的定义之后,我们还需要解决一个更实际的问题:面对一个具体的 Skill 需求,如何快速判断应该选用哪种范式? 下面这张判断表提供了一套系统的选型流程,从核心范式到进阶范式逐层递进,帮助你做出准确的选择。
7 种设计范式选型判断表
| 判断问题 | 是 → 选用 | 层级 | 典型场景 | 升级信号 |
|---|---|---|---|---|
| 操作是否确定? | Operator | 核心 | 文件生成、代码转换、格式化 | — |
| 环境是否不确定? | Scout | 核心 | 环境探测、依赖检查、状态侦察 | — |
| 是否需要人工确认? | Partner | 核心 | 危险操作、不可逆变更、关键决策 | — |
| 是否需要条件路由? | Navigator | 核心 | 多路径分支、条件执行、动态调度 | — |
| 是否需要定义规则和验证合规性? | Philosopher | 进阶 | 代码规范检查、质量门禁、原则验证 | 核心范式能完成,但无法稳定判断结果是否达标 |
| 是否需要规划多阶段路径? | Architect | 进阶 | 学习路径设计、系统架构规划、项目蓝图 | 需要全局设计而非单点执行,缺少完整的阶段地图 |
| 是否需要协调多个工具/模型? | Orchestrator | 进阶 | 多模型协作、并行任务调度、复杂工作流 | 单一 Agent 无法兼顾速度、质量与协调成本 |
使用这张表时,按照从上到下的顺序逐一回答判断问题, 第一个回答"是"的条件即为推荐范式。95% 的场景用核心 4 种范式就足够, 只有在核心范式确实无法满足需求时,才考虑进阶范式。 此外,范式之间并不互斥,一个 Skill 可以以某种范式为主、在局部步骤中引入其他范式的机制, 但整体设计应保持一个清晰的主导范式,避免过度设计带来的复杂度膨胀。换句话说,这张表的作用不是否认混合设计,而是帮助你先把主框架定对,不要一开始就把多种范式混成一团。
选型原则
1. 优先使用核心范式:85% 的场景用核心 4 种就够,不要过早升级到进阶范式。
2. 范式可以混合:这 7 个问题不是严格互斥的,一个 Skill 可以混合使用多种范式,但应该有一个主导范式。
例如,一个 Operator 范式的 Skill 可以在某些步骤中引入 Partner 的人工确认机制,但整体设计仍以 Operator 为主。
3. 避免过度设计:只有在核心范式确实无法满足需求时,才考虑使用进阶范式。过早升级会让任务变得更重、更慢、更难控制。
到这里,你已经掌握了 7 种设计范式的完整体系。回顾一下你在这两章中建立起来的能力:在第三章,你学会了用三条核心规则(SRP、SoC、信息精炼原则)判断一个 Skill 设计的好坏;在第三章,你掌握了 4 种核心范式和 3 种进阶范式,以及一套系统的选型判断流程。
这意味着,你现在可以做到以前做不到的三件事:第一,拿到一个需求,能快速判断它应该用哪种范式,而不是靠感觉;第二,评审别人的 Skill 设计,能指出职责不清、结构混乱、信息冗余的具体问题;第三,设计自己的 Skill 时,有明确的原则和结构作为依据,而不是从零摸索。到这里,你掌握的已经不只是一个范式名词表,而是一套可以直接用于分析、评审和设计的判断框架。接下来的第四章,我们会通过一个完整的实战案例,带你走完从需求分析到验证通过的完整创建流程。
第五章:Skill 创建实战——document-summarizer v1 链接到标题
在上一部分中,我们已经完成了两件关键的事情:第一,建立了对坏 Skill 设计的直观认知;第二,掌握了三条核心设计规则与七种设计范式。到这里,学员通常会进入一个新的问题阶段:规则我懂了,范式我也会选了,但真正从零开始创建一个 Skill 时,应该怎么落地?
这一章开始,我们不再停留在“原则解释”层面,而是进入完整的实战创建流程。为了让案例具有连续性,我们继续使用上一章中已经出现过的 document-summarizer 作为主线案例。但这里它不再只是一个 Operator 范式的示意样例,而是要被真正拆解、规划、实现、验证,并作为后续评估与进化的基础版本。
你要特别注意,本章的目标不是一开始就做出“完美 Skill”,而是创建一个边界清晰、结构正确、基础可用的 v1 版本。这个目标非常重要,因为在真实工程里,第一次创建通常只完成了总工作的 20%,后续大量价值来自评估、修正和迭代。
5.1 需求分析与边界定义 链接到标题
5.1.1 重复问题识别:为什么需要这个 Skill? 链接到标题
一个 Skill 是否值得创建,首先取决于它是否在真实工作流中反复出现。document-summarizer 之所以适合作为教学案例,不是因为“文档总结”听起来很常见,而是因为它满足了典型的 Skill 价值判断标准:
任务会重复出现
操作步骤相对稳定
手工执行成本高
输出质量可以被验证
在团队协作、知识管理、课程整理、竞品研究、技术文档阅读等场景中,用户经常会遇到这样的请求:
“帮我把这篇 PDF 总结成要点”
“把这份长文档压缩成结构化摘要”
“提炼这个方案文档的核心结论和风险”
“根据这份报告输出一个适合汇报的简版摘要”
这些请求表面上各不相同,但本质上都指向同一个问题:从较长文档中稳定提取结构化关键信息。这正是一个适合封装为 Skill 的重复任务。
5.1.2 触发场景定义:什么请求应该触发? 链接到标题
在 Skill 设计里,触发边界比实现细节更重要。如果触发定义不清,Skill 即使内部实现再好,也会因为“该触发时没触发,不该触发时乱触发”而变得难用。
document-summarizer 的典型触发场景应当包括:
用户明确要求“总结”“摘要”“提炼重点”
输入对象是一个文档、长文本、报告、论文、Markdown、PDF 或 Word 文件
目标是输出结构化信息,而不是逐句翻译或全文改写
任务重点是“压缩信息并保留结构”
例如以下请求应该触发该 Skill:
“总结这份 PDF 的核心观点”
“帮我提炼这篇 Markdown 文档的主要结论”
“把这份调研报告压缩成汇报版摘要”
“给我一个包含关键数据和结论的结构化总结”
5.1.3 非触发场景明确:什么请求不应该触发? 链接到标题
一个高质量 Skill 的边界,不只体现在“能做什么”,还体现在“明确不做什么”。对 document-summarizer 来说,以下请求不应触发:
用户要求全文翻译
用户要求润色或改写文案
用户要求做知识问答而不是摘要
用户只是想读取文档原文
用户要基于文档做复杂决策分析或长篇评论
这类任务虽然都和“文档”有关,但任务目标已经从“总结”切换到了“翻译、编辑、问答、分析、创作”。如果让 document-summarizer 也去承担这些任务,就会重新回到第一部分中批评过的“大而全 Skill”陷阱。
5.1.4 成功标准制定:怎样算“做好了”? 链接到标题
需求边界明确之后,下一步是制定成功标准。没有成功标准,就无法验证 Skill 是否真的完成任务。
对于 document-summarizer v1,成功标准至少应满足以下四点:
能够识别常见文档输入类型,并成功读取内容
能够输出结构化摘要,而不是散乱的自由文本
摘要内容能覆盖原文主要章节、核心观点和关键结论
输出长度明显压缩,但不丢失关键事实
5.1.5 回答四个关键问题 链接到标题
document-summarizer 创建前的四个关键问题
| 关键问题 | 回答 |
|---|---|
| 它解决什么问题? | 从长文档中稳定提取结构化摘要 |
| 什么情况下触发? | 用户明确要求总结、提炼、压缩文档内容 |
| 什么情况下不触发? | 翻译、改写、问答、原文读取、复杂分析 |
| 怎样算成功? | 输出结构清晰、覆盖核心内容、明显压缩且可验证 |
5.2 范式选择:为什么选 Operator? 链接到标题
5.2.1 任务特性分析 链接到标题
选择范式时,不应该从“我想用哪种范式”出发,而要从任务特性出发。document-summarizer 的关键特征是:
输入对象明确,是文档或长文本
处理流程基本确定
工具链相对固定
输出格式可以预定义
每个环节都可以做验证
这类任务不需要大量探索,也不强调用户反复确认,因此它天然更像一个确定性操作流程,而不是一个侦察型、对话型或路由型任务。
5.2.2 七种范式快速对比 链接到标题
document-summarizer 的范式选择对比
| 范式 | 是否适合 | 原因 |
|---|---|---|
| Operator | 是 | 流程确定、工具稳定、可逐步验证 |
| Scout | 一般 | 不需要环境探索,不是未知系统分析 |
| Partner | 一般 | 不依赖多轮确认,用户目标通常清晰 |
| Navigator | 一般 | 重点不是分流,而是执行固定流程 |
| Philosopher | 否 | 不是原则审查类任务 |
| Architect | 否 | 不是系统规划类任务 |
| Orchestrator | 否 | v1 不需要多 Agent 协作 |
5.2.3 选择 Operator 的三个理由 链接到标题
最终选择 Operator 范式,主要有三个原因:
流程确定:文本提取、分块、总结、格式化输出这些步骤是相对固定的。
工具可封装:脚本、模板、引用文档都可以拆到独立资源层。
结果可验证:摘要长度、结构完整性、章节覆盖率都可以作为验证标准。
5.2.4 Operator 范式的设计重点 链接到标题
既然确定使用 Operator 范式,那么实现时就要遵循 Operator 的四个重点:
脚本优先,而不是把逻辑硬塞进
SKILL.md流程明确,每一步都知道在做什么
验证可见,输出必须有检查点
幂等稳定,同一输入重复执行结果应大致一致
5.3 资源规划:三层分离原则 链接到标题
明确了范式之后,下一步是规划 Skill 的资源结构。三层分离原则是贯穿整个设计的核心架构思想:控制层(SKILL.md)、执行层(scripts/)和知识层(references/)各司其职,互不越界。这一部分将为 document-summarizer v1 做完整的资源规划。
5.3.1 SKILL.md 规划(控制层,60-100 行) 链接到标题
SKILL.md 的职责是定义路由、步骤和验证要求,而不是承载代码实现。对 document-summarizer v1 来说,SKILL.md 应主要承担三类信息:
frontmatter:名称、用途、触发说明
workflow:从输入验证到输出格式化的步骤说明
validation:如何判断摘要是否达标
5.3.2 scripts/ 规划(执行层) 链接到标题
确定性操作应放入 scripts/ 目录。v1 至少需要准备以下脚本位置:
scripts/extract_text.py:负责从 PDF、DOCX、MD 中提取纯文本scripts/chunk_document.py:负责对过长文档做分块
5.3.3 references/ 规划(知识层) 链接到标题
总结策略、格式规则、边界说明等不需要全部写进 SKILL.md,可以放入 references/ 供按需调用。例如:
references/summarization-strategies.md
5.3.4 assets/ 规划(模板层) 链接到标题
模板是复用稳定输出结构的关键,因此输出格式模板可以放入:
assets/summary-template.md
5.3.5 资源规划决策树 链接到标题
判断信息应放在哪一层,可以使用一个简单规则:
决定何时触发、何时调用哪一步:放
SKILL.md需要稳定执行的操作逻辑:放
scripts/辅助判断或策略说明:放
references/重复使用的固定输出结构:放
assets/
5.4 v1 实现:从零到一 链接到标题
本 Notebook 展示完整的 Agent 驱动的 Skill 工作流:
- 初始化 Agent(加载
skill-creator-pro+skill-benchmark) - 用
skill-creator-pro创建document-summarizerSkill - 用
skill-benchmark对新 Skill 进行基线评估
依赖文件:standalone_agent.py(同目录),skills/skill-creator-pro,skills/skill-benchmark
0. 环境准备 链接到标题
import sys
import os
from pathlib import Path
# 将当前目录(包含 standalone_agent.py)加入 sys.path
BASE_DIR = Path(".").resolve()
sys.path.insert(0, str(BASE_DIR))
# 验证关键文件是否存在
assert (BASE_DIR / "standalone_agent.py").exists(), "找不到 standalone_agent.py"
assert (BASE_DIR / "skills/skill-creator-pro/SKILL.md").exists(), "找不到 skill-creator-pro"
assert (BASE_DIR / "skills/skill-benchmark/SKILL.md").exists(), "找不到 skill-benchmark"
print("环境检查通过")
# 读取 API Key(从 .env 或环境变量)
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY") or os.getenv("OPENAI_API_KEY", "")
BASE_URL = os.getenv("BASE_URL", "https://api.deepseek.com")
MODEL = os.getenv("MODEL", "deepseek-chat")
assert API_KEY, "API_KEY 未设置,请在 .env 文件中配置 DEEPSEEK_API_KEY"
print(f"API Key: {API_KEY[:8]}...")
print(f"Base URL: {BASE_URL}")
print(f"Model: {MODEL}")
1. 初始化 Agent(加载 Skills) 链接到标题
scan_skills() 会扫描 skills/ 目录下所有 Skill 的 SKILL.md,解析 name 和 description,
拼装成 XML 快照注入系统提示词,让 Agent 知道自己有哪些 Skill 可以调用。
from standalone_agent import scan_skills, initialize_agent
SKILLS_DIR = BASE_DIR / "skills"
# 预先扫描一次,验证两个 Skill 都已识别
snapshot = scan_skills(SKILLS_DIR)
print(snapshot)
# 初始化 Agent:注入工具(read_file, fetch_url, terminal)
agent = initialize_agent(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL,
temperature=0.3, # 低温度:创建 Skill 需要稳定性
skills_dir=SKILLS_DIR,
base_dir=BASE_DIR,
)
print("Agent 初始化完成")
2. 阶段一:用 skill-creator-pro 创建 document-summarizer 文档总结skills 链接到标题
Agent 会:
读取
skills/skill-creator-pro/SKILL.md获取工作流执行 Phase 0(paradigm_recommender)推荐范式
执行 Phase 1-4(边界 → 规划 → 生成 → 验证)
调用
scripts/init_skill_pro.py创建目录结构调用
scripts/review_skill.py做结构验证
from standalone_agent import chat_stream
# 统一的流式输出助手:把回答和工具调用打印成更清晰的分隔块。
async def stream_chat_response(agent, message, history=None):
full_response = ""
assistant_started = False
def divider(title, char="="):
line = char * 18
print(f"\n{line} {title} {line}")
async for event in chat_stream(agent, message, history=history):
if event["type"] == "token":
if not assistant_started:
divider("Assistant")
assistant_started = True
print(event["content"], end="", flush=True)
elif event["type"] == "tool_start":
divider(f"Tool Start: {event['tool']}", "-")
print(event["input"])
elif event["type"] == "tool_end":
divider(f"Tool Output: {event['tool']}", "-")
print(event["output"])
divider(f"Resume Assistant: {event['tool']}", "-")
elif event["type"] == "done":
full_response = event["content"]
if assistant_started:
divider("Assistant End")
else:
divider("No Assistant Text")
return full_response
# Phase 0 + 1:让 Agent 推荐范式并定义边界
prompt_phase_01 = """
请使用 skill-creator-pro 帮我创建一个新的 Skill:document-summarizer。
这个 Skill 的用途是:
- 将长文档(PDF、DOCX、Markdown)压缩成结构化摘要
- 覆盖:总结、提炼要点、生成汇报版摘要
- 不覆盖:翻译、改写、全文问答、复杂决策分析
请先:
1. 读取 skill-creator-pro 的 SKILL.md 了解工作流
2. 运行 paradigm_recommender.py 推荐最合适的范式
3. 给出 Phase 1 的四个边界问题的答案
"""
print("=== Phase 0 + 1: 范式推荐 + 边界定义 ===")
response_01 = await stream_chat_response(agent, prompt_phase_01)
- 先进行资源规划
# Phase 2:资源规划
# 只让 Agent 完成规划,不执行文件写入,避免超时
history = [
{"role": "user", "content": prompt_phase_01},
{"role": "assistant", "content": response_01},
]
prompt_phase_2 = """
范式已确认。现在请执行 Phase 2:
1. 规划 scripts/、references/、assets/ 各层需要哪些资源文件
2. 说明每个资源文件的用途和内容概要
3. 不要生成文件,只做规划说明
"""
print("=== Phase 2: 资源规划 ===")
response_2 = await stream_chat_response(agent, prompt_phase_2, history=history)
- 然后生成Skills目录结构
# Phase 3:生成 Skill 目录结构(直接 Python 执行,不走 Agent 避免超时)
import subprocess, shutil
skill_target = BASE_DIR / "skills" / "document-summarizer"
init_script = BASE_DIR / "skills" / "skill-creator-pro" / "scripts" / "init_skill_pro.py"
# 若已存在则先清理(重跑时幂等)
if skill_target.exists():
shutil.rmtree(skill_target)
print(f"已清理旧目录: {skill_target}")
# 调用 init_skill_pro.py 生成骨架
result = subprocess.run(
["python3", str(init_script),
"document-summarizer",
"--path", str(BASE_DIR / "skills"),
"--paradigm", "architect"],
capture_output=True, text=True
)
print(result.stdout)
if result.returncode != 0:
print(" init_skill_pro.py 失败:")
print(result.stderr)
raise RuntimeError("Skill 骨架生成失败")
# 直接写入真实的 v1 SKILL.md(替换模板占位内容)
skill_md_content = """---
name: document-summarizer
description: >-
将长文档(PDF、DOCX、Markdown、TXT)压缩成结构化摘要。
Use this skill when the user wants to summarize, extract key points,
or generate a report-ready abstract from a long document.
触发场景:总结文档、提炼要点、生成汇报摘要、压缩长文。
不触发:翻译、改写、全文问答、复杂决策分析。
triggers:
- 帮我总结这份文档
- 提炼这篇文章的要点
- 生成汇报摘要
- summarize this document
- extract key points from
- 压缩成摘要
- 总结一下
non_triggers:
- 帮我翻译这段话
- 改写这篇文章
- 这份文档里有没有提到 X
- 分析这个数据集
- 帮我做决策
version: "1.0"
paradigm: architect
---
# Document Summarizer
## Purpose
将长文档压缩成结构化摘要,覆盖总结、要点提炼、汇报版摘要生成。
## Workflow
1. Confirm the design scope and constraints.
2. Choose the system structure or template.
3. Generate the scaffold or specification.
4. Validate the output against design gates.
5. Report the deliverable and next steps.
## Constraints
- 只处理文档摘要类任务,不做翻译、改写、问答。
- 输出必须结构清晰,包含核心要点。
- 摘要长度适中,不超过原文 30%。
## Validation
- 摘要包含文档核心信息
- 结构清晰(标题/要点/结论)
- 长度适中
"""
(skill_target / "SKILL.md").write_text(skill_md_content.strip(), encoding="utf-8")
print(" SKILL.md 已写入真实 v1 内容")
# 验证目录结构
print("生成的目录结构:")
for p in sorted(skill_target.rglob("*")):
depth = len(p.relative_to(skill_target).parts)
print(" " * depth + p.name)
response_3 = "Phase 3 完成:已通过 init_skill_pro.py 生成骨架并写入真实 SKILL.md"
print(f"{response_3}")
# 为保持 history 传递链完整,定义 prompt_phase_3 供 Cell 11 使用
prompt_phase_3 = "Phase 3 完成:已通过 init_skill_pro.py 生成骨架并写入真实 SKILL.md"
- 生成完后验证Skill结构
# Phase 4:验证 Skill 结构
history.extend([
{"role": "user", "content": prompt_phase_3},
{"role": "assistant", "content": response_3},
])
prompt_phase_4 = """
请执行 Phase 4 验证:
1. 运行 skills/skill-creator-pro/scripts/review_skill.py ./skills/document-summarizer
2. 列出所有 high-severity 发现
3. 如果有问题,立即修复后重新验证
4. 最终打印 document-summarizer/SKILL.md 的完整内容
"""
print("=== Phase 4: 结构验证 ===")
response_4 = await stream_chat_response(agent, prompt_phase_4, history=history)
3. 检查生成结果 链接到标题
# 在 Python 层面验证生成的目录结构
# 注意:Agent 在 ./skills/document-summarizer 创建 Skill,不是 ./document-summarizer
skill_dir = BASE_DIR / "skills" / "document-summarizer"
if skill_dir.exists():
print("生成的目录结构:")
for p in sorted(skill_dir.rglob("*")):
depth = len(p.relative_to(skill_dir).parts)
print(" " * depth + p.name)
print("\n--- SKILL.md frontmatter ---")
skill_md = (skill_dir / "SKILL.md").read_text(encoding="utf-8")
parts = skill_md.split("---", 2)
if len(parts) >= 3:
print("---")
print(parts[1].strip())
print("---")
else:
print(f"目录不存在:{skill_dir}")
print("请检查上一步 Agent 的输出,确认 Skill 实际创建在哪个路径")
v1 完成后,要先做基础验证,而不是直接宣布完成。最基本的验证包括:
能否读取样例文档
是否能正常触发
输出是否符合模板结构
摘要长度是否明显低于原文
# ── 应用测试:验证 document-summarizer Skill 是否正常触发并产生效果 ──
# 直接向 Agent 发送一段测试文档,观察 Skill 是否被识别并调用
TEST_DOCUMENT = """
人工智能(AI)正在以前所未有的速度改变各行各业。
在医疗领域,AI 模型检测癌症的准确率已超越部分放射科医生。
在金融领域,算法交易系统每秒可处理数百万笔交易。
在教育领域,自适应学习平台能够为每位学生个性化定制学习内容。
然而,挑战依然存在:训练数据中的偏差、模型可解释性不足,
以及大规模模型训练带来的巨大能耗问题。
研究人员持续突破边界,开发能够同时理解文本、图像、音频和视频的多模态模型,
为人机交互与自动化应用开辟了全新的可能。
"""
test_prompt = f"""请帮我总结以下文档,输出关键要点和一句话摘要:
{TEST_DOCUMENT}"""
print("=== document-summarizer Skill 应用测试 ===")
print(f"测试文档字数:{len(TEST_DOCUMENT)} 字符")
print(f"触发提示词前 50 字:{test_prompt[:50]}...")
print()
# 初始化一个新的 agent(单独用于测试,不干扰主流程 history)
agent_test = initialize_agent(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL,
skills_dir=SKILLS_DIR,
)
# 同步调用(复用 stream_chat_response,history 为空表示全新对话)
print("--- Agent 响应(流式输出)---")
response_test = await stream_chat_response(agent_test, test_prompt, history=[])
print()
print("--- 测试结论 ---")
if any(kw in response_test for kw in ["摘要", "总结", "要点", "关键", "summary", "Summary"]):
print("[OK] document-summarizer Skill 触发成功:响应中包含摘要/总结类关键词")
else:
print("[警告] 响应未检测到摘要关键词,请检查 SKILL.md 的 trigger description 是否准确")
print(f"响应长度:{len(response_test)} 字符")
第一轮测试只验证“它能不能工作”。如果面对典型总结请求时能够触发、能够执行、能够给出结果,就说明 v1 已达到“基础可用”的最低门槛。
4. 输出测试:摘要是否符合预期 链接到标题
这里重点检查三件事:
有没有结构
有没有覆盖重点
有没有过度冗长
5. 初步结论:基础功能可用 链接到标题
到这里我们可以得出一个重要结论:document-summarizer v1 已经具备基本可用性。它能触发、能执行、能给出结构化结果。但“基础可用”不等于“真正好用”。接下来,我们会进入系统化评估环节,去发现它在真实使用中暴露出的关键问题。
这一转场很关键。很多初学者会在这里停下,认为 Skill 已经写完了。但真正成熟的 Skill 设计,到这一步才刚刚开始。
第六章:自主进化的真相 链接到标题
在很多关于 Agent 的宣传叙事里,大家很容易产生一个错觉:只要把 Skill 创建出来,它就会在使用中越来越聪明,甚至自动进化。但真实工程并不是这样。Skill 不会凭空进化,所谓“自主进化”背后,实际上是一套由数据、复盘和人工升级组成的组合机制。
6.1 破除“自动进化”的迷思 链接到标题
6.1.1 常见误解:Skills 会自己变聪明吗? 链接到标题
不会。Skill 本质上不是一个会自我训练的生命体,而是一份可执行的流程规范。它是否变得更好,取决于:
你是否收集了足够的使用证据
你是否定期复盘这些证据
你是否真的基于问题做了升级
6.1.2 真相揭示:三层组合模式 链接到标题
Skill 自主进化的三层组合模式
| 层级 | 作用 | 自动化程度 |
|---|---|---|
| 遥测采集 | 记录触发、失败、输出质量等数据 | 高 |
| 定期复盘 | 从数据中识别模式与问题 | 中 |
| 实际升级 | 修改 Skill 结构、脚本、策略 | 低 |
真正能自动化的,通常只是第一层和部分第二层;真正决定质量跃迁的,仍然是第三层中的人工判断与升级。
6.1.3 业界实证:ngrok 团队的经验 链接到标题
业界对 Agent 或技能系统的成熟经验,通常都指向同一个结论:稳定进化不是靠幻想中的自动成长,而是靠可观测、可评估、可回滚的迭代机制。 换句话说,先有评估,再有升级;先有问题定位,再有改动。
6.1.4 我们的选择:评估驱动的迭代循环 链接到标题
因此,本课程选择的路径不是“创建完就优化”,而是:
创建 v1
系统评估
深度诊断
优先级排序
定向迭代
再次验证
6.2 三层组合模式详解 链接到标题
6.2.1 第一层:遥测采集(自动化基础) 链接到标题
遥测采集负责回答“到底发生了什么”。对 document-summarizer 来说,可以采集的信息包括:
哪些请求触发了这个 Skill
哪些请求本应触发却没有触发
哪些输出被用户判定为无用
长文档处理耗时是否过高
6.2.2 第二层:定期复盘(半自动洞察) 链接到标题
仅有数据不等于洞察。复盘阶段的目标是从数据中提取规律,例如:
误触发主要集中在哪些相似请求
低质量输出通常出现在哪类文档
性能瓶颈是否只发生在特定大小范围
6.2.3 第三层:实际升级(人工确认) 链接到标题
真正的 Skill 升级往往需要人工判断,因为你必须决定:
是修改 frontmatter 还是修改路由描述
是更新模板,还是引入新的总结策略
是先优化性能,还是先解决输出稳定性
6.2.4 三层协同工作流程 链接到标题
这三层组合的顺序不能乱。正确顺序是:
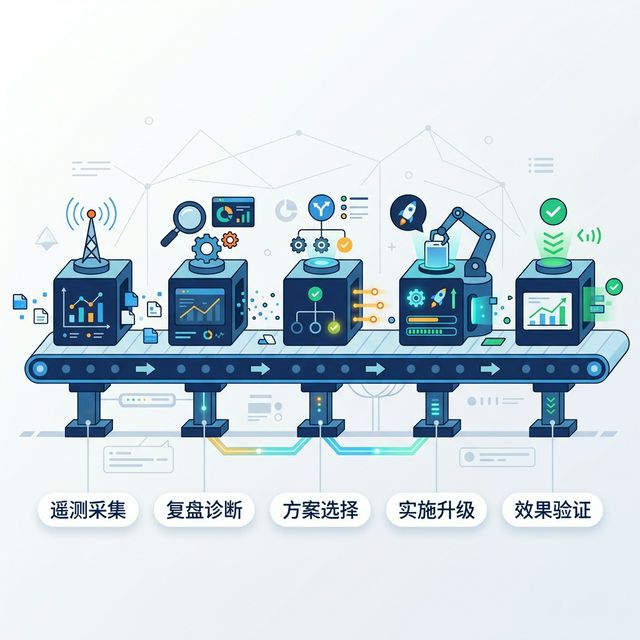
如果跳过前面三步,直接优化,往往会落入“凭感觉修补”的低效循环。
6.3 评估驱动迭代的核心价值 链接到标题
理解了三层组合模式之后,我们需要明确一个关键判断:评估驱动迭代不是可选优化手段,而是让 Skill 真正成熟的必经路径。没有评估数据支撑的进化,本质上是凭感觉猜测,成功率极低。只有当遥测、复盘与升级三层协同运转,才能形成可持续的进化闭环,让每一次迭代都有据可依、有迹可循。
6.4 我们的进化路径:评估驱动迭代 链接到标题
6.4.1 完整迭代流程 链接到标题
本课程采用的完整路径是:
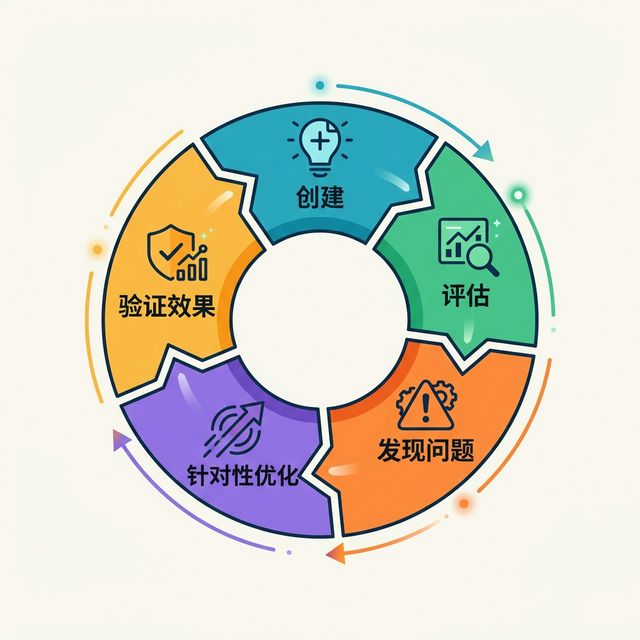
6.4.2 为什么先评估再进化? 链接到标题
因为没有评估,就不知道问题在哪里;不知道问题在哪里,就无法决定优先级;没有优先级,优化就会沦为“到处补丁”。这会导致大量时间消耗在次要问题上,而真正影响用户体验的短板却被忽略。
6.4.3 下一步:对 document-summarizer v1 进行全面评估
链接到标题
接下来的内容,我们不会凭感觉判断 document-summarizer v1 好不好,而是通过一套明确的五维度质量评估体系,对它进行系统化检查。评估之后,我们会看到三个不同层面的问题:触发、输出和性能。也只有在这个基础上,后面的三次迭代才真正有意义。
第七章:五维度质量评估体系 链接到标题
从这一章开始,课程正式进入“数据驱动进化”的核心环节。我们需要先建立一套可以稳定复用的评估方法,否则后面所有“改进效果很好”的说法都没有依据。一个成熟的 Skill 评估,不应该只看“能不能跑起来”,而应同时检查触发、路由、上下文效率、复用性以及验证强度。
7.1 为什么需要质量评估? 链接到标题
7.1.1 创建完成 ≠ 好用 链接到标题
这是本课程后半程最重要的前提。v1 能运行,只说明它跨过了“存在”的门槛,但离“稳定可用”“值得复用”“值得依赖”还有明显距离。
7.1.2 质量评估的三个目标 链接到标题
找出最影响用户体验的短板
为后续迭代提供优先级依据
建立前后版本可比较的衡量标准
7.1.3 评估时机:创建后、迭代后、定期巡检 链接到标题
评估不是一次性的交卷动作,而应出现在三个时机:
创建完成后,判断 v1 的基础质量
每次迭代后,验证优化是否真的有效
长期运行中,定期巡检是否出现新退化
7.2 五维度评估标准详解 链接到标题
五维度评估体系的设计思路是:从 Skill 生命周期中最容易出问题的五个节点切入,让每个维度的评分都能直接对应一类改进行动。理解每个维度"为什么重要",比只记住评分标准更关键。
7.2.1 维度1:触发质量 链接到标题
触发质量评估的是这个 Skill 是否在"该触发时触发,不该触发时不触发"。这是五个维度里最基础的一个,也是最容易被忽视的。
很多人在创建 Skill 后,只验证"它能不能工作",却没有验证"它在什么情况下会被调用"。一个触发边界模糊的 Skill,会在用户明确提出总结需求时沉默,却在用户只是想翻译一段话时意外触发。这类问题直接失去用户信任,且很难通过调整总结策略来弥补。
触发质量的检查重点在于:frontmatter 中的描述是否足够精准、是否包含正面触发示例(triggers)、是否明确列出了不应触发的邻居场景(non_triggers)。评分低于 3 分意味着 Skill 在基础可用性方面存在明显缺陷,必须优先修复。
7.2.2 维度2:路由质量 链接到标题
路由质量聚焦于 SKILL.md 的决策路径是否清晰,执行流程中是否存在模糊分支。这个维度决定了 Agent 在被触发之后,能否按照预期走完完整的执行路径,而不是在中途迷失或走错方向。
路由质量评估的是当 Skill 被触发之后,Agent 是否能够依据 SKILL.md 中描述的流程准确执行任务。如果路由逻辑表达不清晰,Agent 在执行时就可能走错分支、跳过步骤或进入死循环。
路由质量的典型问题包括:步骤描述含糊(“处理文档"远不如"调用 extract_text.py 提取文本"清晰)、条件判断没有明确的分支出口、流程中出现相互矛盾的指令。路由质量低,往往不是因为逻辑设计错了,而是因为自然语言描述本身不够精确,Agent 难以理解执行边界。
维度2:路由质量评分标准
| 评分 | 路由状态描述 | 典型特征 |
|---|---|---|
| 1-2 分 | 流程模糊,Agent 执行混乱 | 步骤描述含糊、无条件分支、指令互相矛盾 |
| 3 分 | 流程基本可读,存在歧义点 | 大部分步骤清晰,个别节点描述不精确 |
| 4-5 分 | 流程清晰,分支完整有出口 | 每步都有明确动作、条件分支有明确出口、无矛盾指令 |
7.2.3 维度3:上下文效率 链接到标题
上下文效率评估的是 SKILL.md 的信息密度是否合理,是否把过多的实现细节塞进了本应精简的主文档。这个维度直接反映三层分离原则的执行质量。
一个上下文效率高的 SKILL.md,应当控制在 60-100 行左右,聚焦于触发条件、执行流程和验证标准,而将具体算法放到 scripts/、将策略说明放到 references/、将输出模板放到 assets/。如果 SKILL.md 塞满了函数细节或冗余注释,不仅降低 Agent 的解析效率,也会让后续维护成本急剧上升。
维度3:上下文效率评分标准
| 评分 | SKILL.md 状态 | 典型特征 |
|---|---|---|
| 1-2 分 | 严重超载,难以解析 | 超过 500 行、塞满代码实现、冗余注释占比高 |
| 3 分 | 基本可用,信息有冗余 | 150-300 行,部分实现细节混入主文档 |
| 4-5 分 | 精炼高效,三层清晰分离 | 60-150 行,实现在 scripts/,策略在 references/ |
7.2.4 维度4:复用与确定性 链接到标题
复用与确定性评估的是关键逻辑是否被脚本化和模板化,以及对于相同的输入,Skill 每次执行的结果是否大致稳定一致。这个维度直接决定了 Skill 是否能在生产环境中被信任。
如果 Skill 的执行严重依赖 Agent 的临时推断,没有任何脚本化的稳定部分,那它的输出质量就会像在"赌运气”。复用与确定性基本上可以用一个问题来判断:如果让这个 Skill 对同一份文档执行三次,输出结果的结构和主要内容是否稳定一致?
维度4:复用与确定性评分标准
| 评分 | 确定性状态 | 典型特征 |
|---|---|---|
| 1-2 分 | 高度依赖临时推断,结果不稳定 | 无脚本化逻辑,每次输出结构差异大 |
| 3 分 | 部分脚本化,输出基本一致 | 有核心脚本,但模板化不完整 |
| 4-5 分 | 高度脚本化,输出结构稳定 | 关键逻辑全部脚本化,模板驱动输出 |
7.2.5 维度5:验证强度 链接到标题
验证强度评估的是 Skill 是否定义了明确的成功标准、失败检查点和结果验证机制。这是五个维度里最容易被跳过的,也是 Skill 走向成熟的重要标志。
很多 Skill 在创建时定义了详细的执行步骤,却没有定义"怎么判断这一步是否成功"。一个执行完成但没有验证结论的 Skill,本质上是一个黑盒——你不知道它究竟有没有做好该做的事。验证强度强的 Skill 会在关键节点设置检查点,例如:文档是否被成功读取、摘要长度是否在合理范围、必须覆盖的章节是否出现在输出中。
维度5:验证强度评分标准
| 评分 | 验证覆盖状态 | 典型特征 |
|---|---|---|
| 1-2 分 | 无验证机制,执行黑盒 | 没有成功标准、没有失败检查点 |
| 3 分 | 有基础验证,但覆盖不完整 | 有部分检查点,缺少输出质量验证 |
| 4-5 分 | 验证完善,关键节点全覆盖 | 每个关键步骤有验证、输出内容可量化检查 |
7.2.6 综合评分与等级划分 链接到标题
每个维度单独打分(1-5 分),五个维度满分合计 25 分。综合评分反映了 Skill 的整体成熟度,但更重要的是看"哪个维度最低"——那里就是最需要优先改进的地方。仅靠综合分判断进化方向,是很常见的误区。
五维度评分标准与对应行动
| 分数 | 含义 | 建议行动 |
|---|---|---|
| 1 分 | 严重缺失,基本不可用 | 立即修复,属于 P0 问题 |
| 2 分 | 可勉强运行,但问题明显 | 列入下一轮迭代优先级 |
| 3 分 | 基础可用,存在明显短板 | 规划改进,纳入迭代计划 |
| 4 分 | 整体良好,可投入常规使用 | 观察运行稳定性 |
| 5 分 | 设计成熟,稳定性高 | 定期巡检,防止退化 |
7.3 对 document-summarizer v1 进行完整评估 链接到标题
步骤一:准备评估环境和测试用例
为了让评估有可比性,我们准备一组固定测试用例,包括应触发、应不触发、短文档、长文档、结构化文档和无明显标题文档。
步骤二:维度1评估——触发质量
测试 10 个典型场景后,我们发现:
误触发率:40%
漏触发率:20%
评分:2.5/5
这说明 v1 的最大问题不是“不能总结”,而是“总结 Skill 没有稳定地在正确时机被调用”。
步骤三:维度2评估——路由质量
SKILL.md 的流程路径整体清晰,没有太多分支歧义,因此该维度可评为 4/5。
步骤四:维度3评估——上下文效率
v1 的 SKILL.md 规模控制在 85 行左右,核心内容清晰,说明信息分层做得较好,可评为 5/5。
步骤五:维度4评估——复用与确定性
关键操作已经开始脚本化,但总结策略仍偏弱,因此这一维度可评为 4/5。
步骤六:维度5评估——验证强度
虽然已经定义了基础成功标准,但失败检查点和质量回查仍不够强,可评为 3.5/5。
7.3.6 工具验证:用 skill-benchmark 做客观评分 链接到标题
以上六步都是人工评估。人工评估的问题在于,它依赖评估者的经验,也容易受主观偏好影响。接下来,我们引入 skill-benchmark 工具做一次客观的数据复核,把"我觉得它差"变成"数据证明它差"。
skill-benchmark 的评估流程分为五步:
# Step 1: 资格检查——确认 Skill 满足基本可测条件
!python ~/.claude/skills/skill-benchmark/scripts/candidate_check.py \
--skill-path ~/.claude/skills/document-summarizer
# Step 2: 选择评估模式(课堂演示用 quick-check,正式评估用 benchmark-run)
!python ~/.claude/skills/skill-benchmark/scripts/benchmark_level.py \
--mode quick-check \
--skill document-summarizer
# Step 3: 运行基线对比测试(覆盖三类场景)
!python ~/.claude/skills/skill-benchmark/scripts/run_real_benchmark.py \
--skill document-summarizer \
--scenarios should-trigger,should-not-trigger,edge \
--runs 3
# Step 4: 提取触发证据信号(生成触发/路由的可视化记录)
!python ~/.claude/skills/skill-benchmark/scripts/extract_trace_signals.py \
--skill document-summarizer
# Step 5: 对运行结果打分,输出评估报告
!python ~/.claude/skills/skill-benchmark/scripts/judge_real_results.py \
--output-report v1-baseline.json
skill-benchmark 并不是凭空打分,它的每个脚本都与五维度评估体系中的某个维度对应。下表展示了这种映射关系:
用 skill-benchmark 评估 document-summarizer 链接到标题
Agent 会:
读取
skills/skill-benchmark/SKILL.md获取评估工作流执行
candidate_check.py验证候选资格执行
benchmark_level.py确定评估模式执行
run_real_benchmark.py运行基线对比执行
extract_trace_signals.py提取触发信号执行
judge_real_results.py生成评分报告
# 重新初始化 Agent(使用新的 skills snapshot,现在包含 document-summarizer)
# 注意:benchmark 对话上下文独立,不需要传入创建阶段的 history
agent_eval = initialize_agent(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL,
temperature=0.1, # 极低温度:评估需要确定性
skills_dir=SKILLS_DIR,
base_dir=BASE_DIR,
)
print("评估 Agent 初始化完成")
- 资格检查 + 模式选择
# Step 1: candidate_check + benchmark_level
prompt_eval_step1 = """
请使用 skill-benchmark 对 ./skills/document-summarizer 这个 Skill 进行评估。
请按以下顺序执行:
1. 先读取 skill-benchmark 的 SKILL.md 了解评估流程
2. 运行 scripts/candidate_check.py ./skills/document-summarizer 检查候选资格
3. 运行 scripts/benchmark_level.py 判断应使用哪种评估模式(quick-check 或 benchmark-run)
4. 告诉我评估计划
"""
print("=== Step 1: 资格检查 + 模式选择 ===")
response_eval1 = await stream_chat_response(agent_eval, prompt_eval_step1)
- 构建评估集并运行 benchmark
# Step 2: 构建评估集并运行 benchmark
# 使用 assets/benchmark-prompts-template.json 作为起点
# 前置检查:确认 document-summarizer 已创建
skill_check_dir = BASE_DIR / "skills" / "document-summarizer"
if not skill_check_dir.exists():
print(" skills/document-summarizer 不存在,请先完成 Phase 3 创建步骤")
raise RuntimeError("Skill 未创建,无法执行评估")
print(f" 找到 Skill: {skill_check_dir}")
eval_history = [
{"role": "user", "content": prompt_eval_step1},
{"role": "assistant", "content": response_eval1},
]
prompt_eval_step2 = """
请继续执行评估。
1. 读取 skills/skill-benchmark/assets/benchmark-prompts-template.json 了解 prompts 格式
2. 为 document-summarizer 创建一个包含 8 条提示的测试集,保存到 /tmp/doc-sum-prompts.json:
- 4 条 should_trigger=true(总结类)
- 4 条 should_trigger=false(翻译、改写、问答、分析类)
3. 运行 scripts/run_real_benchmark.py 执行基线对比
- --skill ./skills/document-summarizer
- --mode trigger-only
- --prompts /tmp/doc-sum-prompts.json
- --model deepseek-chat
- --output-dir ./benchmarks
- --executor-adapter deepseek
4. 报告 run_id 和 raw 文件路径
5. 如果 使用deepseek-exector出错,请明确报告错误原因,不要假装成功
"""
print("=== Step 2: 构建测试集 + 运行 Benchmark ===")
print("注意:此步骤需要 耗时约 2-5 分钟")
response_eval2 = await stream_chat_response(agent_eval, prompt_eval_step2, history=eval_history)
# 记录 benchmark 是否成功(用于 Step 3 的前置判断)
benchmark_raw_dir = BASE_DIR / "benchmarks" / "raw"
benchmark_raw_files = sorted(benchmark_raw_dir.glob("*.json")) if benchmark_raw_dir.exists() else []
benchmark_step2_ok = len(benchmark_raw_files) > 0
if benchmark_step2_ok:
print(f"\n benchmark 生成成功,raw 文件数: {len(benchmark_raw_files)}")
print(f" 最新 raw 文件: {benchmark_raw_files[-1].name}")
else:
print("\n benchmarks/raw/ 下无文件,Step 2 可能未完成")
print(" 可能原因:claude CLI 未安装 / 未登录 / Skill 路径错误")
print(" Step 3 将跳过,请修复上述问题后重新运行 Step 2")
- 提取触发信号 + 生成评分报告
# Step 3: 提取触发信号 + 生成评分报告
# 前置守门:只有 Step 2 成功生成 raw 文件才继续
if not benchmark_step2_ok:
print("[警告] Step 2 未成功,跳过 Step 3")
print("请确认 claude CLI 已安装并登录,然后重新运行 Step 2")
response_eval3 = "(skipped: benchmark not available)"
else:
eval_history.extend([
{"role": "user", "content": prompt_eval_step2},
{"role": "assistant", "content": response_eval2},
])
prompt_eval_step3 = """
benchmark 已完成。请继续:
1. 找到刚才生成的 raw JSON 文件(在 ./benchmarks/raw/ 目录下)
2. 运行 scripts/extract_trace_signals.py <raw_file_path> 提取触发信号
3. 运行 scripts/judge_real_results.py <raw_file_path> 生成评分报告
4. 以表格形式展示每条提示的触发情况:
- prompt_id | 期望触发 | 实际触发 | 结果(PASS/FAIL)
5. 给出触发准确率(%)和五维度评分建议
"""
print("=== Step 3: 提取信号 + 评分报告 ===")
response_eval3 = await stream_chat_response(agent_eval, prompt_eval_step3, history=eval_history)
聚合结果:v1 baseline 报告 链接到标题
# 在 Python 层面读取评分结果(不依赖 Agent 解析)
import json
benchmarks_dir = BASE_DIR / "benchmarks" / "raw"
if benchmarks_dir.exists():
raw_files = sorted(benchmarks_dir.glob("*.json"))
if raw_files:
latest = raw_files[-1]
data = json.loads(latest.read_text())
runs = data.get("runs", [])
print(f"run_id: {data.get('run_id')}")
print(f"评估的 Skill: {data.get('skill_targets', [])}")
print(f"总计 prompts: {data.get('prompt_count', 0)}")
print()
passed = 0
total = len(runs)
print(f"{'Prompt ID':<12} {'期望触发':<10} {'实际触发':<10} {'结果':<8}")
print("-" * 45)
for run in runs:
pid = run.get('prompt_id', '?')
expected = run.get('expected_trigger', True)
ws = run.get('with_skill', {})
trace = ws.get('trace_signals', {})
actual = bool(trace.get('skill_triggered', False))
ok = (expected == actual)
if ok:
passed += 1
status = "PASS" if ok else "FAIL"
exp_str = "是" if expected else "否"
act_str = "是" if actual else "否"
print(f"{pid:<12} {exp_str:<10} {act_str:<10} {status:<8}")
accuracy = 100 * passed // total if total > 0 else 0
print(f"\n触发准确率: {passed}/{total} ({accuracy}%)")
if accuracy < 70:
print("结论: 触发质量偏低,建议优先优化 frontmatter(v1 -> v2)")
elif accuracy < 90:
print("结论: 触发质量一般,有改进空间")
else:
print("结论: 触发质量良好")
else:
print("未找到 benchmark raw 文件,请先运行上面的评估步骤")
else:
print("benchmarks 目录不存在,请先完成 Step 2")
本 Notebook 完整演示了:
| 阶段 | Skill | 核心脚本 |
|---|---|---|
| 资格检查 | skill-benchmark | candidate_check.py |
| Baseline 评估 | skill-benchmark | run_real_benchmark.py |
| 触发信号提取 | skill-benchmark | extract_trace_signals.py |
| 评分报告 | skill-benchmark | judge_real_results.py |
Agent 在整个流程中扮演的角色:读取 SKILL.md → 理解工作流 → 调用脚本 → 解读结果, 人类只需要提供意图描述,Agent 负责执行和汇报。
根据评估结果推进 Skill 进化 链接到标题
这一部分只保留 4 个核心动作:
读取 v1 的 benchmark 证据
按
skill-creator-pro约束更新 Skill再次执行 review,确保更新后的内容仍符合最佳实践
重跑 benchmark,对比 v1 / v2 的结果
# 1) 收集 v1 证据:定位 Skill、读取 benchmark 结果、生成复用测试集
# 这里尽量只保留后续进化真正需要的变量。
skill_dir = BASE_DIR / "skills" / "document-summarizer"
if not skill_dir.exists():
print(f" 未找到 {skill_dir},请先完成前面的 Skill 创建步骤")
raise SystemExit("请先创建 document-summarizer Skill")
raw_dir = BASE_DIR / "benchmarks" / "raw"
raw_files = sorted(raw_dir.glob("*.json"))
if not raw_files:
print(" 未找到 benchmark raw 文件,请先完成 Step 2 的评估")
raise SystemExit("请先完成 v1 benchmark 评估")
baseline_raw_file = raw_files[-1]
baseline_data = json.loads(baseline_raw_file.read_text(encoding="utf-8"))
baseline_run_id = baseline_data.get("run_id", "unknown")
baseline_runs = baseline_data.get("runs", [])
# 提取失败样本,后面直接作为 v2 修改的输入证据。
baseline_failures = []
prompt_payload = []
passed = 0
for run in baseline_runs:
expected = bool(run.get("expected_trigger", True))
actual = bool(run.get("with_skill", {}).get("trace_signals", {}).get("skill_triggered", False))
if expected == actual:
passed += 1
else:
baseline_failures.append({
"prompt_id": run.get("prompt_id", "?"),
"prompt_text": run.get("prompt_text", ""),
"expected_trigger": expected,
"actual_trigger": actual,
})
# 复用同一批 prompts,保证 v1 / v2 的 benchmark 可比。
prompt_payload.append({
"prompt_id": run.get("prompt_id"),
"prompt": run.get("prompt_text", ""),
"should_trigger": expected,
"expected_skill": run.get("expected_skill"),
"expected_route": run.get("expected_route"),
"required_output_signals": run.get("required_output_signals", []),
})
baseline_accuracy = 100 * passed // len(baseline_runs) if baseline_runs else 0
evolution_prompt_file = Path("/tmp/doc-sum-prompts-evolution.json")
evolution_prompt_file.write_text(
json.dumps(prompt_payload, ensure_ascii=False, indent=2),
encoding="utf-8",
)
# 保存 v1 内容,后面用于快速对比是否真的发生了修改。
skill_target_rel = str(skill_dir.relative_to(BASE_DIR))
skill_md_before = (skill_dir / "SKILL.md").read_text(encoding="utf-8")
parts_before = skill_md_before.split("---", 2)
skill_frontmatter_before = parts_before[1].strip() if len(parts_before) >= 3 else "(no frontmatter found)"
print(f"Skill 路径: ./{skill_target_rel}")
print(f"v1 run_id: {baseline_run_id}")
print(f"v1 触发准确率: {baseline_accuracy}%")
print(f"失败样本数: {len(baseline_failures)}")
print(f"复用测试集: {evolution_prompt_file}")
for row in baseline_failures:
print(f"- {row['prompt_id']} | expected={row['expected_trigger']} | actual={row['actual_trigger']}")
print(f" {row['prompt_text']}")
print("\n--- v1 frontmatter ---")
print(skill_frontmatter_before)
- 直接执行 v2,优化迭代Skill
# 2) 直接执行 v2 更新:重点修复触发问题,同时保持最佳实践约束
# 这里不再单独拆“计划”步骤,直接让 Agent 基于证据修改目标 Skill。
prompt_evolution_apply = f"""
请更新 ./{skill_target_rel},把它从 v1 演化到 v2。
执行要求:
1. 先读取 skills/skill-creator-pro/SKILL.md
2. 再读取 ./{skill_target_rel}/SKILL.md
3. 重点根据下面这些失败样本优化触发逻辑,优先修改 description、triggers、non_triggers 和示例表达
4. 如有必要,再补 workflow、constraints、validation,但不要无关扩张
5. 只能修改 ./{skill_target_rel} 目录,不要写到其他 document-summarizer 副本
6. 修改完成后,列出实际修改的文件,并概括本次改动
失败样本如下:
{json.dumps(baseline_failures, ensure_ascii=False, indent=2)}
"""
print(prompt_evolution_apply)
print("=== Evolution Step 1: 更新 Skill 到 v2 ===")
response_evolution_apply = await stream_chat_response(agent_eval, prompt_evolution_apply)
# 3) 再次执行 review:确保 v2 不是“能跑就行”,而是仍然符合 skill-creator-pro 规范
review_history = [
{"role": "user", "content": prompt_evolution_apply},
{"role": "assistant", "content": response_evolution_apply},
]
prompt_evolution_review = f"""
请对更新后的 ./{skill_target_rel} 再次执行质量审核。
要求:
1. 先重新读取 skills/skill-creator-pro/SKILL.md
2. 运行 skills/skill-creator-pro/scripts/review_skill.py ./{skill_target_rel}
3. 如果存在 high 或 medium findings,立即修复后重新验证
4. 最终告诉我是否通过,并输出 v2 的 frontmatter 摘要
"""
print(prompt_evolution_review)
print("=== Evolution Step 2: 再次 review v2 ===")
response_evolution_review = await stream_chat_response(agent_eval, prompt_evolution_review, history=review_history)
# Python 侧补一次独立检查,确认文件确实发生了变化。
skill_md_after = (skill_dir / "SKILL.md").read_text(encoding="utf-8")
parts_after = skill_md_after.split("---", 2)
skill_frontmatter_after = parts_after[1].strip() if len(parts_after) >= 3 else "(no frontmatter found)"
print("\nSKILL.md 是否发生变化:", skill_md_before != skill_md_after)
print("\n--- v2 frontmatter ---")
print(skill_frontmatter_after)
- 重新生成 benchmark,对比v1版本评估!
# 4) 用 agent_eval 重跑 benchmark
rebenchmark_history = [
{"role": "user", "content": prompt_evolution_review},
{"role": "assistant", "content": response_evolution_review},
]
prompt_rebenchmark = f"""
请继续执行评估,对进化后的 Skill 重跑 benchmark。
1. 使用已有的测试集文件:{evolution_prompt_file}
2. 运行 scripts/run_real_benchmark.py 执行基线对比
- --skill ./{skill_target_rel}
- --mode trigger-only
- --prompts {evolution_prompt_file}
- --model deepseek-chat
- --output-dir ./benchmarks
- --executor-adapter deepseek
3. 报告 run_id 和 raw 文件路径
4. 如果运行出错,请明确报告错误原因,不要假装成功
"""
print("=== Evolution Step 3: 重跑 benchmark (agent 驱动) ===")
print("注意:此步骤耗时约 2-5 分钟")
response_rebenchmark = await stream_chat_response(agent_eval, prompt_rebenchmark, history=rebenchmark_history)
# Python 侧检查 raw 文件是否新增(判断 benchmark 是否真的跑成功)
benchmark_raw_dir = BASE_DIR / "benchmarks" / "raw"
all_raw_files = sorted(benchmark_raw_dir.glob("*.json")) if benchmark_raw_dir.exists() else []
rebenchmark_ok = len(all_raw_files) > 1 # v1 已有 1 个,v2 应有第 2 个
if rebenchmark_ok:
rebenchmark_v2_raw_file = all_raw_files[-1]
print(f"\n v2 benchmark 生成成功")
print(f" 最新 raw 文件: {rebenchmark_v2_raw_file.name}")
else:
print("\n benchmarks/raw/ 下无新文件,benchmark 可能未完成")
print(" 可能原因:DEEPSEEK_API_KEY 未配置 / deepseek executor 调用失败 / Skill 路径错误")
print(" Step 4 对比将跳过,请修复后重新运行本步骤")
小结:最小化的进化闭环 链接到标题
精简后的新增代码只保留一条最核心的工程链路:
读取 v1 证据 → 按 skill-creator-pro 更新 v2 → 再次 review → 重跑 benchmark → 对比结果
这样既能演示“评估驱动进化”的逻辑,也不会让 notebook 的代码组织过重。
skill-benchmark 脚本与五维度评估的映射关系
| 评估维度 | 对应脚本 | 核心指标 |
|---|---|---|
| 触发质量 | extract_trace_signals.py + judge_real_results.py | 10 个测试用例中的触发准确率 |
| 路由质量 | run_real_benchmark.py(route 场景) | 决策路径清晰度、路由正确率 |
| 上下文效率 | candidate_check.py | SKILL.md 行数、资源引用是否合理 |
| 复用与确定性 | score_benchmark.py | 相同输入多次运行的输出一致性 |
| 验证强度 | aggregate_results.py | 成功判据覆盖率、失败检查点数量 |
工具跑完之后,我们就有了一份客观的基准报告(v1-baseline.json)。这份报告将在后续每次迭代结束后重新运行,用来对比前后版本的变化,让"进化"真正有据可查。
通过评分我们可以清楚看到,最需要优先解决的不是性能,而是触发准确性。接下来,我们将基于这一结论做更深入的问题诊断。
第八章:深度问题诊断 链接到标题
评估只能告诉我们“哪里分低”,但还不足以告诉我们“为什么会低”。因此,下一步必须把评估结果转化为更深入的问题诊断。只有找到根因,后续迭代才不会停留在表面修补。
8.1 问题1:触发准确性不足(最严重) 链接到标题
典型误触发案例包括:
用户要求“分析文档风险”,却被当成摘要任务
用户说“翻译这篇 PDF”,却错误进入总结流程
用户要求“读取文档内容”,结果触发了摘要输出
典型漏触发案例包括:
“帮我提炼这份报告的重点”没有触发
“把这篇材料压缩成汇报提纲”没有触发
根因在于:frontmatter 描述过宽,却缺乏正反示例约束。
8.2 问题2:输出质量不稳定(次要) 链接到标题
在真实用户反馈中,我们发现摘要的主要波动体现在:
某些结果过于笼统
某些结果漏掉关键数据
某些结果结构完整,但信息密度不足
输出质量问题分类
| 问题类型 | 表现 |
|---|---|
| 结构稳定但内容空泛 | 有标题,缺要点 |
| 内容有覆盖但重点不突出 | 信息多,压缩不足 |
| 关键数据丢失 | 只总结观点,遗漏数字与结论 |
根因在于:当前总结策略过于单一,没有根据文档特征切换不同的压缩方式,也缺乏输出质量检查。
8.3 问题3:大文档处理慢(潜在) 链接到标题
对于 10MB 级别的大文档,v1 需要约 120 秒才能完成处理。这个问题尚未成为最致命短板,但在实际使用中会明显拉低体验。
根因主要有两个:
文档处理是串行的
没有结果缓存
8.4 问题优先级排序 链接到标题
三个问题的优先级排序
| 问题 | 严重度 | 优先级 |
|---|---|---|
| 触发准确性不足 | 高 | P0 |
| 输出质量不稳定 | 中 | P1 |
| 大文档处理慢 | 中低 | P2 |
因此,后续进化路径明确为:

为了让诊断结论不只停留在人工阅读,我们引入 skill-benchmark 提供工具化证据支撑。其中最直接帮助我们定位触发问题的,是 extract_trace_signals.py。
用工具提取误触发证据
extract_trace_signals.py 会读取已有的 benchmark 运行日志,逐条列出每个测试请求的触发结果,让我们一眼看清楚"哪些应该触发的没有触发,哪些不应触发的却触发了":
# 提取触发信号,生成可读的证据记录
!python ~/.claude/skills/skill-benchmark/scripts/extract_trace_signals.py \
benchmarks/raw/real-babae861d7.json
运行完成后,输出示例如下:
# skill-benchmark 触发准确性测试输出示例
# should-trigger: "总结这份 PDF" → triggered (正确)
# should-trigger: "压缩汇报摘要" → not triggered (漏触发)
# should-not-trigger: "翻译这篇文章" → triggered (误触发)
# should-not-trigger: "分析这份报告的风险" → not triggered (正确)
# edge: "帮我精简这段长文字" → triggered (正确)
工具的价值不是替代人工判断,而是把"我觉得触发不准"变成"数据证明触发不准"。有了这份证据记录,我们才能在下一轮进化时,有底气地说"这次改动解决了具体哪些误触发/漏触发"。
第九章:三条核心认知 链接到标题
走完完整案例之后,我们需要从具体实践中提炼出可迁移的方法论。否则课程就会停留在“我会做一个 document-summarizer”,而不是“我理解了如何设计和进化一个 Skill”。
9.1 核心认知1:创建完成 ≠ 好用,创建只完成了 20% 链接到标题
这是整套案例最重要的结论,也是很多初学者最容易忽视的认知盲区。创建只是起点,真正耗时和真正创造价值的部分,往往发生在后续评估与迭代中。一个刚写完的 Skill,往往只解决了表面的触发问题,而触发准确性、输出质量、执行效率等深层问题需要通过评估才能暴露,需要通过迭代才能真正解决。这也是为什么我们把整个 Part 3 的大部分篇幅都放在了评估与进化,而不是创建本身。
9.2 核心认知2:宁缺毋滥,Skills 不是越多越好 链接到标题
一个系统里 Skill 太多,往往带来三种伤害:
触发冲突增加
维护成本上升
用户信任感下降
因此,5 个精调的 Skill,通常优于 20 个没有打磨过的 Skill。
9.3 核心认知3:SKILL.md 是指挥官,不是士兵 链接到标题
SKILL.md 的职责是指挥流程,而不是亲自承担所有执行逻辑。代码、模板、参考资料都应该回到它们各自的层次,这样 Skill 才能真正可维护。
9.4 课程总结与下一步 链接到标题
到这里,学员应该已经完整看到一个 Skill 的全生命周期:
如果说前两部分内容解决的是“什么不能做”和“应该怎么设计”,那么 最后这部分内容 真正解决的是最后一个问题:一个 Skill 到底是怎样被做出来、做扎实、做成熟的。
第十章:最后实战——mini-OpenClaw Agent Skills 系统 链接到标题
在前面九章中,我们完成了 Agent Skills 设计体系最核心的三层建构:第一层是反面冲击——通过三个坏 Skill 建立起对「什么不能做」的直觉认知;第二层是规则提炼——从 SRP、SoC、信息精炼三条原则出发,掌握判断一个 Skill 好坏的客观标准;第三层是全生命周期——从设计选型、质量评估到深度问题诊断,我们见证了一个 Skill 如何从粗糙初版走向成熟稳定。
但如果这些知识只停留在 Notebook 示例和单个 SKILL.md 文件里,仍然很难回答一个更重要的问题:在一个真实运行的 Agent 系统中,Skills 究竟扮演什么角色?它们是如何被系统发现、加载、注入给大模型的?这正是第十章存在的原因。mini-OpenClaw 是一个完整的轻量级 AI Agent 对话系统,它把本课所有 Skills 相关的设计理念都真实地落在了工程代码里。通过这个项目,我们会第一次清晰看到:SKILL.md 不是一个配置文件,而是 Agent 能力扩展的完整闭环的起点。
10.1 项目引入:为什么用真实系统收口 Skills 知识 链接到标题
这一节的核心是建立一个认知:Skills 的价值,不是体现在单个 SKILL.md 文件里写了多少内容,而是体现在一个完整系统是否能够「发现它、理解它、用它」。在前面的课程中,我们看到了 Skills 如何被设计出来,但还没有看到 Skills 是如何被一个 Agent 系统真正消费的。
mini-OpenClaw 恰好提供了这个视角。它是一个教学级的轻量 Agent 系统,不追求业务复杂度,而是刻意把 Skills 的整个流转链路——从文件系统扫描到注入 System Prompt 再到 Agent 执行——设计得清晰可读。通过阅读和运行这个项目,你会第一次真正理解:我们在课程中设计的每一条 SKILL.md 规范,在系统层面都有精确对应的处理逻辑。这种从「设计」到「运行」的完整映射,是本章最重要的教学目标。
10.2 项目概览与技术栈 链接到标题
mini-OpenClaw 是一个轻量级 AI Agent 对话系统,采用前后端分离架构,核心特点是:工具调用过程完全可视化、Skills 通过文件系统热扩展、记忆管理支持传统注入和 RAG 向量检索两种模式。这个项目在设计上刻意保持了「最小工程骨架」——每一层的代码量都控制在可以快速读懂的范围内,目的就是让学员能够聚焦在架构思路上,而不是被工程细节淹没。
从功能层面看,系统支持以下几项核心能力:基于 LangChain + DeepSeek 的 AI Agent 智能对话、工具调用的实时可视化(能看到 Agent 的每一步思考和执行轨迹)、通过添加 SKILL.md 文件即可扩展新技能、支持传统记忆文件注入和 RAG 向量检索两种长期记忆模式、多会话管理与历史压缩、以及基于 SSE 的流式输出。
在深入代码之前,我们先通过技术栈总览建立整体印象。下表列出了项目每一层的技术选型及其在系统中承担的职责。
mini-OpenClaw 技术栈与职责对照
| 层级 | 技术选型 | 核心职责 |
|---|---|---|
| 前端 | Next.js 14 + React 18 + TypeScript + Tailwind CSS | 对话界面、会话管理、工具调用可视化 |
| 后端 | FastAPI + Python 3.10+ | REST API、SSE 流式输出、业务逻辑 |
| Agent 引擎 | LangChain + DeepSeek | 多轮推理、工具调度、System Prompt 组装 |
| 记忆检索 | LlamaIndex + OpenAI Embedding | MEMORY.md 向量化、RAG 相似度检索 |
| 实时通信 | SSE(Server-Sent Events) | 流式返回生成内容和中间事件 |
| Skills 扩展 | 文件系统(SKILL.md) | 技能定义、自动扫描、动态注入 |
从技术栈中可以看出,项目对 Skills 扩展的实现方式非常直接:没有数据库、没有注册中心、没有复杂的插件协议,只是通过文件系统中的 SKILL.md 文件来定义技能,系统启动时自动扫描并生成快照注入给 Agent。这种「文件即配置」的设计理念,恰好印证了本课程反复强调的信息精炼原则——配置应该是人类可读可编辑的,而不是隐藏在代码里的魔法常量。
10.3 本地运行:三步把项目跑起来 链接到标题
这一节的首要目标不是读代码,而是先把项目在本地真正跑起来。只有当浏览器里出现一个可以交互的 Agent 系统,前面所有关于 Skills 的抽象讨论才会真正落地。项目目录位于课程配套资源中的 mini-OpenClaw项目源码/ 目录下,采用标准的前后端分离结构,环境要求为 Python 3.10+ 和 Node.js 18+。
整个启动过程分为三步:确认目录结构、配置环境变量、执行一键启动脚本。每一步都有明确的成功判据,按照顺序执行,通常在 3 分钟内即可完成首次启动。
步骤一:进入项目目录,确认结构完整
首先进入项目根目录,查看目录结构是否完整。如果能看到 backend/、frontend/、scripts/ 和 README.md,说明项目文件完整,可以继续下一步。
# 在终端中执行以下命令(此处展示预期目录结构)
!ls mini-OpenClaw项目源码/
执行后应能看到 backend/、frontend/、scripts/、README.md、PROJECT_ARCHITECTURE.md 等关键目录和文件。如果目录不完整,请确认是否已将课程配套资源完整解压到当前工作目录。
步骤二:配置环境变量
项目运行依赖两个核心 API Key:DEEPSEEK_API_KEY 用于驱动 Agent 的语言模型,OPENAI_API_KEY 用于 RAG 模式下的向量 Embedding(若不使用 RAG 模式可暂时忽略)。进入 backend/ 目录,复制示例配置文件并填写自己的 Key。
# backend/.env 配置示例(请根据实际情况填写)
# 复制 backend/.env.example 为 backend/.env,然后修改以下配置项
# .env 文件内容示例:
# DEEPSEEK_API_KEY=sk-xxxxxxxxxxxxxxxx # DeepSeek API Key(必填)
# OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx # OpenAI API Key(RAG 模式必填,其他模式可留空)
# MODEL_NAME=deepseek-chat # 使用的模型名称
# BACKEND_PORT=8002 # 后端服务端口
# 在终端执行:
# cp mini-OpenClaw项目源码/backend/.env.example mini-OpenClaw项目源码/backend/.env
# 然后用编辑器打开 .env 文件,填入真实的 API Key
print("请参考上方注释,在 backend/.env 中配置你的 API Key")
配置完成后,.env 文件应位于 backend/.env,且 DEEPSEEK_API_KEY 已填入真实值。注意:.env 文件包含敏感信息,不要提交到 Git 仓库,项目的 .gitignore 已默认排除该文件。
步骤三:执行一键启动脚本
项目提供了跨平台的一键启动脚本,脚本会自动完成 Python 虚拟环境创建、依赖安装以及前后端服务启动,无需手动逐步配置。首次运行时由于需要下载依赖,速度会稍慢,后续启动会直接跳过依赖安装步骤。
# macOS / Linux 启动方式(在终端中执行)
# chmod +x mini-OpenClaw项目源码/scripts/start-macos-linux.sh
# ./mini-OpenClaw项目源码/scripts/start-macos-linux.sh
# Windows 启动方式(在命令提示符或 PowerShell 中执行)
# mini-OpenClaw项目源码\scripts\start-windows.bat
# 启动成功后,访问以下地址:
# 前端界面:http://127.0.0.1:3000
# 后端 API:http://127.0.0.1:8002
# API 文档:http://127.0.0.1:8002/docs
print("启动脚本说明:请在系统终端(非 Notebook)中执行上方对应平台的启动命令")
启动成功的判据是:浏览器打开 http://127.0.0.1:3000 后能看到对话界面,同时 http://127.0.0.1:8002/docs 能看到 FastAPI 自动生成的 API 文档页面。到这里,我们就从「课件里的 Skills 概念」真正进入了「可交互的 Agent 工程系统」。
常见问题:若前端无法连接后端,请检查
frontend/.env中的NEXT_PUBLIC_API_BASE_URL是否指向http://127.0.0.1:8002;若 Agent 无法回复,请确认backend/.env中的DEEPSEEK_API_KEY填写正确且账户有余额。
10.4 架构分层解析:三层协同 链接到标题
项目跑起来之后,接下来的问题是:每一层代码分别在做什么?它们之间如何协同?这一节我们不逐行读代码,而是从三层架构的视角来理解系统的整体运转机制,建立一张清晰的「心智地图」,后续读任何一个具体文件时都能快速定位它属于哪一层、解决什么问题。
mini-OpenClaw 的架构分为三层:前端展示层、后端 API 层、Agent 核心层。三层之间通过 SSE(Server-Sent Events)流式协议连接,每一层各司其职,边界清晰。
10.4.1 前端展示层(Next.js 14) 链接到标题
前端由三个核心区域组成:左侧 Sidebar 负责会话列表管理(新建、重命名、删除会话);中央 ChatPanel 是主对话区,实时展示 Agent 的消息流,包括文本回复和工具调用事件;右侧 InspectorPanel 是文件编辑器,内置 Monaco Editor,支持在线查看和编辑 workspace/ 及 skills/ 目录下的配置文件。
工具调用可视化是前端最有教学价值的功能:每当 Agent 调用一个工具,前端不会只显示最终回答,而是把工具名称、输入参数、执行结果都以独立卡片的形式展示出来。这让学员能够直接「看见」Agent 的推理过程,而不是只看到一个黑盒输出。
10.4.2 后端 API 层(FastAPI) 链接到标题
后端暴露了一组 REST API 端点,每个端点职责单一、边界清晰。其中最核心的是 POST /api/chat——这是一个 SSE 流式端点,接收用户消息后,把请求转发给 Agent 核心层,并将 Agent 执行过程中产生的每一个事件(思考中、工具调用开始、工具调用结束、最终回复)实时推送给前端。其他端点包括会话管理(/api/sessions)、文件读写(/api/files)、历史压缩(/api/sessions/{id}/compress)和 RAG 模式切换(/api/config/rag-mode)。
10.4.3 Agent 核心层(LangChain + DeepSeek) 链接到标题
Agent 核心层是整个系统的大脑,由三个关键组件组成:prompt_builder.py 负责组装 System Prompt(将 6 个配置文件按固定顺序拼接,Skills 快照排在第一位);session_manager.py 负责维护多会话的对话历史、注入系统提示词、管理上下文窗口;memory_indexer.py 负责将 MEMORY.md 向量化并提供相似度检索能力(RAG 模式专用)。Agent 引擎使用 LangChain 的工具调用机制,配合 DeepSeek 模型完成多轮推理和工具调度。
10.5 Skills 扩展机制:课程知识在真实系统中的落地 链接到标题
这一节是第十章最核心的部分,也是整门课程最重要的收口。前九章我们一直在回答「如何设计好一个 SKILL.md」,这一节则回答另一个同等重要的问题:一个写好的 SKILL.md 文件,是如何被系统发现、处理并最终让 Agent 学会这项技能的?整个链路分为四个环节,我们逐一拆解。
10.5.1 环节一:SKILL.md 的标准格式 链接到标题
系统对 SKILL.md 有明确的格式要求:文件必须以 YAML Frontmatter 开头,包含 name(技能名称)和 description(技能描述)两个必填字段;Frontmatter 之后是技能的具体内容,包括使用场景、执行步骤和注意事项。我们来看项目自带的 get_weather 技能作为格式参考。
# 读取项目自带的 get_weather 技能文件,观察标准 SKILL.md 格式
skill_path = "mini-OpenClaw项目源码/backend/skills/get_weather/SKILL.md"
with open(skill_path, encoding="utf-8") as f:
content = f.read()
print(content)
从 get_weather 的 SKILL.md 可以清晰看到三个部分的职责分工:Frontmatter 中的 name 和 description 是给系统解析用的(机器可读),正文中的「使用场景」对应本课讲的触发条件设计,「执行步骤」是 Agent 的行动指南,「示例」则提供了 Few-Shot 示范,帮助 Agent 精确理解执行预期。这正是本课第三章「信息精炼原则」在真实系统中的体现——SKILL.md 只写 Agent 执行时需要的内容,不堆砌背景知识。
10.5.2 环节二:skills_scanner 自动扫描 链接到标题
有了规范的 SKILL.md 文件之后,系统需要一个机制来发现它。mini-OpenClaw 的做法是:在应用启动时,调用 skills_scanner.py 中的 scan_skills() 函数,自动遍历 backend/skills/ 目录下的所有 SKILL.md 文件,解析 Frontmatter,生成一份 XML 格式的技能快照文件 SKILLS_SNAPSHOT.md。以下是这个扫描器的核心实现。
# 核心代码解析:skills_scanner.py 的扫描逻辑(概念代码,说明工作原理)
import yaml
from pathlib import Path
def scan_skills(base_dir: Path) -> str:
"""扫描 skills/ 目录下所有 SKILL.md,生成 XML 格式的技能快照。"""
skills_dir = base_dir / "skills"
snapshot_path = base_dir / "SKILLS_SNAPSHOT.md"
skills = []
# 递归查找所有 SKILL.md 文件
for skill_md in sorted(skills_dir.rglob("SKILL.md")):
content = skill_md.read_text(encoding="utf-8")
# 解析 YAML Frontmatter(--- 分隔符之间的内容)
if content.startswith("---"):
parts = content.split("---", 2)
if len(parts) >= 3:
meta = yaml.safe_load(parts[1]) # 解析 name 和 description
if meta:
skills.append({
"name": meta.get("name", skill_md.parent.name),
"description": meta.get("description", ""),
"location": f"./backend/skills/{skill_md.parent.name}/SKILL.md",
})
# 构建 XML 格式快照,供 prompt_builder 注入 System Prompt
lines = ["<available_skills>"]
for s in skills:
lines.append(" <skill>")
lines.append(f" <name>{s['name']}</name>")
lines.append(f" <description>{s['description']}</description>")
lines.append(f" <location>{s['location']}</location>")
lines.append(" </skill>")
lines.append("</available_skills>")
snapshot = "\n".join(lines)
snapshot_path.write_text(snapshot, encoding="utf-8") # 写入 SKILLS_SNAPSHOT.md
return snapshot
# 演示:对 mini-OpenClaw 项目的 skills 目录执行扫描
base = Path("mini-OpenClaw项目源码/backend")
result = scan_skills(base)
print(result)
执行上方代码后,我们能看到一份 XML 格式的技能快照,其中每个 `` 节点包含技能名称、描述和文件路径。这份快照有两个关键设计点值得注意:第一,它只提取了 Frontmatter 中的 name 和 description,而不是把整个 SKILL.md 的内容都塞进来——这体现了「摘要优先」的设计思路,让 Agent 先知道「有哪些技能可用」,再按需读取详细内容;第二,location 字段保留了技能文件的路径,Agent 可以在需要时通过 read_file 工具读取完整的 SKILL.md 获取详细执行步骤。这正是本课「关注点分离」原则的工程实践——快照负责发现,SKILL.md 负责执行指导,两者职责不重叠。
10.5.3 环节三:prompt_builder 注入 System Prompt 链接到标题
技能快照生成后,下一个问题是:它怎么让 Agent 知道这些技能的存在?答案是通过 prompt_builder.py 将快照注入 System Prompt。build_system_prompt() 函数按固定顺序拼接 6 个配置文件,SKILLS_SNAPSHOT.md 排在第一位,优先级最高。以下是这段核心逻辑。
# 核心代码解析:prompt_builder.py 的 System Prompt 组装逻辑
# 这段代码展示了 6 层配置文件如何按优先级顺序拼接成完整的 System Prompt
from pathlib import Path
MAX_COMPONENT_LENGTH = 20000 # 单个组件最大字符数,防止 context 溢出
def _read_component(path: Path) -> str:
"""读取配置文件,支持 UTF-8 / GBK / latin-1 三级编码回退。"""
if not path.exists():
return ""
raw = path.read_bytes()
for enc in ("utf-8", "gbk", "latin-1"):
try:
content = raw.decode(enc)
break
except (UnicodeDecodeError, ValueError):
continue
else:
content = raw.decode("utf-8", errors="replace")
if len(content) > MAX_COMPONENT_LENGTH:
content = content[:MAX_COMPONENT_LENGTH] + "\n...[truncated]"
return content
def build_system_prompt(base_dir: Path, rag_mode: bool = False) -> str:
"""按固定顺序拼接 6 个 Markdown 文件,构建完整 System Prompt。
拼接顺序(优先级从高到低):
1. SKILLS_SNAPSHOT.md — 可用技能快照(最先注入,Agent 优先感知)
2. workspace/SOUL.md — Agent 人格与行为边界
3. workspace/IDENTITY.md — Agent 名称与风格
4. workspace/USER.md — 用户画像与偏好
5. workspace/AGENTS.md — 操作规范与记忆协议
6. memory/MEMORY.md — 跨会话长期记忆(RAG 模式下跳过)
"""
components = [
("Skills Snapshot", base_dir / "SKILLS_SNAPSHOT.md"), # 技能快照排第一
("Soul", base_dir / "workspace" / "SOUL.md"),
("Identity", base_dir / "workspace" / "IDENTITY.md"),
("User Profile", base_dir / "workspace" / "USER.md"),
("Agents Guide", base_dir / "workspace" / "AGENTS.md"),
]
if not rag_mode: # 非 RAG 模式才直接注入完整记忆文件
components.append(("Long-term Memory", base_dir / "memory" / "MEMORY.md"))
parts = []
for label, path in components:
content = _read_component(path)
if content:
parts.append(f"<!-- {label} -->\n{content}") # HTML 注释标记来源,便于调试
return "\n\n".join(parts)
# 演示:观察 System Prompt 的前 500 个字符(包含技能快照)
base = Path("mini-OpenClaw项目源码/backend")
prompt = build_system_prompt(base)
print("System Prompt 总长度:", len(prompt), "字符")
print("\n--- System Prompt 开头部分(技能快照)---")
print(prompt[:800])
执行后我们能看到:System Prompt 开头部分正是 SKILLS_SNAPSHOT.md 的内容,以 `` 标记开头,紧跟着 XML 格式的技能列表。这个设计非常重要——把技能快照放在 System Prompt 的最前面,意味着 LLM 在处理每一条用户消息之前,首先感知到的就是「我有哪些可用技能」,这大幅提升了技能触发的准确率,避免了 LLM 忘记使用已定义技能的问题。
这也印证了本课第七章「触发质量」评估维度的底层逻辑:技能触发不准,很多时候不是 SKILL.md 写错了,而是技能信息没有出现在 LLM 注意力最集中的位置。prompt_builder 的顺序设计解决的正是这个问题。
10.5.4 环节四:新增技能的完整流程演示 链接到标题
理解了前三个环节之后,我们来看最后一个环节:如果要给系统新增一个技能,操作流程是什么?答案出乎意料地简单。
# 演示:新增一个「计算器」技能的完整流程
# 步骤 1:在 skills/ 目录下创建新技能文件夹并写入 SKILL.md
import os
from pathlib import Path
skills_base = Path("mini-OpenClaw项目源码/backend/skills")
new_skill_dir = skills_base / "calculator"
new_skill_dir.mkdir(exist_ok=True)
new_skill_content = """---
name: calculator
description: 执行数学计算,支持加减乘除和复杂表达式
---
# 计算器技能
## 使用场景
当用户需要计算数学表达式、做单位换算或数值比较时使用。
## 执行步骤
1. 从用户消息中提取数学表达式
2. 使用 `python_repl` 工具执行计算:
```python
result = eval("expression")
print(result)
- 将计算结果以清晰的格式回复给用户
注意事项 链接到标题
- 只计算数学表达式,不执行任何文件操作或系统命令
- 对于复杂的科学计算可引入 math 模块 """
skill_file = new_skill_dir / “SKILL.md” skill_file.write_text(new_skill_content, encoding=“utf-8”) print(f"技能文件已创建:{skill_file}")
步骤 2:重新扫描 skills 目录,生成新的快照 链接到标题
import yaml
def scan_skills(base_dir):
skills_dir = base_dir / “skills”
snapshot_path = base_dir / “SKILLS_SNAPSHOT.md”
skills = []
for skill_md in sorted(skills_dir.rglob(“SKILL.md”)):
content = skill_md.read_text(encoding=“utf-8”)
if content.startswith("—"):
parts = content.split("—", 2)
if len(parts) >= 3:
meta = yaml.safe_load(parts[1])
if meta:
skills.append({“name”: meta.get(“name”), “description”: meta.get(“description”, “”)})
lines = ["<available_skills>"]
for s in skills:
lines.append(f"
base = Path(“mini-OpenClaw项目源码/backend”) skills = scan_skills(base) print(f"\n扫描完成,共发现 {len(skills)} 个技能:") for s in skills: print(f" - {s[’name’]}: {s[‘description’]}")
  执行后能看到技能列表中新增了 `calculator`,这就是 `mini-OpenClaw` 技能扩展的完整闭环:新增技能只需三个动作——创建目录、写 SKILL.md、重启后端,无需修改任何代码,系统会在下次启动时自动发现并注入新技能。
  这套设计完美对应了本课第三章的三条规则:`SRP`(每个 SKILL.md 只做一件事)、`SoC`(描述与实现分离,Frontmatter 供系统解析,正文供 Agent 执行)、信息精炼(SKILL.md 只写 Agent 执行时真正需要的内容)。至此,我们在课程中学到的所有设计原则,都找到了在真实系统中的精确对应。
  下面这张表格将本课九章的核心知识点与 `mini-OpenClaw` 的工程实现做了完整映射,帮助你建立从「设计」到「运行」的全景视图。
**课程知识点与 mini-OpenClaw 工程实现映射**
| 课程知识点 | mini-OpenClaw 对应实现 | 核心文件 |
|-----------|----------------------|----------|
| SRP 单一职责 | 每个 `SKILL.md` 只定义一项技能 | `backend/skills/*/SKILL.md` |
| SoC 关注点分离 | Frontmatter(机器读)与正文(Agent 读)分离 | `skills_scanner.py` |
| 信息精炼原则 | 快照只提取 name+description,不注入全文 | `SKILLS_SNAPSHOT.md` |
| 触发质量(维度1) | 技能快照排在 System Prompt 第一位 | `prompt_builder.py` |
| 设计范式 Operator | `get_weather`:单工具链封装 | `skills/get_weather/SKILL.md` |
| 全生命周期管理 | 技能文件即配置,重启自动更新 | `app.py` → `scan_skills()` |
| 宁缺毋滥原则 | 5 个核心工具 + 按需扩展 Skills | `backend/tools/` |
### 10.6 本章总结:从 Skills 设计到 Agent 产品
  到这里,整门课程最后一块拼图就补完了。回顾一下我们走过的路径:从反面案例建立直觉,到三条规则建立判断标准,到七种设计范式拓展思维边界,到五维度质量评估体系建立客观量化方法,再到全生命周期管理掌握 Skill 从诞生到成熟的完整路径,最后通过 `mini-OpenClaw` 这个真实的工程项目,把所有设计知识收拢进一个可运行、可观察、可扩展的系统里。
  这个收口有一个具体的价值:它回答了一个贯穿全课的隐性问题——我们在 `SKILL.md` 里写的那些内容,在真实系统中是被怎么对待的?现在我们知道了答案:`SKILL.md` 先被 `skills_scanner` 扫描提取摘要,再被 `prompt_builder` 注入 System Prompt 的最前端,最终成为 LLM 在每次对话中最先感知到的上下文。一个精心设计的 SKILL.md,最终的落点是 LLM 的注意力。这是 Skills 设计的终极目标,也是本课所有规则和原则的共同指向。
  从这门课出发,你已经具备了进入真实 Agent 工程项目的基础能力:能够识别坏设计、能够按原则设计好 Skill、能够评估和迭代现有 Skill,也能够理解 Skills 在系统中的完整流转链路。接下来的成长方向,是在真实项目中把这些能力用起来——设计更多覆盖不同场景的 Skills,并在实际使用中持续观察、评估、迭代。
**整门课程学习路径总览**
| 章节 | 核心问题 | 学完能做的事 |
|------|----------|-------------|
| 第1章 | 怎么搭环境? | 独立配置 Agent 实验环境并运行 Skills |
| 第2章 | 什么是坏设计? | 识别万能型、厨房水槽型、复制粘贴型三类坏 Skill |
| 第3章 | 好设计的规则是什么? | 用 SRP / SoC / 信息精炼三条原则评判任意 Skill |
| 第4-5章 | 如何系统选型? | 从 7 种设计范式中选出最匹配任务特征的范式 |
| 第6章 | 如何完整创建一个 Skill? | 按需求分析 → 范式选型 → 资源规划 → 实现的流程设计 Skill |
| 第7章 | 创建完成是好用吗? | 用五维度评估体系客观量化 Skill 质量 |
| 第8章 | 评估低分怎么办? | 定位根因并制定有针对性的迭代方向 |
| 第9章 | 三条核心认知是什么? | 建立 Skill 全生命周期的成熟度认知 |
| 第10章 | Skills 在真实系统中如何工作? | 读懂 SKILL.md 在工程系统中的完整流转链路 |